映像合成とは, 3Dシーンを表現するポリゴンメッシュ, 光源, カメラからなるデータ群を入力として, それに対してカメラから見える2次元画像を計算することである. 特に, PCやゲーム機で得られる映像出力は, リアルタイムに映像合成して出力されたものである. そのため, 高い品質の映像と高速な処理の両方が要求される. 現在, パソコンやゲーム機の画面表示など一般的に普及している映像合成方法は, ラスタライズ法という手法によるものである. この処理の専用回路を搭載したGPUによって高速に行われる. この手法は, 3次元のシーンを2次元の画像に投影し, その画像を2次元の図形の組み合わせで近似をしている. そのため, 特にダイヤモンドや水面等の光が複雑に反射するような 複雑な光学現象を伴うシーンの表現は困難である. これに対して, 投影をするのではなく, 光に関する物理現象を シミュレーションすることで, 複雑な光の反射を含むような写実的な映像の合成手法がある. これをパストレーシング法という. これは従来, 映画やアニメーション等の高品位な映像の合成を行う分野で用いられていたが, 専用処理デバイスが存在しないため 高速な映像合成が困難である. そのため, ゲーム機やパソコンなど一般には普及していない.[1] 以上から, パストレーシング法による映像合成をパソコンやゲーム機などの一般的なデバイスに普及させるためには, パストレーシングの高速化が必要である. このためにはラスタライズ法におけるGPUに相当する, パストレーシング法の処理を行う専用デバイスが必要である.
一方で, FPGAはハードウェア動作を記述した専用回路によって高速に処理可能なデバイスであり, GPUに代わるアクセラレータ として利用が広まっている. 特に, FPGAとCPU, メモリを統合したSoC FPGAは, ソフトウェア動作とハードウェアによる高速な処理の両方を活用できる. このSoC FPGAを, 深層学習や自動運転などのアプリケーションにおいて, GPUの代わりに用いることで高速化している例がある.[2]
そこで本研究は, SoC FPGAを用いてパストレーシング法を専用に実装した新たな仕組みの映像合成ハードウェアを提案し, パストレーシング法による映像合成処理を高速化することを目的とする.
本論文の構成は以下のとおりである. 第1章で, 本研究の背景と目的を述べる. 第2章で, 本論文で用いる用語や技術, 開発方法についての説明を述べる. 第3章で, 本研究に関連する理論を述べる. 第4章で, 本研究に関連する研究と関連を述べる. 第5章で, 本研究の提案手法について述べる. 第6章で, 提案手法を元にした実装と結果, その評価を述べる. 第7章で, 本論文の考察を述べる. 第8章で, 本論文の結論を述べる.
本章では本研究において必要な予備知識についての解説を述べる.
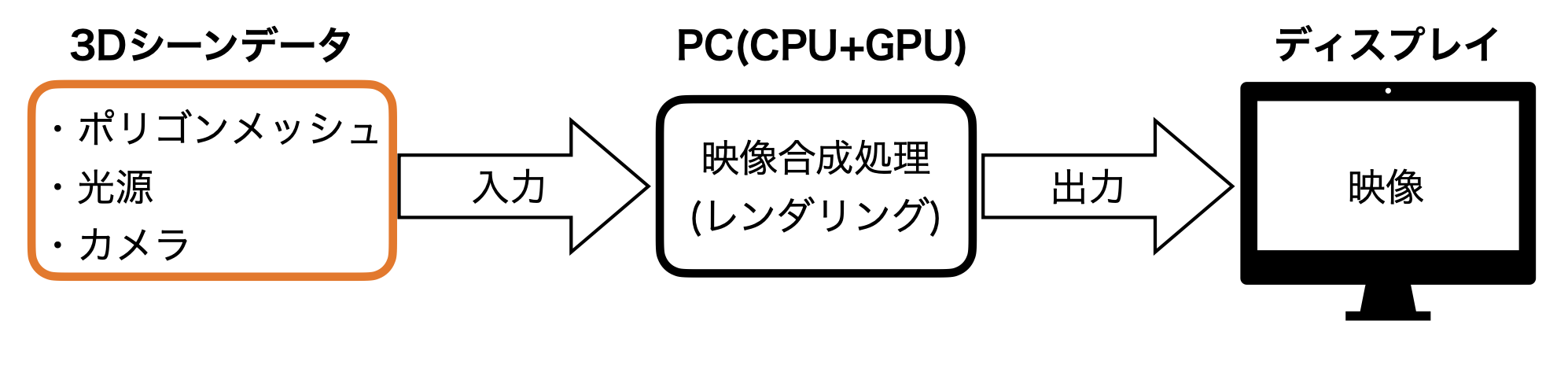
コンピュータにおける映像合成とは, 物体を表すポリゴンメッシュ, 光源, カメラからなる3Dのシーンデータを入力として, 映像合成処理の計算を行い, 計算結果の映像をディスプレイに出力するものである. 図2.1 にコンピュータにおける映像合成の概要を示す.
コンピュータにおいて行われている計算が映像合成処理であり, 主にラスタライズ法とパストレーシング法の2つが存在する.
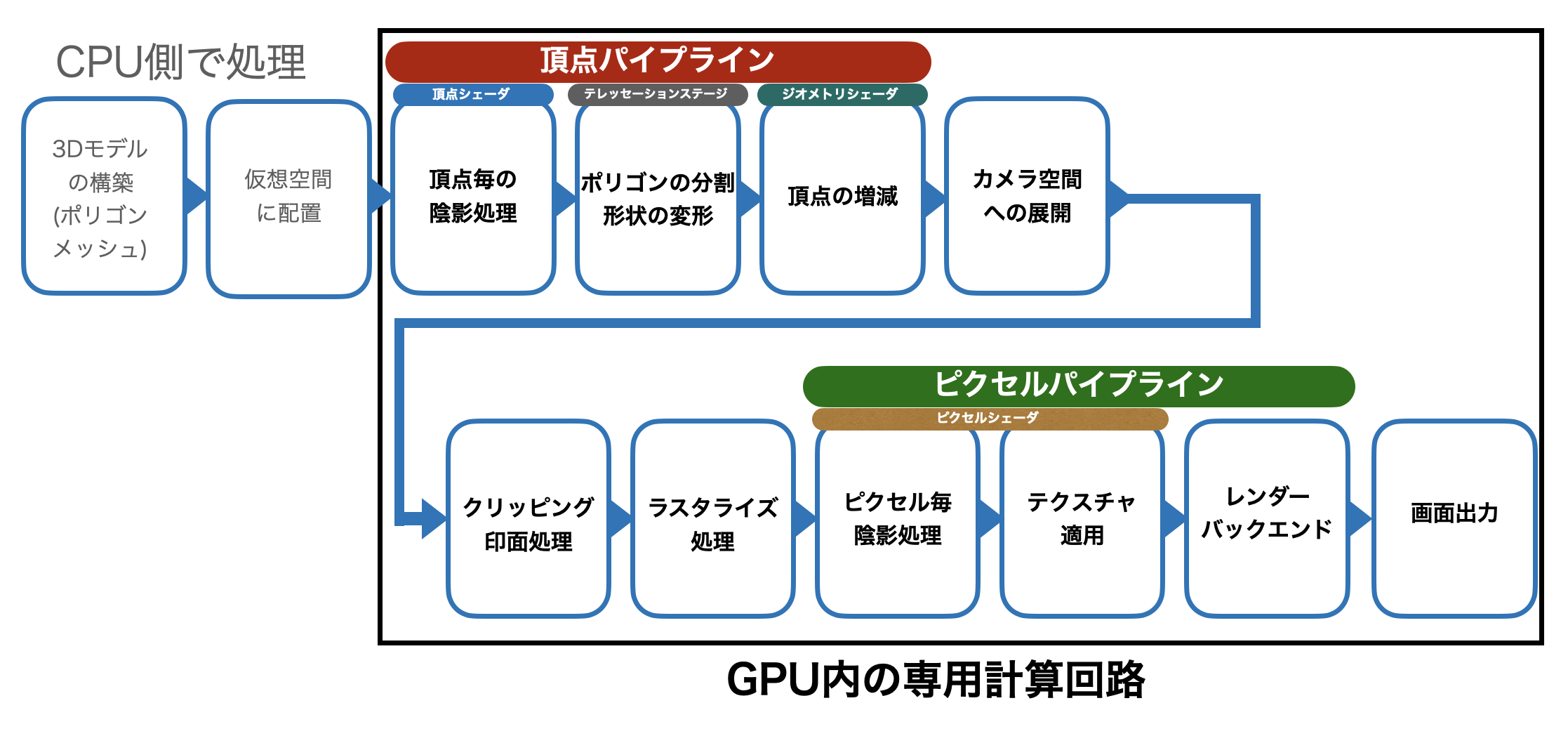
ラスタライズ法は, 図2.2 に示すパイプラインによって処理され, この処理回路を搭載した専用ハードウェアであるGPUを用いて高速に映像合成処理が行われる. そのため, PCやゲーム機などの一般的なデバイスで用いられている.
ラスタライズ法は高速に処理ができる一方で, 仮想的な2Dのスクリーン位置と3Dの物体位置および視界を定義し, 視界内の3D物体を2Dのスクリーンに投影した上で, 2D図形の集合であるテクスチャ画像により近似して映像表現しているため, ダイヤモンドや水面などの複雑な光学現象を伴うシーンの表現は困難である.[1]
物体が見えるのは, 光源から出た光が物体に反射して目に届いているためである. そのためパストレーシング法は, シーン内で行き交う光の物理現象を再現し, 光源から視点への光の到達方法を計算する. これにより, 物体表面における材質ごとの光の反射や屈折, 散乱を再現した写実的な映像を合成する. パストレーシング法における光線追跡は, 視点から光源に至る経路(パス)を生成することで行う.[3] 図2.3 にパストレーシング法での光線追跡のイメージを示す.[3]
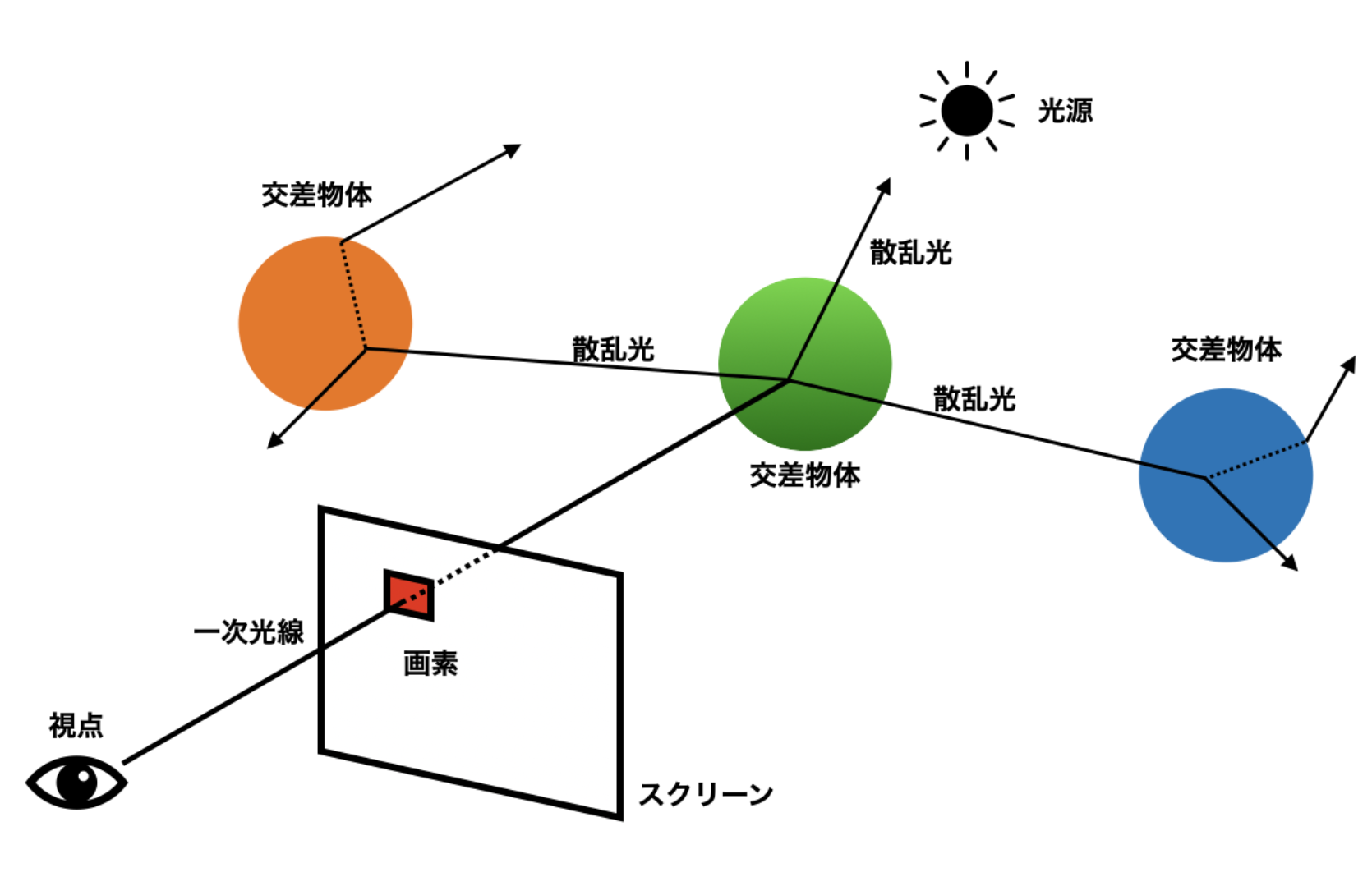
図中において, 経路の生成は以下のステップで行う.
1次経路の生成(視点→画素)
物体との交差判定
物体表面での散乱光サンプリング
次の経路の生成(物体表面→サンプリング方向)
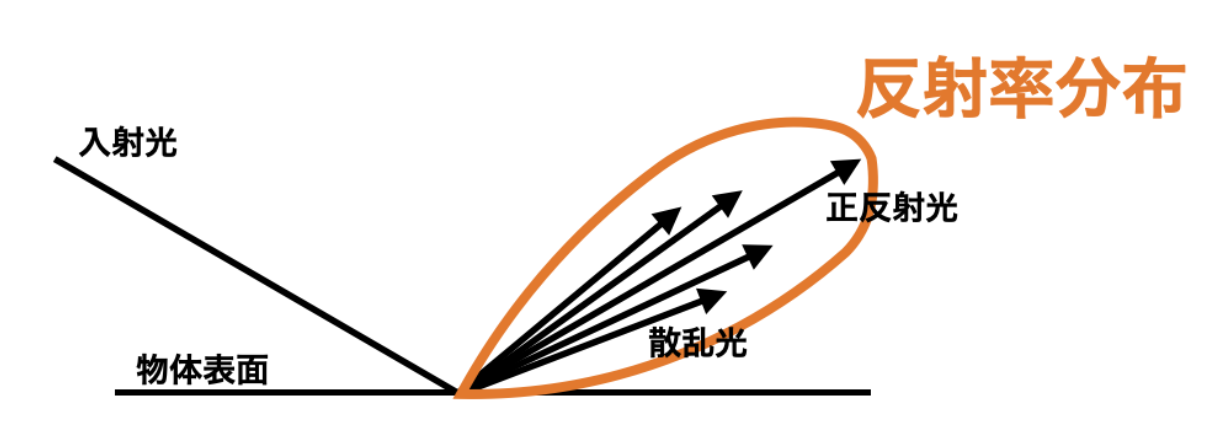
以上の光線の経路生成を繰り返し, 経路が光源に達するまで経路の深度を深めて, 経路を完成する. また, 完全鏡面でない一般的な拡散反射面においては, 図2.4 のように完全反射ではなく反射率分布を持った散乱を起こすため, 繰り返しサンプルを行って経路を多数生成することで, 反射率分布内を細かく網羅することで品質のいい経路生成を行なって計算誤差を減らす. 最後に, 生成した全ての経路を用いて画素値を計算することで, 映像合成結果を得る.
GPU(Graphics Processing Unit)は, ラスタライズ法を用いた映像合成処理に特化したプロセッサであり, 高速な画像処理と映像合成を可能にしている. PCやゲーム機においては, GPUを用いてリアルタイムに映像出力を行っている. GPUは, コンピュータ内でPCI Express経由でCPUと相互に接続され, CPUから描画対象データと描画指令をVRAMで受け取る. GPUは受け取ったデータと指令を元にラスタライズ法による映像合成を行い, 映像出力端子からディスプレイに出力する.[4]
また, GPUにはシーンデータの回転や拡大を高速に行うために用意された行列演算を並列に行うことができるコンピュートシェーダが内包されている. この行列演算回路と高帯域のデータ転送ができるVRAMを組み合わせて, ラスタライズ法以外の大きなデータを扱う演算に応用する技術がある. これをGPGPU(General-purpose computing on graphics processing units)と呼ぶ.[4]
FPGA(Field Programmable Gate Array)は書き換え可能なハードウェアデバイスであり, そのFPGAが持つリソースの範囲内で自由にロジック回路を構築することができる. FPGAのリソースにはLUT(Luck Up Table), FF(Flip-Flop), DSP (Digital Signal Processor), BRAM(Block-RAM)が用いられている.
LUTは特定の入力に対する出力の値を事前に格納しておくメモリであり, 複雑な関数やアルゴリズムを直接計算する代わりに, 事前に計算された結果を瞬時に参照することで高速な処理を実現する. FFは, 同期回路においてクロック信号に基づいてデータの状態を変更する. DSPはデジタル信号に対する高性能な演算を実現する. BRAMは, ブロック構成のランダムアクセスメモリであり, FPGAのプログラマブルロジック内に組み込まれ, 高速なデータアクセスを可能にする.[2]
これらを用いて回路を合成するため, 回路記述はRTL(Register Transfer Level)設計または高位合成によって行う. RTL設計はハードウェア記述言語であるVHDLまたはVerilog言語を用いて回路動作をレジスタ転送レベルで記述するものである. 一方で, 高位合成は高級言語であるC言語またはC++を用いて動作記述を行ない高位合成ツールを用いてRTLを生成するものである. 直接記述または高位合成により生成したRTLから回路合成を行い, FPGAに回路データであるビットストリームデータを書き込んで動作させる. これにより, 開発者が意図した動作をFPGAにおいて専用回路として動作させることができる.[5]
SoC(System-on-a-chip)とは, 従来別々のダイで構成されていたデバイスを統合することで, システム全体をひとつの集積回路上に実現するものである. 特に, SoC FPGA(System-on-a-chip Field-Programmable Gate Array)は, FPGAとCPU, DDRメモリ, 周辺機器インターフェースを統合してワンチップに集積したものである. SoC FPGAにおいては, FPGA部分をPL(Programmable Logic), CPU部分をPS(Processing System)と呼称し, PLに実装できる高度な処理能力を持つ専用演算回路とPSでの柔軟なソフトウェア動作を兼ね備えたデバイスである.
また, PCとSoC FPGAを調歩同期式シリアル通信であるUARTで接続することで, SoC FPGA内のPSとPCのCPUとの通信を行い, PCからFPGAへの動作指示の送信, PSからPCへのコンソール出力を行うことができる.
SoC FPGAは, 人工知能を用いた画像認識やルート検索を伴う自動運転などの, 高度な処理能力と柔軟な処理を必要とする 組み込みアプリケーションにおいて用いられ, GPGPUを置き換えている.[2]
CPUのアーキテクチャを記述した回路をFPGAに書き込むことで, FPGAを簡易的なCPUを実装し, 動作させることができる. これがソフトマクロCPUである. ソフトマクロCPUは最小限の機能で任意のあらゆる仕様のCPUを作ることができる一方で, FPGAはCPUに比べて非常に低速なクロックで動作するため, 処理能力が低い.[5]
ハードマクロCPUとは, 元からCPUとして専用に設計され, 最適化が完了した状態で製造されたCPUである. これは, 一般的なPCにおけるCPUや, SoC FPGAにPSとして搭載されているものである. ハードマクロCPUは仕様を変更することはできないが, ソフトマクロCPUに対して多くの機能と高速な処理を提供する.[5]
FPGAにおいて大規模な回路を構成する際, ロジック素子単体ではなくロジック回路を一つの部品として扱い, その回路同士を接続して抽象的な回路図を作成することで全体のシステムを構成する. FPGA開発においてはこの回路単位をIP(Intellectual Property Core)コアと呼び, 再利用可能な回路コンポーネントの設計データとして定義される. また, IPコアを接続して作成した回路図はダイヤグラムという. IPコアは自身でRTLまたは高位合成により作成する他, FPGAベンダーから無償または有償で提供されるものがある.[5]
FPGAにおいては, 計算にかかる処理時間をレイテンシとして表現する. レイテンシはクロック周期とそのクロック周期において処理が終了するクロック数によって求められる. このレイテンシを評価することで, 合成したIPおよびそれを組み込んだシステムの性能を測ることができる.[5]
コンピュータにおいて, 複数の処理を同時に行うことを並列処理という. C言語におけるfor文やwhile文などのループ処理は, 繰り返しの処理を複数の計算機を使って同時に行うことができ, FPGAでは回路合成時に並列化することができる. ループ処理の並列化方法にはパイプライン処理とアンローリングがある.
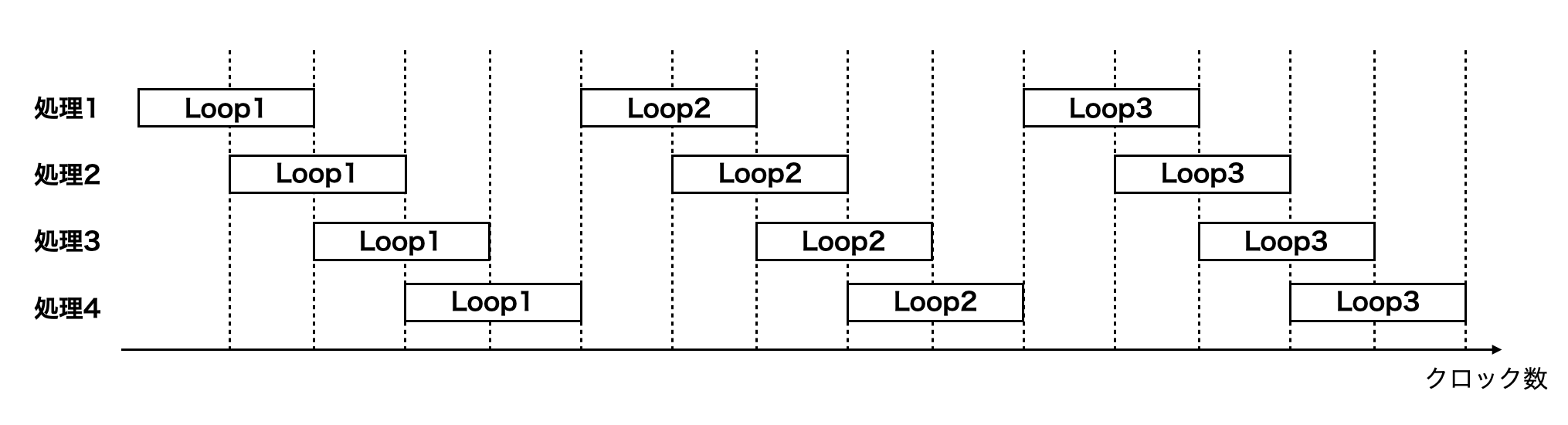
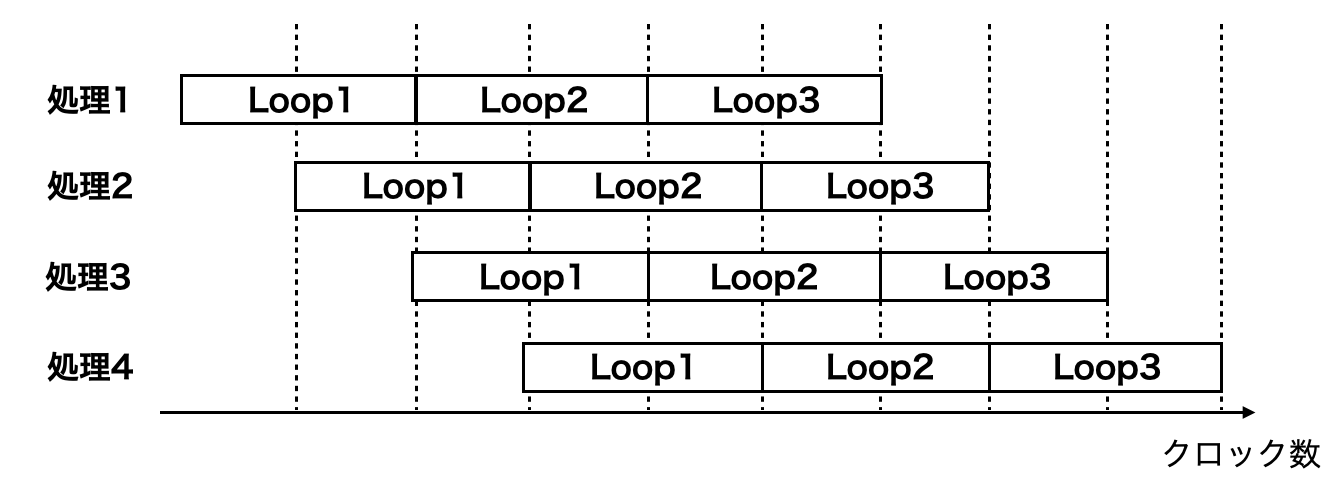
ここで, 処理1, 2, 3, 4からなるループを3回繰り返す処理を行うとする. 通常行われる逐次実行では 図2.5 のようにループで4つの処理が終わるごとに次のループを実行するため, ループの繰り返しの数倍処理時間がかかる. これに対して, パイプライン処理は, 図2.6 のようにループ内の4つの処理が全て終了する前にデータが競合しなければ次のループの処理を始めることで 全体の処理時間を短縮するものである. また, アンローリングは, ループ同士にデータの競合や依存関係が存在しなければ, そのループを全て同時に実行する. アンローリングは1つのループの実行時間で全てのループの実行を完了できるが, 繰り返しの数だけ回路が必要になるため, ハードウェアリソースの使用量が大幅に増える.[6]
Advanced eXtensible Interface(以下, AXI)はARM社により定義されたインターコネクトインターフェースプロトコルであり, 現在のバージョンはAXI4である. SoC FPGAにおけるPSとPL間のデータ転送はこのバスによって実現している. データ転送にはGP(General Purpose Ports), HP(High-Performance Ports), ACP(Accelerator Coherency Port)の 3種類のポートが用いられ, 高パフォーマンス用途のFull AXI4, 単純なレジスタ通信等に用いるAXI4-Lite, 高速なストリーミングデータ転送に用いるAXI4-Streamの3種類の規格で通信を行う.[7]
SoC FPGAの開発には, FPGAで実現するアルゴリズムの記述, FPGAで専用回路化する回路のC/C++による記述と高位合成, IPブロックの作成, IP同士を接続して回路の構成, PSにおける回路制御およびソフトウェア動作の記述のステップが必要である. 本研究で用いるXilinx社製SoC FPGAの開発においては, ハードウェア開発環境である「Vivado」, ソフトウェア開発環境である「Vitis」 を用いる. Vitis HLSを用いて高位合成による専用回路の実装, Vivadoを用いてPSとIPの回路の構成, Vitis Classicを用いてPSで動作するソフトウェアを実装する.[5]
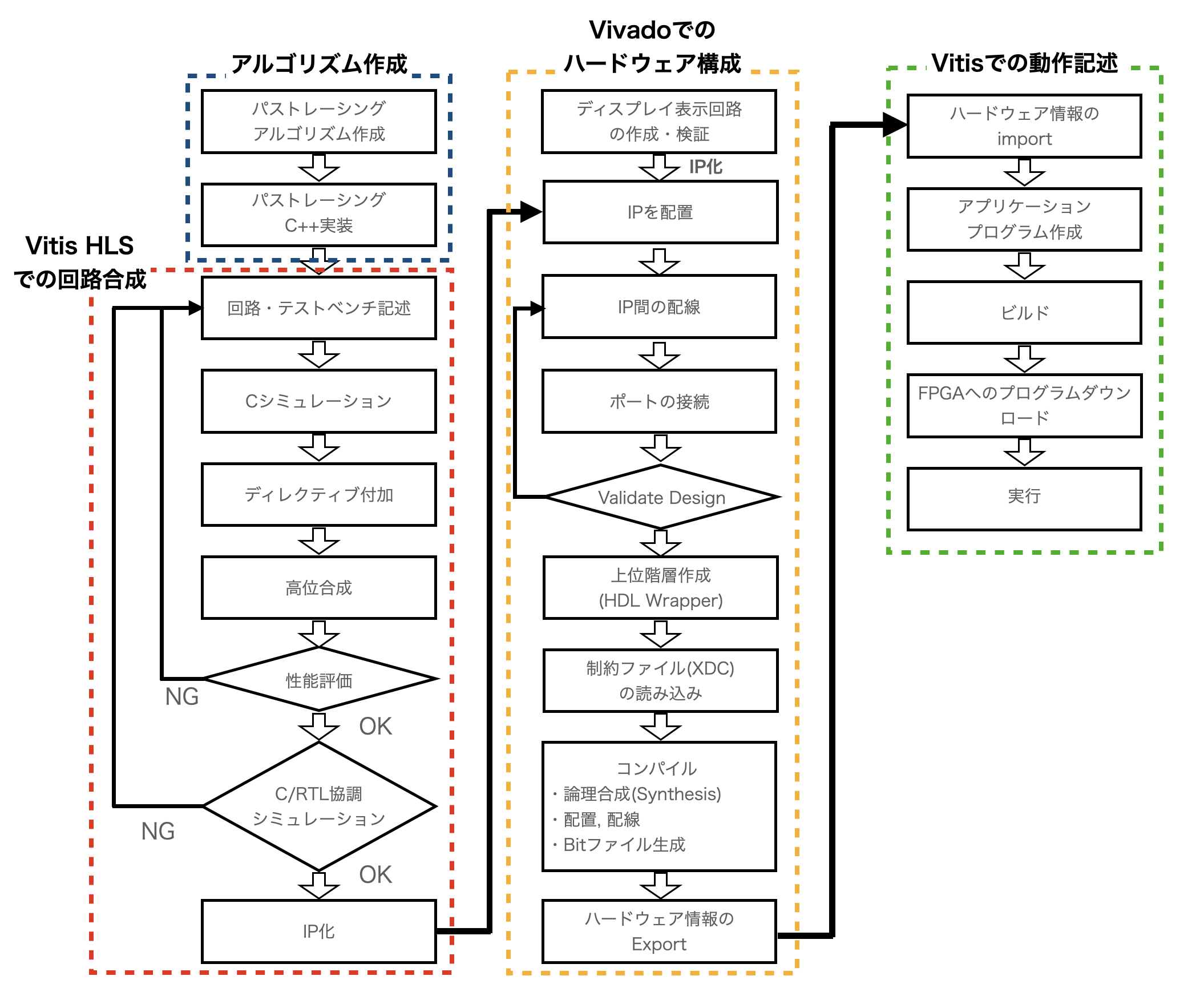
SoC FPGAの開発にあたり, 開発段階の各ステップでテストが必要である. 図2.7 に開発とテストを合わせたフローを示す.
Vivadoでの開発段階においては, 配線を行ったダイヤグラムに対してValidate Designによるデザイン検証, Generate Bitstreamによるビットストリーム書き出しの可否, 動作時の電力および回路規模を確認することで, 正常な動作が可能かテストする. もし問題があれば, 配線の修正, IPコアの再構成を行う.
Vitis HLSにおいては, アルゴリズム由来の問題の有無を"C Simulation"で検証, 回路規模およびレイテンシを"C Synthesis"で検証, 最終的なRTLでの正常動作をC/RTL Co Simulationによって行う.[5]
Vitisにおいては, 動作記述のビルド, デバッグモードでのオンボード実行により最終的な正常動作が可能か検証する.
本章では本研究において必要な予備知識についての解説を述べた.
本章では, 研究で扱う理論について詳細に述べる.
立体角(Solid Angle)は一般的な角度である平面角を立体に応用したものであり, 単位はステラジアン[sr]を用いる. 平面角[rad]が平面上の一点から出る直線上が単位円を動く長さを示すのに対して, 立体角は3次元空間上の一点から出る直線が単位球面上を動く面積で表される. 故に, 平面角は1周が2\(\pi\)(単位円の円周) で表されるのに対して, 立体角が全方位を表すと4\(\pi\)(単位球の表面積)となる.
光の粒子(フォトン)の放出量について総放射量\(\Phi\)[W]を放出している面 を考える場合, その中の一点から放出される放射束は総放射束量を位置に関して微分したものと言える. これを放射発散度と呼び, 微小面積からあらゆる方向へと放出される放射束量の定義であり, 式\eqref{equ:rad_emittance}で表す. \[\label{equ:rad_emittance} \tag{3.1} M=\dfrac{d^2\phi}{dxdy}=\dfrac{d\phi}{dA}(W \cdot m^{-2})\] 放射発散度と逆にある面に入射するフォトンの物理量の場合は放射照度(irradiance, E)で表される
総放射束量Φ[W]がある点からなんらかの分布を持ってあらゆる方向へ放出されている場合, ある方向への放出量は総放射束量を微小立体角で微分することで求められ, これを放射強度(radiance intensity, I)で表し, 式\eqref{equ:rad_strength}で表す. \[\label{equ:rad_strength} \tag{3.2} I=\dfrac{d^2\phi}{sin\theta d\theta d\phi}=\dfrac{d\phi}{d\omega}(W \cdot sr^{-1})\]
レイトレーシングにおいて, 光の基本単位として用いられる単位である. 放射発散度と放射強度を合成した物理量であり, 放射束を投影微小面積で微分したものをさらに微小立体角で微分することで求められる. 放射輝度は 式\eqref{equ:radiation}で表す. \[\label{equ:radiation} \tag{3.3} L(x, \omega)=\dfrac{d^2\phi}{cos\theta dA d\omega}=\dfrac{d\phi}{dA}(W \cdot m^{-2} \cdot sr^{-1})\]
分母のcos成分は, 光を放出する微小面を斜めから観測した時の見かけの面積(投影微小面積)を表しており, これにより分子の放射束を除算する. 放射輝度は光の密度を示している.
双方向反射率分布関数(Bidirectional Reflectance Distribution Function, 以降BRDF)は, 光が物体に当たった際の反射特性をモデル化したものである. BRDFは物体表面の位置, 入射方向, 反射方向を変数とする 6次元の確率密度関数であり, 入射光がどの方向にどの程度反射されるかを表す. 入射する放射輝度に対する反射される放射輝度の比を表し, 式\eqref{equ:BRDF}で表す. \[\label{equ:BRDF} \tag{3.4} f_r(x, \vec{\omega_i}, \vec{\omega_o}) = \dfrac{dL_r(x, \vec{\omega_o})}{dE_i(x, \vec{\omega_i}} = \dfrac{dL_r(x, \vec{\omega_o})}{dE_i(x, \vec{\omega_i})}\]
ある方向から入射する放射照度に対して反射される放射輝度の比を表している
双方向透過率分布関数(Bidirectional Scattering Distribution Function, 以降BSDF)は, BRDFとBTDF(双方向透過率分布関数)を合成したものであり, 反射と透過の両方を含む物体表面の光の散乱特性をモデル化したものである. BSDFも物体表面の位置, 入射方向, 反射方向を変数とする6次元の確率密度関数であり, 入射光がどの方向にどの程度散乱されるかを表す. 入射する放射輝度に対する反射される放射輝度の比を表し, 式\eqref{equ:BFDS}で表す. \[\label{equ:BFDS} \tag{3.5} f_r(x, \vec{\omega_i}, \vec{\omega_o}) = \dfrac{dL_o(x, \vec{\omega_o})}{dE_i(x, \vec{\omega_i}} = \dfrac{dL_r(x, \vec{\omega_o})}{dE_i(x, \vec{\omega_i})}\]
ある方向から入射する放射照度に対して散乱される放射輝度の比を表している.
各ピクセル上の点\(x_0\)に対して, ある方向 \(\vec{\omega}\)から入射する放射輝度 \(L_i (x_0,\vec{\omega})\)を考える. 真空空間とすれば光の減衰はなく放射輝度は進む距離に対して不変であるため, 初めに衝突する点\(x_1\)を\(\vec{\omega}\)方向 に出る放射輝度\(L_o (x_1,\vec{\omega})\)に等しくなる. すなわち,\(L_i (x_0,\vec{\omega})= L_o (x_1,\vec{\omega})\)と表される. 各ピクセルに対してカメラからの光線(放射輝度: \(L_o (x_1,\vec{\omega}))\)を逆伝播させて 追跡し, その衝突点における散乱のうち一つの光線をサンプリング, その放射輝度: \(L_i (x_0,\vec{\omega})\) を蓄積する.
ある物体表面の点から出射される放射輝度を, その点自身の次発光による放射輝度と, 周囲から入射して反射または透過した放射輝度の和でモデル化したものがレンダリング方程式である. レンダリング方程式は, \(L_o (x_1,\vec{\omega})\) についてその点自体が光源として発光する放射輝度と, 周囲から入ってきて\(\vec{\omega}\) 方向に反射する光線の放射輝度によって表すものであり, 拡散反射面における放射輝度の計算を簡易的に表すと次のようになる. (ある方向への放射輝度) = (物体の発光) + (方向1からの入射*射出方向へのBRDF) + (方向2からの入射*射出方向へのBRDF)+ …+ (方向nからの入射*射出方向へのBRDF) これを積分形の一般的な積分によるレンダリング方程式の形で表すと 式\eqref{equ:render_fomula}となる.[3] \[\label{equ:render_fomula} \tag{3.6} L_o(x_1, \vec{\omega}) = L_e(x_1, \vec{\omega})+ \int_Ω f_s(x, \vec{\omega_i}, \vec{\omega_o})L_i(x, \vec{\omega_i})|\vec{\omega_i} \cdot \vec{n_1}|d\vec{\omega_i}\] ここで,
である. 以上の式により, 物体表面の法線を中心とした半球状全ての方向から入射した光の放射輝度を積分している. この\(L_o (x_1,\vec{\omega})\)について再帰的にサンプリングを繰り返し何度も評価することで, レンダリング結果を真値に近づけることができる. また, この式からBSDFは, 各入射方向からの射出方向への反射率と, その確率を合わせた関数(確率密度関数)である. 完全拡散面においては, 全ての方向からの入射に対して反射率は一定のため, 定数である.
前項のレンダリング方程式は, 半球上の全ての領域に対しての積分となっているが, フォトンは半球上の全ての領域から無限に到達するが, 無限にあるものを有限時間で全て積分することは不可能である. そのため, モンテカルロ積分を用いることによって統計的に積分する. そのために光の散乱した時の方向分布を立体角の確率密度関数(Probability Density Function以降, PDF)によって, \(P_{\sigma}(\omega_i)\)と表す. \(L_o(x_1,\vec{\omega})\)は \(x_1\)が光源として出す光と, 周囲から入ってきて \(\vec{\omega}\)方向に反射した光の和で表される. したがって, \(x_1\)が\(\vec{\omega}\)方向に 光を自ら発光している場合はまずその寄与が蓄積され, 次に反射光成分を評価する. これは, \(x_1\)から見たあらゆる方向の積分であり, この項に対してモンテカルロ法を適用し, ある一つの光の入射方法を確率的に選択する. この確率密度を\(P_{\sigma}(\omega_i)\)とすると, BRDFを用いて, \(L_o (x_1,\vec{\omega})\)の推定値は 式\eqref{equ:monte}で表される. \[\label{equ:monte} \tag{3.7} \langle L_o(x_1, \vec{\omega}) \rangle=L_e(x_1, \vec{\omega})+\dfrac{ f_r(x_1, \vec{\omega_{i, 1}}, \vec{\omega_o}) L_i(x_1, \vec{\omega_{i,1}}) |\vec{\omega_{i, 1}} \cdot \vec{n_1}|} {P_{\sigma}(\vec {\omega_i})}\] この式より, ある点における放射輝度\(L_o\)は入射する光の放射輝度\(L_i\)とその点が発光する放射輝度\(L_e\)に対して\(BRDF\)を用いて, 次式の関係にあると言える. \[\tag{3.8} L_o=L_e +Li\times(BRDF)\]
完全にランダムな拡散反射を考えれば, 衝突点に対するサンプリングは半球面への一様サンプリングとなり, \(P_{\sigma}(\omega_i)=1/{4\pi}\) である. この式を解くには確率的に選択された方向\(\vec{\omega_{i,1}}\)から入射する 放射輝度を求める必要があるが, \(L_i(x_1, \vec{\omega_{i,1}})\)は直接評価できないため, \(x_1\)から\(\vec{\omega_{i,1}}\)方向に 経路を生成することで再帰的に計算できる. これに基づき, 式\eqref{equ:monte}に対してノイマン級数展開を用いると, 次のような式変形で表せる. \[\begin{align} &\langle L_o(x_1, \vec{\omega}) \rangle=&\\ & L_e(x_1, \vec{\omega})+ \dfrac{ f_r(x_1, \vec{\omega_{i, 1}}, \vec{\omega_o}) |\vec{\omega_{i, 1}} \cdot \vec{n_1}|} {P_{\sigma}(\vec {\omega_i})} \biggr \lbrace L_e(x_2, \vec{\omega_{i,1}})+ \dfrac{ f_r(x_2, \vec{\omega_{i, 2}}, \vec{\omega_o}) L_i(x_2, \vec{\omega_{i,2}}) |\vec{\omega_{i, 2}} \cdot \vec{n_1}| } { P_{\sigma}(\vec {\omega_i}) } \biggl \rbrace \\ & = L_e(x_1, \vec{\omega})+ \dfrac{ f_r(x_1, \vec{\omega_{i, 1}}, \vec{\omega_o}) |\vec{\omega_{i, 1}} \cdot \vec{n_1}| } { P_{\sigma}(\vec {\omega_i}) } L_e(x_2, \vec{\omega_{i,1}})&\\ & + \dfrac{ f_r(x_1, \vec{\omega_{i, 1}}, \vec{\omega_o}) |\vec{\omega_{i, 1}} \cdot \vec{n_1}| } { P_{\sigma}(\vec {\omega_i}) } \dfrac{ f_r(x_2, \vec{\omega_{i, 2}}, \vec{\omega_o}) L_i(x_2, \vec{\omega_{i,2}}) |\vec{\omega_{i, 2}} \cdot \vec{n_1}| } { P_{\sigma}(\vec {\omega_i}) }& \end{align}\] この式は, 第1項が0回目の反射, 第2項が1回目の反射, 第3項が2回目の反射を示し, 続く項も再帰的に展開を行うことで近似値を得られる. これが第n項まで続くとすると, 式\eqref{equ:noiman}で表される. \[\label{equ:noiman} \tag{3.9} \langle L_o(x_1, \vec{\omega}) \rangle=\sum_{k=1}^{n} \Biggl ( \biggl ( \prod_{k=1}^{n} \dfrac{f_r(x_k, \vec{\omega_{i, k}}, \vec{\omega_{i, k-1}}) \cdot|\vec{\omega_{i, k}} \cdot \vec{n}| }{P_{\sigma}(\vec {\omega_i})} \biggr )L_e(x_k, \vec{\omega_{i,k}})\Biggr )\] これにより, 経路の生成と追跡をするたびにBRDFの寄与を蓄積し, \(L_e \neq 0\)である発光体に衝突したときに追跡を終了してBRDFの寄与と \(L_e\)を乗算することでその経路の放射輝度が得られる.
反射面の材質に合わせ, 法線を中心とした適切な散乱分布を作ることで, 収束にかかる時間を短縮することができる. 前項では完全にランダムな拡散反射と仮定して衝突点に対するサンプリングを半球面上への一様サンプリングとしたが, ランバート反射面においては, 各反射光への寄与は真上(鉛直方面)からの入射光が大きいため, 半球面におけるランダムな分布を真上ほど確率が高くなるように確率密度関数を作ることができる. BRDFとcos項の積に比例した重点サンプリングを行うために, 光線の入射方向に対応する \(\theta\)と\(\phi\)を 式\eqref{equ:sampling}に従ってサンプリングする. \[\label{equ:sampling} \tag{3.10} \theta = cos^{-1}\sqrt{u_1}, \phi = 2\pi u_2\] ここで, \(u_1\), \(u_2\)は\([0, 1)\)に分布する一様乱数である. これを解くと, \(P_σ (\vec{\omega_i})=cos\theta/{\pi}\) であり, 拡散反射面の材質においては, この確率分布関数を用いてサンプリングを行うことで効率的にレンダリングを行う.
本章では, 研究で扱う理論について詳細に述べた.
本章では本研究に関連する研究について詳細に述べる.
FPGAでプロセッシングシステムと統合したワンチップのレイトレーシングを実現する技術として, 田嶋氏らの2021年の論文“FPGAによるパストレーシング法を用いた画像レンダリングの性能評価”[8] がある. PCとPCI Express接続が可能な大規模FPGA AMD Virtex 7 FPGA VC707が用いられており, LUTを485760個, FFを60720個, DSPを2800個, BRAMを37080KB搭載している. また, 回路制御のために32bitのソフトマクロCPU RISC MicroBlazeを用いている. この研究における特徴は, パストレーシング法の全計算を行う専用計算機の開発ではなく, 1つの画素に対して1回のサンプリングのみを行うシンプルな専用計算機を制作する アイディアにより. 回路規模の抑制と, CPU実行に対する高速化を実現している. また, SoC FPGAではなく単一のFPGAのみのシステムでありながら, FPGA上に実装できるソフトマクロCPUであるMicroBlazeからパストレーシング回路を制御するアプローチをとることで, パストレーシング回路の実装とその制御を実現している. 結果として, パストレーシング回路の並列化は行わず, クロック周波数は比較対象のCPU(intel Core i5-4460)の10分の1でありながら, CPUでの実行に対して1.3倍の高速化が実現されている.
田嶋氏らの研究は, 処理対象を1ドット1サンプリングに限定しながらも, パストレーシングの処理を全て行う回路を高位合成によって実装している. これによってパストレーシングの処理を専用に行うハードウェアを実現している. これに対して本研究では, ソフトマクロCPUよりも高い演算能力を持つハードマクロCPUを搭載したSoC FPGAを用い, ハードマクロCPUによる複雑な演算とFPGAにおける専用回路によって さらなる高速化を図る. 一方で, 田嶋氏らの研究は本研究で用いるFPGAの6倍の規模のリソース, 2倍の周波数をもつFPGAを用いており, 本研究で実装できる回路規模は小規模なものにとどまる. 本研究は田嶋氏らの研究のアイディアを発展させ, ハードマクロCPUを持ちこれまでより複雑なソフトウェア処理が可能であるSoC FPGAを用いる. また, このSoC FPGAの利点を活かし, 専用回路化する対象を限定しながらもハードマクロCPUによるソフトウェア動作を用いることで 高速なパストレーシングシステムの実装を可能にする.
交差判定アルゴリズムを高速化する技術として楊氏らの2012年の論文”高速交差判定アルゴリズムのFPGA実装”[9] がある. この研究は, レイトレーシング法の処理時間における\(75\% \sim 95\%\) という大部分が光線と物体の交差判定に費やされることに着目し, Tomas Möller, Ahevtsov, Havelの3種類の交差判定アルゴリズムを回路化し, 効率化するアプローチをとっている. この研究で用いられたXilinx社製大規模FPGA xc4vfx100-10ff1617において, VHDLを用いたRTL設計を通じてハードウェアコストとレイテンシをシミュレーションが行われた. この研究では, 500MHzのクロック, 18690個のDSPスライス, 28314個のFF, 25483個のLUTのリソースを使用して, Tomas Möllerアルゴリズムをパイプライン化した処理の第1段階目の出力において, 76クロックのレイテンシを達成している.
楊氏らの研究は交差判定処理回路のみをRTL設計によって実装し, パストレーシングアルゴリズムにおける主要な処理が高速で小規模な回路で実現できる ことを示している. 一方で, 楊氏らの研究はRTL設計で交差判定のロジックのみを実装しているため, 実際の演算に必要となるインターフェース およびマスター側とのデータのやり取りは実装されていない. 本研究では楊氏らの研究のアイディアを発展させ, PSと協調動作するためのアクセラレータとして動作可能な, インターフェースとデータ送受信機能を持つ交差判定アクセラレータを 高位合成を用いて実装する. さらに, SoC FPGAを用いて, この交差判定アクセラレータを活用した高速なパストレーシング処理の専用デバイスを 実現する.
既存のCPU+GPU環境に対してUSB2.0接続のFPGAを接続した双方向パストレーシングの高速化を実現した技術としてWenzel Jakob氏の 2007年の論文[10]がある. この研究は, RTL設計により光線生成, 交差判定, メモリコントローラを全てアーキテクチャ設計から行い回路合成を行ってFPGAに実装することで, 既存のPCに接続できる 双方向パストレーシングアクセラレータを実装するアプローチを用いている. GPUはレンダリングされた映像の出力のみを担当し. パストレーシングによる描画に関わる計算は全てFPGAが担うことでパフォーマンス向上を図っている.
Jakob氏の研究はパストレーシング全体の処理をFPGAで実現しているため, 完全なパストレーシングアクセラレータを実装して 既存のGPUのレンダリング機能を置き換える方法により, 本研究が目指すシステムをすでに有している. 一方で, Jakob氏の研究はシステムの全てがRTL設計で実装されているため, インターフェースやアルゴリズムの設計の複雑さや更新の困難さを抱えている. 特に, メモリアクセスやインターフェースは高性能化するごとに複雑化しているため, これをRTL設計によって全てを記述してアップデートしていくのは 困難である. 本研究では, 2007年時点では普及が進んでいなかったものの, 近年普及した高位合成を活用することでRTL設計の複雑さを解決し, より柔軟なインターフェース設計やアルゴリズムの容易な更新を可能にする.
本章では本研究に関連する研究について詳細に述べた.
本章では, 本研究で提案するパストレーシングの高速化手法について詳細に述べる.
パストレーシング法において, 光線の経路の深度とサンプリング数を増やすほど計算誤差が少なくなり, 高品質な映像が得られるが, 計算量が指数関数的に増大する. 経路生成は再帰的な処理であり, 必要に応じて増減する必要がある. しかしハードウェアにおいては, 再帰的処理の繰り返しを動的に増減することは困難である. そのため, 現在のGPGPUによるパストレーシングは, 深度とサンプリング数を固定してパフォーマンスの低下を防いでいる. この方法は高速な映像合成が可能な一方で, 不完全で偏った経路生成により映像品質が低下する. これの解決のためには, 光源に達する可能性の低い経路の確率的な打ち切りなどが必要である.[4]
一方で, 多重構造を伴う条件分岐処理のハードウェア実装は, 多くのLUTからなる分岐ブロックを多数消費する. これによりリソースが増大し, 配線遅延の原因となるため, ハードウェアでの実装に適さない. そのため, 多くの条件分岐を必要とする経路生成や映像生成を含むパストレーシング処理の全てをFPGAに回路実装することは 実装不可能な大きなリソースを消費し, 多重構造を伴う条件分岐による非効率な回路合成により低速化を招く.[11] 実際にパストレーシング処理の全てを回路化した場合のリソースおよび計算性能は付録Dにて示す.
また, パストレーシングの処理は経路生成の繰り返しであるため, 経路生成ごとにシーンを構成する全ての物体とその経路についての 交差判定処理が発生する. そのため, パストレーシングにおける処理時間の大部分が交差判定処理に費やされている. 以上から, 全体の処理時間の短縮には交差判定処理の高速化を実現することが特に必要である.
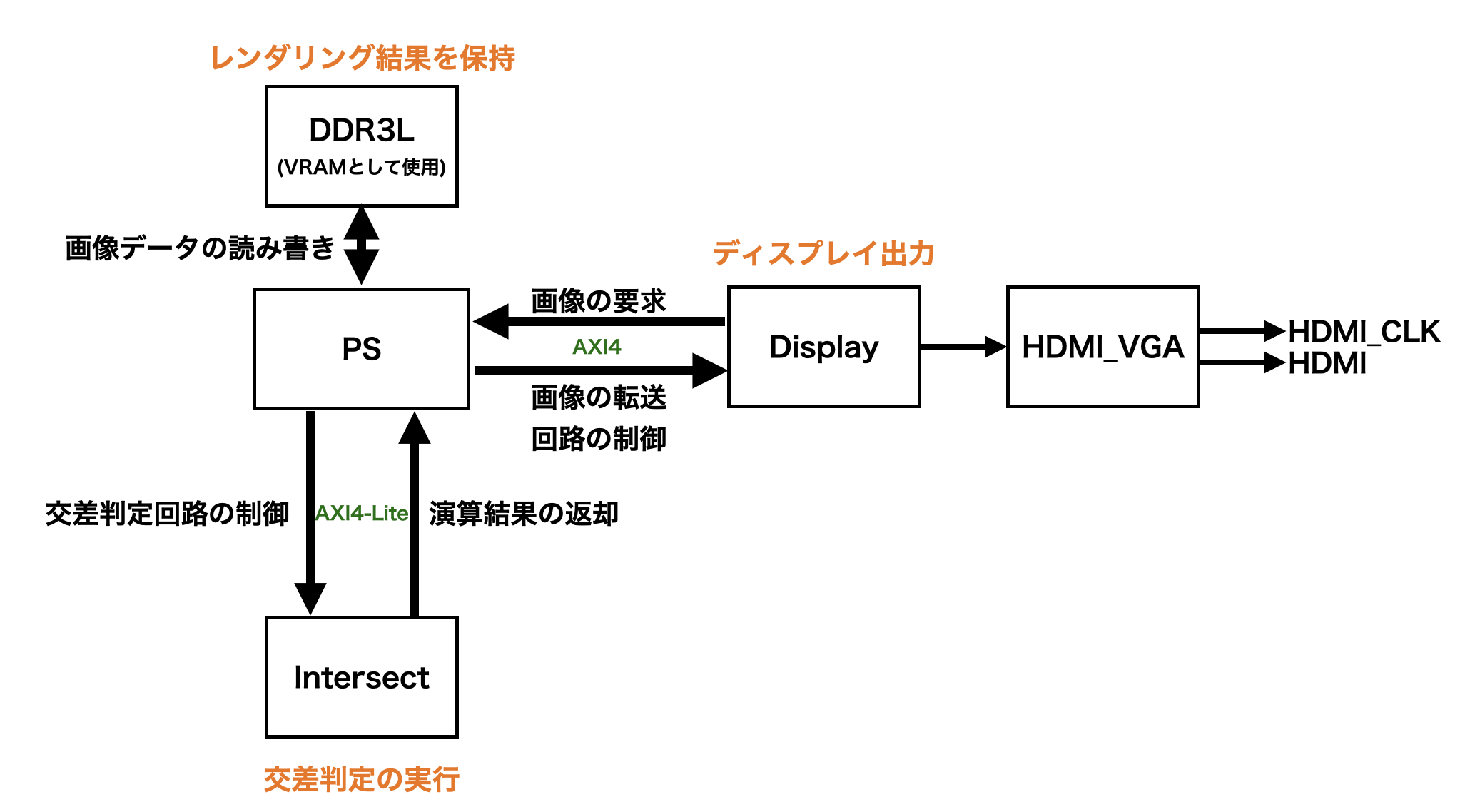
本研究では, 多重構造を伴う条件分岐のハードウェア実装の非効率さと, 交差判定処理の時間がパストレーシング処理の全体の大半を占めることに着目し, 最も処理時間を消費する交差判定処理のみをFPGAに専用処理回路として実装し, それ以外の経路生成や映像処理を含むパストレーシングの処理はソフトウェア実装する, 交差判定アクセラレータ手法を提案する. また, 本研究ではSoC FPGAを用いて交差判定アクセラレータ手法を実現する. 図5.1 に本システムが実現するシステムの概要を示す.
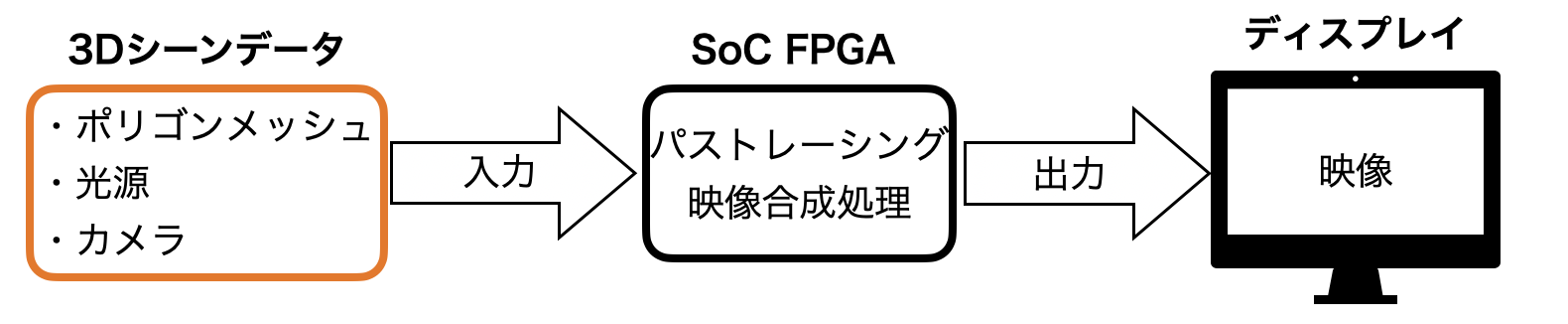
図中において, 交差判定アクセラレータ手法を実装したSoC FPGAは, 3Dシーンデータを入力として受け取りパストレーシングによる映像合成処理を行い, 結果をディスプレイ出力している. これにより, ラスタライズ法でのGPUに相当する, パストレーシング法による映像合成の専用ハードウェアの役割を果たす.
本研究に用いるSoC FPGAは, 図5.2 に示すXC7Z020-1CLG400Cを搭載したFPGA評価ボードZYBO Z7-20である. このSoC FPGAは, 図に示すように, Programmable Logic(以下, PL)とARM Cortex-A9プロセッサによるProcessing System(以下, PS), DDR3Lメモリを一つのチップ内に統合している. またこれらはAXIバスにより接続されており, 相互にデータ通信ができる. これにより, SoC FPGAにおいては, PLに合成する専用処理回路による高速処理とPSにおける動的なソフトウェアの処理を同時に行うことができる. そのため, 交差判定処理の専用回路とその他の処理のソフトウェアを両方実装し, 交差判定アクセラレータ手法を実現可能である.

交差判定アクセラレータ手法をSoC FPGAで実現するための内部構成の詳細を 図5.3に示す. これは, PSが経路生成および映像合成を行い, 交差判定アクセラレータを指す「Intersect」がPSの指示に従って交差判定を実行する. PSは映像合成結果をDDR3Lメモリに格納し, PL内のディスプレイ表示回路を通してHDMI端子を用いて映像出力する.
本章では, 本研究で提案するパストレーシングの高速化手法について詳細に述べた.
本章では, SoC FPGAへの交差判定アクセラレータ手法によるパストレーシングシステムの実装を述べる. また, 本システムとCPUでの実行性能を比較し, 本研究の提案手法を評価する.
本研究で使用した機材を以下に示す.
PC(Windows)
OS : Windows 11 Pro 23H2
CPU : AMD Ryzen 9 5800X
実装RAM : DDR4 64GB
GPU : GeForce RTX 3070 VRAM12GB
PC(Mac)
OS : macOS Sonoma 14.2.1
SoC : Apple M2
実装RAM : LPDDR5 24GB
ソフトウェア
Vivado 2023.2
Vitis Classic 2023.2
Vitis HLS 2023.2
G++ 13
WSL2
OpenMP
irfanview 64bit
MX Power Gadget
CPUID HWMonitor
ZYBO Z7-20
FPGA型番 : XC7Z020-1CLG400C
Logicスライス数 : 13300
6入力LUT数 : 53200
Flip Flop数 : 106400
BRAM容量 : 630KB
DSPスライス数 : 220
クロック発生器 : 4PLLs, 4MMCMs, 125MHz external clock
Processing System : 667MHz dual-core Cortex-A9 Processor
実装RAM : DDR3L 533 MHz 2GB
パストレーシング処理をCPUで実行するための「パストレーシングプログラム」をC++で実装した. 実装の詳細を述べる. ソースコードは付録Aにて示す.
初期設定として, 三角形によるシーンデータ, カメラの位置と向きの3次元ベクトル値, 画像の解像度を定義する. 次に, 各ピクセルに対してカメラを原点としてシーンに対して光線経路を生成, その光線とシーン内の三角形に対して交差判定を行う. 交差があればその交差点での物質の特性(反射, 屈折, 拡散)に従い, XorShiftにより生成する一様乱数とBSDFが表す光線の確率分布を 用いたモンテカルロ法によるサンプリングにより新たな光線経路を生成する. 設定した深度まで再帰的に繰り返し, その間に交差がなければ バックグラウンドカラー, 光源との衝突があれば経路の寄与を返して以上のプロセスを終了し, ピクセルの色を決定する. 以上の映像合成プロセスで全てのピクセルについて画素値の計算を行い, 結果はRGBA画像で保存する.
交差判定アクセラレータを実装するための「交差判定回路プログラム」をC++で実装した. 実装の詳細を述べる. ソースコードは付録Bにて示す.
交差判定回路プログラムは, シーン内の三角形の頂点情報を持ち, シーン内全ての三角形に対して交差判定を行う intersect_triangles関数をトップとして, 各三角形との交差判定を記述したintersect_triangle関数をループで呼び出し, 最も近い交差点のみを交差結果として返すプログラムである.
intersect_triangle関数は, 指定した光線と三角形に対してTomas Möllerの交差判定アルゴリズム[12] を用いて交差判定を行い, 平行または計算誤差による交差判定が起きていない場合を除いて交差判定結果を返す. 光線と三角形の交差判定にあたり, 3次元ベクトルの減算, 除算, 乗算が必要になるが, これらは全てベクトルをスカラー値に変換してから行うことで並列に演算する.
intersect_triangles関数は, intersect_triangle関数の実行, 交差距離の仮変数への保持, 前の交差判定実行時の交差距離よりも小さい値であれば更新する. 以上の処理を一つのループとして, シーンを構成する全ての三角形に対して並列処理を行う. しかし, ループ処理中に交差距離の仮変数への保持と更新がループに含まれるため, ループ間のデータ依存が存在する. そのため, アンローリングではなくパイプライン化による並列化を行う. Xilinx社から提供される#HLS PIPELINEディレクティブ[6] を用いて, 3サイクルごとにパイプライン処理を行う.
さらに, PSと通信を行うためのAXI4-Liteインターフェースを全ての変数について付加して, PSとの通信を可能にした. 以上の交差判定回路プログラムをVitis HLSで高位合成して, 交差判定アクセラレータを実装した.
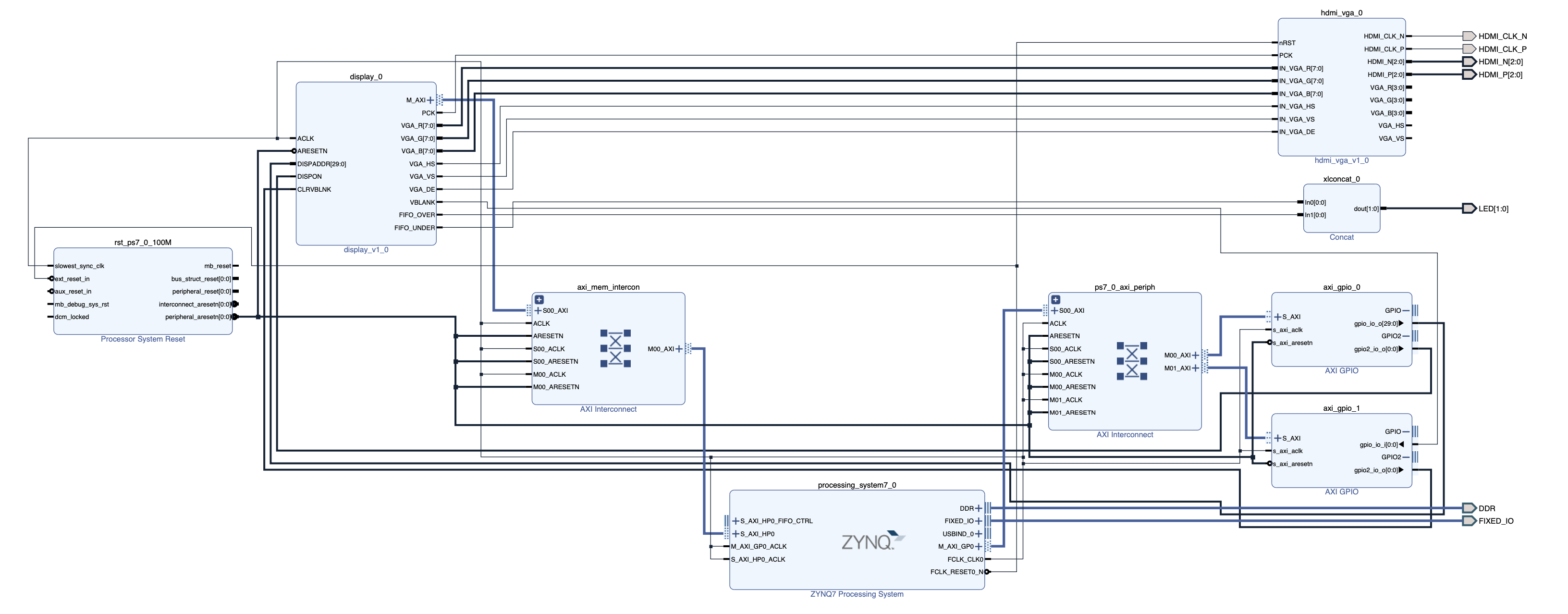
SoC FPGAへの交差判定アクセラレータ手法の実装を述べる. Vivadoを用いて, ディスプレイ表示回路に交差判定アクセラレータを組み込んだ. ディスプレイ表示回路の実装は付録Cにて示す. 本研究で実装したシステムのダイヤグラムを 図6.1に示す.
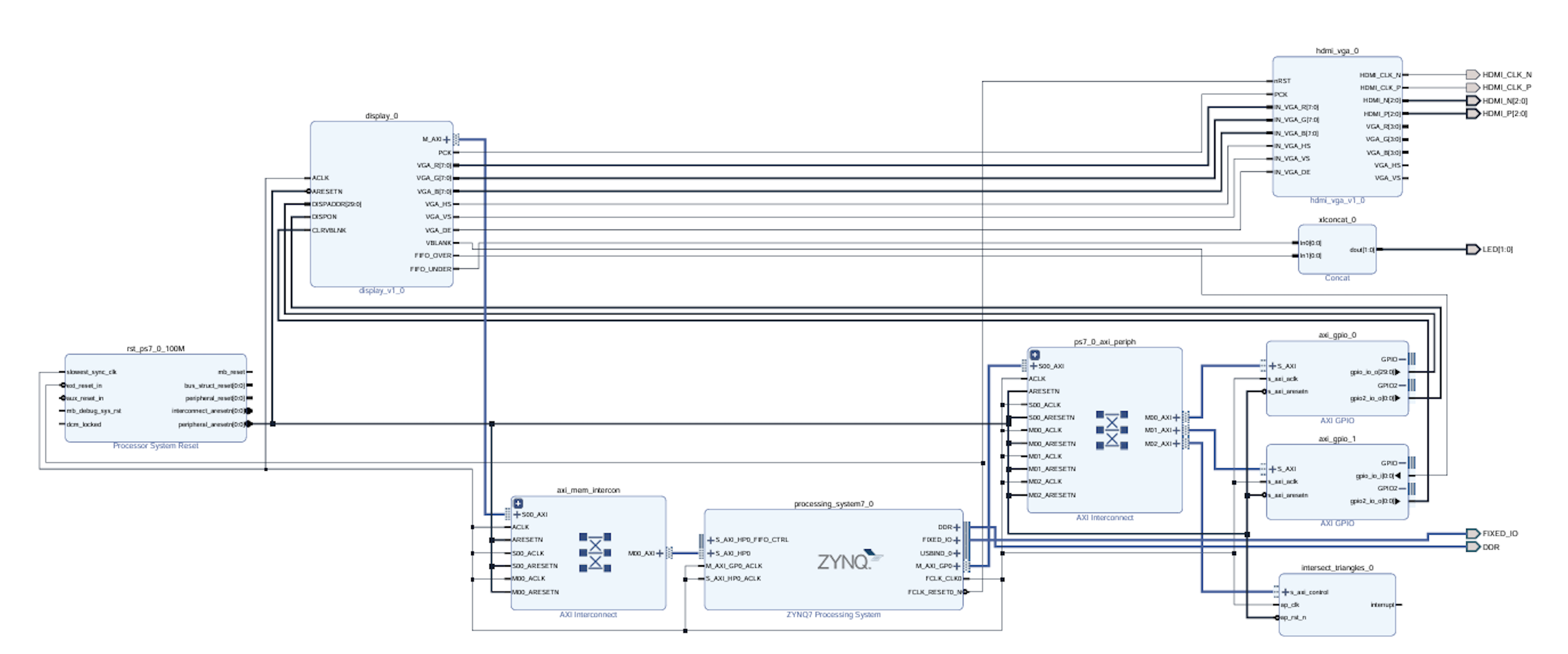
図中のprocsssing_system7_0(PS)で100MHzのクロック信号, rst_ps7_100Mで出力する100MHzに同期したリセット信号を生成させ, これに全てのコアを同期して動作させている. intersect_triangles_0(交差判定アクセラレータ)は procsssing_system7_0とAXI4-Liteで接続し, PSの指示により動作する. レンダリング結果はPS内で統合されたDDR3Lメモリに格納し, AXI4で接続したdisplayコアとHDMI_VGAコアを用いて ZYBO Z7-20ボード上のHDMI出力端子からディスプレイへ映像出力する. displayコアとHDMI\_VGAコアの仕様と実装は付録Cにて示す.
本システムを動作せるための, PSの制御プログラム「パストレーシングシステム制御プログラム」の実装を述べる. ソースコードは付録Eにて示す. パストレーシング処理について, 交差判定と映像出力以外はパストレーシングプログラムと同様である. 交差判定の実行は, PSから交差判定アクセラレータを制御することで行う. 映像合成結果はRGBAデータを各ピクセルに持つ二次元配列として DDR3Lメモリに格納し, displayコアとHDMI_VGAコアを制御してHDMI経由でディスプレイに画像を出力する.
Vitis HLSを用いて, C/RTL協調シミュレーションにより動作波形のシミュレーションを行った. 得られた映像合成結果のraw画像をirfanview 64bitを用いて, RGBA形式を指定して確認した. 映像合成結果を図6.2に示す.

鏡面反射, フレネル効果, 拡散反射と陰影が全て正しく表現された映像合成結果が得られた. パストレーシング法が正しく動作していることが分かる.
本システムの交差判定時間を, Vitis HLSのC/RTL協調シミュレーションの波形データで計測した. パストレーシングの全体実行時間は, 計測していない. 最大消費電力は, VivadoのPowerレポートで観測した.
また, macOS Sonoma 14.2.1及びWindows 11 Pro 23H2上のWSL2 Ubuntu20.04においてCPU実行性能の計測をg++を用いて行なった. OpenMPにより全コアを用いた並列計算を行い, 全体の処理にかかった時間, 交差判定(intersect_triangles関数)の実行回数, 交差判定時間を計測した. 交差判定時間は, 全ての交差判定実行の平均時間とする. さらに, 最大消費電力の計測をmacOSでは MX Power Gadget, Windows OSではCPUID HWMonitorを用いて行なった.
各動作環境における実行時間と消費電力の測定結果を 表6.1に示す.
| 動作環境 | 全体実行時間[\(ms\)] | 交差判定回数 | 交差判定時間[\(\mu s\)] | 最大消費電力[\(W\)] |
|---|---|---|---|---|
| 本手法 | - | - | 1.850000 | 2.040 |
| Ryzen 5800X | 56255.204 | 53321213 | 0.573561 | 140.2 |
| Apple M2 | 65633.221 | 42556928 | 0.684259 | 20.1 |
レンダリングプロセスにおいて共通する交差判定時間について, 以上の交差判定時間(\(E_t\))と 最大消費電力(\(W_p\))から, 1[W]あたりで達成できる計算時間 (\(L_w\))を計算性能として導出する. これは式\eqref{equ:wat_p}で定義し, 値が小さいほど性能が高いことを示す. \[\label{equ:wat_p} \tag{6.1} L_w = E_t \cdot W_p\] これを用いて, 交差判定アクセラレータ手法による本システムの交差判定性能 [\(\mu s \cdot W\)]を1として, それぞれの性能を表6.2に示す.
| 動作環境 | 交差判定性能 [\(\mu s \cdot W\)] | 比率 |
|---|---|---|
| 本手法 | 3.672 | 1 |
| Ryzen 5800X | 80.41 | 21.90 |
| Apple M2 | 13.75 | 4.008 |
動作環境毎の性能対消費電力をまとめたグラフを 図6.3に示す.
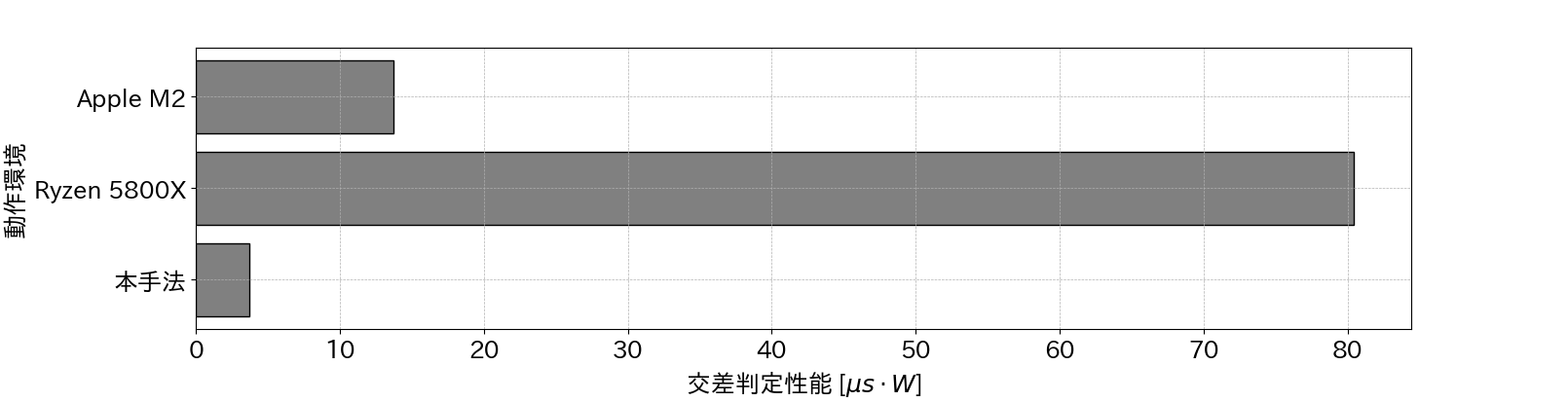
本システムの性能対電力消費における交差判定性能は, x86_64アーキテクチャのRyzen 5800Xと比較して21.90倍, Aarch64アーキテクチャのApple M2と比較して4.008倍高速である. 以上から, 交差判定アクセラレータ手法によってCPU実行からの高速化を示した.
表6.3に, 交差判定アクセラレータの交差判定ループごとのレイテンシパフォーマンスを示す.
| Latency (cycles) | Initiation Interval | |||||
|---|---|---|---|---|---|---|
| Loop Name | min | max | Iteration Latency | achieved | target | Trip count |
| Vitis_LOOP_1 | 185 | 185 | 125 | 3 | 3 | 20 |
交差判定アクセラレータのレイテンシは185クロックの\(1.850\mu s\)であり, Iteration Latancyが125サイクルで, このイテレーションを3サイクルごとに繰り返すループであるため, メッシュ数(\(M_n\))を変えた場合の計算にかかるサイクル数 (\(L_c\))について, イテレーションのサイクル125が一回目の計算ループとなり, その後のループは3サイクル毎に計算が終了する. そのため, レイテンシはメッシュ数\(M_n\)を用いて 式\eqref{equ:l_cycle_pip}で示される. \[\label{equ:l_cycle_pip} \tag{6.2} L_{pip} = 125 + 3 \times M_n - 1 +3\] また, 逐次実行の場合のメッシュ数(\(M_n\))に対する計算にかかるサイクル数 (\(L_c\))は 次式\eqref{equ:l_cycle}で示される. \[\label{equ:l_cycle} \tag{6.3} L_c = 125 \times M_n\] この計算式に基づくメッシュ数に対するパイプライン実行と逐次実行の実行時間を 図6.4に示す. また, 逐次実行の実行時間とパイプライン実行の時間の比により, パイプライン手法による高速化を 図6.5に示す.
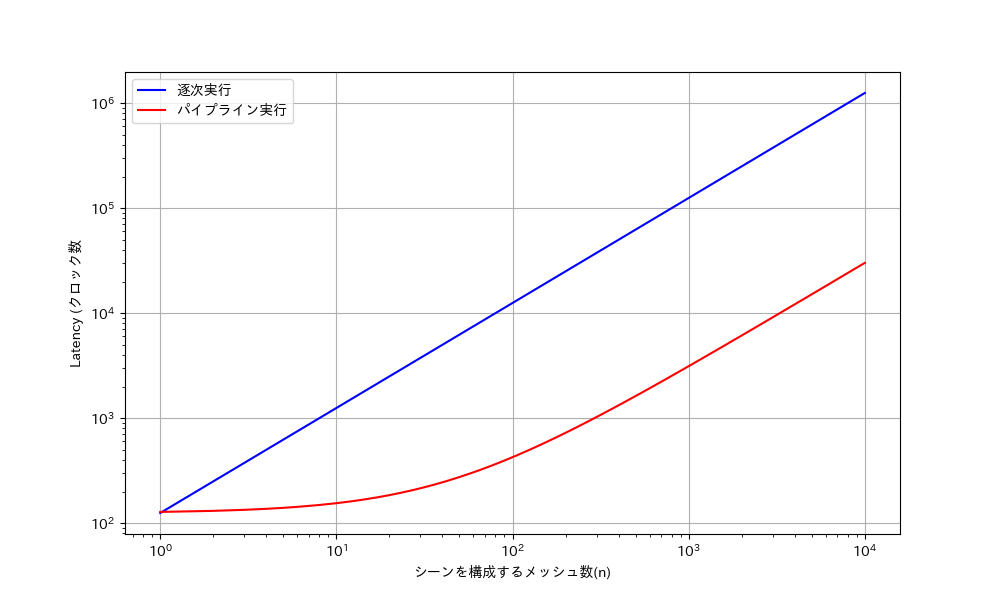
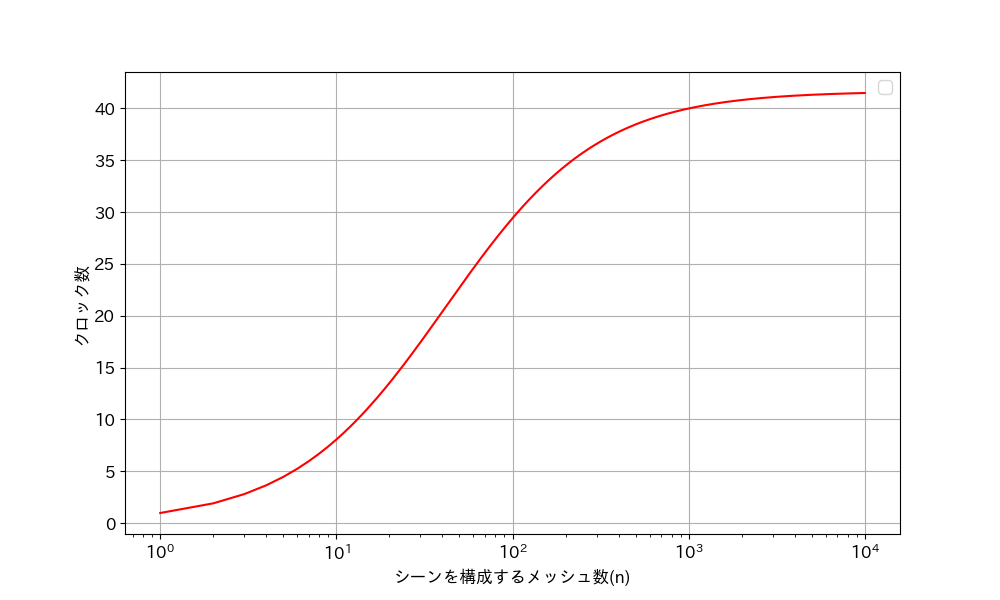
図6.5より, メッシュ数が1000個以下では, メッシュ数を増やすほどパイプライン実行が逐次実行に対して高速化の効果が高くなっていくことが分かる. また, メッシュ数が10000程度で高速化が頭打ちになっていることがわかり, 図6.4からも 平行線になっていることが分かる. このとき, パイプライン処理にかかるレイテンシの逐次実行に対しての比率は \[\tag{6.4} L_s/L_{pip} = {125\times10000}/{125 + 3\times10000 + 3}= 41.49\] より, 10000メッシュまでレンダリング対象のメッシュを増やせば最大41.49倍まで高速化される.
表6.4に 最適化した交差判定回路のリソース使用量を示す.
| リソース | 使用量 | 使用可能量 | 使用率(%) |
|---|---|---|---|
| BRAM | 0 | 280 | 0 |
| DSP | 26 | 220 | 11 |
| FF | 3535 | 106400 | 3 |
| LUT | 5395 | 53200 | 10 |
リソース使用量のグラフを 図6.6に示す.
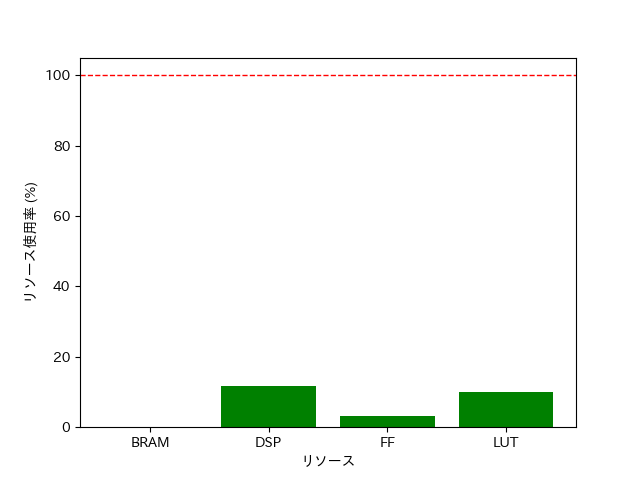
この結果から, リソースは交差判定アクセラレータを本システムに最大9個まで実装して同時に動作可能であると言える.
本章では, 実装と性能評価を示した.
本章では, パストレーシングシステムの実装と評価を基に考察を述べる.
映像合成結果がRTL波形シミュレーションにおいて正しく得られていることから, 交差判定アクセラレータ手法によって正しくパストレーシング法の処理ができていると言える. パストレーシングプログラムにおいては, シーン内は全て真空であると仮定していたため, 光の減衰を考慮していない. 今回のシーンは単純なものであったため光の減衰を考慮しないことによる問題は起きなかったが, ガラス材質は真空中でも光を減衰させる. そのため, 合わせガラスなどのより複雑なモデルにおいては全反射や繰り返しの屈折が正しく反映されないため, 固体物体内での光の挙動を考慮する必要がある. さらに複雑なシーンに対するパストレーシング法を実装する場合には, ポリゴン間における光の減衰のパラメータを材質ごとに付与することで対応できると考える.
交差判定アクセラレータ手法によりCPU実行に対する高速化を示したが, この手法において高速化の効果を高めるには, 交差判定処理の割合を増やす必要がある. パストレーシングプログラムをCPUで実行した場合の交差判定処理に費やされる時間の 全体に対する割合は, Ryzen9 5800Xで54.36%, Apple M2で44.36%であった. これは, 関連研究で挙げた楊氏らの研究”高速交差判定アルゴリズムのFPGA実装"[10] において, パストレーシング法の処理全体における交差判定にかかる時間的割合が \(75\% \sim 95\%\)とされているのに対して低い結果であり, さらに高める必要がある. 交差判定にかかる時間的割合が低かった原因として, パストレーシングプログラムで用いたポリゴンメッシュが25個であり, ゲームなど一般の3DCGで用いられる数千\(~\)数万個のメッシュ数に対して 非常に少なかったことが考えられる. 実用的なメッシュ数を用いた実装や, より交差判定処理を用いる手法のパストレーシング法の処理を実装できれば, 交差判定アクセラレータ手法による高速化の効果を高めることができると考える.
交差判定アクセラレータについて, Tomas Möllerアルゴリズムの交差判定処理をパイプライン化することで 逐次実行に対して最大で42倍程度高速化されていることが分かったが, この高速化はメッシュ数が10000個程度で頭打ちになる. 一方で, 近年のゲーム等に用いられる一般の3DCGは, ポリゴンを非常に多く用いる. そのため, 一般の用途の映像合成に本手法を適用するには, kd-treeやBounding Volume Hierarchy (BVH)を用いて, シーン内のポリゴンメッシュに対して領域分割技術を使うことが必要であると考える. これにより, 交差判定処理を行う対象のポリゴン数を絞り, 高速に映像合成を行うことができると考える.
本システムのリソース使用量は10%程度に収まっており, 配線遅延を起こさない適切なリソース量であると言える. 本手法では交差判定アクセラレータのみを実装したが, 他のアクセラレータを追加で実装する余地がある. 特に, 光線散乱時の経路サンプリングは交差判定と同様に再帰的に行われる処理である. このアクセラレータの実装を行えばさらに高速なパストレーシング処理の専用デバイスを実現できると考える.
本章では, パストレーシングシステムの実装と評価を基に考察を述べた.
本研究では, SoC FPGAを用いてパストレーシングの処理の専用デバイスを実現して高速化することを目的とし, 交差判定アクセラレータ手法を提案した. この交差判定アクセラレータ手法により, パストレーシングを実現し, CPU実行に対する高速化を示した.
GPUはラスタライズ法の専用処理デバイスを制作することによりCPUに対する高速化を目指したデバイスであるが, 本研究はパストレーシング法の専用処理デバイスを実装してCPUに対する高速化を実現した. そのため, 本研究はパストレーシング法について, GPUに代わる専用処理ハードウェアの実現可能性を示した.
今後の課題として次の4点が挙げられる.
実用的なシステムを構成するために, 動的にシーンを書き換え, そのシーンに対して描画を行うシステムを構築する必要がある. 例えば, 一般的に3Dシーンの表現に用いられるobj形式等のデータをCPU側で読み込み, それの頂点データを受け取ってFPGAで演算を行う というシステムを構築することで実現できる.
本研究では, 少ないポリゴン数に限定したパストレーシングを行ったため, 一般のゲーム等に用いられる3DCGとは異なる環境である. また, ポリゴン数を増やすことにより交差判定アクセラレータ手法のメリットを活かす必要がある.
本研究では基本的なパストレーシングのアルゴリズムの実装を行ったが, 実用的なパストレーシングにおいては Next Event Estimation(NEE)や大局照明技術等のさらに高速でフォトリアリスティックな映像をレンダリングする技術がある. これを含めた実用的なパストレーシングエンジンを実装することで性能評価する必要がある.
本研究では, スタンドアロンのPSとPLを内包したSoC FPGAを用いてシステムを開発したが, 既存のGPUを置き換えるためには PCI-Express接続でCPUと協調動作するアクセラレータとして実装する必要がある.
これらの変更を行うことで, GPUに対する高速化を示し, 置き換えをできるパストレーシング専用処理デバイスを開発していきたい.
本研究を行うにあたり, ご指導ご鞭撻に加え自由な研究環境を提供してくださった坂本直志教授に心から感謝の意を表します. また, 本研究にあたり支えていただいたネットワークシステム研究室の皆様, 家族や友人の皆様に心から感謝申し上げます.
パストレーシングの理論に基づいてアルゴリズムを以下に示す. 初めに全ての画素を初期化し, 全てのピクセルに対して視点位置からの光線を生成, シーン内の物体に対して交差判定を行って光線の追跡を行う. 物体との交差時, 発光体であればスループットに発光色を乗算して終了, 発光体以外であれば次の経路をサンプルまたはロシアンルーレットによりランダムに打ち切る. これにより, 物体表面での散乱を確率的にサンプルして経路を作っていき, 光源に到達したら追跡を終了するモンテカルロレイトレーシングを実現している.

パストレーシングプログラムをソースコードA.1に示す. main関数でカメラと視点の設定を行い, radiance関数で映像合成処理を行う, パストレーシング法を実装したプログラムである.
ソースコードA.1 パストレーシングプログラム
FPGAへの組み込みを前提とし, ハードウェアで単純に計算ができる方法としてXorshiftアルゴリズムにより乱数生成器を実装した. Xorshiftは単純なブットシフトと排他的論理和操作に基づく少ない計算量で高品質な乱数を生成できる手法である. 次の2つの関数で実装した.
内部状態(xorshift_state)をビットシフトとXOR操作で変換し, 新たな乱数を生成する. 初期状態は任意の非負値のint整数型数値に設定する. 具体的な操作は, 左に13ビットシフトした後, 右に17ビットシフト, 最後に再び左に5ビットシフトしている.
xorshift関数によって得られた乱数を, [0,1)の浮動小数点数に変換する. 生成された乱数をunsigned int型の取りうる最大値UNIT_MAXで除算する.
FPGAへの組み込みを前提とし, ハードウェアで単純に計算ができる方法としてXorshiftアルゴリズムにより乱数生成器を実装した. Xorshiftは単純なブットシフトと排他的論理和操作に基づく少ない計算量で高品質な乱数を生成できる手法である. 次の2つの関数で実装した.
3次元空間内のベクトルの表現, ベクトル間の加算, 減算, スカラー倍, 正規化, ドット積(内積), クロス積(外積)演算を サポートするためのメンバ関数と演算子オーバーロードの実装をしている.
3次元(R, G, B)の色情報の表現, 放射輝度計算における三次元ベクトル計算を実装している.
3次元座標によって定義される原点座標と方向ベクトルによる3D空間内の光線の表現している.
完全拡散反射”DIFFUSE”, 鏡面反射”SPECULAR”, 屈折”REFLECTION”の3つの異なる材質の表現をしている.
交差判定の実行結果(交差の有無, 距離, 物体ID, 種類)を格納している.
半径, 中心座標, 発光色, 物体色, 材質からなる球を定義している.
3つの頂点, 発光色, 物体色, 材質からなる三角形を定義している.
レンダリング対象は, CG分野のベンチマークで広く使われているコーネルボックスとした. 前項で示したSphere構造体とTriangle構造体によるspheres配列とtriangles配列でを用いてシーンを構築した. 白い天井と奥壁, 床, 赤い右壁と緑の左壁は全てDIFFUSE材質, 床の右側に置かれたダイヤモンド型の鏡面物質はSPECULAR 材質, 床の右側に置かれた球体はREFLECTION材質, 天井の中央には光源となる発光体を配置し, 計20個の三角形と1つの球体からなるシーンを構成した.
光線とシーン内の物体に対して交差判定を行う. シーンは三角形のポリゴンで構成されているため, 光線と三角形の交差判定をTomas Möllerアルゴリズムによって行う.
パストレーシング法による映像合成処理の主な処理を行う. Ray型rayを受け取り, 物体と交差した点での光線の散乱と放射輝度を計算して返却する. 以下に主要な処理ステップと実装を示す.
シーン内の物体との交差点を交差判定関数で計算し, 交差物体がなければ背景色を返す.
シーン内の物体との交差点をintersect_scene関数で計算し, 交差物体の材質に応じて新しい光線の方向を決定する. 拡散反射(DIFFUSE)の場合, 半球面上の重点サンプリングにより決定, 鏡面反射(SPECULAR)の場合, 反射の法則に従い, 法線に対して線対称となるように反射角で反射, 屈折(REFRECTION)の場合,スネルの法則に基づいて決定する.
Throughputは, 経路に沿って光がどれだけ減衰するかを表し, 経路の生成ごとに交差した物体の色を乗算して更新する. さらに, ロシアンルーレットを使用して光線が追跡を続けるかどうかを決定し, 確率的に寄与の少ない経路の追跡を避ける. rand01関数の結果と比較して, throughputの値が小さい場合は追跡を打ち切ることで実装している.
光源に衝突した場合はその光源の放射輝度をthroughputに乗算して返却して終了する.
画面解像度の設定, サンプリング回数の設定, カメラ設定を行っている. radiance関数を呼び出し, 全てのピクセルに対して映像合成処理を行う. また, サブピクセルを確率的に生成して行うことで, アンチエイリアシングを行った. OpenMPにより並列計算を行い, 全体にかかる時間をtime関数により計測した. また, 映像合成結果はPNG形式で保存している.
交差判定アクセラレータの実装で使用した交差判定回路プログラムのソースコードを以下のソースコードB.1に示す.
ソースコードB.1 交差判定プログラム
ZYBO Z7-20の販売元であるDigilent社のサンプルプロジェクトや多くのグラフィック出力アプリケーションで用いられている, VDMA(Video Dynamic Memory Access)転送を用いることを検討した. VDMA転送はXilinxが提供するVideo Dynamic Memory Access(以下, VDMA) IPによって設計することができ, リアルタイムかつ大容量の映像データを送信することができる. 図C.1 にVDMA転送を用いるために設計したシステムのブロック図を示す.
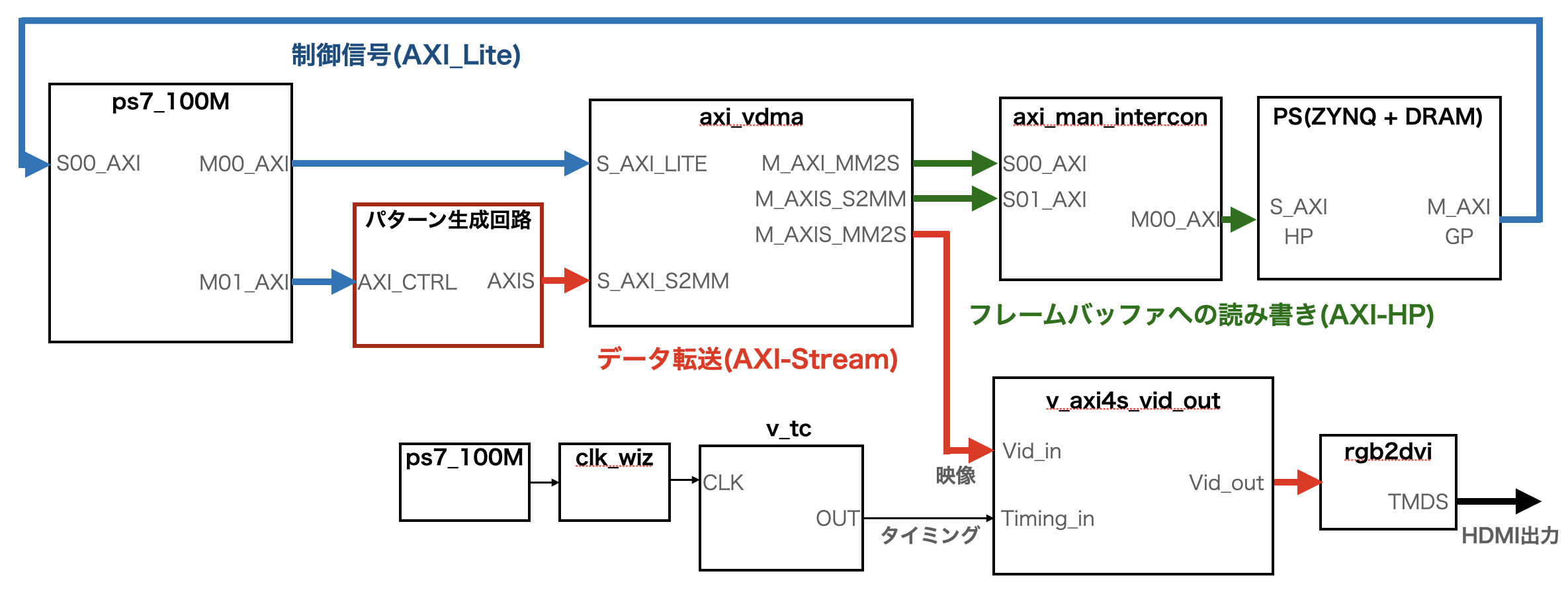
以上のVDMA転送によるディスプレイ表示はPSで後処理を行う複雑な画像処理のようなアプリケーションや大容量映像に適していている一方で, PSからのVDMAコアの制御が非常に煩雑であること, 古い開発環境をターゲットとしたサンプルプロジェクトの互換性がなくそれをベースとした開発が 困難であったことから, 本研究ではVDMA転送を用いず他の方法を検討した.
本研究のシステムにおいて, ディスプレイ表示回路の実装を『FPGAプログラミング大全 Xilinx編 第2版』 (小林優, 2021, 秀和システム, pp.382-438)[5]に記載されている設計を用いた. 本システムは, 前項で示したVDMAによるディスプレイ表示に比べてPSまたはPLで生成したデータを直接グラフィック出力可能であること, レンダリング結果をリアルタイムにグラフィック出力ができること, 最新の開発環境でも再利用できることから, 研究の目的とシステムの要求を満たすため選択した. 図C.2 にディスプレイ表示回路の全体ブロック図を示す.
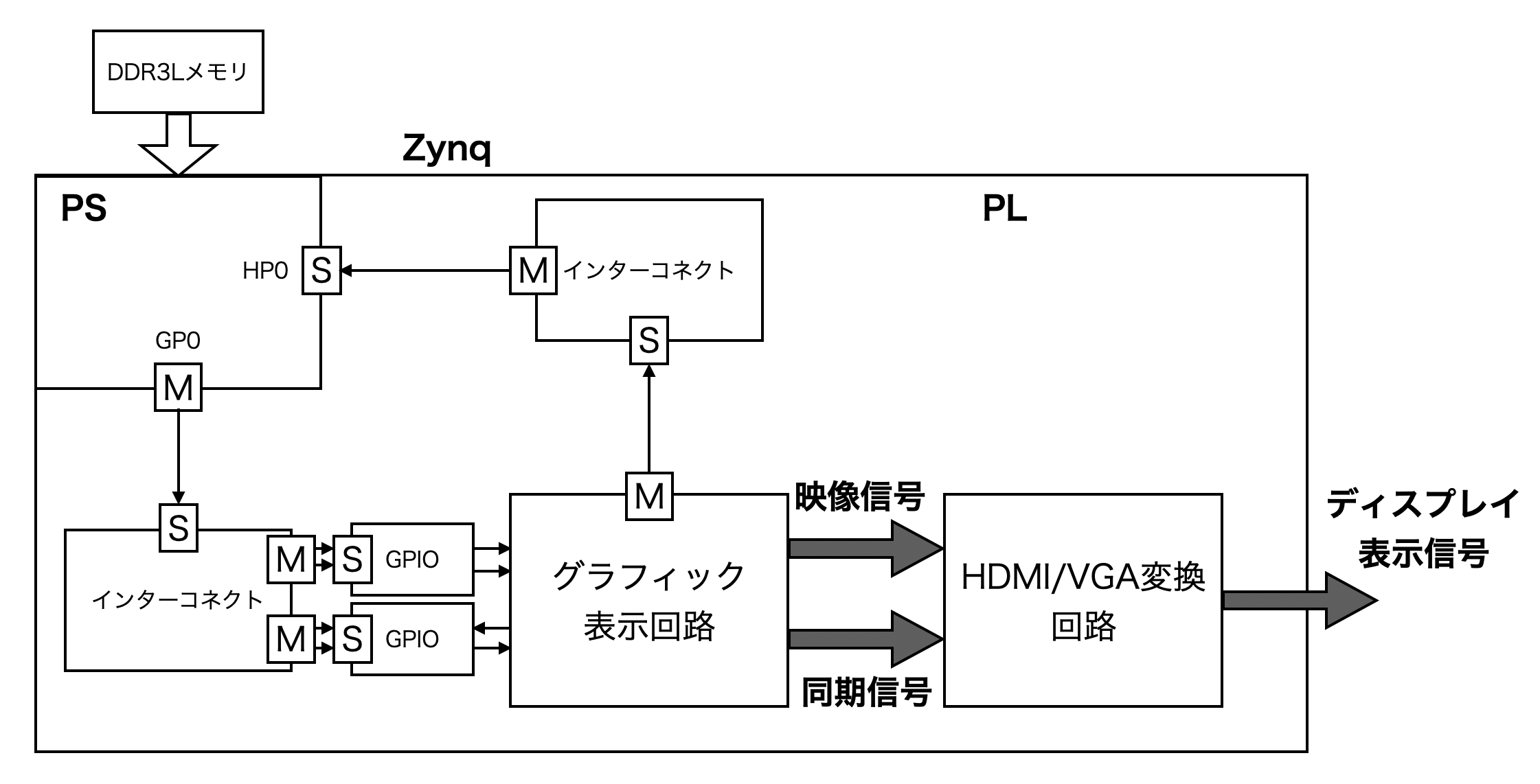
上図のディスプレイ表示回路において, グラフィック表示回路がAXIマスターとしてインターコネクトおよびPSのHPポートを経由して DDR3Lメモリに格納された画像配列を読み出す. また, グラフィック表示回路はAXIスレーブとしても動作し, PSのGPポートからインターコネクトを経由してDDR3Lから読み出す配列アドレス, 表示のON/OFF, 垂直同期, メモリアクセスの指示を受け付ける. PSからの指示を受けてグラフィック表示回路がDDR3Lから読み出した画像配列データは, VGAの同期信号を含んだ映像信号をHDMI/VGA変換回路に転送し, HDMI端子から出力可能な信号に変換してディスプレイに表示する.
Zynq PSコアは, FPGAの一角に作り込まれているARM Cortex-A9デュアルコアである. 32KBのL1キャッシュとメモリ管理ユニットを内包し, DDR3Lへのアクセスができる. HPポートを用いることで, グラフィック表示回路とAXI4で接続する.
グラフィック表示回路は"display"コアとしてIP化する. 以下の図C.3にdisplayコアの構造を示す.
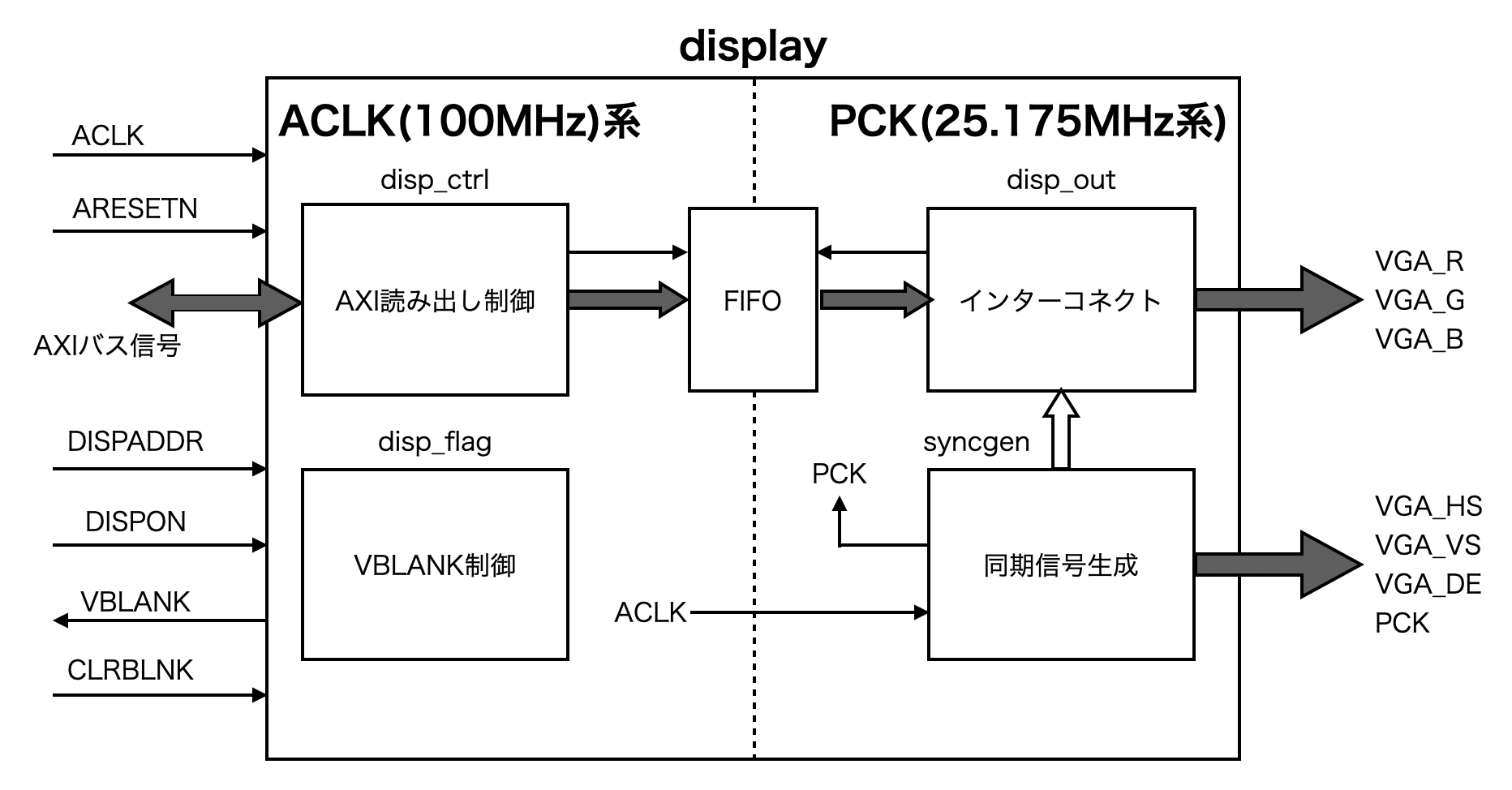
入出力信号の内容を表C.1に示す.
| 信号名 | ビット幅 | I/O | 内容 |
|---|---|---|---|
| ACLK | 1 | I | システムクロック(100MHz) |
| ARESETN | 1 | I | リセット信号 |
| DISPADDR | 30 | I | 表示開始アドレス |
| DISPON | 1 | I | 表示ON |
| VBLANK | 1 | O | 垂直ブランキング |
| VLRVBLANK | 1 | I | VBLANKフラグのクリア |
| VGA_HS | 1 | O | 水平同期信号 |
| VGA_VS | 1 | O | 垂直同期信号 |
| VGA_R | 8 | O | 映像出力(Red) |
| VGA_G | 8 | O | 映像出力(Green) |
| VGA_B | 8 | O | 映像出力(Blue) |
| VGA_DE | 1 | O | 出力イネーブル |
| PCK | 1 | O | ピクセルクロック |
displayコアのVGA映像信号出力と同期信号を入力してHDMI端子を通して出力するためのIPコアである. これは『FPGAプログラミング大全 Xilinx編 第2版』(小林優, 2021, 秀和システム)[5] において提供されている. この回路は, Digilent社が提供するRGBの24ビット映像信号をDVI信号に変換する機能を持つIPコア "rgb2dvi"に対して上位階層を用意し, VGA用のクロック設定を追加したものである.
Windows 11 Pro上のVivado 2023.2のプロジェクトにおいて以上のIPコアおよび2つのGPIOコアを配置し, 配線を行う. AXIポート同士はVivadoて提供される「Run Connection Automation」によりAXIバスの接続を行った. また, PSのAXIマスターからグラフィック表示回路を表示するためのGPIOコアの出力とグラフィック表示回路を接続した. 完成した回路図を図C.4に示す.
パストレーシングプログラムを元に, パストレーシング回路を高位合成により実装した. 回路動作を表すパストレーシング回路プログラムとその動作検証を行うパストレーシング回路テストベンチを実装し, 性能とリソース使用量を確認する.
パストレーシングプログラムを基にして, main関数に相当する処理をrender_video関数としてトップモジュールとして, パストレーシング処理と映像出力を行うパストレーシング回路プログラムを実装した. このrender_video関数内では, main関数と同様に全ての画素に対してradiance関数を呼び出してサンプル数を100としてパストレーシングを行った後, レンダリング結果をVRAMのアドレスへ逐次的に書き込む.
また, ディレクティブ(最適化指示)を追加する. radiance関数において, 経路を生成する最大深度(MaxDepth)を超える回路合成が行われて不要な回路が生成されることを防止するために, forループに対して"#pragma HLS LOOP_TRIPCOUNT min=1 max=10"のディレクティブを追加した. このLOOP_TRIPCOUNT数の指定により, radiance関数内で定義しているMaxDepth=6に対応して最大ループ回数は10回になり, ロシアンルーレットにより最小ループ回数が1回になる動作を表した.
以下のソースコードD.1に, パストレーシング回路プログラムを示す.
ソースコードD.1 パストレーシング回路プログラム
回路記述に対して, 動作を確かめるためにパストレーシング回路テストベンチをC++で実装した. このテストベンチは画像の初期化と, パストレーシング回路のトップモジュールであるrender_video関数の呼び出し, raw形式でデバッグ用の画像書き出しを行う. 以下のソースコードD.2に, パストレーシング回路テストベンチ関数を示す.
ソースコードD.2 パストレーシング回路テストベンチ関数
パストレーシング回路記述とテストベンチに対して, "C Simulation"によりCシミュレーションを行なう. raw形式で書き出された画像を確認してアルゴリズム記述が正しく動作しているかを確認する. raw画像の確認にはirfanview 64bitを用いてBPPを32bit RGBAの形式に指定して開いた. 以下の図D.1 にCシミュレーション結果を示す.

映像合成結果は正しく得られており, Cシミュレーションにおける問題はない.
以下の 表D.1 に高位合成したパストレーシング回路のタイミングパフォーマンスを示す.
| Clock | Target | Estimated | Uncertainly |
|---|---|---|---|
| ap_clk | 10.00ns | 9.591ns | 2.70ns |
10.00nsのクロック周期をターゲットにして, 9.553nsで1サイクルを終了できることを示している. これにより, xc7z20-clg400-1でサポートされる最大周波数100MHzのクロック信号で正しく動作可能である.
表D.2 に, 高位合成したパストレーシング回路のレイテンシパフォーマンスを示す.
| latency(cycles) | latency(absolute) | Interval(cycles) | |||
|---|---|---|---|---|---|
| min | max | min | max | min | max |
| 128 | 2122517023448 | 1.280us | 2.1e+04 sec | 129 | 2122517023449 |
表D.3 に, モジュールごとのレイテンシパフォーマンスを示す.
| latency(cycles) | latency(absolute) | Interval(cycles) | ||||
|---|---|---|---|---|---|---|
| Module | min | Max | min | Max | min | Max |
| sin_or_cos_float_s | 17 | 17 | 0.170us | 0.170us | 1 | 1 |
| radiance | 293 | 5034 | 2.930us | 50.340us | 293 | 5034 |
回路全体のレイテンシは\(2.100\times10^{13} [ns]=21000[s]\)であり, CPU実行に対して低速である.
以下の 表D.4 に高位合成したパストレーシング回路のリソース使用量を示す.
| Name | BRAM_18K | DSP | Flip-Flop | LUT | URAM |
|---|---|---|---|---|---|
| DSP | - | - | - | - | - |
| Expression | - | - | 0 | 1651 | - |
| FIFO | - | - | - | - | - |
| Instance | 0 | 2666 | 365669 | 419777 | - |
| Memory | - | - | - | - | - |
| Multiplexer | - | - | - | 3194 | - |
| Register | - | - | 2682 | - | - |
| Total | 0 | 2666 | 368351 | 424622 | 0 |
| Available | 280 | 220 | 106400 | 53200 | 0 |
| Utilization(%) | 0 | 1211 | 346 | 798 | 0 |
xc7z20-clg400-1が有するリソースを大幅に超えたリソースを消費した. DSP(乗算器), FF(Flip-Flop), LUT(Look Up Table)の3つについて利用可能なリソースを超えて使用しており, 実装不可能である.
パストレーシングシステム制御プログラムは, PSにおけるパストレーシングの処理と交差判定アクセラレータの制御, 映像合成結果のディスプレイ出力を行う. パストレーシング制御プログラムをソースコードE.1に示す.
ソースコードE.1 パストレーシング制御プログラム
パストレーシング処理に関してはパストレーシングプログラムと同様であり, それに加えてディスプレイ表示回路と交差判定アクセラレータを制御を行っている. 交差判定アクセラレータはAXI4-Liteでインターフェースを作成しているため, Vitisで自動的に以下の 表E.1 に示すドライバ関数[13]が生成されている.
| Function Name | Function Usage |
|---|---|
| Initialize IP | int X<IP_name>_Initialize(&<Instanse_var>, <Devive_ID>); |
| Start IP | void X<IP_name>_Start(&<Instance_var>); |
| IP IsDone | u32 X<IP_name>_IsDone(&<Instance_var>); |
| Get Return Value | u32 X<IP_name>_Get_Return(&<Instance_var>); |
| Write to Port | u32 X<IP_name>_Set_<Port_name>(&<Instance_var>, <value>); |
| Read from Port | u32 X<IP_name>_Get_<Port_name>(&<Instance_var>); |
これらの関数を用いて交差判定アクセラレータを制御した.