-
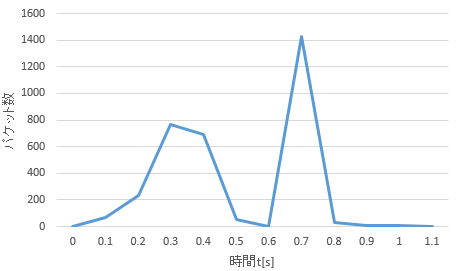
- 図2.1 東京電機大学のホームページのパケット数のトラフィック
Webサイトに接続すると、データはパケットに分割され送受信される。このパケットが一定時間に流れる数は各Webページやサイトによって異なる。又、さらに、Webページは一般に複数のファイルによって構成され、それぞれの容量や数はページによって固有のものであるため、Webページを開く際のパケットの流れにはそれぞれ特徴が出る。この流れの違いに注目すると、閲覧者が接続するあるWebページのトラフィックの流れを観測し、予め用意した様々なWebページのトラフィックの流れと比較することで、用意したうちのどのWebページに接続したのかを特定することができると予想される。
本研究は、通信トラフィックの特徴からWebページの特定について研究を行い、どれほどのWebページの特定を行うことができるのかを求める。本論文の構成は次のようになっている。第2章では本論文で使用する諸概念について述べる。
トラフィックとはネットワーク上で通信する際に送受信されるデータの流れである。Webでは、ブラウザがURLを受け取ると、Webサイトを調べアクセスし、Webページを構成する必要なファイルを次々にダウンロードする。HTTP/1.0ではファイルを1つずつTCPの1コネクションが必要だったが、HTTP/1.1では基本的に1つのTCPコネクションで複数のファイルのやりとりが可能になった。2015年に制定されたHTTP/2では、1つのページを開くのに1つのサイトにも複数のファイルに優先順位をつけてダウンロードできるようになった。
本実験ではWebサイトのTCP上のHTTPというプロトコルで構成されているパケットおよびデータ量をトラフィックとして観測する。
本実験であらかじめWebサイトのトラフィックの流れとして、全て実在する国公立大学および私立大学の30のホームページのトラフィックとする。使用するブラウザはGoogle Chromeとして、キャッシュは全て無効にして通信を行う。なお、特定元(以下A)は各大学1回(合計30回)、特定先(以下B)は各大学10回(合計300回)観測する。使用する大学名およびホームページのWebアドレスは以下の表2.1に記載する。
| 使用する大学名 | Webアドレス |
|---|---|
| 東京電機大学 | https://www.dendai.ac.jp/ |
| 慶応義塾大学 | https://www.keio.ac.jp/ja/ |
| 早稲田大学 | https://www.waseda.jp/ |
| 上智大学 | https://www.sophia.ac.jp/ |
| 国際基督大学 | https://www.icu.ac.jp/ |
| 法政大学 | http://www.hosei.ac.jp/ |
| 立教大学 | https://www.rikkyo.ac.jp/ |
| 青山学院大学 | http://www.aoyama.ac.jp/ |
| 東京理科大学 | http://www.tus.ac.jp/ |
| 同志社大学 | https://www.doshisha.ac.jp/ |
| 日本女子大学 | http://www.jwu.ac.jp/sp/ |
| 麻布大学 | https://www.azabu-u.ac.jp/ |
| 北里大学 | https://www.kitasato-u.ac.jp/ |
| 國學院大學 | https://www.kokugakuin.ac.jp/ |
| 京都大学 | http://www.kyoto-u.ac.jp/ja |
| 東京大学 | http://www.u-tokyo.ac.jp/index_j.html |
| 神戸大学 | http://www.kobe-u.ac.jp/ |
| 東京外国語大学 | http://www.tufs.ac.jp/ |
| 一橋大学 | http://www.hit-u.ac.jp/index.html |
| 大阪大学 | http://www.osaka-u.ac.jp/ja |
| お茶の水女子大学 | http://www.ocha.ac.jp/ |
| 筑波大学 | http://www.tsukuba.ac.jp/ |
| 徳島大学 | http://www.tokushima-u.ac.jp/ |
| 京都府立大学 | https://www.kpu.ac.jp/ |
| 鳥取大学 | https://www.tottori-u.ac.jp/ |
| 帯広畜産大学 | http://www.obihiro.ac.jp/ |
| 岩手大学 | http://www.iwate-u.ac.jp/ |
| 大阪府立大学 | http://www.osakafu-u.ac.jp/ |
| 東京医科歯科大学 | http://www.tmd.ac.jp/ |
| 順天堂大学 | http://www.juntendo.ac.jp/ |
本実験では「Wireshark」というネットワーク・アナライザ・ソフトウェアを使用する。このソフトウェアは800以上のプロトコルの解析ができ、パケットキャプチャを行うことができる。またキャプチャ結果を表示する際、特定のパケットのみに絞ることができるフィルタ機能がある。他にパケットのやり取りをグラフ化する入出力グラフという機能もあり、グラフ化したデータをCSVファイルとして出力することができる。
本研究では、Webサイトのトラフィックを観測するためにWiresharkのフィルタ機能を用いて、TCP上のHTTPのプロトコルで構成されているパケットおよびデータ量のみトラフィックとして100ms毎に観測を行う。その際、フィルタは「TCP || HTTP」と入力する。なお、400ms以上の通信が行われている場合、かつ400ms以上通信が行われなくなるまでをWebページのトラフィックとする。図2.1はWiresharkを用いて観測した東京電機大学のホームページのパケット数のトラフィックである。
Kolmogorov-Smirnov検定とは、統計学における1つの仮設検定である。2つの有限個の標本から累積確率分布を求め、その差の絶対値の最大値(以下KS値)を求めることで、2つの分布の相違を計るために使われる。
本実験ではWiresharkを用いて収集したAおよびB全ての累積確率分布を求め、AとBのKS値を求める。このKS値が0に近いほど、AとBは素管関係の強いトラフィックとなり、最もKS値が小さい組み合わせからBはAの大学のトラフィックであると特定できる。図2.2は東京電機大学の特定元と特定先を標本化し、KS値を求めた図である。
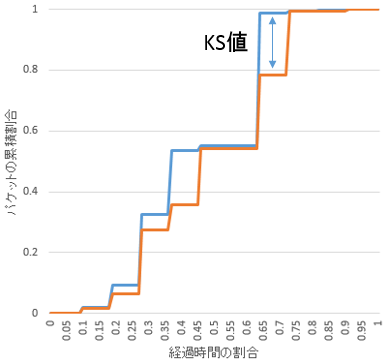
図2.3はAとBのKS値を求める例である。この図だとKS値が最も小さい組み合わせはA2とB1であるため、B1はA2の大学であると特定する。
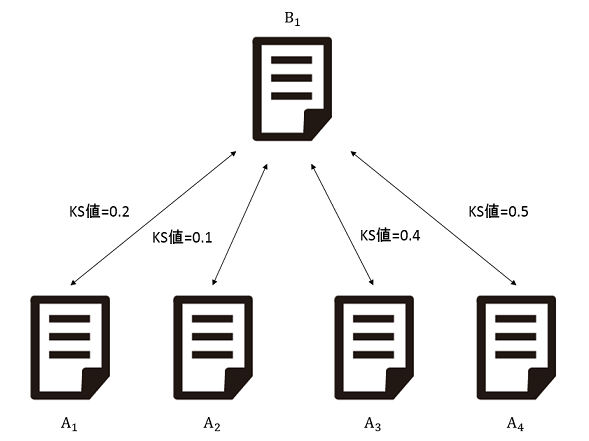
このようにKS値を求めていき、最小のKS値からBのWebサイトを特定する。
KS値を用いてWebページを特定する方法とは別に、観測したトラフィックのデータ量の総量の差からWebページを特定する手法も用いることにした。
本実験で求めた全てのトラフィックに対して、観測したデータ量の総量を求める。その後、1つのBの総データ量の差と全てのAの総データ量の差を求める。この差が0に近いほど、AとBは似たトラフィックとなり、最も差の小さい組み合わせからBはAの大学のトラフィックであると特定できる。
ここでは前章の2.4で述べたようにAとBのKS値を求め、KS値の大きさから実際に大学のホームページの特定を行う。まず1つのAおよび1つのBそれぞれのパケットおよびデータ量を標本化してKolmogorov-Smirnov検定を行い、それぞれのKS値を求め、2つのKS値の和Sを求める。
FX(t)をt時間内の総バイト数、TXをWebページの全ダウンロード時間、FX(TX)を総バイト数とすると、Xの累積確率分布は式(3.1)のようになる。(0≤s≤1)
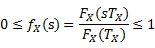 (3.1)
(3.1)
式(3.1)を用いてKS検定によるXとYのKS値を求める式は式(3.2)のようになる。
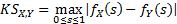 (3.2)
(3.2)
これを全てのAを用いて、30個のSを求める。このSのうち、最も値の小さい和であるAのホームページが、Bのホームページであると特定する。これを全てのBに対して行い、Bがどの大学のホームページにトラフィックであるかの特定を行う。合計300あるBのうちどれほどのBが正しい大学のWebページだと特定できたのかを評価指数を用いて求める。
実験1を行った結果、図3.1のような評価指数となった。横軸は正解率(特定率)であり、どれほどのBを正しく特定できたかの割合である。縦軸は特異率であり、B以外のものを正しくB以外と判別できたかという割合である。また四角形は平均値であり、正解率(特定率)は22.33%で特異率は97.31%であった。また大学毎の特定率は表3.1のようになった。
| 大学名 | 特定率 |
|---|---|
| 東京電機大学 | 0 |
| 慶応義塾大学 | 0 |
| 早稲田大学 | 0 |
| 上智大学 | 0 |
| 国際基督大学 | 0 |
| 法政大学 | 0.5 |
| 立教大学 | 0.1 |
| 青山学院大学 | 0.4 |
| 東京理科大学 | 0.1 |
| 同志社大学 | 0.3 |
| 日本女子大学 | 0.8 |
| 麻布大学 | 0.1 |
| 北里大学 | 0.1 |
| 國學院大學 | 0.5 |
| 京都大学 | 0.9 |
| 東京大学 | 0.7 |
| 神戸大学 | 0 |
| 東京外国語大学 | 0 |
| 一橋大学 | 0 |
| 大阪大学 | 0.5 |
| お茶の水女子大学 | 0 |
| 筑波大学 | 0.1 |
| 徳島大学 | 0 |
| 京都府立大学 | 0 |
| 鳥取大学 | 0 |
| 帯広畜産大学 | 0 |
| 岩手大学 | 0.1 |
| 大阪府立大学 | 0.5 |
| 東京医科歯科大学 | 0.3 |
| 順天堂大学 | 0.7 |
実験2では前章の2.5を用いて、AとBとのトラフィックの総データ量の差を求め、差の大きさから実際に大学のホームページの特定を行う。まず1つのAおよび1つのBそれぞれのトラフィックからデータの総量を求め、差Dを求める。これを全てのAに対して行い、30個のDを求める。このDのうち、最も値の小さい値であるAのホームページが、Bのホームページであると特定する。これを全てのBに対して行い、Bがどの大学のホームページにトラフィックであるかの特定を行う。合計300あるBのうちどれほどのBが正しい大学のWebページだと特定できたのかを評価指数を用いて求める。
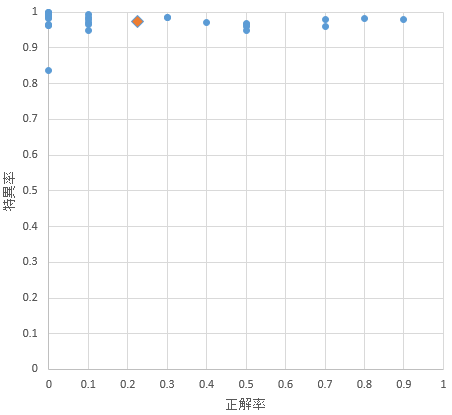
実験2を行った結果、図3.2のような評価指数となった。四角形が平均値であり、正解率(特定率)は78%で特異率は99.13%であった。また大学毎の特定率は表3.2のようになった。
| 大学名 | 特定率 |
|---|---|
| 東京電機大学 | 0 |
| 慶応義塾大学 | 0.8 |
| 早稲田大学 | 0.8 |
| 上智大学 | 0 |
| 国際基督大学 | 1 |
| 法政大学 | 0.1 |
| 立教大学 | 1 |
| 青山学院大学 | 1 |
| 東京理科大学 | 1 |
| 同志社大学 | 0.3 |
| 日本女子大学 | 0.8 |
| 麻布大学 | 0.5 |
| 北里大学 | 1 |
| 國學院大學 | 1 |
| 京都大学 | 1 |
| 東京大学 | 1 |
| 神戸大学 | 1 |
| 東京外国語大学 | 0.1 |
| 一橋大学 | 0.6 |
| 大阪大学 | 0.8 |
| お茶の水女子大学 | 1 |
| 筑波大学 | 1 |
| 徳島大学 | 1 |
| 京都府立大学 | 1 |
| 鳥取大学 | 1 |
| 帯広畜産大学 | 0.9 |
| 岩手大学 | 1 |
| 大阪府立大学 | 0.8 |
| 東京医科歯科大学 | 0.9 |
| 順天堂大学 | 1 |
前章の実験結果では、Kolmogorov-Smirnov検定を用いた結果と、データ量の差から求めた結果では大きな差が出ていた。そもそもなぜKolmogorov-Smirnov検定を用いた実験1の特定率が22.33%であったのかを考えた結果、送受信する際に発生する遅延によって累積分布関数が特定元および特定先と大きく異なり、結果的にKS値に大きな差ができて特定がうまくできなくなってしまった。しかしこの実験方法は実験2とは違い、累積分布確率を用いて特定する手法なので、総データ量が変化する暗号化や、Webページの更新には強いというメリットが存在する。
そして実験2の総データ量の差で特定しようとした結果、特定率は78%となり、かなり高い確率で特定に成功している。しかしこの実験方法にはデメリットがあり、Tor等の匿名化通信を用いた送受信からの特定はデータ量に変動があり難しく、暗号化に弱い。
このように2つの実験にはそれぞれ長所短所があることがわかった。この違いを用いることで相手の利用している通信環境に合わせて、より高い特定率を求めることが可能になると思われる。そしてこの実験は特定するための初歩的な段階である。実験1で発生した遅延の改善することで特定率をあげることができるかもしれない。また他の手法を用いることでより特定率をあげることができる可能性がある。
実験結果から、パケットの構成を見ずにWebページを特定することは可能であるが、本実験では30種類のWebページを特定元としたが、30種類では少なすぎるため、次は100以上のWebページを特定元としてどれほどの特定ができるか、また新しい手法を見つけどれほどの特定率が得られるかを研究したい