GET 要求ファイル名 [プロトコル.バージョン] CRLF
を送る。
(3)サーバは、クライアントからの要求にこたえてファイルの内容を送る、そのとき、次の情報も付加する。
- プロトコル情報
- ファイル作成年月日、時間
- サーバ情報
- MIMEバージョン情報
- ファイルのデータ・タイプ
(4)クライアントは,サーバから送られてきたファイル本体の情報をファイルデータ・タイプに適した形式で表示する。
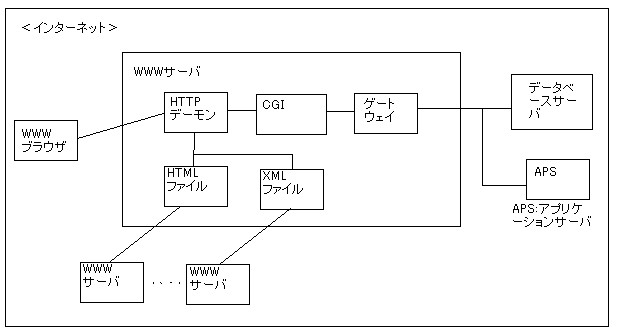
2-1.WWWサーバー
WWWシステムのサーバーとは、WWWのサービスを行うコンピュータである。つまり クライアントであるWWWブラウザの要求に従って、HTTPを用いてファイルを送信するサーバの事である。また,CGIなどを介して,データベースの処理結果や他のアプリケーションの処理結果を返送する事もできる。
サーバは,クライアントからリクエストを受け取ると、その返事としてレスポンスを返す。レスポンスの形式は、HTTPの規格として定められているが、おおまかな形式は次のとおりである。
Full-Reaponse =Status-Line
*(General-Header
| Response-Header
| Entity-Header )
CRLF
[Entity-Body]
メッセージはheaderとbodyに分けられる。headerとbodyはひとつの空行(CRLFのみぼ行)で区切られる。headerは複数の行からなり各行もCRLFで区切られる。
Headerの先頭行はStatus Lineと呼ばれ、クライアントの要求に対する返答が記入される。
レスポンスの例:
HTTP/1.0 200 OK <−ステータスライン
Date: Mon,7 Jan 2002 15:52:11 GMT <−以下ヘッダー>
Server: ○○
Content-type:text/html
Content-length: 454
<HTML> <−以下ファイルー>
...
</BODY>
</HTML>
ステータスラインとは、HTTPのヴァージョン、リクエストに対するコードが書かれる。クライアントがサーバからファイルを取得する事ができる時は「200 OK」などが帰ってくる。
2-2.WWWクライアント
WWWシステムでいうクライアントとは、インターネットに接続されたコンピュータ上で動く、Webブラウザの事である。HTTPプロトコルを利用してWWWサーバと通信処理しながら,WWWサーバ上のHTMLファイルやXMLファイルを取得する。クライアントからWWWサーバへ送る命令をリクエスト(Request)という。そのメッセージの最初の行には、Method、リソースの認識、使われているプロトコルヴァージョンが含まれる。これらには,下位互換性のために,Full-RequestとSimple-Requestの二つがある。以下にそれぞれについて説明する
シンプルリクエス:
Simple-Request = "GET" SP Request-URI CRLF
フルリクエスト:
Full-Request = Request-Line
*(General-Header
| Request-Header
| Entity-Header)
CRLF
[Entity-Body]
Request-Lineは、
Method SP Request-URI SP HTTP-Version CRLF
という形式で書かれる。
Full-RequestのReqest-LineとSimple-Requestの注目すべき違いは、GET以外の有用性とHTTP-Versionである。
また、(Method)には、"GET","HEAD","POST"があり
- GET—ヘッダーとファイル本体を取得する。
ブラウザはこのメソッドを使ってWWWサーバからファイルをダウンロードする。ブラウザは,HTMLファイルをダウンロードするとHTMLの内容を解析し,そのページで使用されている画像ファイルやJavaなどのファイルがあれば自動的にGETリクエストを出してダウンロー素子,ブラウザ上に表示する。
- HEAD—ヘッダーのみを取得する。
ファイルをダウンロードしないので,ホームページが更新されたかどうかをチェックする時などに使われる。
- POST—ブラウザからサーバへデータを転送する
メールフォームにメッセージなどを書き込んで送信できるホームページ等がこのメソッドを使っている。
Request-URIはプロキシを経由する場合とそうでない場合とで異なり、以下のようになる。
プロキシを経由する場合:
GET http://www.w3.org/pub/WWW/TheProject.html HTTP/1.0
プロキシを経由しない場合:
GET /pub/WWW/TheProject.html HTTP/1.0
この違いは,クライアントから直接サーバにリクエストを送る場合、すでにホスト○○のポート××とTCP接続をしているためである。つまり,プロキシを通す場合は、クライアントからのリクエスト行からホスト名、ポート番号を読み取り指定された接続をプロキシが行うために、それらの情報が必要になるのである。
リクエストに関する注意として,あるHTTP/1.0サーバがSimple-Requestを受け取ると、そのサーバはHTTP/0.9Simple-Requestを一緒にして答えなければならないので、Full-Responseを受け取れるHTTP/1.0のクライアントは,決してSimple-Requestを発生させるべきではない。また、URIは空ではならず、もしオリジナルURIが無いのであれば,それは"/"として与えなければならない。
2-3.Webプロキシ

プロキシとは,内部ネットワークと外部ネットワークの間に位置し、データが一方から他方に移動するときに、ある一定の処理を行う機能である。実際にこの役割を果たす サーバ の事を,プロキシサーバ と呼ぶ。
プロキシとは、「代理」という意味で、元々はネットワークを流れるデータのセキュリティや適合性をチェックするために考え出された仕組みである。プロキシの応用使用として,<日本語文字コードの自動変換> がある。これは文字コードの変換機能をプロキシがまとめて請け負うことで、個々のソフトは変換機能を持つ必要がなくなり、効率的に動作できるようになる。
また、外部からのデータやアクセス要求を一時的に貯めておくキャッシュサーバ>としての利用法もあり、WWW のページなど一旦ネットワークから取得したデータを、しばらくの間プロキシサーバに保存する事により、再び同じデータが必要になった際、ネットワーク経由でデータを取得するのではなく、代わりにプロキシサーバ上のデータを使い、ネットワーク経由よりも高速にデータの取得が可能になる。
さらに,セキュリティーに適用し、外部の侵入者からネットワークを守る<ファイアーウォール >としても使える。これは、インターネットの弱点であるセキュリティをカバーする機能で、外部と内部のネットワークの間にプロキシサーバを置く事によって、外部からの不正な進入や内部で発生した障害が外部に広がってしまうのを防ぐ。ただし、すべてのデータがプロキシのチェックを受けるために、通信速度は遅くなる。
上記でも少し述べたように,プロキシはクライアントに変わってサーバと接続する。プロキシはクライアントからのリクエストを解析し、そこから"ホスト名"、"ポート番号"、"HTTPバージョン"を読み取り、指定されたホストへ指定されたポートで接続する。さらに、クライアントからのリクエストを,ちょうど上の"プロキシを経由しない場合"と同じようなリクエストに書き換え、サーバに送る。
つまりプロキシを経由する場合
GET http://www.w3.org/pub/WWW/TheProject.html HTTP/1.0
という要求をクライアント側はする必要がある。この要求からプロキシは,
ホスト名:www.w3.org
ポート番号:80(リクエストに特にポート番号の指定が無い場合、WWWのデフォルト値80を使用する)
という接続に必要な情報を得て,接続し必要な情報を得ることができる。
そしてプロキシサーバは、接続先に次のように書き換えた、新たな要求を置くる。
GET /pub/WWW/TheProject.html HTTP/1.0
これにより接続先から要求に対する、応答を受け、クライアントに転送する。
またプロキシアプリケーションは、実際に要求を送信する前に,その要求に対して多くの操作を行う。ローカルプロキシキャッシュを調べて,要求されたデータがすでに存在していないかどうかを確認するのもプロキシアプリケーションの責任となる。データが存在し,存続期間(TTL)が期限切れになっておらず,オブジェクトが相手先サーバ上で変更されていない場合は,プロキシアプリケーションは,インターネットでそのオブジェクトを取得する変わりにキャッシュから取得して要求側に送信する。
プロキシは,リクエストループを避けるため別名も含めて全てのサーバ名、IPアドレスを見分ける事が出来なければならない。
MicrosftのInternet Explorerでの設定方法。[ツール]−>[インターネットオプション]−>[接続]−>[設定]と進み,"プロキシサーバを使用する"のチェックボックスをチェックする。アドレスにはプロキシの名前を入れ,ポートには使用するポート番号を指定する。これで,プロキシを使用することができるようになる。