東京電機大学 工学部 情報通信工学科
ネットワークシステム研究室
指導教員 坂本直志
14EC028 尾形直椰
近年,音声認識や画像認識の分野で注目を浴びている深層学習であるが,同様にゲームAIの分野についても深層学習を用いた研究が数多く行われている. 2015年にDeepMind社が開発したアルゴリズムDeep Q-networks(DQN)を用いたコンピュータ囲碁プログラムAlphaGOが,人間のプロ囲碁棋士をハンディキャップなしで破るといった目覚ましい進歩がなされている. DQNは教師なし学習の一種である強化学習が用いられており,連続した行動の結果から報酬を得ることで行動の評価を行い,最も報酬が得られる方策を学習する. それに対し事前に与えられた指標をもとに学習を行うことを教師あり学習といい,本研究では教師あり学習の一種である時系列予測を行うことが可能なRecurrent Neural Network(RNN)を用いることでゲームプレイヤーの制作を行っていく. 教師あり学習では与える学習データによって精度が大きく影響してくる. 学習データに着目することで,学習データがゲームプレイヤーに対して与える影響を測定する. 二人零和有限確定完全情報ゲームであり,解析が容易である三目並べを対象とし,教師データの数がゲームプレイヤーの勝率に対しどの程度影響を及ぼすのかを調査する.
本論文の構成を以下に示す.
2章では本研究に用いる用語や,使用した手法についてまとめる.
3章では実験概要とその結果についてまとめる.
4章では本研究のまとめを述べる.
5章では参考文献についてまとめる.
6章では本実験で使用したプログラムの全文とその説明を行う.
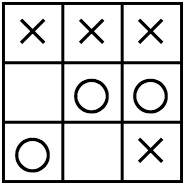
三目並べは,2人のプレイヤーが☓側(先手)と○側(後手)に別れ,3×3のマス目に交互に○☓を書いていき,どちらかが○☓を3つ並べた時点で勝敗が決まるゲームである. 二人零和有限確定完全情報ゲームであり,互いに最善を尽くすと常に引き分けになることが自明であるゲームとして知られている.
ニューラルネットワークとは,機械学習におけるモデルの一種である. 本項ではニューラルネットワークについて説明を行っていく. ここではニューラルネットワークの一種である多層パーセプトロンを想定し説明を行う.
多層パーセプトロンは生物の脳を構成する神経細胞「ニューロン」を単純化・数理モデル化したパーセプトロンと呼ばれるユニットで構成される. ユニットにはパラメータが存在し,閾値を表すバイアスとユニット間における結合強度を表す重みが備わっている. パーセプトロンは複数の入力を受け取り,入力の総和が閾値を超えたときに出力を行う. 出力には活性化関数と呼ばれる非線形関数を適用させる. 入力層・隠れ層・出力層から成る階層構造になっており,ユニットに対し閾値を超える入力信号が伝わると,活性化関数を通した後次の層のユニットへ信号伝達が行われ,その間の結合強度によって伝達される信号量が決定される. この工程を繰り返し,最終的にモデルの出力が行われる.
ニューラルネットワークにおける学習とは最適化問題を解くことである. ネットワークに入力データおよびそれに対応する教師データが与えられた時,ネットワークのパラメータである重みおよびバイアスを最適化するための関数のことを目的関数と呼ぶ. この目的関数を最大化あるいは最小化するようにパラメータを更新していくことが学習目標となる. ニューラルネットワークはモデルの出力と正解のデータを比較することで学習を行う. このとき,モデルの出力と教師データとの誤差を表す関数のことを誤差関数と呼び,この誤差関数を元に各ユニットのパラメータを更新していく.
以下に実例を示す.
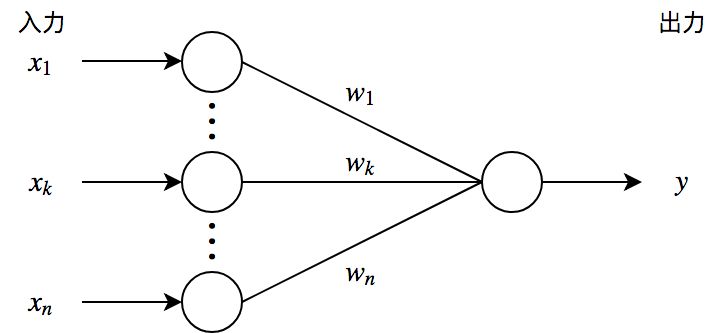
まずはパーセプトロンにおける出力を表す.
出力は
であり,活性化関数を適用すると
となる.このとき
とおくと
と表せる.
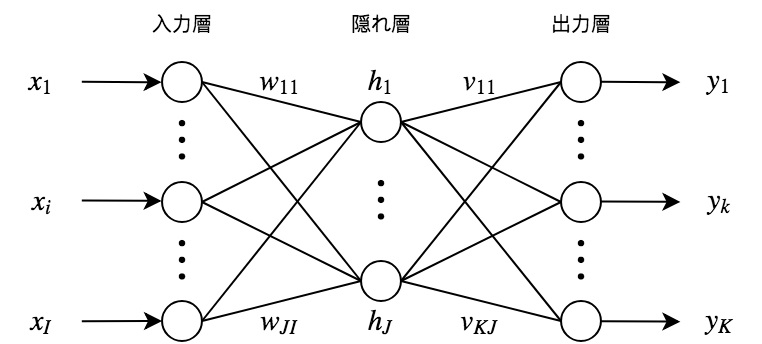
次に3層で構成されるニューラルネットワークについて考える. 重み行列,バイアス,活性化関数に対し,隠れ層における出力は
となる.ここで得られたが出力層に伝播するため,重み行列,バイアス,活性化関数に対し
となる.これを順方向伝播と呼ぶ.
次にパラメータを最適化していくことを考えるが,ここでは確率的勾配降下法を用いる. 誤差が0となるパラメータを解析的に求めるのは困難なため,代わりに反復学習によりパラメータを逐次的に更新していくことで誤差を小さくする. 確率的勾配降下法ではN個データがあるとき,そこからデータを1つずつランダムに選んでパラメータを更新する. パラメータが,,目的データ,モデルの出力とすると以下にように表せる.
ここでは学習率を表す. はモデルの学習速度を調節する. 一般的に0.1や0.01といった値が使用される.
図2のモデルのパラメータは,,,なので最小化すべき誤差関数をとすると
であり、確率的勾配降下法によって最適なパラメータを求めるには各パラメータに対する勾配を求める必要がある. N個データがあるとき,それぞれのデータで発生する誤差は独立なので
と表せる.よってに対する各パラメータの勾配を考えていくこととする. なお,以降データの順番を表すベクトルの添字 は省略する.
各層の活性化前の値をそれぞれ
とおくと,各層の重み行列および に対して
となるので,およびを求めれば各パラメータの勾配が求まる.また
で定義されるおよびは
とすることができる. 勾配を計算するための誤差が逆向きの出力を考えていくことで求められるので誤差逆伝播法と呼ばれる.
ニューラルネットワークでは各ユニットにおいて,入力の総和に対して非線形変換を行う活性化関数が適用される. この項では本実験で使用されるシグモイド関数,tanh(hyperbolic tangent function)関数の2つの活性化関数について示す.
シグモイド関数は以下の式によって表される.
tanh関数は以下の式によって表される.
本研究において使用していく学習モデルについて説明を行っていく.
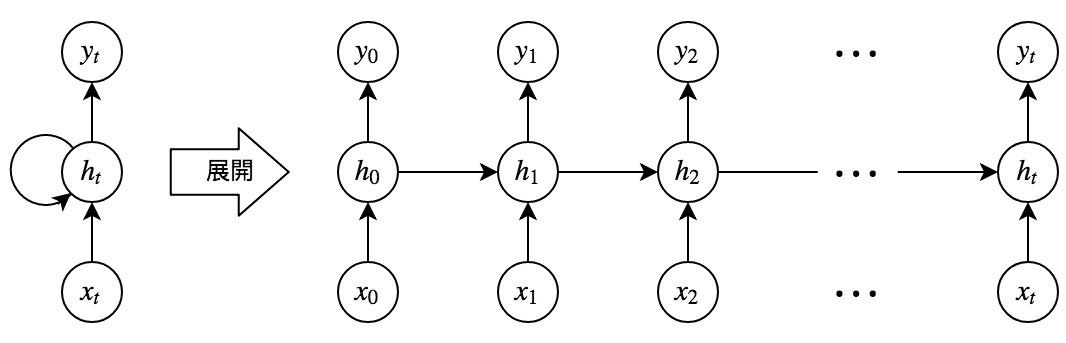
RNNは,時系列データを考慮しながら学習ができるニューラルネットワークである. 隠れ層が過去の隠れ層と接続されており,これにより再帰的に過去の状態が反映されるようになっている. RNNでは勾配を求める際,通常の誤差逆伝播法ではループ部の勾配を求められないため,モデルを時間軸方向に展開することで解決する. このとき誤差は時間を遡って逆伝播していることになるので,これをBackpropagation Through Time(BPTT)と呼ぶ. しかしBPTTでは,時間軸方向の展開をすることでネットワークの規模が大きくなり,勾配消失(爆発)の問題を起こしてしまうため,長期依存性の学習をすることは困難である.
RNNでは,長期の時間依存性は勾配消失(爆発)の問題を起こすため学習を行うことができなかったが,これはLSTMを用いることによって解決することができる. LSTMモデルではRNNにおける隠れ層の代わりにLSTM ブロック(LSTM block)を使用する.
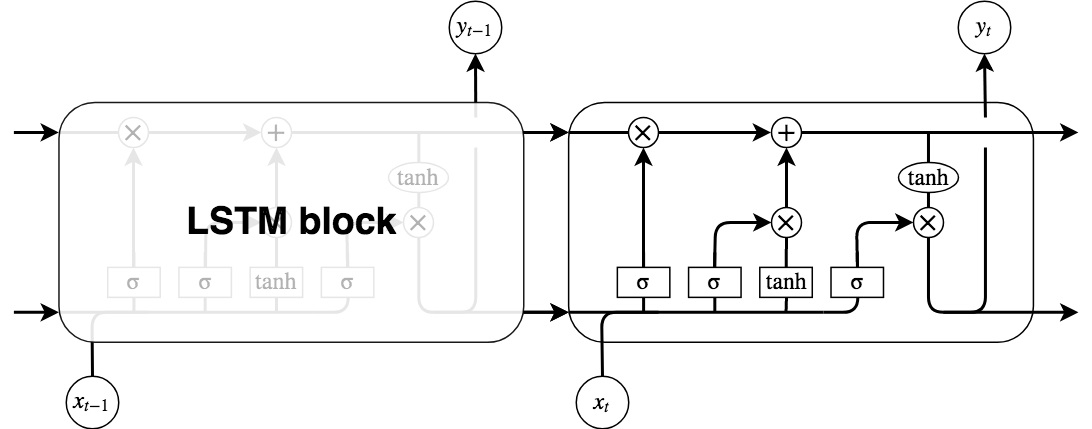
LSTMブロックは鎖状構造を有している. 4つの層に分けられ,これらの層が相互作用することにより,LSTMは長期的な情報の依存関係を学習することができる.
LSTMブロックの各構造について説明を行う.
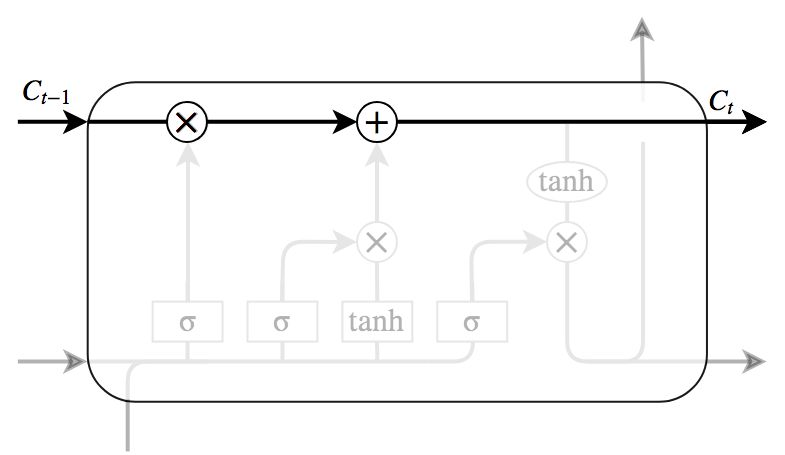
LSTMにおいて重要な部分が,図6のLSTM blockの上部を通る水平線である. Memory cellと呼ばれ,cellの状態に対し情報を追加したり,削除したりすることにより,LSTMは長期的な依存関係を記憶する.
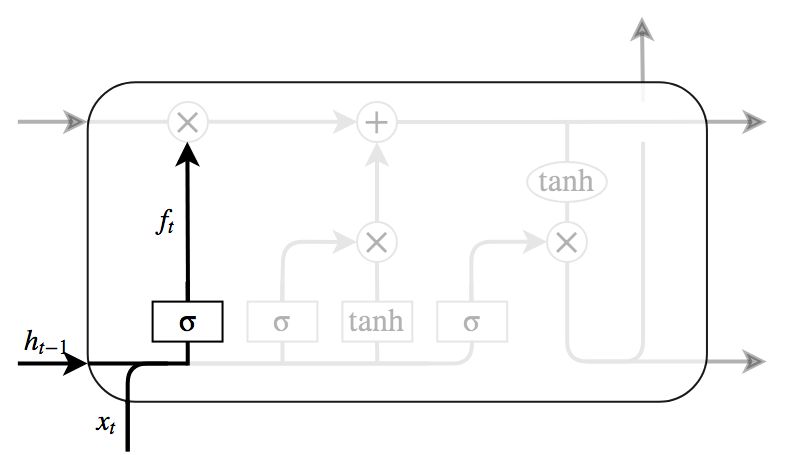
図7によって示されているのがForget gateである. ここはcellの状態に対し,捨てるべき情報を判定するところである. 忘却ゲートと呼ばれるシグモイド層によって行われ,入力と前ステップの出力を見て,cellの状態の各数値に対し0から1の間の数値を出力する. 0が完全に情報を取り除き,1が完全に情報を維持することを意味する.
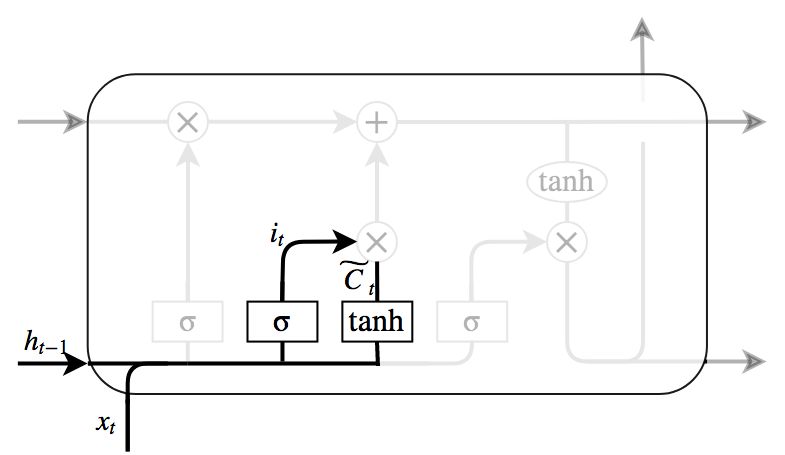
図8によって示されているのがInput gateである. ここはcellの状態に対して保存する新たな情報を判定する場所である. Input gateには入力ゲートと呼ばれるシグモイド層とtanh層の2つの層がある. シグモイド層はどの値を更新するか判定し,tanh層はcellの状態に加えられる新たな候補値のベクトルを生成する. これら2つの層の出力を組み合わせ,cellの状態を更新する.
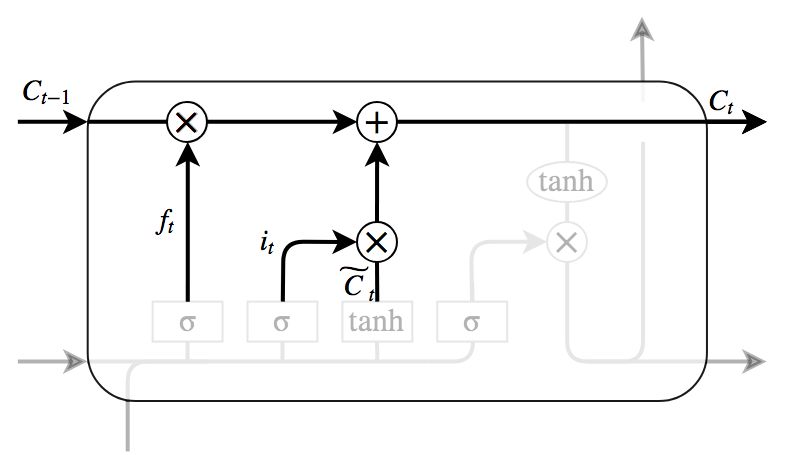
図9はcellの状態の更新部を示している. Forget gateとInput gateにより,更新すべき状態値は決定されているので,Cellの古い状態を新しい状態にするためにここで更新を行う.
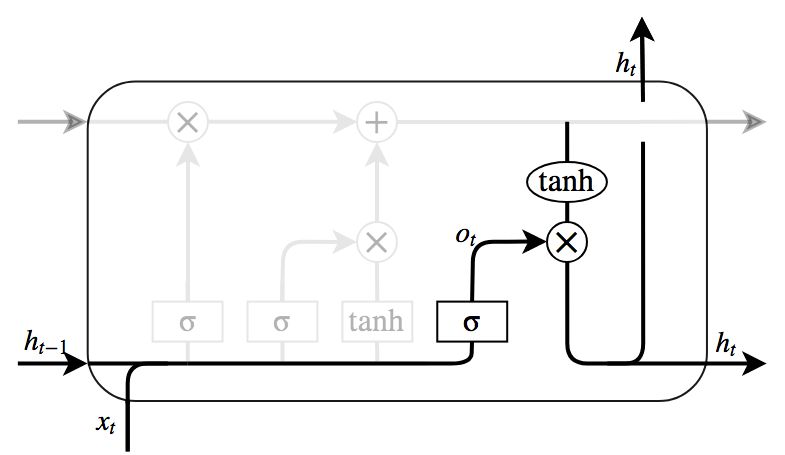
図10はOutput gateを示している.ここでは出力する内容を決定する. 出力はcellの状態に基づくが,フィルタを適用したものになる. まずcellの状態のどの部分を出力するかをシグモイド層によって判定する. その後判定された部分のみを出力するためにcellの状態にtanhを適用し,シグモイド層の出力を掛け,最終的に出力すべき部分のみを出力するようにする.
本研究では三目並べプレイヤーを制作するため,盤面を見て次の手を予測するモデルを作成する. 次の手の予測は多クラス分類と見なすことができるため,今回使用するモデルには出力層にソフトマックス層を設けた. ソフトマックス層では活性化関数にソフトマックス関数を用いる. ソフトマックス関数を用いることでベクトルの成分が正規化され,モデルの出力を確率分布として扱えるようになる. ソフトマックス関数は以下のように表される.
n次元ベクトルに対して
ここでを成分に持つベクトルをyとすると,softmax関数の定義より
本研究で作成するモデルはクラス分類を行うモデルとなっている. モデルの出力は,ソフトマックス層を通して出力されるため確率分布となる. そのため本実験では確率分布に対する誤差をとることのできる交差エントロピー誤差関数を使用する. 交差エントロピー誤差関数は以下の式で表される.
モデルの学習には確率的勾配降下法を用いるが,その際設定する学習率は0.1や0.01といった,決め打ちで学習を通して同じ値を用いていた. 学習率によって最適解が得られるかどうかが左右されるのであれば学習率も適切に設定を行う必要がある.
ここでは学習率の設定手法について説明を行う.
局所最適解に陥らず効率よく解を探索するには,学習率は「始めは大きく徐々に小さく」していくのが望ましい. モメンタムでは,学習率の値自体は同じだが,パラメータの更新時にモメンタム項と呼ばれる調整項を用いることで疑似的にこれを表現する. 誤差関数に対して,モデルのパラメータを,のに対する勾配をとすると,ステップtにおけるモメンタム項を用いたパラメータ更新式は以下のように表される.
がモメンタム項であり,は係数である.通常0.5や0.9といった値を使用する.
モメンタムは学習率の値は固定であり,モメンタム項によりパラメータの更新値を調整したが,Adagrad(adaptive gradient algorithm)は学習率そのものを更新する.
とおくと,Adagradは以下のように表される.
ただし,行列は対角行列であり,その成分は,ステップまでのに対する勾配の2乗和となる.
は分母が0になるのを防ぐための微小項であり,一般的にの値が使用される.
または対角行列であるため,下記のようにまとめることができる.
Adagradでは学習率が自動調整されるようになったが,対角行列は勾配の2乗の累積和であるため,単調増加する. そのため学習のステップを経るごとに勾配にかかる係数の値が急激に小さくなり,学習が進まなくなる問題が起こる. Adadeltaではステップ0から2乗和を積み重ねるのではなく,積み重ねるステップ数を定数wに制限することで問題を解決した. ただし実装の観点から見ると,単純にwの分だけ2乗和を同時に保持しておくのは非効率的であるため,Adadeltaは直前のステップまでの全勾配の2乗和を減衰平均させることで再帰式として計算する. このとき,式の簡略化のためと書いていたところを と表すと,ステップ における勾配の2乗 の移動平均 は
となり,AdadeltaはAdagrad(33式)におけるを勾配の2乗の減衰平均 で置き換えるため,以下のように表せる.
Adadeltaでは直前のステップt-1までの勾配の2乗の移動平均 を指数関数的に減衰平均させた項を保持し,パラメータの更新式に用いていたが,Adam(adaptive moment estimation)では,それに加え単純な勾配の移動平均 を指数関数的に減衰させる項も用いる.
はハイパーパラメータであり,移動平均の減衰率を調整する. はそれぞれ勾配の1次モーメント(平均),2次モーメント(分散)の推定値に相当する. 2つの移動平均 はともに偏りのあるモーメントとなるので,偏りを補正した推定値を求める. で初期化した場合,式(37)より
が得られる.2次モーメント の移動平均 と真の2次モーメント の関係性を知りたいので,これを上の式から求めると
となる.ここで と近似できるようにハイパーパラメータの値を設定すると
偏りのない推定値が得られる. についても同様で
が求められる.以上より
がパラメータの更新式として得られる.
本研究ではこのAdamをパラメータの更新に使用している.
本研究ではミニバッチ勾配降下法を使用する.確率的勾配降下法では,N個のデータに対しデータを1つずつランダムに選んでパラメータを更新したが,ミニバッチ勾配降下法ではN個のデータをM(<N)個ずつのかたまりに分けて学習を行う. このときM個のデータのかたまりをbatchと呼び,そのデータの数をbatch sizeと呼ぶ.
LSTMを用いて三目並べプレイヤーの学習を行う. 事前に三目並べの全手順が書かれたデータセットを用意し,学習させるデータ数を割合で増やしていったときに,どの程度三目並べプレイヤーの学習に影響がでるかを,対戦を行うことで比較検討する.
学習にはLSTMモデルを使用する.以下にモデルの構造を示す.
| 層数 | 入力層 | 隠れ層 | 出力層 |
|---|---|---|---|
| 3 | 9 | 256 | 9 |
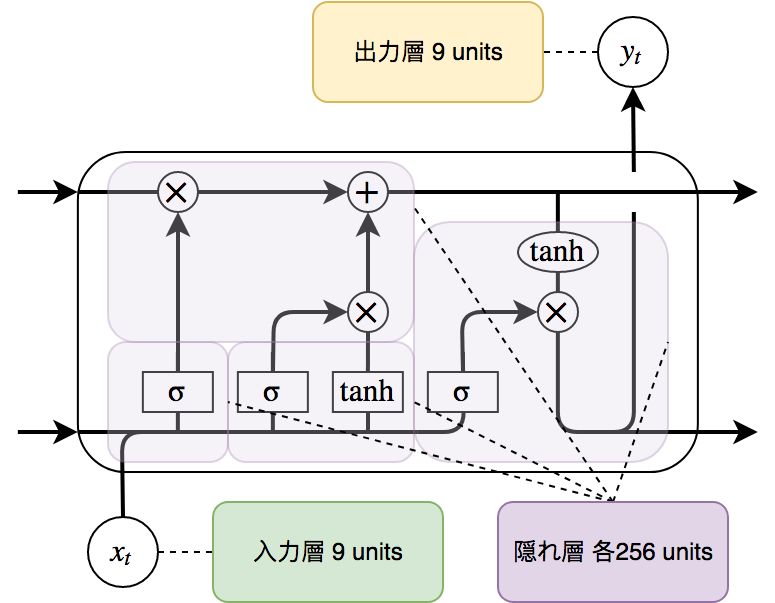
実験環境は次の通りである.
| 項目 | 環境 |
|---|---|
| OS | Ubuntu 18.04 |
| CPU | Intel Core i9-7900X 3.30GHz |
| RAM | 8GB |
| GPU | NVIDIA GeForce RTX 2080Ti |
| 項目 | 環境 |
|---|---|
| 言語 | Python 3.6.6 |
| 深層学習 | Tensorflow 1.12.0 |
| 数値計算 | Numpy 1.15.4 |
| データ処理 | Pandas 0.23.4 |
三目並べは3×3のマス目があるため手順は9!通り以下である. そこからゲームルールに合致するもののみを抽出しデータセットを作成した. 各データはゲーム開始からゲーム終了まで,1ゲームにおける手順を含んでいる. 本実験ではプレイヤーの学習を後手の場合のみに絞り学習を行う. そのため,学習には後手勝利の手順のみの場合と,後手勝利手順に引き分け手順を加えたものの2種類を与えることとした.
| 項目 | 三目並べデータセット |
|---|---|
| 先手勝利手順数 | 131,184 |
| 後手勝利手順数 | 77,904 |
| 引き分け手順数 | 46,080 |
| 全状態遷移数 | 255,168 |
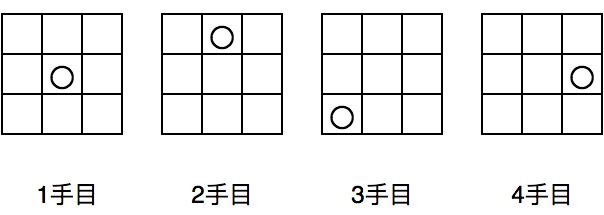
実際にモデルにデータを渡す前に正規化を行う. モデルに与える入力データを後手盤面の状態,教師データをその盤面における返答とした. 盤面の状態は0が空白,1が☓(先手),2が○(後手)とする. 三目並べは最大9手で終了するが,本実験では後手の場合に限り学習を行うため,最大4手分を考慮すれば良い. 4手に満たない(既に勝敗が決定している)場合は0 paddingを行う. 教師データはOne-hotで表現する. One-hot表現では,正解を表す1が1つだけあり他はすべて0で表される. そのため本実験では1が立っている場所が次に打つべき箇所となる.以下に具体例を示す.
以下に入力データの例を示す.
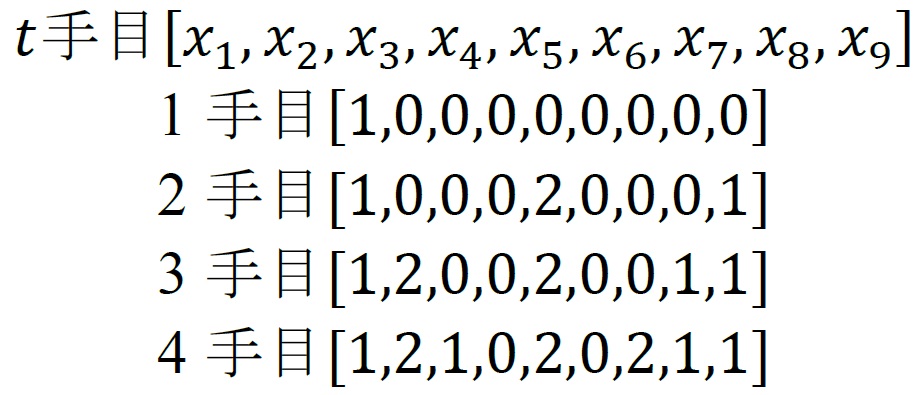
上記の入力データに対応する教師データの例を示す.

以下に0paddingの例を示す.

まず学習させるデータ数による影響を比較するために,LSTMモデルを複数作成する. モデルを作成する際,与える学習データを割合で増やしていく. 増やす割合はbatch sizeを基準とし,本実験ではbatch sizeは512で固定することとする. モデルに対して学習データを与える際は,全学習データからランダムに抽出したデータをモデルに渡す. LSTMモデルを作成後,作成したモデル毎にランダムに手打つプレイヤーと10000回の対戦を行い,その勝敗数からモデルに与える学習データ数による影響を測定する.
まず後手勝利手順のみを学習させたモデルから示す. 縦軸がプレイヤー毎の勝率と引き分けの割合,横軸は左から学習データが少ないモデルを表している.
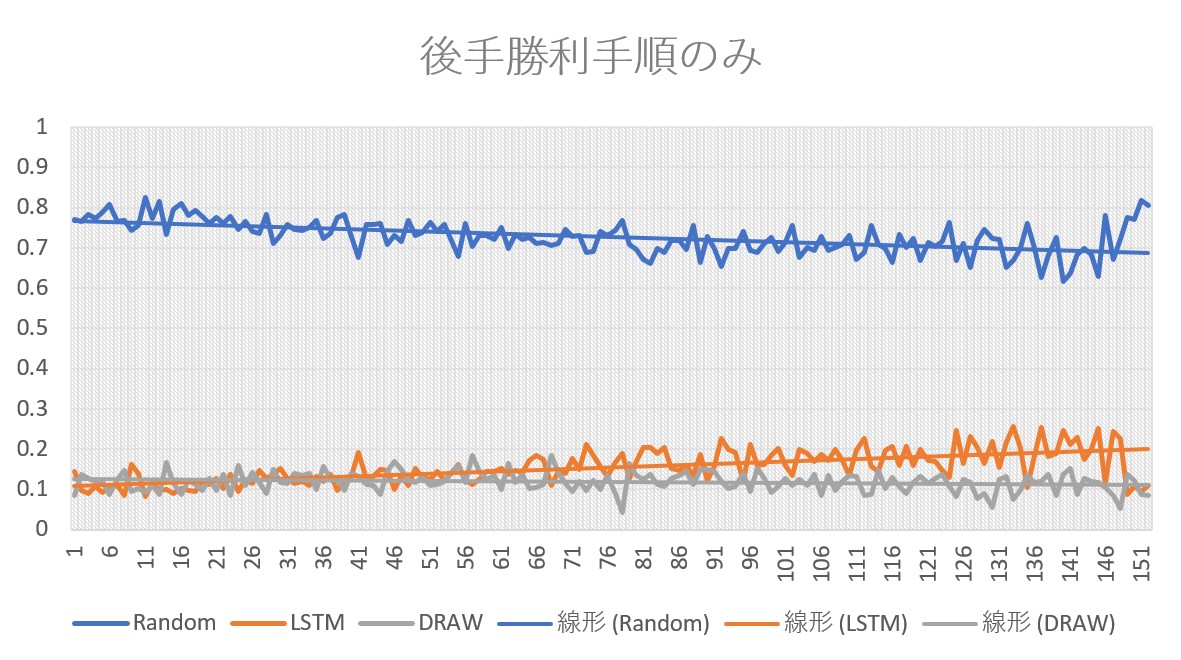
次に後手勝利手順に引き分け手順を加えて学習させたモデルを示す.
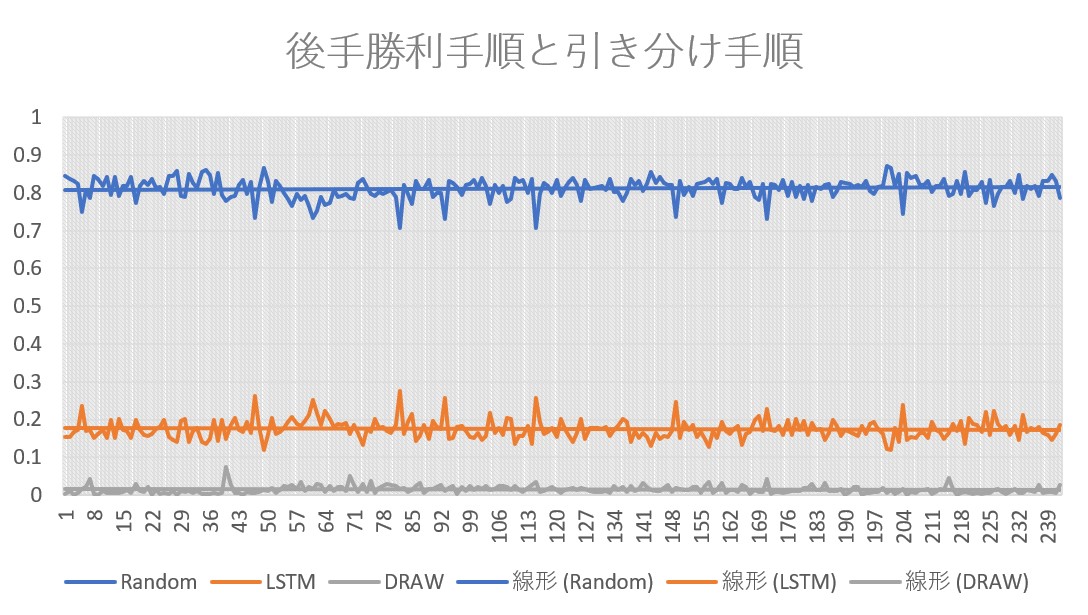
後手勝利手順のみを与えたモデルでは,与える学習データ数の増加とともにモデルの勝率が上昇することを観測できた. しかし引き分け手順を加えたモデルでは,学習データを増やしても勝率が上昇しないどころか,引き分けの割合が後手勝利手順のみを与えたモデルよりも低い結果がでた. 勝つための手と引き分けを目的とする手で競合してしまっているものと見られる.
また,本研究では全状態遷移を学習対象としているため,同盤面における返答が複数あり,それが学習精度や勝率に影響してしまっているのが見受けられた. 本実験では三目並べを対象としているため,教師データの最適化を施すことは容易である. しかしゲームプレイヤーを制作するといった観点からみると,三目並べに限らず囲碁や将棋といったゲームを対象とする場合もある. これらのゲームでは組み合わせ爆発が起こるため,状態数が膨大となり,どの手が最適であるか容易に判定できない場面が出てくる. そのためプロの棋譜などを利用し学習を行うが,与える教師データにより精度に大きく影響してしまうデメリットがある. そこで教師データの最適化以外の方法で,プレイヤーの能力を向上させることが出来ないか検討を行いたい.
例えば本研究で用いたモデルは全状態遷移を学習させるものであり,ゲームに負けないための目的をモデルに与えられているわけではない. 「勝てる見込みがあるときは勝つための手を打ち,負ける可能性がある場合は引き分けに持ち込むための手を打つ」といった複数の目的を最適化する方法が考えられる.
また本実験では,モデルに対し与える入力データの盤面状態を,0が空白,1が☓(先手),2が○(後手)というように表現した. 入力データの表現の仕方を変えることで,モデルの精度向上が図れると思われる. 例えばユニット数を倍に増やし,先手と後手とで表現する領域を分けることにより,1のみでデータを構成することが考えられる.
本研究では,LSTMモデルを用いて三目並べプレイヤーを作成した. 三目並べのような簡単なゲームであっても単純にデータを与えるだけでは上手く学習が行えないことが分かった. また後手勝利手順のみを与えるモデルでは,教師データの量によってゲームプレイヤーの強さに影響を及ぼすことが確認できた. 今後としては,前処理によって学習精度・効率の向上が図れるかどうか,多目的最適化を行う必要があるかを検討したい.
使用したプログラムの全文を載せるとともに,各プログラムの関数に対し説明を行っていく.
| 関数名 | 動作説明 |
|---|---|
| __init__ | コンストラクタを定義している. |
| search | 順列を用いて全手順を生成し,その手順から三目並べの盤面を再現することで,三目並べにおいてゲームが成り立つ手順のみを抽出している. 三目並べは最低5手最長9手でゲームが終了するので,盤面のマス目を表す0~8の9つの数字の中から,5~9つ選んだ場合の並べ方を考え,そこからゲーム上あり得る手順のみを取り出すようにしている. また,勝敗が決まっているのにゲームが続いてしまっているような手順は除く. |
| cheak_board | search関数において生成した手順から三目並べの盤面を再現しているが,その盤面上において,○或いは✕が3つ縦横斜めのいずれかに並んだときのみTrueを返す関数になっている. |
| temp_recording_fs | cheak_board関数においてTrueが返され,かつゲーム上あり得る手順だった場合,先手における勝利手順か後手における勝利手順かを判定し,一時的に変数に記録する. |
| temp_recording_d | temp_recording_fs関数と同様で,ゲーム上あり得る手順であり,かつ引き分けの条件を満たす場合,一時的に変数に記録を行う. |
| writing_files | temp_recording_fs,temp_recording_d関数において,一時的に記録しておいたデータをcsvとしてfileへ書き込みを行う. |
| 関数名 | 動作説明 |
|---|---|
| __init__ | コンスタラクタの定義を行っている.csvfileの読み込みを行っているが,このとき後に前処理を行う都合上,各手順が9手分の長さを持つように調整を行っている. |
| generate_learning_data | 学習データの前処理を行う.手順から各盤面の状態へ変換を行う. このとき学習データが1ゲーム毎の情報になるように区切り,9手分の長さに満たない場合は0でpaddingを行う. このとき教師データの生成も同時に行い,各盤面における返答をone-hotで表現する. |
| reduce_data | batch sizeを基準としてモデルの生成を行っていくため,学習データに対し端数が出てしまう. ミニバッチの大きさを可変としモデルに与えることは難しいため,学習前にデータの削減をしておく. なおデータの削減を行う前にはデータをシャッフルする. |
| splitting_datasets | モデルに対し決まった量の学習データを与えるため,実際にモデルに渡すデータセットを全学習データから分割する形で生成する. |
| 関数名 | 動作説明 |
|---|---|
| __init__ | コンスタラクタの定義を行っている. モデル各層のユニット数を定義するとともに,LSTMがどの程度の長さ時系列予測を行うかを定義する(max_len). 今回後手のみに絞りモデルに推論させるため,長さは4となっている. |
| inference | モデルに推論を行わせる. モデルの構造をこの関数で定義し,重みやバイアスなどもここで定義,初期化を行う. TensorFlowでは計算グラフの生成を行い,そのグラフに従ってモデルの出力がなされる. あらかじめ入力データの予定地(placeholder)を用意する形でグラフを生成し,実際に処理を行う際にデータを渡す. そのためグラフに対しこの関数はあくまでモデル定義を行っているだけであり,この関数はグラフの作成のために一度だけしか呼ばれない点に注意する必要がある. つまりモデルの学習時(実際にデータを渡して学習を行うとき)この関数は使用されない. 以下に関数の説明を述べていくが,このことを前提とし説明を行う. 細かく行単位で処理を追っていく. ・inferenceに入力データが与えると,まず与えられたデータのbatch sizeを取得する. ・__init__により定義された隠れ層のユニット数からLSTMCellを定義する. ・LSTMCellの初期状態の設定を行う. ・RNNCellで指定されたリカレントニューラルネットワークを作成する.モデルの時系列に対する動的な展開を行う.このときbatchにおける各入力データの時系列長情報(sequence_length)をベクトルで渡すことでそのステップ数分だけリカレントネットワークは展開を行うことができる.padding部分は全て0で返される. ・出力層における重みとバイアスを定義. ・出力層の重みとバイアスを適用させる前に,Cellのoutputにmaskを掛ける. ・outputに重みとバイアスを適用. ・outputの形状をmaskを掛ける前に戻す. [batch size, sequence length(max_len), 出力層のユニット数] ・outputをモデルの予測(prediction)として出力する. |
| weight_variable | 重みの変数スコープと初期状態の設定を行う. |
| bias_variable | バイアスの変数スコープと初期状態の設定を行う. |
| cost | モデルの予測と教師データとのクロスエントロピー誤差を返す. なおモデルの予測(出力)にはソフトマックス関数を適用させるが,使用するAPIの都合上,ソフトマックス関数の適用とソフトマックス関数適用後の教師データとのクロスエントロピー誤差の計算処理は同時に行う. |
| training | パラメータの最適化処理をAdam Optimizerによって行う. |
| accuracy | モデルの出力と教師データとでどれだけ一致しているかを求め,モデルの学習データに対する予測精度を測る. |
| length | inference関数においてモデルの時系列展開を行うとき,padding部分を考慮して出力を行う場合,各入力データに対する時系列長情報をベクトルで渡さなければならない. そのためこの関数を用いて時系列長の計算を行う. |
| reshape_1 | 本実験では三目並べを対象として学習を行うが,手順において最長である9手に満たない手を多く扱うためpadding部が大きくなる. そのため学習データが比較的疎な行列となるが,そのまま重みやベクトルを適用すると余分な処理が増えてしまう. そこでCellのoutputに対してmaskを掛けることで,一時的にpadding部を除く. |
| reshape_2 | reshape_1関数によって除かれたpadding部を戻す. |
| train | 入力データと教師データのplaceholderの定義,計算グラフの流れを記述し,実際に学習を行う. 計算グラフの流れは以下の通りである. 1. inference関数にbatch size分の入力データを渡し,モデルの予測を受け取る. 2. モデルの予測からloss関数によって教師データとの誤差を取る. 3. training関数に誤差を渡し,各パラメータの更新を行う. 4. accuracy関数により,モデルの予測と教師データの比較を行い,モデルの予測精度を測る. 上記の流れを全入力データ渡しきるまで行う. 全入力データを渡しきったところを1epochとし,事前に決めておいた回数分だけepochを繰り返す. |
class TTTBoardは三目並べのゲーム自体である. 三目並べにおける盤面の各操作を担う.
| 関数名 | 動作説明 |
|---|---|
| __init__ | コンストラクタの定義. 三目並べの盤面を生成するが,TTTBoardの生成時,盤面が渡された場合はそちらを優先する. ゲームの勝者はNoneとする. |
| get_possible_pos | プレイヤーが打てる手(箇所)を返す. |
| print_board | 盤面を表示する. |
| cheak_winner | 勝者がいるかどうかを判定する. |
| check_draw | 引き分けか否かの判定を行う. |
| move | プレイヤーが選んだ手を受け取り,盤面に打つ. その後,勝敗と引き分けのチェックを行う. |
| clone | 盤面を複製する. |
class TTT_GameOrganizerは三目並べ(TTTBoard)と各プレイヤーの橋渡しを担う.
| 関数名 | 動作説明 |
|---|---|
| __init__ | コンストラクタ. ☓や○に対するプレイヤーの対応,勝敗数の初期化,盤面や結果の表示を行うかの設定などを行う. |
| progress | ゲームの進行を行う.以下にゲームの基本的な流れを記述する. 1. 盤面を初期化し,☓のプレイヤー(本実験ではPlayerRandom)を先手とする. 2. プレイヤーが盤面に対して交互に打つ(関数act). 3. プレイヤーが手を打つたびに盤面の判定を行い,勝敗か引き分けが決まるまで2を繰り返す. 4. 1~3の流れを一定回数行い,勝敗数の記録を行う. |
| switch_player | 打つプレイヤーを入れ替える. |
class PlayerRandomは三目並べをランダムに打つプレイヤー.
| 関数名 | 動作説明 |
|---|---|
| __init__ | コンストラクタ. プレイヤーの名前と自分のターンを設定. |
| act | 盤面に対して打てる場所を取得し,そこから乱数を用いて打つ. |
class LSTMは本研究で作成した三目並べを打つプレイヤー.
| 関数名 | 動作説明 |
|---|---|
| __init__ | コンストラクタ. プレイヤーの名前と自分のターンの設定,保存されたモデルを読み込むための各種パラメータ復元,入力から出力を行うまでのグラフの流れを記述する. また,作成したグラフに実際に演算処理をさせるためのオブジェクトsessionを開く. |
| softmax_function | モデルの出力に対してsoftmax関数を適用する. |
| masked_softmax | モデルに予測させた手を打たせるが,予測した箇所が既に打たれてしまっている場合がある. その場合は既に打たれた場所は打つ選択肢から除き,その上でモデルが出力した確率分布の中で最も確率が高い場所を打たせる. Pythonにおいてsoftmaxの計算ではexp(-inf)=0であることを利用し,マスキングすることでこれを行う. |
| act | 実際に盤面の情報をモデルに渡し,予測をさせる. 予測後盤面に対して手を打たせるが,予測した手が既に打たれてしまっている場合はmasked_softmax関数を使用する. |
| preprocessing | act関数においてモデルにデータを渡すが,その前に適切に処理を行えるようデータに整形を加える. モデルに渡すデータの形状は [1, 時系列長(4), 入力層のユニット数(9)] でなければいけないので,時系列長が4の長さになるよう時系列に対するpaddingを行う. |
| processing_of_output | モデルの学習時入力と出力の関係がmany to manyであったが,次の手を打つために必要な情報は1つだけであるため,出力から過去の情報とpadding部を除きmany to oneの形へ変換を行う. |
| close_session | sessionを閉じる. |