図1:Tony Hain氏による枯渇時期予測 上位8bitの数
指導教員 坂本 直志
02kc452 岡田 真悟
近年、インターネットは日本だけでなく世界規模で大幅に普及してきている。その普及度はインターネットが作られた当初の予想を大きく超えている。そのため、作られた当時には考えられなかった問題として、IPアドレスの不足などが発生してしまった。
これらの問題を根本的に解決するための策として、現行のIPv4(Internet Protocol version 4)の代わる次世代のインターネットにも対応できる新たなプロトコルが、IETF(Internet Engineering Task Force:インターネット特別技術調査委員会)のワークグループIPng(Internet Protocol next generation)で協議され、1994年に標準化されることとなった。これがIPv6(Internet Protocol version 6)である。つまりIPv6とは、次世代プロトコルなのである。
ところが、IPv6が標準化されてから十数年たつがIPv4にとって代わり普及しているかというと、実際はしていない。基幹ネットワークと末端ネットワークにわけて考えると、基幹ネットワークにおいては近年徐々にIPv6が導入されてきているが、末端ネットワークにおいてはインターネット全体からみるとほぼ導入されていないと言える。これは、IPv4にさまざまな問題があっても現在利用しているユーザーにとっては、あまり実感できることではなく、そのためあえてコストをかけてまでIPv6を導入しようとしないからである。また、NAT(Network Address Translation)などの一時しのぎ的な技術やハードウェアの性能向上による処理能力向上などもその要因である。
しかし、最近の予測ではアドレスの枯渇時期が当初の予測より大幅にはやまり、早ければ2009年にも枯渇してしまうという結果もでている。そのため、末端ネットワークにもIPv6導入の必要性が増してきているといえる。近年では多くのプラットフォームがIPv6に対応してきており、導入も低コストかつ簡単に行えるようになってきている。また、IPv6移行期においてはIPv4とIPv6を共存させつつIPv6に徐々に切り替えていけば、利用しているユーザーには支障なく移行を行える。
本論文では末端ネットワークにIPv6を導入する方法の研究として研究室内の小規模ネットワークをIPv6に対応させるため、移行期における共存技術のひとつである6to4を利用して、IPv6の導入実験を行った。
インターネットとは全世界規模で相互接続されたコンピュータネットワークのことである。近年では大幅に普及が進み、日常生活にも浸透してきている。インターネットではコンピュータ間で通信をおこなうさいにお互いを識別するためのIPアドレスを利用している。
IPアドレスとはネットワークに接続されたコンピュータ1台1台に割り振られた識別番号であり、インターネット上ではこの数値に重複があってはならないため、割り当てなどの管理は各国のNIC(Network Information Center)が行っている。また、インターネット上で利用される重複してはいけないIPアドレスをグローバルアドレスといい、インターネットに直接接続されていないローカルネットワークにおけるIPアドレスをローカルアドレスと呼ぶ。現在インターネットで広く利用されているIPアドレスはIPv4というインターネットプロトコルのものである。
NICとはインターネット上で利用されるIPアドレスやドメイン名などを割り当てる民間の非営利機関である。インターネットは全世界規模で広がっているため、NICも地域ごとに複数の機関がある。APNIC、RIPE-NCC、ARIN、LACNIC、AfirNICなどの広範囲の地域を管理するNICをRIR(Regional Internet Registry:地域インターネットレジストリ)と呼び、その下のJPNICなど各国にあるNICをNIR(National Internet Registry:国別インターネットレジストリ)と呼ぶ。
RIRにはさらに上部組織としICANNという組織がある。ICANNはインターネット上で利用されるアドレス資源(IPアドレス、ドメイン名、プロトコル番号など)の標準化や割り当てを行う組織であり、ここからRIRにIPアドレスの割り当て等を行う。また、ICANNの前にアドレス資源を管理していたIANAという組織があったが現在はICANNにその管理を移管された。現在では、IANAはICANNにおける資源管理・調整機能の名称として使われている。
そもそもなぜ現状のIPv4ではなぜいけないのか。まずはその理由としてIPv4の問題点を以下に述べる。
現在一番大きな問題とされてるのが、グローバルアドレスの枯渇である。IPv4のアドレス長は32bitで構成されており、これは2の32乗個、約43億個のアドレスが使えるということである。IPv4が設計された当初はここまで爆発的にインターネットが普及するとは予測されておらず、43億個もあればなくなることはないだろうということで設計された。しかし、現在においてインターネットの普及は当時の予想を大きく超え世界中に広まりつつある。その結果、43億個で足りると思われていたアドレス数が足らなくなってきているのである。2005年12月現在まだ枯渇はしていないが、枯渇するのも時間の問題だとされている。
2003年7月にAPNICのGeoff Huston氏がRIRのもつ詳細なデータを用いて解析を行った結果、アドレス割り当て累積量はほぼ線形であり、IANAのアドレス在庫が無くなるのが2021年、RIRのアドレス在庫がなくなるのが2022年という予測が出た[5]。 以来、この結果が広く引用されるようになった。
ところが、この予測の後からIPv4の消費量が増加傾向となる。RIRの公開資料による集計結果では、2003年1月〜10月に割り振られたホスト数が約6,664万ホストだったのに対して、2004年の同期間に割り振られたホスト数は約1億1,104万、2005年の同期間では1億4,854万となっている。
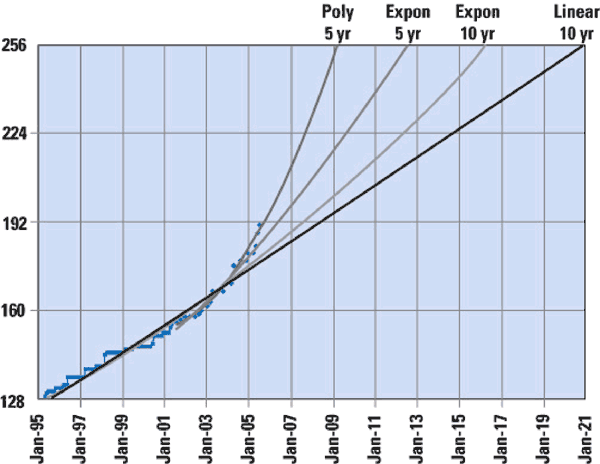
この消費量の増加により、Geoff Huston氏の予測を見直す動きが2005年夏あたりからおきた。そして、CISCOのTony Hain氏がInternet Protocol Journalの2005年9月版で「現在の消費ペースが続くとすると、早くて2009年、遅くとも2016年にはIANAの在庫が枯渇する」と発表した[5]。 その予測図を下記に示す。
その発表を受け、Geoff Huston氏も再度枯渇時期の予測を計算した結果、2005年11月の時点の予測で、IANAの在庫が無くなるのが2012年5月、RIRの在庫が無くなるのが2013年5月と発表した。両氏の予測にずれはあるものの、2003年時の予測より枯渇時期が大幅に早まっていることがわかる。これらの予測通りならば、あと10年もしないうちにIPv4アドレスは枯渇してしまうことになる。
IPv4のアドレスにはクラスという概念がある。これは、32bitのIPアドレスをネットワークアドレス部とホストアドレス部に分割する仕方で、クラスはA,B,Cの3種類がある。分割は上位8bit、16bit、24bitで分割するのがそれぞれクラスA,B,Cとなり、上位のクラスほど使えるホストアドレスが多いということである。仕様できるアドレス数を下記表に示す。
表1:IPv4アドレスのクラス
|
|
最大ネットワーク数 |
最大ホスト数 |
|---|---|---|
|
クラスA |
128 |
1,677,214 |
|
クラスB |
16,384 |
65,534 |
|
クラスC |
2,097,152 |
254 |
アドレス数の枯渇などという考えがない時代は、アドレスの配布はクラス単位で行われており、またその配布基準も厳しくなかったため、組織が申請したクラスがそのまま貰えてしまうということが多々あった。これにより、実際はそこまで多くのグローバルアドレスを必要としないのにクラスB等を持っていたりする組織が多くあった。
その結果、インターネットが普及し、多くの組織がアドレスの配布を申請をしても配布するべきクラスがなく配布できなくなるという事態が起きた。そこで、すでに配布しているアドレスを返却してもらい、クラス単位で配布するのではなく可変長ネットマスクを用いて、小さなブロックごとにアドレスを割り当てるCIDR(Classless Inter-Domain Routing)という方法で配布するなどしてきた。
しかし、そのようなアドレス配布を行ったために、同じ組織内であるのにもかかわらず違うアドレス範囲を使用するなどの問題が発生し、組織のネットワーク内のアドレスを人が意識しながら管理・運営していかなくてはいけなくなり、アドレス管理のトラブルを招く原因にもなり、管理者の負担が大きくなった。
2−2−2で述べたように、アドレスの配布は当初のクラス単位からより細かい配布をすることが多くなった。これによりアドレス数の節約は可能になったが、かわりに経路情報の増加という問題が出てきた。
これは、一つの組織が複数のアドレス範囲を持っていたりするため、経路を集約できなかったり、組織の合併などで違うアドレス体系が一つの組織になったりすることで経路情報が複雑雑多になってしまい、結果として経路情報が増加した。そのため、その処理がルータの処理能力を超えてしまう可能性も出て来た。
この問題は、現在ではルータの性能も向上したため、差し迫った問題ではなくなったが、アドレスの返却・再利用などをしていくと経路情報は今後さらに増加していくだろう。
IPv4ではグローバルアドレス不足の解決策として、NAT、NAPT(Network Address Port Translation)という技術が開発された。これは、プライベートアドレスとグローバルアドレス間の変換技術である。
NAT、NAPTを使うことにより、一つのグローバルアドレスで複数のホストがインターネットに接続することができるようになった。これらは、ローカルネットワーク内のホストがインターネットを利用して通信をするときなど、グローバルアドレスが必要な時だけそのホストのプライベートアドレスをグローバルアドレスに変換する。
これらの技術により、IPv4のグローバルアドレス不足は当面は解消されることになった。 しかし、この技術を使うと外部から内部のホストへのアクセスができなくなるという弊害がおきた。内部から外部への片方向のアクセスなら問題はないのだが、外部からもアクセスが必要な双方向な通信ができなくなってしまった。現在ではルータの設定などで内部の特定のホストへの双方向通信等はできるようになっているが、誰しもが設定ができるわけではないし、その権限があるとも限らない。そのため、現在ではEnd-to-End通信ができない環境も多くあるのである。
このように、アドレス数の枯渇、アドレス管理の複雑化、経路情報の増加、End-to-End通信の困難化などの問題を解決するために考えられたのがIPv6である。
IPv4での問題を解決するために考えられたIPv6には以下の大きな特徴がある。
上記でも述べたように、IPv4が使えるアドレス数は約43億個であるが、その配布形態により、利用できる組織数は現在のインターネット普及率を考えると少ない。そのためIPv4のアドレスはじきに枯渇してしまう。IPv6では今後こういった問題が起きないように、使えるアドレス数を大幅に増やしている。
IPv4は32ビット構成だったが、IPv6では128ビット構成となった。これは、2の128乗個、約340澗個のアドレスが使えるということである。数字にして比較してみると
IPv4=2の32乗 =4,294,967,296
IPv6=2の128乗 =340,282,366,920,938,463,463,374,607,431,768,211,456
となる。IPv4に比べて遥かに桁違いな数のアドレスが使えることがわかる。
また、使えるアドレス数が膨大なためインターネットに接続している全ホストにグローバルアドレスが割り振れ、End-to-End通信が容易になる。
IPv6のアドレスでは、クラスの概念は排除されその代わりに先頭からの数ビットのフォーマットプレフィックスに基づき、「経路集約可能ユニキャストアドレス」、「リンクローカルユニキャストアドレス」、「マルチキャストアドレス」などに分類されている。このうち、グローバルアドレスに相当するものが「経路集約可能ユニキャストアドレス」である。
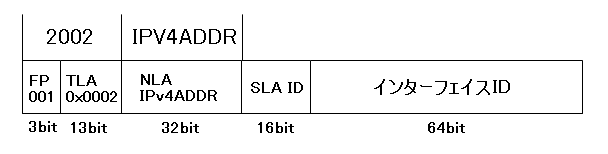
経路集約可能ユニキャストアドレスの場合、先頭の3ビットはフォーマットプレフィックスとして001(2進法表記)が割り当てられている。そして、最上位プロバイダを表すTLA(Top Level Aggregation)ID、一般プロバイダを表すNLA(Next Level Aggregation)ID、一般組織を表すSLA(Site Level Aggregation)IDがそれぞれ割り当てられる。
これにより、各IDにより階層的に経路が集約されていくので、IPv6ネットワークの経路表はIPv4ネットワークの経路表よりもはるかに小さくすることができるようになっている。結果、ルーティングが容易になり、グローバルアドレスが増えてもルータの負荷は比較的大きくならないようになっている。
IPv6ではIPv4に比べヘッダーが大幅に簡略化されている。これは、IPv4で実装されていたが、あまり利用されていない機能などを削ったためである。また、IPv4では可変長ヘッダだったがIPv6では固定長になった。詳細は2−4にて示す。
IPv6のヘッダーには拡張ヘッダーと呼ばれるものがある。これは、後々の機能追加にも対応できるように設けられたものであり、ヘッダーをいくつも含めることができる。また、拡張ヘッダーは連結が可能であり、必要な機能を組み合わせて使うことができる。現在でも「中継点オプションヘッダー」、「経路制御ヘッダー」、「断片ヘッダー」、「認証ヘッダー」、「暗号ペイロードヘッダー」、「終点オプションヘッダー」などがあり、高度なセキュリティ通信なども可能になっている。
IPv6では機器をネットワークに接続するだけでアドレスがルータから付与されるプラグアンドプレイ機能の導入が義務化された。これにより、IPv4のDHCPサーバと同様な仕組みをルータに義務づけることで、ノード側ではネットワークの設定は基本的にする必要がない。ネットワークに接続されたノードは自律的にアドレスを決定/使用開始する。
IPv6ではアドレス長が128bitになりIPv4と比べ大幅に増えた。そのため、アドレスも当然長くなり、見づらくなった。そのため表記方法にはアドレスを短く表すための2つのルールが存在する。
まず、一番基本的な省略していない表記方法を下記に示す。基本は4桁の16進数を8つ、コロンで区切って書く。
例0:3ffe:0000:0000:0012:3400:0000:5678:0001
ルール1.各16進数4桁の部分ごとに、先頭の連続する0を省略できる。これは例えば「0012」なら「12」のように、表記することができる。ただし、全て0の場合「0000」の時は0を一つ残す必要があるため、「0」となる。このルールを上記アドレスに適用すると下記のようになる。
例1:3ffe:0:0:12:3400:0:5678:1
ルール2.「:0:0:0:」など連続して0が続いた時、「::」と省略できる。ただし、「::」はアドレス全体で一度しか使えない。これは例えばアドレスの途中で「0000:0000:0000」という部分があったとしたら「::」と表記することができる。このルールを例2のアドレスに適用すると、下記のようになる。
例2:3ffe::12:3400:0:5678:1 or 3ffe:0:0:12:3400::5678:1
このルールはアドレス内で1度しか使えないため、上記の例2のようにどちらかにしか適用できない。
2−2で述べているようにIPv6のヘッダー構造はIPv4に比べて大幅に簡略されている。それぞれのヘッダー図を下記に示す。
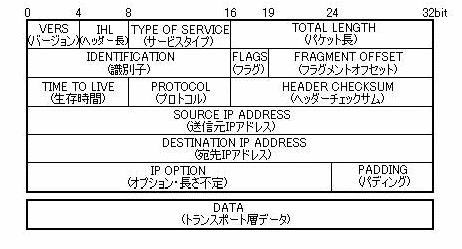
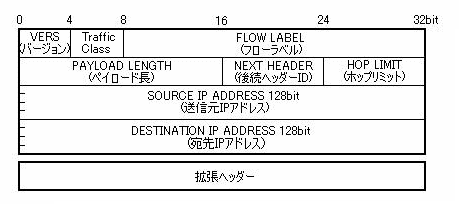
上記図を見比べると、IPv4とIPv6ではヘッダーの構造も大幅に変わったように見える。しかし、実際にはIPv6のヘッダーではIPv4から名前が変わっただけでほぼ同じ役割のフィールドもある。以下にその比較表を示す。
表2:IPv4とIPv6のヘッダー比較表
|
IPv4のフィールド名 |
IPv6のフィールド名 |
各フィールドの説明 |
|---|---|---|
|
VERS |
VERS |
IPのバージョンを示す。IPv4では4、IPv6では6が入る。 |
|
IHL |
廃止 |
Internet Header Lengthの略。 IPヘッダーの長さを表すがIPv6では40byteに固定のため廃止された。 |
|
Type of Service(TOS) |
Traffic Class |
IPパケットの品質を表す。ここで優先度や最低限の遅延で送ることや、最大限のスループットで送ることなどを指定できる。この値はアプリケーションによって指定される。しかし、広く採用されている規定はない。IPv6ではTraffic Classと名前を変えたが、IPv4と同様に標準の使用方法は規定されていない。 |
|
Total Length |
Payload Length |
パケットの長さを表す。IPv6ではPayload Lengthと名前を変えた。意味もIPv4ではIPヘッダーを含む全パケット長だったが、IPv6ではこのヘッダー以降のペイロード部分の長さ(このヘッダーの次の拡張ヘッダーを含む)に変更された。 |
|
Identification |
廃止 |
分割されたパケットの組立を補助するために、送信者によって割り当てられる識別値。IPv6では転送途中ではパケットの分割が禁止になったため、廃止となった。 |
|
Flags |
廃止 |
パケットを分割する際に使用する。IPv6では同上の理由のため廃止になった。 |
|
Fragment Offset |
廃止 |
分割されたパケットが元のデータのどこに位置するかを表す。IPv6では同上の理由のため廃止になった。 |
|
Time To Live(TTL) |
Hop Limit |
IPパケットの無限ループなどを防ぐために、パケットが破棄されるポイントを示す。パケットが転送されていく際に、値を徐々に減らしていき、0になったところでそのパケットを破棄する。IPv4の当初の仕様では値は1秒に1ずつ減らしていくという動作をするはずだったが、実際にはルータなどの中継機器を1つ経由するごとに1ずつ減らしていくという動作をするようになった。 IPv6では、この動作を明確な仕様として名前もHop Limitに変更された。 |
|
Protocol |
Next Header |
IPパケットで使用される次(上位)のレベルのプロトコルを示す。例えば、TCPパケットを運んでいるとしたら6が入る。IPv6ではヘッダーの連結構造が変わったため、意味も、このヘッダーの次に来るヘッダーのプロトコル番号と変わり、名前はNext Headerとなった。 |
|
Header Checksum |
廃止 |
IPヘッダーのチェックサムとしてCRCを格納し、ヘッダーの伝送エラーなどをチェックする。しかし、伝送エラーはIPパケットそのものを運ぶ下位レイヤーで検出されるのが通常であり、IPヘッダー独自のチェックサムにはほとんど価値がないとされたためIPv6ではヘッダーのエラー検出機構そのものが廃止された。 |
|
なし |
Flow Label |
IPv6で新設されたフィールド。送信元が中継ルータ(あるいはネットワーク)に対し、自分の送信する特定のトラフィックフローに対する特別な扱いをリクエストできるようになっている。しかし、RFC2460に含まれている説明では、「これは実験的なものであり、インターネットにおけるフローへの対処方法が明確化するとともに変化していく余地がある」とされていて、このフィールドをどう使うかについては、詳しく触れられていない。 |
上記比較表でもわかるように、基本的にIPv6のヘッダー構造はIPv4から必要ないフィールドを削りシンプルな構造にした物である。唯一「Flow Label」フィールドが新設されているが、これも今のところ明確な使用方法が決まっていない。
IPv6のヘッダーは基本部分をIPv4に比べシンプルにした分、拡張ヘッダーが新設されている。これはIPv4のOptionフィールドと同等のものである。IPv4ではこの部分に暗号化などの、さまざまな付加サービスに関する情報を書き込むようになっている。このため、ヘッダーが可変長であり、伝送経路上に存在するルータにとってはハードウェア処理がしにくい。また、ヘッダーの一部であるということから、長さが限定されてしまう難点もあった。そこで、IPv6ではヘッダーは40バイトの固定長とし、ルータの処理を高速化することができるようにされた。そして、暗号化などを使うさいの各種の拡張ヘッダーは数珠つなぎに続けられる構造であり、長さに制限がなくなった。また拡張ヘッダーは、機能別にそれぞれ用意されている。このように付加機能をそれぞれ別個のヘッダーとして独立させたことにより、将来の機能変更や追加に対応できるようになっている。
IPv6ではコンピュータ以外の端末が接続されることを想定していることなどから、管理作業を軽減し、端末がプラグアンドプレイで接続できるようにアドレス自動設定の機構が標準で取り入れられている。これは、IPv4ではDHCPサーバを設置して行う機能がIPv6ではルータに義務付けられたのである。但し、DHCPでは配布するアドレスをDHCPサーバが管理するが、IPv6では、ルータは単にネットワークアドレスを広告するだけである。端末はその広告を自らの持つインターフェイスIDから自分のIPアドレスを生成する。このプラグアンドプレイ機能のことをステートレスアドレス自動設定と呼ぶ。
IPv6でのアドレスは、1つのインターフェイスにいくつも割り当てられる。IPv6を利用するインターフェイスには、少なくとも1つ、通常はリンクローカルアドレスとグローバルアドレスの2つが割り当てられる。リンクローカルアドレスは制御用に使われるアドレスであり、グローバルアドレスは通常のデータ通信に使われるアドレスである。
IPv6のアドレスは先に述べたように、128bitで構成されている。これを、そのネットワークを示すプレフィックスと、各端末を示すインターフェイスIDの2つに分けて扱う。このうち、プレフィックスをそのネットワーク(主にルータ)が、インターフェイスIDを端末が生成し、両者を組み合わせることでIPアドレスができあがる。その構成を下記図に示す。
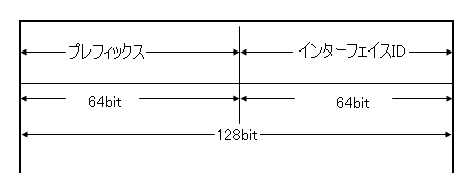
インターフェイスIDは64bitで構成されるため、4桁の16進数4つで構成される。この値の作成方法は次の通りである。
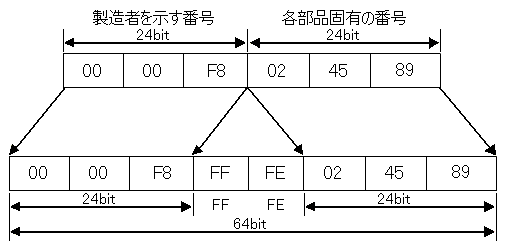
ネットワークカードにはMACアドレスというものが製造段階でつけられている。これは、16進法で表される48bitの情報で、前半24bitが製造者を示す番号となっており、IEEEによって管理されている。後半24bitは各製造者によって割り振られた各部品に固有の番号である。従って、MACアドレスが重複することはあり得ないということになっている。
このMACアドレスをIEEE EUI-64という64bitのMACアドレス体系にマッピングし、更にインターフェイスIDへとマッピングする。まずMACアドレスをEUI-64アドレスへとマッピングする方法は、MACアドレスを上位24bitと下位24bitに分け、間に「FF FE」という16bitの値を挿入するだけである。MACアドレス「00 00 F8 02 45 89」を例とした詳細を下記図に示す。
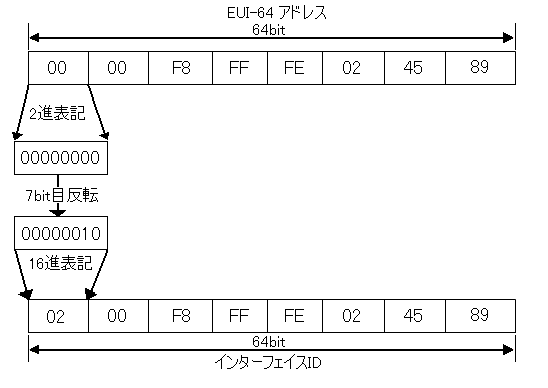
次に、上記でできたEUI-64アドレスを更にインターフェイスIDへとマッピングする。方法は、EUI-64アドレスの先頭から7bit目であるU/Lbitを補完する。これは、7bit目を反転するということである。EUI-64アドレス「00 00 F8 FF FE 02 45 89」を例とした詳細を下記図に示す。
上記のようにしてできた、インターフェイスIDを下位64bitに割り当ててIPv6のアドレスは生成される。
アドレス自動設定では、IPv6ネットワークに端末を接続すると、端末がリンクローカルアドレスを作成し、インターフェイスに割り当てる。リンクローカルアドレスは基本的に以下のように作成される。
例:fe80:0000:0000:0000:[インターフェイスID]
そして、設定したリンクローカルアドレスが重複していないことを次のように確認する。まず端末がNS(Neighbor Solicitation)メッセージをネットワークに送る。もし、そのアドレスをすでに利用している端末があればその端末がNA(Neighbor Advertisement)メッセージを送る。NSを送出した端末は、一定時間待って対応するNAが戻ってこないことを確認すると、そのリンクローカルアドレスを使用する。この段階でアドレスが重複していることがわかった場合、そのインターフェイスにアドレスを割り当てず、インターフェイスを使用停止状態にする。
リンクローカルアドレスが確定すると、端末はそのアドレスを用いて、端末から情報をリクエストするRS(Router Solicitation)メッセージをネットワークに送る。RSメッセージを受けたノード(基本的にルータ)は、プレフィックスなどの情報を含んだRA(Router Advertisement)メッセージを送る。ただし、RAメッセージは定期的に送出されているため、端末は必ずしもRSメッセージを送る必要はなく、受動的にRAメッセージを待っていてもよい。。
端末はRAメッセージを受け取り、IPv6アドレスのプレフィックスを取り出し、リンクローカルアドレスを作成した時と同様に、プレフィックスとインターフェイスIDを組み合わせてグローバルアドレスを合成する。ただし、RAメッセージはルータ毎に送出されているため、複数のルータが別々のプレフィックス情報を乗せたRAメッセージを同一ネットワークに流している場合、端末は両方を受け取り、それぞれのIPv6アドレスを作成してしまうのでRAメッセージを流す際は注意が必要である。
また、インターフェイスIDからある程度の情報が読みとれてしまうため、インターフェイスIDにあたる部分をランダムで生成しプレフィックスと組み合わせグローバルアドレスを作成する場合もある。WindowsXPなどは、このようにして生成している。
このようにして、IPv6では端末のアドレス自動設定を実現している。ただし、ステートレスアドレス自動設定では端末が自身でアドレスを生成するために、管理の手間は減る代わりに端末のアドレス設定はルータ側で管理できないことになる。
アドレス管理をしたい場合、IPv4のDHCPとほぼ同様の機能を持つDHCPv6を用いてアドレス設定を管理する方法もある。これを、ステートフル自動設定と呼ぶ。
現在ほとんどのネットワークがIPv4で構築されている。一部ではIPv6 での運用もされ始めているが、まだ多く運用されてるとはいい難い。そのため、IPv6のみのネットワークを構築しても、そのネットワークが孤立してしまいインターネットなどに繋げないのが現状である。
そのためIPv6では、IPv4からの移行が最大の問題点となっている。IPv6はIPv4と互換性がないため、いきなり切り替えるということができないのである。
そこで、IPv4からIPv6への移行するための技術が多く考案されている。それらの技術は基本的にIPv4とIPv6が混在する移行期間のために考えられており、将来IPv6のみのネットワークになった場合、使う必要性がなくなる。つまり移行期間のみ使用される技術である。
IPv6 へ移行するにあたって、IPv4とIPv6の混在期はどうやっても避けられない。そのため、混在期間中IPv4とIPv6を共存させるための技術が多く考えられた。それらの技術の基礎となる概念がいくつかある。
デュアルスタックデュアルスタックは、同一の環境、同一のインタフェース上でIPv4とIPv6を両方利用できるようにするものである。端末とルータの双方において、IPv4を継続的にサポートするとともに、IPv6もサポートできるようにする。
デュアルスタックでは、IPv6機能が追加されるものの、端末はこれまで通りIPv4上のリソースにも接続可能である。図7参照。
トンネリング(カプセル化)
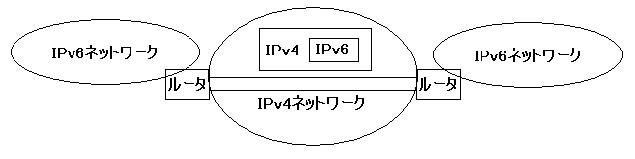
あるネットワークの中にパケットをカプセル化して通過させる技術が「トンネリング」である。IPv6ネットワーク間にIPv4ネットワークがあっても、トンネリング技術を用いることにより、IPv6のパケットを通すことができるようになる。IPv4からIPv6へ移行期のインターネットのバックボーンは基本的にIPv4で構築されている。そのため、その中をIPv6パケットを通すために IPv4パケットの中にIPv6パケットを格納するトンネリング技術を用いる必要がある。(図8参照)デュアルスタックとトンネリングを組み合わせることにより、現在のインターネットでIPv6を利用することが可能になる。図8参照。
トランスレート
トランスレートは、パケットを変換する技術である。IPv4パケットをIPv6パケットに、IPv6パケットをIPv4パケットに変換する。これをルータで行うことで、それぞれのIPしか使えない端末もお互いに通信ができるようになる。また、トランスレートにはいくつかの方式があり、ヘッダー変換などIPv6とIPv4のプロトコルを変換するものや、プロキシのように間に入って通信を代理で行なうものがある。
2−5−1の3つの概念を基礎としてIPv4とIPv6を共存させるための技術がいくつか考案されているが、本論文ではそのうちの6to4という技術を利用した。その詳細を以下に述べる。
6to4は自動トンネルを伴うカプセル化とルータのデュアルスタックを利用した技術である。6to4により作られるIPv6ネットワークのアドレスには、IPv4インターネットのグローバルアドレスを利用する。専用に予約されている16bitのIPv6プレフィックスに、この32ビットのIPv4アドレスを組み合わせることで、ルータはグローバルに一意な48bitのIPv6プレフィックスを作成する。各端末は48bitのプレフィックスと自由に定めた16bitのサブネットアドレスから一意のアドレスを与えられる。つまり、6to4ではIPv6ネットワークとIPv4ネットワークの境界において導入すればよく、このネットワーク内の端末においては移行メカニズムを実装する必要がない。
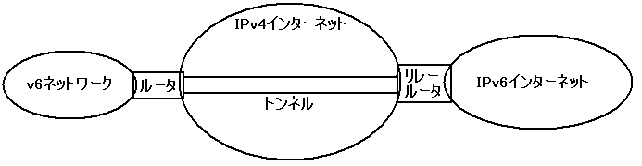
6to4では、ルータがグローバルなIPv4アドレスを1つ持っていて、かつ6to4に対応していれば、リレールータを指定するだけで、自動的にトンネル処理をしIPv6網と通信を行える。
6to4を利用するには、エッジのルータがグローバルに一意なIPv4アドレスを用い、IPv6アドレスを生成する。IPv6アドレスでは6to4用に2002というプレフィックスが割り当てられており(図10参照)、これにIPv4アドレスを組み合わせて、IPv6アドレスを生成する。アドレス生成方法の例を図11に示す。
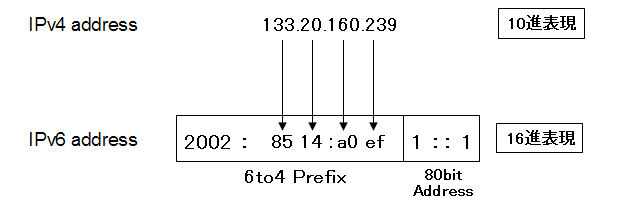
これで同一ネットワーク内において利用可能な、グローバルに一意な48bitのIPv6プレフィックスが作成できる。6to4がネットワークの境界で導入されれば、このネットワーク内の各ネットワークには16bitのサブネット番号を割り振ることがでる。つまり、これで/サブネットワークネットワークを65000以上構成することができるようになる。また、利用するIPv4アドレスはグローバルに一意なので、このアドレスから作成される48bitのIPv6プレフィックスもグローバルに一意である。したがって、サブネット番号はローカルで一意で、インターフェイスIDも一意なので、6to4で使用するIPアドレスはインターネット上で一意になる。
6to4を構成したネットワーク内では、境界のルータ以外では特に何もする必要がない。つまり、6to4 ネットワーク内の端末はIPv6に対応していれば、6to4を実装する必要がない。これらの端末に対しては、標準的な設定手法により48bitの6to4プレフィックスと自由にルータに設定したサブネット番号からアドレスが割り当てられる。
6to4導入の利点はいくつかある。
・比較的導入は簡単であり、多数のプラットフォームにサポートされている。
・レジストリへの登録なしにアドレスブロックを入手することができる。
・標準として成立している(RFC 3056)。
・パブリックな6to4リレールータが存在している。
・グローバルなIPv4アドレスが一つあれば、48bitのプレフィックスが持てるため、一つの6to4ネットワーク内で2の80乗個という膨大な数のグローバルなIPv6アドレスが利用できる。これは、全IPv4アドレス数(2の32乗個)よりも多い。
・16bitのサブネット番号を自由に定められるので、小規模から大規模なネットワークまでサポートできる。
上記の利点から、この6to4を利用して研究室内の小規模なネットワークをIPv6に対応させた。
実験では、IPv6のみのネットワークを構築するのではなく同時にIPv4も利用できるデュアルスタックなネットワークを構築していく。これは、IPv6が普及していない現状ではIPv6のみのネットワークにしてしまうとできないことが多く色々な作業に支障をきたしてしまうからである。また、ネットワーク構成は最初は最小にし、徐々に拡張していく方法を採っている。これは、いきなり大きなネットワークを組んでしまうと、失敗した時にどこが原因なのかを特定するのに時間がかかってしまうのと、最小から始めることで徐々に理解を深めていけるためである。
そして、最終的に6to4を利用した対外接続を実現する。
実験で使う機器を以下に示す。
ルータ1,2,3:PC(Celeron , 100BaseTX x2) OS:FreeBSD5.4
ホスト1,2,3:PC(Celeron , 100BaseTX x2) OS:Fedora Core 4又はWindowsXP Home Edition SP2
スイッチングハブ (Planex S-0024FF)
上記のOSを選んだ理由は、全てIPv6に対応しており、広く使われているからである。
はじめにルータ1台とホスト1台での通信実験を行う。サーバアプリケーション等はなしで双方をデュアルスタック化し、IPv4とIPv6での通信ができるようにする。図12にこの実験でのネットワーク構成図を示す。但し、ルータのIPv6アドレスは手動で設定し、ホストのIPv6アドレスはルータからの広告を受け取って自動的に生成されたものである
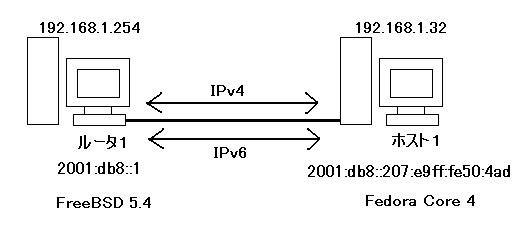
この実験では、ルータとホストを直接LANで繋ぎ、通信を行う。ホストにはFedora Core4を使用する。まずは、IPv4、IPv6が同時に利用できるようにそれぞれをデュアルスタック化する。それぞれのアドレス構成を以下に示す。
ルータ1 IPv4アドレス:192.168.1.254 IPv6アドレス:2001:db8::1
ホスト1 IPv4アドレス:192.168.1.32 IPv6アドレス:2001:db8::207:e9ff:fe50:4ad2
次に、それぞれの設定の詳細を以下に示す。
<ルータ1の設定>
ルータに使用したFreeBSD5.4は正式にIPv6をサポートしている。また、FreeBSD OSのインストール方法については割愛する。
この実験でルータの設定する項目は以下の通りである。
・IPv6を利用するための設定 ・ゲートウェイとして動作させる ・IPv4アドレスの設定 ・IPv4で利用するネットワークカードの指定 ・IPv6アドレスの設定 ・IPv6で利用するネットワークカードの指定 ・ルータ広告を流す設定とその情報の設定
FreeBSDをデュアルスタックとして動作させるためには、/etc/rc.confファイルの設定のみを編集する必要がある。また、ここではデュアルスタック化に必要な項目、主にIPv6関連だけ示す。そのため、IPv4の基本的な設定項目や他の設定項などについては割愛する。
/etc/rc.conf
ファイル内では各行に等式が書かれており、左辺が設定項目、右辺がその設定内容とな っている。
ipv6_enable="YES"
IPv6の使用を宣言する
ipv6_network_interfaces="rl0 lo0"
IPv6で利用するネットワークカードを指定する。ここでは、""内のrl0とlo0はそれぞれ、ネットワークカードとローカルループバックにOSから割り当てられた名前である。
ipv6_ifconfig_rl0="2001:db8::1"
ルータノードではIPv6アドレスは手動で設定する 必要があるため、IPv6アドレスを振りたいインター フェースをipv6_network_interfacesに指定し、各々 のインターフェースについて「ipv6_ifconfig_インタフェース名 」で128bit全てを指定する。また、プレフィックスだけ指定する方法もある。「ipv6_prefix_インタフェース名 」にプレフィックス部64ビットを指定する。ipv6_prefix_*を指定した場合、ホスト識別子にはMACアドレスから生成されるインターフェイスIDが使用される。
例:ipv6_prefix_rl0="2001:db8::"
ipv6_gateway_enable="YES"
ルータとして使用するので、ゲートウェイになるように指定する。
rtadvd_enable="YES"
rtadvdを起動する場合、YESを指定する。rtadvdとは、ルータがRAを送出するためのプログラムデーモンである。
rtadvd_interfaces="rl0"
rtadvdによりRAを流すインタフェースを指定する。RAに含まれるプレフィックス情報はそのインターフェイスに割り振られているIPv6アドレスの上位64bitが使用される。
ipv6_router_enable="YES"
IPv6ルーティングデーモン(経路制御デーモン)を起動したい場合、YESを 指定する。デフォルトで使用するデーモンは route6d(RIPng)である。他のデーモンを使用したい場合は、 ipv6_router=*で指定する。
また、IPv6アドレスは上記の項目で設定したのとは別に、リンクローカルアドレスが自動で生成される。
<ホスト1(Fedora Core4)の設定>
ホストであるFedora Core4もまた、正式にIPv6をサポートしているためネットワークの設定項目を変更するだけで利用できるようになる。
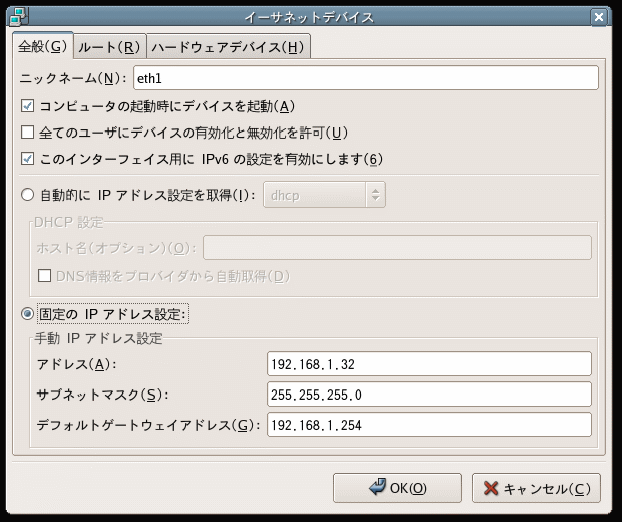
図13にある「このインターフェイス用にIPv6の設定を有効にします」にチェックをいれるだけで、自動的にリンクローカルアドレスを生成し、さらにRAメッセージを受け取れた場合、グローバルアドレスを生成する。
以上の設定をし、それぞれからPingコマンドを使い通信をした結果、IPv4、IPv6ともに通信ができることを確認した。動作確認の実行例と結果を以下に示す。
ルータの設定確認
ルータ1# ifconfig
rl0: flags=8843
ルータのルーティングテーブル
ルータ1# netstat -rn Routing tables
Internet: Destination Gateway Flags Refs Use Netif Expire 127.0.0.1 127.0.0.1 UH 0 20 lo0 192.168.1 link#1 UC 0 0 rl0 192.168.1.254 00:02:96:02:5d:87 UHLW 0 4 lo0
Internet6: Destination Gateway Flags Netif Expire ::/96 ::1 UGRS lo0 ::1 ::1 UH lo0 ::ffff:0.0.0.0/96 ::1 UGRS lo0 2001:db8::/64 link#1 UC rl0 2001:db8::1 00:02:96:02:5d:87 UHL lo0 fe80::/10 ::1 UGRS lo0 fe80::%rl0/64 link#1 UC rl0 fe80::202:96ff:fe02:5d87%rl0 00:02:96:02:5d:87 UHL lo0 fe80::207:e9ff:fe50:4b8b%fxp0 00:07:e9:50:4b:8b UHL lo0 fe80::%lo0/64 fe80::1%lo0 U lo0 fe80::1%lo0 link#4 UHL lo0 ff01::/32 ::1 U lo0 ff02::/16 ::1 UGRS lo0 ff02::%rl0/32 link#1 UC rl0 ff02::%lo0/32 ::1 UC lo0
IPv4での通信
ルータからホストへのPing
ルータ1# ping 192.168.1.32 PING 192.168.1.32 (192.168.1.32): 56 data bytes 64 bytes from 192.168.1.32: icmp_seq=0 ttl=64 time=0.422 ms 64 bytes from 192.168.1.32: icmp_seq=1 ttl=64 time=0.203 ms 64 bytes from 192.168.1.32: icmp_seq=2 ttl=64 time=0.190 ms ^C --- 192.168.1.32 ping statistics --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max/stddev = 0.190/0.272/0.422/0.106 ms
ホストからルータへのPing
ホスト1# ping 192.168.1.254
PING 192.168.1.254 (192.168.1.254) 56(84) bytes of data. 64 bytes from 192.168.1.254: icmp_seq=0 ttl=64 time=0.201 ms 64 bytes from 192.168.1.254: icmp_seq=1 ttl=64 time=0.178 ms 64 bytes from 192.168.1.254: icmp_seq=2 ttl=64 time=0.178 ms
--- 192.168.1.254 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 1999ms rtt min/avg/max/mdev = 0.178/0.185/0.201/0.019 ms, pipe 2
IPv6での通信
ルータからホストへのPing
ルータ1# ping6 2001:db8::207:e9ff:fe50:4ad2
PING6(56=40+8+8 bytes) 2001:db8::1 --> 2001:db8::207:e9ff:fe50:4ad2 16 bytes from 2001:db8::207:e9ff:fe50:4ad2, icmp_seq=0 hlim=64 time=310.192 ms 16 bytes from 2001:db8::207:e9ff:fe50:4ad2, icmp_seq=1 hlim=64 time=0.252 ms 16 bytes from 2001:db8::207:e9ff:fe50:4ad2, icmp_seq=2 hlim=64 time=0.250 ms ^C --- 2001:db8::207:e9ff:fe50:4ad2 ping6 statistics --- 3 packets transmitted, 3 packets received, 0.0% packet loss round-trip min/avg/max/std-dev = 0.250/103.565/310.192/146.108 ms
ホストからルータへのPing
ホスト1# ping6 2001:db8::1
PING 2001:db8::1(2001:db8::1) 56 data bytes 64 bytes from 2001:db8::1: icmp_seq=0 ttl=64 time=1.01 ms 64 bytes from 2001:db8::1: icmp_seq=1 ttl=64 time=0.213 ms 64 bytes from 2001:db8::1: icmp_seq=2 ttl=64 time=0.203 ms
--- 2001:db8::1 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2000ms rtt min/avg/max/mdev = 0.203/0.476/1.014/0.380 ms, pipe 2
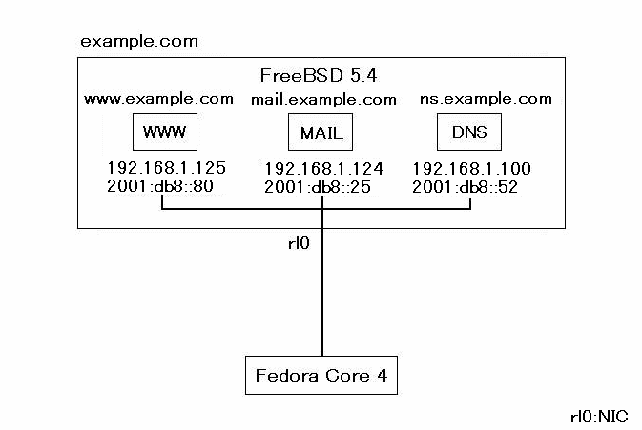
3−1で構築したネットワークのルータ機にサーバアプリケーションとして、DNSサーバ、Webサーバ、Mailサーバをインストールし、それぞれデュアルスタック化する。利用するサーバアプリケーションとネットワーク構成図は以下の通りである。
・DNSサーバ:BIND 9.3.1
・webサーバ:Apache 2.0.54
・Mailサーバ SMTPサーバ:Postfix 2.2.5
POPサーバ:Courier-IMAP
これらのアプリケーションは全てIPv6にも公式に対応しており、特別なパッチ等をあてなくてもデュアルスタック化ができる。
この実験では、サーバ機は1台だが複数のサーバアプリケーションを利用する。そこで、サーバ機に複数のIPv4、IPv6のアドレスを付与しそれぞれのアプリケーション毎に利用する。以下にそのアドレス構成図を示す。
FreeBSDでは一つのインターフェイスに複数のアドレスを割り当てることができる。そのためのrc.confの設定例を以下に示す。
/etc/rc.conf
ifconfig_rl0="inet 192.168.1.254 netmask 255.255.255.0" ifconfig_rl0_alias0="inet 192.168.1.124 netmask 255.255.255.0" ifconfig_rl0_alias1="inet 192.168.1.125 netmask 255.255.255.0" ifconfig_rl0_alias2="inet 192.168.1.100 netmask 255.255.255.0"
ipv6_ifconfig_rl0="2001:db8::1 prefixlen 64" ipv6_ifconfig_rl0_alias0="2001:db8::25 prefixlen 64" ipv6_ifconfig_rl0_alias1="2001:db8::80 prefixlen 64" ipv6_ifconfig_rl0_alias2="2001:db8::52 prefixlen 64"
上記のように各インターフェイスにaliasを使うことで複数個のアドレスを割り振ることができる。この機能を使うことでIPベースのバーチャルホストの運営を行うことができる。
デュアルスタック化されたDNSサーバでは1つのURLに対して、そのURLのサイトがデュアルスタック化されている場合にはIPv4とIPv6の2つの情報を持つ。そして、クライアントからDNSサーバに対してAAAAレコード(クワッドエーレコード)で問い合わせがあるとIPv6のIPアドレスを返し、Aレコードで問い合わせがあるとIPv4のIPアドレスを返すようになっている。
また、デュアルスタック化されたDNSサーバへのクライアントからの通信ではIPv4、IPv6のどちらからでも通信をすることができるが、これはDNSサーバへの問い合わせとは関係しない。IPv6通信でIPv4アドレスに関する問い合わせもできるしその逆もできる。DNSサーバへの通信形態についてはクライアントに依存しているためDNSサーバではどちらの通信で問い合わせがきても対応できるようになっている。
BINDはIPv6に対応しており、問題なくデュアルスタック化できる。そのための設定を以下に示す。ただし、インストール方法や基本的な設定などは割愛する。
BINDをデュアルスタック化する場合以下の設定ファイルの編集を行う必要がある。ただし、ファイル名やファイルの設置場所は各環境によって変わる。
/etc/namedb/master/localhost.rev IPv4用ループバックアドレスの逆引き定義ファイル
/etc/namedb/master/localhost-v6.rev IPv6 用ループバックアドレスの逆引き定義ファイル
/etc/namedb/master/example.com example.comドメインのゾーンファイル
/etc/namedb/master/168.192.in-addr.arpa IPv4の逆引き定義ファイル
/etc/namedb/master/0.0.0.0.8.B.D.0.1.0.0.2.ip6 IPv6の逆引き定義ファイル
/etc/namedb/named.conf ゾーンファイルのとアドレスの定義づけ
上記のファイルを用意し、named.confできちんと参照するように設定するだけで、BINDはデュアルスタック化できる。設定ファイルの内容は付録に収録する。
BINDがきちんとデュアルスタック化しているかどうか動作確認をするにはdigコマンドを利用する。その実行例と結果を以下に示す。
> dig @localhost www.example.com aaaa
; <<>> DiG 9.3.1 <<>> @localhost www.example.com aaaa ; (2 servers found) ;; global options: printcmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 36978 ;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 2, ADDITIONAL: 4
;; QUESTION SECTION: ;www.example.com. IN AAAA
;; ANSWER SECTION: www.example.com. 86400 IN AAAA 2001:db8::80
;; AUTHORITY SECTION: example.com. 86400 IN NS ns.example.com.
;; ADDITIONAL SECTION: ns.example.com. 86400 IN A 192.168.1.100 ns.example.com. 86400 IN AAAA 2001:db8::52
;; Query time: 1 msec ;; SERVER: ::1#53(::1) ;; WHEN: Mon Dec 26 16:25:25 2005 ;; MSG SIZE rcvd: 185
Webサーバのデュアルスタック化とは、サーバにIPv4、IPv6 の両方のアドレスが付与されていて、IPv4、IPv6のどちらからのアクセスも処理できるようにすることである。(図16参照)
また、基本的にはどちらからのアクセスでも同じコンテンツを表示するが、別々のコンテンツを表示させることもできる。IPv4とIPv6のそれぞれのアクセスで別々のコンテンツを表示させたい場合、2種類の方法がある。
一つ目は、それぞれのアクセスによって参照先フォルダを変える方法である。IPv4のアクセスではフォルダAのファイルを参照、IPv6のアクセスではフォルダBのファイルを参照するというように設定してやればよい。この方法ではファイル作成者は特に特殊な知識を必要としないが、フォルダが分かれてしまうため管理の手間が増えてしまう。
二つ目は、SSIによる方法である。SSIとはサーバ側で実行したコマンドの結果をWeb上に表示する機能のことで、これを使えば1つのファイルでIPv4のアクセスの場合とIPv6のアクセスの場合で表示するコンテンツを切り替えられる。ただし、作成者がSSIのための知識を持っていないといけない。
本実験ではApache2を用いて、デュアルスタック化とそれぞれのアクセスで別々のコンテンツを表示させるWebサーバを設置した。別々のコンテンツを表示させる手法としては、上記の一つ目の方法を用いた。一つ目の方法ならばApacheの設定を少し変更するだけで実現可能なためである。 Apacheの標準の設定ファイルは、httpd.confファイル内にまとめられている。以下にその設定例を示す。ただし、Apacheのインストールや標準の設定方法などはここでは割愛する。
<Apacheのデュアルスタック化の設定>
httpd.conf
ファイル内は、各行に空白で区切られた単語が並ぶが、1つめの単語が設定項目で2つめ以降が、設定する値となる。但し、複数の項目が構造を持つとき、タグにより複数の項目がまとめられる。
Listen 80
Apache2はIPv6に対応したシステム上で稼働させるとデフォルトでIPv6上での動作が可能となっている。上記のように指定すれば、利用可能な全てのIPv4、IPv6アドレスから接続を受け付けるようになる。また、Apacheデーモンを起動するためのホストのIPアドレスとポート番号を明示的に指定するこもできる。例を以下に示す。
httpd.conf
Listen 192.168.0.126:80
Listen [2001:db8::1]:80
明示的に指定する場合にはIPアドレス:ポート番号とする。IPv4の場合はアドレスを直接書けばいいが、IPv6の場合はアドレスは[]くくる必要がある。
<別々のコンテンツを表示させるための設定>
httpd.conf
# ServerAdmin webmaster@dummy-host.example.com
DocumentRoot /usr/local/www/example.org/data
ServerName www.example.com
ErrorLog /usr/local/www/example.com/log/httpd-error.log
ScriptAlias /cgi-bin/ "/usr/local/www/example.com/cgi-bin/"
CustomLog /usr/local/www/example.com/log/httpd-access.log Combined
# ServerAdmin webmaster@dummy-host.example.com
DocumentRoot /usr/local/www/example.com-v6/data
ServerName www.example.com
ErrorLog /usr/local/www/example.com-v6/log/httpd-error.log
ScriptAlias /cgi-bin/ "/usr/local/www/example.com-v6/cgi-bin/"
CustomLog /usr/local/www/example.com-v6/log/httpd-access.log Combined
別々のコンテンツを表示させるにはApacheのバーチャルホスト機能を利用する。これは、1台のマシンで仮想的に複数のWebサイトを構築する機能である。ここではIPv4アドレスとIPv6アドレスにそれぞれ参照先フォルダを指定することで、閲覧者のアクセス方法により表示コンテンツを変えることができる。
電子メールを配送するアプリケーションを一般的にメールサーバ、またはMTA(Mail Transfer Agent)と呼ぶ。MTAは、SMTP(Simple Mail Transfer Protocol)を利用して、外部のMTAから自分のMTA宛てに配送されてきたメールの受信と、外部のMTA宛てに廃そうすべきメールの送受信機能、クライアントアプリケーションからのメールの受信機能を持っている。クライアントアプリケーションは、MUA(Mail User Agen)と呼ばれる。そして、クライアントにMTAに到着したメールを渡すためのPOPやIMAPなどを利用するサーバアプリケーションは、MRA(Mail Retrieval Agent)と呼ばれる。
メールサーバを構成するのはMTAとMRAである。これらのアプリケーションはデュアルスタック化しても、機能等は変わらない。
<SMTPサーバのデュアルスタック化の設定>
SMTPサーバにはPostfix2.2を利用する。PostfixはIPv6を正式にサポートしており、簡単な設定でデュアルスタック化できる。
Postfixの基本設定ファイルはmain.cfである。以下に、設定例を示す。ただし、インストール方法や標準の設定方法などはここでは割愛する。
main.cf
inet_protocols = ipv4, ipv6
上記のように設定するだけ、IPv4、IPv6のどちらからでも通信可能となる。また、inet_protocolsには他にも以下のような設定方法がある。
inet_protocols = ipv4 (デフォルト: IPv4のみ有効)
inet_protocols = all (IPv4と、サポートされていればIPv6ともに有効)
inet_protocols = ipv4, ipv6 (IPv4とIPv6ともに有効)
inet_protocols = ipv6 (IPv6のみ有効)
このように、環境が変化してもPostfixは簡単な設定変更だけで対応できるようになっている。
Telnetを利用してPostfixにIPv6通信で接続した場合の動作確認の実行結果を以下に示す。
telnet 2001:db8::1 25
Trying 2001:db8::1...
Connected to www.example.com (2001:db8::1).
Escape character is '^]'.
220 mail.example.com ESMTP Postfix
HELO v6host.example.com
250 mail.example.com
mail from:r1@example.com
250 Ok
rcpt to:r2@example.com
250 Ok
data
354 End data with
From: r1@example.com
To: r2@example.com
Subject: test
test mail
.
250 Ok: queued as 5213B17146
quit
221 Bye
Connection closed by foreign host.
<POPサーバ>
POPサーバにはCourier-IMAPのPOP3サーバを利用する。Courier-IMAPはデュアルスタック化するのに特に設定は必要なく、デフォルトの設定で、IPv4、IPv6ともに接続ができる。以下にTlenetを利用してこのPOPサーバにIPv6通信で接続した場合の動作確認の実行結果を示す。
telnet 2001:db8::1 pop3
Trying 2001:db8::1...
Connected to mail.example.com (2001:db8::1).
Escape character is '^]'.
+OK Hello there.
user r2
+OK Password required.
pass *******
+OK logged in.
list
+OK POP3 clients that break here, they violate STD53.
1 497
2 487
.
retr 1
+OK 497 octets follow.
Return-Path:
X-Original-To: r2@example.com
Delivered-To: r2@example.com
Received: from v6host.example.com (unknown [IPv6:2001:db8::1])
by mail.example.com (Postfix) with SMTP id 238DF170B7
for
From: r1@example.com
To: r2@example.com
subject: test
Message-Id: <20051226074633.238DF170B7@mail.example.com>
Date: Mon, 26 Dec 2005 16:46:33 +0900 (JST)
test mail
.
dele 1
+OK Deleted.
quit
+OK Bye-bye.
Connection closed by foreign host.
3−2までに構築したネットワークに新たにルータ2台とホスト2台を追加し、拡大したネットワーク下での接続実験を行う。以下にネットワーク構成図を示す。
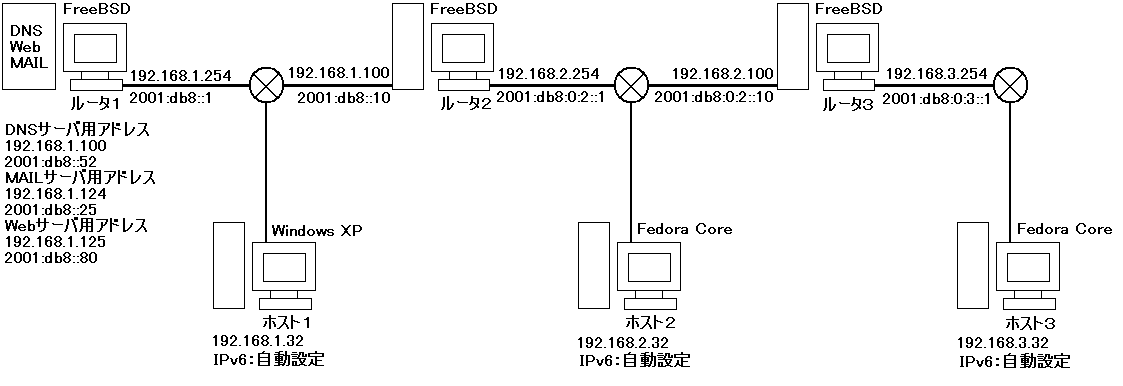
アドレスの割り当てはIPv4アドレスは手動で、IPv6アドレスはルータは手動で設定し、ホストは自動設定をするようにした。またルータ機は全てOSはFreeBSDで構築した。ルータ機能に関係する設定は基本的に全て同じである。以下にルータ機能に必要なrc.confの設定を述べる。
/etc/rc.conf
ipv6_enable="YES" #IPv6を有効にする
gateway_enable="YES" #IPv4のゲートウェイになる
ipv6_gateway_enable="YES" #IPv6のゲートウェイになる
router_enable="YES" #IPv4ルーティングデーモンを起動
ipv6_router_enable="YES" #IPv6ルーティングデーモンを起動
network_interfaces="fxp0 rl0 lo0" #IPv4で利用するネットワークカードの指定
ipv6_network_interfaces="fxp0 rl0 lo0" #IPv6で利用するネットワークカードの指定
defaultrouter="*.*.*.*" #上流にルータがある場合そのルータのアドレスを指定
ipv6_defaultrouter="*:*::*" #上流にルータがある場合そのルータのアドレスを指定
rtadvd_enable="YES" #rtadvdを起動
rtadvd_interfaces="rl0" #rtadvdによりRAメッセージを流すネットワークカードを指定
ipv6_prefix_rl0="*:*:*:*" #指定したネットワークカードのIPv6アドレスのプレフィックスを指定
基本的に3−1の実験のルータの設定と変わらない。
また、この実験からホストにWindowsXPを導入した。WindowsXP SP2ではIPv6を正式にサポートしている。WindowsXPにおけるIPv6の導入の仕方を以下に述べる。
コマンドプロンプトを起動し
C\>ipv6 install
と入力、実行しsucceededと表示されれば完了である。動作確認はコマンドプロンプトでC:\>ping6 ::1と入力し自分にPingが通れば正常に動作している。但し、::1とはループバックアドレスといい、自身に割り当てられた自分自身を示すIPアドレスのことである。ネットワーク上において自分自身を表す仮想的なアドレスであり、IPv4においては「127.0.0.1」、IPv6においては「::1」(0:0:0:0:0: 0:0:1)が使われる。
ネットワークの動作確認の実行結果を以下に示す。
ルータ1のルーティングテーブル(netstat -rn実行結果)
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
127.0.0.1 127.0.0.1 UH 0 42 lo0
192.168.1 link#1 UC 0 0 rl0
192.168.1.254 00:02:96:02:5d:87 UHLW 0 4 lo0
192.168.2/23 192.168.1.100 UG 0 9 rl0
Internet6:
Destination Gateway Flags Netif Expire
::/96 ::1 UGRS lo0 =>
::1 ::1 UH lo0
::ffff:0.0.0.0/96 ::1 UGRS lo0
2001::/24 ::1 UGRS lo0 =>
2001::/16 2001:db8::1 U stf0
2001:7f00::/24 ::1 UGRS lo0
2001:db8::1 link#5 UHL lo0
2001:db8:: 00:02:96:02:5d:87 UHL lo0 =>
2001:db8::/64 link#1 UC rl0
2001:db8::25 00:02:96:02:5d:87 UHL lo0
2001:db8::52 00:02:96:02:5d:87 UHL lo0
2001:db8::80 00:02:96:02:5d:87 UHL lo0
2001:db8:0:2::/64 fe80::290:27ff:fe57:85ad%rl0 UG rl0
2001:db8:0:3::/64 fe80::290:27ff:fe57:85ad%rl0 UG rl0
2001:e000::/20 ::1 UGRS lo0
2001:ff00::/24 ::1 UGRS lo0
fe80::/10 ::1 UGRS lo0
fe80::%rl0/64 link#1 UC rl0
fe80::202:96ff:fe02:5d87%rl0 00:02:96:02:5d:87 UHL lo0
fe80::290:27ff:fe57:85ad%rl0 00:90:27:57:85:ad UHLW rl0
fe80::%fxp0/64 link#2 UC fxp0
fe80::207:e9ff:fe50:4b8b%fxp0 00:07:e9:50:4b:8b UHL lo0
fe80::%lo0/64 fe80::1%lo0 U lo0
fe80::1%lo0 link#4 UHL lo0
ff01::/32 ::1 U lo0
ff02::/16 ::1 UGRS lo0
ff02::%rl0/32 link#1 UC rl0
ff02::%fxp0/32 link#2 UC fxp0
ff02::%lo0/32 ::1 UC lo0
ルータ2のルーティングテーブル(netstat -rn実行結果)
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
default 192.168.1.254 UGS 0 11 fxp0
127.0.0.1 127.0.0.1 UH 0 0 lo0
192.168.1 link#1 UC 0 0 fxp0
192.168.1.1254 00:02:96:02:5d:87 UHLW 2 904 fxp0 1186
192.168.2 link#2 UC 0 0 rl0
192.168.2.100 link#2 UHLW 1 2 rl0
192.168.3 192.168.2.100 UG 0 8 rl0
Internet6:
Destination Gateway Flags Netif Expire
::/96 ::1 UGRS lo0 =>
default 2001:db8::1 UGS fxp0
::1 ::1 UH lo0
::ffff:0.0.0.0/96 ::1 UGRS lo0
2001:db8::/64 link#1 UC fxp0
2001:db8::10 00:90:27:57:85:ad UHL lo0
2001:db8::1 00:02:96:02:5d:87 UHLW fxp0
2001:db8:0:2:: 00:02:96:02:57:b2 UHL lo0 =>
2001:db8:0:2::/64 link#2 UC rl0
2001:db8:0:2::1 00:90:27:57:85:3a UHLW rl0
2001:db8:0:3::/64 fe80::290:27ff:fe57:853a%rl0 UG rl0
fe80::/10 ::1 UGRS lo0
fe80::%fxp0/64 link#1 UC fxp0
fe80::202:96ff:fe02:5d87%fxp0 00:02:96:02:5d:87 UHLW fxp0
fe80::290:27ff:fe57:85ad%fxp0 00:90:27:57:85:ad UHL lo0
fe80::%rl0/64 link#2 UC rl0
fe80::202:96ff:fe02:57b2%rl0 00:02:96:02:57:b2 UHL lo0
fe80::290:27ff:fe57:853a%rl0 00:90:27:57:85:3a UHLW rl0
fe80::%lo0/64 fe80::1%lo0 U lo0
fe80::1%lo0 link#5 UHL lo0
ff01::/32 ::1 U lo0
ff02::/16 ::1 UGRS lo0
ff02::%fxp0/32 link#1 UC fxp0
ff02::%rl0/32 link#2 UC rl0
ff02::%lo0/32 ::1 UC lo0
ルータ3のルーティングテーブル(netstat -rn実行結果)
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
default 192.168.2.254 UGS 0 19 fxp0
127.0.0.1 127.0.0.1 UH 0 0 lo0
192.168.1 192.168.2.254 UG 0 9 fxp0
192.168.2 link#1 UC 0 0 fxp0
192.168.2.254 link#1 UHLW 3 0 fxp0
192.168.3 link#3 UC 0 0 rl0
192.168.3.32 00:07:e9:50:4a:d2 UHLW 0 13 rl0 1194
Internet6:
Destination Gateway Flags Netif Expire
::/96 ::1 UGRS lo0
default 2001:db8:0:2:1 UGS fxp0
::1 ::1 UH lo0
::ffff:0.0.0.0/96 ::1 UGRS lo0
2001:db8::/64 fe80::202:96ff:fe02:57b2%fxp0 UG fxp0
2001:db8:0:2::/64 link#1 UC fxp0
2001:db8:0:2::10 00:90:27:57:85:3a UHL lo0
2001:db8:0:3:: 00:07:40:c7:ef:98 UHL lo0 =>
2001:db8:0:3::/64 link#3 UC rl0
2001:db8:0:3::1 00:07:e9:50:4a:d2 UHLW rl0
fe80::/10 ::1 UGRS lo0
fe80::%fxp0/64 link#1 UC fxp0
fe80::202:96ff:fe02:57b2%fxp0 00:02:96:02:57:b2 UHLW fxp0
fe80::290:27ff:fe57:853a%fxp0 00:90:27:57:85:3a UHL lo0
fe80::%fxp1/64 link#2 UC fxp1
fe80::290:27ff:fe57:855e%fxp1 00:90:27:57:85:5e UHL lo0
fe80::%rl0/64 link#3 UC rl0
fe80::207:40ff:fec7:ef98%rl0 00:07:40:c7:ef:98 UHL lo0
fe80::%fxp2/64 link#4 UC fxp2
fe80::207:e9ff:fe50:4bc5%fxp2 00:07:e9:50:4b:c5 UHL lo0
fe80::%lo0/64 fe80::1%lo0 U lo0
fe80::1%lo0 link#6 UHL lo0
ff01::/32 ::1 U lo0
ff02::/16 ::1 UGRS lo0
ff02::%fxp0/32 link#1 UC fxp0
ff02::%fxp1/32 link#2 UC fxp1
ff02::%rl0/32 link#3 UC rl0
ff02::%fxp2/32 link#4 UC fxp2
ff02::%lo0/32 ::1 UC lo0
ルータ1→ホスト3へのPing
IPv4
# ping 192.168.3.32
PING 192.168.3.32 (192.168.3.32): 56 data bytes
64 bytes from 192.168.3.32: icmp_seq=0 ttl=64 time=0.453 ms
64 bytes from 192.168.3.32: icmp_seq=1 ttl=64 time=0.208 ms
64 bytes from 192.168.3.32: icmp_seq=2 ttl=64 time=0.201 ms
^C
--- 192.168.3.32 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max/stddev = 0.201/0.287/0.453/0.117 ms
IPv6
# ping6 2001:db8:0:3:207:e9ff:fe50:4ad2
PING6(56=40+8+8 bytes) 2001:db8::1 --> 2001:db8:0:3:207:e9ff:fe50:4ad2
16 bytes from 2001:db8:0:3:207:e9ff:fe50:4ad2, icmp_seq=0 hlim=62 time=682.156 ms
16 bytes from 2001:db8:0:3:207:e9ff:fe50:4ad2, icmp_seq=1 hlim=62 time=0.589 ms
16 bytes from 2001:db8:0:3:207:e9ff:fe50:4ad2, icmp_seq=2 hlim=62 time=0.606 ms
^C
--- 2001:db8:0:3:207:e9ff:fe50:4ad2 ping6 statistics ---
3 packets transmitted, 3 packets received, 0.0% packet loss
round-trip min/avg/max/std-dev = 0.589/227.784/682.156/321.290 ms
ルータ1→ホスト3へのTraceroute
IPv4
# traceroute 192.168.3.32
traceroute to 192.168.3.32 (192.168.3.32), 64 hops max, 40 byte packets
1 192.168.1.100 (192.168.1.100) 0.499 ms 0.496 ms 0.573 ms
2 192.168.2.100 (192.168.2.100) 0.521 ms 0.562 ms 0.625 ms
3 192.168.3.32 (192.168.3.32) 0.478 ms 0.684 ms 0.516 ms
IPv6
# traceroute6 2001:db8:0:3:207:e9ff:fe50:4ad2
traceroute6 to 2001:db8:0:3:207:e9ff:fe50:4ad2 (2001:db8:0:3:207:e9ff:fe50:4ad2) from 2001:db8::1, 64 hops max, 12 byte packets
1 2001:db8::10 0.357 ms 0.716 ms 0.506 ms
2 2001:db8:0:2::10 0.543 ms 0.685 ms 0.542 ms
3 2001:db8:0:3:207:e9ff:fe50:4ad2 0.572 ms 0.738 ms 0.525 ms
ホスト3→ルータ1へのPing
IPv4
# ping 192.168.1.254
PING 192.168.1.254 (192.168.1.254) 56(84) bytes of data.
64 bytes from 192.168.1.254: icmp_seq=0 ttl=62 time=1.29 ms
64 bytes from 192.168.1.254: icmp_seq=1 ttl=62 time=0.789 ms
64 bytes from 192.168.1.254: icmp_seq=2 ttl=62 time=0.799 ms
--- 192.168.1.254 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2000ms
rtt min/avg/max/mdev = 0.789/0.959/1.290/0.235 ms, pipe 2
IPv6
# ping6 2001:db8::1
PING 2001:db8::1(2001:db8::1) 56 data bytes
64 bytes from 2001:db8::1: icmp_seq=0 ttl=62 time=0.707 ms
64 bytes from 2001:db8::1: icmp_seq=1 ttl=62 time=0.638 ms
64 bytes from 2001:db8::1: icmp_seq=2 ttl=62 time=0.642 ms
--- 2001:db8::1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2000ms
rtt min/avg/max/mdev = 0.638/0.662/0.707/0.037 ms, pipe 2
ホスト3→ルータ1へのTraceroute
IPv4
# traceroute 192.168.1.254
traceroute to 192.168.1.254 (192.168.1.254), 30 hops max, 38 byte packets
1 192.168.3.254 (192.168.3.254) 0.250 ms 0.197 ms 0.190 ms
2 192.168.2.254 (192.168.2.254) 1.124 ms 0.708 ms 0.732 ms
3 192.168.1.254 (192.168.1.254) 1.522 ms 0.901 ms 1.124 ms
IPv6
# traceroute6 2001:db8::1
traceroute to 2001:db8::1 (2001:db8::1) from 2001:db8:0:3:207:e9ff:fe50:4ad2, 30 hops max, 16 byte packets
1 2001:db8:0:3::1 (2001:db8:0:3::1) 0.359 ms 0.267 ms 0.253 ms
2 2001:db8:0:2::1 (2001:db8:0:2::1) 0.478 ms 0.483 ms 0.491 ms
3 2001:db8::1 (2001:db8::1) 0.709 ms 0.651 ms 0.653 ms
上記の結果からローカルネットワークにおけるIPv4、Ipv6 ネットワークの構築は正常に動作していることがわかる。
3−3で構築したローカルネットワークを利用して対外接続実験を行う。まず、グローバルなIPv4アドレスを一つ利用してIPv4ネットワークの対外接続を行い、その上でそのIPv4アドレスを6to4で利用しIPv6ネットワークの対外接続を行う。
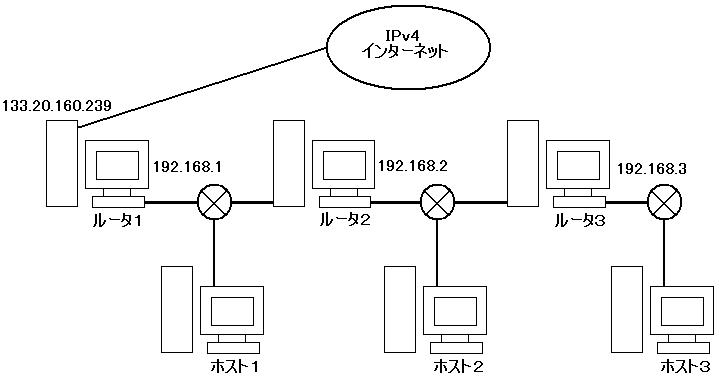
グローバルなIPv4アドレス1つでネットワーク内の全てのホストをインターネットに接続するにはNATを利用する(図18参照)。NATはIPv4のグローバルアドレス不足から開発された技術であり、利用できるIPv4アドレスが利用する端末数未満の時に利用される。現在のIPv4ネットワークでは必須の技術ではあるが、アドレス数が十分あるIPv6ネットワークでは必要とされない技術である。
NATを利用するにはルータであるFreeBSDのカーネルの再コンパイルをしなければならない。以下にカーネルの設定ファイルに追加するオプションを示す。ただし、ここでは再コンパイルの手順等は割愛する。
options IPDIVERT # NATを使用するため
このオプションを追加してカーネルを再コンパイルすればNATが利用できるようになる。利用するにはrc.confを編集すればよい。以下に設定例を示す。
/etc/rc.conf
natd_enable="YES" #NATを利用する場合YESを指定
natd_interface="fxp0" #インターネットに接続されている側のネットワークカード。図18のネットワーク図ではルータ1側のネットワークカード
router_enable="NO" #IPv4ルーティングデーモンを停止
ネットワーク内の全てのルータのカーネルを再コンパイルしNATを有効にし、ルータ1にグローバルアドレスを割り振りばネットワーク内の全ての端末はインターネットに接続できる。また、NATを利用するためIPv4のルーティングデーモンは必要ないのでNOを指定する。
ネットワークのルータ1以外のアドレス割り当ては実験3−3と同様である。ルータ1のアドレス割り当ては以下のとおりである。
ルータ1のIPv4アドレス割り当て
133.20.160.239(NAT用グローバルアドレス)
192.168.1.254(ルータ用)
192.168.1.100(DNSサーバ用)
192.168.1.124(MAILサーバ用)
192.168.1.125(Webサーバ用)
以下に動作確認の実行結果を示す。
ホスト3からwww.dendai.ac.jpへのPing
# ping www.dendai.ac.jp
PING www.dendai.ac.jp (133.20.16.60) 56(84) bytes of data.
64 bytes from www.dendai.ac.jp (133.20.16.60): icmp_seq=0 ttl=251 time=5.21 ms
64 bytes from www.dendai.ac.jp (133.20.16.60): icmp_seq=1 ttl=251 time=3.01 ms
64 bytes from www.dendai.ac.jp (133.20.16.60): icmp_seq=2 ttl=251 time=2.61 ms
--- www.dendai.ac.jp ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 2.614/3.616/5.219/1.147 ms, pipe 2
ホスト3からwww.dendai.ac.jpへのTraceroute
# traceroute www.dendai.ac.jp
traceroute to www.dendai.ac.jp (133.20.16.60), 30 hops max, 38 byte packets
1 192.168.3.254 (192.168.3.254) 0.266 ms 0.198 ms 0.190 ms
2 192.168.2.254 (192.168.2.254) 0.595 ms 0.733 ms 0.690 ms
3 192.168.1.254 (192.168.1.254) 1.338 ms 1.175 ms 1.103 ms
4 133.20.160.254 (133.20.160.254) 2.045 ms 1.690 ms 1.785 ms
5 133.20.110.249 (133.20.110.249) 2.176 ms 2.023 ms 2.495 ms
6 133.20.97.242 (133.20.97.242) 3.163 ms 2.257 ms 2.328 ms
IPv6ネットワークを対外接続するためには6to4を利用する。6to4では2章で述べたように、1台のルータに導入するだけでよい。この実験ではルータ1に導入した。(図19参照)
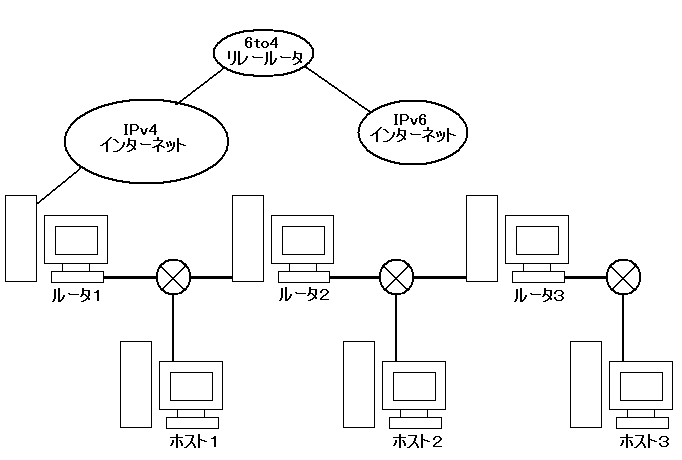
6to4を利用するには、6to4リレールータを指定しなければならない。本実験ではhttp://www.6to4.jp/でオープンに公開されているリレールータを利用した。
下記にルータ1のrc.confの6to4関連の設定を示す。
ipv6_defaultrouter="2002:c01a:5bb2::1"
利用可能な6to4リレールータをここで指定する。
stf_interface_ipv4addr="133.20.160.239"
6to4トンネルにはstf仮想ネットワークインタフェースを使用する。ここで自ホストのグローバルIPv4アドレスを指定すると、6to4インタフェースが有効に なる。
上記の二つの設定をルータ1のrc.confに追加するだけで、6to4が利用できるようになる。そして、133.20.160.239を16進表記に変換しIPv6プレフィックス2002と組み合わせた「2002:8514:a0ef /48」のグローバルなIPv6プレフィックスが利用できるようになる。
このプレフィックスを利用して下記のようにルータアドレスを割り当てた。また、各ホストはルータからのRAを受けて自動割当がされるようになっている。
ルータ1
2002:8514:a0ef ::1(仮想ネットワークカード)
2002:8514:a0ef:1::1(下流側ネットワークカード)
2002:8514:a0ef:1::52(DNSサーバ用)
2002:8514:a0ef:1::25(MAILサーバ用)
2002:8514:a0ef:1::80(Webサーバ用)
ルータ2
2002:8514:a0ef :1::10(上流側ネットワークカード)
2002:8514:a0ef :2::1(下流側ネットワークカード)
ルータ3
2002:8514:a0ef :2::10(上流側ネットワークカード)
2002:8514:a0ef :3::1(下流側ネットワークカード)
また、アドレス割り当て変更にあたり、ルータ2,3のrc.confのipv6_defaultrouterなどの設定やDNSサーバのゾーンファイルの変更が必要である。これで、IPv6ネットワーク内の全ての端末にグローバルなIPv6アドレスがついたことになる。以下に動作確認の実行結果を示す。
ホスト3からwww.kame.netへのPing6
# ping6 www.kame.net
PING www.kame.net(orange.kame.net) 56 data bytes
64 bytes from orange.kame.net: icmp_seq=0 ttl=56 time=4.79 ms
64 bytes from orange.kame.net: icmp_seq=1 ttl=56 time=4.71 ms
64 bytes from orange.kame.net: icmp_seq=2 ttl=56 time=5.18 ms
--- www.kame.net ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 4.719/4.899/5.189/0.214 ms, pipe 2
ホスト3からwww.kame.netへのtraceroute6
# traceroute6 www.kame.net
traceroute to www.kame.net (2001:200:0:8002:203:47ff:fea5:3085) from 2002:8514:a0ef:3:207:e9ff:fe50:4ad2, 30 hops max, 16 byte packets
1 2002:8514:a0ef:3::1 (2002:8514:a0ef:3::1) 0.366 ms 0.275 ms 0.253 ms
2 2002:8514:a0ef:2::1 (2002:8514:a0ef:2::1) 0.541 ms 0.482 ms 0.497 ms
3 2002:8514:a0ef:1::1 (2002:8514:a0ef::1) 0.726 ms 0.665 ms 0.675 ms
4 2002:c01a:5bb2::1 (2002:c01a:5bb2::1) 4.162 ms 3.615 ms 3.133 ms
5 hitachi1.otemachi.wide.ad.jp (2001:200:0:1800::9c4:2) 4.73 ms 3.902 ms 4.012 ms
6 2001:200:0:1c04:230:13ff:feae:5b (2001:200:0:1c04:230:13ff:feae:5b) 6.815 ms 6.549 ms 6.518 ms
7 2001:200:0:4800::7800:1 (2001:200:0:4800::7800:1) 6.51 ms 7.404 ms 7.342 ms
8 orange.kame.net (2001:200:0:8002:203:47ff:fea5:3085) 4.765 ms 4.509 ms 5.484 ms
上記の結果から、ネットワーク内からのインターネットへの接続ができていることがわかる。次に、外部からネットワーク内への接続ができるかの動作確認を行う。ここでは、 http://chivas.jp/IPv6/にあるIPv6用のPingとTracerouteがうてるツールを利用した。
外部からホスト3へのPing
PING6(56=40+8+8 bytes) 2001:470:1f01:ffff::32f --> 2002:8514:a0ef:3:207:e9ff:fe50:4ad2
16 bytes from 2002:8514:a0ef:3:207:e9ff:fe50:4ad2, icmp_seq=0 hlim=55 time=393.169 ms
16 bytes from 2002:8514:a0ef:3:207:e9ff:fe50:4ad2, icmp_seq=1 hlim=55 time=393.349 ms
16 bytes from 2002:8514:a0ef:3:207:e9ff:fe50:4ad2, icmp_seq=2 hlim=55 time=393.516 ms
16 bytes from 2002:8514:a0ef:3:207:e9ff:fe50:4ad2, icmp_seq=3 hlim=55 time=393.098 ms
--- 2002:8514:a0ef:3:207:e9ff:fe50:4ad2 ping6 statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max/std-dev = 393.098/393.283/393.516/0.163 ms
外部からホスト3へのTraceroute
1 ewnix.tunnel.tserv2.fmt.ipv6.he.net 122.067 ms 121.750 ms 121.844 ms
2 2001:470:1fff:2::26 122.139 ms 122.226 ms 121.181 ms
3 3ffe:81d0:ffff:1::1 124.634 ms 124.661 ms 124.262 ms
4 2001:470:1fff:1::1 208.333 ms 207.955 ms 207.785 ms
5 2001:504:0:2:0:3:3437:1 207.821 ms 207.855 ms 207.702 ms
6 iad0-stf.hotnic.net 208.206 ms 207.805 ms 207.847 ms
7 2002:8514:a0ef::1 396.914 ms 392.947 ms 393.904 ms
8 2002:8514:a0ef:1::10 395.655 ms 393.164 ms 394.109 ms
9 2002:8514:a0ef:2::10 393.120 ms 394.426 ms 545.802 ms
10 2002:8514:a0ef:3:207:e9ff:fe50:4ad2 396.361 ms 393.843 ms 393.012 ms
上記の結果から自IPv6ネットワークが正常に動作していることがわかる。
本論文は、小規模ネットワークへのIPv6の導入方法について研究をした。その結果、6to4を利用すれば非常に簡単に小規模ネットワークにIPv6が導入できることがわかった。そして、グローバルなIPv4アドレスを1つもっていれば利用できる6to4は小規模ネットワークだけでなく、個人ユーザなどにも非常に有効な技術であることもわかった。
IPv6を実際に実装してみるとIPv6の長所短所が色々と感じられた。現在IPv6はほとんどのプラットフォームで正式にサポートされているため、導入自体が非常に簡単に行える。そして、プラグアンドプレイ機能が義務化されたことにより、ネットワークを構築する際にはルータを設定するだけでよく、ホストはIPv6を利用するように設定するだけで、ネットワークなどの設定を気にする必要がない。これは、インターネット利用者側にかかる負担をIPv4よりも大幅に軽減でき、またPC以外の端末をインターネットに接続する際に非常に有用だと思われる。
しかし、IPv4と互換性がないためIPv6への以降がなかなか進まないことや、ネットワーク管理者が新たにIPv6に関する勉強をしなければいけないなどの問題もある。また、移行期である現在ではどこがIPv6に対応しているのか、どこがしていないのかがわかり辛い。そして、管理者はこういった問題を一般的な利用者に意識させることなく、解決していかなければならない。IPv4からIPv6への以降が完全に済めば、問題の多くはなくなるだろうが、それまでは運営・管理側の負担は大きなものとなるだろう。
今後のIPv6導入の展開としては、さまざまな共存技術を利用し小規模から大規模までのネットワークにまずIPv6を導入していき、IPv6がある程度普及したのちに個人ユーザーなどもIPv6を導入していけば、比較的スムーズに移行していけるのではないかと考える。 ただし、ほぼ全てのネットワークがIPv6に対応するまでの移行期間はIPv4との共存が必要である。
以下に載せる各種設定ファイルは実験3−2の時点で設定ファイルである。
localhost.rev
$TTL 3600
@ IN SOA ns.example.com. root.www.example.com. (
20050930 ; Serial
3600 ; Refresh
900 ; Retry
3600000 ; Expire
3600 ) ; Minimum
IN NS ns.example.com.
1 IN PTR localhost.example.com.
localhost-v6.rev
$TTL 3600
@ IN SOA ns.example.com. root.www.example.com. (
20050930 ; Serial
3600 ; Refresh
900 ; Retry
3600000 ; Expire
3600 ) ; Minimum
IN NS ns1.example.com.
IN PTR localhost.example.com.
example.com
$TTL 86400
@ IN SOA ns.example.com. root.www.example.com. (
20050930 ; Serial
86400 ; Refresh
3600 ; Retry
604800 ; Expire
86400 ) ; Minimum
;NameServer
IN NS ns.example.com.
;MailServer
IN MX 0 mail.example.com.
;
ns IN AAAA 2001:db8::52
IN A 192.168.1.100
mail IN AAAA 2001:db8::25
IN A 192.168.1.124
www IN AAAA 2001:db8::80
IN A 192.168.1.125
168.192.in-addr.arpa
$TTL 86400
@ IN SOA ns.example.com. root.example.com.(
20050930 ; Serial
86400 ; Refresh(1day)
3600 ; Retry(1hour)
604800 ; Expire(1week)
86400) ; Minimum(1day)
IN NS ns.example.com.
;
100.1 IN PTR ns.example.com.
124.1 IN PTR mail.example.com.
125.1 IN PTR www.example.com.
0.0.0.0.8.B.D.0.1.0.0.2.ip6
$TTL 86400
@ IN SOA ns.example.com. root.www.example.com. (
20050930 ; Serial
86400 ; Refresh
3600 ; Retry
604800 ; Expire
86400 ) ; Minimum
;
IN NS ns.example.com.
;
3.5.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0 IN PTR ns.example.com.
5.2.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0 IN PTR mail.example.com.
0.8.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0.0 IN PTR www.example.com.
[1] PROFESSIONAL LIBRARY IPv6入門 著者:Mark A. Miller 訳者:有限会社 トップスタジオ 出版:株式会社 翔泳社
[2] IPv6実践ガイド 著者:小早川 知昭、宮本 崇之、齊藤 允 出版:日経印刷株式会社
[3] IPv6 環境構築と利用 著者:今井 悟志 出版:株式会社 工学社
[4] FreeBSD ビギナーズバイブル 著者:後藤 大地 出版:(株)毎日コミュニケーションズ
[5] IPv6 Style http://www.ipv6style.jp/jp/index.shtml
[6] KAME Project http://www.kame.net/
[7] 6to4 http://www.6to4.jp/
[8] Chibas IPv6 http://chivas.jp/IPv6/