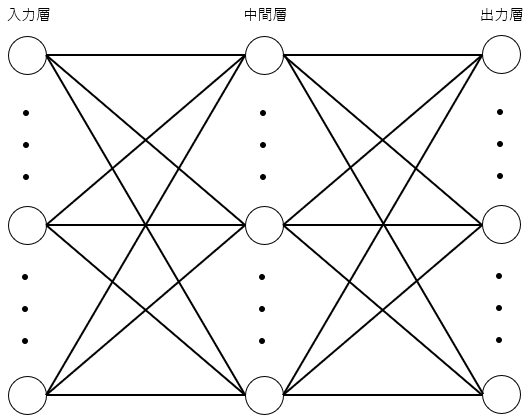
図2.1:ニューラルネットワークの例
東京電機大学 工学部 情報通信工学科
ネットワークシステム研究室
指導教員 坂本 直志
16EC111 町田 拓海
ニューラルネットを作成し学習を行う際には、それに適した様々なハイパーパラメータを設定する必要がある。これを適切に設定しないと効率的な学習を行うことができない。本研究では、このハイパーパラメータの中でもニューロン数に焦点を置いた。具体的には、手書き文字認識用のテストデータセットを用いてニューラルネットが機能する最低数のニューロン数を探索し、機能しているニューロン数としないニューロン数ではどのような違いがあるかを調査する。
ニューラルネットワークとは、人間の脳内の神経細胞(ニューロン)とそのつながりを数式的なモデルで表現したものである。それは、入力層、出力層、隠れ層で構成されている。各層のニューロンの間には重み「W」があり出力層と隠れ層のニューロンはバイアス「b」を持っている。図2.1にニューラルネットの例を示す。
図2.1:ニューラルネットワークの例
各ニューロンはそのニューロンへの入力x_iと重みw_i、バイアスbを参考にyが出力される。yは、次の式で表される。
ここでfとは活性化関数と呼ばれるもので通常は非線形関数である。
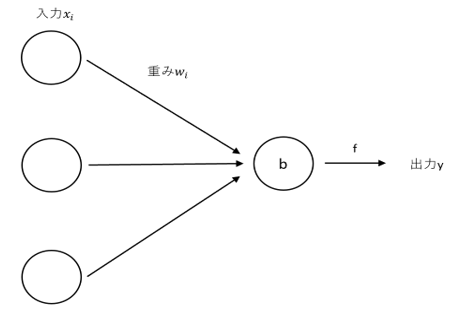
図2.2:ニューロンへの入力と出力例
活性化関数にはさまざまな種類があるが、今回は隠れ層ではReLU関数を使用している。ReLU関数とは、入力した値が0以下のとき0になり1より大きい場合入力がそのまま出力されるという関数である。その式を以下に示す。
一方出力層では次で定義されるソフトマックス関数を用いた。今回の研究では、MNISTと呼ばれるデータセットの画像を0~9に分類するニューラルネットワークを使用するため分類問題に該当する。分類問題というのは、データのクラス分けのことである。分類問題では、出力層での活性化関数にソフトマックス関数を用いる。ソフトマックス関数とは、分母に全出力の和を分子に各出力の値を入れることで、値を正規化して出力する。式を以下に示す。
この活性化関数を使用することで出力を確立として出力することができる。 入力層に値を与え隠れ層、出力層と順に計算していき値を出力することを順伝搬という。 しかし、重みWやバイアスbといったパラメータを最適に定めるためには学習用のデータを使って学習を行わせる。入力から順伝搬で得た出力と教師データの値の差である損失Lを求めそれを最小にしていくようにパラメータw_i,bの最適化を行っていく。その最適化を行うために誤差逆伝搬法というアルゴリズムが使用されている。 誤差逆伝搬法では、勾配降下法を用いて各パラメータを最適化していく。例えば以下の式のように、誤差に対する各重みの勾配をネガティブフィードバックして
徐々に値を更新していく。ここでαは学習率と呼ばれるもので、この大きさによってパラーメータの更新速度を調整することができる。 このパラメータの最適化手法には勾配降下法以外にも様々なものがある。今回はAdamと呼ばれる最適化手法を使用するため解説する。 Adamとは、勾配の二乗平均と平均を考慮することでパラメータごとに適切なスケールで重みが更新される最適化手法である。式を以下に示す。
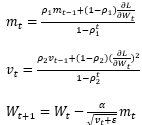
ハイパーパラメータは、α=0.001, ρ_1=0.9, ρ_2=0.999, ε=10^(-8)で設定されることが多い。 出力層の活性化関数にソフトマックス関数を用いる場合、損失関数を求めるのに交差エントロピー誤差を用いる。交差エントロピー誤差の式を以下に示す。
ここでt_kは教師データである。
MNISTとは、60,000の学習用画像と10,000のテスト画像とその画像に書かれた数字を表すラベルデータから構成されるデータセットである。解像度は28×28の256のグレイスケールである。
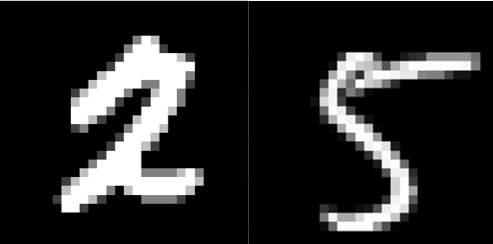
図2.3:MNISTデータ画像例(左から2,5)
この研究の目的は、ニューラルネットワークが機能する必要最小限のニューロン数を発見し、その時のニューロン数と機能していないときのニューロン数ではどのような相違点があるのかを探索することである。そのために一つ目は、隠れ層のニューロン数を1~100に対して、各ニューロン数でのテストデータに対する正答率を調査する。 二つ目は、正答に貢献していないニューロンと機能しているニューロンで重みを比較し、違いを調査する実験を行う。
今回の研究で使用するニューラルネットの構成は入力層、隠れ層1層、出力層の全3層の全結合層で構成されている。活性化関数にはReLU関数が使用されている。入力層のニューロン数は784個、出力層のニューロン数は10個、隠れ層のニューロン数は状況によって変更している。入力層には28×28の数値の文字画像が入力される。
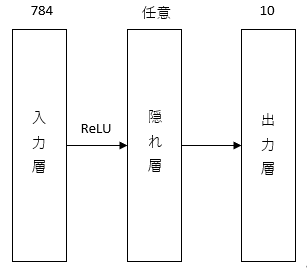
図3.1:使用するニューラルネットの構成
・実験内容
3.2のニューラルネットの構成で隠れ層のニューロン数を1~100にひとつずつ増やしていき、各ニューロン数でのテストデータに対する正答率を調査する。エポック数は100回ミニバッチサイズは1024で学習を10回行った。
・実験結果
それぞれのニューロン数での最大の正答率をまとめたグラフを以下に示す。グラフから最初に大きく値が変化しニューロン数40ほどで正答率が収束したことがわかる。さらにニューロン数が5まで来ると正答率が9割付近に達していることが分かる。このことからニューロン数を5まで上げるとある程度ニューラルネットが機能しているとしてニューロン数5とあまり機能していないニューロン数1で比較を行う。
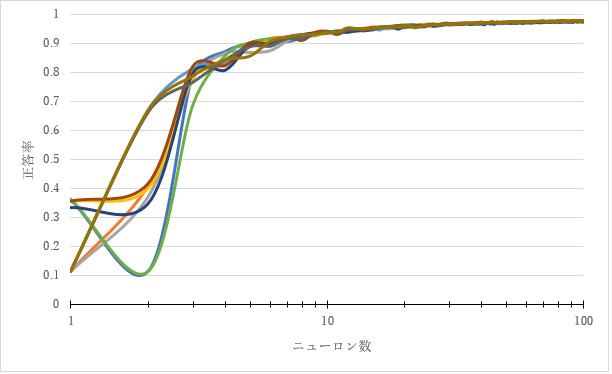
図3.2:ニューロン数1~400での正答率
・実験内容
ニューロン数1の時の、入力層から隠れ層の重みとニューロン数5の時の、入力層から隠れ層の重みを比較する。3.2のニューラルネットの構成で隠れ層のニューロン数を1,5に設定し、エポック数は400回ミニバッチサイズは1000で学習を10回行った。なお取得した重みは学習を400エポック行った最終的な値を取得した。
・実験結果
取得した値を5より上,5以下1より上,1以下0.1より上,0.1以下-0.1より上,-0.1以下-1より上,-1以下-5より上,-5以下に分類した。その各平均と標準偏差を取ったグラフを以下に示す。以下のグラフからニューロン数1の時はニューロン数5の時に対して重みが0.1~-0.1の範囲に多く分布していることが分かる。
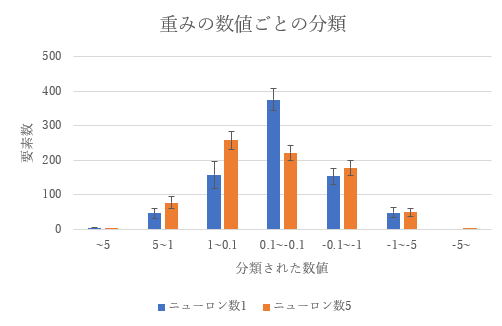
図3.3:ニューロン数1,5の重みの数値ごとの分類
3.3からは、MNISTを用いた学習では、ニューロン数5で既に正答率88.9%ほどに達しているため意外と少ないニューロン数である程度の精度を確保できることが確認できた。そしてある程度機能しているニューロン数5のニューラルネットとニューロン数1のニューラルネットで比較を行った結果、双方には重みの大きさが0.1から-0.1の範囲に分布している量に大きな差があった。具体的にはニューロン数1の時は平均375.1個、ニューロン数5の時は平均221.36個で153.74個もの差があった。ニューロン数1の時は、入力層と隠れ層の間の重みの数が784個であるのに対してニューロン数5の時の重みの数は、3920個である。そのため重みの数が少ないニューロン数1のほうがニューロン数5よりも一つ一つの重みの大きさが大きくなるといったイメージがあったが、実際にはニューロン数1は0.1から-0.1という非常に小さい範囲に多くの値が集中していた。ここからニューロン数1の時はニューロン数5の時に対して、結果に大きな影響を与える重みの数が少ないといえる。ここからニューロン数1の時にニューラルネットがあまり機能していない原因として、単純にニューロン数が足りずパラメータの数が足りないという理由だけではなく機能している重みが少ないということが考えられる。今後の課題としては、実際に値が非常に小さい重みを抜いてニューラルネットを使用したときに重みを抜く前と抜いた後でどの程度正答率に差が出るのかを調査したい。
Class MLP(chainer.Chain)でニューラルネットの構成を記述している。
def__init__で層数をdef__call__各層の活性化関数を記述している。
for count in range(1,401)で学習を400回繰り返している。
それ以降はデータセットの読み込みやバッチサイズ、使用する最適化手法、エポック数の設定を行いtrainer.run()で学習を実行する。
class NeuralNet (chainer.Chain)でニューラルネットの構成を記述している。
def__init__で層数をdef__call__各層の活性化関数を記述している。
def check_accuracyで選択したモデルの正答率の算出を行う。
def mainで学習と学習後の重みの保存を行っている。