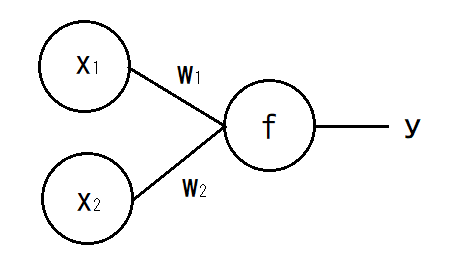
図1.2入力1出力のニューラルネットワークモデル例
近年のニューラルネットワークを使ったディープラーニングの技術の発展は、画像処理の分野でも応用されている。ディープラーニングを応用した技術は、画像処理の分野の一つである白黒画像を自動、もしくは半手動半自動でカラー画像へと変換する「カラリゼーション」の分野でも例外なく応用され、大きな進歩を見せているといってもいいだろう。一方、それらの技術は大変複雑な構造のニューラルネットワークを用いる手法や、人の手の介入による半自動のカラリゼーション手法が主である。そこで本研究では、オートエンコーダという深層ニューラルネットワーク構造を利用して単純なモデルを構築することで既存の手段より簡易なカラリゼーション手段を実現できないかを模索し、考察することとする。
最初にカラリゼーションの用語の説明と、その技術についての既存の研究について述べる。 カラリゼーションとは、与えられた白黒画像をカラー画像へと変換する技術を指す[1]。現在までに複数の手段が既に確立されており、2002年のWelshらの研究[2]や、2004年のLevinらの研究などによる手法[3]が存在するLevinの手法は人間が画像へ色差情報の一部を与え、それをもとにして白黒画像のカラー化を行う。Welshの手法は、参考画像の画素の輝度値とその統計量に注目して関係関数を作り、目的の白黒画像のカラー化を行うWelshの手法をもとにしてニューラルネットワークを適用した小林らの手法も開発されており[4]、ニューラルネットワークを用いるのがカラリゼーションにおける近年の主流となっている。ニューラルネットワークをカラリゼーションに適用した代表例としては、2016年の飯塚らの研究[5]があげられる。この研究では、入力画像の大特徴と局所特徴を考慮した畳み込みディープニューラルネットワークを利用した手法の開発が行われた。これにより、入力画像の全体の特徴と、局所的な部分の特徴の両方を学習することができる。また、入力画像の画素数が固定されず、どのような画素数の画像でもカラリゼーションが行われるのが特徴である。本研究でも近年の主流に従ってニューラルネットワークを用いた白黒画像のカラリゼーションの検討を行う。
ニューラルネットワークとはアルゴリズムの一種であり、人間の脳の神経構造を模した構成となっているのが特徴である。ニューラルネットワークはニューロン(神経細胞)を網目状に組み合わせてネットワークを構成しているためニューラルネットワークと呼称される。単純なニューラルネットワークの例を次に示す。
図1.2入力1出力のニューラルネットワークモデル例
図1.2入力1出力のニューラルネットワークモデル例 この時、x_1とx_2は入力、yが出力となる。w_1とw_2はネットワークの重みと呼ばれる値で、各ニューロンの結合の強さを表している。出力される値yは、バイアスθを加えて次のように表される。
fは活性化関数と呼ばれる非線形の関数である。本研究ではReLU関数とSigmoid関数を活性化関数として使用する。ReLU関数とSigmoid関数は以下のように表される。
図1は2入力の例であるが、これをn個の入力が存在すると仮定して式を一般化すると次のようになる。
図1で示したようなニューロンを多層に重ねることでニューラルネットワークは構成されている。その例を以下に示す。
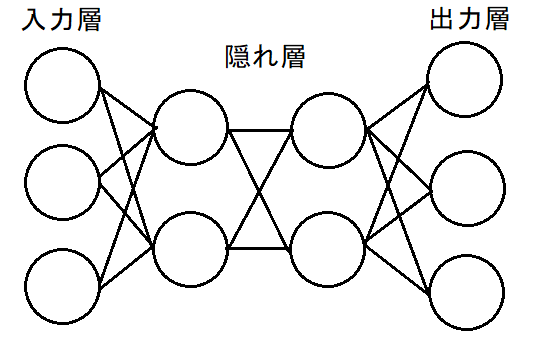
図2.隠れ層2層のニューラルネットワーク例
ニューラルネットワークは、「入力層」、「隠れ層」、「出力層」から構成されている。隠れ層の層が厚く作られているニューラルネットワークは特別に「深層(ディープ)ニューラルネットワーク」と呼ばれる。また、図2のように隣接する層のノードが全てつながっているようなニューラルネットワークは「全結合ニューラルネットワーク」と呼ばれる。ニューラルネットワークの学習は、ニューラルネットワークの出力と正解データとなる教師画像を比較し、その誤差をもとにしてニューラルネットワークの重み、バイアスの値を修正していくことで行われる。
畳み込みニューラルネットワーク(Convolutional Neural Network : CNN)は画像認識や音声認識の分野で用いられる特殊な形状のネットワーク構造である。CNNは「畳み込み層」、「プーリング層」などの特殊な層から構成されている。畳み込み層では、入力画像データに対して小さなサイズの「フィルタ」と重なり合う部分の積を算出し、画像全体に対して総和を求める。このフィルタは「カーネル」と呼ばれる。プーリング層では、プーリング処理が行われる。今回の実験ではマックスプーリング法を採用する。マックスプーリング層で行われる処理は、入力に対して、適用されたカーネル内の画素のうち最大値を取得する処理である。
オートエンコーダとは、深層ニューラルネットワーク構造の一種であり、入力データのノイズ除去やデータの可視化のための次元削減などで活躍しているものである。一般的な全結合ニューラルネットワークを利用したオートエンコーダの構造は次の図の様なものである
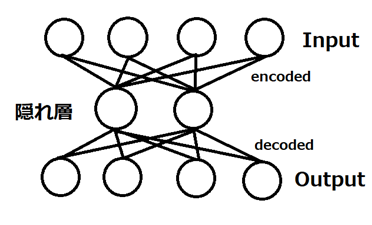
図3.オートエンコーダモデル例
図3のモデルは隠れ層が1層のモデルで、4つの入力を2つへ圧縮(エンコード)し、再び4つの出力へと展開(デコード)している。このようにオートエンコーダは次元を入力データの次元を削減してより小さなものとする「エンコーダ」、削減された次元をもとに戻す「デコーダ」の二つの部分から構成されている。実際のネットワークモデルでは隠れ層が3層以上のモデル等も用いられる。
畳み込みオートエンコーダは、畳み込みニューラルネットワークの構造をもとにオートエンコーダへ応用したものである。エンコーダ部分には通常の畳み込みニューラルネットワークと同じ畳み込み層、プーリング層を用いたが、デコーダ部分に新たにアップサンプリング層を使用する。 アップサンプリング層は、プーリング層で削減された次元を復元する働きを持つ。例えば4×4の画像を2×2のカーネルサイズでプーリング処理を行った場合、出力される画像のサイズは2×2となる。アップサンプリング層では各画素を同じ数値を持ったまま縦横2倍に引き伸ばすことで4×4の画像に復元する。このような働きを持つアップサンプリング層をデコーダ部分で用いることで、エンコーダ部分で圧縮された画像を復元することができる。
実験では、全結合オートエンコーダと畳み込みニューラルネットワークを用いたオートエンコーダを製作して、その出力を観測する。画像のサイズは32×32、128×128とする。
表1.実験環境
| OS | Windows10 Pro |
|---|---|
| CPU | Intel(R)Core i7-9700K 3.60GHz |
| メモリ | 32GB |
| GPGPU | NVIDIA GeForce RTX2060 |
表2.ライブラリ環境
| 言語 | Python3.7.3 |
|---|---|
| 機械学習 | Keras2.3.1(TensorFlow10.1) |
| 画像処理 | OpenCV4.1.1 |
| 行列計算 | NumkPy1.16.4 |
データセットは、CIFAR-100データセットと、Google画像検索により手動で収集された再使用可能な画像で構成したデータセットの2つを使用し、それぞれ実験を行う。
CIFAR-100は100種類のクラス分けされた500枚の画像と100枚のテスト画像の6万枚の32×32の画像から構成されたデータセットである。そのままの形状では画像の解像度が128×128の実験で利用することができないので、目標の画素数にリサイズすることで利用する。リサイズの為のプログラムの例は次の通りである。
def resize_img(image):
img = image.repeat(2,axis=0).repeat(2,axis=1)
return np.asarray(img)
図4.リサイズプログラム
この画像をリサイズするプログラムの例はimageで与えられた画像を縦横それぞれ2倍の大きさにリサイズし、NumPyの配列として返している。自作の画像集は航空機の写真を中心に手作業でGoogle画像検索より463枚の画像を収集し、それらを左右反転、ぼかし加工を加えることで1852枚に増やした画像によって構成されている。また、完成したニューラルネットワークの評価用に、自作のデータセットと同様Google画像検索より10枚の画像を収集した。画像を割り増しするために使用したプログラムは以下の通りである。
import glob
import os
import cv2
path_1 = './image/*.jpg'
i = 1
flist = glob.glob(path_1)
for x in flist:
img = cv2.imread(x)
flp = cv2.flip(img,1)
dst = cv2.GaussianBlur(img,(5,5),3)
fdt = cv2.GaussianBlur(flp,(5,5),3)
cv2.imwrite('./image2/'+str(i)+'.jpg',img)
i+=1
cv2.imwrite('./image2/'+str(i)+'.jpg',flp)
i+=1
cv2.imwrite('./image2/'+str(i)+'.jpg',dst)
i+=1
cv2.imwrite('./image2/'+str(i)+'.jpg',fdt)
i+=1
図5.割り増しプログラム
このプログラムはimageフォルダに保存されたJPEG画像を読み込み、左右反転、ぼかしを加えたうえでimage2フォルダへ保存している。ニューラルネットワークの入力画像として使用する白黒画像を作成するため、PythonやC言語で利用可能な画像処理ライブラリであるOpenCVを利用し、カラー画像をグレースケール化する手順を行う。 カラー画像をグレースケール化画像へ変換し、データセットとするプログラムは次の通りである。
def graycale(image):
img = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
return np.asarray(img)
図6.グレイスケール化プログラム
実験で使用するために作成したオートエンコーダは、全結合ニューラルネットワークを使用したものと、畳み込みニューラルネットワークを使用したものの二つである。 全結合型のオートエンコーダは隠れ層が3層で構成されている。ノード数は、900-400-900である。
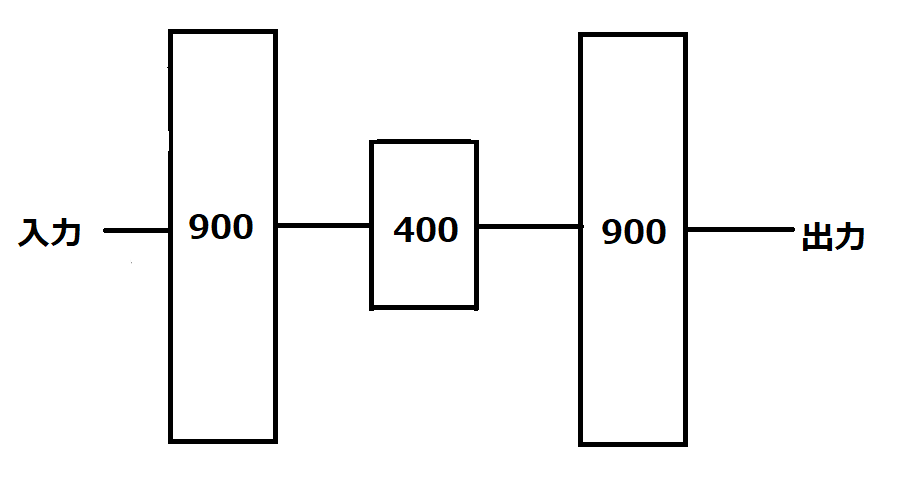
図7.全結合型オートエンコーダ構造図
畳み込みオートエンコーダは、エンコーダ部分が畳み込み層2層、プーリング層2層。デコーダ部分が畳み込み層2層、アップサンプリング層2層で構成されている。エンコーダとデコーダはノード数512の全結合層でつながれている。
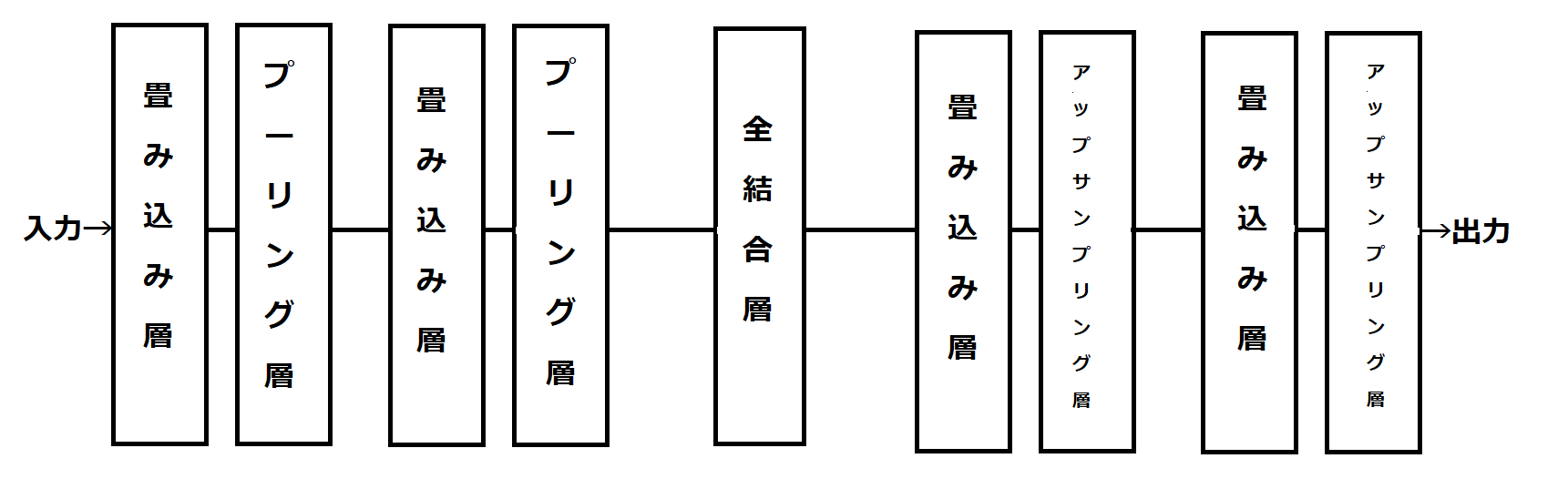
図8.畳み込みオートエンコーダ構造図
作成した2つのネットワークモデルに対して、CIFAR-100および自作のデータセットを学習させ、モデルの損失の推移を確認した。損失関数を用いることでモデルの精度、学習の進み具合が判断できる。
次に、検証用の10枚の画像を2つのネットワークそれぞれに入力し、その出力を確認し、それらの結果を基に評価・考察を行う。
画像の画素数は32×32、128×128とした。バッチサイズは両ネットワーク共に128、エポック数は全結合型オートエンコーダでは400、畳み込みオートエンコーダでは100に設定して実験を行っている。
学習過程
最初に、ネットワークを学習させたときの損失グラフを示す。以後のグラフは縦軸が損失、横軸がエポック数を表す。下のグラフは全結合型オートエンコーダを、CIFAR-100データセットを使って画素数32×32で学習させた場合である。
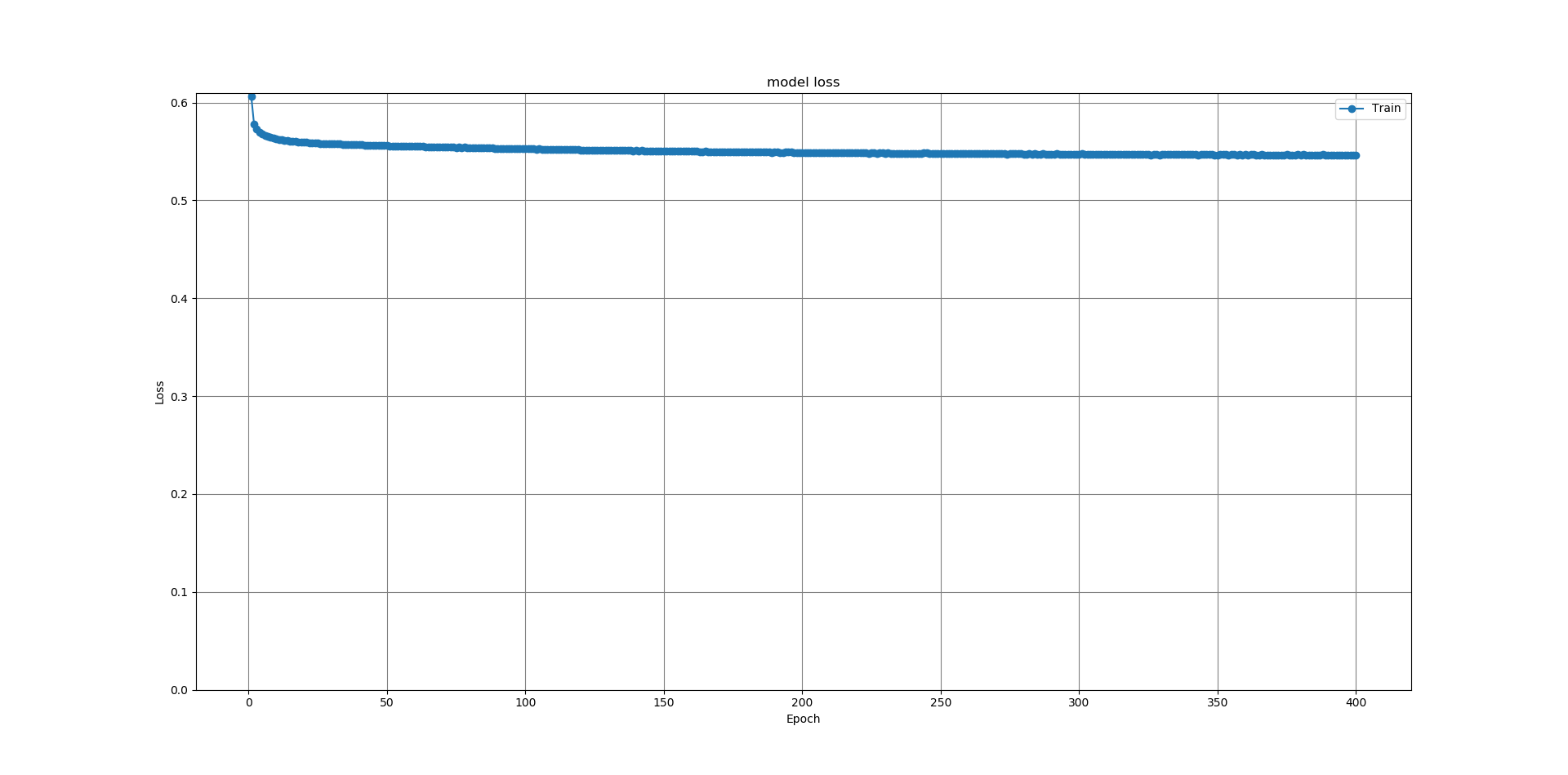
図9.32×32CIFAR-100全結合オートエンコーダ損失グラフ
続いて、畳み込みオートエンコーダを、CIFAR-100データセットを使って画素数32×32で学習させた場合である。
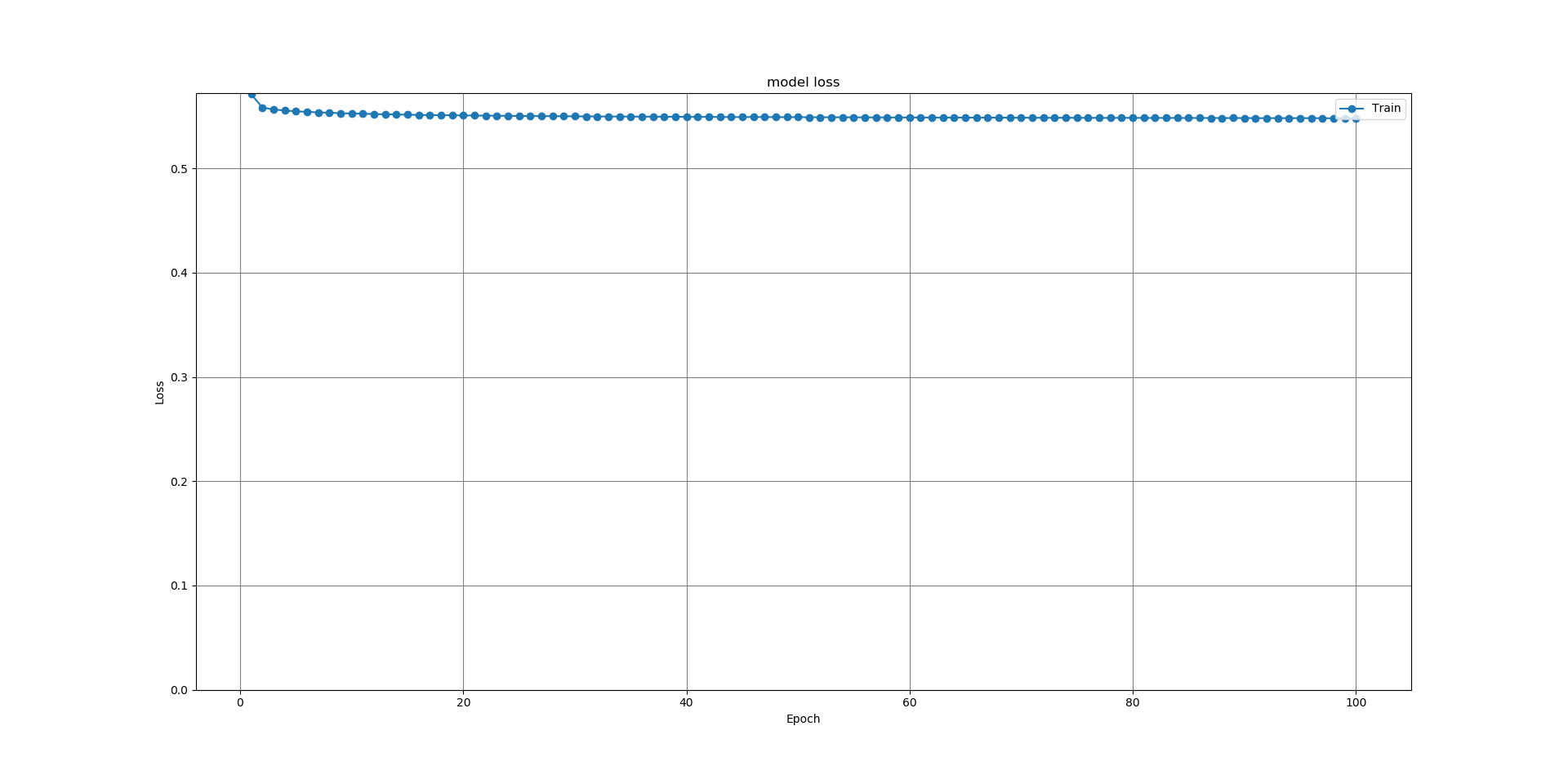
図10.32×32CIFAR-100畳み込みオートエンコーダ損失グラフ
続いて、全結合型オートエンコーダを、CIFAR-100データセットを使って画素数128×128で学習させた場合である。
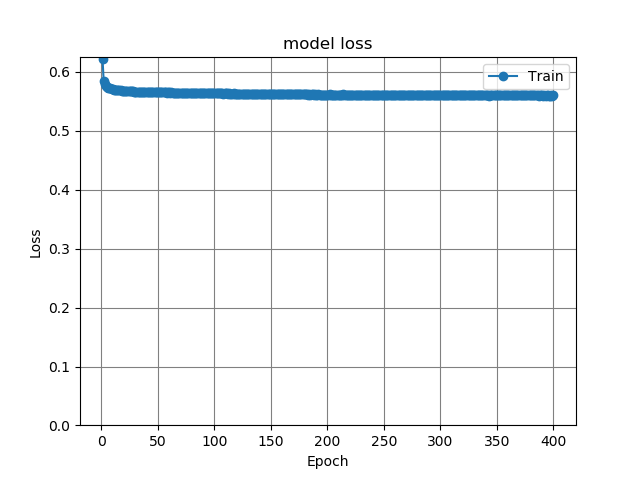
図11.128×128CIFAR-100全結合オートエンコーダ損失グラフ
続いて畳み込みオートエンコーダを、CIFAR-100データセットを使って画素数128×128で学習させた場合である。
図12.128×128CIFAR-100畳み込みオートエンコーダ損失グラフ
続いて全結合型オートエンコーダを、自作データセットを使って画素数32×32で学習させた場合である。
図13.32×32自作データセット全結合型オートエンコーダ損失グラフ
続いて畳み込みオートエンコーダを、自作データセットを使って画素数32×32で学習させた場合である
図14.32×32自作データセット畳み込みオートエンコーダ損失グラフ
続いて全結合型オートエンコーダを、自作データセットを使って画素数128×128で学習させた場合である。
図15.128×128自作データセット全結合型オートエンコーダ損失グラフ
続いて畳み込みオートエンコーダを、自作データセットを使って画素数128×128で学習させた場合である。
図16.128×128自作データセット畳み込みオートエンコーダ損失グラフ
出力
次に学習させたネットワークに評価用の画像を入力したときの出力を示す。上段が入力された白黒画像、中段が正解のカラー画像、下段がネットワークより出力されたカラー画像を示す。 はじめに、全結合型オートエンコーダにおいて、CIFAR-100を使って32×32の解像度で得た出力である。

図17.全結合型オートエンコーダの場合の出力
続いて、畳み込みオートエンコーダにおいて、CIFAR-100を使い、解像度32×32で得た結果である。

図18.畳み込みオートエンコーダの場合の出力
続いて、全結合型オートエンコーダにおいて、CIFAR-100を使い128×128の画素数で得た出力である。

図19.全結合型オートエンコーダの場合の出力
続いて、畳み込みオートエンコーダにおいて、CIFAR-100を使い128×128の画素数で得た出力である。

図20.畳み込みオートエンコーダの場合の出力
続いて全結合型オートエンコーダにおいて、自作データセットを使い画像解像度32×32の場合で得た出力である。

図21.全結合型オートエンコーダの場合の出力
続いて畳み込みオートエンコーダにおいて、自作データセットを使い画像解像度32×32の場合で得た出力である。

図22.畳み込みオートエンコーダの場合の出力
続いて全結合型オートエンコーダにおいて、自作データセットを使い画像解像度128×128の場合で得た出力である。

図23.全結合オートエンコーダの場合の出力
続いて畳み込みオートエンコーダにおいて、自作データセットを使い画像解像度128×128の場合で得た出力である。

図24.畳み込みオートエンコーダの場合の出力
図15~23が示すように、単純なオートエンコーダを使ったシステムでも、空や地面部分を認識した色付けが行われた。しかし、一番左の列の画像の例のように固有の色が画像にあった場合(この場合黄色である)は色付けが行われていない。データセットで与えられなかったような例、もしくはデータが少なかったデータがニューラルネットワークの入力として与えられた場合は色付けが行われないと思われる。
図16、18、20、21が示す結果から、全結合型のオートエンコーダでは出力画像にノイズが発生しているのに対して、畳み込みオートエンコーダの出力では目立ったノイズは見受けられない。入力画像に対して、色付けを行ったうえでより鮮明な画像を提供する能力は畳み込みオートエンコーダの方が優れていることが確認できる。下図は、128×128の解像度で自作のデータセットを用いて得られた結果の比較を例として示したものである。上段が全結合のオートエンコーダ、下段が畳み込みオートエンコーダの出力である

図25.出力の比較
結果がより良かった畳み込みオートエンコーダを使った場合の出力と、飯塚らの手法[5]を使った場合の結果とを比較した図を以下の示す。解像度は128×128である。

図26.飯塚らの手法との比較
単純なオートエンコーダを使用した手法でも一定の色付けが行われるが、より鮮明で正確な色付けを行うためには飯塚らの手法のように複雑なディープニューラルネットワーク構造を持つ必要があることがうかがえる。
今回の実験では、2種類の全結合型オートエンコーダ、畳み込みオートエンコーダを使用して白黒画像をカラー化する実験を行った。実験結果より、単純な構造をもつニューラルネットワークを使用したオートエンコーダでも一定のカラリゼーション能力があることがわかったが、その能力には限界があったため、使い道が制限されるだろう。今後の発展として、さらに多くの画像を使用したデータセットを作成して実験を行う事、データセットとして使う画像を制限して特化させた実験を行うこと、などがあげられるだろう。