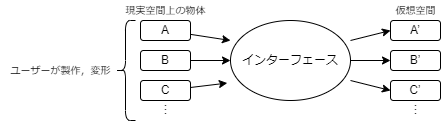
図1.1 本研究の目指すシステム
現在,ゲームで出来るようになった体験が様々であるが,従来のコントローラでは可能な体験が限られてしまうと感じた. 例を挙げると,任天堂のWiiリモコンや銃の形を模したコントローラなど,直感的な操作を可能にするデバイスが開発されているが,可能な操作は ポインタによる操作,コントローラを振る,ボタンを押す,トリガーを引くなどで限られてしまう. 本研究では,コントローラなどのゲームへの入力デバイスをより抽象的な存在として捉え,ユーザーのクリエイティビティも付加できるようなシステムを目指した. 具体的に述べると,木の棒がゲーム中では伝説の勇者の剣として扱える,ブロック遊びなどで飛行機に見立てて作った作品をゲーム中の実際の飛行機として再現できる, 簡単な形をした絵をゲーム中に実際の物体に近い形状で再現させるなど,ユーザーの想像力を反映し,具現化されるようなシステムである. このようなシステムでは,ユーザーはあらゆる形のコントローラを手にする体験ができ,実際に想像した物を扱うような感覚で,より直感的な操作が可能になると考える.
本研究では,図1.1のようにユーザーが用意した現実空間の物体をインターフェースを用いて仮想空間上に出力するシステムの構築を目的とし, その中で,現実空間の物体に,安価で加工が簡単な折り紙を用いて仮想空間上に作用させるシステムの構築を研究の目的とした.
図1.1 本研究の目指すシステム
また,前述した目的を達成するためには,以下の2つの条件を満たす必要があると考える.
本研究ではPythonを用いて折り紙の形状を学習させた後に, 学習結果からUnity上で折り紙の形状を推論させ,推論結果からUnity上のゲームに入力信号を発生させ仮想空間に作用をさせた.
本研究で行った実験の構成図を以下の図1.2に示す.
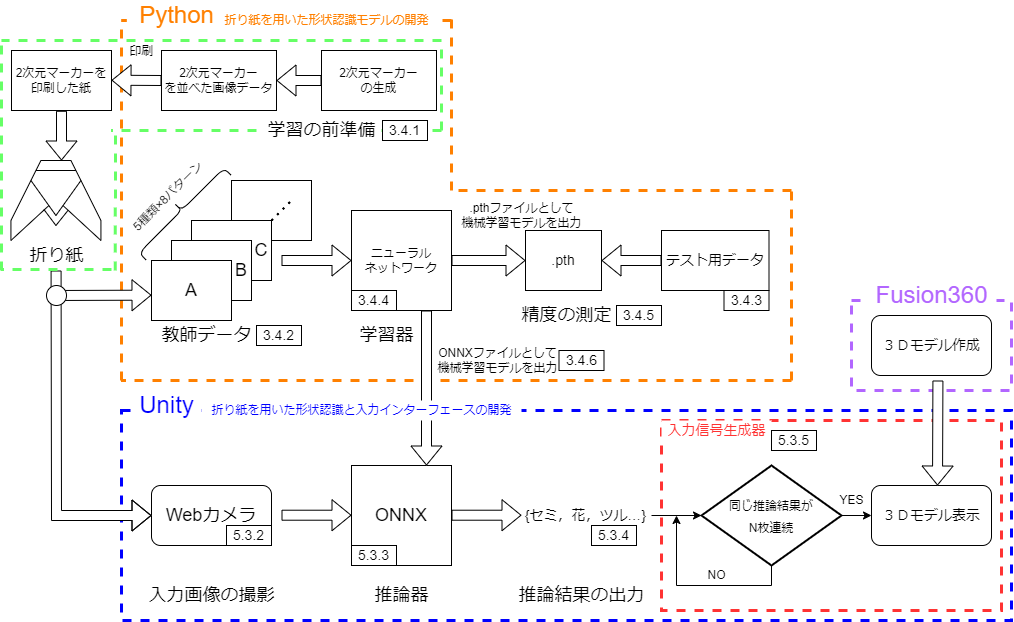
図1.2 本実験の構成図
以下に本論文の構成を示す.
本章では,従来の研究と関連技術を詳細に述べる.
非定型物体をゲームのコントローラとして扱う技術には,ソニー・インタラクティブエンタテインメント株式会社が 米国の特許に出願した”SYSTEM AND METHOD FOR GENERATING USER INPUTS FOR A VIDEO GAME”[1]がある. この技術は,マーカーを持たない非発行物体を撮影し,輪郭検出や機械学習モデルの出力を用いて物体の姿勢を検出し, 検出された物体の変化に応じた入力信号を生成する技術である.
三谷純氏の論文[2]では,20cm四方の紙にそれぞれの座標の情報を持たせた二次元バーコードを20x20で配置し,二次元コードのデコード,計算を行い折り紙の折り方の推定をしていた.
実験の結果より,幼児を対象にした簡単な折り紙では80\%の割合で折り方の推定が可能であったが, 伝承的に折られている複雑な形になると折り方の推定が可能であった割合は26%まで減少した.また,立体物には対応されないという制約がある.
PyTorchは,GPUやCPUを用いた深層学習用に最適化されたPythonのオープンソースの機械学習ライブラリである.
特徴として,GPUによる強力なアクセラレーションを備えたテンソル計算が可能,テープベースの自動微分で構築されたディープニューラルネットワークである部分が挙げられる.[3][4]
RezNetとは,"Deep Residual Learning for Image Recognition"で提案された,残差ネットワークを複数個つなげたネットワークで構成された,入力データが残差ネットワークを通過した場合と通過していない場合の差分を計算し,それを用いて学習をするモデルである.
PyTorchでは,18,34,50,101,152層のRezNetが用意されている.[5][6]
.pthファイルとは,PyTorchで出力された,学習済みモデルの学習済みパラメータである.
torch.save()関数を用いて出力が可能であり,モデルの復元が容易なため,PyTorchでは推奨されている.[7]
Open Neural Network Exchange(ONNX)とは,計算グラフモデル,組み込み演算子や標準的なテータ型が定義されているオープンソースのエコシステムである.
PyTorchでは,torch.onnx.export関数でONNXファイルの出力が可能であり,UnityやTensorFlowなどの外部ソフトでの読み込みが可能である.[8][9][10]
本章では,従来の研究と関連技術を述べた.
本章では,実験に使用した機材,Pythonを用いた折り紙の形状認識モデルの開発,実装を詳細に述べる.
本実験で使用した機材を以下に示す.
二次元マーカーを複数個印刷した紙で折り紙を作成し,Pythonを用いて折り紙の形状を認識しその折り紙が何を表しているかを推測する学習モデルを生成した.
折り紙を用いた形状認識モデルの開発の構成図を図3.1に示す.
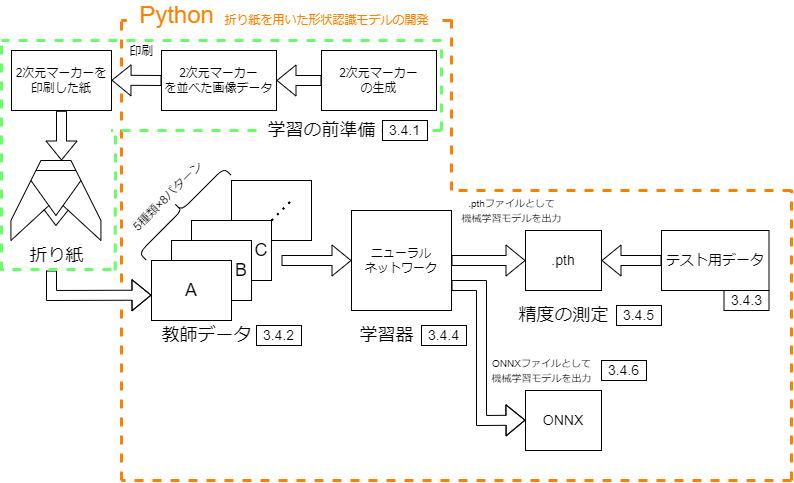
図3.1 折り紙を用いた形状認識モデルの開発
3.4.1では,学習の前準備として二次元マーカーの生成,二次元マーカーを複数個配置した折り紙用の印刷データの作成, 印刷をした紙での折り紙の作成を述べる.
3.4.2では,2種類のカメラを用いた3.4.1で作成した折り紙の撮影,PythonとOpenCVを用いた複数種類の教師データの作成方法を述べる.
3.4.3では,学習モデルで行った推論の精度測定の際に用いたテスト用画像データの作成方法を述べる.
3.4.4では,PyTorchを用いたニューラルネットワークの作成方法を述べる.
3.4.5では,3.4.4で学習された学習モデルである.pthファイルの出力,精度測定用の画像データを述べる.
3.4.6では,3.4.4で学習された学習モデルであるONNXファイルの出力方法を述べる.
折り紙用の紙に印刷するマーカーとして,OpenCVに含まれている二次元マーカーライブラリであるArUcoマーカーを用いた.
図3.2 ArUcoマーカーの一例
4x4ピクセルで1000番まで扱えるライブラリを使用した.
片面にマーカーを20x20個,合計で400個配置し,裏面にも同様に配置して表裏合計で800個のマーカーを配置した紙を印刷した.

図3.3 マーカーを400個並べた紙
上記で作成した紙を用いて,セミ(Cicada,図3.4),ツル(Crane,図3.5),花(Flower,図3.6),パックンチョ(Pakkuncho,図3.7),トラック(Truck,図3.8)の5種類の折り紙を作成した.

図3.4 作成したセミの折り紙

図3.5 作成した鶴の折り紙

図3.6 作成した花の折り紙

図3.7 作成したパックンチョの折り紙

図3.8 作成したトラックの折り紙
3.4.1で作成した5種類の折り紙と以下の表3.1に示すカメラ2種を用いて教師データを作成した.
表3.1 教師データ作成に用いたカメラの詳細
| カメラ | 解像度 | フレームレート[fps] | 外観 |
|---|---|---|---|
| BSWHD06MWH | 640x480 | 30 |
|
| Movio M1034K M1034K-111L | 1280x720 | 60 |
|
作成した5種類の折り紙とカメラ2種を用いて以下の表3.2に示される8種類の教師データを作成した.
表3.2 機械学習の実験内容
| ナンバリング | カメラ | 折り紙一種類に対する学習枚数[枚] | 概要 |
|---|---|---|---|
| Training1 | BSWHD06MWH | 1000 | マーカー部分の塗りつぶしのみ |
| Training2 | BSWHD06MWH | 1000 | エッジ+マーカー塗りつぶし |
| Training3 | BSWHD06MWH | 1000 | エッジ+マーカー塗りつぶし+指 |
| Training4 | BSWHD06MWH | 1000 | カラー写真 |
| Training5 | Movio M1034K | 1000 | カラー写真 |
| Training6 | BSWHD06MWH,Movio M1034K | 2000 | カラー写真 |
| Training7 | BSWHD06MWH | 2000 | カラー写真+ノイズ |
| Training8 | Movio M1034K | CIcada,Flower,Truck=1000 Crane,Pakkuncho=2000 | クロマキー合成5種類 |
すべての教師データでは,カメラで折り紙を撮影する際にArUcoマーカーが最低でも1つ認識された画像のみを使用した.また,PyTorchのtransforms.Normalize関数でmean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]で正規化をした.
Training1では,カメラBSWHD06MWHで撮影した画像を用意し,認識されたマーカーの四隅を頂点座標として四角形の内側を塗りつぶすOpenCVのfillpoly関数を用いて教師データを作成した.この際に,認識されたマーカーのIDが紙の表面にあたる1~400番の場合は赤色,紙の裏面に当たる401~800番の場合は青色で色分けをした.
学習枚数は折り紙5種類全てに対してそれぞれ1000枚,5種類の合計5000枚で学習を行った.
Training2では,カメラBSWHD06MWHで撮影した画像を用意し,物体のエッジを検出し白線で表すOpenCVのCanny関数を用いて加工を行った上に,Training1と同様にOpenCVのfillpoly関数を用いてマーカー部分を塗りつぶし教師データを作成した.
学習枚数は折り紙5種類全てに対してそれぞれ1000枚,5種類の合計5000枚で学習を行った.
Training3では,カメラBSWHD06MWHで折り紙を撮影する際に折り紙の一部分を指で隠した画像を用意し,Training2と同様の処理を行い,エッジの付加とマーカー部分の塗りつぶし加工を行い教師データを作成した.
学習枚数は折り紙5種類全てに対してそれぞれ1000枚,5種類の合計5000枚で学習を行った.
Training4では,カメラBSWHD06MWHで折り紙の一部分を指で隠した画像を用意し,画像に加工をせずに教師データを作成した.
学習枚数は折り紙5種類全てに対してそれぞれ1000枚,5種類の合計5000枚で学習を行った.
Training5では,カメラMovio M1034Kで折り紙の一部分を指で隠した画像を用意し,画像に加工をせずに教師データを作成した.
学習枚数は折り紙5種類全てに対してそれぞれ1000枚,5種類の合計5000枚で学習を行った.
Training6では,カメラBSWHD06MWHとMovio M1034Kで折り紙の一部分を指で隠した画像を用意し,画像に加工をせずに教師データを作成した.
学習枚数は折り紙5種類全てに対してそれぞれ2000枚,5種類の合計10000枚で学習を行った.
Training7では,Training4の教師データ全てに対して,σ=15でガウシアンノイズを付加し,教師データを作成した.
学習枚数は折り紙5種類全てに対してそれぞれ2000枚,5種類の合計10000枚で学習を行った.
Training8では,カメラMovio M1034Kで折り紙を撮影する際に,背景にグリーンバックを用いてクロマキー加工を施して,折り紙の部分は変更せず背景のみを5種類の背景画像に差し替えた画像を用意し,教師データを作成した.
学習枚数は,セミ,花,トラックの折り紙ではそれぞれ1000枚,ツル,パックンチョの折り紙ではそれぞれ2000枚用意し,5種類の合計7000枚で学習を行った.
Training1,Training2,Training3ではそれぞれの教師データと同様に5種類の折り紙に対して各1000枚,合計5000枚のテストデータを用意した.
Training3,Training4,Training5,Training6,Training7ではカメラBSWHD06MWHとMovio M1034Kで折り紙の一部分を指で隠した画像をそれぞれ撮影し,それぞれのカメラで撮影された5種類の折り紙に対して各1000枚,合計5000枚のテストデータを用意した.
はじめに,3.4.3で用意した教師データに前処理を行った.教師データの前処理の手順を以下に示す.
ニューラルネットワークの構築の際に,モデルはRezNet50,損失関数はPyTorchのCrossEntropyLoss関数を用いた.エポック(繰り返し回数)を100回と設定し,各エポックごとに学習データにおける損失であるTraining lossと精度の検証データにおける損失であるValidation loss,学習中に計測したTraining Accuracyと精度の検証データを用いて検証したValidation Accuracyを測定,記録した.
3.4.4で生成された.pthファイルを用いて折り紙の形状認識の推論を行った.
テストデータは,3.4.3で用意した画像から,5種類の折り紙でそれぞれ各200枚,合計1000枚をランダムで選択した.
折り紙各200枚を推論させた結果のうち,.pthファイルへの入力画像のラベルと推論結果が同じであった確率を記録した.
カメラBSWHD06MWHとMovio M1034Kで撮影されたテストデータに対して,それぞれで測定,記録を行った.
3.4.4での学習モデルを,PyTorchのtorch.onnx.export関数を用いてONNXファイルを出力した.
本章では,折り紙を用いた形状認識モデルの開発を述べた.
本章では,折り紙を用いた形状認識モデルの実験内容と実験結果を詳細に述べる.
Training1では,OpenCVで折り紙に印刷されたマーカーの四隅の座標を取得し,その範囲を塗りつぶすfillpoly関数を用いて学習させる画像を用意した.
学習に用いたセミの折り紙の画像の一例を図4.1に示す.

図4.1 Training1で使用したセミの折り紙
Training2では,Training1で作成した画像にCanny関数で輪郭の情報を付加させた画像を学習させた.
学習に用いたセミの折り紙の画像の一例を図4.2に示す.

図4.2 Training2で使用したセミの折り紙
Training3では,Training2で作成した画像に加えて指で一部分を隠した画像を学習させた.
学習に用いたセミの折り紙の画像の一例を図4.3に示す.
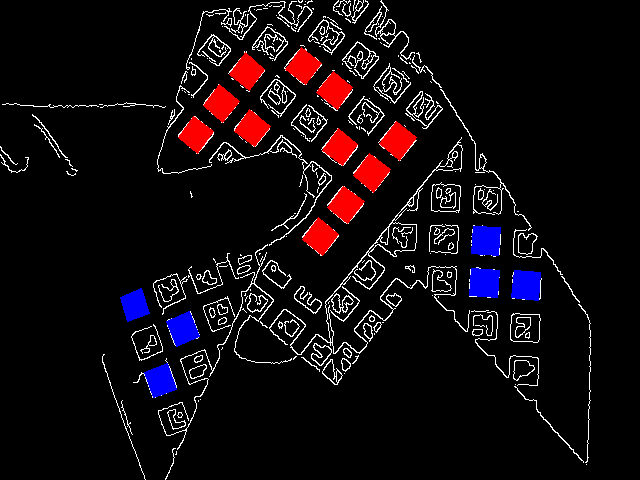
図4.3 Training3で使用したセミの折り紙
Training4では,カメラBSWHD06MWHで撮影した画像を加工せずに学習に用いた.
学習に用いたセミの折り紙の画像の一例を図4.4に示す.

図4.4 Training4で使用したセミの折り紙
Training5では,カメラMovio M1034K M1034K-111Lで撮影した画像を加工せずに学習に用いた.
学習に用いたセミの折り紙の画像の一例を図4.5に示す.

図4.5 Training5で使用したセミの折り紙
Training6では,カメラBSWHD06MWHとカメラMovio M1034K M1034K-111Lで撮影した画像をそれぞれ1000枚加工せずに学習に用いた.
学習に用いたセミの折り紙の画像の一例を図4.6,図4.7に示す.

図4.6 Training6で使用したセミの折り紙 カメラ:BSWHD06MWH

図4.7 Training6で使用したセミの折り紙 カメラ:Movio M1034K M1034K-111L
Training7では,カメラBSWHD06MWHで撮影した画像1000枚に加え,カメラBSWHD06MWHで撮影した画像にσ=15でガウシアンノイズを付加した画像1000枚を学習に用いた.
学習に用いた無加工のセミの折り紙の画像の一例を図4.8,ガウシアンノイズを付加したセミの折り紙の画像の一例を図4.9に示す.

図4.8 Training7で使用した無加工のセミの折り紙

図4.9 Training7で使用したガウシアンノイズを付加したセミの折り紙
Training8では,カメラMovio M1034K M1034K-111Lで撮影した画像にグリーンバックを用いてクロマキー加工を行った画像を画像1000枚を学習に用いた.
背景画像を5種類用意し,それぞれにセミの折り紙を追加した画像を図4.10,図4.11,図4.12,図4.13,図4.14に示す.

図4.10 Training8で使用した赤い背景のセミの折り紙

図4.11 Training8で使用した緑色の背景のセミの折り紙

図4.12 Training8で使用した青い背景のセミの折り紙

図4.13 Training8で使用した机を背景としたセミの折り紙

図4.14 Training8で使用した壁を背景としたセミの折り紙
Training1で学習を行った際のlossの遷移を示すグラフを図4.15に,accuracyの遷移を示すグラフを図4.16に示す.縦軸はloss及びaccuracy,横軸はいずれもエポック(繰り返し回数)である.
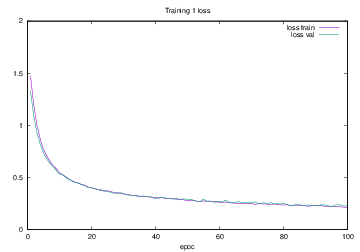
図4.15 Training1でのloss
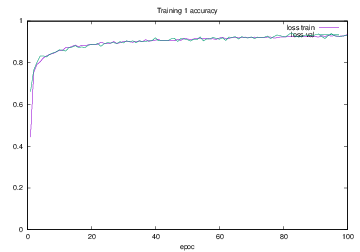
図4.16 Training1でのaccuracy
Training1の学習画像と同様に撮影した1000枚の画像の中からランダムで選択した200枚を対象に行なったテストの結果を以下の表4.1に示す.
表4.1 Training1での推論結果[%]
![表4.1 Training1での推論結果[%]](pic/table/4_3_1.png)
表4.1より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表4.2に示す.
表4.2 Training1での各折り紙に対する精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 97.00 |
| Crane | 87.00 |
| Flower | 98.00 |
| Pakkuncho | 87.00 |
| Truck | 97.50 |
| 平均 | 93.30 |
Training2で学習を行った際のlossの遷移を示すグラフを図4.17に,accuracyの遷移を示すグラフを図4.18に示す.縦軸はloss及びaccuracy,横軸はいずれもエポック(繰り返し回数)である.
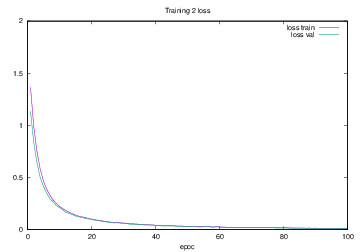
図4.17 Training2でのloss
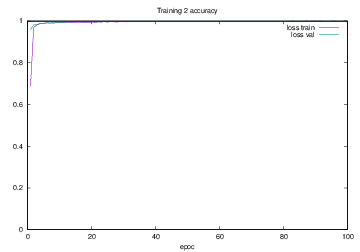
図4.18 Training2でのaccuracy
Training2の学習画像と同様に撮影した1000枚の画像の中からランダムで選択した200枚を対象に行なったテストの結果を以下の表4.3に示す.
表4.3 Training2での推論結果[%]
![表4.3 Training2での推論結果[%]](pic/table/4_3_2.png)
表4.3より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表4.4に示す.
表4.4 Training2での各折り紙に対する精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 99.00 |
| Crane | 99.50 |
| Flower | 97.50 |
| Pakkuncho | 99.50 |
| Truck | 98.50 |
| 平均 | 98.80 |
Training3で学習を行った際のlossの遷移を示すグラフを図4.19に,accuracyの遷移を示すグラフを図4.20に示す.縦軸はloss及びaccuracy,横軸はいずれもエポック(繰り返し回数)である.
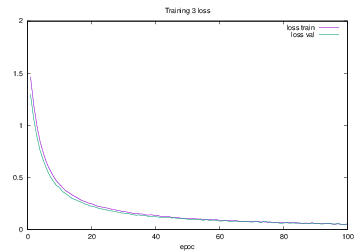
図4.19 Training3でのloss
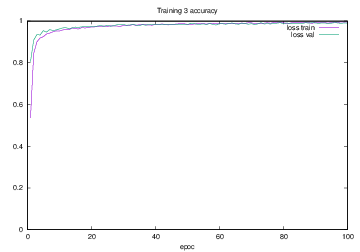
図4.20 Training3でのaccuracy
Training3の学習画像と同様に撮影した1000枚の画像の中からランダムで選択した200枚を対象に行なったテストの結果を以下の表4.5に示す.
表4.5 Training3での推論結果[%]
![表4.5 Training3での推論結果[%]](pic/table/4_3_3.png)
表4.5より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表4.6に示す.
表4.6 Training3での各折り紙に対する精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 80.00 |
| Crane | 96.50 |
| Flower | 80.50 |
| Pakkuncho | 84.00 |
| Truck | 98.50 |
| 平均 | 87.90 |
Training4で学習を行った際のlossの遷移を示すグラフを図4.21に,accuracyの遷移を示すグラフを図4.22に示す.縦軸はloss及びaccuracy,横軸はいずれもエポック(繰り返し回数)である.
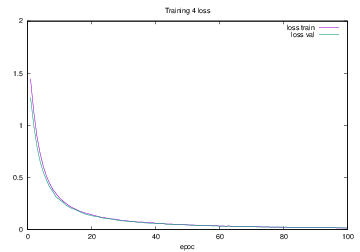
図4.21 Training4でのloss
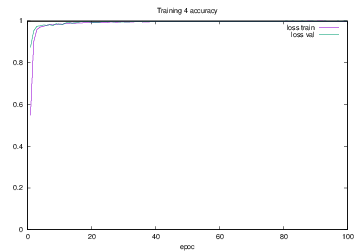
図4.22 Training4でのaccuracy
カメラBSWHD06MWHとMovio M1034K M1034K-111Lで撮影した1000枚の画像の中からランダムで選択した200枚を対象に行なった推論の結果を以下の表4.7,表4.8に示す.
表4.7 Training4での推論結果[%] カメラ:BSWHD06MWH
![表4.7 Training4での推論結果[%] カメラ:BSWHD06MWH](pic/table/4_7.png)
表4.8 Training4での推論結果[%] カメラ:Movio M1034K M1034K-111L
![表4.8 Training4での推論結果[%] カメラ:Movio M1034K M1034K-111L](pic/table/4_8.png)
表4.7,表4.8より求めた推論結果の平均を表4.9に示す.
表4.9 Training4でのカメラ2種の推論結果の平均[%]
![表4.9 Training4でのカメラ2種の推論結果の平均[%]](pic/table/4_9.png)
以上の表4.7,表4.8,表4.9より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表4.10,表4.11,表4.12に示す.
表4.10 Training4での各折り紙に対する精度 カメラ:BSWHD06MWH
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 78.50 |
| Crane | 100.00 |
| Flower | 85.00 |
| Pakkuncho | 95.50 |
| Truck | 97.50 |
| 平均 | 91.30 |
表4.11 Training4での各折り紙に対する精度 カメラ:Movio M1034K M1034K-111L
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 94.50 |
| Crane | 59.50 |
| Flower | 48.00 |
| Pakkuncho | 47.00 |
| Truck | 63.00 |
| 平均 | 62.40 |
表4.12 Training4での各折り紙に対するカメラ2種の平均精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 86.50 |
| Crane | 79.75 |
| Flower | 66.50 |
| Pakkuncho | 71.25 |
| Truck | 80.25 |
| 平均 | 76.85 |
Training5で学習を行った際のlossの遷移を示すグラフを図4.23に,accuracyの遷移を示すグラフを図4.24に示す.縦軸はloss及びaccuracy,横軸はいずれもエポック(繰り返し回数)である.
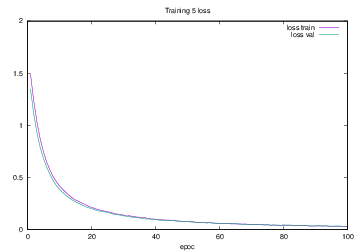
図4.23 Training5でのloss
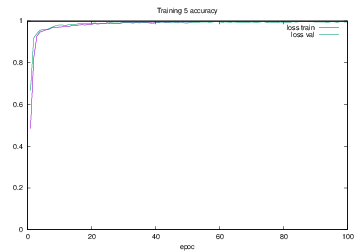
図4.24 Training5でのaccuracy
カメラBSWHD06MWHとMovio M1034K M1034K-111Lで撮影した1000枚の画像の中からランダムで選択した200枚を対象に行なった推論の結果を以下の表4.13,表4.14に示す.
表4.13 Training5での推論結果[%] カメラ:BSWHD06MWH
![表4.13 Training5での推論結果[%] カメラ:BSWHD06MWH](pic/table/4_13.png)
表4.14 Training5での推論結果[%] カメラ:Movio M1034K M1034K-111L
![表4.14 Training5での推論結果[%] カメラ:Movio M1034K M1034K-111L](pic/table/4_14.png)
表4.13,表4.14より求めた推論結果の平均を表4.15に示す.
表4.15 Training5でのカメラ2種の推論結果の平均[%]
![表4.15 Training5でのカメラ2種の推論結果の平均[%]](pic/table/4_15.png)
以上の表4.13,表4.14,表4.15より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表4.16,表4.17,表4.18に示す.
表4.16 Training5での各折り紙に対する精度 カメラ:BSWHD06MWH
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 48.00 |
| Crane | 54.00 |
| Flower | 30.50 |
| Pakkuncho | 96.50 |
| Truck | 100.00 |
| 平均 | 65.80 |
表4.17 Training5での各折り紙に対する精度 カメラ:Movio M1034K M1034K-111L
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 70.00 |
| Crane | 58.00 |
| Flower | 76.00 |
| Pakkuncho | 97.50 |
| Truck | 97.50 |
| 平均 | 79.80 |
表4.18 Training5での各折り紙に対するカメラ2種の平均精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 59.00 |
| Crane | 56.00 |
| Flower | 53.25 |
| Pakkuncho | 97.00 |
| Truck | 98.75 |
| 平均 | 72.80 |
Training6で学習を行った際のlossの遷移を示すグラフを図4.25に,accuracyの遷移を示すグラフを図4.26に示す.縦軸はloss及びaccuracy,横軸はいずれもエポック(繰り返し回数)である.
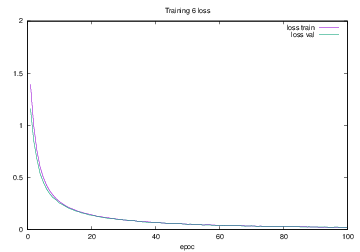
図4.25 Training6でのloss
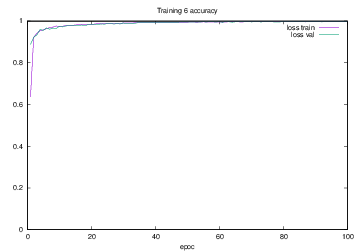
図4.26 Training6でのaccuracy
カメラBSWHD06MWHとMovio M1034K M1034K-111Lで撮影した1000枚の画像の中からランダムで選択した200枚を対象に行なった推論の結果を以下の表4.19,表4.20に示す.
表4.19 Training6での推論結果[%] カメラ:BSWHD06MWH
![表4.19 Training6での推論結果[%] カメラ:BSWHD06MWH](pic/table/4_19.png)
表4.20 Training6での推論結果[%] カメラ:Movio M1034K M1034K-111L
![表4.20 Training6での推論結果[%] カメラ:Movio M1034K M1034K-111L](pic/table/4_20.png)
表4.19,表4.20より求めた推論結果の平均を表4.21に示す.
表4.21 Training6でのカメラ2種の推論結果の平均[%]
![表4.21 Training6でのカメラ2種の推論結果の平均[%]](pic/table/4_21.png)
以上の表4.19,表4.20,表4.21より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表4.22,表4.23,表4.24に示す.
表4.22 Training6での各折り紙に対する精度 カメラ:BSWHD06MWH
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 77.50 |
| Crane | 98.50 |
| Flower | 93.50 |
| Pakkuncho | 95.00 |
| Truck | 98.50 |
| 平均 | 92.60 |
表4.23 Training6での各折り紙に対する精度 カメラ:Movio M1034K M1034K-111L
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 95.00 |
| Crane | 79.00 |
| Flower | 79.00 |
| Pakkuncho | 88.50 |
| Truck | 98.00 |
| 平均 | 87.90 |
表4.24 Training6での各折り紙に対するカメラ2種の平均精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 86.25 |
| Crane | 88.75 |
| Flower | 86.25 |
| Pakkuncho | 91.75 |
| Truck | 98.25 |
| 平均 | 90.25 |
Training7で学習を行った際のlossの遷移を示すグラフを図4.27に,accuracyの遷移を示すグラフを図4.28に示す.縦軸はloss及びaccuracy,横軸はいずれもエポック(繰り返し回数)である.
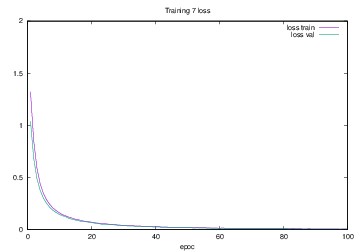
図4.27 Training7でのloss
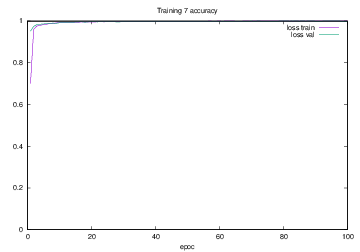
図4.28 Training7でのaccuracy
カメラBSWHD06MWHとMovio M1034K M1034K-111Lで撮影した1000枚の画像の中からランダムで選択した200枚を対象に行なった推論の結果を以下の表4.25,表4.26に示す.
表4.25 Training7での推論結果[%] カメラ:BSWHD06MWH
![表4.25 Training7での推論結果[%] カメラ:BSWHD06MWH](pic/table/4_25.png)
表4.26 Training7での推論結果[%] カメラ:Movio M1034K M1034K-111L
![表4.26 Training7での推論結果[%] カメラ:Movio M1034K M1034K-111L](pic/table/4_26.png)
表4.25,表4.26より求めた推論結果の平均を表4.27に示す.
表4.27 Training7でのカメラ2種の推論結果の平均[%]
![表4.27 Training7でのカメラ2種の推論結果の平均[%]](pic/table/4_27.png)
以上の表4.25,表4.26,表4.27より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表4.28,表4.29,表4.30に示す.
表4.28 Training7での各折り紙に対する精度 カメラ:BSWHD06MWH
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 89.00 |
| Crane | 100.00 |
| Flower | 86.00 |
| Pakkuncho | 93.50 |
| Truck | 96.00 |
| 平均 | 92.90 |
表4.29 Training7での各折り紙に対する精度 カメラ:Movio M1034K M1034K-111L
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 91.00 |
| Crane | 63.00 |
| Flower | 55.00 |
| Pakkuncho | 65.50 |
| Truck | 73.00 |
| 平均 | 69.50 |
表4.30 Training7での各折り紙に対するカメラ2種の平均精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 90.00 |
| Crane | 81.50 |
| Flower | 70.50 |
| Pakkuncho | 79.50 |
| Truck | 84.50 |
| 平均 | 81.20 |
Training8で学習を行った際のlossの遷移を示すグラフを図4.29に,accuracyの遷移を示すグラフを図4.30に示す.縦軸はloss及びaccuracy,横軸はいずれもエポック(繰り返し回数)である.
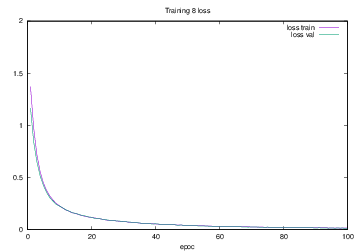
図4.29 Training8でのloss
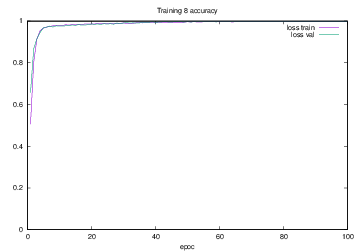
図4.30 Training8でのaccuracy
カメラBSWHD06MWHとMovio M1034K M1034K-111Lで撮影した1000枚の画像の中からランダムで選択した200枚を対象に行なった推論の結果を以下の表4.31,表4.32に示す.
表4.31 Training8での推論結果[%] カメラ:BSWHD06MWH
![表4.31 Training8での推論結果[%] カメラ:BSWHD06MWH](pic/table/4_31.png)
表4.32 Training8での推論結果[%] カメラ:Movio M1034K M1034K-111L
![表4.32 Training8での推論結果[%] カメラ:Movio M1034K M1034K-111L](pic/table/4_32.png)
表4.31,表4.32より求めた推論結果の平均を表4.33に示す.
表4.33 Training8でのカメラ2種の推論結果の平均[%]
![表4.33 Training8でのカメラ2種の推論結果の平均[%]](pic/table/4_33.png)
以上の表4.31,表4.32,表4.33より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表4.34,表4.35,表4.36に示す.
表4.34 Training8での各折り紙に対する精度 カメラ:BSWHD06MWH
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 52.50 |
| Crane | 78.00 |
| Flower | 0.00 |
| Pakkuncho | 96.50 |
| Truck | 65.50 |
| 平均 | 58.50 |
表4.35 Training8での各折り紙に対する精度 カメラ:Movio M1034K M1034K-111L
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 82.50 |
| Crane | 81.00 |
| Flower | 64.00 |
| Pakkuncho | 87.00 |
| Truck | 65.50 |
| 平均 | 76.00 |
表4.36 Training8での各折り紙に対するカメラ2種の平均精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 67.50 |
| Crane | 79.50 |
| Flower | 32.00 |
| Pakkuncho | 91.75 |
| Truck | 65.50 |
| 平均 | 67.25 |
Training1からTraining8の結果より,loss trainをまとめたグラフを図4.31に示す.縦軸はloss,横軸はエポック(繰り返し回数)である.
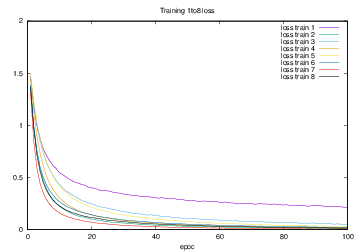
図4.31 Training1からTrainig8でのloss train
図4.31を対数グラフで表したグラフを図4.32に示す.
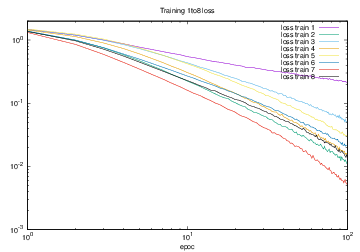
図4.32 Training1からTrainig8でのloss train
Training1からTraining8の結果より,acc trainの各値を1から引いた数値をまとめたグラフを図4.33に示す.縦軸はaccuracy,横軸はエポック(繰り返し回数)である.
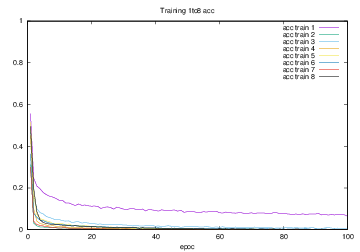
図4.33 Training1からTrainig8でのacc train
図4.33を対数グラフで表したグラフを図4.34に示す.
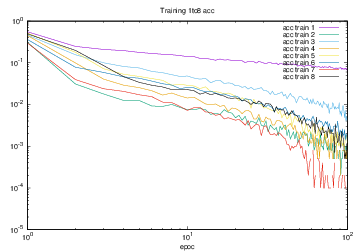
図4.34 Training1からTrainig8でのacc train
Training1からTraining8の結果より,カメラBSWHD06MWHで撮影された画像でのテスト結果をまとめた表を表4.37に示す.
表4.37 Training1からTraining8での各折り紙に対する精度[%] カメラ:BSWHD06MWH
![表4.37 Training1からTraining8での各折り紙に対する精度[%] カメラ:BSWHD06MWH](pic/table/4_37.png)
Training4からTraining8の結果より,カメラMovio M1034K M1034K-111Lで撮影された画像でのテスト結果をまとめた表を表4.38に示す.
表4.38 Training4からTraining8での各折り紙に対する精度[%] カメラ:Movio M1034K M1034K-111L
![表4.38 Training4からTraining8での各折り紙に対する精度[%] カメラ:Movio M1034K M1034K-111L](pic/table/4_38.png)
表4.37,表4.37より求めた平均の精度を表4.38に示す.
表4.38 Training4からTraining8でのカメラ2種の推論結果の平均精度[%]
本章では,折り紙を用いた形状認識モデルの実験を述べた.
本章では,Unityでの折り紙の形状認識の実装と入力インターフェースの開発ついて詳細に述べる.
折り紙を用いた形状認識モデルの開発で作成したONNXモデルを用いてUnity上で推論を行い,Fusion360で作成した3Dオブジェクトを表示させる入力信号を発生させた.また,Unityの画面出力先をOculusQuest2に設定し,仮想空間上のオブジェクトの変化を確認した.
折り紙を用いた形状認識と入力インターフェースの開発の構成図を図5.1に示す.
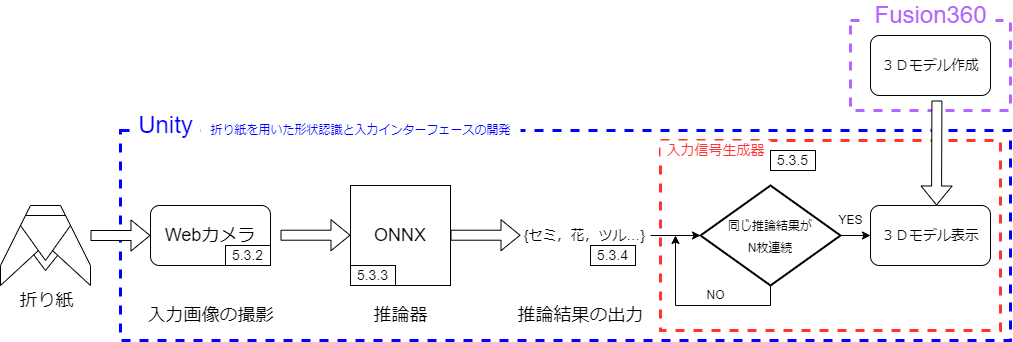
図5.1 折り紙を用いた形状認識と入力インターフェースの開発
5.3.1では,Unityでのシーンとファイルの構成を述べる.
5.3.2では,カメラMovio M1034Kで撮影された画像をUnityの推論器へ入力するために施した加工を述べる.
5.3.3では,3.4.6で出力されたONNXファイルをUnityで読み込み,5.3.2 から入力された画像の推論,推論結果の出力方法を述べる.
5.3.4では,5.3.3での推論の精度の測定方法を述べる.
5.3.5では,Fusion360での3Dモデルの作成と5.3.3での推論結果に応じたゲーム内への入力信号の発生方法について述べる.
Unityで構築したシーンの構成を図5.2に示す.
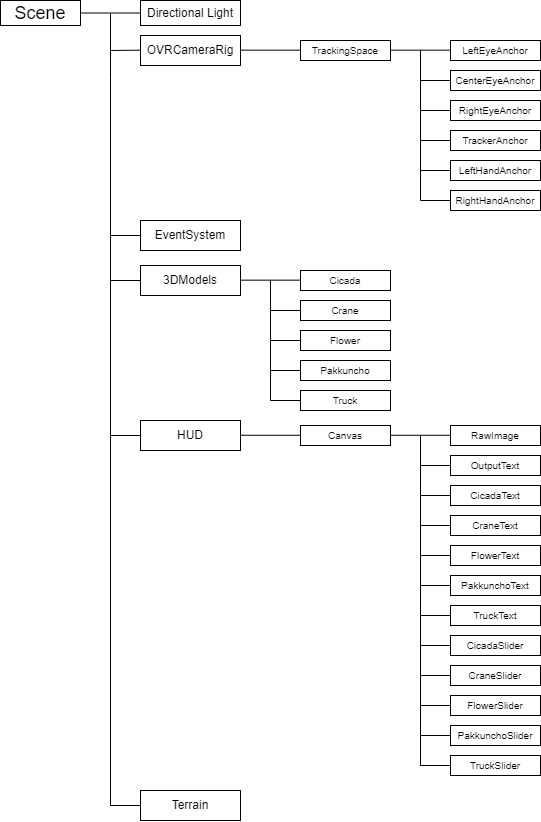
図5.2 Unityのシーン構成
Unityのシーンの画面を図5.3,図5.4に示す.
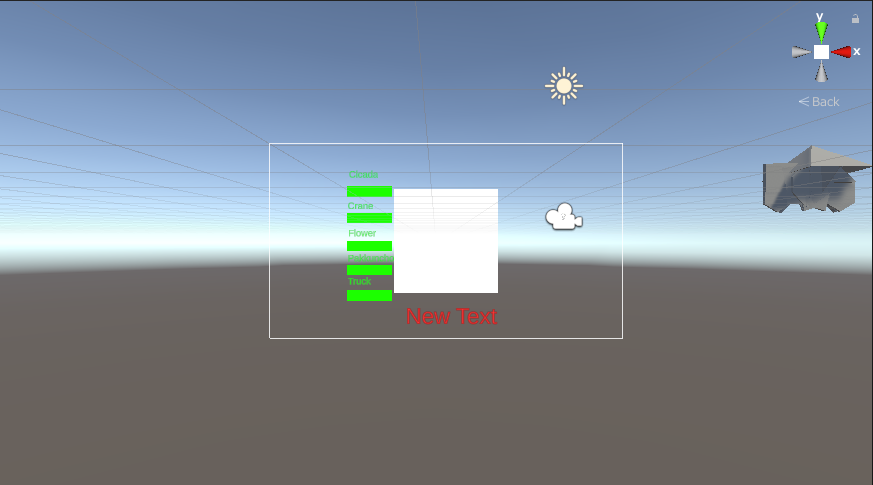
図5.3 地形データを除いたUnityのシーン
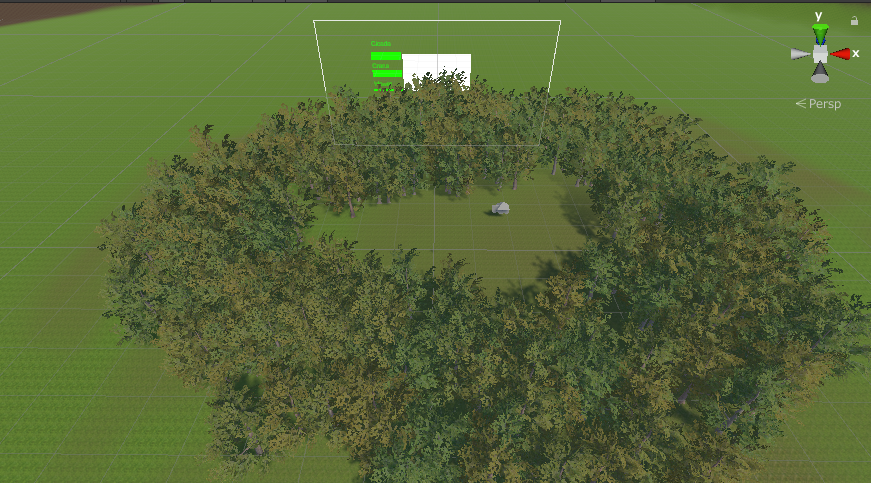
図5.4 地形データを含めたUnityのシーン
OVRCameraRigは,UnityのアセットOculus Integration 33.0で追加されたカメラライブラリであり,OculusQuest2での表示に対応している.
図5.3の中央部にはHUDファイル内のCanvasファイルを配置した.
RawImageでは,カメラで読み取った画像を表示させた.
RawImageの左側の緑色で示されている部分には各Textと各Sliderを配置し,各折り紙の推論結果を表示した.
RawImageの下部にはOutputTextを配置し推論結果の折り紙の名前を表示した.
RawImageの右側には3DModelsファイルから各折り紙に対応した3Dモデルを配置した.
Terrainは地形データであり,図5.4に示されるように地面や木などで装飾をした.
Webカメラからの入力を推論器への入力データに変換する手順を以下の図5.5に示す.
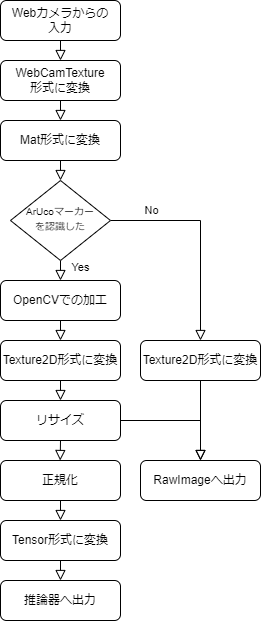
図5.5 Webカメラからの入力の処理
ArUcoマーカーが認識されなかった場合,正規化,推論器への出力はせずにRawImageへの出力のみを行った.
3.4.6で出力されたONNXファイルをModelLoader.Load関数で読み込み,WorkerFactory.CreateWorker関数で推論エンジンの生成を行った.
生成した推論エンジンに,5.3.2で作成したTensor形式のデータを読み込ませ推論を行った.
テストデータはカメラMovio M1034Kでリアルタイムで撮影した画像の中から,ArUcoマーカーが1つでも認識された画像を用いた.カメラMovio M1034Kで折り紙を撮影し,200回推論させた結果から精度を百分率で求めた.
推論器から同じ推論結果がN回連続した場合にFusion360で作成した3Dモデルを表示させた.OpenCVforUnityでArUcoマーカーが認識されなかった場合,推論結果の連続回数を0に戻した.今回の実験では,N=20とした.
本章では,折り紙を用いた形状認識と入力インターフェースの開発を述べた.
本章では,折り紙を用いた形状認識と入力インターフェースの実験内容と実験結果を詳細に述べる.
OpenCVforUnityでArUcoマーカーを認識し,マーカーの四隅の座標を頂点座標としてfillpoly関数を用いて入力画像を生成した.この際に,認識されたマーカーのIDが紙の表面にあたる1~400番の場合は赤色,紙の裏面に当たる401~800番の場合は青色で色分けをした.
推論モデルは4.2.1のTraining1の学習で生成されたONNXファイルを用いた.推論の実験を200回行い,推論結果から精度を求めた.また,200回の推論のうち,同じ推論結果が20回連続して3Dモデルが表示された回数を記録した.加えて,全体の3Dモデルが表示された回数とその中から誤って入力画像とは違う3Dモデルが表示された回数を記録し,出力の精度を求めた.
Training2では,物体のエッジを検出し白線で表すOpenCVforUnityのCanny関数を用いて加工を行った上に,Training1のモデルでの実験と同様にOpenCVのfillpoly関数を用いて入力画像を生成した.
推論モデルは4.2.2のTraining2の学習で生成されたONNXファイルを用いた.推論の実験を200回行い,推論結果から精度を求めた.また,200回の推論のうち,同じ推論結果が20回連続して3Dモデルが表示された回数を記録した.加えて,全体の3Dモデルが表示された回数とその中から誤って入力画像とは違う3Dモデルが表示された回数を記録し,出力の精度を求めた.
Training3では,Training2のモデルでの実験と同様にCanny関数とfillpoly関数を用いて入力画像を生成した.
推論モデルは4.2.3のTraining3の学習で生成されたONNXファイルを用いた.推論の実験を200回行い,推論結果から精度を求めた.また,200回の推論のうち,同じ推論結果が20回連続して3Dモデルが表示された回数を記録した.加えて,全体の3Dモデルが表示された回数とその中から誤って入力画像とは違う3Dモデルが表示された回数を記録し,出力の精度を求めた.
Training4では,OpenCVforUnityによる加工を行わずにリサイズと正規化のみで入力画像を生成した.
推論モデルは4.2.4のTraining4の学習で生成されたONNXファイルを用いた.推論の実験を200回行い,推論結果から精度を求めた.また,200回の推論のうち,同じ推論結果が20回連続して3Dモデルが表示された回数を記録した.加えて,全体の3Dモデルが表示された回数とその中から誤って入力画像とは違う3Dモデルが表示された回数を記録し,出力の精度を求めた.
Training5では,OpenCVforUnityによる加工を行わずにリサイズと正規化のみで入力画像を生成した.
推論モデルは4.2.5のTraining5の学習で生成されたONNXファイルを用いた.推論の実験を200回行い,推論結果から精度を求めた.また,200回の推論のうち,同じ推論結果が20回連続して3Dモデルが表示された回数を記録した.加えて,全体の3Dモデルが表示された回数とその中から誤って入力画像とは違う3Dモデルが表示された回数を記録し,出力の精度を求めた.
Training6では,OpenCVforUnityによる加工を行わずにリサイズと正規化のみで入力画像を生成した.
推論モデルは4.2.6のTraining6の学習で生成されたONNXファイルを用いた.推論の実験を200回行い,推論結果から精度を求めた.また,200回の推論のうち,同じ推論結果が20回連続して3Dモデルが表示された回数を記録した.加えて,全体の3Dモデルが表示された回数とその中から誤って入力画像とは違う3Dモデルが表示された回数を記録し,出力の精度を求めた.
Training7では,OpenCVforUnityによる加工を行わずにリサイズと正規化のみで入力画像を生成した.
推論モデルは4.2.7のTraining7の学習で生成されたONNXファイルを用いた.推論の実験を200回行い,推論結果から精度を求めた.また,200回の推論のうち,同じ推論結果が20回連続して3Dモデルが表示された回数を記録した.加えて,全体の3Dモデルが表示された回数とその中から誤って入力画像とは違う3Dモデルが表示された回数を記録し,出力の精度を求めた.
Training8では,OpenCVforUnityによる加工を行わずにリサイズと正規化のみで入力画像を生成した.
推論モデルは4.2.8のTraining8の学習で生成されたONNXファイルを用いた.推論の実験を200回行い,推論結果から精度を求めた.また,200回の推論のうち,同じ推論結果が20回連続して3Dモデルが表示された回数を記録した.加えて,全体の3Dモデルが表示された回数とその中から誤って入力画像とは違う3Dモデルが表示された回数を記録し,出力の精度を求めた.
Training1で生成されたモデルを使用した場合のUnityでの推論結果を表6.1に示す.
表6.1 Training1のモデルでの推論結果[%]
![表6.1 Training1のモデルでの推論結果[%]](pic/table/6_1.png)
表6.1より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表6.2に示す.
表6.2 Training1のモデルでの各折り紙に対する精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 76.00 |
| Crane | 47.50 |
| Flower | 49.50 |
| Pakkuncho | 22.00 |
| Truck | 97.50 |
| 平均 | 58.50 |
同じ推論結果が20枚連続し,Unity内に3Dオブジェクトが表示された回数を以下の表6.3に示す.
表6.3 Training1のモデルでの3Dオブジェクトの表示回数[回]
![表6.3 Training1のモデルでの3Dオブジェクトの表示回数[回]](pic/table/6_3.png)
入力画像と表示された3Dオブジェクトが一致した回数を抜粋した表を以下の表6.4に示す.
表6.4 Training1のモデルでの各折り紙に対する3Dオブジェクトの表示回数
| 入力画像 | 表示回数[回] |
|---|---|
| Cicada | 3.00 |
| Crane | 0.00 |
| Flower | 0.00 |
| Pakkuncho | 0.00 |
| Truck | 7.00 |
| 平均 | 2.00 |
表6.3より,全体の出力回数,誤検出回数を求め,検出精度を求めた.出力回数と検出精度を表6.5に示す.
表6.5 Training1のモデルでの各折り紙に対する3Dオブジェクト表示の出力精度
| 全体の出力回数[回] | 11.00 |
| 誤出力回数[回] | 1.00 |
| 出力精度[%] | 90.91 |
Training2で生成されたモデルを使用した場合のUnityでの推論結果を表6.6に示す.
表6.6 Training2のモデルでの推論結果[%]
![表6.6 Training2のモデルでの推論結果[%]](pic/table/6_6.png)
表6.6より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表6.7に示す.
表6.7 Training2のモデルでの各折り紙に対する精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 22.00 |
| Crane | 40.00 |
| Flower | 86.00 |
| Pakkuncho | 31.00 |
| Truck | 99.50 |
| 平均 | 55.70 |
同じ推論結果が20枚連続し,Unity内に3Dオブジェクトが表示された回数を以下の表6.8に示す.
表6.8 Training2のモデルでの3Dオブジェクトの表示回数[回]
![表6.8 Training2のモデルでの3Dオブジェクトの表示回数[回]](pic/table/6_8.png)
入力画像と表示された3Dオブジェクトが一致した回数を抜粋した表を以下の表6.9に示す.
表6.9 Training2のモデルでの各折り紙に対する3Dオブジェクトの表示回数
| 入力画像 | 表示回数[回] |
|---|---|
| Cicada | 0.00 |
| Crane | 0.00 |
| Flower | 4.00 |
| Pakkuncho | 0.00 |
| Truck | 8.00 |
| 平均 | 2.40 |
表6.8より,全体の出力回数,誤検出回数を求め,検出精度を求めた.出力回数と検出精度を表6.10に示す.
表6.10 Training2のモデルでの各折り紙に対する3Dオブジェクト表示の出力精度
| 全体の出力回数[回] | 13.00 |
| 誤出力回数[回] | 1.00 |
| 出力精度[%] | 92.31 |
Training3で生成されたモデルを使用した場合のUnityでの推論結果を表6.11に示す.
表6.11 Training3のモデルでの推論結果[%]
![表6.11 Training3のモデルでの推論結果[%]](pic/table/6_11.png)
表6.11より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表6.12に示す.
表6.12 Training3のモデルでの各折り紙に対する精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 62.00 |
| Crane | 29.00 |
| Flower | 60.00 |
| Pakkuncho | 30.50 |
| Truck | 100.00 |
| 平均 | 56.30 |
同じ推論結果が20枚連続し,Unity内に3Dオブジェクトが表示された回数を以下の表6.13に示す.
表6.13 Training3のモデルでの3Dオブジェクトの表示回数[回]
![表6.13 Training3のモデルでの3Dオブジェクトの表示回数[回]](pic/table/6_13.png)
入力画像と表示された3Dオブジェクトが一致した回数を抜粋した表を以下の表6.14に示す.
表6.14 Training3のモデルでの各折り紙に対する3Dオブジェクトの表示回数
| 入力画像 | 表示回数[回] |
|---|---|
| Cicada | 3.00 |
| Crane | 0.00 |
| Flower | 2.00 |
| Pakkuncho | 0.00 |
| Truck | 8.00 |
| 平均 | 2.60 |
表6.13より,全体の出力回数,誤検出回数を求め,検出精度を求めた.出力回数と検出精度を表6.15に示す.
表6.15 Training3のモデルでの各折り紙に対する3Dオブジェクト表示の出力精度
| 全体の出力回数[回] | 19.00 |
| 誤出力回数[回] | 6.00 |
| 出力精度[%] | 68.42 |
Training4で生成されたモデルを使用した場合のUnityでの推論結果を表6.16に示す.
表6.16 Training4のモデルでの推論結果[%]
![表6.16 Training4のモデルでの推論結果[%]](pic/table/6_16.png)
表6.16より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表6.17に示す.
表6.17 Training4のモデルでの各折り紙に対する精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 45.50 |
| Crane | 90.00 |
| Flower | 56.50 |
| Pakkuncho | 77.00 |
| Truck | 97.00 |
| 平均 | 73.20 |
同じ推論結果が20枚連続し,Unity内に3Dオブジェクトが表示された回数を以下の表6.18に示す.
表6.18 Training4のモデルでの3Dオブジェクトの表示回数[回]
![表6.18 Training4のモデルでの3Dオブジェクトの表示回数[回]](pic/table/6_18.png)
入力画像と表示された3Dオブジェクトが一致した回数を抜粋した表を以下の表6.19に示す.
表6.19 Training4のモデルでの各折り紙に対する3Dオブジェクトの表示回数
| 入力画像 | 表示回数[回] |
|---|---|
| Cicada | 2.00 |
| Crane | 5.00 |
| Flower | 1.00 |
| Pakkuncho | 3.00 |
| Truck | 8.00 |
| 平均 | 3.80 |
表6.18より,全体の出力回数,誤検出回数を求め,検出精度を求めた.出力回数と検出精度を表6.20に示す.
表6.20 Training4のモデルでの各折り紙に対する3Dオブジェクト表示の出力精度
| 全体の出力回数[回] | 19.00 |
| 誤出力回数[回] | 0.00 |
| 出力精度[%] | 100.00 |
Training5で生成されたモデルを使用した場合のUnityでの推論結果を表6.21に示す.
表6.21 Training5のモデルでの推論結果[%]
![表6.21 Training5のモデルでの推論結果[%]](pic/table/6_21.png)
表6.21より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表6.22に示す.
表6.22 Training5のモデルでの各折り紙に対する精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 87.00 |
| Crane | 11.50 |
| Flower | 3.50 |
| Pakkuncho | 51.50 |
| Truck | 99.50 |
| 平均 | 50.60 |
同じ推論結果が20枚連続し,Unity内に3Dオブジェクトが表示された回数を以下の表6.23に示す.
表6.23 Training5のモデルでの3Dオブジェクトの表示回数[回]
![表6.23 Training5のモデルでの3Dオブジェクトの表示回数[回]](pic/table/6_23.png)
入力画像と表示された3Dオブジェクトが一致した回数を抜粋した表を以下の表6.24に示す.
表6.24 Training5のモデルでの各折り紙に対する3Dオブジェクトの表示回数
| 入力画像 | 表示回数[回] |
|---|---|
| Cicada | 3.00 |
| Crane | 0.00 |
| Flower | 0.00 |
| Pakkuncho | 2.00 |
| Truck | 7.00 |
| 平均 | 2.40 |
表6.23より,全体の出力回数,誤検出回数を求め,検出精度を求めた.出力回数と検出精度を表6.25に示す.
表6.25 Training5のモデルでの各折り紙に対する3Dオブジェクト表示の出力精度
| 全体の出力回数[回] | 20.00 |
| 誤出力回数[回] | 8.00 |
| 出力精度[%] | 60.00 |
Training6で生成されたモデルを使用した場合のUnityでの推論結果を表6.26に示す.
表6.26 Training6のモデルでの推論結果[%]
![表6.26 Training6のモデルでの推論結果[%]](pic/table/6_26.png)
表6.26より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表6.27に示す.
表6.27 Training6のモデルでの各折り紙に対する精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 78.00 |
| Crane | 51.00 |
| Flower | 67.50 |
| Pakkuncho | 83.00 |
| Truck | 100.00 |
| 平均 | 75.90 |
同じ推論結果が20枚連続し,Unity内に3Dオブジェクトが表示された回数を以下の表6.28に示す.
表6.28 Training6のモデルでの3Dオブジェクトの表示回数[回]
![表6.28 Training6のモデルでの3Dオブジェクトの表示回数[回]](pic/table/6_28.png)
入力画像と表示された3Dオブジェクトが一致した回数を抜粋した表を以下の表6.29に示す.
表6.29 Training6のモデルでの各折り紙に対する3Dオブジェクトの表示回数
| 入力画像 | 表示回数[回] |
|---|---|
| Cicada | 2.00 |
| Crane | 1.00 |
| Flower | 3.00 |
| Pakkuncho | 5.00 |
| Truck | 8.00 |
| 平均 | 3.80 |
表6.28より,全体の出力回数,誤検出回数を求め,検出精度を求めた.出力回数と検出精度を表6.30に示す.
表6.30 Training6のモデルでの各折り紙に対する3Dオブジェクト表示の出力精度
| 全体の出力回数[回] | 19.00 |
| 誤出力回数[回] | 0.00 |
| 出力精度[%] | 100.00 |
Training7で生成されたモデルを使用した場合のUnityでの推論結果を表6.31に示す.
表6.31 Training7のモデルでの推論結果[%]
![表6.31 Training7のモデルでの推論結果[%]](pic/table/6_31.png)
表6.31より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表6.32に示す.
表6.32 Training7のモデルでの各折り紙に対する精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 76.50 |
| Crane | 77.00 |
| Flower | 59.00 |
| Pakkuncho | 89.50 |
| Truck | 100.00 |
| 平均 | 80.40 |
同じ推論結果が20枚連続し,Unity内に3Dオブジェクトが表示された回数を以下の表6.33に示す.
表6.33 Training7のモデルでの3Dオブジェクトの表示回数[回]
![表6.33 Training7のモデルでの3Dオブジェクトの表示回数[回]](pic/table/6_33.png)
入力画像と表示された3Dオブジェクトが一致した回数を抜粋した表を以下の表6.34に示す.
表6.34 Training7のモデルでの各折り紙に対する3Dオブジェクトの表示回数
| 入力画像 | 表示回数[回] |
|---|---|
| Cicada | 3.00 |
| Crane | 3.00 |
| Flower | 1.00 |
| Pakkuncho | 5.00 |
| Truck | 8.00 |
| 平均 | 4.00 |
表6.33より,全体の出力回数,誤検出回数を求め,検出精度を求めた.出力回数と検出精度を表6.35に示す.
表6.35 Training7のモデルでの各折り紙に対する3Dオブジェクト表示の出力精度
| 全体の出力回数[回] | 20.00 |
| 誤出力回数[回] | 0.00 |
| 出力精度[%] | 100.00 |
Training8で生成されたモデルを使用した場合のUnityでの推論結果を表6.36に示す.
表6.36 Training8のモデルでの推論結果[%]
![表6.36 Training8のモデルでの推論結果[%]](pic/table/6_36.png)
表6.36より,入力画像と推論結果が一致した場合の数値を抜粋した表を以下の表6.37に示す.
表6.37 Training8のモデルでの各折り紙に対する精度
| 入力画像 | 精度[%] |
|---|---|
| Cicada | 75.50 |
| Crane | 44.50 |
| Flower | 0.00 |
| Pakkuncho | 72.50 |
| Truck | 59.00 |
| 平均 | 50.30 |
同じ推論結果が20枚連続し,Unity内に3Dオブジェクトが表示された回数を以下の表6.38に示す.
表6.38 Training8のモデルでの3Dオブジェクトの表示回数[回]
![表6.38 Training8のモデルでの3Dオブジェクトの表示回数[回]](pic/table/6_38.png)
入力画像と表示された3Dオブジェクトが一致した回数を抜粋した表を以下の表6.39に示す.
表6.39 Training8のモデルでの各折り紙に対する3Dオブジェクトの表示回数
| 入力画像 | 表示回数[回] |
|---|---|
| Cicada | 4.00 |
| Crane | 2.00 |
| Flower | 0.00 |
| Pakkuncho | 1.00 |
| Truck | 0.00 |
| 平均 | 1.40 |
表6.38より,全体の出力回数,誤検出回数を求め,検出精度を求めた.出力回数と検出精度を表6.40に示す.
表6.40 Training8のモデルでの各折り紙に対する3Dオブジェクト表示の出力精度
| 全体の出力回数[回] | 10.00 |
| 誤出力回数[回] | 3.00 |
| 出力精度[%] | 70.00 |
Training1からTraining8のモデルでの結果より,各モデルごとでの精度をまとめた表を表6.41に示す.
表6.41 Training1からTraining8でのモデルによる各折り紙に対する精度[%]
![表6.41 Training1からTraining8でのモデルによる各折り紙に対する精度[%]](pic/table/6_41.png)
Training1からTraining8のモデルでの結果より,各モデルごとでの3Dオブジェクトの表示回数をまとめた表を表6.42に示す.
表6.42 Training1からTraining8のモデルでの各折り紙に対する3Dオブジェクトの表示回数[回]
![表6.42 Training1からTraining8のモデルでの各折り紙に対する3Dオブジェクトの表示回数[回]](pic/table/6_42.png)
Training1からTraining8のモデルでの結果より,各モデルごとでの3Dオブジェクトの出力精度をまとめた表を表6.43に示す.
表6.43 Training1からTraining8のモデルでの各折り紙に対する3Dオブジェクトの出力精度[回]
![表6.43 Training1からTraining8のモデルでの各折り紙に対する3Dオブジェクトの出力精度[回]](pic/table/6_43.png)
本章では,折り紙を用いた形状認識と入力インターフェースの実験を述べた.
本章では,折り紙を用いた形状認識モデルの実験と,折り紙を用いた形状認識と入力インターフェースの実験の結果を基に考察を述べる.
図4.32では,Training1からTraining8のloss trainの減少を対数グラフで表した.このグラフから,最もlossの減少が大きい,すなわち学習の効率が良かったのはTraining7であるが確認できる.要因として,折り紙一種類あたりの学習枚数が2000枚であったために1エポックあたりの学習量が最も多く,教師データが通常の画像とガウシアンノイズのみを付加した画像のみで学習を行ったため,教師データによる変化が小さい画像で学習ができたために学習が早く進んだのではないかと考えられる.
また,最もlossの減少が小さい,すなわち学習の効率が悪かったのはTraining1であった.要因として,教師データの情報量の不足が考えられる.Training1の場合,数個しかマーカーが認識されなかった場合は画像の一部分にのみfillpoly関数で描画されたポリゴンが表示される.この場合,折り紙の種類によってポリゴンは区別されないため,別種の折り紙でも同じようなポリゴンの配置などで似たような画像が出力される場合がある.そのため,画像とラベルの関係性が不安定になり,学習の効率が悪くなったと考えられる.
図4.34では,Training1からTraining8のacc trainの推移を対数グラフで表した.このグラフから,最終的なaccuracyの値が最も大きかったのはTraining7の学習結果であった.要因として,lossの場合と同様に学習枚数と教師データによる影響であると考えられる.
また,最終的なaccuracyの値が最も小さかった結果はTraining1の学習結果であった.要因として,こちらもlossの場合と同様に教師データによる影響であると考えられる.
カメラBSWHD06MWHで撮影した画像を教師データとした実験のTraining1からTraining8での各折り紙に対する精度を示す表4.37より,平均の精度が最も良かった実験結果はTraining2の98.80%であった.要因として,Training2の教師データはTraining1の教師データと比較をすると,Canny関数を用いた輪郭線が追加された分情報量が増えたために判別がしやすくなったと考えられ,またTraining3以降の教師データと比較をすると指で折り紙が隠れてしまっている分の情報量が減り,またカラー写真で学習をしたために背景部分が学習結果に悪影響を与え,その結果精度が減少したと考えられる.
平均の精度が最も悪かった実験結果はTraining8の58.50%であった.要因として,Training8の教師データはCraneとPakkunchoのみ2000枚と他の3種類の倍を用意したため学習結果に偏りが出てしまい平均の精度が落ちてしまったと考えられる.表4.31より,Cicada,Flowerの結果においてはPakkunchoと推論された結果が多く平面物の認識が難しくなってしまっていた.
表4.37と表4.38を比較すると,Training5,Training8以外のTraining4,Training6,Training7において表4.38の方が精度が低い.要因として,Training5とTraining8はすべての教師データにおいてカメラMovio M1034K M1034K-111Lで撮影をした画像を用いたため,学習の際の入力画像と推論の際の入力画像の差が小さくなり,結果として精度が向上したと考えられる.
カメラMovio M1034K M1034K-111Lで撮影した画像を教師データとした実験のTraining4からTraining8での各折り紙に対する精度を示す表4.38より,平均の精度が最も良かった実験結果はTraining6の87.90%であった.要因として,折り紙一種類あたりの学習枚数が2000枚と多く,カメラMovio M1034K M1034K-111Lで撮影された画像が教師データに用いられている影響が考えられる.
平均の精度が最も悪かった実験結果はTraining4の62.40%であった.要因として,Training4は折り紙一種類あたりの学習枚数が1000枚とく,カメラBSWHD06MWHで撮影された画像のみが用いられている影響が考えられる.教師データに使用されたカメラと推論の際の入力画像に用いたカメラが違うと,精度が落ちてしまう可能性があると考えられる.
カメラ2種類で撮影した画像を教師データとした実験のTraining4からTraining8での各折り紙に対する平均精度を示す表4.39より,平均の精度が最も良かった実験結果はTraining6の90.25%であった.要因として,Training5,Training8はカメラBSWHD06MWHで撮影された画像をテストデータとした場合の精度が低く,Training4,Training7はカメラMovio M1034K M1034K-111L撮影された画像をテストデータとした場合の精度が低かったため,両方のカメラで撮影された画像をテストデータとしたTraining6がバランスが良く精度も安定していたからだと考えられる.
Training1からTraining8でのモデルによる各折り紙に対する精度を示す表6.41より,最も平均の精度が良かった実験結果はTraining7のモデルを使用した実験の80.40%であった.しかし,Flowerの推論精度が59.00\%と低く,他の推論精度と比較するとおよそ20%ほど低くなっていた.これらの原因として考えられるのは,ONNXファイルを生成する際の学習で用いた教師データが他の実験と比べると折り紙一種類辺り2000枚と多く,ガウシアンノイズを付加しただけであり教師データの中での変化が小さい事が考えられる.Training7のモデルでの推論結果を示す表6.31から,Flowerの推論の際にTruckとPakkunchoが多く出力されていたためにFlowerの精度が下がってしまったと考えられる.
Training1からTraining8のモデルでの各折り紙に対する3Dオブジェクトの出力精度を示す表6.43より,出力精度が100%であるのはTraining4,Training6,Training7であった.また,その中で全体の出力回数が最も多かった結果はTraining7のモデルで実験をした結果であった.こちらでも,Flowerの表示回数がTraining7の平均の4回を下回る1回であり,Flowerの推論が十分に機能していないと考えられる.
折り紙を用いた形状認識モデルの実験と,折り紙を用いた形状認識と入力インターフェースの実験より,学習時に用意したテスト画像でPython上で推論をした結果,最も精度が優れていたモデルと,Unity上で推論をした結果最も優れていたモデルは異なる結果が確認できた.この要因として,Python上でテストを行った際のテストデータではUnity上での推論で用いられた入力データと比較して,折り紙の撮影の際の写す角度の抜けがあったと考えられる.Python上でのテストデータは予め用意された角度からしか推論できないが,Unityでは実際の推論結果を見ながら角度を変えるられるため,推論しやすい角度の撮影が多くできるのではないかと考えられる.
実際に入力インターフェースとして活用する場合は,誤った出力がされない出力精度が重要であると考えられるため,Unity上での推論の正確性と出力精度が共に優れているTraining7のモデルが最も良い結果が得られたと考える.
本章では,折り紙を用いた形状認識モデルの実験と,折り紙を用いた形状認識と入力インターフェースの実験の結果を基に考察を述べた.
本研究では,ユーザーが用意した現実空間の物体をインターフェースを用いて仮想空間上に出力するシステムの構築を目的とし,その中で,現実空間の物体に安価で加工が簡単な折り紙を用いて仮想空間上に作用させるシステムの構築を目的とした.
目標を達成するために,Pythonを用いて折り紙の形状を学習させた後に,学習結果からUnity上で折り紙の形状を推論させ,推論結果からUnity上のゲームに入力信号を発生させる一連のシステムを構築した.
構築したシステムが目的を達成しているかを評価するために,目的にて示された2つの条件が達成されたかを述べる.
最も高い推論精度を記録した実験は,折り紙を用いた形状認識モデルの実験のカメラBSWHD06MWHで撮影した画像を教師データとした実験のTraining2の結果で,98.80%を記録した.そのため,予め用意された静止画像の場合はこちらの条件は達成できたと考えられるが,Unity上でリアルタイムで推論をさせた実験である折り紙を用いた形状認識と入力インターフェースの実験のTraining7の結果では,80.40%と目標としていた90%を下回る結果であった.実際にシステムを活用していく上で,予め用意された静止画像で推論をさせる機会は少ないと考えられ,リアルタイムでの推論で性能が発揮できる処理が重要であると考えられる.そのため,学習精度を向上させるか,リアルタイムでの推論の際により良い精度を実現できるような改良が必要であると考える.
折り紙を用いた形状認識と入力インターフェースの実験のTraining4,Training6,Training7の結果で,100%を記録した.すなわち,ゲーム上に誤った入力信号を出力させないというこちらの目標は達成できたと考えられる.しかしながら,表6.42のTraining7の項目のように200枚推論をさせて1度のみ入力信号を出力されたFlowerのような結果は,必ずしも良好な結果であるとは考えにくく,さらに高感度で正確な入力インターフェースの開発が必要であると考えられる.
以上より,序論にて掲げた目標は一部達成できたが,改良が必要な部分が見受けられた.
しかし,リアルタイムの推論によりゲーム内に対応する入力信号が出力できたために,目標としたユーザーが用意した現実空間の物体を,インターフェースを用いて仮想空間上への出力が可能なシステムの基本部分の構築に成功したと結論付ける.
今後の課題として,以下の3点が挙げられる.
モデルの改善方法として,教師データの改良が考えられる.折り紙を撮影する際に,さらに多くの角度や背景,カメラなどの環境を用意し,教師データの枚数を増やせば学習モデルの改善につながると考えられる.また,ガウシアンノイズやその他の処理を加えた画像を用意すればさらなる改善が見込めるであろう.
よりゲーム性をもたせた入力インターフェースとするためには,3Dオブジェクトを表示させるだけでなく,キャラクターやアイテムを動かすなどの入力信号の増量が重要であると考える.また,目的で述べたような抽象的な入力画像を分析して具体的な出力をするシステムを実現するためには,入力画像が何を示しているかの分析,また分析結果となる3Dオブジェクトを仮想空間に再現させるようなシステムを別途で構築する必要があると考える.
折り紙を用いた形状認識と入力インターフェースの実験では,最大フレームレートが60fpsのカメラを用いて実験を行った.しかし,実際の動作では1秒間に20枚程しか推論が出来ておらず処理による遅延が見受けられた.処理の簡易化,軽量化により高速に入力信号の生成が可能になればより直感的な入力インターフェースが実現できるであろうと考える.また,より単純なシステム構造に変更しスマートフォンやゲーム機などの処理能力が比較的低いハードウェアでも動作できるように改良を加えていきたい.
これらの改良を加え,より直感的でユーザーの創造性が生かせるようなシステムを構築していきたい.
本研究を行うにあたり,研究室配属前からご指導ご鞭撻をくださった坂本直志教授に心から感謝の意を表します.また,本研究の実験に助言をくださったネットワークシステム研究室の皆様,家族や友人の皆様にも心から感謝申し上げます.

