3-2:性能評価の意義
3-3:評価
参考文献
第1章:はじめに
1-1.WWWの歴史
70年代後半から、分散処理を基本としたシステムの必要性が高まってきた。それまでの集中処理を基本としたコンピュータシステムでは、性能を上げるためには、より高速で、より記憶容量の大きいコンピュータが必要になり、そのためには大型コンピュータを導入するしかなかった。しかし、負荷が、ホストコンピュータに集中するために、処理速度が低下し、高性能な機種に変更する事で一概に解決する事が出来なくなってきた。そこで、このホストコンピュータに集中する負荷を減らすために、分散処理が考えられ、発展してきた。当時の分散処理は、入力機能、記憶機能、処理機能などの大型計算機の機能を分散するものであった。やがて、異機種のコンピュータ、互換性のないオペレーティングシステムでも互いにデータのやり取りできるものへと発展する。
80年代入ると、UCバークレーが、DECのVAXシステム用にTCP/IPを装備したUNIXのバークレー版を配布。UNIXは多くの研究者を魅了し、以後研究機関等で広く用いられるようになっていった。
この頃のインターネットはどちらかと言うと研究機関中心のネットワークであった。これは共同研究を行う場合でも大きなメリットになった。しかし現実にはネットワークにつながっているからといって、研究者が望む情報を他のコンピュータから簡単に取り出せたわけではない。例えば、ネットワークに繋がっている別のコンピュータ上にある情報を手に入れようとした場合でも、そのコンピュータの名前、接続に必要なIDとパスワードが必要になり、仮にそれをうまく手に入れられたとしても、その情報が本当に求めていたものかどうかわかるまでには、かなりの時間がかかってしまう。
この状況を改善したのが、当時ヨーロッパ原子核研究所(CERN)の研究員であったティム・バーナーズ・リーである。リーはインターネット上の異なるコンピュータにある論文を簡単に検索、閲覧できないものかと考え、1989年「情報管理に関する提案」を提唱した。これはインターネットに繋がる全員が、共通のソフトウェアをパソコンに入れて交信すれば、互いの文書及び情報を共有する事が出来るというものである。この提案に基づきリーはマウス1つでクリックするだけで世界中のコンピュータから芋づる式に文書を取り出せるソフトウェアを書き上げた。これを用いたシステムは、「世界中のパソコンを結びつける蜘蛛の巣」という意味で“World Wide Web”と名づけられた。
しかしこれで一気にWWWが普及したわけではない。なぜならリーの開発したシステムはNEXTと呼ばれるコンピュータでのみ動くため小規模なものであった。そこで、リーはこのシステムの仕様と構造をインターネット上に公開し、他の研究者に移植をゆだねた。
これを知った、当時イリノイ大学のスパーコンピュータ応用センター(NCSA)でソフトウェアの開発をするアルバイトをしていたマーク・アンドリーセンは、クリック1つで文書を取り出せるWWWで絵(写真)も表示できないかと考えた。彼は友人のロブ・マックール、ジョン・ミッテルハウザー、アレックス・トテックらと共に、「絵の表示できるWWW」の研究開発にのめりこんでいった。1993年「Mosaic」と呼ばれるソフトウェアを開発した。
彼らは、1994年Mosaic Communications社を設立。1994年10月「Netscape」と呼ばれるブラウザソフトを開発し、インターネット上に無料でこれを公開した。また1995年Micrisoft社が、オペレーティングシステムである「Windows95」を発売。「Windows95」はインターネットへの接続をより簡単にできるようにした。Microsoft社はInternet Explorer(IE)というWebブラウザで「Netscape」の牙城を崩しにかかった。IEはWindows95と共に人気を博し、1998年Netscapeをシェアで逆転した。その後、ハイパーテキストの言語であるHTMLが改善されたり、ネットワークに対応したプログラミング言語のJAVA等、新技術の導入に見られるように常に進化している。
このように、WWWの歴史はその登場から現在まで10数年しか経っていない。
しかし、WWWのホスト数は爆発的に増えており、情報を如何に効率よく見つけ出せるかが問題となってきた。この社会の需要により次項に述べる情報検索技術が求められた。
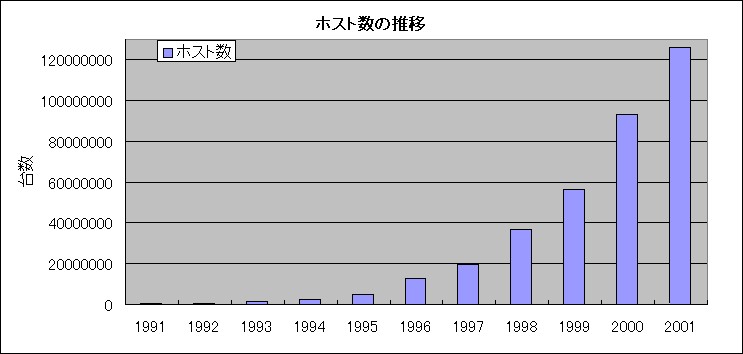
上の図は、WWWのホスト台数の推移であり、爆発的な増加が見て取れる。
1-2.検索エンジンの歴史
WWWの開発当初はWWWのサーバー数自体もそれほど多くなく,ハイパーテキストリンクをたどりながらページを閲覧していくブラウジングによって十分に情報を得ることができた。しかしWWWの規模が大きくなるにしたがって,文書間の構造はより複雑になり,ブラウジングによって求める情報を探すことが非常に困難になってきた。自分が今WWWの世界のどこにいるのかを見失ってしまうということもしばしばである。そこでこのような問題を解決するためにできたのが,広大なインターネットの世界から求める情報を容易に探し出すことを可能にする情報検索システムである。
インターネットにおける情報検索にはWWWのもの以外にも、ArchieGopher,Veronica,WAISなどが利用されてきた。以下にその概要を説明する。
- Archie(アーキ)
FTPサーバのファイル名を検索対象とするキーワード検索システムである。 Archie は,ユーザが欲しいフリーソフトウェア等のアーカイブの存在する場所(ネットワーク上のどの アノニマス ftp サイトと,その anonymous ftpのどこにあるか)を検索するためのシステムである。ユーザは,キーワードとして欲しいアーカイブのファイル名(の一部でも可能)で検索することができる。 - Gopher(ゴーファ)
各サーバ(FTPサーバ,Archieサーバ,Gopherサーバ,WAISサーバ)が持つディレクトリ 情報を検索対象とするカテゴリ検索システムである。 Gopher は,ある項目ごとに分類されたメニューから,必要なデータを検索するために利用される。ユーザは,図書館で,分野別に分類されたインデックスから,読みたい本を探す感覚で利用することができる。 - Veronica(ベロニカ)
Gopherのメニュー項目(ディレクトリ名,ファイル名)を検索対象とするキーワード検索システムである。 Archieを使えば,全てのFTPサイトでファイルの検索を行なえるが,Veronicaを使っても同様に全てのGopherサイトでメニュー項目の検索を行ない,更にその資料をデータソースから直接取り寄せることができる。 - WAIS(ウエイズ)
WAISサーバの保持するテキストデータの全文を検索対象とするキーワード検索システムである。 WAISは,WAISクライアントを介して,インターネット上に存在するWAISデータベースのサイトから必要な情報を取り出すために利用される。情報を取り出すために,WAISサーバが提供している以下のような検索機能を利用することができる。- 自然言語による検索
- 論理演算子を利用する検索
- 自然言語と論理演算子による検索
- 項目検索
- 日付と数字の範囲指定よる検索
- 前方一致による検索
- 検索語のグループ化による検索
- 妥当性フィードバックによる検索
1994年頃に発表されたJumpstationが、WWWのサーチエンジンとしては初めての本格的なサーチエンジンであった。同年にLycos、Yahoo!、WebCrawlerといったより強力なサーチエンジンが大学レベルで次々とできた。1995年にはInfoseekが当初から企業レベルでサービスを始めた。やがては、日本でも大学レベルで千里眼、Mo-n-do-u、そしてODINというものが開発され、企業レベルでは、NTT DIRECTORY、NETPLAZAというような国内系のものが現れたが、とくに海外のInfoseek、OpenText、Yahoo!が1996年、日本に進出した。また、HotBotの日本語版であるgooも, 1997年3月にサービスを開始している。さらに,AltaVistaも1998年5月に、Lycosは7月に、それぞれ日本語に対応した。
つまり、WWWの歴史と同様にサーチエンジンの歴史もまだ浅い。しかし、試験的な意味でのサーチエンジンは消えていった。この数年間だけでなくこの一年間でもサーチエンジンは大きく変化している。
現在サーチエンジンは大学の研究プロジェクトからサービス産業へと移行しており、各サーチエンジン間の競合が一段と激しくなっている。インターネットにおける情報検索のうち1994年以降はWWWの情報検索システムにその人気は移っていった。Gopherなどの情報検索は現在でも利用できるが、これらのものはこれ以上ほとんど発展はしておらず、WWWの利用者の増加に比べてむしろ減少していく傾向にある。
1-3.最近の検索エンジンの動向
Web検索エンジン開発の歴史はインターネットの開始から数えてもまだ数年しか経っていない。この間にWebコンテンツが爆発的に増加したため、検索エンジンの性能は短期間にもかかわらず進歩を遂げている。検索エンジンで[ネットワーク]や[コンピュータ]、[IT]と言った語句を検索すると,およそ10万件近く見つかる。これは良いのだが,"重要な探し物を簡単に見つける"という検索エンジンの登場理由からすると、この10万件というヒット数は果たして正当な検索結果といえるだろうか。検索ヒット数が10件程度ならば,一つ一つを見てユーザが判断できるが,10万件では無理である。
これは、自動プログラムには,文章の意味するところ,たとえばそれが全体のテーマなのか,ある特定のジャンルなのか,詩なのか芝居なのか,あるいは広告なのかといったことを判別する機能がないことによる。
さらにウェブには,自動索引づけを支援するような標準が存在しない。結果としてウェブ上の文書構造はばらばらで,人間なら簡単に判断できるような,著者,出版の年月日,テキストの長さといった「メタデータ」も,プログラムにとっては取り出すことが難しい。たとえば,よくある名前の著者の記事をウェブ探索プログラムで探す場合,この名前が出てくる何千もの無関係な記事や参考文献をいっしょに検索してしまうのである。
そこで、この検索結果をいかに処理しユーザの求める情報を表示するかという技術を重視する傾向がでてきた。
1999年10月にGoogleがリンク情報を利用した検索システムを登場させ、日本語Googleは2000年9月から本格サービスを始めている。この特徴は検索結果のランキングが優れていることで、ポータル化を進めている他の検索サイトが盛沢山な情報を画面いっぱいに表示するのに較べて、検索に特化した結果をシンプルなデザインで表示している。最近、日本語Googleは新しい形態素解析を導入し全文検索を強化している。
新しい技術を取り入れたサービスが登場すると、他の検索サイトは3〜6ヶ月でそれに対応する。gooは2000年10月ごろから頻繁にシステムの更新を繰り返して第3世代検索エンジンを開発し、総合的にみてGoogleよりもよい結果を得ている。
最近の検索エンジンのデータベースはばらばらのページという概念から離れ、ページを連結したり、ページに関連した情報を取り込んだり、ページ間の関連性を重視する傾向にある。しかし何を関連として追加するかが問題だが、人手で追加するのは不可能で、自動的に付加できるのが一番望ましい。単純な方法としては階層下部のページを連結することで、Googleのようにリンク情報を利用してページ間の関係を利用するのも一つの方法である。
最近の検索エンジンによる検索の特徴は、ランキング表示が改善されることと、それに付随して重点的なデータ収集が可能になることである。現在、Googleはリンクを使ってランキングをしている。goo、ODiN、Nexearchなどもリンク情報を使い始めた。
しかし、関連情報も一緒に検索するため、従来のキーワード検索のルールは適応しなくなっている。まず、検索したページのなかに検索キーワードが存在しない場合もでてくるという傾向にある。さらにラフなキーワードを使っても、同義語をある程度カバーするようになり、必然的に検索結果は多くなり、AND検索はあいまいになる。
つまりかつての、検索したコンテンツの一部や、全てを忠実に処理し表示していた時代に比べ、現在はポータル化を進め検索ヒット数を増やし、情報に重みをつけるといった、検索結果をいかに処理するかという部分に改良が移ってきている。
1-4.性能評価の問題
性能評価に関する論文は数多くあるが,ユーザ側の立場にたった論文は数少ない。斎藤裕樹、中所武司両氏の論文"透過的クライアント監視層によるネットワークシステムの性能評価システムの開発"[13]によると、従来、インターネット技術を用いたネットワークシステムの品質評価のために、端末間の到達性の保証や、リンクの性能確保を目的とした評価技術が開発されてきた。しかし、これらの評価技術は主にネットワーク層の機器の管理を目的としたものであり、アプリケーション層での品質指標ではない。利用者の利便性確保を目的としたネットワークサービスの品質評価のためには、アプリケーション層での性能評価が求められる。
アプリケーション層でのネットワークシステムの性能には、帯域、ルータの処理能力、端末間のスループット、サーバーシステムやクライアントシステムの性能など、多くの要因がある。また、主なネットワークシステムで用いられているTCPの性能はネットワーク層やアプリケーション層の特性に左右される事が知られている。このため、これまでのネットワークシステムの性能評価には、ネットワーク管理者の技術的な知識、経験や勘などが必要とされてきた。
しかし、これらはユーザが直接感じるネットワークサービスではない。また勘や経験に頼った評価であり、客観性に欠ける。
以上のような観点から、クライアントアプリケーションの振る舞いを観測する監視層を導入し、ネットワークシステムの性能評価を行う方式を提案している。
同論文では,クライアントとサーバ間でやり取りされる要求—応答単位の通信に着目し,クライアントアプリケーションの挙動を観測する事により,終点アプリケーションの性能を評価する方式を提案し、実装実験を行っている。この実装実験では,監視層のオーバーヘッドの検証を行い、オーバーヘッドは平均2%でありこの監視層の導入による影響は少ないと結論付けている。また、監視層が性能を性格に計測する事ができるかを、稼動中のWWWシステムの性能を監視層で計測した場合と、サーバのアクセス記録で計測した場合との比較によって検証している。これによると、サーバのアクセス記録では、バッファリングの影響で計測自体が不正確なものとなるとしている。