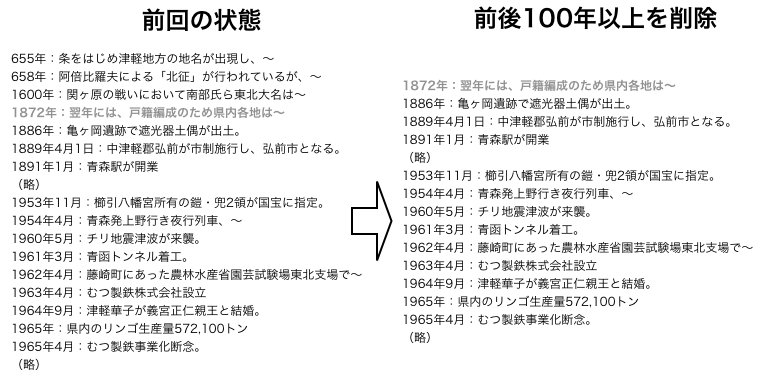
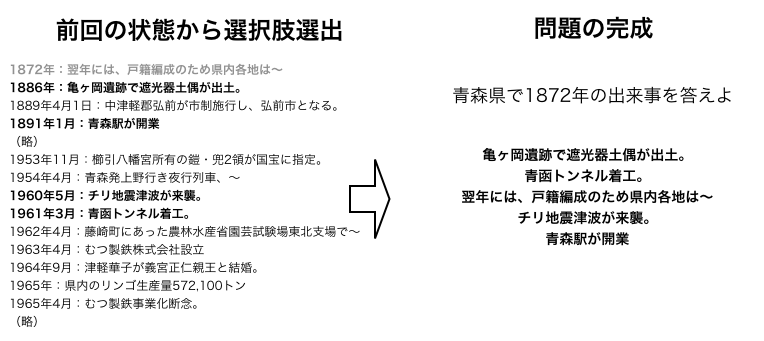
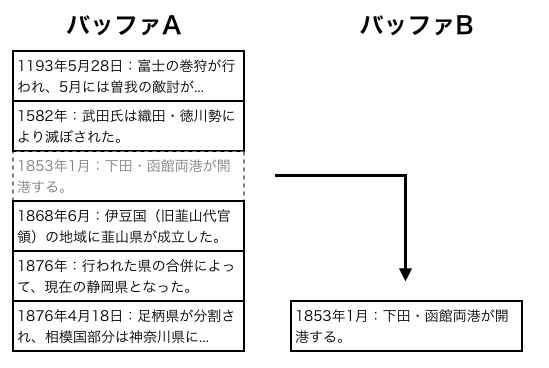
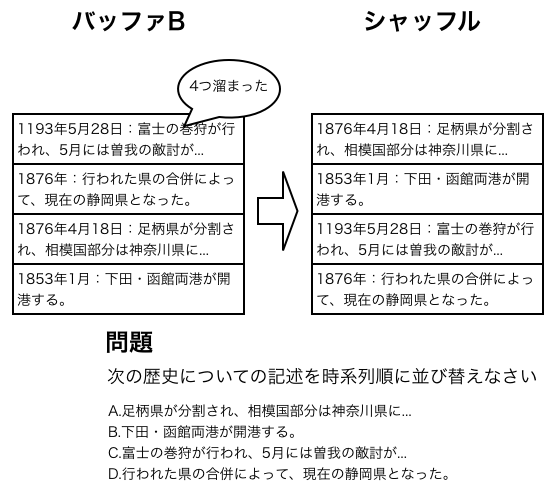
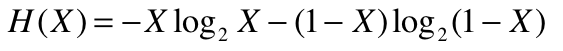予備知識
本章では、本研究で使用した技術について述べる。
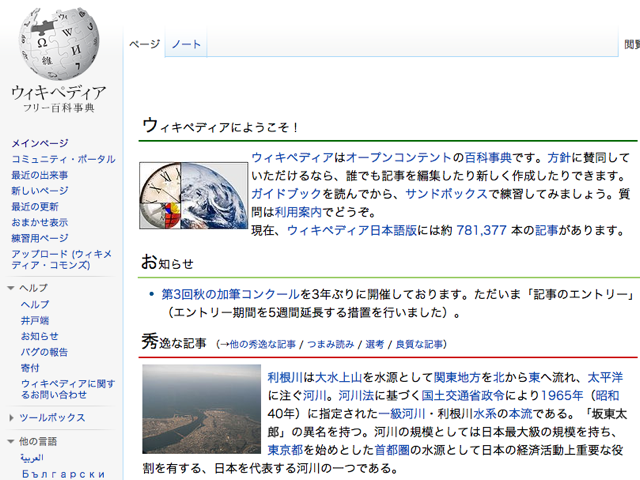
XML
XML(Extensible Markup Language)とは、文章の構造や意味を記述できる マークアップ言語の一つである。マークアップ言語とは、 文章中にタグを付与する事により、文章構造(見出しや段落、箇条書き)、 見栄え(文字の色、大きさ)などの情報を埋め込む事に対応した言語である。 文章構造の記述に特化したマークアップ言語として開発された SGML(Standard Generalized Markup Language)から派生して、 World Wide Web Consortium(W3C)によって記法や仕様が策定、勧告されている。 XMLで記述された文書の事は、XML文書と呼ぶ。 プログラム中でXML文書を利用する際は、 XMLパーサと呼ばれるソフトウェアを用いてプログラム中で扱いやすい 形式のデータに変換してから利用する。
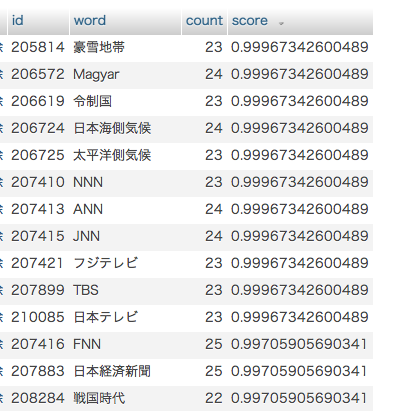
XMLはタグによって文章に情報を付加できるが、 ユーザー側で独自の意味のタグを作ることも可能である。 統一された記法を用いながらも、独自の意味を持たせることができるため、 様々な情報をコンピュータ上で扱うために利用される。 下図に、XMLを使用して連絡先データを記述する例を示す。 (ただし行番号は説明の便宜上付けたものであり、本来不要である。)
 XMLを使用した連絡先データの例
XMLを使用した連絡先データの例
次に、XML文書の記法について簡単に説明する。
文章の情報を付加するためのタグは、情報の意味を表す文字列を
<
と>
で囲むことで表す。
タグには「開始タグ」と「終了タグ」の2種類あり、
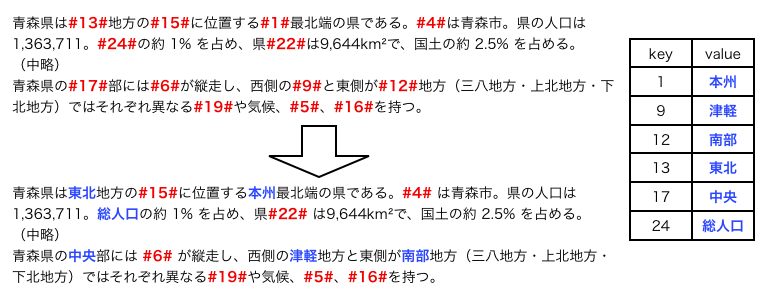
それぞれ<文字列>
と</文字列>
で表す。
情報を付加したい文字列を、開始タグと終了タグで囲むと、
その文字列には情報が付加された事になる。
開始タグと終了タグで囲むと、その部分は「要素」と呼び、
タグで囲んだ内容は「要素の内容」と呼ぶ。
例えば、2行目に<contacts>
から、
25行目の</contacts>
までをcontacts要素と呼び、
3行目から24行目までが、contacts要素の内容である。
XML文書では、要素の中に更に他の要素を含むことができる。 図1のXML文書の例では、contacts要素は2つのperson要素を含んでおり、 この場合はperson要素はcontacts要素の子要素であるという。 この規則は主に、各要素同士の関係性を表すために利用される。 例えばこのXML文書では、contacts要素の子要素は連絡先の情報であることを示す。 現在contacts要素には個人の連絡先を示すperson要素が含まれているが、 もしcontacts要素に会社の連絡先を示すcompany要素などが追加された場合でも、 連絡先の一つとして扱うことができる。
XML文書中で、一番最初に登場する要素(図1ではcontacts要素)は 最上位要素という。最上位要素は通常、XML文書中に1つしか存在できない。 そのためXML文書は、基本的に最上位要素の開始タグ及び終了タグの間に 記述することとなる。 また、最上位要素の直前には、XML宣言を記述する必要がある。 XML宣言とは、使用するXMLのバージョンや文書の文字コードを宣言するもので、 図1では1行目がXML宣言にある。
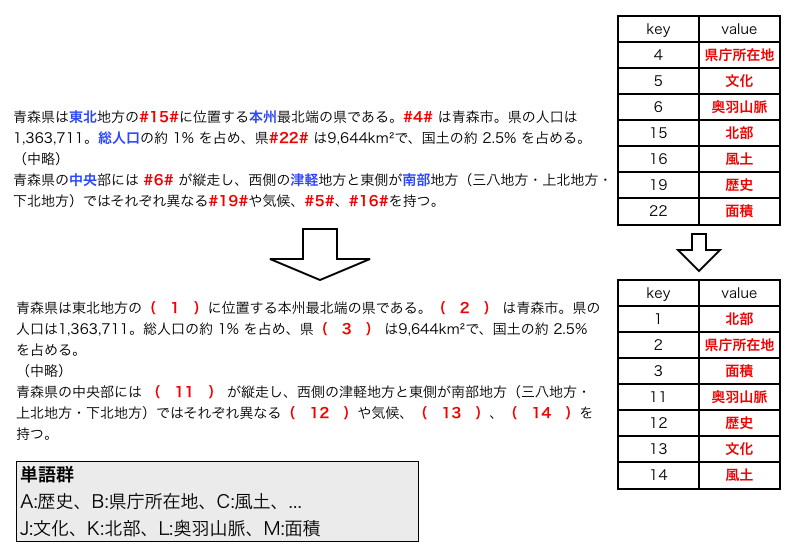
XML文書内の要素には「属性」を指定することができる。
属性は要素に追加できる情報のことで、名前と値の組み合わせである。
開始タグの要素名以降に、属性名="属性値"
と書く。
半角スペースで区切ると複数の属性について記述できる。
例えば、4行目のlast_name要素の内容は名字だが、
読み方の情報を付加するためにruby属性を指定している。
また、10行目では住所について記述するaddress要素に、
郵便番号の情報を付加している。
XML文書を構成する要素や属性、要素内にあるテキストなどは、 それぞれ「要素ノード」、「属性ノード」、「テキストノード」と呼ぶ。 特に前述の「最上位要素」は「ルートノード」とも呼び、 XML文書は最上位要素がルートノードのツリー構造で表すことができる。 図1のXML文書をツリー構造で表した図を以下に示す。
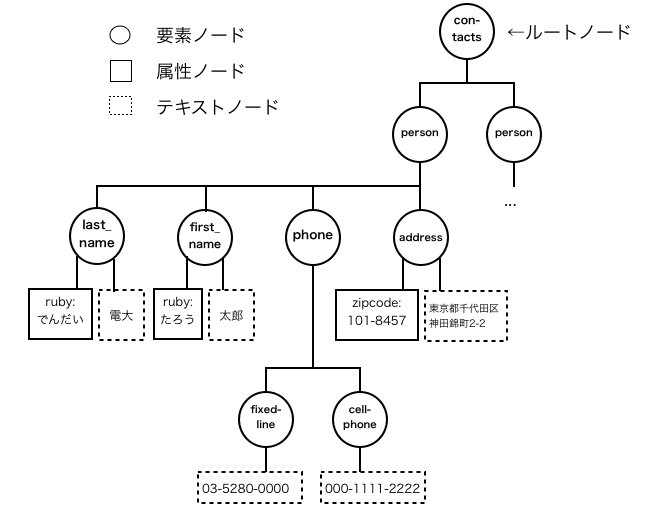 ツリー構造
ツリー構造
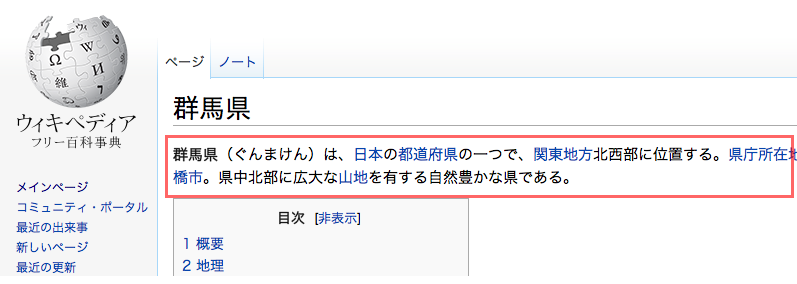
以上の知識を踏まえて、本研究で扱うWikipediaの記事を 解析するために必要となるXHTMLについて説明する。
XHTML
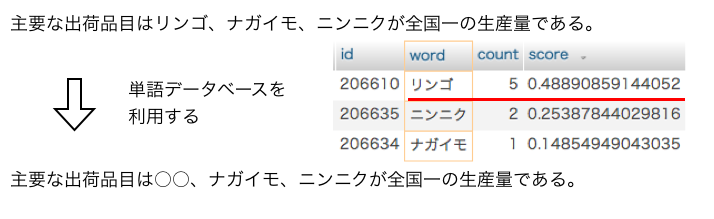
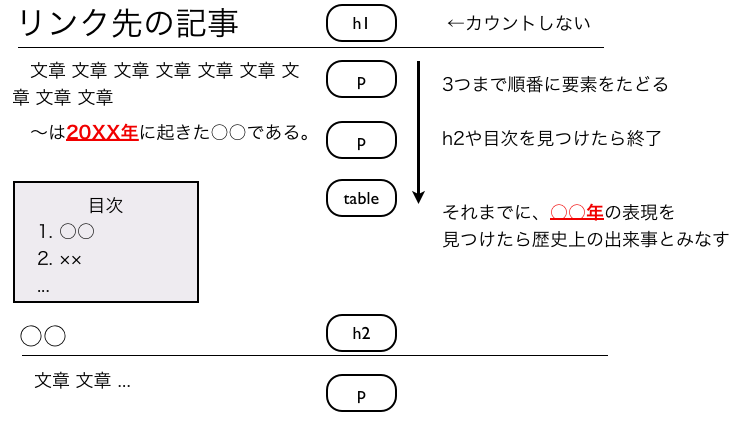
Webページを記述する事に特化した、HTMLと呼ばれるマークアップ言語を、 XML準拠になるように一部の仕様を変更したのがXHTMLである。 XHTMLでは、Webページを構成するための要素が数多く定義されている。 下図に簡単なXHTML文書の例を示す。
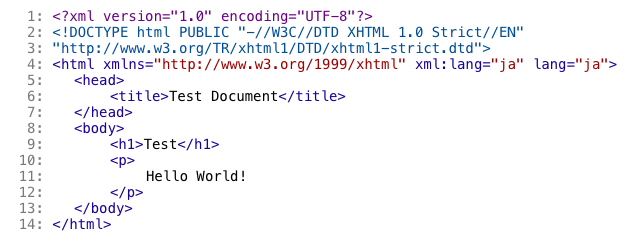 簡単なXHTML文書の例
簡単なXHTML文書の例
また、XHTMLにはいくつかのバージョンが存在し、 バージョンごとに利用できる要素や属性が異なる。 文書のバージョン宣言の事を「DOCTYPE宣言」と呼ぶ。 上図では2行目から3行目の部分がDOCTYPE宣言にあたる。
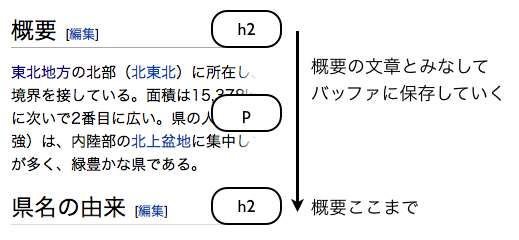
次に、XHTMLで定義されている代表的な要素を以下の表に示す。
| 要素名 | 説明 | 使用例 |
|---|---|---|
| html | XHTMLの最上位要素。 |
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja"> ... </html> |
| head | XHTML文書のヘッダ情報を記述する。 子要素にtitle要素が含まれていなければならない。 |
<head> <title>ページタイトル</title> </head> |
| title | XHTML文書のタイトルを記述する。 | <title>ページタイトル</title> |
| body | XHTML文書の本文を記述する。 |
<body> ... </body> |
| h1, h2, h3, h4, h5, h6 | 見出しを記述する。数字が小さいものほど優先度が高い。 | <h1>e-ラーニング用問題自動生成サービスの制作と評価</h1> |
| p | 段落を記述する。 |
<p>Webページを記述する事に特化した、
HTMLと呼ばれるマークアップ言語を...</p> <p>また、XHTMLにはいくつかのバージョンが存在し...</p> |
| br | この要素が挿入された場所で強制的に改行する。
この要素はテキストノードを含めることはできない。
この場合は、終了タグの代わりに<br />と記述する。 |
<p>ここで改行→<br /> します。 ここは改行→ しません。</p> |
| a | 別のHTML/XHTML文書へのリンクを記述する。 文書内の特定の位置に移動するという情報も追加できる。 |
別の文書へのリンクの記述の例: →<a href="appendix.html">付録ページ</a> 文書内の特定の位置に移動する記述の例: <a href="#auto_generation">例題の自動生成アルゴリズム</a> |
| div | これ自体は特に意味を持たない要素で、 内容を含むブロックを構成する。 属性を付与してスタイリングに使用したり、 他の要素をまとめるために使用する。 |
<div id="bodyContent"> <div class="section"> <p>本文</p> ... </div> </div> |
| img | この要素が挿入された場所に画像を表示させる。
br要素と同様の理由により、<img 〜 />と記述する。 |
<p>これがテスト画像です。 <img alt="テスト画像" src="image.png" /> </p> |
| ul, ol, li | リストを記述する。ulは並列列挙リストで、 項目の順序が重要な意味を持たないリストを記述するのに使用する。 olは順序付きリストで、 順序が意味を持つ場合はこちらを使用する。 liは、ul, olの子要素で、リスト項目を記述する。 |
ulの使用例: <p>用意する材料は以下の通りです。</p> <ul> <li>肉150g</li> <li>にんじん1個</li> </ul> olの使用例: <p>以下の手順で作業を行ってください。</p> <ol> <li>電源をONにする</li> <li>30秒待つ</li> <li>プログラムを実行する</li> </ol> |
| dl, dt, dd | 定義リストを記述する。ある用語などの名前をdt要素で 定義し、dd要素で直前に定義した用語の説明を行う。 |
<dl> <dt>XML</dt> <dd>Extensible Markup Languageの略で、 文章の構造や意味を記述できる マークアップ言語の一つである。</dd> <dt>Wikipedia</dt> <dd> ウィキメディア財団が運営する インターネット百科事典のことである。</dd> </dl> |
| table, tr, th, td | 表を記述する。trで行、thで見出し、tdで列を記述する。 |
<table> <tr> <th>単語</th> <th>意味</th> </tr> <tr> <td>language</td> <td>言語</td> </tr> <tr> <td>node</td> <td>節, ノード</td> </tr> <tr> <td>space</td> <td>空間</td> </tr> </table> |
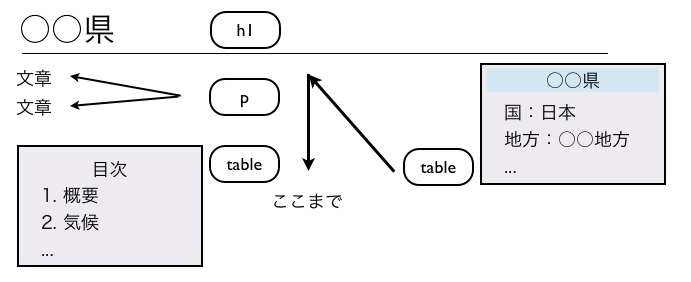
DOMとXPath
DOMとは、Document Object Modelの略であり、 World Wide Web Consortium(W3C)が公式に公開しているAPIである。 XML文書をDOMツリーと呼ばれるツリー構造として扱う事ができる。 ツリー構造とは、「2.1 XML」節の図2で示した通りである。 DOMツリーを生成するために、長いXML文書であるほど多くのメモリを要求する。 しかし、XML文書中の特定の要素へのアクセスを素早く行う事ができるため、 プログラム中でXML文書を扱う際によく利用される。
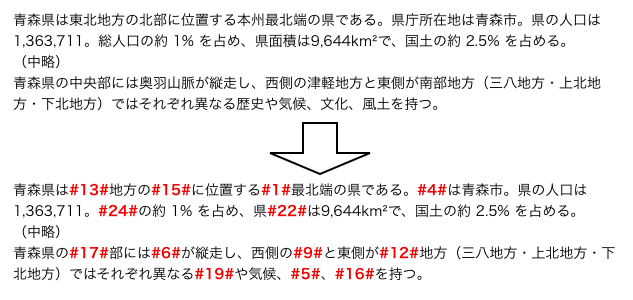
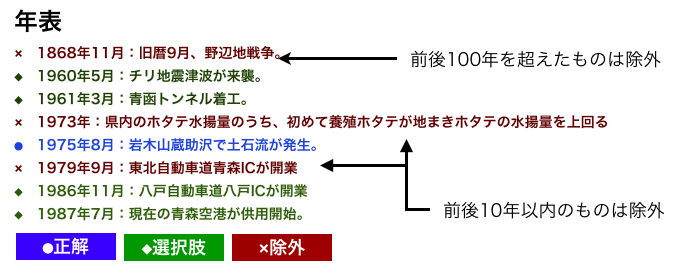
XPathとは、XML文書の特定の要素・属性がある位置を指定する言語構文である。 下図に、XML文書から「あるdiv要素の子要素になっているh2要素」 を指定するために使用する構文の例を示す。
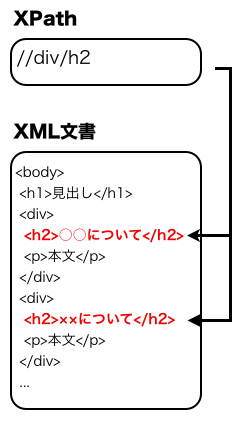 XPath
XPath
図3は、ロケーションパスと呼ばれる式を用いてXML文書中の要素を示した例で、 XPathではよく使われる表記方法である。 ロケーションパスの書き方についての詳細はここでは説明せず、 本研究で使用した表現のみ紹介する。
| 表現 | 意味 | 使用例 |
|---|---|---|
| //要素 | 要素とその子要素を全て選択 | //div/ (文書中のdiv要素及びその子要素を全て選択) |
| 要素[@属性名='属性値'] | 属性名が属性値の要素を選択 | //p[@class='test'] (文書中のclass属性がtestのp要素を全て選択) |
| 要素/* | 要素の子要素を全て選択 | //div/p/* (文書中の、div要素の子要素になっている p要素の子要素を全て選択) |
XPathは、様々なプログラミング言語で利用可能である。 (例:PHP, Java, JavaScript等) 通常は、DOMとXPath式を表す文字列を与えると、 ノードの集合を配列として受け取ることができる。