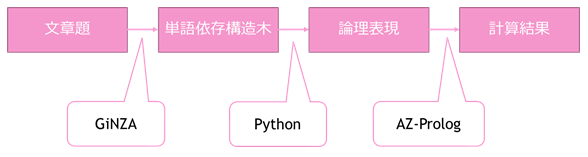
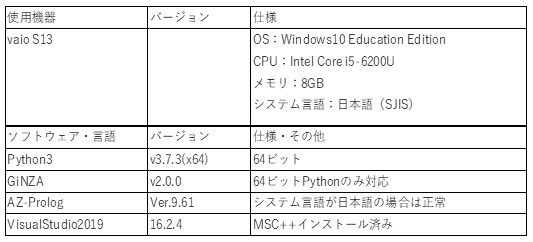
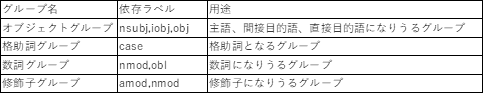
3-2.GiNZA
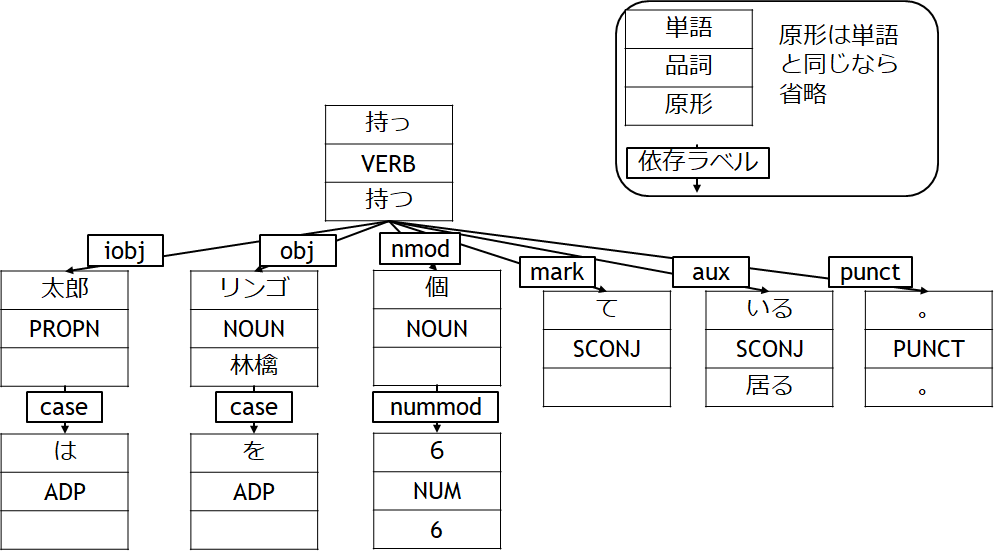
図 2.GiNZAの入出力例
GiNZAはリクルートのAI開発機関が国立国語研究所との共同研究成果の学習モデルを用いたPython向け日本語自然言語処理オープンソースライブラリである [6]。2019年4月2日に一般公開され、7月8日に2.0.0バージョンが公開されている(本研究ではこのバージョンを利用する)。同じくオープンソースの自然言語処理ライブラリ「SpaCy」と形態素解析器「SudachiPy」を利用し、高精度なトークン化処理と依存構造が実現している。
図 2は入力の例とその出力した解析木を示す。出力情報には区切られた単語、その単語の原形、構文の注釈のフレームワークである「Universal Dependencies」に基づいた品詞と依存ラベルがある。ここで、単語の原型は活用形であれば活用の原形(例:「持っ」の原形が「持つ」)を表示するがそれ以外にも次のような特徴がある。
- 「いる」、「りんご」といった平文が平仮名であっても適切な漢字である「居る」、「林檎」が原形になる。
- 「在る」と「有る」の原形は「有る」になるように、同じ意味の動詞で存在すれば単語の形が変化するものもある。
- 全半角数字(例:「6」、「6」)、漢数字(例:「六」)、ローマ数字(例:「Ⅵ」)の原形は半角数字(例:「6」)になる。
これらの性質を利用することで、平文中の様々な形をした単語を同一の意味の単語として認識できたり、少ない情報量で処理ができるメリットがある。次に、依存ラベルは主述や目的語、接頭辞など、単語間の関係性を表している。これを利用すれば、対象物の動作を読み取ることができる。
但し、依存ラベルが間違えるケース(矢印方向はあっているがラベルの種類が違うケース)は多々ある。実際、図2の結果も厳密には間違っており、「持っ」と「太郎」は主述の関係「nsubj」が正しく、述語と間接目的語の関係「iobj」ではない。このようなケースを対処するために、接頭辞(「case」ラベルなど)や品詞といった情報も解析木から論理表現への変換の処理に利用する。
3-3.Prolog
Prolog言語とは述語論理形態に基づいたプログラミング言語である。この言語ではまずいくつかの定義をし、その定義に基づいて質問に答えるプロセスを行う。以下では、Prologをシステムに採用する利点をリスト 5~リスト 7の動作例と共に説明する。
リスト 5.定義の例

まず、定義についてリスト 5を例に説明する。今回の定義の記述方法は「ある(A,B).」の書き方は「AにBがある。」を意味し、「含む(A,B)」は「AはBを含む。」を意味する。よって、1~4行目の意味は上から「袖ヶ浦市にドイツ村がある。」、「浦安市にディズニーランドがある。」、「千葉県は袖ヶ浦市を含む。」、「千葉県は袖ヶ浦市を含む。」である。また、「A:-B,C.」の書き方は一階述語論理の「B∧C→A」(BかつCであればA)を意味する。よって、5行目の意味は「『XはZを含む。』かつ『ZにYがある。』なら『XにYがある。』」(それぞれの「X」,「Y」,「Z」は同一のものを指す)である。具体的には「含む(X,Z).」と「ある(Z,Y).」が定義されていれば「ある(X,Y).」も定義されることになる。
リスト 6.質疑応答の例 1
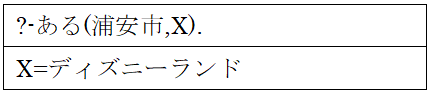
次に、質問の1つ目についてリスト 6を例に説明する。この質問文の意味は「浦安市に何があるか。」であり、「浦安市にディズニーランドがある。」ため回答は「ディズニーランド」と返す。具体的には、「ある(A,B).」の「A」を「浦安市」、「B」をワイルドカード(変数)の「X」にすることで、プログラムは定義されているものの中で「ある(浦安市,X).」に当てはまるものを検索し、当てはまるものがあればその「X」に当たる部分をすべて列挙するといった処理を行う。この質問に対しての結果は定義の2文目が当てはまるため、「X=ディズニーランド」といった出力をする。
リスト 7.質疑応答の例 2

次に質問の2つ目についてリスト7を例に説明する。この質問文の意味は「千葉県」に何があるかを意味する。今回の質問は直接的な「ある(千葉県,X).」の定義は存在しないが、定義の5文目によってこの質問に回答が存在する。まず、定義の1文目に「ある(袖ヶ浦市,ドイツ村).」、3文目に「含む(千葉県,袖ヶ浦市).」があるから、5文目によって「ある(千葉県,ドイツ村).」が定義されているから、これが質問に当てはまる定義となる。2文目と4文目の定義からも同様に「ある(千葉県,ディズニーランド).」の質問に当てはまる定義になる。よって、回答は「X=ドイツ村」と「X=ディズニーランド」となる。
このように今回の定義文では「含む(千葉県,袖ヶ浦市).」のような書き方で、簡単に千葉県の市を定義して活用できる。これによって、システムの辞書の作成、検索の実装も簡単にできる。
AZ-Prolog [8]はこのPrologの言語処理系の一つである。また、C言語のインターフェースがサポートされているため、今回ベースとなるPythonプログラムに簡単に組み込むことができる。