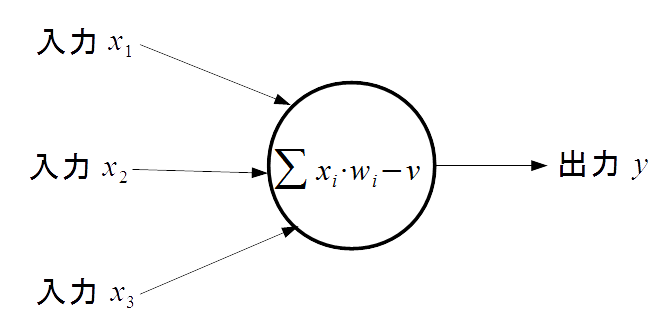
- 図1 ニューロセル
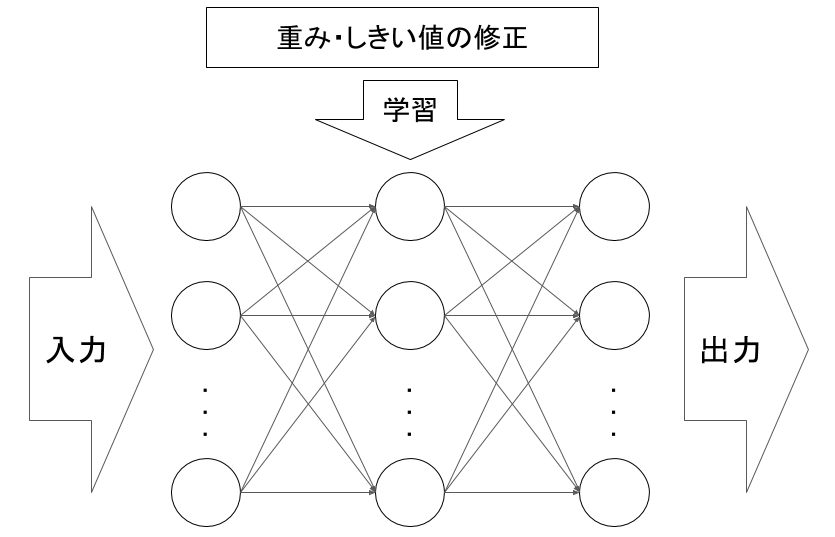
- 図2 ニューラルネットのモデル
近年, 深層学習(Deep Leaning) が広く知られるようになった. 深層学習を用いた技術として, 特に囲碁におけるAI であるAlpha GO の活躍[1] や, Microsoft 社によって開発されたAI「りんな」[2]は大きな話題となった.
深層学習とは, ニューラルネットワークを用いた機械学習における学習手法の1 つである. 膨大なデータを学習するために多層のニューラルネットワークを構築したものが深層学習である. ライブラリが開発されたことで, ニューラルネットワークによる機械学習は容易になっている. また, タブレットの教育現場への導入, e-Learning の利用など, 教育分野においてコンピュータが使われる場面が多くなった.
そこで本研究では, ニューラルネットワークによる画像認識を用いた手書き数式の正誤判定を取り上げ, ニューラルネットワークによる学習実験を行う. Python のライブラリ“Chainer'”を用いてニューラルネットワークを構築し, 機械学習の基本的な手順を確かめると共に, 機械学習の教育分野への活用について考える.
本研究で用いるニューラルネットワークについて述べる. ニューラルネットワークとは, 人間の神経細胞(ニューロン)をモデル化した計算素子である, ニューロセルを組み合わせて構成されるネットワークである. ニューロンは, 他のニューロンから信号を受けとり, 他の多数のニューロンに信号を送っている. これをモデル化したものがニューロセル(図1)であり, ニューラルネットワークはこのニューロセルを図2 のように層状に結合させた, 人間の神経構造を模したネットワークである.
ニューロセルは, 複数の入力と各入力に対応した重みを持つ. 各入力に対し重みを乗算することで重み付けを行い, それぞれの総和を求める. その総和からしきい値を減算し, 伝達関数で処理した結果を出力とする. この出力は複数の方向に出力でき, 次の層のニューロセルへの入力となる. 伝達関数は, 次の層のニューロセルに値を渡す際に入力された値に適応する関数であり, 学習の効率や内容に影響する.
ニューラルネットワークによる学習について述べる. 学習の際には, 入力として学習・認識したいデータと, ニューラルネットに出力させたい値を示すデータラベルをそれぞれ組にして用意する. そのデータをデータセットと呼ぶ. 学習するデータをニューラルネットに入力すると, 各層のニューロセルによって計算された情報が出力される. 出力された値とデータラベルとの誤差を求め, データラベルの値に近づくように各ニューロセルの重みやしきい値を調整する. この過程を複数の既知のデータを用いて繰り返すことで, 未知のデータに対しても正しい出力を行うようなニューラルネットに調整していく.
関連研究として, コンピュータによる正誤判定の分野に関連して, 篠田ら[4]による記述式問題の自動採点についての研究と, ニューラルネットワークによる数字認識に関連する藤木ら[5]による研究を紹介する.
篠田らの研究では, eラーニングにおける記述式問題の自動採点について取り上げている. 正解・不正解の判定を必要としているeラーニングにおいては, 選択式や穴埋め式の出題形式が多く見られる. これは記述式問題の正確な採点が難しいことによるものだと考えられる. この研究では回答の文章構造から, 同義語辞書の導入と文章の意味を縮約する2つの手法を用いて文章の意味を評価するシステムを構築している.
文章中に現れる語の意味は, 文脈に依存して変化するが, 限られた出題分野においては肯定的な表現・否定的な表現といったように, 意味情報を考慮できる. 例えば, 数学の回答では「2つの解を持つ」という表現と, 「解が2つある」という表現は, 採点者にとっては同じ意味を持っていると考えられる. このように出題する分野に現れる語に対して, 肯定的もしくは否定的意味を設定した同義語辞書を作成する.
文章中には, 上記の同義語辞書によって意味付けされた語が多く存在する. 採点のためには, あるキーワードに対する文が何を意味しているかを理解する必要がある. 次のような例題を考える.
ここで, 「ある」や「簡単」は肯定的(Positive)表現, 「困難」や「ない」は否定的(Negative)表現とすると, 肯定的な表現の重ね合わせによって, キーワードは肯定される. また, 否定的な表現の重ね合わせは, キーワードを肯定していると解釈される. 一方, 肯定的な表現と否定的な表現の組み合わせは, 順序によらず否定的な表現とされる.
上記の同義語辞書と縮約ルールを適用し, 回答文を分析する. 表1の例文を分析した結果, 図3に示すような木構造になる. このように文章中のキーワードと肯定的・否定的な意味付けによって正誤判定を行うシステムを構築した.
| 例文1 | 解は存在しない. |
| 例文2 | 上に凸ならば不安定である. |
| 例文3 | 計算は時間がかかるが, 困難ではない. |
| 例文4 | (2, 3)と(1, 3)に交点を持つ. |
![分析例(出典:篠田[4], 2007)](./img/reibunfig.png)
藤木らの研究では, 複合型ニューラルネットワークを用いた手書き数字の認識実験を行った. 3層からなるニューラルネットを用いた学習実験を行うが, 中間層のニューロセルの個数をランダムに変化させ, 複数のネットワークに学習を行う. これによって, 初期条件の異なる複数の学習済みネットワークを構築することができる.
これらのネットワークに手書き数字を認識させると, 同じ数字を認識させていても正しく認識できるネットワークと, 誤った認識をしてしまうネットワークが存在する. 誤答の中にも, 例えば3という数字であれば, 5や8という似ている数字に認識することが明らかになった. 藤木らはこのような数字の類似性を示す情報も判断材料として活用できると考え, 複数のネットワークを併用する認識方法を考案した. 初期条件を変えた複数のネットワークを図4のように並列に結合し, 1つの学習済みネットワークとして構築した. そこでは構築した複合型ネットワークについて「小さなネットワークサイズであっても高い能力を持たせることができることが明らかにされた[5]」とあり, ネットワークの構造や学習の方法によって結果が向上されることがわかる.
![複合型ネットワークの模式図(出典:藤木[5], 2009)](./img/hukugou.png)
本研究では, ニューラルネットワークモデルに対し手書きの数式画像を学習させ, 数式の答えの導出や, 解かれた数式の正誤判定を行う. 学習させるのは数式の答えや数式の正誤のみで, 数式に含まれる数や演算子についての情報は持たない. 数や演算子を認識してコンピュータが解くのではなく, 数式を見るだけでその数式の答えや正誤を識別することができるかを実験する.
コンピュータによる正誤判定については, チェックボックスやフォームに入力した情報を判定したり, あるいは枠内に書かれた数字が何かを認識することでその数字が正答と一致しているかを判定したりする方法がある. しかし, 書かれた数式が成立しているかどうか, 正しいかについては人間の目で判断される. ここでは, 数式を数字や演算子に分割することなく, 数式の書かれた画像のみで学習させる. その中で, 学習の効率, 精度について考え, 向上させるための手法を用いながら, 学習の効率・精度を比較していく.
ニューラルネットを構築し, 手書き数式の学習を行う. 実験の目標は手書き数式画像の正誤判定であるが, 手書き数字の学習, 数式の解答学習を行い, 手書き数式画像の正誤判定実験に活かす.
実験にはニューラルネットを構築, 学習ができるPython用ライブラリ“Chainer”をPython3.4.3上で用いる. Chainer上のニューラルネットは, ネットワーク構造を表すモデルとニューロセルのパラメタを調整するオプティマイザで構成され, Chainerではニューラルネットの構造(モデル)の定義と, 活性化関数をネットワークの層に割り当て, オプティマイザの最適化手法の定義を行うことでニューラルネットを構築, 容易に学習が可能である. また, モデル・オプティマイザは保存, 読み込みが可能で, 学習済みモデルを保存しておき, 認識の際には復元, 利用することができる.
Chainerで扱えるデータはPythonのnumpy配列であるため, 画像認識においても画像データをnumpy配列に変換して入力する必要がある. 画像データは, 1ピクセル毎の色情報を要素とするnumpy配列に変換する.
なお, Chainerを用いたニューラルネットワークモデル構築, 学習に用いるプログラムに関して, 「【機械学習】ディープラーニング フレームワークChainerを試しながら解説してみる。」から一部引用した. 引用部分は付録[6章]にて示すソースコード内にコメントアウトにて示す.
ニューラルネットによる学習経過の評価として, loss(損失)とaccuracy(正答率)がある. lossはニューラルネットによる出力値と, 教師データの与える正解との誤差を表す. accuracyはニューラルネットによる出力値の正答率を表す. 2値分類の場合を考えると, ニューラルネットによる出力結果は, 教師データの正答に応じて表2のように分類される.
| 出力 | |||
|---|---|---|---|
| 教師データ | 正 | 誤 | |
| 正 | a | b | |
| 誤 | c | d | |
この4つに分類された中で, どれだけ正答と一致しているかを示すのがaccuracyであり, 以下の式で表される. \[ Accuracy = \frac{a+d}{a+b+c+d} \]
学習においては, テストデータで検証した際のlossを下げることを目標とし, テストデータ時のlossの少ない学習モデルをより良いモデルと評価する.
Pythonを用いた実験方法を示す.
学習する教師データとそのデータの正解ラベルを組にしたデータセットを読み込む. データセットは学習用とテスト用を用意し, 教師データと正解ラベルは対応付けられるようにする.
Chainerを用いて, ニューラルネットのモデル及びニューラルネットのパラメタを調整するオプティマイザを定義する. ネットワークは入力層・中間層・出力層の3層からなり, それぞれの層は全結合のネットワークを構成している. 各層からの出力の個数は, 次の層のニューロセルの個数と一致している必要がある.
準備したデータセットと構築したニューラルネットのモデルを用いて学習を行う. ニューラルネットの学習の流れは以下のとおりである.
ここで1.の過程を順伝播と呼び, 3.の過程を誤差の逆伝播と呼ぶ.
順伝播の構造は, ニューロセルの活性化関数を定義することで実装する. 活性化関数は, relu関数とdropout関数を併用している. relu関数はニューラルネットにおいて良い結果が得られるとされる関数であり, 以下の式で定義される. \[ H(x)=max(0,x) \]
Chainerによる学習の概念図を図5に示す.
学習済みニューラルネットモデルを用いた, データの識別実験の手順を示す. 学習したモデルとオプティマイザは, ファイルで保存することができる. 保存したモデルやオプティマイザは, 別のプログラムで復元することで, 学習済みのニューラルネットモデルを利用することができる.
データの識別は, 学習時と同様にニューラルネットにデータを入力する. ニューラルネットからは, データの示す値として考えられるそれぞれの値について, その値である確率が出力される. 例えば, 0~9の画像を識別するのであれば, 入力した画像が0~9である確率がそれぞれ出力される. ここで, ニューラルネットは出力された確率が最も高くなったものを識別の結果とする.
ニューラルネットによる出力を求めた後に, 確率の最も高い値が求まる. これが入力したデータのラベルと一致していれば識別が成功したことになり, そうでなければ識別は失敗となる.
MNISTと呼ばれる手書き数字データセットを用いて, 学習と認識を行う. MNISTは“Mixed National Institute of Standards and Technology database”の略で, 機械学習による画像認識で頻繁に使われるデータセットであり, 7万個の手書きの数字(0~9)にそれぞれ正解ラベルが与えられている. ChainerにはこのMNISTデータを取得するメソッドがあり, numpy配列で手書き数字画像データを得ることができる. このMNISTによる実験を基に, オリジナルのデータセットでの実験を進めていく.
画像の学習, 認識に用いるニューラルネットを, 扱うデータに適したものに定義する. 各層のニューロセルの個数, ニューロセルの活性化関数の定義を行う.
入力データになる配列の次元数とニューラルネットの入力層の個数を同じにする必要がある. MNISTで得られるデータは1ピクセル辺り1値のデータで構成されるため, 28*28の画像データでは784次元の配列データが入力となる.
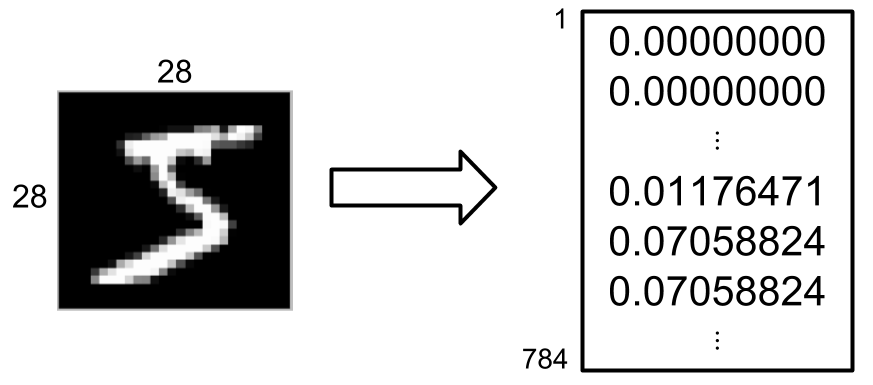
そのため, ニューラルネットの入力層は784個となる. ニューラルネットの出力層は望む出力の個数で良いため, 0~9の数字の個数である10個となる. 続いて, 中間層のユニット数を定める. 中間層が多くなればその分学習に時間がかかるが, 少なすぎても十分な学習ができないため, ここでは1000個で学習を行わせている.
構築したモデルに学習を行う. 学習は画像データとその画像がどの数字であるかを表すラベルをセットにしたデータセットを用いて行われる. また, データセットには学習用データとテスト用データがあり, 学習用データを基にパラメタを更新しつつ, テストデータを認識して正答率を出しながら学習していく.
ニューラルネットによる学習では, 同データによる学習を繰り返し行い, その度にパラメタを更新する. MNISTの学習は単純な手書き数字の学習であり, 学習する特徴量は少ない. そのため, 学習の繰り返し数(epoch数)は20回とする. 識別実験の為に, 繰り返し毎のモデルを保存しておく. 学習の成果を確認する識別では, 保存されたモデルを読み込んで識別を行う. 学習を繰り返すことで学習による精度は向上するが, 回数が多すぎると与えられたデータでのみ精度が向上し, テストがうまくいかなくなる過学習という現象が起きてしまう. 過学習が起きていると, 学習データでのloss値が減少するのに対し, テストデータでのloss値が増加する. そのため, 学習の経過を確認し, 過学習の起きていない繰り返し数のモデルを使用し, 識別を行う.
mnist/train.pyを実行し,ニューラルネットの学習を行う. 各繰り返し毎のモデル及びオプティマイザが保存される. 学習を行った結果を表3に示す. 以下のデータにおけるaccuracyは, そのデータでの正答率を表す.
| epoch | train loss | train accuracy | test loss | test accuracy |
|---|---|---|---|---|
| 1 | 0.276 | 0.915 | 0.111 | 0.965 |
| 2 | 0.136 | 0.958 | 0.087 | 0.973 |
| 3 | 0.108 | 0.966 | 0.076 | 0.976 |
| 4 | 0.092 | 0.972 | 0.075 | 0.977 |
| 5 | 0.084 | 0.973 | 0.066 | 0.980 |
| 6 | 0.079 | 0.975 | 0.059 | 0.982 |
| 7 | 0.073 | 0.978 | 0.059 | 0.982 |
| 8 | 0.066 | 0.979 | 0.060 | 0.982 |
| 9 | 0.063 | 0.979 | 0.060 | 0.982 |
| 10 | 0.060 | 0.982 | 0.060 | 0.983 |
| 11 | 0.060 | 0.981 | 0.066 | 0.983 |
| 12 | 0.053 | 0.983 | 0.066 | 0.983 |
| 13 | 0.055 | 0.983 | 0.061 | 0.983 |
| 14 | 0.049 | 0.985 | 0.060 | 0.985 |
| 15 | 0.051 | 0.985 | 0.058 | 0.985 |
| 16 | 0.048 | 0.986 | 0.064 | 0.984 |
| 17 | 0.049 | 0.985 | 0.057 | 0.985 |
| 18 | 0.049 | 0.986 | 0.076 | 0.983 |
| 19 | 0.046 | 0.986 | 0.067 | 0.984 |
| 20 | 0.046 | 0.986 | 0.063 | 0.985 |
この実行結果から, epoch 17ではテストデータでのloss値が少ない. 17回目のepochでのモデルを用いて認識を行う.
学習済みモデルを用いて, 画像データの識別を行う. 識別を行うデータも, テスト時と同様にChainerで得られるMNISTデータセットを用いる. 学習と同じデータを用いているため, 学習時の正答率と同様の値が得られると予想されるが, ここではモデルを用いた識別の方法を確認する.
識別の際には, 学習時に用いたものと同じ構造のニューラルネットモデルを構築する. そのモデルに対して, 保存された学習済みモデルと, パラメタを操作するオプティマイザを読み込み, 割り当てる. これによって, 学習済みモデルを用いた画像の識別を行うことができる. モデルに識別したいデータを入力させると, 出力層ではそのデータがある出力である確率を得ることができる. 例えば今回の実験であれば, データラベルの値が画像データの表す数字であるため, 出力層ではその数字である確率を得ることができる. この確率が最も高い, つまり出力層での値が最も大きいものを識別の結果とする.
mnist/predict.pyを実行して, 画像の識別を行う. 得られたデータからランダムに1000個を取り出して識別させ, 正答率を確認する. 結果を表3に示す.
| 認識結果 | 正答データ |
|---|---|
| 6 | 8 |
| 0 | 9 |
| 0 | 3 |
| 1 | 9 |
| 6 | 8 |
| 3 | 5 |
| 5 | 8 |
| 5 | 6 |
| 8 | 6 |
| 3 | 8 |
| 8 | 6 |
| 5 | 6 |
| 9 | 7 |
誤認識したのは1000個のうち13個で, 正答率は98.7%と高い数値が確認できる. このように, モデルの構築・学習・識別を基本的な流れとして実験を行う.
手書き風フォントを用いた, 数式画像の学習実験を行う. 扱う数式の画像データは, フリーの手書き風フォントを使用し, Javaプログラムで作成する.
ここでは, 1桁の数字同士の足し算の数式を入力し, その答えを出力データとする. 数値や演算記号をそれぞれ認識, 数式を処理するのではなく, 数式を入力して学習させることによって学習が可能かどうかを確かめる. 学習に用いる画像データは単一のフォントでなく複数のフォントを組み合わせて数式を生成し, 画像量を増やしている. テストデータは同じフォントで数式を書いたものを, 全てのフォントに対して生成している.
用意したフォント数は50種類で, これを各数字・記号に対してランダムに割り当て, 100種類の数式画像をそれぞれ0+0から9+9の100枚ずつ生成した. ラベルデータは数式の計算結果とし, 数式を計算した結果を学習し, データ認識では数式の画像データを入力すると計算結果を出力させる.
実験で扱うデータに適するように, ニューラルネットのモデルを構築する. 活性化関数やモデルの基本構造は変わらないが, 入力・出力層の個数を変更する必要がある.
前回と同様, 画像データを1ピクセル毎のnumpy配列に変換してネットワークに入力する. そのため, 今回扱うデータのサイズに合わせたモデルを構築する. 入力データは28*84のサイズであるため, 入力層の個数は28×84=2352個となる. 対して出力は1桁の足し算の結果の個数になるため, あり得る値の0~18である19個を出力層の個数とする.
オリジナルのデータセットを扱うに当たって, 学習の効率向上のための処理や, Chainerで扱えるnumpy配列への変換等が必要になる. この前処理と, 画像データの読み込みを, Python上でOpenCVを用いて行う.
画像データに適用する前処理としては, リサイズ・グレースケール化・白黒反転・2値化がある.
リサイズ処理は, ニューラルネットに入力する際のデータ量を統一するものである. 本実験では画像のサイズを統一して生成しているため必要ない処理ではあるが, 今後の実験でも同様の処理を行うため, リサイズを行っている. グレースケール化は, 学習する画像データが数字や演算子であり, 色を問わない画像であるため, 行うことができる処理である. グレースケール化を行うと各ピクセルの情報がRGBの3次元から白黒の1次元になり, 不要な情報量を取り除くことができる.
2値化は, グレースケールで表されている画像を, しきい値を定めて白か黒の2値に変換する処理である. これによって画像の輪郭が明確になり, 学習の効率が向上する. ここでは, しきい値を128とし, 黒白の画素値を0と255の2値に変換している.
続いて, Chainerで扱える配列に変換する. OpenCVで読み込んだ画像はnumpy配列で扱えるため, numpyで与えられるメソッドを用いて入力として望まれる次元に変換することができる. numpy.arrayメソッドは多次元配列に変換するメソッドである. また, reshapeメソッドは要素数を指定して多次元配列の次元数を変換するメソッドである. これらの変換を行った要素を全て255で除算することで, 0と255の2値であった画素値が0と1の2値に変換される. このように情報を0-1に変換することを正規化という.
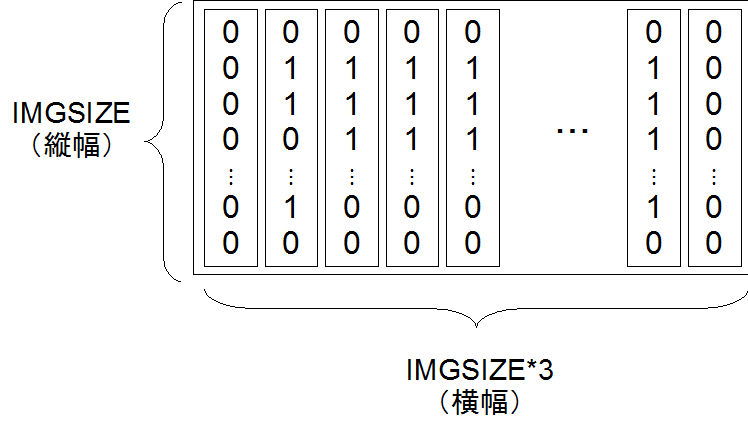
これらの前処理を行った上で, ニューラルネットによる学習を行う.
前述のデータセットを用いて学習を行う. ex1/train_tegaki.pyを実行して学習を行う.
epoch数は100とし, テストデータでのloss値が最も少ない学習済みモデルを優秀なものとして選ぶ. 学習の結果, 繰り返し回数50まででloss値とaccuracy値が収束した. 繰り返し回数50までの結果を表5に示す.
| epoch | train loss | train accuracy | test loss | test accuracy |
|---|---|---|---|---|
| 1 | 2.690 | 0.990 | 2.385 | 0.185 |
| 2 | 2.229 | 0.183 | 2.128 | 0.278 |
| 3 | 1.863 | 0.291 | 1.795 | 0.421 |
| 4 | 1.548 | 0.408 | 1.521 | 0.536 |
| 5 | 1.207 | 0.544 | 1.323 | 0.629 |
| 6 | 0.927 | 0.657 | 1.144 | 0.707 |
| 7 | 0.697 | 0.751 | 1.009 | 0.755 |
| 8 | 0.510 | 0.822 | 0.945 | 0.802 |
| 9 | 0.382 | 0.866 | 0.933 | 0.817 |
| 10 | 0.291 | 0.903 | 0.893 | 0.835 |
| 11 | 0.873 | 0.922 | 0.873 | 0.847 |
| 12 | 0.200 | 0.932 | 0.826 | 0.854 |
| 13 | 0.165 | 0.945 | 0.850 | 0.865 |
| 14 | 0.136 | 0.957 | 0.854 | 0.868 |
| 15 | 0.115 | 0.965 | 0.826 | 0.878 |
| 16 | 0.112 | 0.964 | 0.842 | 0.878 |
| 17 | 0.123 | 0.959 | 0.805 | 0.879 |
| 18 | 0.103 | 0.966 | 0.806 | 0.888 |
| 19 | 0.098 | 0.970 | 0.805 | 0.880 |
| 20 | 0.083 | 0.976 | 0.834 | 0.885 |
| 21 | 0.077 | 0.976 | 0.838 | 0.892 |
| 22 | 0.080 | 0.974 | 0.838 | 0.881 |
| 23 | 0.083 | 0.972 | 0.879 | 0.889 |
| 24 | 0.078 | 0.974 | 0.849 | 0.887 |
| 25 | 0.090 | 0.972 | 0.836 | 0.891 |
| 26 | 0.084 | 0.973 | 0.885 | 0.890 |
| 27 | 0.081 | 0.976 | 0.833 | 0.894 |
| 28 | 0.074 | 0.976 | 0.910 | 0.886 |
| 29 | 0.082 | 0.975 | 0.843 | 0.896 |
| 30 | 0.068 | 0.979 | 0.879 | 0.895 |
| 31 | 0.061 | 0.980 | 0.862 | 0.901 |
| 32 | 0.073 | 0.977 | 0.862 | 0.901 |
| 33 | 0.072 | 0.977 | 0.850 | 0.899 |
| 34 | 0.081 | 0.977 | 0.851 | 0.899 |
| 35 | 0.067 | 0.980 | 0.870 | 0.901 |
| 36 | 0.057 | 0.981 | 0.870 | 0.902 |
| 37 | 0.056 | 0.981 | 0.954 | 0.899 |
| 38 | 0.058 | 0.982 | 0.909 | 0.894 |
| 39 | 0.061 | 0.980 | 0.922 | 0.894 |
| 40 | 0.065 | 0.978 | 0.874 | 0.897 |
| 41 | 0.087 | 0.974 | 0.939 | 0.896 |
| 42 | 0.072 | 0.978 | 0.927 | 0.898 |
| 43 | 0.072 | 0.978 | 0.917 | 0.904 |
| 44 | 0.080 | 0.978 | 0.939 | 0.904 |
| 45 | 0.073 | 0.980 | 0.969 | 0.903 |
| 46 | 0.076 | 0.979 | 0.949 | 0.902 |
| 47 | 0.059 | 0.982 | 0.877 | 0.906 |
| 48 | 0.065 | 0.982 | 0.921 | 0.905 |
| 49 | 0.062 | 0.982 | 0.957 | 0.904 |
| 50 | 0.072 | 0.980 | 0.976 | 0.900 |
以降の繰り返しでは, loss値とaccuracy値が変動せずに学習が進んだ. テストデータでのloss値が最も少ないモデルはepochが17のものである. よって, 17回目の繰り返しで作られたモデルが最も優秀である.
ここで, MNIST学習実験と比べると, 繰り返しを重ねるにつれてテスト時のloss値が大きく増加している. これは過学習が起きているため, 学習データの学習のみが過多になり, 学習時と異なるデータでの精度が向上しなくなってしまっている. MNIST学習実験で扱ったデータ量が7万枚(うち学習用データが6万, テストデータが1万)であり, 各数字に対して7000枚程度あるのに対し, ここでは学習用データの個数は各式に対して100種類となっている. これによって, 繰り返しによる学習が過多になってしまい, 結果としてテストデータでの精度が上がらなくなってしまう.
テストデータを用いてデータの識別を行う. ex1/predict_tegaki.pyを実行して, 5000個用意したテストデータのうちランダムに1000個を抽出し, 正しい答えが出力されるかを確認する.
識別を行った結果, 正答だったものは1000個のうち878個であった. よって正答率は87.8%であった. MNISTの実験と比べると正答率は低いが, 数式を学習して識別できていることは確認できる.
ここでは, 画像に書かれた手書き数式を判定するための実験を行う. 数式の正誤判定を行うために, 学習する画像データは完結した数式を表し, それが正答であるかどうかをラベルデータとする. 正答のデータには1を, 誤答のデータには0を与え, 出力は0か1の2種である.
誤答として考えられるものには, 数式の形は合っているが答えが誤っているものと, 答えの数しか書かれていいない等で数式として成り立っていないものの2つが考えられる. よって, 誤答のデータの半数は答えが誤っているもの, もう半数は数式が成立していないものをデータセットに用意しておく.
画像データのフォント数は50種類用意し, 正答データは1桁の数字の足し算の全てのパターンを作成, それぞれのフォントについて100枚になる. よって正答の学習データは全5000枚用意する. 誤答のデータは前述した2つの場合についてそれぞれ2500枚ずつ, 全5000枚を用意した. テストデータも学習データと同様に生成したものを利用する. 正答データとして, 1桁の足し算のそれぞれの式について5種類ずつ, 全500枚. 誤答データは2つの誤答パターンで250枚ずつ, 全500枚を用意した.
画像に対する前処理は前実験と同様であり, ニューラルネットモデルは出力層を望む出力の個数に合わせて2つとした.
ex3/train.pyを実行して学習を行う. ここでは, プログラム内の変数n_extendを0とする.
データ量が多く, 一回の繰り返しにかかる時間が長いため, epoch数は50とした. 表6に学習の結果を示す.
| epoch | train loss | train accuracy | test loss | test accuracy |
|---|---|---|---|---|
| 1 | 0.500 | 0.734 | 0.447 | 0.798 |
| 2 | 0.437 | 0.791 | 0.462 | 0.782 |
| 3 | 0.400 | 0.818 | 0.463 | 0.782 |
| 4 | 0.382 | 0.828 | 0.470 | 0.800 |
| 5 | 0.366 | 0.843 | 0.418 | 0.818 |
| 6 | 0.349 | 0.851 | 0.381 | 0.842 |
| 7 | 0.334 | 0.860 | 0.402 | 0.834 |
| 8 | 0.322 | 0.867 | 0.372 | 0.852 |
| 9 | 0.308 | 0.872 | 0.370 | 0.852 |
| 10 | 0.295 | 0.881 | 0.438 | 0.861 |
| 11 | 0.298 | 0.877 | 0.402 | 0.849 |
| 12 | 0.276 | 0.889 | 0.398 | 0.859 |
| 13 | 0.270 | 0.890 | 0.362 | 0.870 |
| 14 | 0.263 | 0.896 | 0.379 | 0.852 |
| 15 | 0.251 | 0.900 | 0.427 | 0.855 |
| 16 | 0.242 | 0.903 | 0.396 | 0.857 |
| 17 | 0.236 | 0.905 | 0.399 | 0.870 |
| 18 | 0.228 | 0.908 | 0.415 | 0.862 |
| 19 | 0.221 | 0.913 | 0.435 | 0.854 |
| 20 | 0.211 | 0.920 | 0.397 | 0.871 |
| 21 | 0.207 | 0.919 | 0.388 | 0.869 |
| 22 | 0.206 | 0.918 | 0.392 | 0.868 |
| 23 | 0.190 | 0.924 | 0.441 | 0.862 |
| 24 | 0.198 | 0.919 | 0.406 | 0.856 |
| 25 | 0.184 | 0.924 | 0.473 | 0.867 |
| 26 | 0.179 | 0.928 | 0.427 | 0.869 |
| 27 | 0.175 | 0.928 | 0.483 | 0.873 |
| 28 | 0.170 | 0.930 | 0.470 | 0.875 |
| 29 | 0.170 | 0.933 | 0.446 | 0.873 |
| 30 | 0.158 | 0.936 | 0.449 | 0.879 |
| 31 | 0.157 | 0.937 | 0.506 | 0.874 |
| 32 | 0.150 | 0.940 | 0.462 | 0.870 |
| 33 | 0.149 | 0.940 | 0.533 | 0.871 |
| 34 | 0.139 | 0.945 | 0.530 | 0.871 |
| 35 | 0.140 | 0.944 | 0.538 | 0.876 |
| 36 | 0.131 | 0.945 | 0.492 | 0.869 |
| 37 | 0.133 | 0.948 | 0.521 | 0.880 |
| 38 | 0.131 | 0.948 | 0.501 | 0.873 |
| 39 | 0.130 | 0.950 | 0.476 | 0.880 |
| 40 | 0.116 | 0.954 | 0.615 | 0.878 |
| 41 | 0.120 | 0.954 | 0.615 | 0.876 |
| 42 | 0.104 | 0.960 | 0.592 | 0.879 |
| 43 | 0.115 | 0.954 | 0.569 | 0.881 |
| 44 | 0.119 | 0.954 | 0.568 | 0.870 |
| 45 | 0.113 | 0.958 | 0.527 | 0.872 |
| 46 | 0.103 | 0.961 | 0.594 | 0.877 |
| 47 | 0.105 | 0.960 | 0.642 | 0.875 |
| 48 | 0.099 | 0.962 | 0.525 | 0.872 |
| 49 | 0.100 | 0.962 | 0.652 | 0.875 |
| 50 | 0.092 | 0.965 | 0.614 | 0.868 |
テストデータも学習データと同じ様に自動生成したものであるため, 正答率は85%程度ある.
このモデルを用いて, 画像から数式を読み込み, 正誤判定ができるかどうかを確認する.
数式の書かれた画像から数式を読み込み, その数式の正誤判定を行う. 数式の読み取りの為に数式を書く画像の書式は固定し, ある範囲内に数式が書かれていれば自動的にトリミング, 処理できるようにした. これについても, Python上のOpenCVを用いた.
数式の範囲をトリミングする際には, 上下左右位置に余白を追加する. 余白を追加することでニューラルネットによる識別の精度が上がる他, 後に行うデータ拡張の際にも利用できる. また, ここでは画像に手書き風フォントで記載した数式を書き込んだものを利用して正誤判定を行う. 正誤判定を行う画像を図13,14に示す.


学習したモデルを用いて, 画像の正誤判定を行う. ex3/predict.pyを実行し, 画像を数式毎に分割して正誤判定を行った結果を以下に示す.
| 判定 | 正答 | |
|---|---|---|
| 問題1 | × | ◯ |
| 問題2 | × | ◯ |
| 問題3 | × | ◯ |
| 問題4 | × | × |
| 問題5 | × | × |
| 問題6 | × | × |
| 判定 | 正答 | |
|---|---|---|
| 問題1 | × | ◯ |
| 問題2 | × | ◯ |
| 問題3 | × | ◯ |
| 問題4 | × | ◯ |
| 問題5 | × | ◯ |
| 問題6 | × | ◯ |
画像(1)の問題1~3は正答, 4~6は誤答であり, 画像(2)の問題は全て正答であるが, 全て誤答と判定されている.
学習時のデータセットやテストデータに用いた画像は手書き風フォントで自動生成したもので, 余白や文字の位置が統一されているが, ここでは1つの画像から数式を切り取って識別しているため, 学習時とは数式の位置が異なる. そのため, 学習したものとは異なる画像を判別できず, 正答率が低くなってしまったと考えられる.
そこで, 1つの画像に対して, 平行移動や回転の操作を加えることにより, データの幅を拡張させる. この拡張によって学習の効率, 精度の向上が図れるかを確認する.
データ操作のためのPythonプログラムを作成し, 読み込んだ画像に対して操作を行う. 操作はOpenCVを用いて行った.
画像データの平行移動は, 上下左右それぞれ5ピクセルの範囲でランダムに, 回転は-10~10度の範囲でランダムに行い, データ拡張の際には1画像に対し平行移動及び回転の操作をどちらも行う.
各画像について9回拡張を行い, 学習を行う. ex3/train.pyを実行して学習を行う. ここで, データの拡張を行うため, プログラム内のn_extendを9として実行する. 学習の結果を表9に示す.
| epoch | train loss | train accuracy | test loss | test accuracy |
|---|---|---|---|---|
| 1 | 0.550 | 0.695 | 0.464 | 0.771 |
| 2 | 0.514 | 0.724 | 0.453 | 0.770 |
| 3 | 0.503 | 0.731 | 0.419 | 0.805 |
| 4 | 0.498 | 0.737 | 0.406 | 0.806 |
| 5 | 0.491 | 0.742 | 0.409 | 0.817 |
| 6 | 0.487 | 0.744 | 0.389 | 0.831 |
| 7 | 0.484 | 0.747 | 0.385 | 0.829 |
| 8 | 0.479 | 0.750 | 0.373 | 0.832 |
| 9 | 0.474 | 0.752 | 0.409 | 0.819 |
| 10 | 0.469 | 0.757 | 0.376 | 0.845 |
| 11 | 0.462 | 0.761 | 0.399 | 0.833 |
| 12 | 0.459 | 0.761 | 0.384 | 0.837 |
| 13 | 0.452 | 0.768 | 0.381 | 0.835 |
| 14 | 0.446 | 0.771 | 0.412 | 0.834 |
| 15 | 0.440 | 0.776 | 0.380 | 0.845 |
| 16 | 0.435 | 0.778 | 0.384 | 0.847 |
| 17 | 0.429 | 0.782 | 0.385 | 0.839 |
| 18 | 0.420 | 0.788 | 0.392 | 0.848 |
| 19 | 0.415 | 0.791 | 0.428 | 0.836 |
| 20 | 0.405 | 0.798 | 0.398 | 0.851 |
| 21 | 0.399 | 0.800 | 0.383 | 0.852 |
| 22 | 0.393 | 0.806 | 0.408 | 0.844 |
| 23 | 0.384 | 0.809 | 0.390 | 0.851 |
| 24 | 0.379 | 0.814 | 0.415 | 0.852 |
| 25 | 0.371 | 0.818 | 0.405 | 0.839 |
| 26 | 0.364 | 0.820 | 0.406 | 0.851 |
| 27 | 0.360 | 0.824 | 0.445 | 0.859 |
| 28 | 0.351 | 0.830 | 0.413 | 0.849 |
| 29 | 0.344 | 0.833 | 0.494 | 0.843 |
| 30 | 0.338 | 0.837 | 0.421 | 0.852 |
| 31 | 0.332 | 0.840 | 0.447 | 0.848 |
| 32 | 0.327 | 0.843 | 0.441 | 0.851 |
| 33 | 0.321 | 0.846 | 0.437 | 0.833 |
| 34 | 0.313 | 0.852 | 0.438 | 0.852 |
| 35 | 0.309 | 0.854 | 0.426 | 0.850 |
| 36 | 0.303 | 0.857 | 0.453 | 0.850 |
| 37 | 0.300 | 0.859 | 0.465 | 0.849 |
| 38 | 0.293 | 0.862 | 0.498 | 0.854 |
| 39 | 0.287 | 0.866 | 0.433 | 0.844 |
| 40 | 0.284 | 0.869 | 0.448 | 0.858 |
| 41 | 0.280 | 0.870 | 0.547 | 0.843 |
| 42 | 0.274 | 0.873 | 0.474 | 0.859 |
| 43 | 0.270 | 0.876 | 0.478 | 0.849 |
| 44 | 0.266 | 0.877 | 0.504 | 0.858 |
| 45 | 0.262 | 0.881 | 0.527 | 0.843 |
| 46 | 0.260 | 0.882 | 0.511 | 0.855 |
| 47 | 0.254 | 0.885 | 0.484 | 0.836 |
| 48 | 0.251 | 0.885 | 0.540 | 0.850 |
| 49 | 0.247 | 0.888 | 0.577 | 0.856 |
| 50 | 0.244 | 0.889 | 0.547 | 0.854 |
bestepochは8で, 学習データでの正答率は0.75006, テストデータでの正答率は0.83200であった このモデルを用いて正誤判定を行った結果を以下に示す.
| 判定 | 正答 | |
|---|---|---|
| 問題1 | ◯ | ◯ |
| 問題2 | ◯ | ◯ |
| 問題3 | ◯ | ◯ |
| 問題4 | ◯ | × |
| 問題5 | ◯ | × |
| 問題6 | × | × |
| 判定 | 正答 | |
|---|---|---|
| 問題1 | ◯ | ◯ |
| 問題2 | × | ◯ |
| 問題3 | × | ◯ |
| 問題4 | ◯ | ◯ |
| 問題5 | ◯ | ◯ |
| 問題6 | ◯ | ◯ |
画像(1)については4, 5問目を正答と判断しており, 画像(2)でも問題2と3を誤答と判断しているが, 拡張の無い場合と比べて正答率は向上している. このように, データに幅を持たせることで, 学習の精度の向上が期待できる.
加えて, 学習の際に画像に不要な黒点, 汚しを加え, 同様に学習を行う. 学習したいデータとは直接的な関係のない黒点をランダムに与えることによって, 学習にどのような影響があるかを確かめる. データ拡張の回数は同様の9回とし, 拡張の際にランダムな黒点を0~10個の範囲で画像に加えた上で学習をさせる.
ex3/train.pyを実行して学習を行う. n_extendは前回と変わらず9とする. ここでプログラム内の変数f_dirtをTrueとして実行し, 汚しの処理を行う. 汚し処理を行った画像の学習結果を表12に示す.
| epoch | train loss | train accuracy | test loss | test accuracy |
|---|---|---|---|---|
| 1 | 0.614 | 0.628 | 0.470 | 0.745 |
| 2 | 0.577 | 0.670 | 0.494 | 0.753 |
| 3 | 0.554 | 0.693 | 0.441 | 0.787 |
| 4 | 0.534 | 0.714 | 0.411 | 0.808 |
| 5 | 0.510 | 0.736 | 0.409 | 0.810 |
| 6 | 0.483 | 0.759 | 0.400 | 0.825 |
| 7 | 0.452 | 0.781 | 0.382 | 0.834 |
| 8 | 0.421 | 0.800 | 0.390 | 0.828 |
| 9 | 0.391 | 0.820 | 0.410 | 0.822 |
| 10 | 0.361 | 0.838 | 0.381 | 0.835 |
| 11 | 0.337 | 0.852 | 0.392 | 0.830 |
| 12 | 0.314 | 0.864 | 0.392 | 0.833 |
| 13 | 0.292 | 0.874 | 0.372 | 0.847 |
| 14 | 0.272 | 0.886 | 0.411 | 0.820 |
| 15 | 0.258 | 0.892 | 0.380 | 0.835 |
| 16 | 0.243 | 0.898 | 0.387 | 0.833 |
| 17 | 0.230 | 0.906 | 0.390 | 0.832 |
| 18 | 0.221 | 0.909 | 0.371 | 0.849 |
| 19 | 0.208 | 0.916 | 0.398 | 0.835 |
| 20 | 0.201 | 0.921 | 0.381 | 0.854 |
| 21 | 0.192 | 0.925 | 0.381 | 0.843 |
| 22 | 0.184 | 0.927 | 0.377 | 0.844 |
| 23 | 0.178 | 0.930 | 0.414 | 0.834 |
| 24 | 0.172 | 0.933 | 0.372 | 0.850 |
| 25 | 0.163 | 0.947 | 0.397 | 0.838 |
| 26 | 0.162 | 0.937 | 0.402 | 0.843 |
| 27 | 0.159 | 0.939 | 0.376 | 0.850 |
| 28 | 0.153 | 0.941 | 0.418 | 0.842 |
| 29 | 0.148 | 0.943 | 0.382 | 0.854 |
| 30 | 0.145 | 0.945 | 0.412 | 0.847 |
| 31 | 0.141 | 0.946 | 0.439 | 0.850 |
| 32 | 0.140 | 0.947 | 0.443 | 0.850 |
| 33 | 0.136 | 0.949 | 0.414 | 0.849 |
| 34 | 0.131 | 0.951 | 0.455 | 0.837 |
| 35 | 0.128 | 0.952 | 0.421 | 0.842 |
| 36 | 0.125 | 0.953 | 0.432 | 0.840 |
| 37 | 0.124 | 0.955 | 0.449 | 0.840 |
| 38 | 0.122 | 0.953 | 0.420 | 0.848 |
| 39 | 0.118 | 0.956 | 0.428 | 0.852 |
| 40 | 0.118 | 0.956 | 0.444 | 0.857 |
| 41 | 0.115 | 0.958 | 0.440 | 0.856 |
| 42 | 0.112 | 0.959 | 0.426 | 0.853 |
| 43 | 0.109 | 0.960 | 0.447 | 0.844 |
| 44 | 0.109 | 0.960 | 0.461 | 0.841 |
| 45 | 0.107 | 0.961 | 0.474 | 0.842 |
| 46 | 0.106 | 0.961 | 0.479 | 0.847 |
| 47 | 0.106 | 0.961 | 0.490 | 0.846 |
| 48 | 0.102 | 0.963 | 0.437 | 0.854 |
| 49 | 0.101 | 0.963 | 0.503 | 0.851 |
| 50 | 0.100 | 0.964 | 0.506 | 0.858 |
bestepochは18で, 学習時の正答率は, 学習データでは0.90945, テストデータでは0.8490であった. 汚しを加えた上で学習したモデルでの正誤判定の結果は以下の様になった.
| 判定 | 正答 | |
|---|---|---|
| 問題1 | ◯ | ◯ |
| 問題2 | ◯ | ◯ |
| 問題3 | ◯ | ◯ |
| 問題4 | × | × |
| 問題5 | ◯ | × |
| 問題6 | × | × |
| 判定 | 正答 | |
|---|---|---|
| 問題1 | ◯ | ◯ |
| 問題2 | ◯ | ◯ |
| 問題3 | × | ◯ |
| 問題4 | ◯ | ◯ |
| 問題5 | × | ◯ |
| 問題6 | ◯ | ◯ |
画像(1)については判定失敗が問題5のみの1つになっているが, 汚しを加える前とは判定を失敗する問題も異なる.
ここで, 正誤判定の為に学習したそれぞれの場合について, 学習の進捗を比較する. 学習の繰り返し毎のテストデータにおけるloss値とaccuracy値のグラフから, 比較, 検討する.
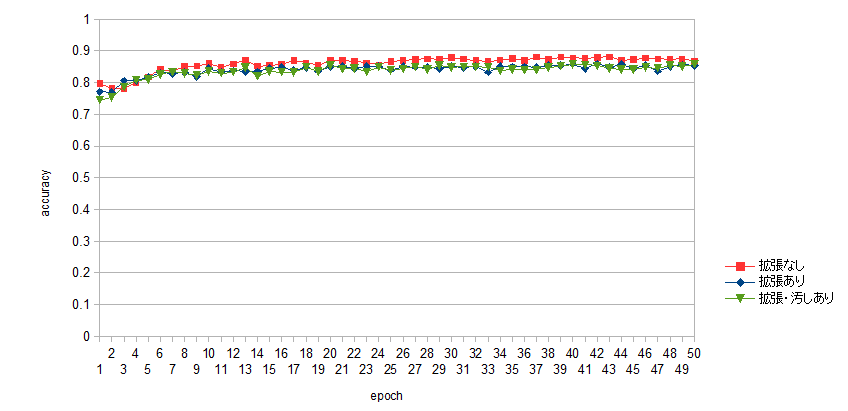
学習におけるloss値, accuracy値の比較のグラフを図15, 16に示す.
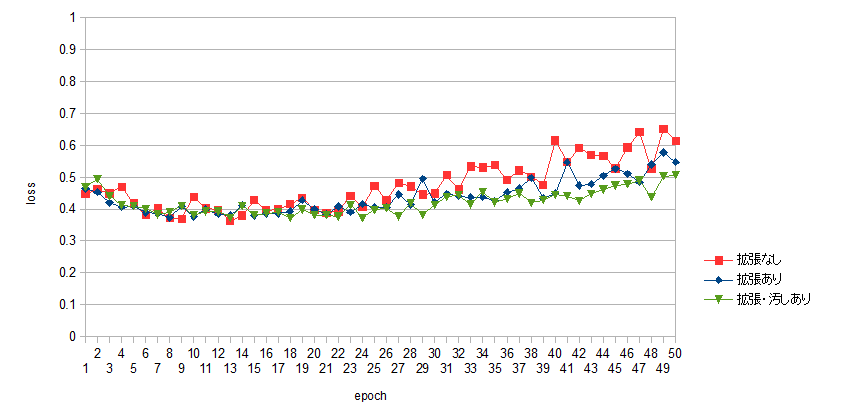
loss値について検討すると, epoch数が多くなるにつれて, loss値の差が大きくなっている. データ拡張なしのデータ量が少ない場合の学習では, loss値が顕著に多くなっている. これはデータの種類が少ないことによる過学習の結果である. データ量が同じでも, 汚しの有無によってloss値に違いがあることも確認できる. データの拡張量はどちらも同じであるため, 学習とは無関係にランダムな要素を含むことによって, 過学習を避けることができると考えられる.
accuracy値については, データの拡張を行わない場合で最も高い値が現れている. これはテストデータが学習データと同じく, 数式の位置や角度のズレを伴わないものであるためと考えられ, 事実, 画像から切り取った数式の判定はうまくいかなかった.
データの拡張を行った場合は, 汚しの有無に関わらず正答率はあまり変わらなかった. テストするデータにも汚れを含むものがあれば正答率にも影響したのかもしれないが, 今回のテストデータでは影響は見られなかった.
本実験では, 手書き風フォントを用いて数式画像を作成し, 出力となるラベルデータを変えてニューラルネットワークによる学習を行った. 学習モデルを用いた画像認識では, 学習したデータと同様にして生成された数式画像と, 手書きによる回答を想定して作成した画像を切り取った数式の2つを取り上げた. 識別するデータが学習データと同様の形式を持ち, 位置や角度の違い等を考慮しなければ, 高い正答率で認識することが可能であったが, 手書きを想定して画像から切り取ったものは数式自体以外にも学習データとの微妙な差異を生じるため, 数式画像をただ学習させるだけでは画像認識として機能しなかった.
しかしながら, 画像に対して平行移動や回転の操作をランダムに加えることでデータに幅を与えることができ, 位置や角度が一定でない数式についても認識ができたことによって, ニューラルネットを用いた画像認識の有用性を確認することができた. また, 学習データの無関係な要素, 今回は黒点による汚しをランダムに加えることによって, 過学習を軽減することができた. 本実験から, ニューラルネットによる学習では, 認識する対象の様々な場合を考慮し, それに対応して幅広いデータを学習させることが必要であると考える.
本実験で行った正誤判定は, 12問の判定を行った中でも誤判定が起こり, 正確な結果は期待できなかった. しかし, 数式の表す内容を知らずとも, 正答・誤答を教師データとすることで学習ができたことは有用であると考える. 本実験の様に手書き風のフォントによるデータでなく, 実際の正答・誤答のデータを利用し, またそのデータ量もより膨大になっていくことで, より豊富なデータを学習することができれば, 記述式問題の回答評価にも機械学習が利用できると考え, また実際の手書き回答に対してもこの学習実験を応用することを今後の課題としたい.