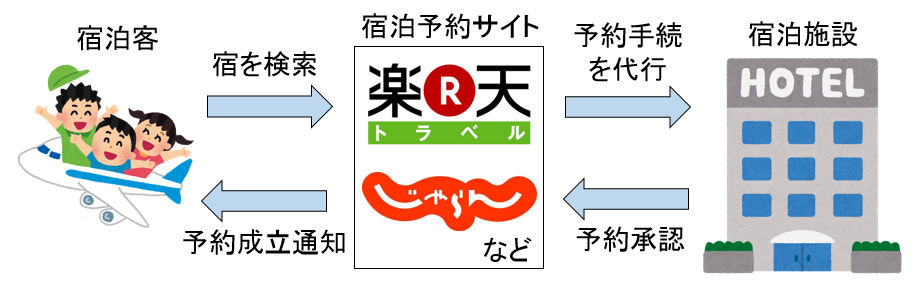
�l�b�g���[�N�V�X�e��������
�w�������@��{�@���u
14EC071�@�|���@�s��
�@���݁A�h���\��T�C�g�̕��y�ɂ����{�����̂قڑS�Ă̏h���{�݂̏��̓C���^�[�l�b�g��ʼn{���ł���B�h���\��T�C�g�Ƃ́A�C���^�[�l�b�g��ŏh���̗\�ł���Web�T�[�r�X�ł���B�]���̈�ʓI�ȏh���\����@�ł���d�b�\��Ɣ�ׂ�24���ԗ\��\�ȗ�����A�|�C���g�����܂铙�̓_���猻��ɂ����čł��������p�����h���\��̕��@�ł���ƌ�����B�Â���JTB��HIS�ȂǗ��s��Ђ̃T�[�r�X���I�����C�����������̂ł��������A���݂ł͂������y�V�g���x���Ȃǂ̃I�����C����p�̂��̂����{�����ł͈�ʓI�Ƃ���Ă���h���\��T�C�g�ł���B�h���\��T�C�g�́A�h����]�̓��ɂ��Ȃǂ���͂��邱�Ƃŏ����ɍ������h���{�݂̈ꗗ��\������B����ɏh���q�����͂��������g���h���\��̎葱�����s����B�i�}1�j
�}1. �h���\��T�C�g��p�����h���\��̃C���[�W
�@�h���\��T�C�g����͗l�X�ȏ������B���̒��ł��{�����ł͏h���{�݂̑����]���ƃ��[�U�[���r���[�̕������ɒ��ڂ��f�[�^���W�y�ѕ��͂��s���B�����]���Ƃ́A�H���≷��E���n�Ȃǂ̗v�f�����ۂɏh���������[�U�[���l�����A�S�Ă̗v�f�𑍍��I�ɔ��f�����h���{�݂ɑ���]���ł���B���[�U�[���r���[�Ƃ́A�h�������ۂɊ����������ȓ_��s���ȓ_��������Ă���h���q�ɂ��R�����g�ł���B�����]���ƃ��[�U�[���r���[�͎��ۂɂ͈ȉ��̐}2�̗l�ȃf�[�^�ł���B
![�y�V�g���x���ɂ����鑍���]���ƃ��[�U�[���r���[](img2.png)
�}2. �y�V�g���x���ɂ����鑍���]���ƃ��[�U�[���r���[
�@�}2�����ĕ�����l�ɁA���[�U�[���r���[�͎��ۂ̕����̐������₻��ɑ���]�ƈ��̑Ή��̗l�q�Ƃ�������L�ڂ���Ă���B�h���{�݂̌����T�C�g�����ł͒m�蓾�Ȃ��������̂ŁA�h���\�������ۂɂ̓��[�U�[���r���[�͔��ɎQ�l�ɂȂ���̂ł���B��������]���̓��[�U�[���r���[�قǏڍׂȏ����܂�ł͂��Ȃ����A�h���{�݂̕]�������̐��Œm�鎖���o����B����đ����]���͊ȈՓI�ɏh���{�݂̕]����m�肽�����ɗL�p�ł���B�{�����ł́A����瑍���]���ƃ��[�U�[���r���[�̓�̃f�[�^����̏h�̃p�����[�^�Ƃ��Đݒ肵�A�n�悲�ƂɃf�[�^���W����B���̃f�[�^���N���X�^���͂��邱�ƂŒn������̕��͂��s���B���͂̌��ʁA�e�n�悲�ƂɃN���X�^�\���ɈႢ������ꂽ�B����ɃN���X�^���͂̌��ʂ��l�@���鎖�Ŋe�n��̋q�w�Ȃǂ������Ă��鎖�����������B
�@�y�V�g���x���͓��{�����̑�\�I�ȏh���\��T�C�g�̈�ł���A�h���{�݂̗\��݂̂łȂ������o�X����^�J�[�̗\����\�ȗ��s�Ɋւ��鑍���\��T�C�g�ł���B�}3�͊y�V�g���x���̃z�[����ʂł���B�y�V����łȂ��Ƃ����p���鎖���ł��邪�A�y�V����ł���Ίe��\��̌��ς̓x�Ɋy�V�X�[�p�[�|�C���g�߂鎖���ł���B
�@�{�����ł́A���̊y�V�g���x�����瑍���]���ƃ��[�U�[���r���[�̃f�[�^�����W�����͂��s���B�����ΏۂƂ��ďd�v�Ȃ̂́AAPI�����J���Ă���_�ł���B
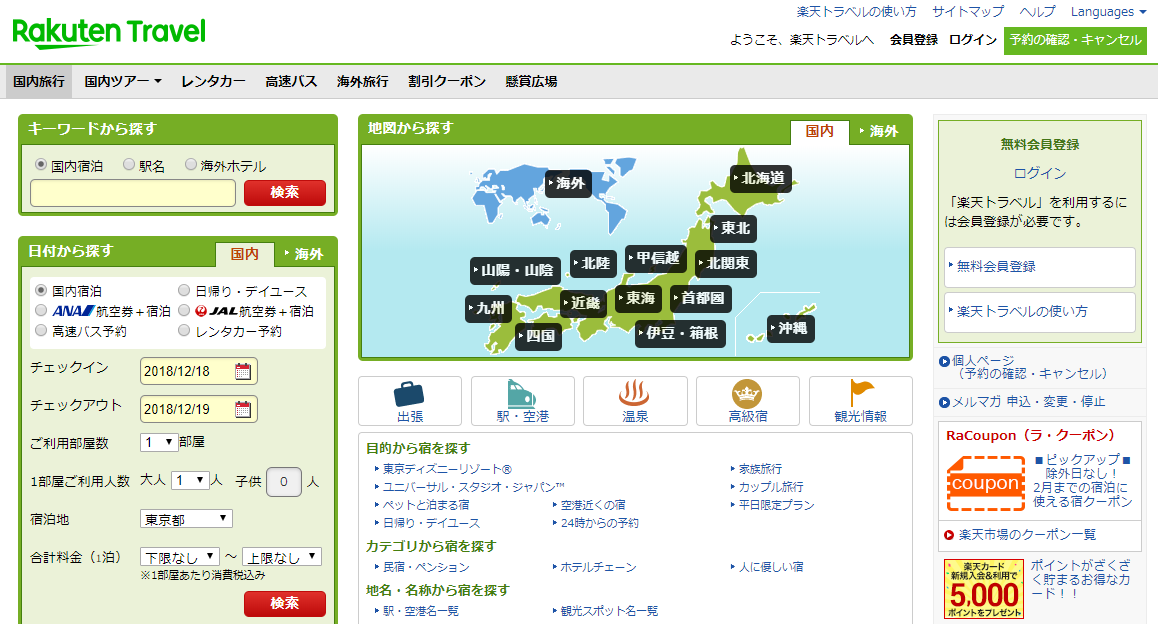
�}3. �y�V�g���x���̃z�[�����
�@�{�߂ł́A�y�V�g���x����p���Ď��ۂɏh���{�݂���������l�q���������B�O������Ƃ��āA�h���n�͕��Ɍ���JR�O�m�{�w���ӂŏh���l���͓�l�A������2019�N3��4������ꔑ�Ƃ���B
�@�܂��͊y�V�g���x���̃z�[����ʂ̃L�[���[�h��T���̍��ڂ���w���Ƀ`�F�b�N�����ĎO�m�{�w�Ɠ��́B�i�}4�j
�}4. �L�[���[�h�������
�@�����đ��̌�����������͂����ʁi�}5�j�ɏh�������E�l���Ȃǂ���͂���B�Ȃ��A�\�������������Őݒ肵�Ă������Ƃ����������B�������鎖�ŖړI�̏h���{�݂������₷���Ȃ�B����͗����̈������ɐݒ肷��B

�}5. �y�V�g���x���ɂ�����h���{�����̏����ݒ�
�@�}6�͐}5�̏����Ō������s�������ʂ̈ꕔ�ł���B�y�V�g���x���ł͂��̗l�ɍŒ���̌�����������͂��邱�ƂŊ�]�ɂ������h���{�݂̏��̈ꗗ�����鎖���ł���B
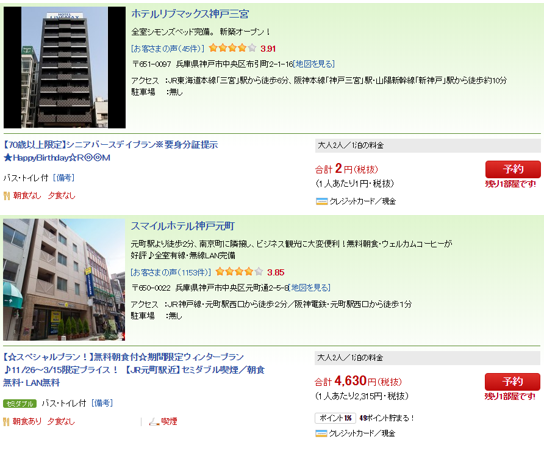
�}6. �O�m�{�w���ӂ̏h���{�݂̌������ʁi�ꕔ�j
�@����ɁA�e�h���{�݂̂��q�l�̐��̍��ڂ��N���b�N���鎖�ő����]���ƃ��[�U�[���r���[���{���ł���B�i�}7�j
![�z�e�����u�}�b�N�X�_�ˎO�{�̑����]���ƃ��[�U�[���r���[](img7.png)
�}7. �z�e�����u�}�b�N�X�_�ˎO�{�̑����]���ƃ��[�U�[���r���[
�@���̗l�Ɋy�V�g���x���ł͊�]�̏h����������͂��鎖�ŏ����ɍ������h���{�݂̏����{���ł���B
�@API��URL���w�肷�鎖�ŖړI�̃f�[�^���擾������̂ł���B��������͊y�V�����J���Ă���URL���w�肹���Ƀp�����[�^���w�肷�邾���Ńf�[�^���擾�ł���y�V�g���x���nAPI��Web�y�[�W���g�p����B�y�V�g���x���nAPI�ɂ͐}8�̒ʂ莵�̎�ނ�����B�擾�ł���f�[�^�̗�Ƃ��Ď{�ݏ���A���̑��ɂ��n��R�[�h��h�̃����L���O���擾���邱�Ƃ��ł���B�{�����ŗp����̂͊y�V�g���x���{����API�Ɗy�V�g���x���n��R�[�hAPI�̓�ł���B�y�V�g���x���{����API�ł́A����n��̏h���{�݂̃f�[�^����x�ɍő��30���擾�ł���B�y�V�g���x���n��R�[�hAPI�ł̓f�[�^�����W�������n��̃p�����[�^�ƂȂ�y�V�g���x���n��R�[�h���擾�ł���B������̎g������ڍׂɂ��Ă�3�͂Ő�������B

�}8. �y�V�g���x���nAPI�̎��
�@�{�߂ł͊y�V�g���x���{����API�Ɗy�V�g���x���n��R�[�hAPI��p���ďh�̑����]���ƃ��[�U�[���r���[�̃f�[�^�����W�����@�ɂ��ďq�ׂ�B
�@�܂��n�߂ɁARakuten Developers�̃y�[�W����e�n��̊y�V�g���x���n��R�[�h���擾����B��̓I�Ȏ菇�͈ȉ��̒ʂ�ł���B
1.�@Rakuten Developers�̊y�V�g���x���n��R�[�hAPI�̃y�[�W���J���B�i�}9�j
�@�@URL�Fhttps://webservice.rakuten.co.jp/api/getareaclass/
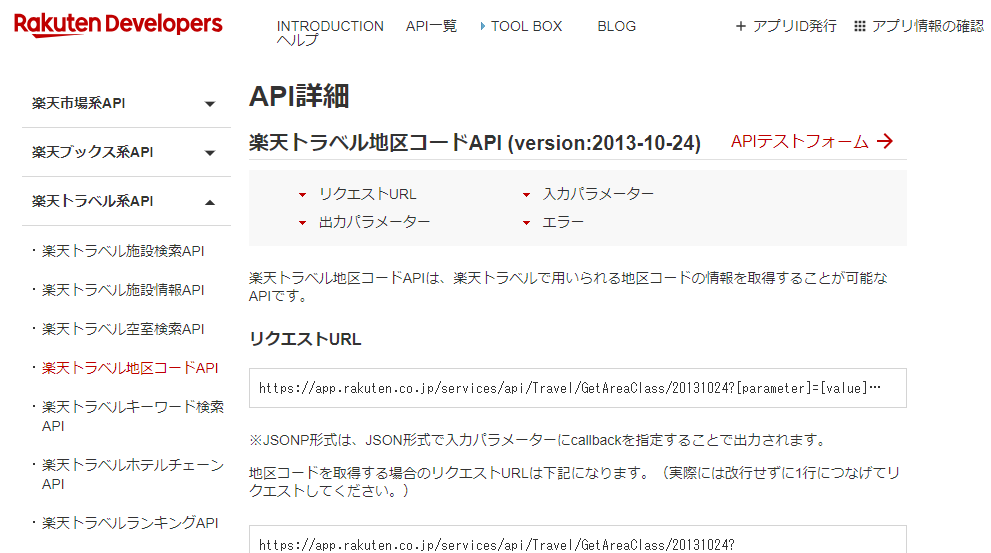
�}9. �y�V�g���x���n��R�[�hAPI�̃y�[�W
2.�@API�e�X�g�t�H�[���Ɉړ�����B
3.�@�p�����[�^�̍���largeclasscode�A�E��japan�ɐݒ肷��B�i�}10�j
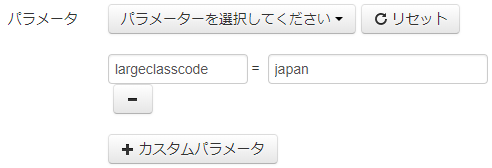
�}10. �p�����[�^�̎w��
4.�@GET�{�^���Ńf�[�^���擾����B
�@�ȉ��̐}11�͊y�V�g���x���n��R�[�h�̎擾���ʂ̈ꕔ�ł���B�擾�����f�[�^��"�f�[�^�̎��"�F"�f�[�^�̒l"�Ƃ�����JSON�ł̕\�L�ƂȂ��Ă���B

�}11. �n��R�[�h�̎擾���ʁi�ꕔ�j
�@�����Ċy�V�g���x���{����API�ŏh���{�݂̏������W����B��̓I�Ȏ菇�͈ȉ��̒ʂ�ł���B
1.�@Rakuten Developers�̊y�V�g���x���{����API�̃y�[�W���J���B�i�}12�j
�@�@URL�Fhttps://webservice.rakuten.co.jp/api/simplehotelsearch/
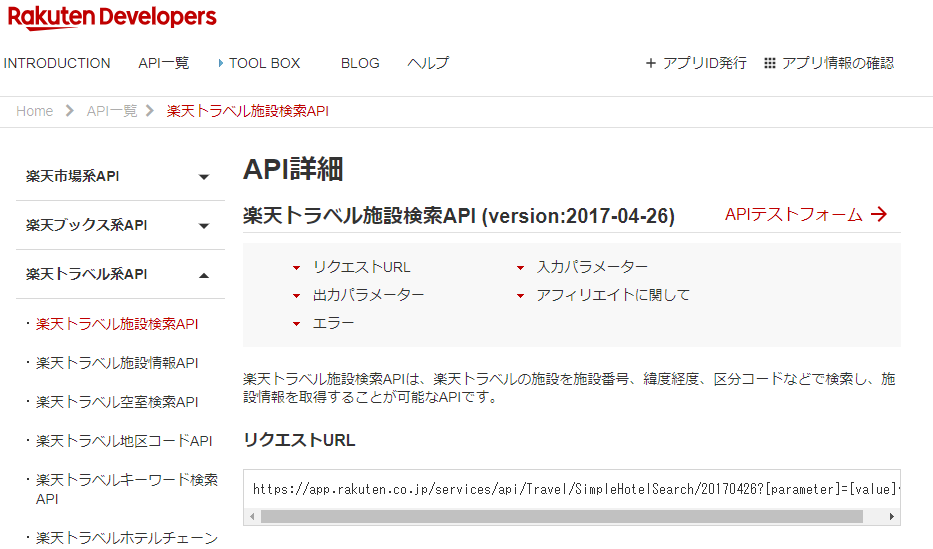
�}12. �y�V�g���x���{����API�̃y�[�W
2.�@API�e�X�g�t�H�[���Ɉړ�����B
3.�@�f�[�^�����W�������n��̊y�V�g���x���n��R�[�h���p�����[�^�ɓ��͂���B�i�}13�j
�@largeClasscode=japan
�@middleClasscode=hokkaido
�@smallClasscode=sapporo
�@detailClasscode=A
�@�ȏ�̃p�����[�^�ݒ�ŁA���{�̖k�C���D�y�s���̎D�y�E�V�D�y�E�Վ��G���A���w�肵�����ɂȂ�B�����̃G���A��largeClasscode����smallClasscode�܂ł̎w��ŗǂ��B�������ׂ������ނ���Ă���ꕔ�̃G���A��detailClasscode���w�肷��K�v������B
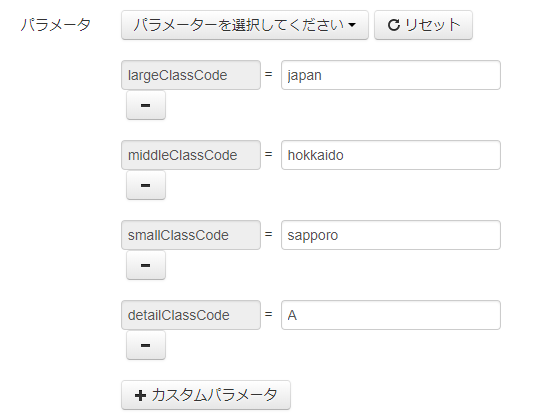
�}13. API�e�X�g�t�H�[���̃p�����[�^���͗�i�D�y�E�V�D�y�E�Վ��G���A�j
4.�@GET�{�^���Ńf�[�^���擾����B
�@�}14�͎D�y�E�V�D�y�E�Վ��G���A���w�肵�A�f�[�^���擾�������ʂ̈ꕔ�ł���B��̏h�ɂ��h���A�d�b�ԍ��A�Z���ɉ����ďh���q�̕]���ƃ��[�U�[���r���[�Ȃǂ��擾�ł���B�{�����ł͂��̃f�[�^�̒����瑍���]���ireview Average�j�ƃ��[�U�[���r���[���L�^���Ă����B�Ȃ��A���[�U�[���r���[�͏h���ƂɍŐV�P���̃��r���[���\�������B�}14�ł͈�̏h�̃f�[�^���\������Ă��邪�A���ۂɂ�30���̏h�̃f�[�^���Ɏ擾���Ă���B�������ē���ꂽ30���S�Ă̏h���{�݂̑����]���ƍŐV���r���[�̃f�[�^�����W���A�n�悲�Ƃɂ܂Ƃ߂�B

�}14. �h���{�݂̃f�[�^�擾��
�@�Ȃ��A�h���{�݂ɂ���Ă̓��[�U�[���r���[������Ɏ擾�ł��Ȃ��ꍇ������B�}15�͋��s�@���R����@�n�����Ƃ������ق̃f�[�^�ł���B���[�U�[���r���[�̍��ڂ������"null"�ƕ\������Ă��ăf�[�^���擾�ł��Ă��Ȃ�����������B

�}15. �ŐV���r���[�̎擾�Ɏ��s������
�@�y�V�g���x���ɂē����ق���������Ɛ}16�̗l��161���̃��[�U�[���r���[���m�F�ł����B���̎�����y�V�g���x���{����API�Ńf�[�^�擾�Ɏ��s���錴���͏h���{�݂̃��[�U�[���r���[���ꌏ�����݂��Ȃ��Ƃ������ł͖����A�����ʂ̌����ɂ����̂ł���ƍl������B���r���[���e���}17�̗l�ɓ��ʂȂ��̂ł͂Ȃ��A���̐���Ƀ��r���[���擾�ł��Ă��闷�قƂ̍��ق͖����悤�Ɏv����B

�}16. �f�[�^�擾�Ɏ��s�����h���{�݂̊y�V�g���x���ł̌�������
�}17. �f�[�^�擾�Ɏ��s�����h���{�݂̌��R�~
�@�y�V�g���x���{����API�ɂ���Ċe�G���A���Ƃɏh��review Average��user Review�̕��������擾���A�������ŐV���r���[�̕������A�c���𑍍��]���ireview Average�j�Ƃ��ĎU�z�}��`���ƈȉ��̐}18�̗l�ɂȂ�B�O���t�E�[�ɓ_�̂܂Ƃ܂肪���邪�A����͎擾�ł��郌�r���[�������̏����100�����ł��邱�Ƃɂ���Ăǂ̃O���t�ɂ����R�Ɣ���������̂ł���B
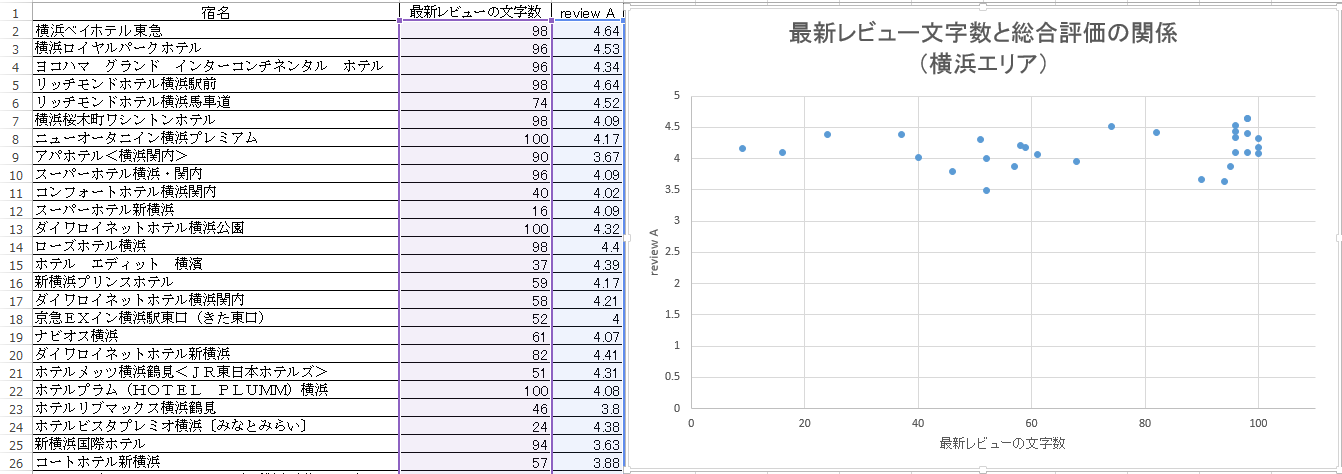
�}18. �擾�������̉����i���l�G���A�j
�@�ȍ~�͓��{�̊e�n����ď̂���ۂɁA�ȒP�̈ȉ��̗l�Ɍď̂���B
�D�y�E�V�D�y�E�Վ��G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�D�y�G���A
����E�����E�o�ʃG���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@����G���A
�X�E����G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�X�G���A
�H�c�G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�H�c�G���A
�R�`�E�����E�V���E��R�G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�R�`�G���A
��z�E������E�����G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@��z�G���A
���ˁE�}�ԃG���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@���˃G���A
���E�y�Y�E���G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@���G���A
��{�E�Y�a�E����E����G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@��{�G���A
�V���E�����E�l�����E�����G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�V���G���A
�����w�E����E�H�t���E���z���E�����G���A�@�@�@�@�@�@�@�@�@�@���@�����G���A
���l�G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@���l�G���A
���q�E���E��\�㗢�E�����E�Ό��G���A�@�@�@�@�@�@�@�@�@�@�@�@���@���q�G���A
�b�{�E�����E���勬�G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�b�{�G���A
�z�K�G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�z�K�G���A
�l���E�l���E�V���G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�l���G���A
���É��w�E�����E�ۂ̓��G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@���É��G���A
�l���s�E�K���E���̎R�E��������G���A�@�@�@�@�@�@�@�@�@�@�@�@���@�l���s�G���A
���s�w�G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@���s�G���A
���w�E�~�c�E���j�o�[�T���V�e�B�E���G���A�@�@�@�@�@�@�@�@���@���G���A
�_�ˁE�L�n����E�Z�b�R�G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�_�˃G���A
�����E���ʂ��E��������G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�����G���A
���m�E�썑�E����E�ɖ�G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@���m�G���A
���R�G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@���R�G���A
�q�~�E���ЁE�ʖ�E�}���G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�q�~�G���A
���ցE�F���G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@���փG���A
�����E�L���i���V�e�B�E�C�̒����E���ɕ{�E����s�G���A�@�@�@�@���@�����G���A
�ʕ{�E���o�G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�ʕ{�G���A
�{��G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�{��G���A
�ߔe�G���A�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@���@�ߔe�G���A
�@�}19�Ɛ}20�͎O�͂ŏq�ׂ���@�ŕʕ{�G���A�Ɠ����G���A�̏h�̑����]���ƍŐV���r���[�̕����������������O���t�ł���B
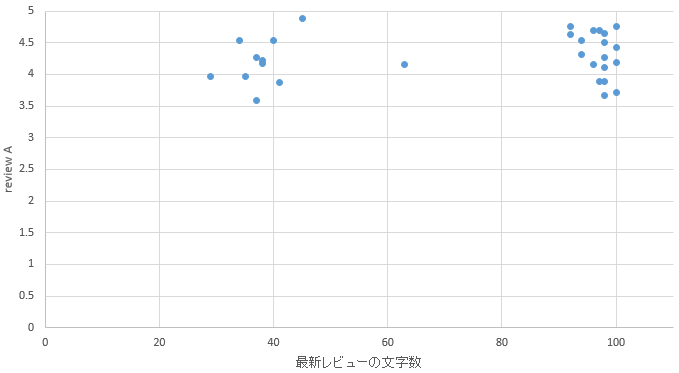
�}19. �ʕ{�G���A
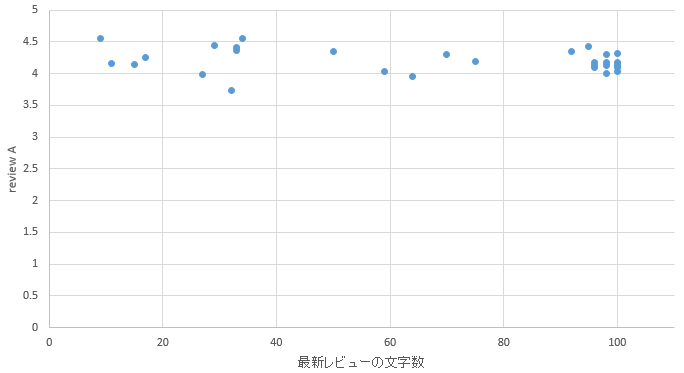
�}20. �����G���A
�@�}19�̕ʕ{�G���A�͍ŐV���r���[�̕�����40��100�ɃN���X�^������悤�Ɍ�����B���̂���40�����t�߂̃N���X�^�𒆊ԕ������N���X�^�ƌĂԁB����A�}20�̓����G���A�͍ŐV���r���[�̕�����100�̃N���X�^�͂��邪�A40�̃N���X�^�͌������A���ԕ������N���X�^�������Ă��Ȃ��B
�@�{�����ł͂��̗l�ɍŐV���r���[�̕������|�����]���O���t�ɂ�����N���X�^�\���ɒ��ڂ��A�N���X�^�\���ƃG���A�̊W���o�������l�����B
�@���̑��A�f�[�^���W���s�����G���A�̃O���t���ȉ��Ɏ����B
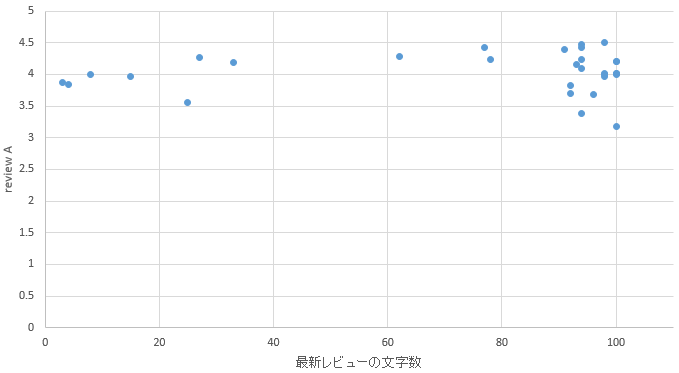
�}21. �D�y�G���A
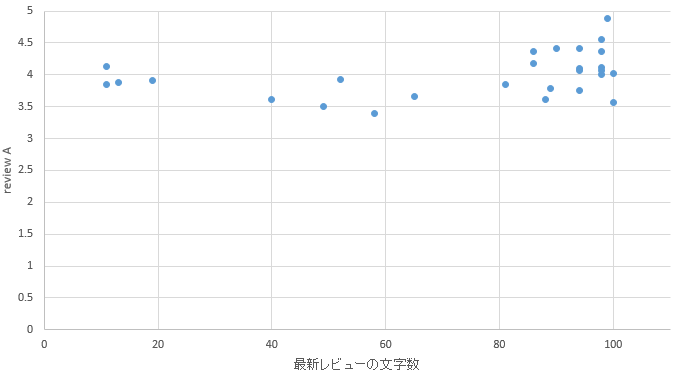
�}22. ����G���A
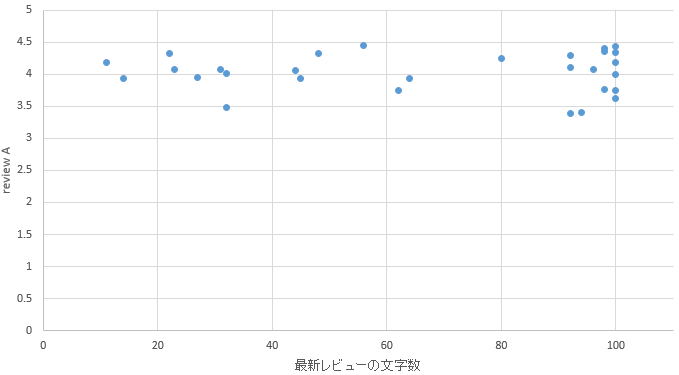
�}23. �X�G���A
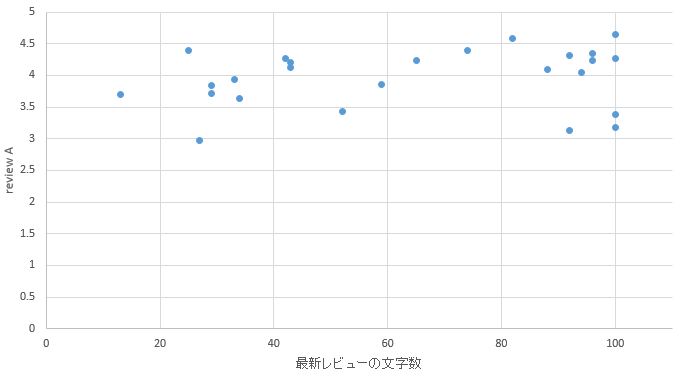
�}24. �H�c�G���A
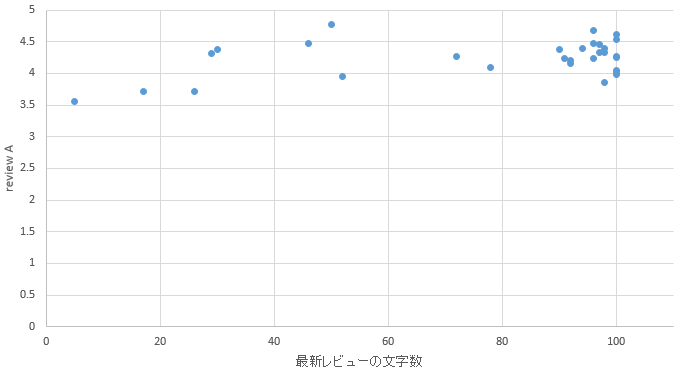
�}25. �R�`�G���A
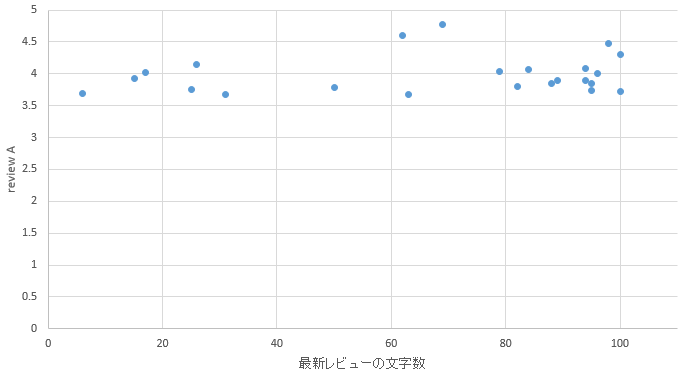
�}26. ��z�G���A
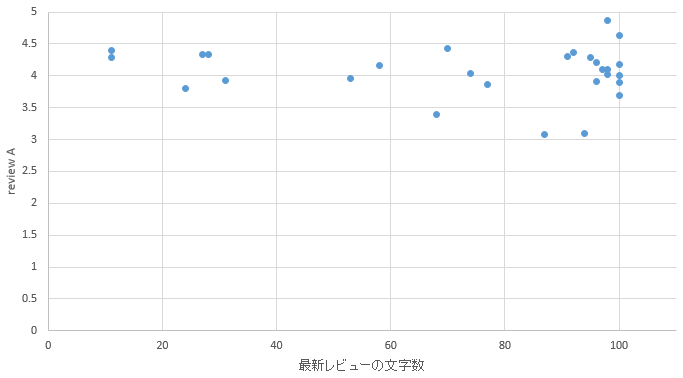
�}27. ���˃G���A
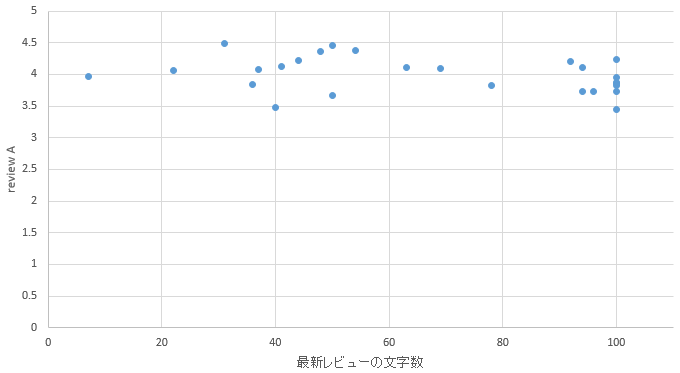
�}28. ���G���A
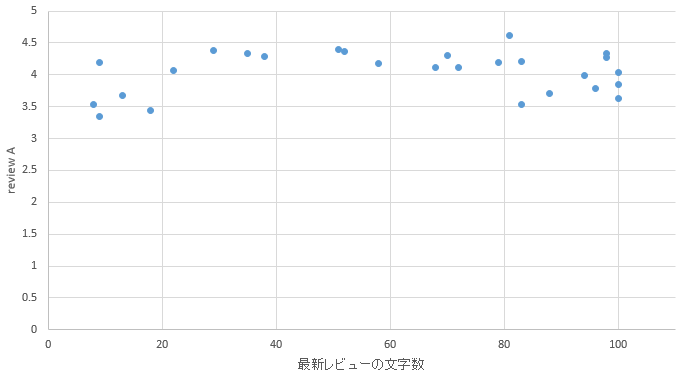
�}29. ��{�G���A
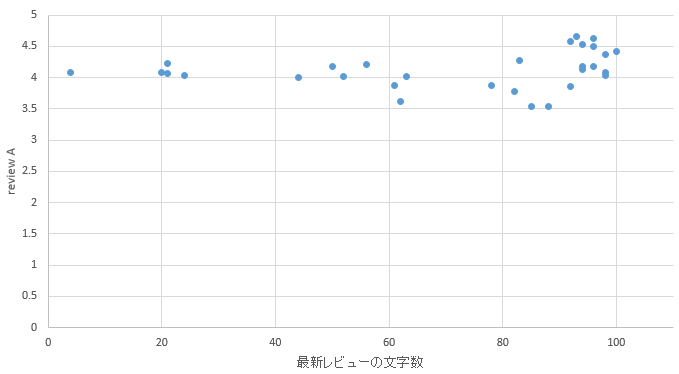
�}30. �V���G���A
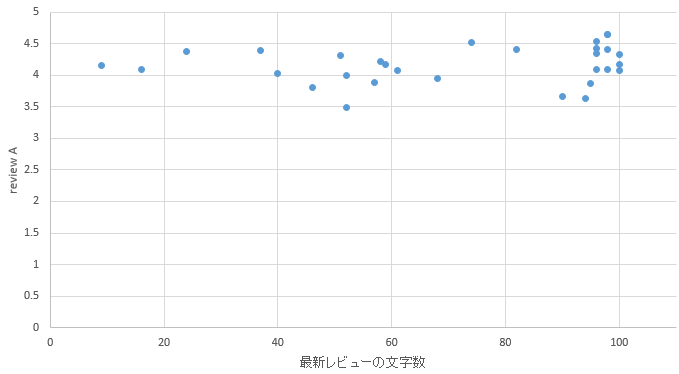
�}31. ���l�G���A
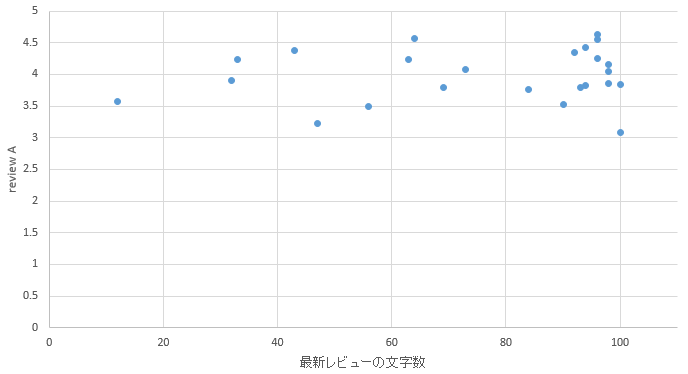
�}32. ���q�G���A
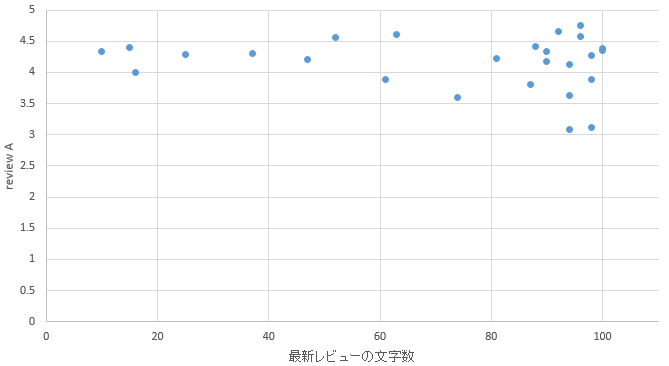
�}33. �z�K�G���A
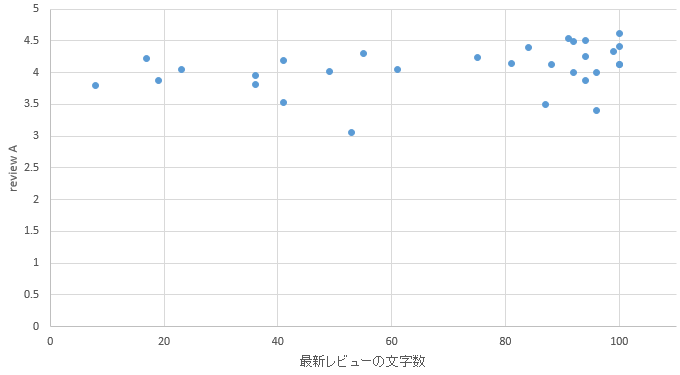
�}34. �l���G���A
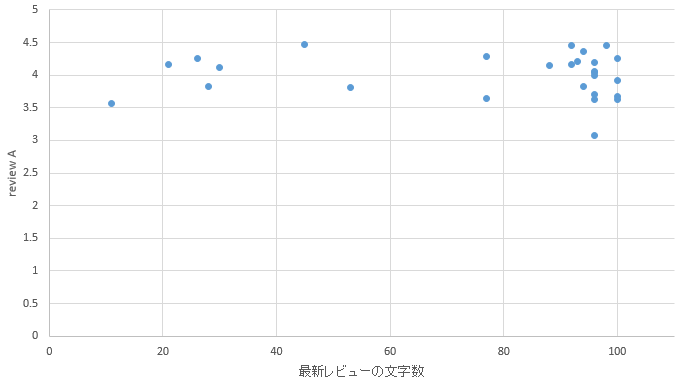
�}35. �b�{�G���A
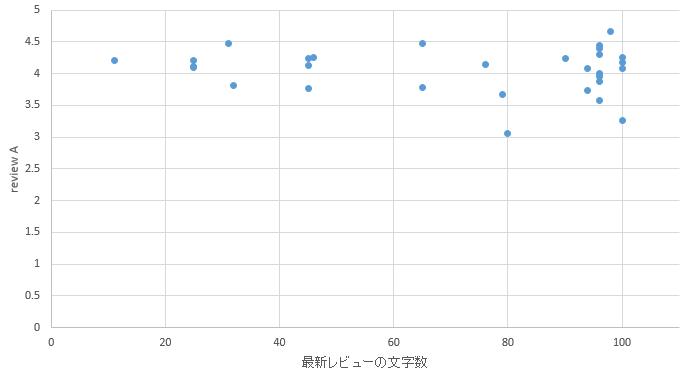
�}36. �����G���A
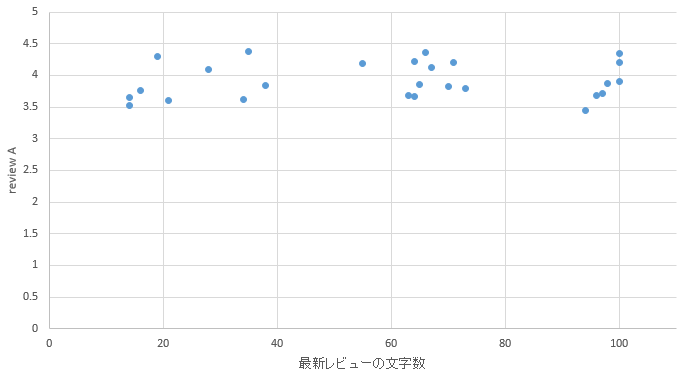
�}37. �l���s�G���A
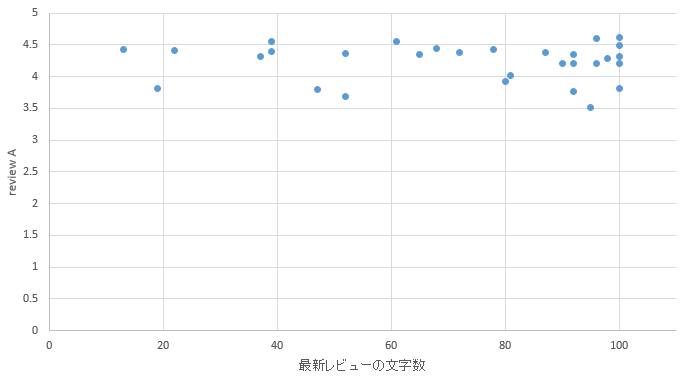
�}38. ���s�G���A
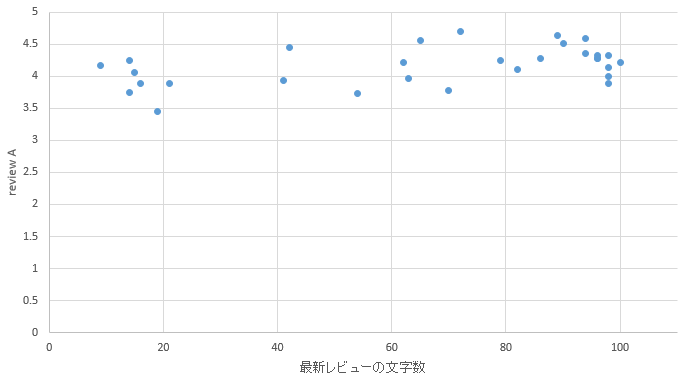
�}39. ���G���A
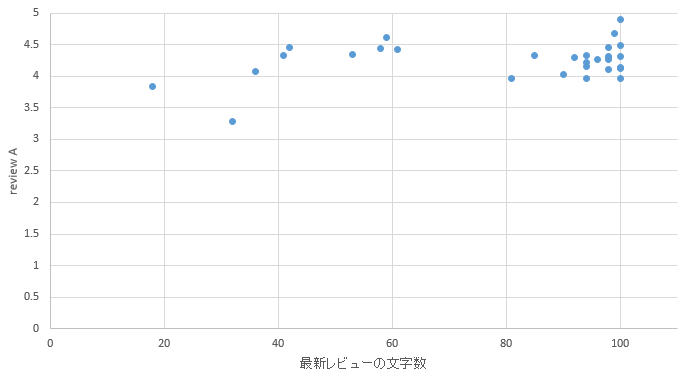
�}40. �_�˃G���A
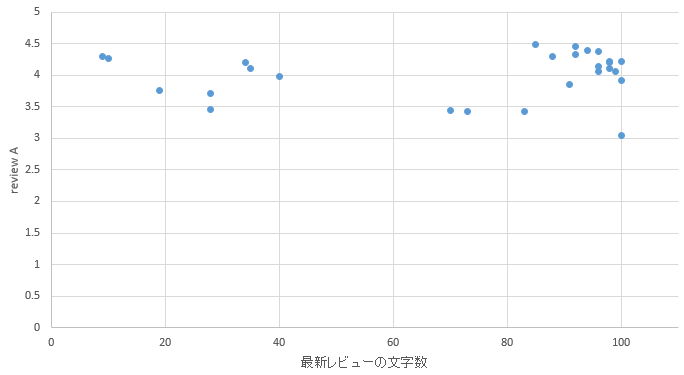
�}41. �q�~�G���A
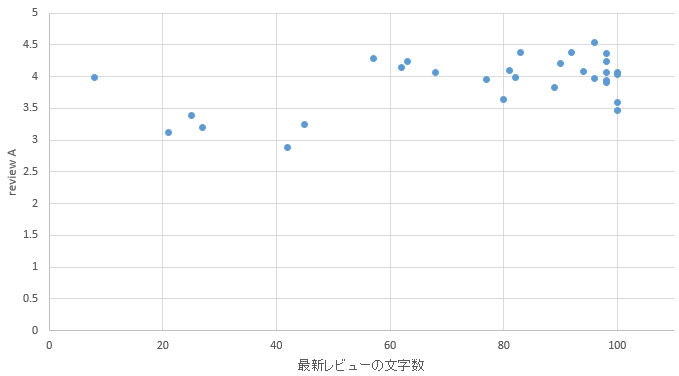
�}42. ���R�G���A
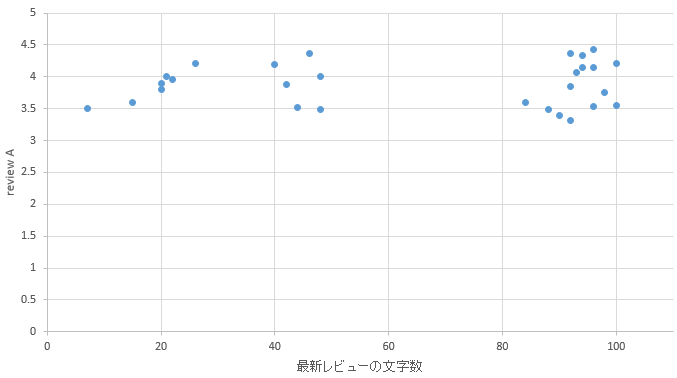
�}43. �����G���A
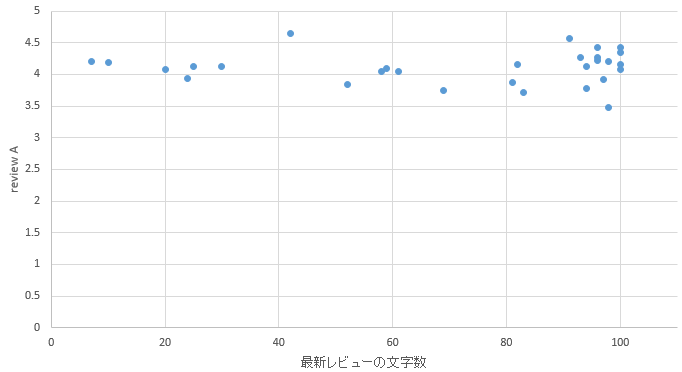
�}44. ���m�G���A
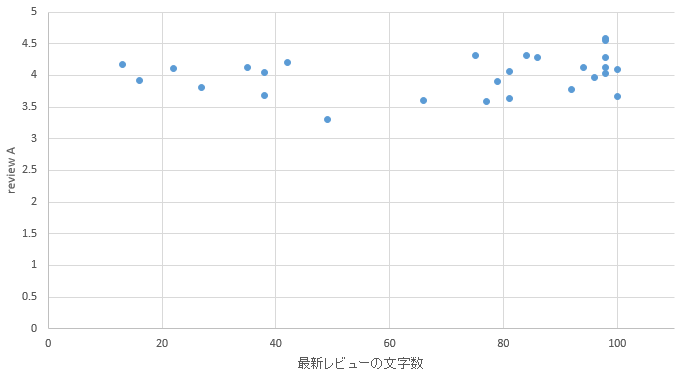
�}45. ���փG���A
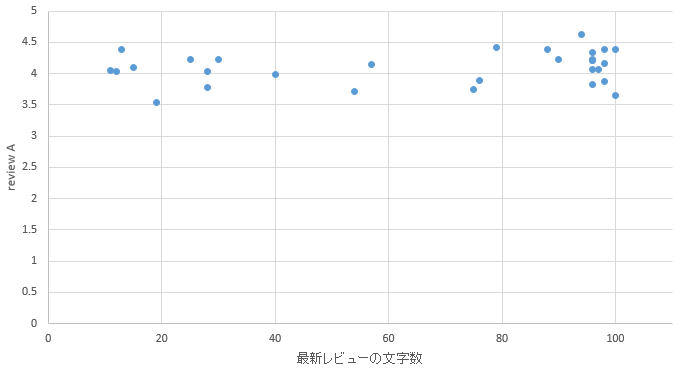
�}46. �����G���A
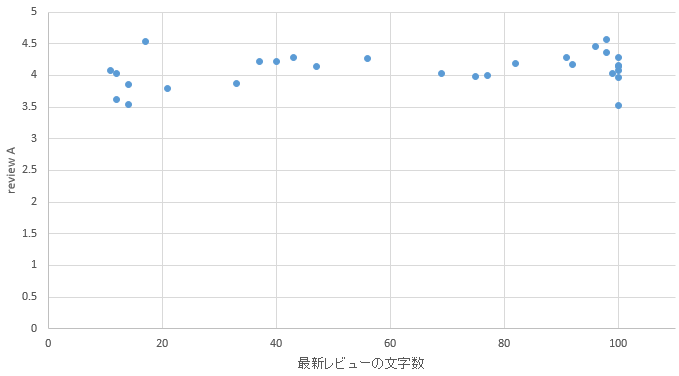
�}47. �{��G���A
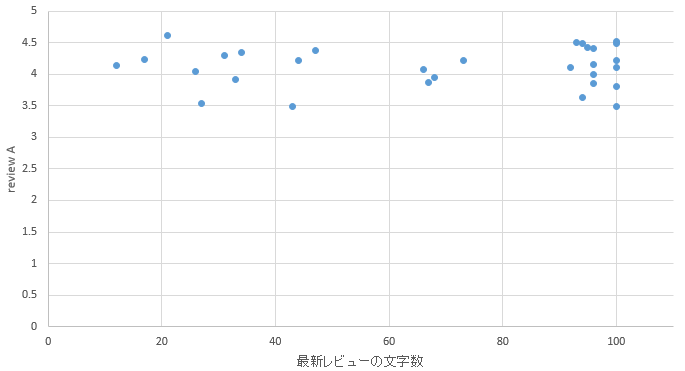
�}48. �ߔe�G���A
�@�e�n��ɂ�����N���X�^�\�����ڍׂɕ��͂���ׁA�N���X�^���͂��s���B�N���X�^���͂ɂ�Rapidminer��p����B�܂��͎O�͂ōs�����̂Ɠ��l�̕��@�Ŋe�n�悲�Ƃ̏h���{�݂̑����]���ƍŐV���r���[�̕��������擾����B���̏�ŃN���X�^���͂��s�����ŁA�e�G���A�̃f�[�^�������̂܂Ƃ܂�ɕ��ނł��邩�A�܂�̓N���X�^�\�����m�F�ł���B�}49�̗l�ɕʕ{�G���A�̃O���t�̓N���X�^����2�ł���Ƒ����ɔ��f�ł���B�������}50�̓����G���A�̗l�ȍL�͈͂ɓ_���U�z���Ă���O���t�̓N���X�^�������߂鎖������ł���ׁA�N���X�^���͂��s���K�v������B
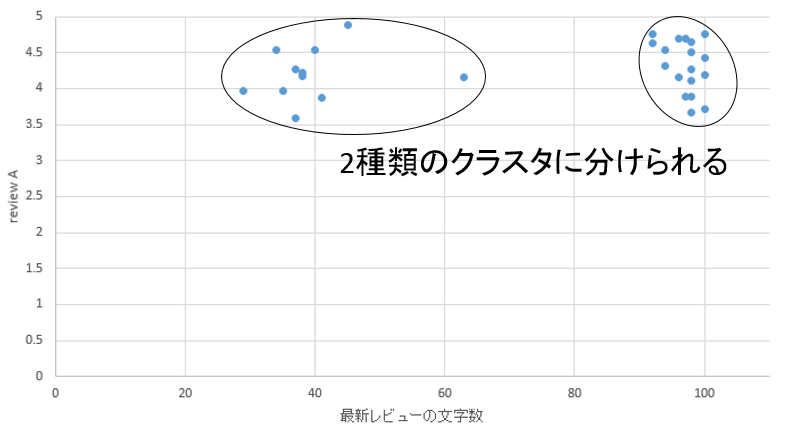
�}49. �N���X�^����������₷���O���t�i�ʕ{�G���A�j
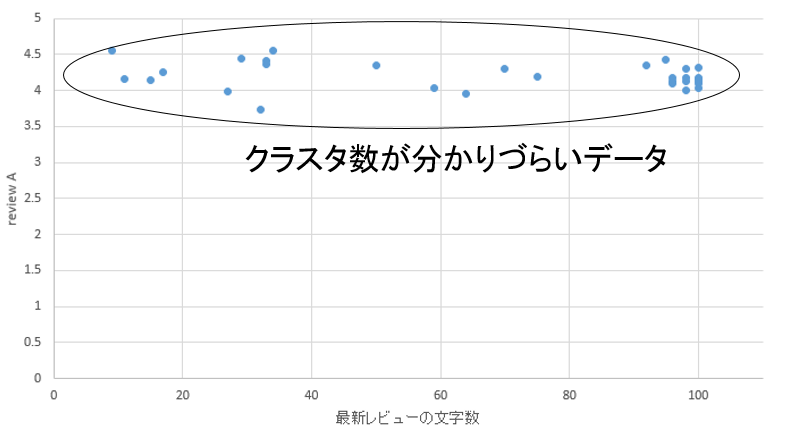
�}50. �N���X�^��������Â炢�O���t�i�����G���A�j
�@Rapidminer��p�����N���X�^���͂̎菇�͈ȉ��̒ʂ�ł���BProcess��Operator�̔z�u�Ɣz���͐}51�̒ʂ�ł���B
�����O�����Ƃ��āAImport Data�ŕ��͂������G���A�̃f�[�^��S��Rapidminer�ɓǂݍ���ł���
�@���͂���G���A�̃f�[�^��ǂݍ��ށB
�A���͂���ϐ��i�����review A�ƍŐV���r���[�̕������j��I������B
�@Parameters��attribute filter type��subset�Ɏw�肵�ASelect Attributes�ŕ��͂���ϐ���I������B
�B�I�������ϐ��̃f�[�^�𐳋K������B
�@Parameters��attribute filter type��subset�Ɏw�肵�ASelect Attributes�ŇA�őI�������ϐ����w�肷��B
�C�听�����͂��s���B
�@Parameters��dimensionality reduction��none�Ɏw�肷��B
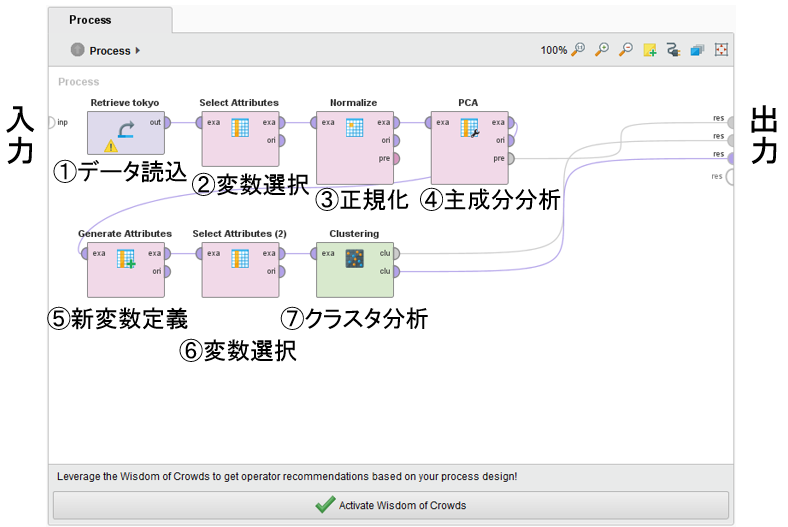
�}51. Rapidminer�ł̃N���X�^�����O�̗l�q
�D�听�����͂̌��ʂ�V���ȕϐ��Ƃ��Ē�`����B
�@Parameters��Edit List��attribute name����`����B�ip1��p2�Ƃ���j
�@������p1��p2�̌v�Z������͂���B���ꂼ��̓d��̃A�C�R�����N���b�N����p1��pc_1�Ap2�̌v�Z����pc_2�Ɏw�肷��B
��pc_1��pc_2�Ƃ́A�听�����͂̌��ʐ������ꂽ�V���ȓ�̕ϐ�PC1��PC2��\���Ă���B�i�}52�j

�}52. �听�����͂̌���
�@filter type��subset�Ɏw�肵�ASelect Attributes�ŕ��͂���ϐ���I������B
�Ep1��p2�͂���ׁA�ϐ��I������B
�@Parameters��attribute filter type��subset�Ɏw�肵�ASelect Attributes��p1��p2��I������B
�Fk-means�@��p���ăN���X�^���͂��s���B
�@�N���X�^�������߂�ɂ́A�@�`�F�̎菇�ȍ~�Ɉȉ��̍�Ƃ��s���B
1.�@�F��Clustering�ik-means�j��Parameters��k��2�Ɏw�肷��B�i�}53�j
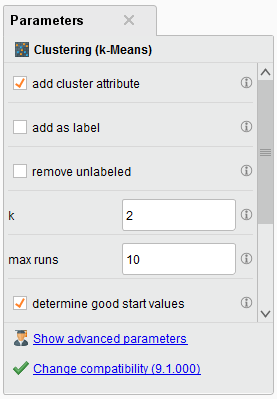
�}53. Clustering�ik-means�j��Parameters
2.�@Process�����s���āA���ʂ�\��������B
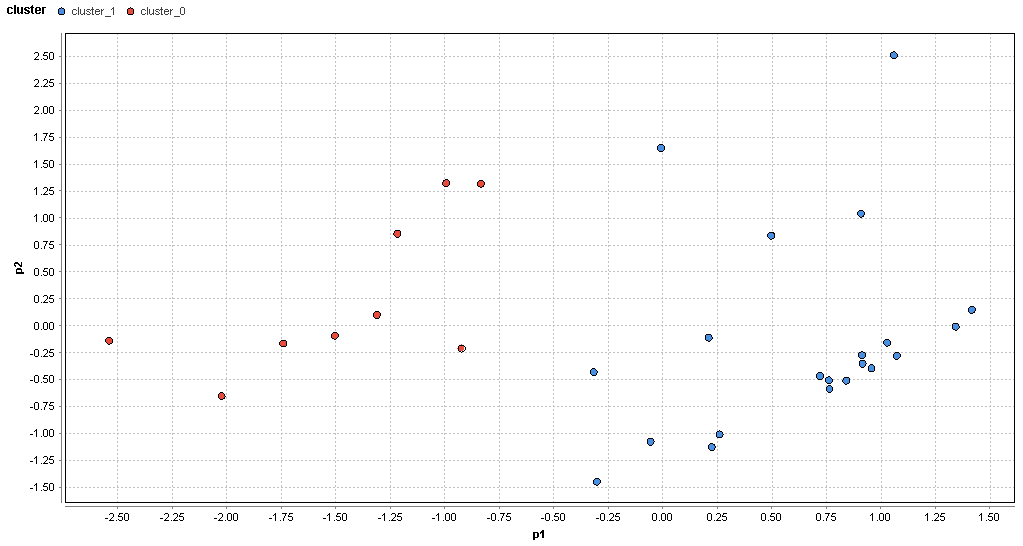
�}54. �����G���A�̃N���X�^���͂̌��ʁik=2�j
�@�}54�̒ʂ�O���t�̒����Ńf�[�^������Ă���A����ɃN���X�^���͂��s���Ă��鎖���m�F�ł���B�Ȃ��A����ɃN���X�^���͂��ł��Ă��邩�͖��炩�ɋߐڂ����f�[�^���قȂ�N���X�^�ɕ��ނ���Ă�����������Ă��邩�ǂ����Ŕ��f����B
3.�@Clustering�ik-means�j��Parameters��k��3�Ɏw�肵�A�Ă�Process�����s���Č��ʂ�\��������B
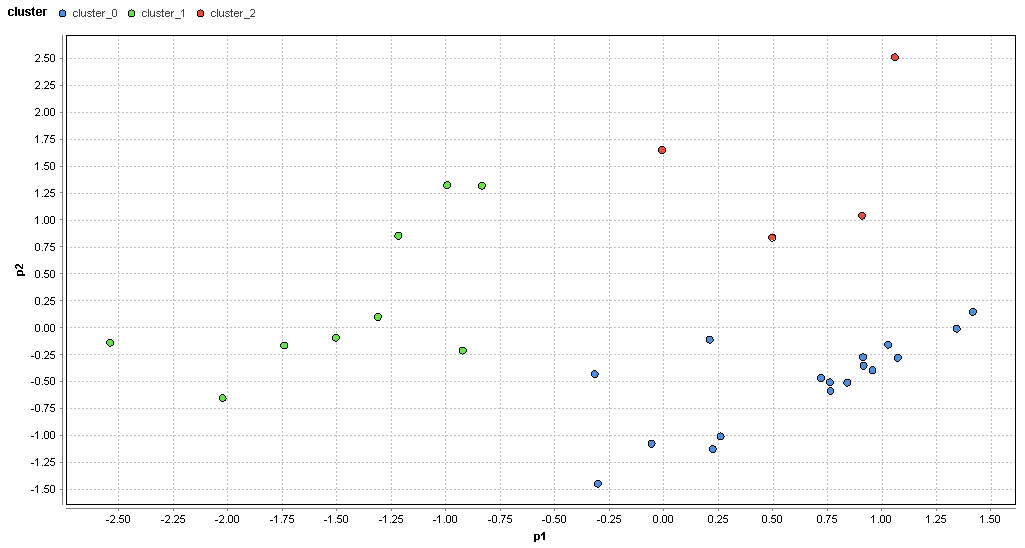
�}55. �����G���A�̃N���X�^���͂̌��ʁik=3�j
�@k=3�ɐݒ肷��ƁAk=2�̎��ɂ͈�̃N���X�^�������E���̃f�[�^����̃N���X�^�ɕ������Ă��鎖���}55���番����B���炩�ɋߐڂ����f�[�^���قȂ�N���X�^�ɕ��ނ���Ă���l�ȏ͔������Ă��Ȃ��̂ł���������Ȃ��N���X�^���͂ł��Ă���ƌ�����B
4.�@Clustering�ik-means�j��Parameters��k��4�Ɏw�肵�A�Ă�Process�����s���Č��ʂ�\��������B
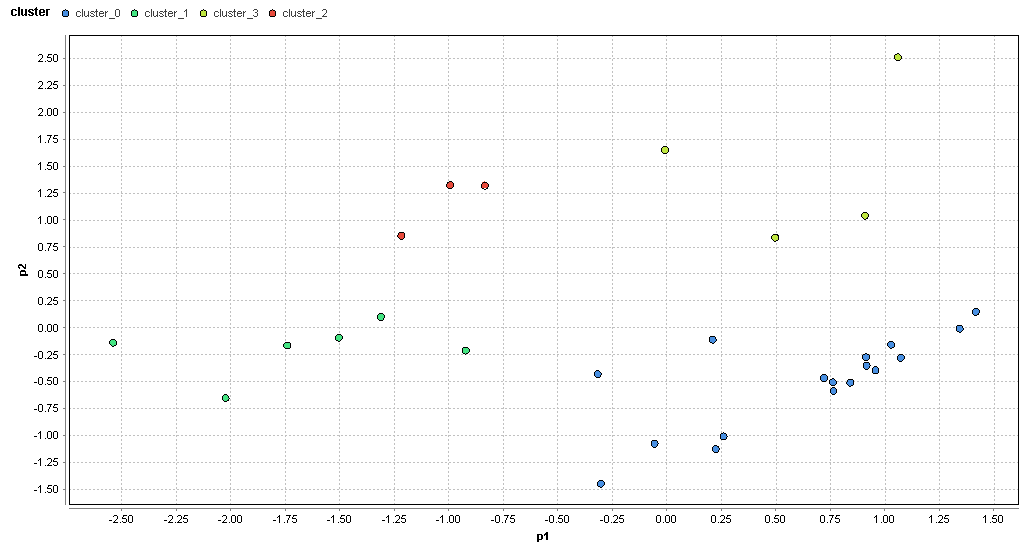
�}56. �����G���A�̃N���X�^���͂̌��ʁik=4�j
�@�}56������ƃO���t�����̃f�[�^����̃N���X�^�ɕ������Ă��鎖��������B����ɃN���X�^���͂ł��Ă��邩�̔��f�͕ۗ�����B
5.�@Clustering�ik-means�j��Parameters��k��5�Ɏw�肵�A�Ă�Process�����s���Č��ʂ�\��������B
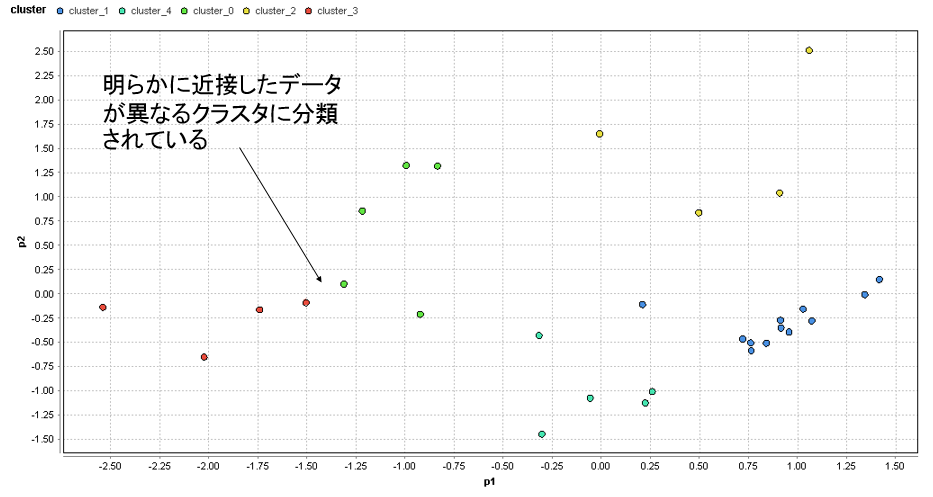
�}57. �����G���A�̃N���X�^���͂̌��ʁik=5�j
�@�}57��k=5�œ����G���A�̃N���X�^���͂��s�������ʂł��邪�A���Ŏw���������t�߂Ŗ��炩�ɋߐڂ����f�[�^���قȂ�N���X�^�ɕ��ނ���Ă��鎖���m�F�ł���B����͐���ɃN���X�^���͂��ł��Ă���Ƃ͌������A���̂��Ƃ��瓌���G���A�̃N���X�^����5�ł͂Ȃ��ƌ�����B
6.�@k=3��k=4�̃N���X�^���͂̌��ʂ����Ăǂ��炪�K�����f����B
�@�N���X�^�������߂�ɂ́A����ɃN���X�^���͂��ł���k�̒l�̍ő�l�����߂鎖���K�v�ł���B�����_�Ő���ɃN���X�^���͂��ł��Ă���Ƃ����k�̒l�̍ő�l��3�ł���B���f��ۗ��ɂ���k=4�̃O���t������ɃN���X�^���͂ł��Ă���Ɣ��f�ł���Γ����G���A�̃N���X�^����4�Ƃ������ɂȂ�B����k=4�̃O���t������ɃN���X�^���͂ł��Ă��Ȃ��ꍇ�͓����G���A�̃N���X�^����3�ł���Ƃ������ʂɂȂ�Bk=4�̃O���t�i�}56�j�ł͍����̃f�[�^�Q���ɕ����Ă��邪�A����͎��R�ȕ������ł͂Ȃ��Ɣ��f���Ak=4�̃N���X�^���͂̌��ʂ͕s�K�ł���ƌ��_�Â���B
�@����āA�����G���A�̃N���X�^����3�ł���B���̗l��k-means�@��p����k�̒l��2����1�Âグ�Ă����A����ɃN���X�^���͂��s����k�̍ő�l�����߂鎖�Ŋe�G���A�̃N���X�^�������߂�B
�@�N���X�^���͂��s�����n��Ƃ��̌��ʂ�\1�Ɏ����B�Ȃ��A�ȍ~�͊e�n����ď̂���ۂɁ����G���A�ƌď̂��������ƌď̂���B
| k=2�̃G���A | ����A�H�c�A���l�A�b�{�A���s�A���A���R�A�����A���ցA�ʕ{�A�{��A�ߔe |
| k=3�̃G���A | �D�y�A�X�A�R�`�A��z�A���ˁA���A��{�A�����A�z�K�A�l���A�l���s�A���É��A�_�ˁA�q�~�A���m�A���� |
| k=4�̃G���A | ���q |
| k=5�̃G���A | �V�� |
�@�\1������ƁA���������s�ł�������k=3�Ȃ̂ɑ��āA�V���̃N���X�^����5�ƈُ�ɑ�������������B�����͎�ɓ����w���ӂ̃G���A�ł���A�V���͐V���w���ӂ̃G���A�ł��鎖�����̃G���A�͗��n�I�ɂ͂��܂荷�������B�����N���X�^����3��5�ő傫���������鎖���瓌���G���A�̋q�w�ƐV���G���A�̋q�w�ɂ͉��炩�̈Ⴂ������ƍl������B
�@k=2�̃G���A������ƁA�ό��n�Ƃ��ėL���ȋ��s���܂܂�Ă���B���ɂ����l�Ƒ��������Γ���E�b�{�E�ʕ{�E�{��E�ߔe�Ȃǂ̊ό��n�Ƃ��Ă̈�ۂ������G���A���ڗ��B�����k=3�̃G���A�͎D�y�E�����E���É��E�����Ȃǂ̐l���������r�W�l�X�q���������݂���ƍl������G���A�����ނ���Ă���B
�@����ăN���X�^���͂̌��ʁA�ȉ���3�̉��������Ă���B
1.�@�����s���{�����̋ߐڂ����G���A�ł��N���X�^���ɍ����o��ꍇ������B
2.�@�N���X�^�������Ȃ��G���A�́A�ό��n�ł���X��������B
3.�@�r�W�l�X���[�U�[���������݂���G���A�̓N���X�^���������Ȃ�X��������B
�@����̎����ŃN���X�^���͂��s�����n��̃N���X�^�̗l�q���ȉ��Ɏ����B
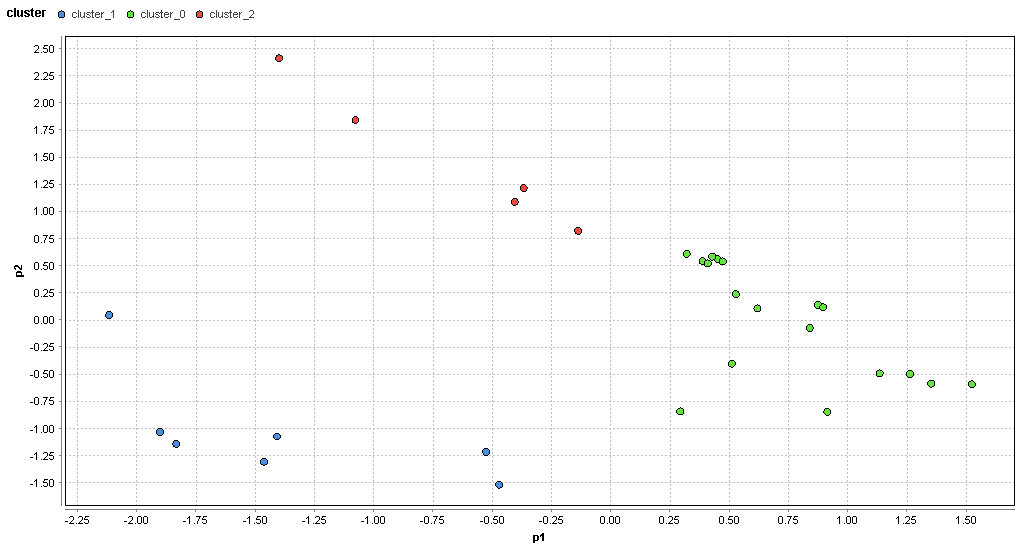
�}58. �D�y�G���A�̃N���X�^�ik=3�j
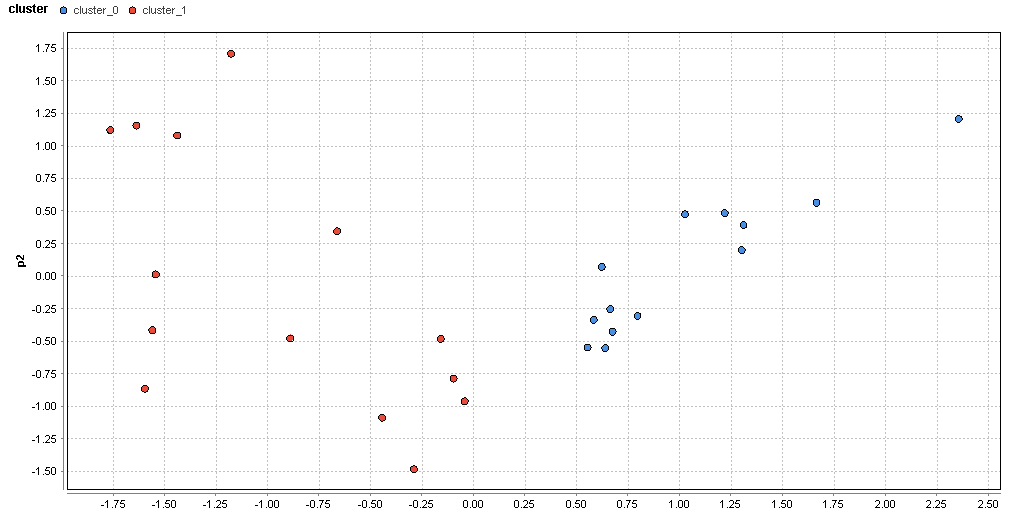
�}59. ����G���A�̃N���X�^�ik=2�j
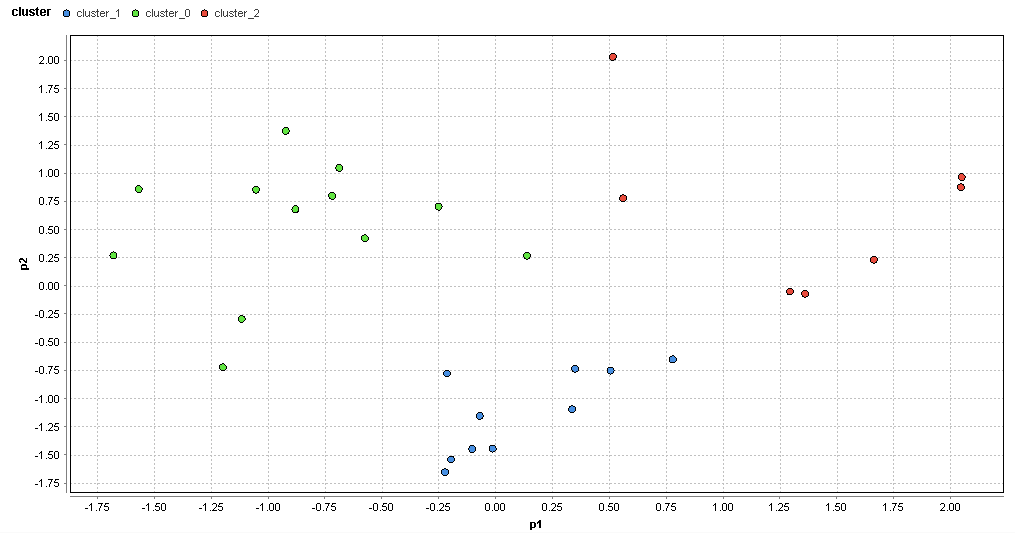
�}60. �X�G���A�̃N���X�^�ik=3�j
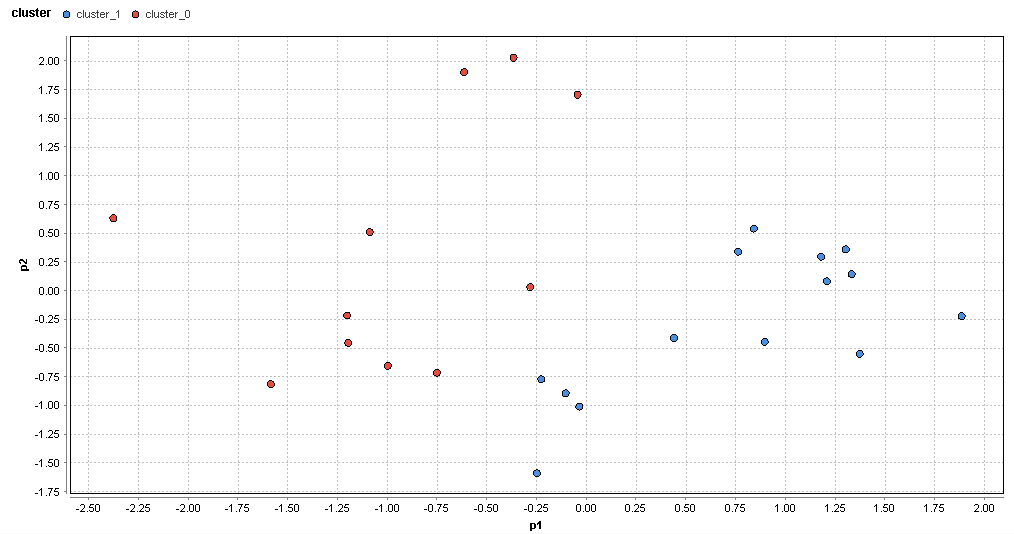
�}61. �H�c�G���A�̃N���X�^�ik=2�j
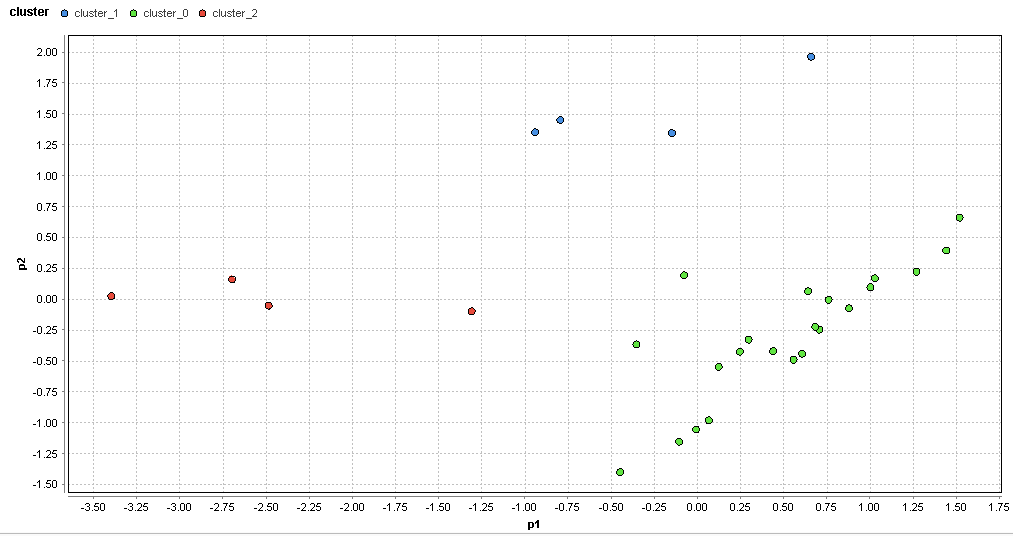
�}62. �R�`�G���A�̃N���X�^�ik=3�j
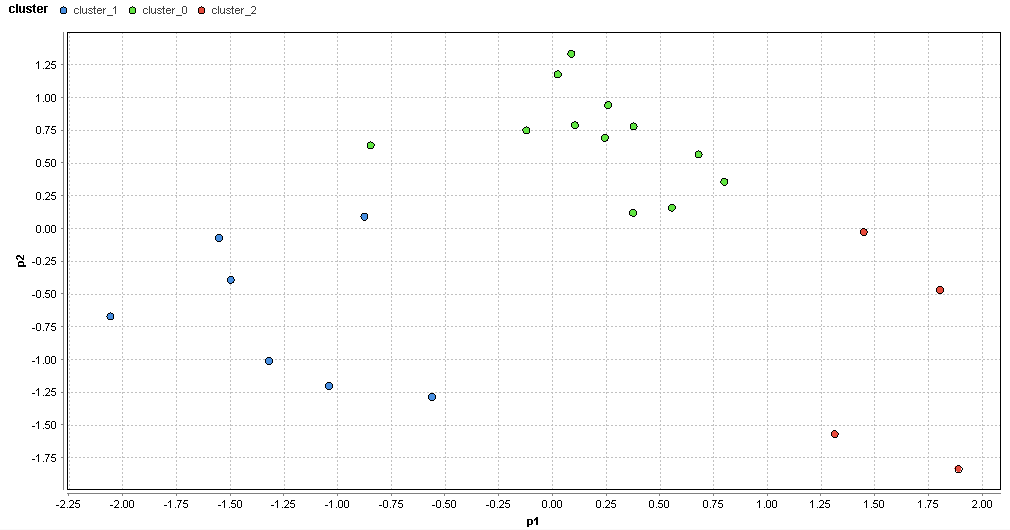
�}63. ��z�G���A�̃N���X�^�ik=3�j
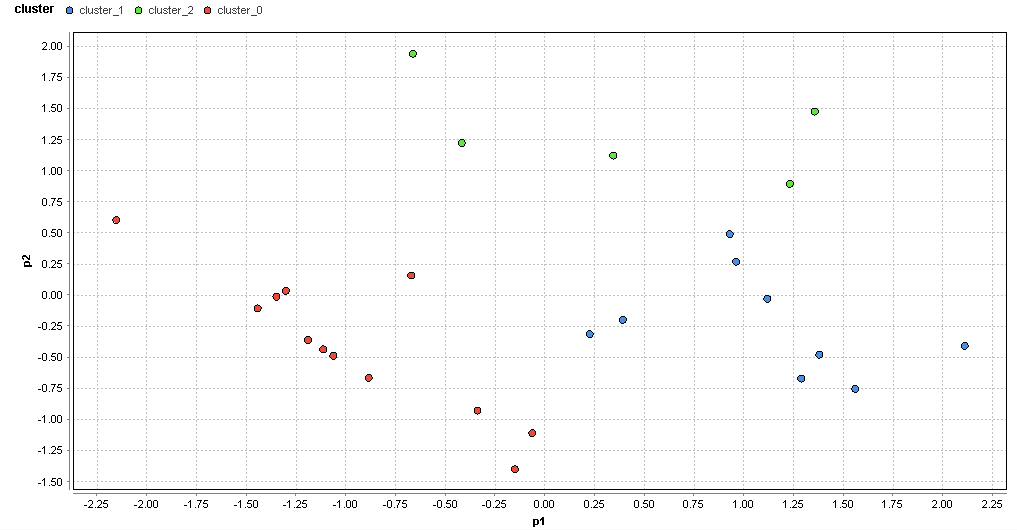
�}64. ���G���A�̃N���X�^�ik=3�j
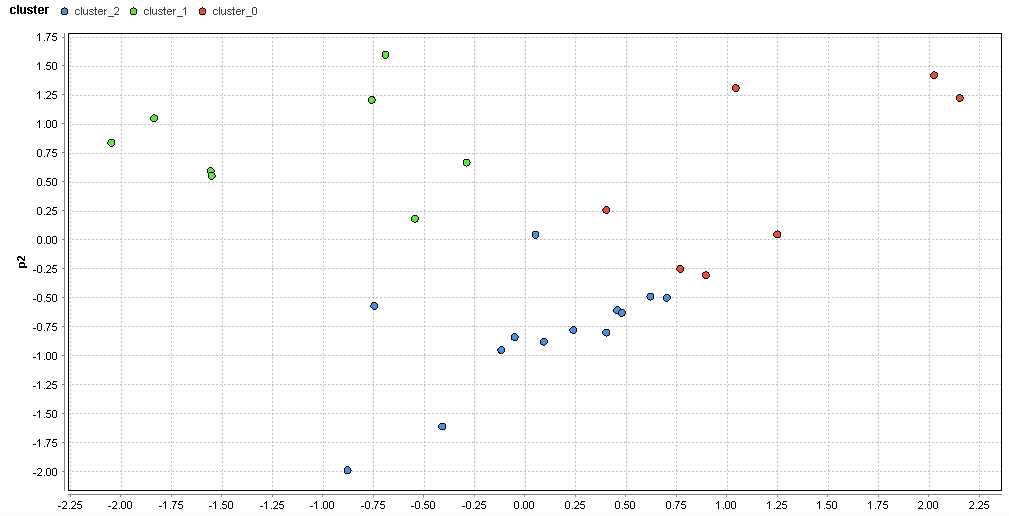
�}65. ���˃G���A�̃N���X�^�ik=3�j
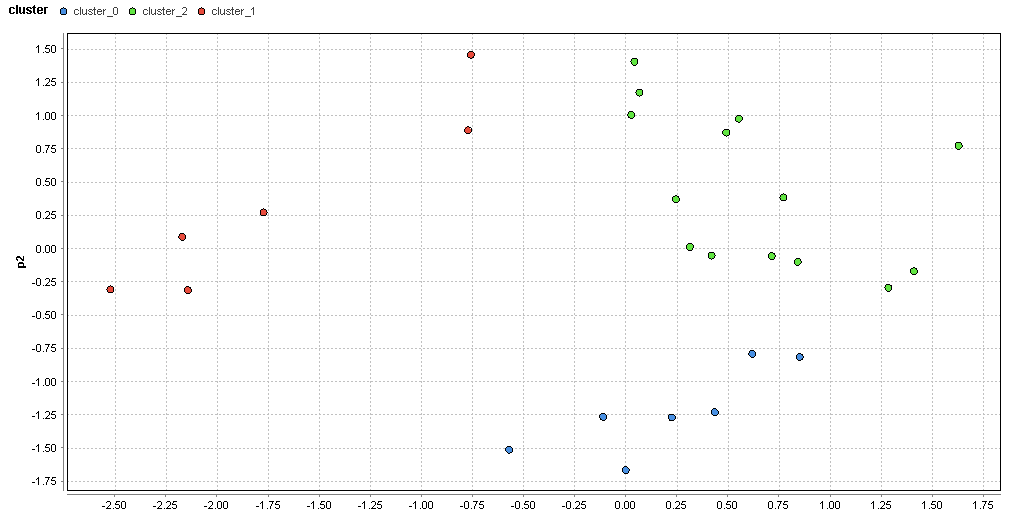
�}66. ��{�G���A�̃N���X�^�ik=3�j
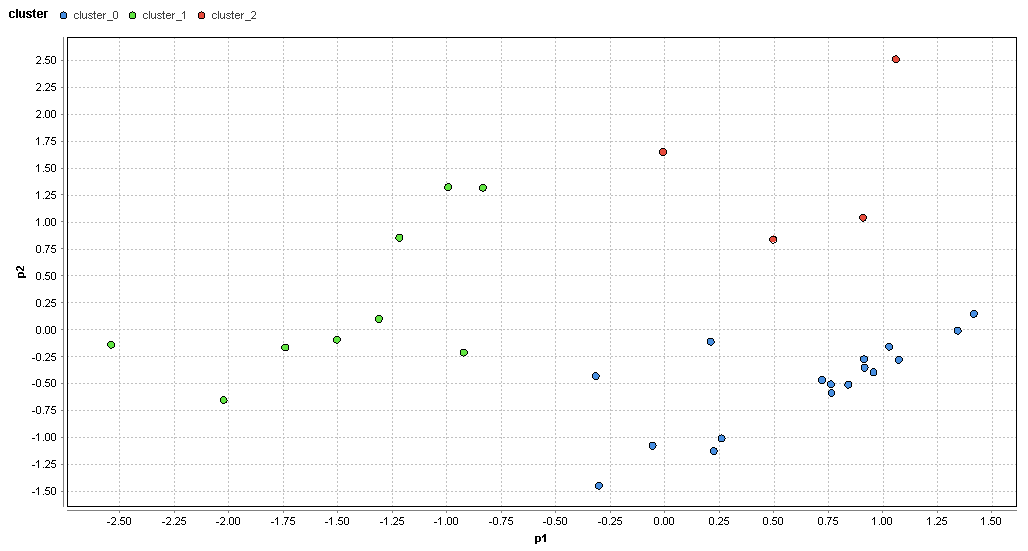
�}67. �����G���A�̃N���X�^�ik=3�j
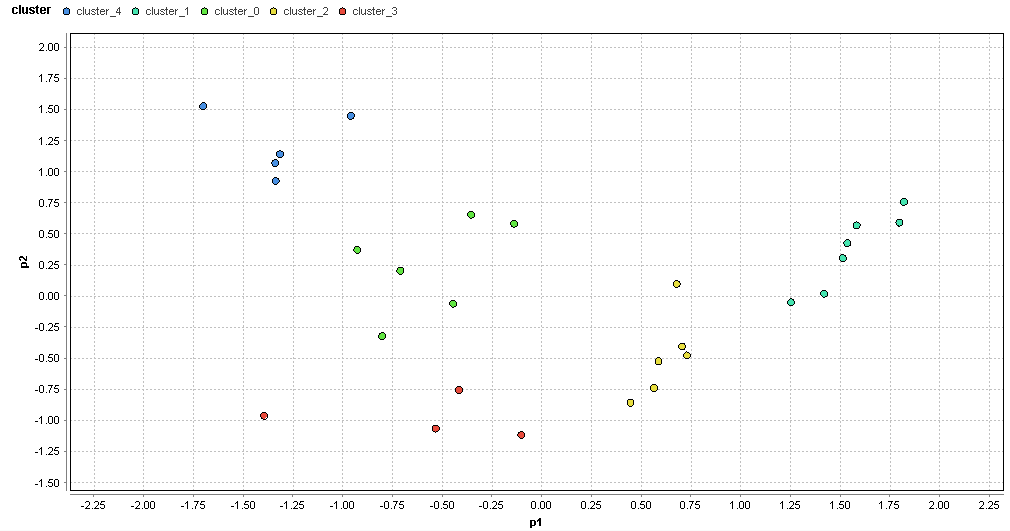
�}68. �V���G���A�̃N���X�^�ik=5�j
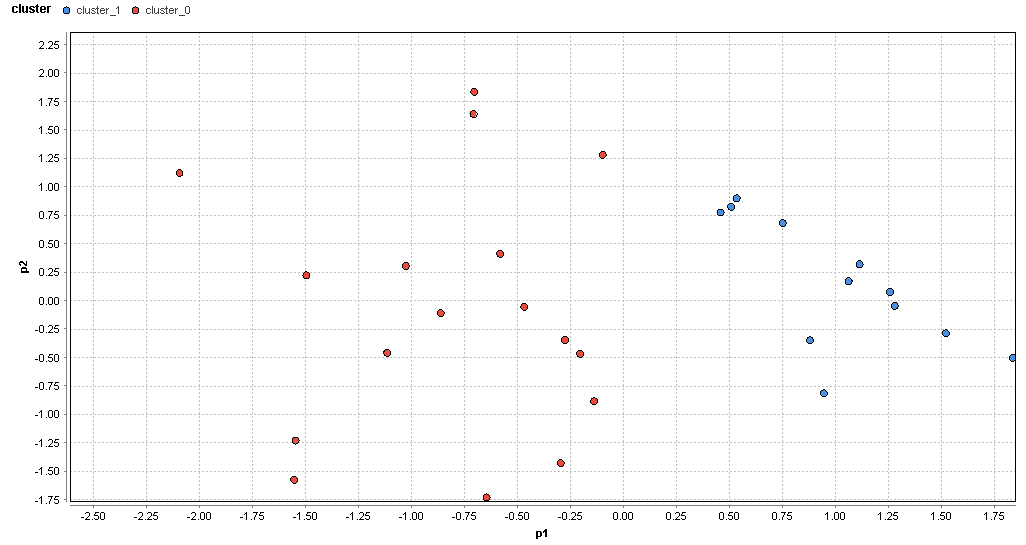
�}69. ���l�G���A�̃N���X�^�ik=2�j
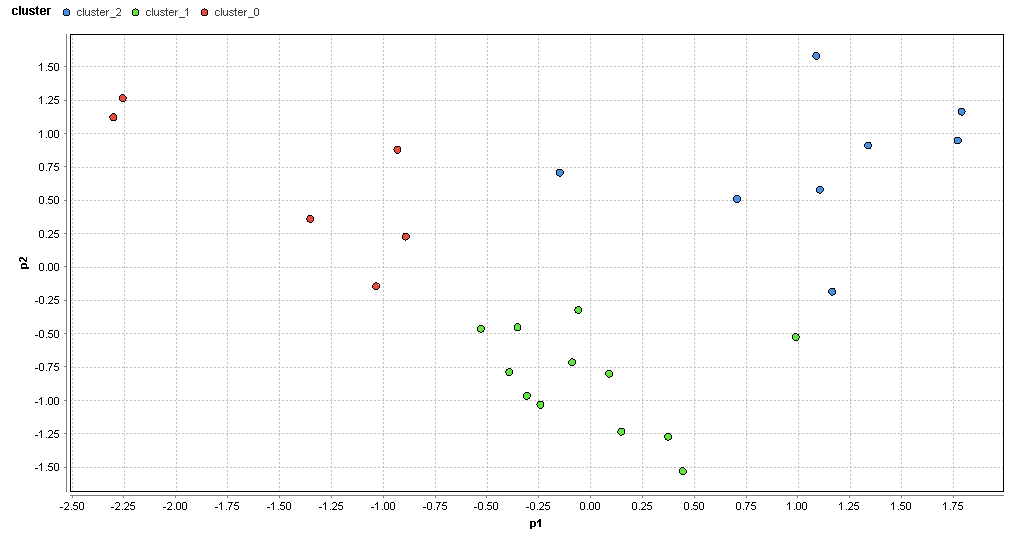
�}70. �z�K�G���A�̃N���X�^�ik=3�j
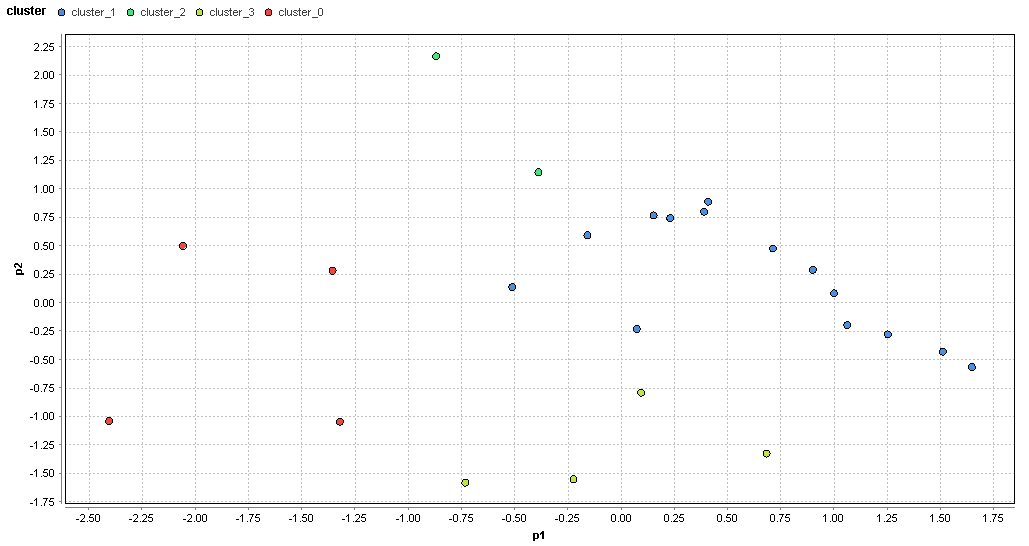
�}71. ���q�G���A�̃N���X�^�ik=4�j
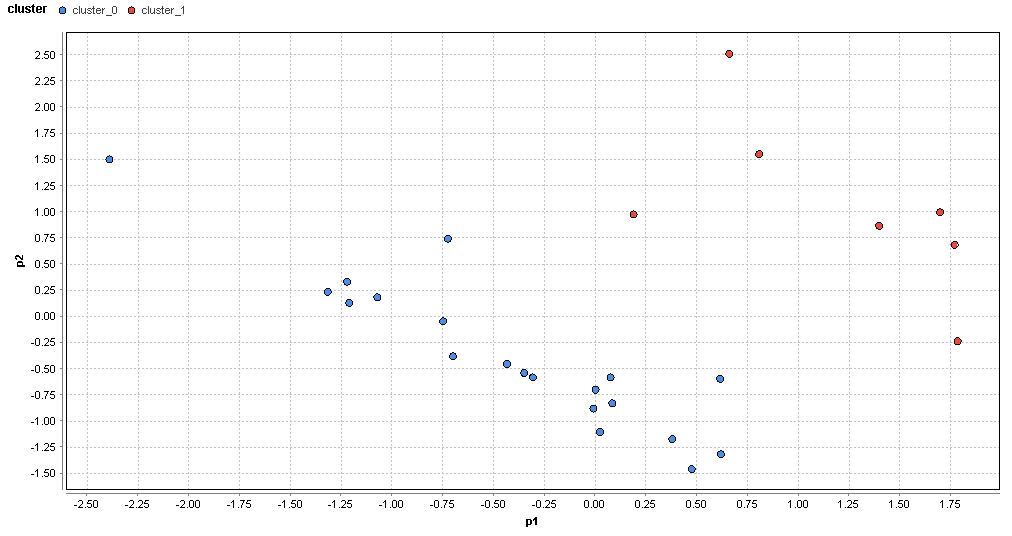
�}72. �b�{�G���A�̃N���X�^�ik=2�j
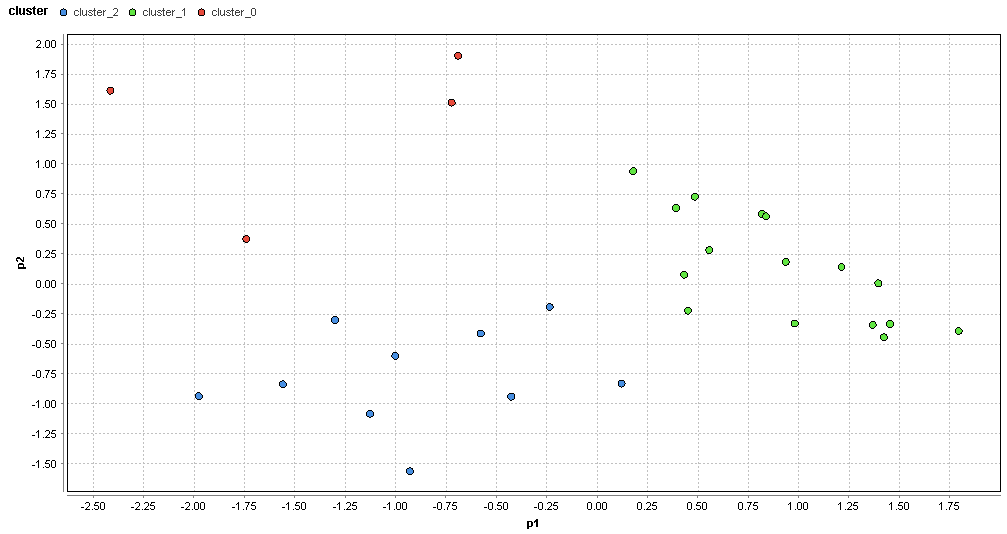
�}73. �l���G���A�̃N���X�^�ik=3�j
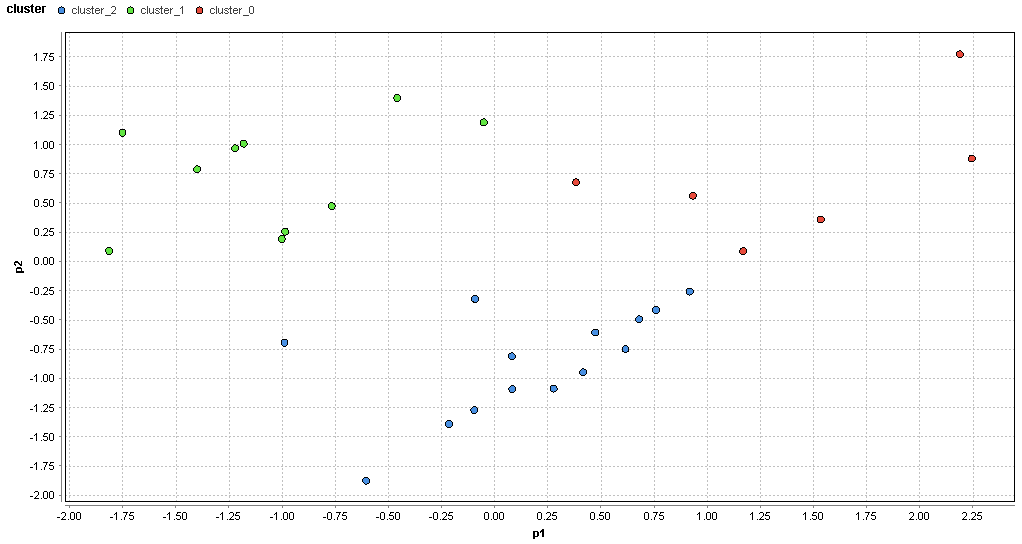
�}74. ���É��G���A�̃N���X�^�ik=3�j
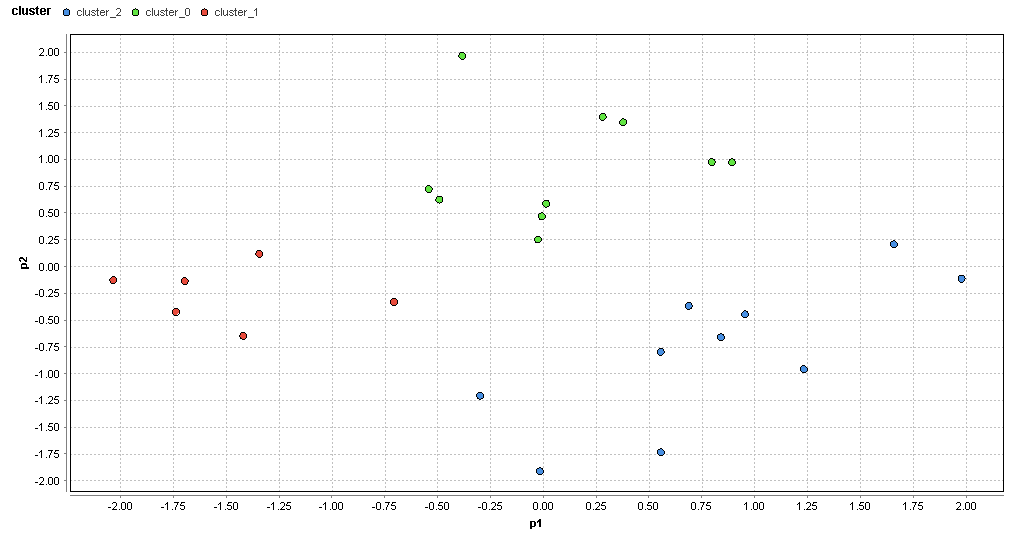
�}75. �l���s�G���A�̃N���X�^�ik=3�j
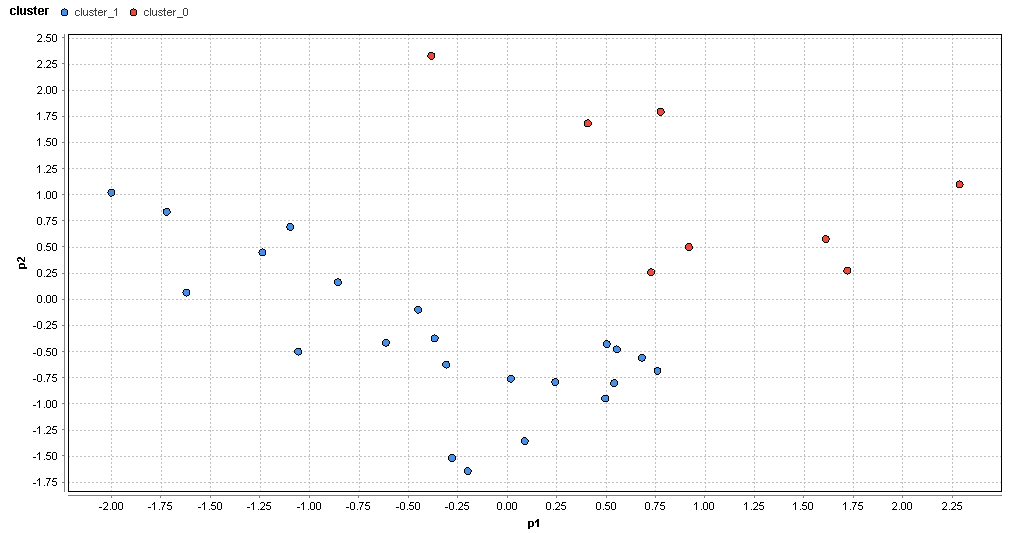
�}76. ���s�G���A�̃N���X�^�ik=2�j
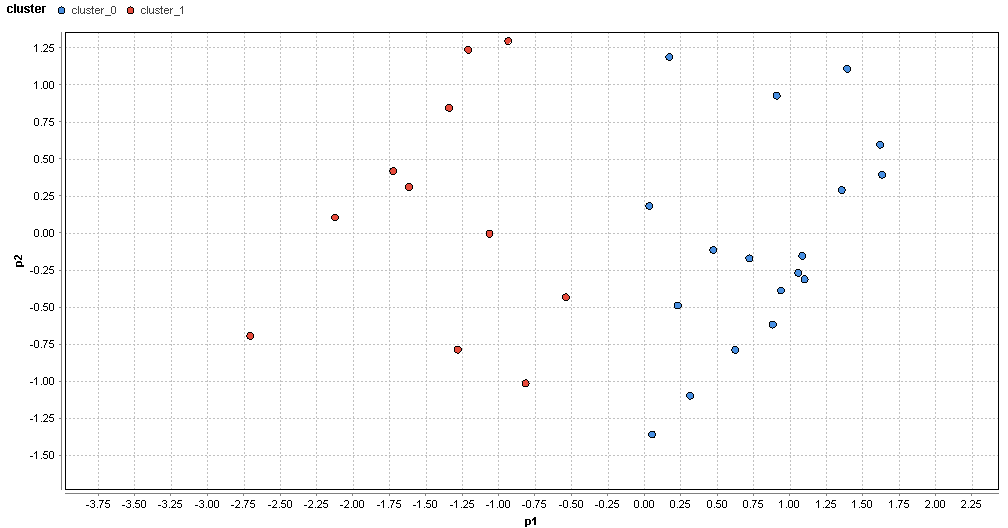
�}77. ���G���A�̃N���X�^�ik=2�j
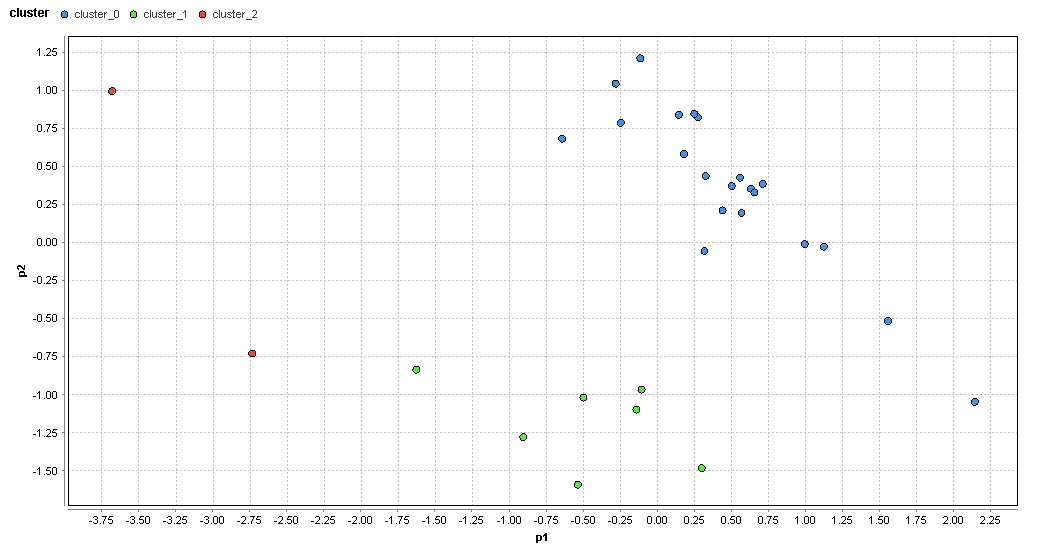
�}78. �_�˃G���A�̃N���X�^�ik=3�j
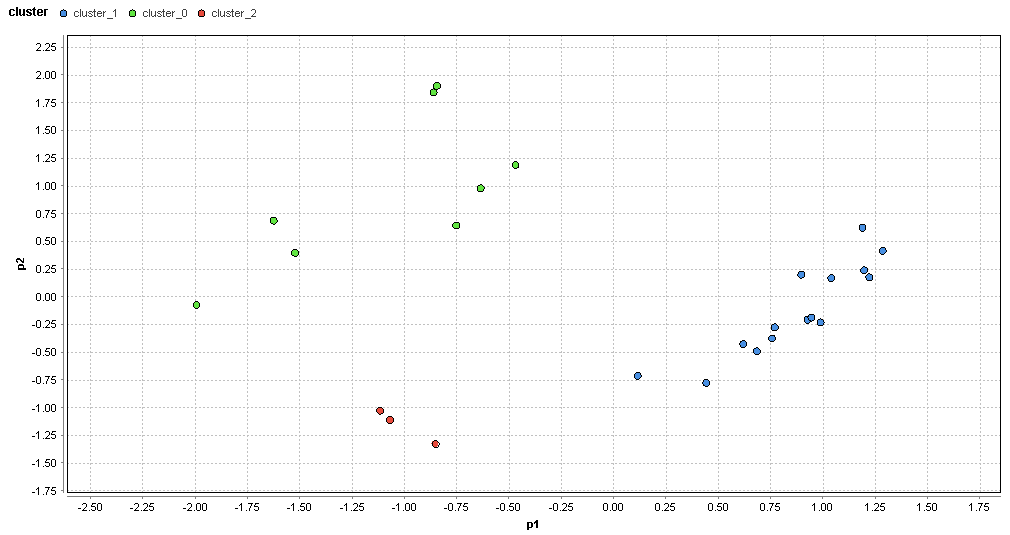
�}79. �q�~�G���A�̃N���X�^�ik=3�j
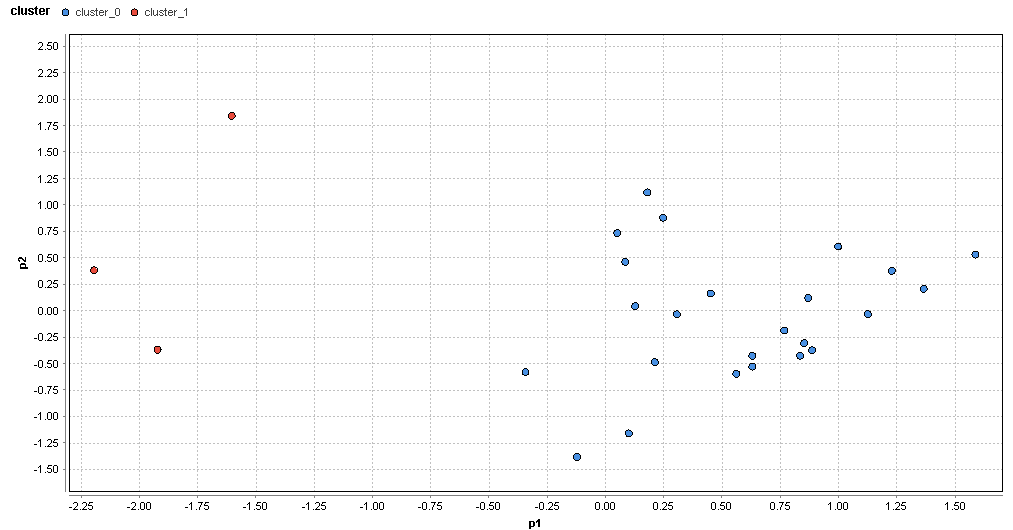
�}80. ���R�G���A�̃N���X�^�ik=2�j
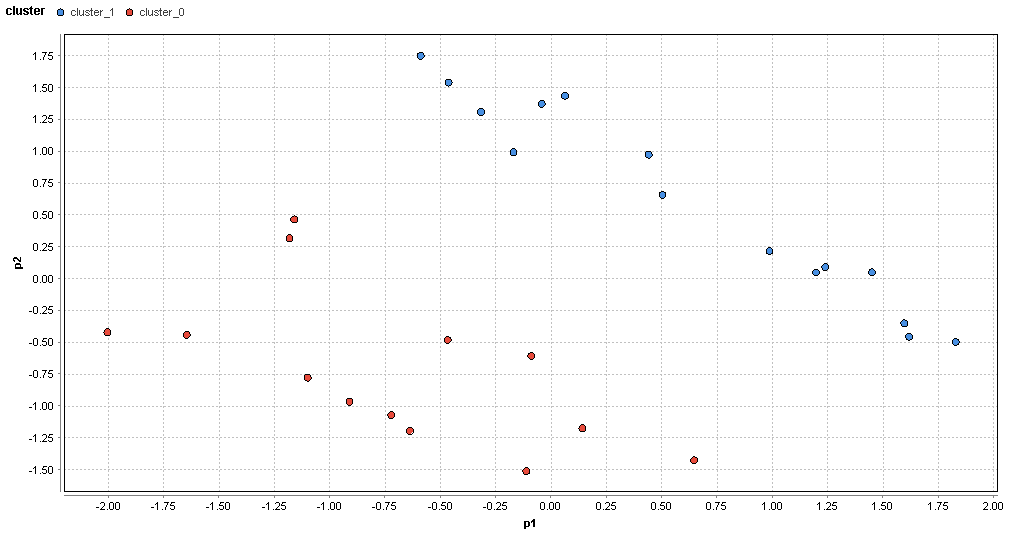
�}81. �����G���A�̃N���X�^�ik=2�j
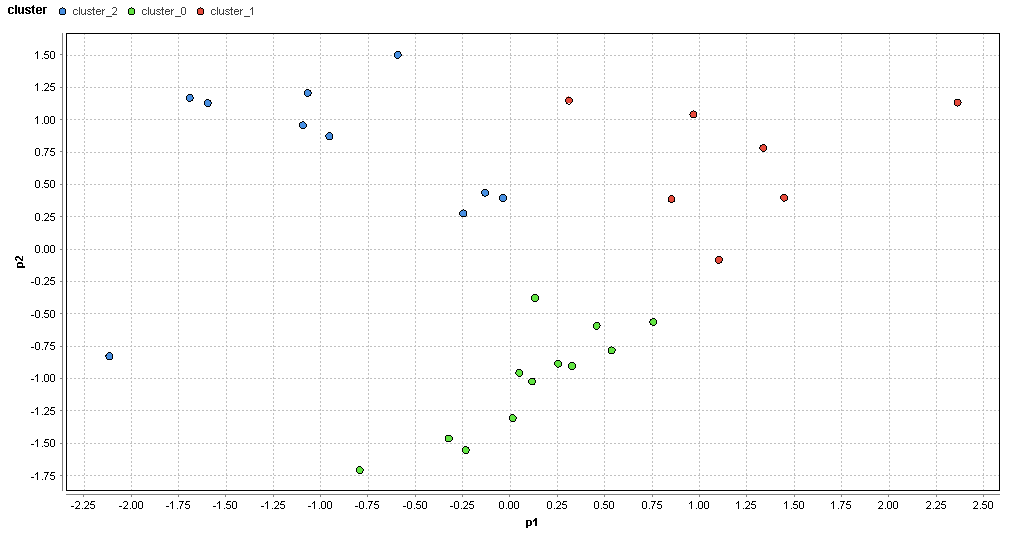
�}82. ���m�G���A�̃N���X�^�ik=3�j
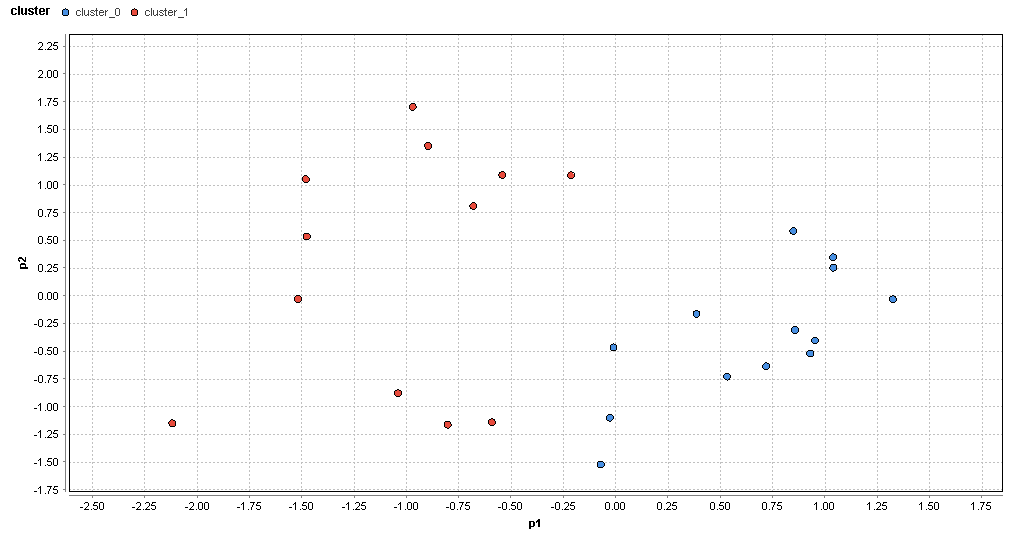
�}83. ���փG���A�̃N���X�^�ik=2�j
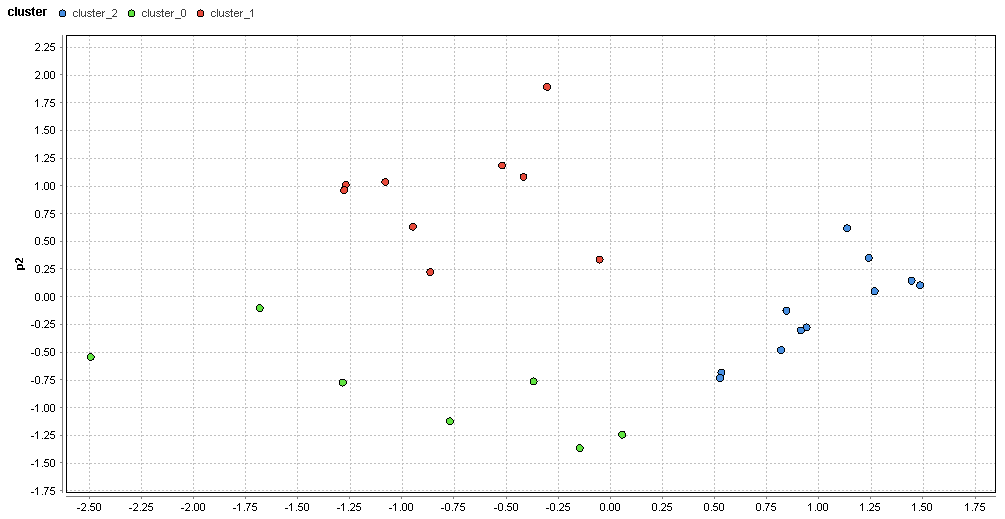
�}84. �����G���A�̃N���X�^�ik=3�j
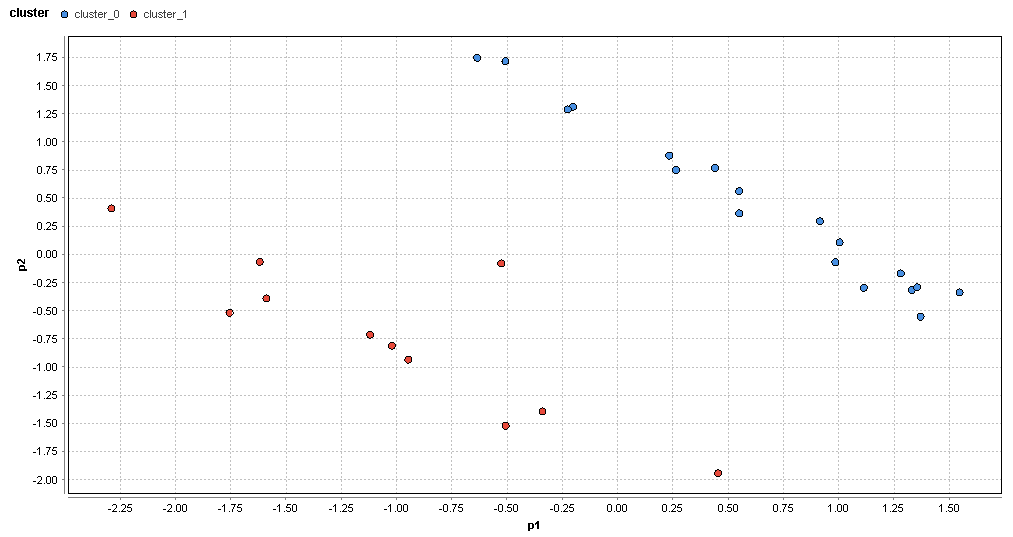
�}85. �ʕ{�G���A�̃N���X�^�ik=2�j
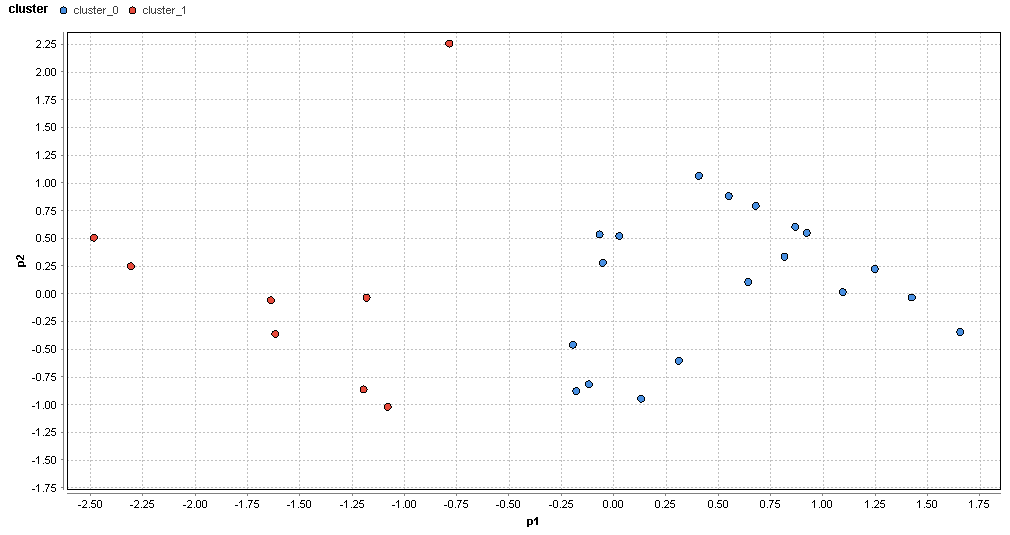
�}86. �{��G���A�̃N���X�^�ik=2�j
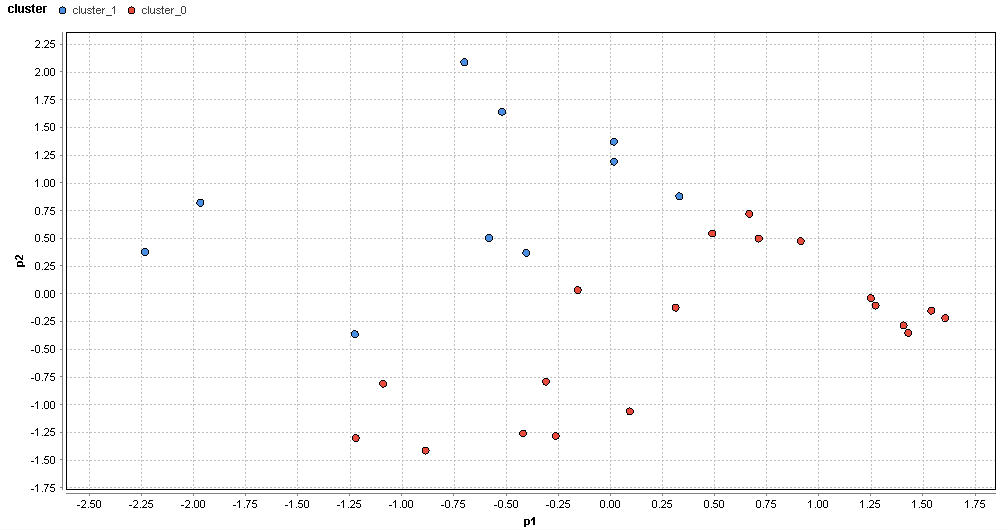
�}87. �ߔe�G���A�̃N���X�^�ik=2�j
�@�{�����ł́A�y�V�g���x���{����API��p���ē��{�̊e�n��̏h���{�݂̑����]���ƍŐV���r���[�̕������̃f�[�^�����W���ARapidminer��p���ăN���X�^���͂��s�����Œn������͂����B
�@�N���X�^���͂̌��ʁA�N���X�^���Ŋe�n��ɂ�����Ⴂ�������A����ɂ�胆�[�U�[�̓����������鎖�������Ă����B�{�����ł̓��[�U�[���r���[�̕�������p�������͂����s���Ă��Ȃ����A���r���[�̓��e�����͂��鎖�Ŋe�n��ɂ����郆�[�U�[���z���m�F�ł���\��������B�e�n��ɂ͂ǂ��������q�w������̂������A�{�����œ���ꂽ�N���X�^���̃f�[�^�ƏƂ炵���킹�鎖�ŋq�w�ƃN���X�^���̊W������薾�m�ɂ��邱�Ƃ�����̉ۑ�ł���B
[1] �y�V�g���x��
URL�Fhttps://travel.rakuten.co.jp/
[2] Rakuten Developers
URL�Fhttps://webservice.rakuten.co.jp/
[3] Rapidminer
URL�Fhttps://www.rapidminer.jp/