-
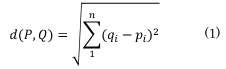
- ユークリッド距離dを求める式
ネットワークシステム研究室
11EC060 田中 雄太
指導教員 坂本 直志
レコメンドとは顧客の求めているであろう商品を勧めることである。近年インターネットショッピングサイトなどで商品の購入履歴や閲覧履歴を基にレコメンドをするレコメンデーションシステムが開発されてきた。しかし、商品のロングテール化により商品点数の莫大な増加により、レコメンドされる商品を更新するのに時間がかかるようになってきた。
さて、近年マルチコアプロセッサの発達により並列処理が高速化している。特にGPGPUはスーパーコンピューターにも用いられている。
一方、パソコン向けにコア数が2000個を超えるGPUも存在している。これは並列計算に強く、データ量が莫大になるレコメンデーションシステムにおいて効果的なのではないかと考えられる。
そこでGPUを用いてレコメンデーションシステムを開発することでよりリアルタイムなデータを用いてレコメンド出来ることが期待される。
本研究ではユークリッド距離を用いたレコメンデーションアルゴリズムをGPGPUで計算するプログラムを開発し、その性能を評価した。
本章ではレコメンデーションシステムについて、本研究で類似度を計測するために用いたユークリッド距離について説明していく。
レコメンデーションシステムとは特定ユーザが興味を持つと思われる情報を提示するシステムである。従来は店員が記憶力や洞察力を使い、顧客の過去の購買履歴や、現在の表情・会話から勧める商品を考えていた。ところがウォルマートが行ったデータマイニングの手法により売上が向上したのを受け、顧客の販売履歴の分析とそれを利用した広告が行われるようになってきた。特に顧客の販売履歴から顧客ごとの広告をすることをレコメンデーションと呼び、その計算する仕組みをレコメンデーションシステムという。特にインターネットでは顧客の表情などの情報を得ることが出来ないが、アクセスデータを記録することが出来る。そこで、顧客の購入履歴や、商品へのアクセスデータを用いてフィルタリングをかけることで顧客の求めているであろう商品を勧めるためにレコメンデーションシステムが用いられている。
レコメンデーションの基本的な考え方は顧客のモデル化である。つまり、似ている顧客は同じ購買行動をすると仮定する。そして似ている顧客AとBにおいてAが購入していてBが購入していない商品があったとき、その商品をBに勧める。
そしてこの似ているかどうかの判定に類似度を用いる。類似度を実数値で表すとする。類似度は「近い」、「遠い」などと表すように直観的に距離と同じ性質を持つと考えやすい。そのため、次のように
Cを顧客集合、d:C×C→Rを類似度とし、以下の距離空間の公理を満たすとする。
本研究では類似度を計算するためにユークリッド距離を用いる。n個の商品に対して、n次元ベクトルを考える。そして顧客Pが商品iを購入していたら、pi=1、していないならpi=0というベクトルPを顧客ベクトルとする。そして顧客の類似度をその点の間のユークリッド距離d(P,Q)と考える(式(1))。この値自体は大きいほど距離がより離れている。つまりより似ていないユーザであると考えられる。但し、商品の種類がベクトルの次元になるため、0〜∞次元の距離となってしまい扱いづらい。そこで2.2節に関わらず本研究ではユークリッド距離dに対して、次元に依存しない1/(1+d^2 )という形で正規化を行う。これにより次元nに関わらず値が1に近い程似ているユーザであり、0に近い程似ていないユーザだと考えられるようになる。
本章ではCUDAについて、スレッド管理の方法やメモリ構造について説明していく。
CUDAはCompute Unified Device Architectureの略である。これはNVIDIA社のGPUをGPGPUとして扱い、並列計算を行うための統合開発環境である。これはGPUを動作させるためのプログラミングモデル及びプログラミング言語、そのコンパイラとライブラリやサンプル・ソースコード、実行環境で構成される。プログラミング言語としてはC言語を用いる。
GPUには多数のコアがある。そのためGPUの性能を充分に引き出すには、これらのコアを同時にフル稼働させる必要がある。そうすることによりGPUではCPUと比べ数千スレッド、あるいは数万スレッドといったコア数よりも圧倒的に多い数のスレッドで計算することによって、GPUの高い性能が引き出すことが出来る。
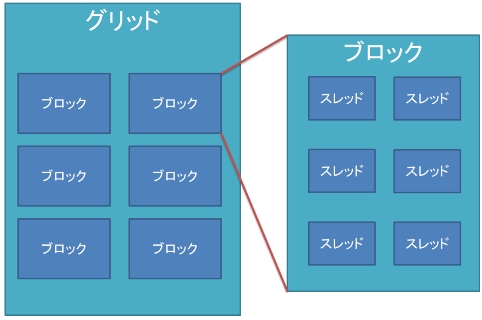
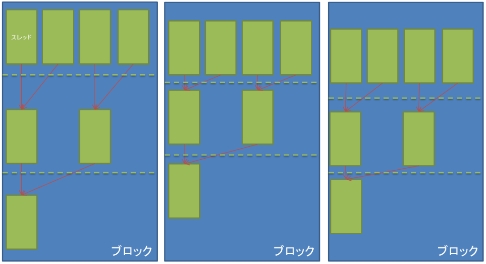
CUDAの仕様ではGPUのコアに対して65535×65535×512個のスレッドの実行を命令することが出来る。CUDAではこの多数のスレッドを管理するためにグリッドとブロックという概念を導入し、その中で階層的にスレッドを管理することで、容易に管理することを実現している。全てのスレッドは同じコードを実行する。
CUDAではスレッド管理の最上位にグリッドという階層を設けている。図1にスレッド管理の概念図を示す。グリッドの中にはブロックという階層で構成されている。グリッドの中のブロックはx方向、y方向、z方向の三次元的に配置されて管理されている。グリッド内のブロック数のx方向とy方向の最大値は65535個である。これを超えた配置すると実行時エラーになる。
さらに、同じようにブロック内にはスレッドが配置されている。またブロック内のスレッドのx方向とy方向の最大値は1024である。x方向とy方向を合わせたブロック内のスレッド数の最大値は1024個となっている。これを超えて配置すると、同じように実行時エラーになる。
CUDAでは32個のスレッドがウォープという単位で管理される。スレッド中のプログラムにおいてif文などの制御構文で異なる方向に分岐する可能性があるとき、ウォープ内で は全ての分岐を実行する。ウォープ内のスレッドが多くの分岐命令含むと、GPUは多くの ルートを実行することになってしまい、GPUの性能低下を招いてしまう。これをウォープ ダイバージェントと呼ぶ。
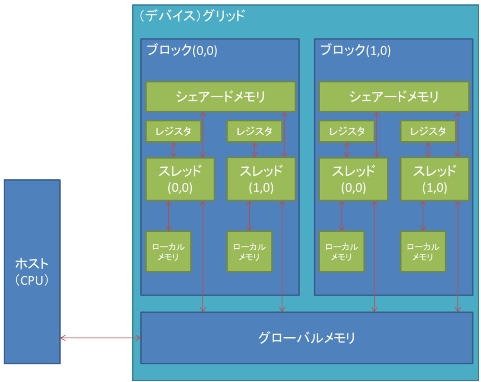
CUDAには複数のメモリが存在している。ここではメモリの種類について説明をしてい く。図2にCUDAのメモリモデル[5]を示す。これらのメモリをどのように使うかによって 実際の性能は大きく異なる。GPGPUの演算装置はSM/SMX(Streaming Multiprocessor) であり、これは8又は32個の演算器Cudacoreのクラスタになっている。
レジスタはGPUのチップ上に実装されているメモリである。高速に読み書きができる ためカーネル関数のプログラム中で使われる変数の値が保持される。
ローカルメモリはSM内のCudacoreで共有される。レジスタ数が不足している時にレジスタデータの退避場所として使われる。レジスタに比べ100倍以上アクセスが低速にな るため出来るだけ使わないほうがいい。
グローバルメモリはGPUのチップ外に置かれ、レジスタに比べ100倍以上アクセスが 低速なメモリである。グローバルメモリはハード上ではビデオメモリ上に置かれるためグ ローバルメモリとして使える量はビデオメモリの量となり、レジスタ等に比べて容量が大 きくすることが可能である。
シェアードメモリはSMX内に存在するメモリであり、レジスタと同等の速度でアクセ スが可能である。ブロック内の全てのスレッドで共有することが出来る。また、別のブロ ックのシェアードメモリへのアクセスをすることは不可能である。またシェアードメモリ は16個のバンクによって構成されている。各バンクは一度に一箇所へのアクセスにしか対 応していない。同じバンクに属している複数の箇所にアクセスが起こる場合、順番に処理 が行われるため、より長い時間がかかってしまう。これをバンクコンフリクトと呼び、回避する必要がある。
本研究ではレコメンデーションシステムにユークリッド距離を用いて類似度を計算している。そこで本章ではCUDAでユークリッド距離の計算の実装、使用したサンプルデータについて説明していく。
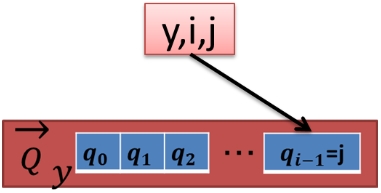
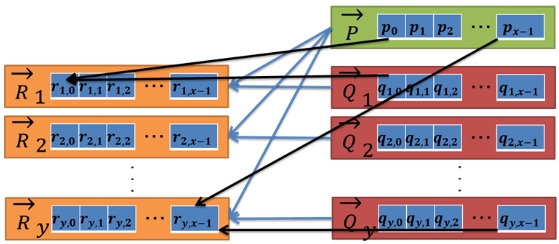
本研究ではCollaborative filtering dataset - dating agency [3]内のrating.datをサンプルデータとして用いる。このデータはチェコスロバキアの出会い系サイトの評価データを匿名化したものである。ファイルにはユーザID、プロフィールID、評価をカンマで区切ったデータが17,358,346件格納されている。図3にデータの例を示す。ユーザIDは135359件、プロフィールIDは220970件である。プロフィールIDはユーザが他のユーザに対しての評価を表す。
これを前処理として各ユーザIDごとに集計する。y,i,jというデータがあればQyのi番目のデータはjとなり、無ければ0とする。そしてユーザIDyがベクトルQyとなる。図4にユーザIDごとの集計のイメージを示す。
さて、本研究ではあるユーザPを考える。ベクトルPとQyで類似度を計算し、Pに一番似ているユーザを見つける。

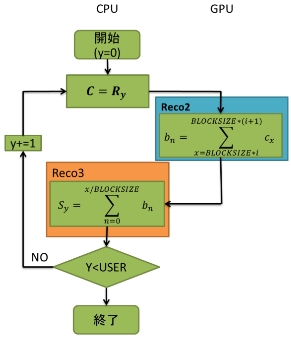
本研究で用いたユークリッド距離を求めるアルゴリズムをフローチャートで図5に示す。
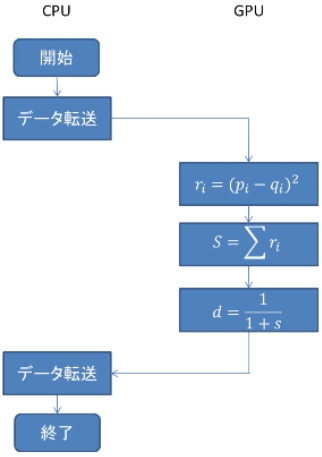
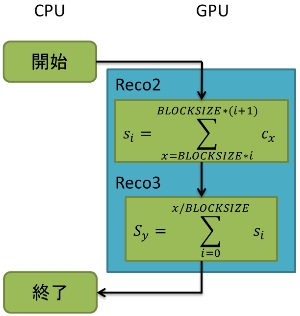
全体の構成としては初めにCPU側でデータを用意し、GPUにコピーしてユークリッド距離を求めるカーネル関数を呼び出している。また、今回の実装ではカーネル関数を複数作成し、式を分割して段階的に実装していく方法を採っている。これはカーネル関数によってブロックの中のスレッドの数を変更するためである。カーネル関数Recoでは式の始めの処理として全てのデータの差と、その二乗を求めている。カーネル関数Reco2とReco3では求めた差の総和を計算している。Reco4では求めた総和に平方根をとった後、正規化を行っている。また、この動作は全てのデータにおいて計算を終えるまでループしている。また、それぞれのカーネル関数については後で説明をしていく。
ここではカーネル関数Recoが行うデータの差の二乗を求める計算についてCUDAによってどのように並列化されていくか説明していく。
先の2.3において説明をしたユークリッド距離を求める式(1)
より初めに
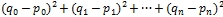 を計算する。
を計算する。
カーネル関数Recoは顧客ベクトルPとQのポインタが渡されると各スレッドで実行され、それぞれの成分の差の二乗を求める。それぞれのスレッド毎にカーネル関数をコピーして実行している。これによりスレッドで並列に実行することが出来る。つまり、スレッドidがy,xの時、rxの値としてQy-Pのx個目のデータの差の二乗
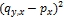 を計算する。ブロックやスレッドをx方向とy方向にそれぞれ管理することでユーザIDのデータの差を全て並列に計算することが出来る。図6に動作のイメージを示す。
を計算する。ブロックやスレッドをx方向とy方向にそれぞれ管理することでユーザIDのデータの差を全て並列に計算することが出来る。図6に動作のイメージを示す。
プログラム中の各変数の意味を次に示す。
予約変数
グローバル変数
変数
ratings型の構造体のメンバ
この動作をするコードを図7に示す。
__global__ void Reco(ratings *myda, ratings *da, ratings *g_s_da)
{
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
if(y < USER && x < ID){
int idx = y*ID+x;
g_s_da[idx].rate = myda[x].rate-da[idx].rate;
g_s_da[idx].rate = g_s_da[idx].rate*g_s_da[idx].rate;
}
}
図7 カーネル関数Recoのプログラム
変数xはスレッドがx方向のどのブロックIDに属しているどのスレッドかを示している。同じように変数yはy方向のどのブロックIDに属しているどのスレッドかを示している。変数idxは一次配列を二次配列のように扱うため、変数xとy*IDを足した値が代入される。構造体ratings型の変数mydaとdaのメンバrateの差を変数g_s_dataのメンバrateに代入して二乗する。全てのスレッドで同じコードを実行し、変数xとyの値により、スレッドがどのブロックのどのスレッドに属しているかが分かり、データの差の二乗を求めるという動作を並列に実行することが出来る。
ここではカーネル関数Reco2及びReco3においてRecoで求めた差の二乗の和の計算について、どのようにして実装するか、またどのように高速化をしていくかについて、過程についても説明する。
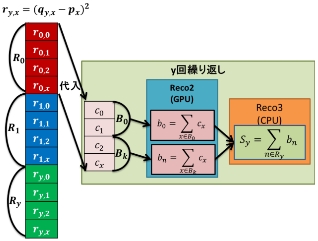
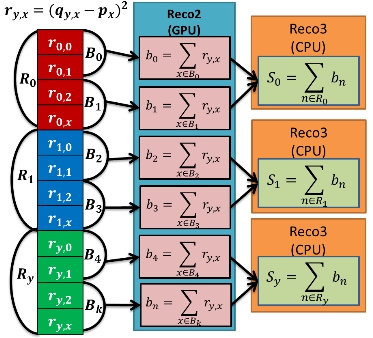
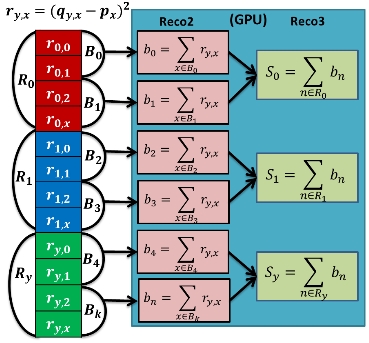
ユークリッド距離を求めるためにベクトルRyの成分が持つ評価の差の二乗の列から和を計算する。つまり、ベクトルRyの大きさの二乗を求めている。この時CUDAではシェアードメモリを使うことで同一ブロック内のスレッドが同期しながら木構造的にスレッドの和を計算する。この時3つの手法を用いて高速化を図っている。カーネル関数Reco2ではブロック内のスレッドで部分和bnを求め、Reco3ではReco2で求めた部分和bnから和Syを求めている。また、プログラム1及びプログラム2ではReco3に当たる部分はCPUで動作しているため、カーネル関数ではない。図8に和の計算のイメージを示す。
なお、各スレッドが同バンクのシェアードメモリにアクセスすることを防ぐために、文献[1]のアルゴリズムを使用した。
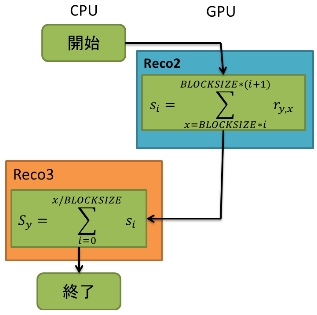
プログラム1(手法1)はベクトルRyのデータの中から一つのベクトルを抽出し、GPUにメモリ転送を行う。カーネル関数Reco2を呼び出すとGPUでブロック内のスレッドの部分和bnを求める。求めたブロック内の部分和bnをCPUにメモリ転送し、全ブロックの和Syを求める。この動作を全てのユーザIDのベクトルの大きさを求めるまで繰り返す。
プログラム2(手法2)はベクトルRyをGPUにメモリ転送を行う。そしてReco2を呼び出し、ブロック内のスレッドの部分和bnを求める。その後求めたブロック内の部分和bnをCPUにメモリ転送し、CPUで全ブロックの和Syを求める。
プログラム3(手法3)はベクトルRyをGPUにメモリ転送し、Reco2でGPUを使ってブロック内の部分和bnを求める。その後求めたブロック内の部分和bnをReco3に引数として渡し、Reco3のスレッドに割り当て、全ブロックの和Syを求める。
それぞれの手法で使われる変数の意味は次の通りである。
ここでは総和計算をするためのプログラム1(手法1)について説明をしていく。手法1ではカーネル関数Recoで求めたデータの差のベクトルRyの中から一つのベクトルを抽出し、GPUにメモリ転送を行う。カーネル関数Reco2を呼び出すとGPUでブロック内のスレッドの部分和bnを求める。求めたブロック内の部分和bnをCPUにメモリ転送し、全ブロックの和Syを求める。この動作を全てのユーザIDの大きさを求めるまで繰り返す。
プログラム1のフローチャートを図9、動作のイメージを図10に示す。
この動作をするコードを図11に示す。
for(int i = 0;i < USER; i++){
for(int j = 0;j < ID; j++){
onenear[j] = s_data[i*ID+j].rate;
}
cudaMemcpy( g_onenear, onenear, sizeof(int)*ID, cudaMemcpyHostToDevice);
Reco2<<< grid2, block2, BLOCKSIZE3*sizeof(int) >>>(g_onenear,g_souwa_y);
cudaThreadSynchronize();
cudaMemcpy(souwa_y, g_souwa_y, sizeof(int)*((ID/BLOCKSIZE3)), cudaMemcpyDeviceToHost);
a = 0.0;
for(int j = 0;j < (ID/BLOCKSIZE3);j++){
a += souwa_y[j];
}
sq_souwa_y[i] = a;
}
図11 プログラム1のmain関数の和の計算部分のプログラム
変数s_data.rateより変数onenearへユーザID一つ分のデータをfor文を使い代入する。よって変数onenearにはユーザID一つ分のベクトルcの成分が格納されている。その後cudaMemcpy関数でCPU側の変数onenearからGPU側の変数g_onenearへメモリ転送を行い、カーネル関数Reco2を呼び出す。Reco2ではブロック内のスレッドの部分和bnを求めている。そしてGPU側の変数g_souwa_yからCPU側の変数souwa_yへと再びメモリ転送を行い、Reco3に当たる部分で求めた部分和から和Syを求めている。この時for文の条件にはj<(ID/BLOCKSIZE3)となっている。IDはプロフィールIDのデータの数となっており、BLOCKSIZE3はブロック内のスレッドの数となっている。ブロック内で部分和を求めているためIDをスレッド数で割っている。この動作を変数USERの値まで繰り返し行なっている。
ここでは総和計算をするためのプログラム2(手法2)について説明していく。手法2ではカーネル関数Recoで求めたデータの差のベクトルRyをGPUにメモリ転送を行う。そしてReco2を呼び出し、ブロック内のスレッドの部分和bnを求める。その後求めたブロック内の部分和bnをCPUにメモリ転送し、CPUで全ブロックの和Syを求める。
プログラム2のフローチャートを図12、動作のイメージを図13に示す。
この動作をするコードを図14に示す。
Reco2<<< grid2, block2, BLOCKSIZE3*sizeof(int) >>>(g_s_data,g_souwa_y);
cudaThreadSynchronize();
cudaMemcpy( souwa_y, g_souwa_y, sizeof(int)*(((USER*ID)/BLOCKSIZE3)), cudaMemcpyDeviceToHost);
n = 0;
j = 0;
for(i = 0; i < USER; i++){
a = 0.0;
for(j = n;j < n+(ID/BLOCKSIZE3);j++){
a += souwa_y[j];
}
sq_souwa_y[i] = a;
n = j;
}
図14 プログラム2のmain関数の和の計算部分のプログラム
この手法では手法1と比べ、ユーザID一つ分のベクトルを抽出する必要が無いため、初めにカーネル関数Reco2を呼び出し、ブロック内のスレッドで部分和bnを計算している。その後GPU側の変数g_souwa_yからCPU側の変数souwa_yへメモリ転送を行い、Reco3に当たる部分でユーザID毎にReco2で求めた部分和から和SyをCPU上でfor文を使い求め、計算した値を変数sq_souwa_yに代入している。この手法では全てのユーザIDのデータを全て一度のカーネル関数呼び出しで実行するためにブロック内のスレッド数で割り切れる値になるようにデータの最後にダミーのデータを置くことで割り切れるようにデータの数を揃えている。手法1と比べるとデータの抽出するという動作が無くなり、メモリ転送を行う回数が減っている。
ここでは総和計算をするためのプログラム3(手法3)について説明していく。手法3ではカーネル関数Recoで求めたデータの差のベクトルRyをGPUにメモリ転送し、Reco2でGPUを使ってブロック内のスレッドの部分和bnを求める。その後求めたブロック内の部分和bnをReco3に引数として渡し、Reco3のスレッドに割り当て、和Syを求める。
プログラム3のフローチャートを図15、動作のイメージを図16に示す。
この動作をするコードを図17に示す。
Reco2<<< grid2, block2, BLOCKSIZE3*sizeof(int) >>>(g_s_data,g_souwa_y);
cudaThreadSynchronize();
Reco3<<< grid3, block3, BLOCKSIZE4*sizeof(int) >>>(g_souwa_y,g_sq_souwa_y);
cudaThreadSynchronize();
図17 プログラム3のmain関数の和の計算部分のプログラム
この手法では手法2と同じようにデータの抽出の必要が無いため、初めにカーネル関数Reco2を呼び出し、ブロック内の部分和bnを求めている。次に求めた部分和から和を求めるが、この手法ではそれぞれのブロックで求めた部分和をCPUで計算せずにカーネル関数Reco3を呼び出しReco2で求めた各ブロックで求めた部分和をReco3のスレッドに割り当てて和Syを計算している。この手法では手法2でデータの後ろにダミーデータを置いて割り切れるように揃えていたが、更にカーネル関数Reco3で和を計算をするために更に割り切れるようにダミーデータを置くことで数を揃えている。このためダミーデータの数を増えてしまうのが問題になる可能性が考えられる。またCPUで計算を行うことが無いため、メモリ転送を行う必要が無いため高速化出来ると考えられる。
今回の計測に使用したPCの環境を表1に示す。
| OS | Windows7 Professional 64bit |
| CPU | Intel Core i7-4820k CPU 3.70GHz |
| GPU | NVIDIA GeForce GTXTITAN×2 |
| CUDA | Ver5.5 |
| RAM | 32GB |
| 源データ | 参考文献[3]サイト内のrating.dat |
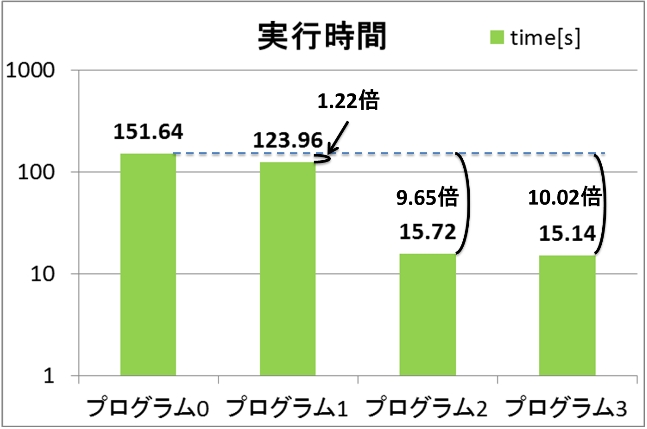
それぞれのプログラムを各5回ずつ実行した平均の結果を表2及び図18に示す。CPUのみで動作するプログラム0と比べ、プログラム1(手法1)では1.22倍、プログラム2(手法2)では9.65倍、プログラム3(手法3)では10.02倍高速化出来た。プログラム1ではベクトルRyの中からユーザID一つ分のデータを抽出をしてGPUに転送しているためカーネル関数の呼び出し回数とメモリ転送の回数が増えたことがロスになっているのではないかと考える。プログラム2とプログラム3ではどちらもCPUの実行時間と比べ約10倍以上の高速化出来た。またプログラム2とプログラム3を比べた場合プログラム3の実行時間のほうが短くなった。これはプログラム2ではReco3に当たる部分をCPUで動作させるためにメモリ転送をしていたがプログラム3ではGPUで動作させているため、その分メモリ転送が無くなったため、高速化に繋がったのではないかと考えられる。
| プログラム0[s] | プログラム1[s] | プログラム2[s] | プログラム3[s] | |
|---|---|---|---|---|
| 1 | 152.568 | 122.624 | 15.778 | 15.179 |
| 2 | 150.453 | 125.632 | 15.775 | 15.15 |
| 3 | 152.58 | 124.69 | 15.746 | 15.129 |
| 4 | 151.574 | 124.659 | 15.676 | 15.12 |
| 5 | 151.022 | 122.172 | 15.618 | 15.138 |
| 平均 | 151.6394 | 123.9554 | 15.7186 | 15.1432 |
本研究ではレコメンデーションシステムをGPGPUで高速化することを目標に研究を行った。結果としてCPUのみで動作するプログラムに比べ、最大で約10倍高速化出来た。3つの手法を用いて高速化したが、速い手法とあまり速くない手法があった。これはメモリ転送の回数やカーネル関数の呼び出し回数が多い手法だったためあまり速くならない手法になってしまったのだと考えられる。また約10倍高速化出来たが、より高速化出来る手法を見つけていきたい。