図1 ニューラルネットワークのモデル例
東京電機大学 工学部 情報通信工学科
ネットワークシステム研究室
担当教員 坂本 直志
17ec013 猪瀬琢磨
近年のニューラルネットワークを使ったディープラーニングの技術の進展は、様々な分野で応用されている。ディープラーニングを応用した技術は画像の分野でも応用され、画像の識別や白黒画像をカラー画像へと変換させるカラリゼーションでも使用されている。一方、それらの技術は複雑な構造のネットワークを使用しているのが主である。そこで本研究は全結合ニューラルネットワークおよび深層ニューラルネットワーク構造を利用して、どのような構造でカラリゼーションが実現できるかを模索し、考察することとする。
カラリゼーションとは、モノクロの画像や動画などに対して、コンピュータ技術を用いて色彩をつける技法である。現在までに複数の手段がすでに確立されており、2002年のWelshらの研究[3]や、2004年のLevinらの研究などによる手法[4]が存在する。Levinの手法は人間が画像へ色差情報を一部与え、それをもとにして白黒画像のカラー化を行う。 Welshの手法は、参考画像の画素の輝度地とその統計量に注目して関係関数を作り、目的の白黒画像のカラー化を行う。これをもとにしてニューラルネットワークを適用した小林らの手法[5]も開発されており、ニューラルネットワークを用いるのがカラリゼーションにおける近年の主流になっている。ニューラルネットワークをカラリゼーションに適応した代表例は、2016年の飯塚らの研究[6]があげられる。この研究では、入力画像の大特徴と局所特徴を考慮した畳み込みディープニューラルネットワークを利用した手法の開発が行われた。これにより、入寮区画像の全体の特徴と、局所的な部分の特徴の両方を学習することができる。また、入力画像の画素数が固定されず、どのような画素数の画像でもカラリゼーションが行われるのが特徴である。本研究でも近年の主流に従ってニューラルネットワークを用いた白黒画像のカラリゼーションの検討を行う。
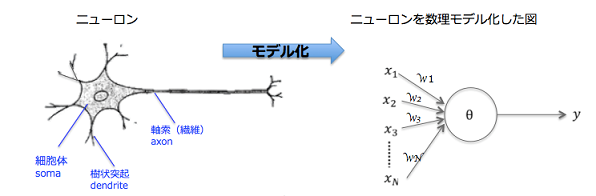
ニューラルネットワークとは、人間のニューロンを数理モデル化したものの組み合わせのことである。ニューラルネットワークの例を以下に示す。
図1 ニューラルネットワークのモデル例
図1もモデルでは、x1~xnは入力、w1~wnはネットワークの重みと呼ばれる 値で、各ニューロンの結合の強さを表している。yは出力となっている。出 力される値は、バイアスθを加えて次のように表される。
y=f(x_1 ω_1+⋯+x_n ω_n+θ)
Fは活性化関数と呼ばれる非線形の関数である。本研究ではReLU関数とSigmoid関数、tanh関数を活性化関数として使用する。ReLU関数とsigmoid関数は以下のように表される。
図1で示したようなニューロン数を多層に重ねることでニューラルネットワークは構成されている。その例を以下に示す。
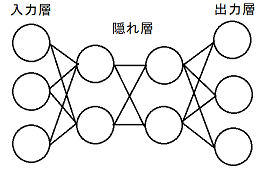
図2 隠れ層2層のニューラルネットワーク
ニューラルネットワークは、入力層、隠れ層、出力層から構成されている。隠れ層が多いニューラルネットワークは特別に「深層(ディープ)ニューラルネットワーク」と呼ばれている。また、図2のように隣接する層のノードが全てつながっているニューラルネットワークは全結合ニューラルネットワークと呼ばれる。ニューラルネットワークの学習は、出力と正解データとなる教師画像を比較し、その誤差をもとにニューラルネットワークの重み、バイアスの値を修正していくことで正解画像に近づけさせていく。
畳み込みニューラルネットワーク(Convolutional Neural Network : CNN)とは、AIが画像分析を行うための学習手法の一つである。CNNは畳み込み層とプーリング層という2つの層を含む構造の順伝播型のネットワークである。畳み込み層では、入力される画像データからエッジなどの特徴を抽出する。プーリング層は特徴の空間サイズを縮小する役割がある。データの次元削減を行い、計算に必要な処理コストを削減する役割をもつ。今回の実験ではマックスプーリイング法を採用する。マックスおうーリング層で行われる処理は、入力に対して適用されたカーネル内の画素のうち最大値を取得する処理である。
オートエンコーダとは、深層ニューラルネットワーク構造の一種であり、入力データのノイズ除去やデータの可視化のための次元削減などで活躍しているものがある。一般的な全結合ニューラルネットワークを利用したオートエンコーダの構造を以下の図に示す。
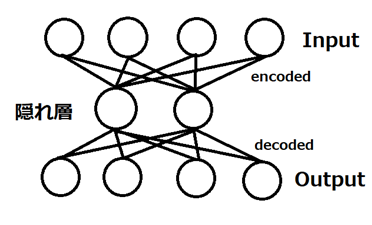
図3 オートエンコーダのモデル例
図3のモデルは隠れ層が1層のモデルで、4つの入力を2つへ圧縮(エンコード)し、再び4つの出力へと展開(デコード)している。このようにオートンコーダは次元を入力データの次元を削減してより小さなものとするエンコーダ、削減された次元を元に戻すデコーダの二つの部分から構成されている。実際の根とワークモデルでは隠れ層が3層以上のモデル等も用いられる。
畳み込みオートエンコーダとは、畳み込みニューラルネットワークを元にオートエンコーダへ利用したものである。エンコーダ部分には畳み込み層、プーリング層を用いる。今回の実験では、デコーダ部分にはアップサンプリング層を用いる。アップサンプリング層は、プーリング層で削減された次元を復元する働きをもっている。デコーダ部分で用いることで、エンコーダ部分で圧縮された次元を復元することができる。
表1 実験環境
| OS | Windows10 |
|---|---|
| CPU | Intel(R)Core(TM) i5-7200U CPU@ 2.50GHz 2.71GHz |
| メモリ | 8 GB |
表2 ライブラリ環境
| 言語 | Python3.8.3 |
|---|---|
| 機械学習 | Keras2.3.1(TensorFlow2.2.0) |
| 画像処理 | OpenCV4.1.1 |
| 行列計算 | NumPy1.16.4 |
データセットは、MNISTと、CIFAR-10データセットを使用し、それぞれ実験を行う。 CIFAR-10は10種類のクラス分けされた5万枚の訓練データと1万枚のテストデータが幅32×高さ32ピクセルのデータセットである。
まずは、CIFAR-10のような複雑な画像ではなく、MNISTに指定した色付けをして、学習させてみる。MNISTへの色付けは1から9まで、それぞれ順番に赤、青、緑、紺、黄色、オレンジ、グリーンイエロー、ピンク、茶色と色付けをした。損失関数を用いることでモデルの精度、学習の進み具合が判断できる。今回はval_lossといったどれだけ正しい結果を出力できたかを表すもので比較していく。値が小さいほど正しい結果を出力し、値が大きいほど正しい結果が出せていないと判断をすることができる。
図4に示した設定のニューラルネットワークに対して、mnistというデータを用いて、100エポックまで学習を行った。Mnistとは、手書き数字画像6万枚と、テスト画像1万枚を集めた画像データセットである。四角内の数字はノード数を表している。
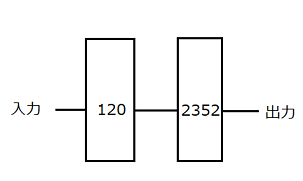
図4 全結合層2層のニューラルネットワーク
この学習済みのニューラルネットワークに対して、ランダムな10枚のmnistの白黒画像の検証用の入力を与え、出力とval_lossのグラフを観測した。

図5 全結合層2層の出力
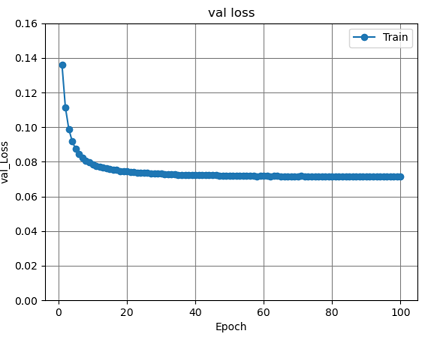
図6 全結合層2層のval_lossグラフ
前実験の構造に中間層に1層、ノード数36の層を加えて実験を行う。 つまり、図7に示した設定のニューラルネットワークに対して、mnistというデータを用いて、100エポックまで学習を行った。Mnistの数字につけた色も同様にして実験を行った。
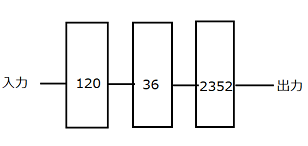
図7 全結合層3層の構造
この学習済みのニューラルネットワークに対して、ランダムな10枚のmnistの白黒画像の検証用の入力を与え、出力とval_lossのグラフを観測した。

図8 全結合層3層の出力
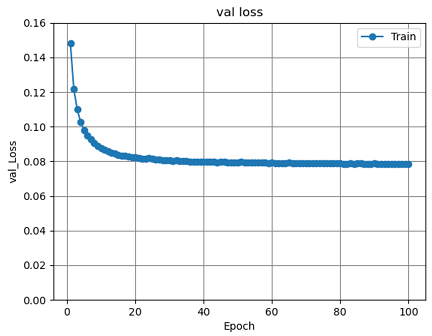
図9 全結合層3層のval_lossグラフ
前実験の構造に中間層に1層、ノード数36の層を加えて実験を行う。 つまり、図10に示した設定のニューラルネットワークに対して、mnistというデータを用いて、100エポックまで学習を行った。Mnistの数字につけた色も同様にして実験を行った。
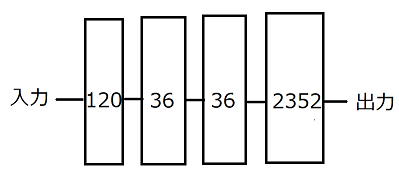
図10 全結合層4層の構造
この学習済みのニューラルネットワークに対して、ランダムな10枚のmnistの白黒画像の検証用の入力を与え、出力とval_lossのグラフを観測した。

図11 全結合層4層の出力
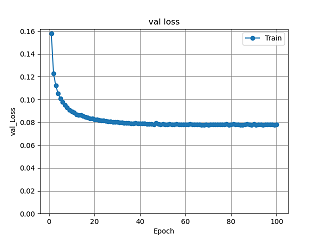
図12 全結合層4層のval_lossグラフ
前実験の構造に中間層に1層、ノード数36の層を加えて実験を行う。 つまり、図13に示した設定のニューラルネットワークに対して、mnistというデータを用いて、100エポックまで学習を行った。Mnistの数字につけた色も同様にして実験を行った。
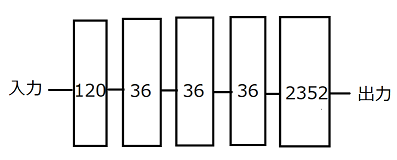
図13 全結合層5層の構造
この学習済みのニューラルネットワークに対して、ランダムな10枚のmnistの白黒画像の検証用の入力を与え、出力とval_lossのグラフを観測した。

図14 全結合層5層の出力
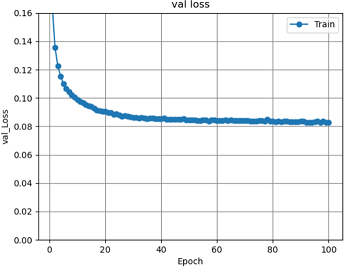
図15 全結合層5層のval_lossグラフ
これまでは全結合層のみの構造で実験をしたが、この実験では畳み込みオートエンコーダを使用して実験を行う。図16に示した構造でニューラルネットワークに対して、mnistというデータを用いて、100エポックまで学習を行った。Mnistの数字につけた色も同様にして実験を行った。畳み込み層のノード数は28-14-14-28で、エンコーダ部分とデコーダ部分をつなぐ全結合層のノード数は32である。
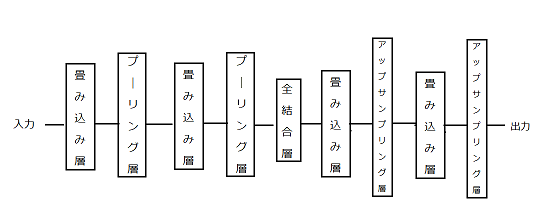
図16 畳み込みオートエンコーダ2層の構造
この学習済みのニューラルネットワークに対して、ランダムな10枚のmnistの白黒画像の検証用の入力を与え、出力を観測した。

図17 畳み込みオートエンコーダ2層の出力
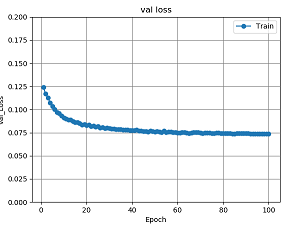
図18 畳み込みオートエンコーダ2層のval_lossグラフ
3.2.5の実験と同様で、畳み込み層とプーリング層を1層増やして実験を行う。つまり、図19に示した設定のニューラルネットワークに対して、mnistというデータを用いて、グラフを見て100エポックまで学習を行った。Mnistの数字につけた色も同様にして実験を行った。ノード数は畳み込み層28-14-7-7-14-28とし、エンコーダ部分とデコーダ部分をつなぐ全結合層のノード数は32である。
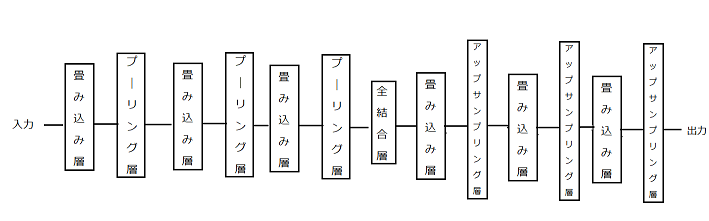
図19 畳み込みオートエンコーダ3層の構造
この学習済みのニューラルネットワークに対して、ランダムな10枚のmnistの白黒画像の検証用の入力を与え、出力を観測した。

図20 畳み込みオートエンコーダ3層の出力
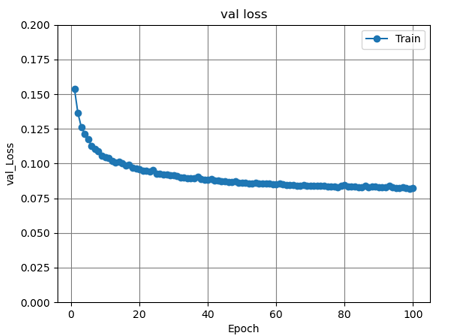
図21 畳み込みオートエンコーダ3層のval_lossグラフ
3.2.6の実験と同様で、畳み込み層とプーリング層を1層増やして実験を行う。つまり、図22に示した設定のニューラルネットワークに対して、mnistというデータを用いて、グラフを見て100エポックまで学習を行った。Mnistの数字につけた色も同様にして実験を行った。ノード数は畳み込み層28-14-7-4-4-7-14-28とし、エンコーダ部分とデコーダ部分をつなぐ全結合層のノード数は32である。
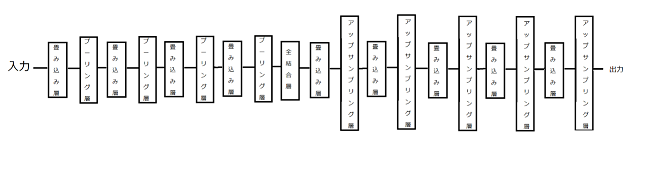
図22 畳み込みオートエンコーダ4層の構造
この学習済みのニューラルネットワークに対して、ランダムな10枚のmnistの白黒画像の検証用の入力を与え、出力を観測した。
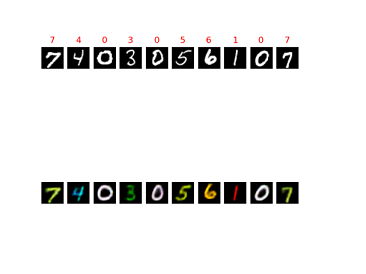
図23 畳み込みオートエンコーダ4層の出力
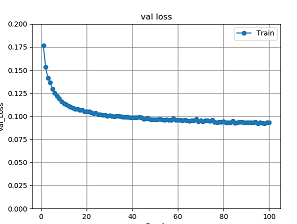
図24 畳み込みオートエンコーダ4層のval_lossグラフ
3.2.7の実験と同様で、畳み込み層とプーリング層を1層増やして実験を行う。つまり、図25に示した設定のニューラルネットワークに対して、mnistというデータを用いて、グラフを見て100エポックまで学習を行った。Mnistの数字につけた色も同様にして実験を行った。ノード数は畳み込み層28-14-7-4-2-2-4-7-14-28とし、エンコーダ部分とデコーダ部分をつなぐ全結合層のノード数は32である。
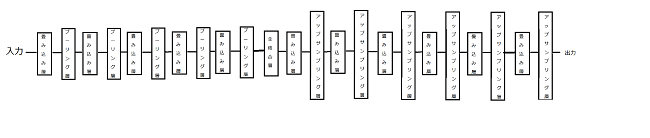
図25 畳み込みオートエンコーダ5層の構造
この学習済みのニューラルネットワークに対して、ランダムな10枚のmnistの白黒画像の検証用の入力を与え、出力を観測した。

図26 畳み込みオートエンコーダ5層の出力
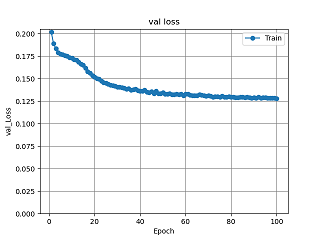
図27 畳み込みオートエンコーダ5層のval_lossグラフ
今回の実験では、畳み込みオートエンコーダを用いてCifar10の画像を学習し色付けを行っていく。実験5と同様のデータセット、エポック数で行った。構造は実験5の図16と同じ構造で、ノード数は畳み込み層64-128-128-64とし、エンコーダ部分とデコーダ部分をつなげる全結合層のノード数は512である。
この学習済みのニューラルネットワークに対して、鳥の白黒画像の検証用の入力を与え、出力とlossを観測した。

図28 畳み込みオートエンコーダ2層の出力
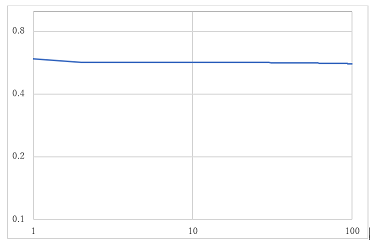
図29 畳み込みオートエンコーダ2層のloss
3.3.1の実験と同様のデータセット、エポック数で行った。構造は図19と同じ構造で、ノード数は畳み込み層64-128-256-256-128-64とし、エンコーダ部分とデコーダ部分をつなげる全結合層のノード数は512である。
この学習済みのニューラルネットワークに対して、鳥の白黒画像の検証用の入力を与え、出力とlossを観測した。

図30 畳み込みオートエンコーダ3層の出力
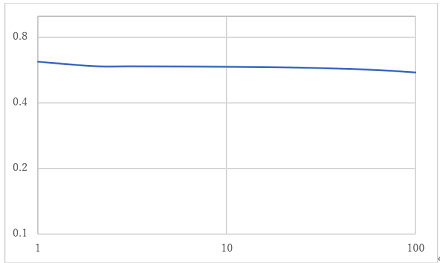
図31 畳み込みオートエンコーダ3層のloss
3.3.2の実験と同様のデータセット、エポック数で行った。構造は図22と同じ構造で、ノード数は畳み込み層64-128-256-512-512-256-128-64とし、エンコーダ部分とデコーダ部分をつなげる全結合層のノード数は512である。
この学習済みのニューラルネットワークに対して、鳥の白黒画像の検証用の入力を与え、出力とlossを観測した。

図32 畳み込みオートエンコーダ4層の出力
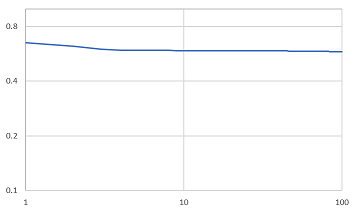
図33 畳み込みオートエンコーダ4層のloss
畳み込みオートエンコーダ3層のlossのグラフを見ると、まだlossが下がっていくと予測できるので、エポック数を増やしていき、出力の画像とlossのグラフで精度を確かめていく。3.3.2の実験と同様のデータセット、構造で行った。つまり、畳み込みオートエンコーダ3層で実験を行った。エポック数を1000として実験を行った。
この学習済みのニューラルネットワークに対して、鳥の白黒画像の検証用の入力を与え、出力とlossを観測した。
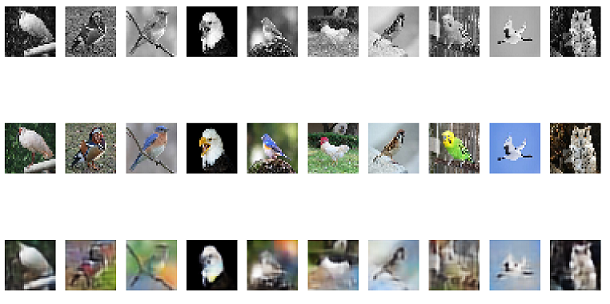
図34 畳み込みオートエンコーダ3層の1000エポックの出力
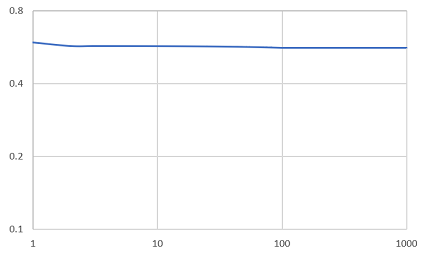
図35 畳み込みオートエンコーダ3層の1000エポックのloss
各実験を比較していくと、出力では畳み込みオートエンコーダ2層から4層までを比較すると、背景が薄い部分があるが数枚は色付けがされている画像があるが、インコのように白黒のまま出力されている画像があることが分かる。2層と3層を比べると2層より3層の方が、色が少し濃く色付けされているのが分かる。4層では一番右の背景の青色の画像が2層や3層では色付けがされていたのに白黒で出力されたことが分かる。また、2層3層と比較すると緑色が濃く色付けされていることが分かる。エポック数を増やした実験と3層の実験を比較すると、右から4番目の画像がより正確に色付けされていることが分かる。また、lossのグラフを比較していくと100エポック固定の実験では3層が、一番損失が少ないことが分かる。また、少しではあるが1000エポックの実験のlossのグラフでは100エポックから少し損失は減少しているので、損失の値を見ると3層の1000エポックの精度が一番良いと分かる。
今回の実験では全結合のみのニューラルネットワークと畳み込みオートエンコーダを使用して白黒画像のカラーを試した。Mnistの実験から、単色の色付けは手書きの数字の色付けにより、誤って色付けをしてしまう場合もあるが正確に色付けされることが分かる。このことから、単色の簡単な色付けはで来ることが分かる。Cifar-10の実験より、鳥の白や黒、茶色は色付けされているが、緑や青などの色はカラー化されていないことが分かる。このことから、畳み込みオートエンコーダでは、複雑な画像のカラー化は一定のカラー化はできるが十分なカラー化ができないことが分かる。発展として、既存ででているネットワーク(alexnet、resnet)などの複雑な構造のネットワークを使用しなければ満足のいくカラー化はできないと考えられる。