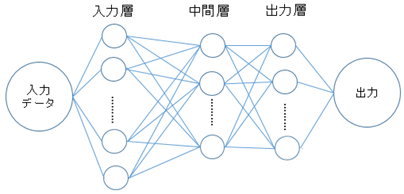
- 図1 ニューラルネットワークの概略図
高層ビルでは各階の構造が似てしまうので,自分が今何階にいるかは重要な情報である.近年,大学などでは各フロアにそれぞれ別組織が異なる運用をするようなビルの運用がされることがある.大学に通っている学生ならばその大学の構造については次第に慣れていくと考えられるが,オープンキャンパスや学園祭などで初めて大学に足を踏み入れる受験生やその保護者といった学外からの来場者はそうではない.構内の各フロアでは目印になるものも無いために迷い,目当ての部屋に行けなかったなどといったことがあると悪印象を持たれてしまうことも考えられる.そこで,多くの人が持っている携帯電話やスマートフォンを用いて,手軽に自分が今建物の何階にいるのかを判別できるシステムを作成し,学外からの来場者への手助けなどに活用することを考える.判別するためのシステムとしてはニューラルネットワークによる学習済みモデルによる判別を使用する.近年,ニューラルネットワークによる画像分類は著しい進歩を遂げており,人間やその他の動物の顔分類で多大な成果を挙げているため,法則性の無い建物内の画像に対しても,一定の成果を上げられるのではないかと考えた.
本研究では,東京電機大学 1号館の14階建てのビルの構内の画像をニューラルネットワークを用いて学習したモデルを作成し,そのモデルを用いた階数の識別を行う.
本論文の構成は以下のとおりである.
2章では本論文で用いる用語や技術についての説明,その定義について述べる.
3章では行った実験の手法と結果について述べる.
4章では実験全体の考察について述べる.
5章では本研究を行うにあたって助力を頂いた方々への謝辞を述べる.
6賞では本論文を執筆するにあたり参考にした参考文献について述べる.
付録では本実験に使用したプログラムのソースコードを記載する.
上の図1において,左の層から入力層,中間層,出力層と呼ばれる.これら3種類の層はそれぞれユニット間で結合しており,それぞれのユニットは重みやバイアスといった,各入力に対応したパラメータを持っている.学習を行うとその結果から出力層からの出力と実際の正解ラベルデータとの誤差によって各層のユニットが持つ重みやバイアスが更新され,よりモデルの精度が高くなる.ニューラルネットワークを用いた機械学習では,学習データを用いた学習を複数回行うことでモデルの精度を上げ,学習に使用していない未知の入力データに対しても正しい出力を行えるようにすることを目標とする.
今回の研究で使用するニューラルネットワークでは入力層の次元数は9248次元,中間層の次元数は2000次元で構築している.また,出力層は1階から14階までの識別結果となるので14次元で構成している.
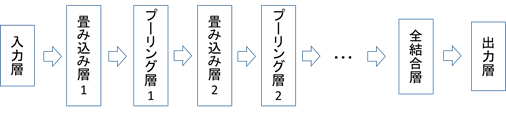
畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)は,上の図2のように入力層から受けとったデータに対し畳み込み層とプーリング層という2種類の層で計算を交互に複数回行い,最終的に計算結果を全結合層で集計し,出力層に出力を渡すニューラルネットワークである.また,今回は多クラス分類を行うため,出力層にはソフトマックス層を使用する.多層の畳み込み層とプーリング層の働きにより,畳み込みニューラルネットワークは特徴抽出,特に画像認識の分野で目覚ましい成果をあげている.本論文で行う実験でも畳み込みニューラルネットワークを使用する.
畳み込み層,プーリング層,ソフトマックス層について説明を記述する.
畳み込み層は畳み込みニューラルネットワークにおいて,入力データに対して畳み込み計算を行うニューロン層である.主にエッジ検出といった特徴抽出の役割を持つ.
畳み込み計算とは入力画像にフィルタを重ね合わせ,フィルタと入力画像の重なり合う画素同士の積を求め,画像全体でその積の和を求める計算である.
畳み込み計算の具体的な手順を示す.
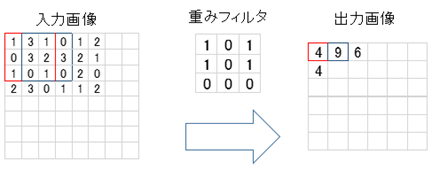
入力画像の赤枠部分に対し,重みフィルタを重ね合わせると
1×1 + 3×0 + 1×1 + 0×1 + 3×0 + 2×1 + 1×0 + 0×0 + 1×0 = 4
となり,入力画像の赤枠部分は出力画像の赤枠部分の4となる. 赤枠部分の計算が終わると今度は重みフィルタを右にずらして青枠部分の計算を行う.青枠部分の計算も終わると,重みフィルタを青枠部分の1段右へずらして計算を行う.右端までの計算が終わると重みフィルタを赤枠部分から1段下の場所へ移動し,また同様の計算を行う.
一連の畳み込み計算が終わると,図3のように,8×8の入力画像が重みフィルタによって特徴抽出された6×6の画像に調整されて出力される.
畳み込み層で用いられる重みフィルタは学習の結果に応じて更新され,識別器の精度が向上する.
プーリング層は畳みこみニューラルネットワークにおいて,入力画像データに対してプーリング処理を行うニューロン層である.畳み込み層での畳み込み計算に用いるフィルタは学習の結果に応じて更新されるが,プーリング層では常に同一のフィルタを用いてプーリング処理を行う.主に入力画像データに対し解像度を下げるともに,局所的な違いに左右されないような普遍的特徴を抽出する役割を持つ.画像認識の分野においては最大プーリングという手法で畳み込み計算を行うことが一般的であり,本研究でも最大プーリングを使用する.
最大プーリングの具体的な手順を次の図4に示す.
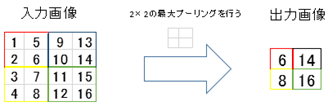
図4では,4×4の画像に対し2×2をプーリング領域とした最大プーリングを行っている.この処理では2×2の範囲内の各要素の中で最大値を選択して出力値とし,2×2の画像へと変換している.最大プーリングの他に,範囲内の各要素の平均値を出力値とする平均プーリングという手法も存在する.
ソフトマックス層は,畳みこみニューラルネットワークにて他クラス分類をする際に出力層として用いられる層である.ソフトマックス層では活性化関数としてソフトマックス関数が使用される.ソフトマックス関数は以下の式で表される.
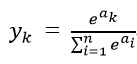
このときy_kは0から1の値を取り,全ての次元で和を取ると1になる.つまり各ラベルのスコアを各ラベルの確率へと変換でき,y_kは入力データがクラスkに属する確率となる.これは他クラス分類をする際には非常に有用であり,本実験でも出力層として使用している.
ReLU関数は,ニューラルネットワークで用いられる活性化関数の一つである.数式で表すと以下の式となる.
f(x) = max(0,x)
0未満の出力値を全て0にする関数であり,非常に簡単かつ単純で計算量が少ないため,シグモイド関数やステップ関数といった他の活性化関数よりも早く学習を行える. 本研究でも活性化関数として使用している.
Chainerは,Preferred Networksが開発を進めている,深層学習用のフレームワークである.ニューラルネットワークをPythonで柔軟に記述し,学習させることができる.また,CUDAをサポートしており,GPUを利用した高速な計算が可能であるほか,その柔軟さゆえに畳み込みニューラルネットワークなどの様々なニューラルネットワークをPythonのプログラムとして記述することができる.
ニューラルネットワークにデータを読み込ませる際には,そのニューラルネットワークが効率よく学習を行えるように,そして学習に十分な量のデータを用意するために予めデータセットに処理を加える必要がある.この処理のことを前処理と呼ぶ.今回の実験で読み込ませるデータセットは画像であるためPythonの画像ライブラリであるOpenCVを用いて処理を行った.今回の実験で行った処理を以下に記す.
元画像の画像サイズを変更する.ニューラルネットワークは入力数の変化に柔軟に対応できないため,使用するニューラルネットワークに適した画像サイズに変更する必要がある.
元画像を単色化する.カラー画像に比べると格段に情報量が減るが,輪郭や濃淡は強調されるため,画像認識においてはより高速な処理を行うことが出来るようになる.
グレースケール化された画像に対し,指定した閾値を基準に,元画像を白と黒の二色に分ける処理である.グレースケール化された画像の輪郭が更に協調されるため,輪郭処理などに有用である.
入力された画像データに対し,γ値によって輝度値を変換する非線形濃度処理である.
入力画像の画素値をY,画素値の最大値をY_max,出力画像の画素値をY’,ガンマ値をγとすると,ガンマ補正の式は以下の計算式で表される.
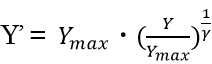
入力された画像データに対し,X,Y方向に指定した座標分だけ位置座標を移動させ、出力を行う.
入力された画像データに対し,指定した角度で回転を行う.
まず初めに,判別に用いるために,判別モデルに読み込ませる画像を用意する.



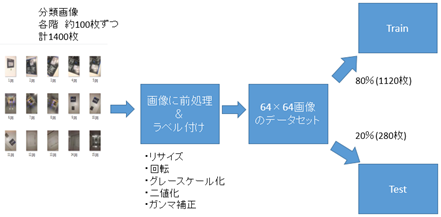
今回の実験で使用する画像として,上の図5,図6,図7のような東京電機大学 東京千住キャンパス 1号館の1階から14階の各階で撮影した画像を使用する.1階当たり100枚,計1400枚の画像を用意した.これらの画像はスマートフォンを用いて撮影した画像であり,1084×1920ピクセルと画像サイズが大きいため,64×64ピクセルの画像へと変換する.その後,画像に1階から14階までの正解ラベルを割り振り,データセットとする.
撮影した画像に下処理とラベル付けを行ってデータセットとし,学習させるまでの流れは以下の図8の通りとなる.
次に畳み込みニューラルネットワークをChainerを用いてPythonのプログラムで実装する.モデルのプログラムとして「modeling2.py」を,学習用のプログラムとして「train.py」を作成した.「train.py」を実行し,学習を行う.出力される1epochごとの学習データとテストデータに対するloss値とaccuracy値をまとめた学習結果は次の表1の通りとなる.また,表1の結果を図9,図10にグラフ化する.
| epoch | train loss | test loss | train accuracy | test accuracy |
|---|---|---|---|---|
| 1 | 3.116 | 2.621 | 0.088 | 0.007 |
| 2 | 2.548 | 2.588 | 0.099 | 0.119 |
| 3 | 2.519 | 2.561 | 0.124 | 0.127 |
| 4 | 2.488 | 2.534 | 0.119 | 0.124 |
| 5 | 2.439 | 2.499 | 0.164 | 0.127 |
| 6 | 2.419 | 2.517 | 0.172 | 0.173 |
| 7 | 2.374 | 2.509 | 0.172 | 0.172 |
| 8 | 2.330 | 2.542 | 0.185 | 0.172 |
| 9 | 2.321 | 2.554 | 0.218 | 0.157 |
| 10 | 2.251 | 2.564 | 0.223 | 0.164 |
| 11 | 2.197 | 2.530 | 0.245 | 0.165 |
| 12 | 2.157 | 2.530 | 0.235 | 0.172 |
| 13 | 2.086 | 2.584 | 0.254 | 0.157 |
| 14 | 2.060 | 2.531 | 0.262 | 0.157 |
| 15 | 1.991 | 2.557 | 0.304 | 0.187 |
| 16 | 1.956 | 2/538 | 0.321 | 0.181 |
| 17 | 1.860 | 2.612 | 0.325 | 0.134 |
| 18 | 1.818 | 2.596 | 0.357 | 0.172 |
| 19 | 1.745 | 2.652 | 0.360 | 0.187 |
| 20 | 1.606 | 2.572 | 0.380 | 0.172 |
| 21 | 1.560 | 2.615 | 0.419 | 0.172 |
| 22 | 1.532 | 2.666 | 0.421 | 0.157 |
| 23 | 1.432 | 2.642 | 0.449 | 0.157 |
| 24 | 1.283 | 2.654 | 0.487 | 0.189 |
| 25 | 1.215 | 2.707 | 0.490 | 0.164 |
| 26 | 1.139 | 2.715 | 0.499 | 0.149 |
| 27 | 1.022 | 2.773 | 0.524 | 0.149 |
| 28 | 0.949 | 2.754 | 0.542 | 0.179 |
| 29 | 0.907 | 2.922 | 0.556 | 0.149 |
| 30 | 0.796 | 2.800 | 0.596 | 0.164 |
| 31 | 0.724 | 3.025 | 0.603 | 0.142 |
| 32 | 0.657 | 2.922 | 0.614 | 0.172 |
| 33 | 0.586 | 2.923 | 0.653 | 0.149 |
| 34 | 0.551 | 3.019 | 0.646 | 0.172 |
| 35 | 0.533 | 3.188 | 0.655 | 0.127 |
| 36 | 0.479 | 3.187 | 0.640 | 0.164 |
| 37 | 0.467 | 3.182 | 0.673 | 0.134 |
| 38 | 0.413 | 3.243 | 0.720 | 0.134 |
| 39 | 0.409 | 3.507 | 0.709 | 0.172 |
| 40 | 0.325 | 3.431 | 0.725 | 0.164 |
| 41 | 0.304 | 3.432 | 0.748 | 0.149 |
| 42 | 0.260 | 3.409 | 0.746 | 0.164 |
| 43 | 0.232 | 3.522 | 0.759 | 0.172 |
| 44 | 0.230 | 3.510 | 0.763 | 0.149 |
| 45 | 0.197 | 3.502 | 0.776 | 0.149 |
| 46 | 0.196 | 3.670 | 0.762 | 0.127 |
| 47 | 0.210 | 3.650 | 0.792 | 0.179 |
| 48 | 0.139 | 3.701 | 0.798 | 0.179 |
| 49 | 0.129 | 3.876 | 0.804 | 0.164 |
| 50 | 0.122 | 3.799 | 0.976 | 0.172 |
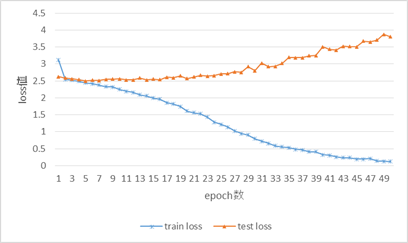
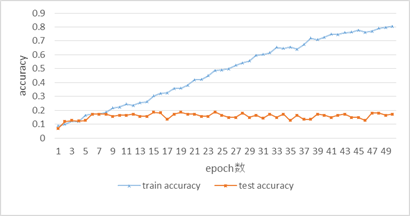
図9を見ると,学習データでのloss値はepoch数が進んでいくごとに減少していっている.一方,テストデータでのloss値はepoch数が進んでも上昇していく一方である.
図10を見ると,学習データでのaccuracy値はepoch数が進んでいくごとに上昇している.一方,テストデータでのaccuracy値はepoch数が進んでもそれほど上昇が無く,安定せずまばらになっていることが確認できる.
ここで
「画像内の情報や特徴ではなく,画像の明るさを読み込んで結果を予測しているのではないか?」
という仮説が立ったので,今度はデータセット内の画像の明るさを変更して実験を行う.
今後の実験では,学習を行う際のepoch数は50に固定する.
今回は学習を行う前に,データセット内の画像に以下の処理を行った.なお,これらの処理にはPythonの画像ライブラリであるOpenCVを使用した.
・二値化(閾値= 50,75,100,128,150,200)
・ガンマ補正(γ値= 0.50,0.75,1.25,1.50,2.00)
データセット内の画像にこれらの処理を行った後,実験1と同様の手順で新たに学習を行い,epoch = 50におけるテストデータへのaccuracy値の比較を行う.
以下の図11が二値化を行ったときのaccuracy値,図12がガンマ補正を行ったときのaccuracy値の比較である.
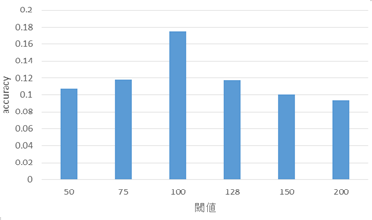
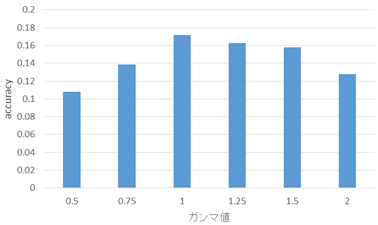
二値化とガンマ補正によって画像の明るさを一定に保った結果,多くの処理でテストデータのaccuracy値は低下したものの,ランダムに階を選ぶ確率である1/14 = 0.0714...の値より大きい値は保っている.また,読み込ませる画像に対して処理を加えることでaccuracy値が変化していることから,作成したモデルによって画像の学習自体は行えていると考えられる.
今度はデータセットの画像の総量を増やし,学習精度を向上させることを考える.
実験1で使用したデータセットに対して以下の前処理を行い,画像枚数の拡張を図る.なお,これらの処理にはPython内のライブラリであるOpenCVを使用した.
・グレースケール化
・元画像を20×20ピクセルずつ左上,右上,左下,右下へと平行移動
・元画像を左右に45°,90°ずつ回転させる
これらの前処理により,データセットは1階当たり1000枚になり,総枚数は14000枚となった.
データセット内の画像にこれらの処理を行った後,実験1と同様の手順で新たに学習を行い,epoch = 50までの1epochごとのloss値とaccuracy値をまとめる.
学習結果は次の表2の通りとなる.また,表2の結果を図13,図14にグラフ化する.また,図15では実験1と実験3のloss値の比較を,図16ではaccuracy値の比較を行う.
| epoch | train loss | test loss | train accuracy | test accuracy |
|---|---|---|---|---|
| 1 | 2.815 | 2.578 | 0.109 | 0.113 |
| 2 | 2.482 | 2.505 | 0.151 | 0.145 |
| 3 | 2.424 | 2.418 | 0.171 | 0.183 |
| 4 | 2.359 | 2.396 | 0.193 | 0.163 |
| 5 | 2.315 | 2.330 | 0.212 | 0.194 |
| 6 | 2.242 | 2.264 | 0.242 | 0.234 |
| 7 | 2.166 | 2.199 | 0.268 | 0.267 |
| 8 | 2.103 | 2.177 | 0.289 | 0.275 |
| 9 | 2.010 | 2.117 | 0.324 | 0.291 |
| 10 | 1.932 | 2.071 | 0.342 | 0.312 |
| 11 | 1.812 | 1.994 | 0.395 | 0.342 |
| 12 | 1.681 | 1.888 | 0.439 | 0.382 |
| 13 | 1.558 | 1.835 | 0.481 | 0.398 |
| 14 | 1.426 | 1.687 | 0.528 | 0.459 |
| 15 | 1.297 | 1.633 | 0.574 | 0.472 |
| 16 | 1.178 | 1.501 | 0.619 | 0.542 |
| 17 | 1.052 | 1.412 | 0.662 | 0.569 |
| 18 | 0.939 | 1.279 | 0.703 | 0.613 |
| 19 | 0.818 | 1.200 | 0.739 | 0.642 |
| 20 | 0.725 | 1.132 | 0.770 | 0.672 |
| 21 | 0.639 | 1.086 | 0.798 | 0.706 |
| 22 | 0.594 | 1.013 | 0.810 | 0.721 |
| 23 | 0.529 | 0.902 | 0.836 | 0.753 |
| 24 | 0.451 | 0.813 | 0.862 | 0.806 |
| 25 | 0.377 | 0.816 | 0.885 | 0.794 |
| 26 | 0.367 | 0.760 | 0.884 | 0.818 |
| 27 | 0.313 | 0.707 | 0.908 | 0.836 |
| 28 | 0.283 | 0.723 | 0.914 | 0.852 |
| 29 | 0.259 | 0.634 | 0.923 | 0.871 |
| 30 | 0.223 | 0.628 | 0.932 | 0.880 |
| 31 | 0.208 | 0.677 | 0.941 | 0.860 |
| 32 | 0.202 | 0.570 | 0.939 | 0.901 |
| 33 | 0.175 | 0.580 | 0.949 | 0.904 |
| 34 | 0.164 | 0.601 | 0.952 | 0.898 |
| 35 | 0.158 | 0.526 | 0.956 | 0.909 |
| 36 | 0.139 | 0.566 | 0.960 | 0.908 |
| 37 | 0.151 | 0.556 | 0.957 | 0.907 |
| 38 | 0.132 | 0.523 | 0.965 | 0.917 |
| 39 | 0.129 | 0.524 | 0.964 | 0.921 |
| 40 | 0.141 | 0.560 | 0.957 | 0.915 |
| 41 | 0.119 | 0.567 | 0.966 | 0.920 |
| 42 | 0.095 | 0.517 | 0.974 | 0.926 |
| 43 | 0.109 | 0.588 | 0.968 | 0.922 |
| 44 | 0.121 | 0.612 | 0.963 | 0.917 |
| 45 | 0.095 | 0.547 | 0.971 | 0.922 |
| 46 | 0.084 | 0.532 | 0.975 | 0.922 |
| 47 | 0.097 | 0.543 | 0.969 | 0.923 |
| 48 | 0.102 | 0.535 | 0.969 | 0.926 |
| 49 | 0.095 | 0.611 | 0.971 | 0.923 |
| 50 | 0.082 | 0.651 | 0.975 | 0.917 |
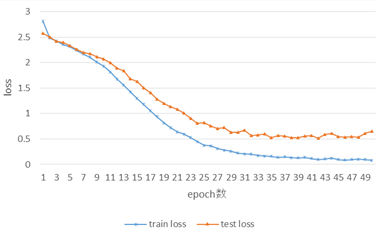
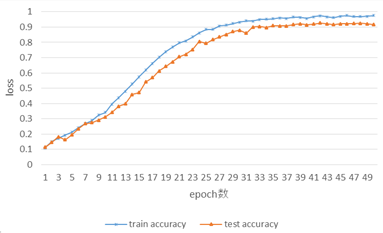
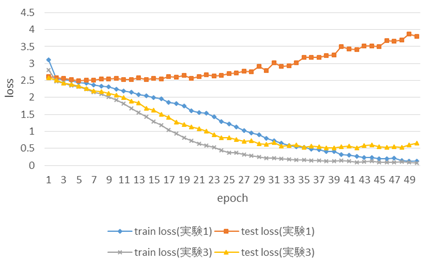
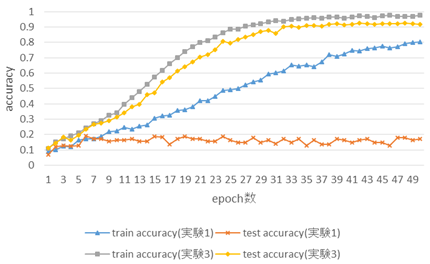
図15を見ると,実験3のテストデータに対するloss値はepoch数が進んでいくごとに低下しており,実験1のテストデータに対するloss値の推移とは真逆の推移を見せている.また,学習データに対するloss値も,実験1ではepoch = 48 になってようやくloss値が0.2以下になったのに対し,実験3ではepoch =33 の時点で0.2以下になっている.
図16を見ると,実験3のテストデータに対するaccuracy値は実験1の結果と違い,epoch数が進んでいくごとに大幅に上昇している.また,学習データに対するaccuracy値も,実験1ではepoch = 50になって0.8以上になったのに対し,実験3ではepoch = 21の時点で0.8以上に到達している.
学習効果,学習効率共に実験1の結果より大きく上昇していると考えられる.
今回の実験3で作成された学習済みモデルを用いて,学習に用いた画像データとは異なる画像データの識別を行う.
使用する学習済みモデルとして,テストデータへのaccuracy値が最も高かったepoch = 42のモデルを使用する.以後,この学習済みモデルを「model3_ep42」と呼称する.
実験3で新たに作成された学習済みモデルを使用し,学習に用いた画像データとは異なる画像データを用いて識別を行う.今回使用する学習済みモデルは,実験3で作成された学習済みモデル「model3_ep42」を使用する.
今回の識別に使用する画像として,今までの実験と同様に東京千住キャンパス 1号館の1階から14階の各階で撮影した画像を使用する.新たに1階当たり20枚,計280枚の画像を用意した.また,今回使用する画像群は現実に位置予測の機能として使用する場合のことを考え,以下の図17,図18のように,階ごとにほぼ同一の地点から撮影した20枚の画像を使用する.


「predict1.py」を実行し,学習を行う. 280枚の画像データを入力し,識別を行った結果が次の表3である.表3内の数値は入力画像データに対して出力された階の枚数である.
| 入力\出力 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 2 | 3 | 1 | 0 | 0 | 0 | 1 | 1 | 3 | 1 | 2 | 0 | 1 |
| 2 | 0 | 5 | 2 | 1 | 0 | 0 | 0 | 2 | 4 | 0 | 0 | 3 | 0 | 3 |
| 3 | 0 | 0 | 6 | 1 | 2 | 0 | 0 | 3 | 2 | 1 | 1 | 4 | 0 | 0 |
| 4 | 5 | 1 | 2 | 2 | 0 | 2 | 2 | 1 | 2 | 1 | 2 | 0 | 0 | 0 |
| 5 | 1 | 3 | 0 | 2 | 0 | 0 | 0 | 6 | 2 | 1 | 2 | 2 | 0 | 1 |
| 6 | 1 | 1 | 3 | 0 | 2 | 3 | 0 | 0 | 7 | 0 | 0 | 1 | 0 | 2 |
| 7 | 2 | 1 | 2 | 1 | 0 | 3 | 0 | 1 | 4 | 0 | 2 | 2 | 0 | 2 |
| 8 | 1 | 0 | 2 | 2 | 1 | 0 | 0 | 6 | 0 | 3 | 2 | 3 | 0 | 0 |
| 9 | 3 | 1 | 0 | 0 | 0 | 2 | 0 | 3 | 4 | 2 | 1 | 3 | 0 | 1 |
| 10 | 3 | 1 | 0 | 0 | 0 | 2 | 0 | 3 | 3 | 4 | 0 | 3 | 0 | 1 |
| 11 | 0 | 1 | 3 | 1 | 1 | 0 | 0 | 0 | 4 | 1 | 5 | 4 | 0 | 0 |
| 12 | 3 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 2 | 2 | 0 | 8 | 0 | 1 |
| 13 | 0 | 0 | 4 | 2 | 0 | 0 | 0 | 5 | 0 | 1 | 5 | 1 | 0 | 2 |
| 14 | 4 | 4 | 0 | 2 | 0 | 0 | 0 | 1 | 5 | 1 | 0 | 3 | 0 | 0 |
表3の結果に対し,
・A = n階のデータを入れて,「n階」と当てたデータ数
・B = n階のデータを入れて,「n階」と当てられなかったデータ数
・C = n階でないデータを入れて,「n階」と答えたデータ数
・D = n階でないデータを入れて,「n階でない」と答えたデータ数
として,True-Positive値とTrue-Negative値を
True-Positive値:A/A+B
True-Negative値:D/C+D
として計算する.
表3の結果から14階分のTrue-Positive値とTrue-Negative値を計算し,グラフ化したものが次の図19である.
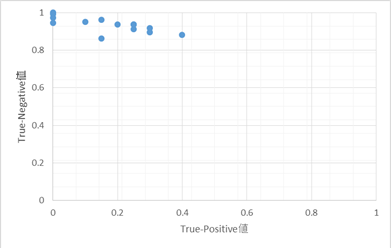
もしランダムに階数を選択するのであれば,True - Positive値は1/14=0.0714...となるはずであるが,どの階もその値ではない.また,True-Positive値が1/14よりも小さい階も存在するが,半数以上の階ではランダムに階数を選択する場合の値を上回っている.
True - Negative値に関してはどの階に対しても最低でも0.862以上の値があり,どちらの値から見ても一定以上の精度を持って判別を行えていることが確認できる.
また,実験1で作成された学習済みモデルに対しても同様に識別を行い,280枚の識別結果に対するTrue - Positive値とTrue - Negative値を測定する.使用する学習済みモデルとして,実験1でテストデータへのaccuracy値が最も高かったepoch = 24のモデルを使用する.以後,この学習済みモデルを「model1_ep24」と呼称する.
280枚の識別結果は次の表4の通りとなる.
| 入力\出力 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 0 | 0 | 0 | 1 | 3 | 0 | 1 | 2 | 0 | 3 | 3 | 0 | 4 |
| 2 | 1 | 3 | 2 | 1 | 2 | 5 | 0 | 1 | 1 | 0 | 3 | 1 | 0 | 0 |
| 3 | 2 | 2 | 3 | 1 | 1 | 2 | 0 | 2 | 1 | 1 | 2 | 1 | 0 | 2 |
| 4 | 0 | 0 | 6 | 0 | 5 | 1 | 1 | 1 | 1 | 2 | 2 | 1 | 0 | 0 |
| 5 | 3 | 3 | 0 | 2 | 1 | 2 | 0 | 6 | 1 | 0 | 0 | 0 | 0 | 2 |
| 6 | 4 | 0 | 0 | 0 | 1 | 2 | 1 | 1 | 2 | 0 | 3 | 2 | 0 | 4 |
| 7 | 1 | 0 | 3 | 0 | 1 | 0 | 0 | 3 | 0 | 0 | 3 | 2 | 0 | 7 |
| 8 | 1 | 0 | 2 | 0 | 1 | 1 | 0 | 3 | 0 | 0 | 3 | 2 | 0 | 7 |
| 9 | 2 | 0 | 2 | 0 | 1 | 1 | 0 | 9 | 0 | 0 | 3 | 1 | 0 | 1 |
| 10 | 0 | 3 | 1 | 1 | 1 | 0 | 1 | 5 | 0 | 6 | 2 | 0 | 0 | 0 |
| 11 | 2 | 0 | 1 | 0 | 0 | 2 | 0 | 1 | 1 | 2 | 8 | 2 | 0 | 1 |
| 12 | 2 | 1 | 0 | 1 | 3 | 1 | 0 | 0 | 4 | 0 | 5 | 2 | 0 | 1 |
| 13 | 0 | 1 | 2 | 3 | 1 | 1 | 0 | 4 | 0 | 1 | 5 | 1 | 0 | 1 |
| 14 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 2 | 5 | 4 | 1 | 2 | 0 | 2 |
表4の結果から14階分のTrue-Positive値とTrue-Negative値を計算し,グラフ化したものが以下の図20である.
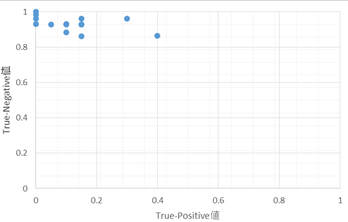
図19と図20の結果を比較するとTrue - Negative値に関しては「model1_ep24」を用いた識別の最低値が0.865であるため,「model3_ep42」を用いた識別結果と大きな差は無い.True-Positive値に関しては,True - Positive値が1/14を超えている階の数は「model1_ep24」を用いた識別では8階であったのに対し,「model3_ep42」を用いた識別では10階に増加している.また,True-Positive値が0.2を超えている階の数は「model1_ep24」を用いた識別では2階であったのに対し,「model3_ep42」を用いた識別では6階に増加している.
図19,図20の比較結果と合わせて,実験3で作成された学習済みモデルは実験1で作成された学習済みモデルより性能が向上していると考えられる.
本研究では,高層ビル内の各フロアの画像をニューラルネットワークを用いて学習したモデルを作成し,階数の識別を行った.ニューラルネットを作成しデータセットをそのまま読み込ませると,学習済みモデルの汎化性能が低くなってしまう.データセットを読み込ませる前に前処理を行ってデータセットの総量を増やし,かつニューラルネットが読み込みやすい形に処理することで学習速度と学習精度を向上させた.最終的にはフロアの50%程度の判別を行うことのできる判別器を作成することができた.
今回の実験での最終的な判別率は50%程度であり,作成された学習済みモデルを用いた識別器を実用的なシステムとするにはまだ精度が足りていない.しかしながら,正答率が半分程度の精度であれば判別が行えたことも事実であり,これを役立てられる可能性はあると考えられる.例えば,本研究の実験4で行ったように,同一地点で複数枚の画像を撮影して識別器に入力し,それらの結果を多数決方式でまとめることで判別を行うという方式であれば,正答率を向上させることが可能であるかもしれない.
実験3で行った学習ではテストデータのaccuracy値が90%を超えるほどに高くなったのに対し,実験4で実験3にて作成した学習済みモデル「model3_ep42」を用いて未知データの予測をした際にはそこまでの精度を発揮できなかった.これは実験1で撮影した写真と実験4で新たに撮影した写真の撮影状況が違うからであると考えられる.微細な明るさや撮影角度の違いなど,様々な要因が影響していると考えられ,データセットへの前処理が非常に重要であると推察される.
本研究では正答率は高くないが,単純な前処理を行うだけでも一定の精度の学習済みモデルを作成することができた.今後実験を行う際には,使用するニューラルネットワークの改良や,大元のデータセットの総量を増やしてそれに適した前処理を行うことで更に精度を上げることが可能であると考えられる.
本研究を進めるにあたり,終始のご指導を頂いた坂本 直志教授に心より感謝をいたします.そして,ともに研究に励み,協力し合ってきたネットワークシステム研究室の皆様に深く御礼を申し上げます.