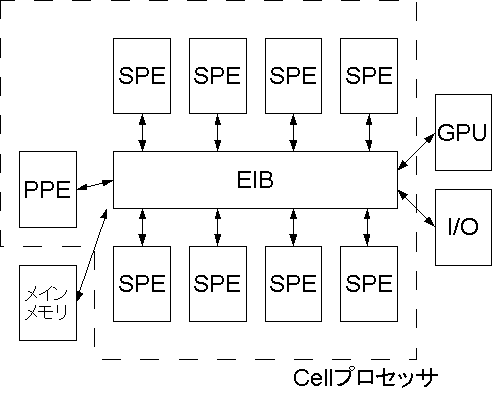
図1.Cellプロセッサの構成
Cellプロセッサは1基の汎用的なプロセッサコアと8基のシンプルなプロセッサコアを持つヘテロジニアスマルチコアプロセッサコアである。 Cellプロセッサは非常に高速なプロセッサであるが、性能を向上させるために既存のプロセッサに搭載されていた複雑な専用回路が搭載されていない。 よって、その性能を活かすためにはソフトウェア側での対応が必要となる。 個人でCell上のプログラムの開発にはIBMから提供されているCellSDKを使用する。 CellSDKはPS3Linux上で使用できる開発キットのことである。このCellSDKにはCell上でプログラムを開発するための多くのライブラリが実装されている。 これは汎用性が高い代わりにCellの特性を活かしていないため動作が低速である。 本論文ではCellSDKの中に標準で実装されている高速フーリエ変換を行うLibfftの一部の改良を行い、速度の向上を図る。
近年、CPUの計算速度の進化は動作周波数の向上やスーパースカラや2次キャッシュといった複雑な専用回路の構築を行うことで実現されるようになったが、これらの手段での速度向上にはほぼ限界が来ており、その代わりに単体のプロセッサコアの処理能力の向上を行うのではなく、1つのチップの中に複数のプロセッサコアを搭載し、並列に処理を行うことで全体の処理能力の向上を図るといった方法が主流になりつつある。この中でソニー・エンタテインメント、IBM、東芝の3社で共同開発されたプロセッサがCellプロセッサである。
Cellプロセッサは従来のPowerPCプロセッサ要素(PPE)に加えて8基のSPEと呼ばれるSIMD演算という演算に特化したプロセッサ要素を搭載したヘテロジニアスマルチコアプロセッサである。SPEでは32ビット単精度浮動小数データについては4個のデータをスループット1で積和演算ができる。積和演算は乗算と加算の2個の演算を一度に行うので、SPEの単体でのピーク性能は以下のようにして求められる。
(SPE単体のピーク性能) = (動作周波数) × 4 × 2 [FLOPS]
PS3でのSPEの動作周波数は3.2GHz、PS3Linuxで使用できるCellプロセッサのSPEの数は最大6つなので単体のSPEの処理能力は25.6GFLOPS、プロセッサ全体が最大で153.6GFLOPSになる。これは同じプロセスを利用したPentium4(3.8GHz)のピーク性能(15.2GFLOPS)と比較して約10倍の性能差がある。
上記のように全プロセッサが全て有効に動作するという仮定ではCellプロセッサの速度は速いと言える。しかし、実際の情報処理において多くのSPEを使って高速に処理をさせることは難しい。そのため、ソフトウェア開発においてもCell特有のプログラミングが必要になる。
現在、Cellプロセッサを使用したプログラムを個人で開発する場合、CellSDKを使用して開発を行う。CellSDKはIBMより提供されているCellプロセッサを利用するプログラムの開発キットである。ユーザーはこのCellSDKをCellプロセッサを搭載したコンピュータにインストールする事によって開発が可能である。CellSDKには開発に必要な一通りのツール、ライブラリが同梱されている。この同梱されているライブラリは汎用性に富んでおり開発において非常に有効である。しかしながら、処理はPPEと1つのSPEで行うためにCellプロセッサの性能を活かしきれているとは言えない。そこで、複数のSPEを使用できるようにすれば処理効率を上げ、全体のプログラムの処理速度を上げられると考えられる。本研究ではCellSDKに標準で同梱されているライブラリの一つであるlibfftの一部、fft_1d_r2.hを複数のSPEで動作するように改良を行った。そして、元のプログラムと処理速度の比較評価を行い、Cellプロセッサを使用したプログラムにおける並列処理の効率性について考える。
本論文では、まず2章で現在のプロセッサコアの背景とCellの構成とFFTの基本的な概念について述べ、3章でCellについての近年の類似の研究を示す。4章でこれらを踏まえた上でCell上で動作する高速なFFTのプログラムの作成と評価、考察を行い、5章で今後の展望について述べる。
Cellプロセッサは1基のPowerPC Processor Element(PPE)と呼ばれるOS処理などの制御用のプロセッサと8基以下のSynergistic Processor Element(SPE)と呼ばれる計算に特化したプロセッサ、そして外部インターフェースとそれらを繋ぐElement Interconnect Bus(EIB)と呼ばれる高速なバスで構成される。
PPEはPowerPC 970(G5)互換の64bit PowerPC Architecture準拠のプロセッサコアである。 PPEは2ウェイのマルチスレッド機構を持ち、2スレッドを交代に実行することが可能である。 切り替えが速いことからOS等の制御系の処理を行う。
SPEはCellの主に計算を行うプロセッサである。 特に単純な計算を多く処理する場合に有効なプロセッサである。 CellにはSPEが8つ搭載されている。そのうち7つが正常に動くことが保証されている。 PS3Linuxではその中で更に6つのSPEを使用することができる。 SPEはSynergistic Processor Unit(SPU)、Local Store(LS)、Memory Flow Controller(MFC)で構成される。 SPEの構造を示す。
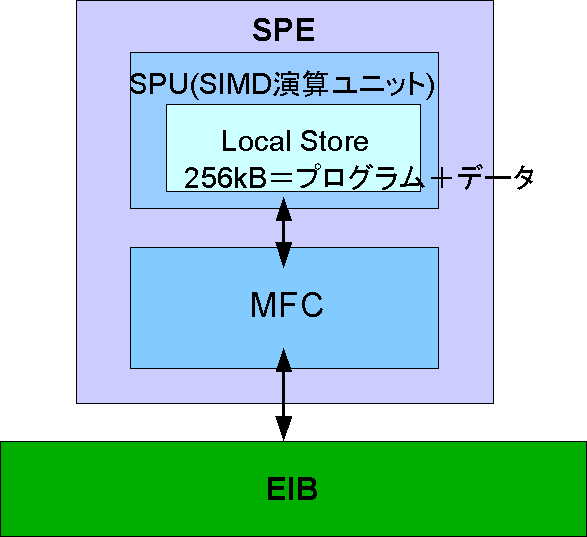
SPUはSIMD型のアーキテクチャで、128bit長のデータ列に対して1回の命令で処理を行える。 例えば、単精度浮動小数点演算を4スロット同時に行える。 SIMDについては2.2.4項に詳しく記す。 Intel社のPentiumシリーズと比較して単純な構造となっており、SIMD演算を用いて高速に演算を行うことができる。 それぞれのSPUはLocal Storeと呼ばれる記憶領域を持つ。
LSは各SPUに搭載されている256KBのメモリである。 LSは各SPUから直接参照できる唯一のメモリである。 SPE上で実行されるプログラムはLS上にロードされ実行される。 この為、SPEのプログラムとプログラムが処理するデータは、合計で256KBより小さなサイズである必要がある。
MFCはメインメモリや他のSPUとデータのやり取りを行うためのユニットである。 MFCはチャネルインターフェースとDMAインターフェースを介してSPUと接続されている。 SPUはチャネル命令を実行すると、チャネルインターフェースはその命令に応じてMFCにDMA転送コマンドを発行する。 その命令を基に、SPU内部のLSと外部メモリとの間のDMA転送を行う。
EIBは4本のリングバス構造の高速なバスでCell内部のメインバスとして各部を接続している。 4本のバスは16バイト幅で構成されており、プロセッサコアの半分の周波数で動作する。 バスは片方向に転送できるリングが時計回りと反時計回りとでそれぞれ2組ずつ搭載されている。 データは衝突が起こらない限り同じリング上に流すことができるので複数のデータを同時に転送することが可能である。 SPEとメインメモリ間でデータ転送を行う場合はすべてEIBを介して行われるが一度の転送サイズの制限が存在する。 これはそれぞれDMA転送、メールボックス、シグナル通知レジスタの項で詳細を述べる。
本項ではC言語を使ってCellプログラミングを行う為に、SPEを使用した簡易なプログラムを用いて説明を行う。 次に、Cellプロセッサ特有の機能であるDMA転送、メールボックス、シグナル通知レジスタとそれらに付随する制限について述べる。
Cellプロセッサを使用したプログラムを実行する時、SPEのプログラムはPPEのプログラム上でそれぞれのLSにロードされ実行される。 SPEでプログラムを実行させるためにはPPEのプログラム上でSPEプログラムを実行するSPEのLSにロードさせる必要がある。 これを実現するためにCellSDKのlibspe2を用いることで実現できる。 SPEを使用するためのPPEの手順をを以下に述べる。
PPE側の処理
例えば、実際にSPEでHello World!を表示するプログラムは次のようになる。
PPE側の処理:
#include<stdio.h>
#include<libspe2.h>
int main(int argc, char **argv){
int ret;
spe_context_ptr_t spe;
spe_program_handle_t *prog;
unsigned int entry;
spe_stop_info_t stop_info;
prog = spe_image_open("spu.elf");
if (!prog) {
perror("spe_image_open");
exit(1);
}
spe = spe_context_create(0, NULL);
if (!spe) {
perror("spe_context_create");
exit(1);
}
ret = spe_program_load(spe, prog);
if (ret) {
perror("spe_program_load");
exit(1);
}
entry = SPE_DEFAULT_ENTRY;
ret = spe_context_run(spe, &entry, 0, NULL, NULL, &stop_info);
if (ret < 0) {
perror("spe_context_run");
exit(1);
}
ret = spe_context_destroy(spe);
if (ret) {
perror("spe_context_destroy");
exit(1);
}
ret = spe_image_close(prog);
if (ret) {
perror("spe_image_close");
exit(1);
}
return 0;
}
SPE側の処理:
#include<;stdio.h>
int main(){
printf("Hello World!")
return 0;
}
複数のSPEを用いたプログラムを作成する場合、プログラムのスレッド化を行う必要がある。 このスレッド化を行うためにC言語ではPPE上でpthreadを用いて、スレッドごとにSPEコンテキストをロード、実行させることによって実装することが可能である。この方法を使用すると、SPEの処理実行中はPPE側は処理実行中のSPEの処理が終了するまで待機状態になる。 SPEの処理中にPPEの処理を実行するためにはSPEコンテキストをロードするスレッドを立てる前にPPE上にもう一つスレッドを立て、そのスレッド中でPPEが行う処理を行えばよい。
SPEはそれぞれのLS以外のメモリに直接アクセスすることはできない。 そのため、PPEプログラムが利用するメインメモリ上のデータをSPEプログラムで利用したり逆にSPEプログラムで使用したデータをPPEプログラムに渡すためには、DMA転送を利用してLS上とメインメモリ上の間でデータの転送を行う。 MFCの中にはSPUからのDMAリクエストを保持するための16本のDMAキューが存在し、16個まで同時にDMA転送を実行できる。DMA転送によるデータはDMAインターフェースを通ってSPUとやりとりを行われる。 一度のDMA転送で128bitから16KBまでのデータを読み書きすることが出来る。SPUの命令実行とDMA転送は独立して並列に行われる。 また、SPE外部からのEIBを介したDMAリクエストを処理するために、SPUからのDMAリクエスト用とは別に8本のDMAキューが存在する。 DMA転送を用いるプログラミングの際の注意点がいくつか存在する。 DMA転送を行う際にはLSとメインメモリの先頭アドレスが必要となるが、アドレスは16バイト境界に揃えられている必要がある。DMA転送を行うデータサイズは1、2、4、8バイトもしくは16バイトの倍数である必要があり、最大サイズは16KBである。16バイト未満のデータを転送する場合データが転送サイズでアラインメントされていて、かつ、メインメモリとLSの下位4ビットのアドレスが同一である必要がある。大きなデータを転送するときには転送処理をなるべく減らすため、データを16KBずつに分けて転送を行う必要がある。 DMA転送を行う際には、あらかじめ送受信で使用するメインメモリの先頭アドレスを格納する構造体をPPE側で用意して、この構造体のアドレスをSPEプログラム起動時に引数として渡すことによって可能となる。 この構造体は16の倍数バイトでなければならないため、送受信を行うデータとは別に帳尻合わせ用のデータを確保する必要がある場合がある。例えば、long型の変数を2つとint型の変数を転送するとする。 long型のデータサイズは8バイト、int型のデータサイズは4バイトである。今、これを合計すると20バイトであるが、DMA転送を行うためにはあと12バイト余分に領域を確保する必要がある。 SPEはDMA転送が完了するのを待たずに次の処理を実行する。また、DMA転送が完了してから次の処理を行う場合は関数supu_mfcstat()を使用し、引数にMFC_TAG_UPDATE_ALLを指定することで可能である。
DMA転送はSPE上のLSとPPE上のメインメモリ間の大きなデータ通信を行うために使用する。 MFCにはこれとは別にPPEとSPE、SPE同士で通信を行う方法を実装している。 ここではMFCが提供するメールボックスについて述べる。 メールボックスはPPEとSPE間で通信を行う機構である。 DMA転送と異なるのは転送サイズが32ビットデータのみを受け渡すという点である。 通信サイズの特性からサイズの小さな実効アドレスやパラメータ、イベントフラグ等を送るのに適している。 PPEとSPEで双方向のデータの受け渡しが可能である。 SPEにはPPEからのデータを受け取る32ビットの非ブロッキングなキューが4つ用意されているので蓄積が可能である。 SPEからPPEにデータを送る場合、各SPEにそれぞれ1つずつ用意されている送信用キューにデータを渡す。 その際にPPEに対して割り込みを行うか行わないかを選択することができる。 割り込みを行わない場合、SPEはPPEがデータを読み込むまで待機する。 キューにデータが受信されていない状態で受信側のプログラムがキューに対して読みこみを行った場合、そのプログラムはキューに何らかのデータを受信するまで待機状態になる。
SPUシグナル通知レジスタはPPEからSPEへ、もしくはSPE同士で制御メッセージやイベントをシグナルとして通知するために利用する。 32ビットのレジスタが各SPEに2本ずつ用意されている。 シグナルを送信する側のPPEやSPEは、シグナルを受信する側のシグナル通知レジスタに対して32ビット長のデータをシグナル値として書き込む。 送信する側はあらかじめ受信側のシグナル通知レジスタの実効アドレスを把握している必要があり、DMA転送やメールボックスを用いてPPE側から受け取ることで可能である。 受信側のSPEはSPEコンテキストのロード時に次の宣言のように、あらかじめシグナル通知レジスタを使用するためのフラグを立てる必要がある。
spe_context_ptr_t spe = spe_context_create(SPE_MAP_PS, NULL);
受け取ったシグナルを受信側のSPEが読み込むと、読み込まれたシグナル値はクリアされる。
シグナルが到着していないときにSPEプログラムがシグナル通知レジスタを読みだそうとした場合、SPEプログラムはシグナルを受信するまで待機する。
SIMD演算はSPEで使用できる演算である128ビット単位の演算を行うので、1つの命令で複数のデータに対する処理を同時に行うことができる。 従って1つの命令で32ビットのデータに対して処理を行う通常のCPUと比べると命令数を少なくして、多くの処理を行うことができる。 例えば、単精度浮動小数点は32ビットなので、Cellでは4つの単精度浮動小数点演算を1つの命令で行うことができる。 例えば積和演算を行う場合、次の図のようになる。 RA×RB+RCの計算を1つの命令で処理できる。

図のRA、RB、RCはそれぞれ32ビットの浮動小数点の配列である。 これらはそれぞれ4つで1組のデータとして1回の処理命令で同時に処理を行うことができる。 ただし、SIMD演算では128ビットのデータ同士であっても、複数の命令を同時に処理することはできない。 SIMD演算は画像処理や物理演算のような膨大なデータに対して計算を単調に繰り返すような演算を行う場合には有効である。 CellプログラミングでSPE上でSIMD演算を行うにはSIMD演算を行う関数にベクタ型で引数を渡す必要がある。 ベクタ型はchar、int、long等のスカラ型にそれぞれ対応した型がある。 Cellで扱うベクタ型のデータはすべて128ビットの固定長で構成されており、データ型によって2〜16個の要素を含む。 これは、16バイト長の配列にスカラデータをひとまとめにして格納ていることと同義である。 実際にプログラムを組む際にはそれぞれ対応するデータ型をキャストすることで実装できる。 例えばvector float型が必要ならfloat型の配列をキャストすることによって実装することができる。
CellSDKはIBMより提供されているCellプロセッサを利用するためLinux用の開発環境である。 CellSDKにはPPE、SPE用のコンパイラ、ライブラリ、デバッガ、使用法などのテキスト等が含まれている。 ユーザーは各自でIBMのホームページからCellSDKのイメージファイル(iso形式)とLinuxでパッケージを管理するためのrpmファイルをダウンロードすることによって入手できる。 x86、PPC64等のCPU上のLinuxで使用できるため、Cellプロセッサを搭載していないPCでも、Cellプロセッサで動作するプログラムの開発が可能である。 また、オプションでCellシミュレータが入手できる。これは、Cellプロセッサが搭載されていないPCで主にデバッグを行うために使用される。 Cellシミュレータはlinux上に仮想OSを起動し、その中で擬似的にCell用のプログラムを実行することができる。 また、プログラムの実行中にそれぞれのプロセッサの動作状況や、シグナル受信等の情報がグラフィカルに表示され、ユーザーはCell上での動きを確認することができる。
libfftはCellSDKに標準で同梱されているFFTを行うためのライブラリである。 libfftには次のような関数が収録されている。
これらの関数はそれぞれ1次元FFTと2次元FFTのハンドルの初期化、それぞれのFFTの計算、それぞれのFFTのハンドルの開放を行う。 各関数にはそれぞれパラメータを渡すことができる。 これは、FFTの入出力の形式を実数、虚数で選択することができるFFTライブラリはサンプリング数が2のべき乗である必要はない。 実数と虚数をそれぞれ別の配列に格納した状態で渡すことができる。
離散フーリエ変換(DFT)は信号処理などでのデジタル信号の周波数分析に使われる。 それ以外にも偏微分方程式や畳込み積分にも使用されることがあり、その使用頻度は高い。 以下に式によって変換できる。
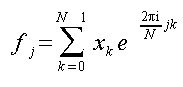
(j = 0,1,2,...N-1)
高速フーリエ変換(FFT)は離散フーリエ変換(DFT)をコンピュータで高速に計算するためのアルゴリズムである。FFTにはいくつかの方法が存在するが、本論文ではCooley-Tukey型FFTアルゴリズムのことを示す。 Cooley-Turkey型FFTは分割統治法を用いたアルゴリズムで、ステップごとに変換のサイズをN/2の2つの変換に分割するので、Nの大きさは2の累乗に限られる。 前項で示したDFTは直接計算した場合の時間計算量はO(N2)であるがFFTを用いた場合、O(Nlog2N)の計算量で同様の解を得ることができる。
FFTはDFTの処理を高速化するために信号における3つの特性、伸縮特性、シフト特性、加算特性を利用することによって行われる。
前項のDFTの式の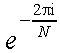 をWNとすると次のように表せる。
をWNとすると次のように表せる。
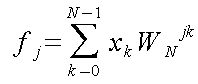
これは、N×NのWの行列にN×1の行列をかけるのと同義である。
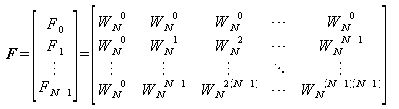
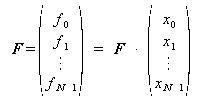
Σを用いないで考えると、WNjで括り出せる。 また、Nは偶数の時、Wの指数から1を除いた数が奇数のものと偶数のものとで半分に項を分けることができる。
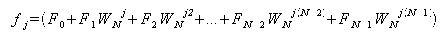
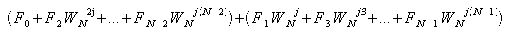
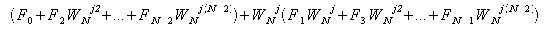
この変形によって2つのカッコの中はどちらも各項のWの指数がすべて偶数になる。ここで、Wは、
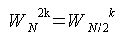
であるため、fjの式は次式に変形できる。
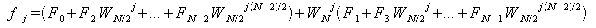
カッコの中の式はそれぞれ、データ数がN/2個の離散フーリエ変換である。 これはそれぞれに対して個別に処理を行って最後に足し合わせれば同じ結果になるということを示している。 更に、N/2の値が偶数なら同様の操作を行えば4つの集合に変形することができる。 Nの値が2のべき乗であれば、この操作を繰り返すことによって集合を細かく分割できる。
以上よりfjの各式は以下のようになる。
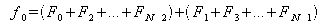
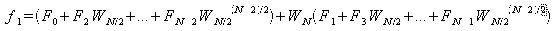
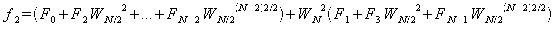
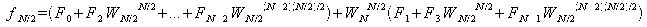
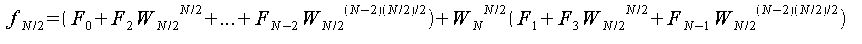
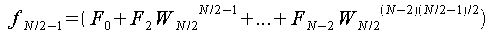
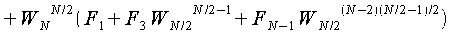
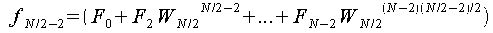
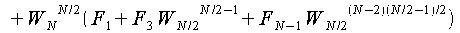
この時、
が成り立つので、fjの各式を変形すると、
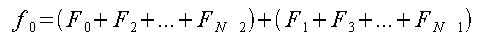
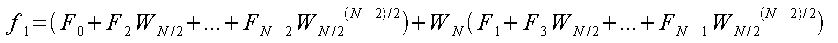
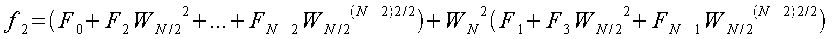
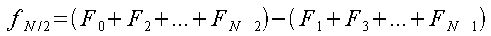
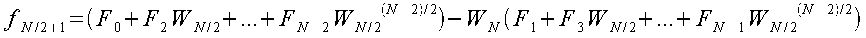
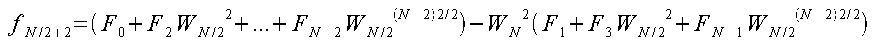
となる。この時、jの値がN/2より大きいものは括弧内の式が同様で、それを減算している式であるということがわかる。 すなわち、j=N/2-1までの処理を行えばそれ以降の計算は不要である。 この計算方法を図に示すと次のようになる。
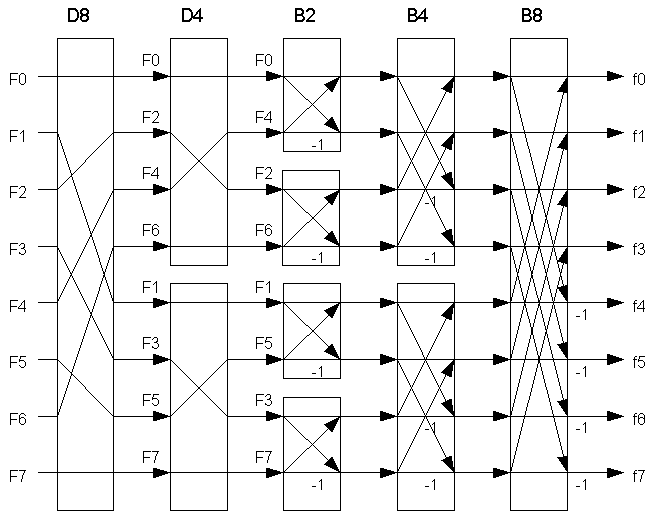
このような図は図形の形からバタフライと呼ばれている。 この図ではN=8の時の分解処理とバタフライを示している。 図の-1と書いてある部分は減算を行う部分である。
D8、D4の部分でバタフライ演算を行うための順番の入れ替えを行っている。 最初の入れ替えで偶数番目の要素と奇数番目の要素になるように入れ替えを行っている。 2番目の入れ替えでそれぞれのグループにおいて第2ビットの値が0のものと1のもので入れ替えを行っている。 これは、各要素のn番目の値を2進数で表記した時のビット列を反転させた時と同等の処理になる。 これをビット反転と呼ぶ。
FFTは再帰的な処理であるが、このビット反転とバタフライ演算を行うことによってプログラムを再帰処理させる必要がなくなる。
今回Cellプログラミングを行うにあたって、IBM社より提供されているCellSDKを使用する。 作成に当たって、使用するSPEの個数は2個に固定し、2個で高速化できるようにチューニングを行う。 入出力のサンプリング数は64個、型は浮動小数点floatの配列を使用する。 入力のデータは実数と虚数があり、下図のように、n番目の実数→n番目の虚数→n+1番目の実数・・・といった配置にする。 出力も同じ形式となるようにする。 よって、入力用、出力用に確保する変数はサンプリング数の2倍になる。

PPEとSPEの転送にはDMA転送を用いる。 SPE同士の通信にはシグナル通知レジスタを用いる。 SPE同士が通信を行うためには送信側のSPEが受信側のSPEの実効アドレスを取得している必要がある。 そこで、SPEの実効アドレスをPPEからメールボックスを用いて転送する。 PPE上でSPEコンテキストをロードするスレッドを立てると、すべてのSPEプログラムが終了するまで処理が行えなくなってしまうので、SPEのスレッドを立てる前にもう一つメールボックス用の小スレッドを立てる。 SPEメインのプログラムはPPE上で実行し、LS上に入出力の変数を保存する領域の確保を行う。 2つのSPEにプログラムをロードし、それぞれのSPEで処理を行うように設計する。
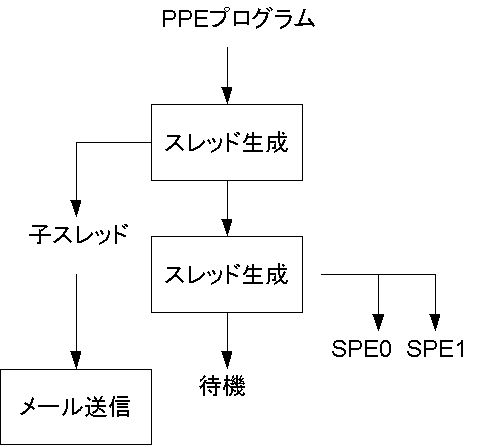
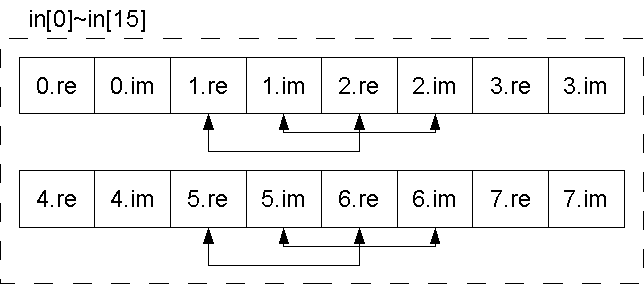
SPE上ではFFTを行う関数を実行する。 バタフライ演算を行う回数はlog2(N)で求められる。 本実験ではサンプリング数が64個であるため、FFTを行うために全体で6回のバタフライ演算を行う必要がある。 このバタフライ演算のうち、その前半3回と後半3回を分割して処理を行う。 この内、前半部分のバタフライ演算を入力配列の前半と後半に分割する。 入力変数は実数と虚数がそれぞれ64個ずつ存在するため、サンプリング数が64の場合、合計で128個の変数の配列になる。 よって128/2=64個の配列を2つのSPEでそれぞれバタフライ演算を行う。
1回目と2回目のバタフライ演算の段階でで入力変数の偶数番目の変数と奇数番目の変数に入れ替えを行う。 入れ替えにはSIMD演算を用いる。
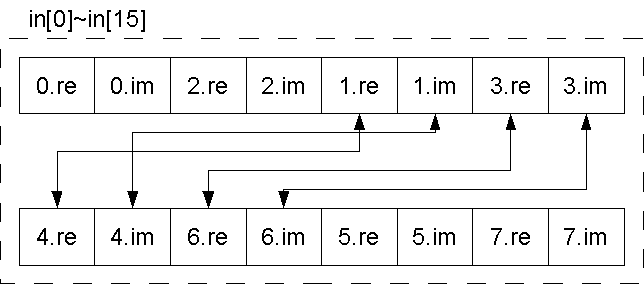
2回目のバタフライ演算の段階でビット列の2番目の値が0と1とで分ける。 この時、処理結果を実数と虚数に分けてそれぞれ別の配列(dst_re,dst_im)に入れる。
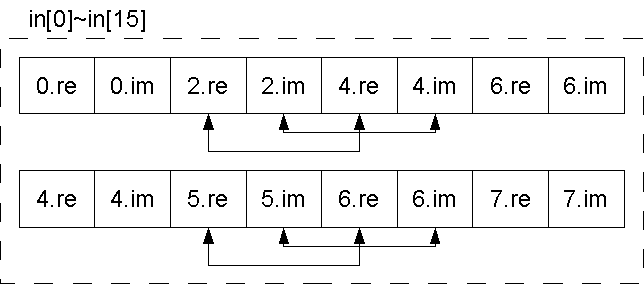
3回目のバタフライ演算が終了した段階で変数の順番の入れ替えと実数と虚数を分割する処理が終了する。
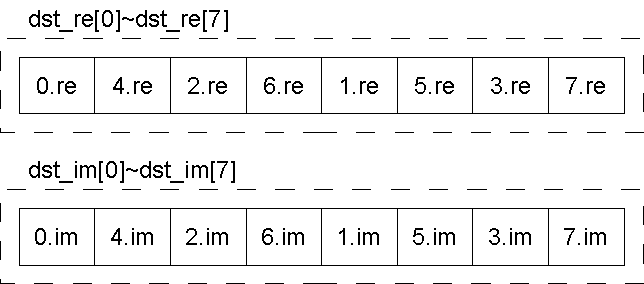 図10.処理結果
図10.処理結果
1〜3回目のバタフライ演算の処理が終了した時点で片方のSPEはDMA転送で処理結果をメインメモリに書き込む。 メインメモリへの書き込みが終了した段階で、終了の旨をもう片方のSPEに伝えるためにシグナル通知レジスタを用いて情報を送る。 本実験では使用SPEは2つのため送る適当な情報を送る。 待機しているSPEはこの通知を受け取ってから、メインメモリに書き込まれた処理結果をDMA転送で受け取り、残りのバタフライ演算を行う。
PPE上でメインプログラムでFFTを行うために必要な変数を用意する。 以下にPPE上で作成するFFTに渡す変数をまとめる。
| 変数名 | 型 | 用途 |
| in | float[128] | 入力用 |
| out | float[128] | 出力用 |
| W | float[64] | Wの行列用 |
これらの作成が完了してから自作のFFTの関数を渡す。この時、引数として作成した変数を渡す。 この際、inとoutはvector float型にキャストする。
SPEプログラムをSPEのLSにロードする。 複数のプログラムを同時に走らせるためにpthreadライブラリを用いてSPEプログラムをスレッド化する。 このスレッド化の時にSPEのプログラムを実行するための変数を構造体にひとまとめにして一度のDMA転送で渡す。 この時、引数としてSPEに数字を付け、区別できるようにする。ここではそれぞれSPE0、SPE1とする。 この状態でSPEのスレッドを走らせてしまうと、SPEの処理が完全に終了するまでPPEでの処理ができなくなってしまう。 SPE0もSPE1もPPEからメールボックスの受信を行う必要があるため、SPEのスレッドを走らせる前にもう一つメールボックスを使用してSPEにSPEの実効アドレスを渡す子スレッドを立ち上げる必要がある。 PPE上でそれぞれのSPEプログラムを実行させる。
まず、SPEプログラムを実行させる前に立てた子スレッドからメールボックスを使用して、SPEの実効アドレスをSPE0、SPE1に転送する。 SPE側はメールボックスのキューにデータが入るまで待機する。
それぞれのSPEで前半のFFTを行うためin、outをPPEよりDMA転送を用いてそれぞれのSPEに送る。 PPEは立ち上げたSPEの実効アドレスを取得し、その実効アドレスの値をメールボックス機能を用いてそれぞれのSPEに転送する。SPE側ではそれを受け取る。 プログラムの流れを次図にまとめる。
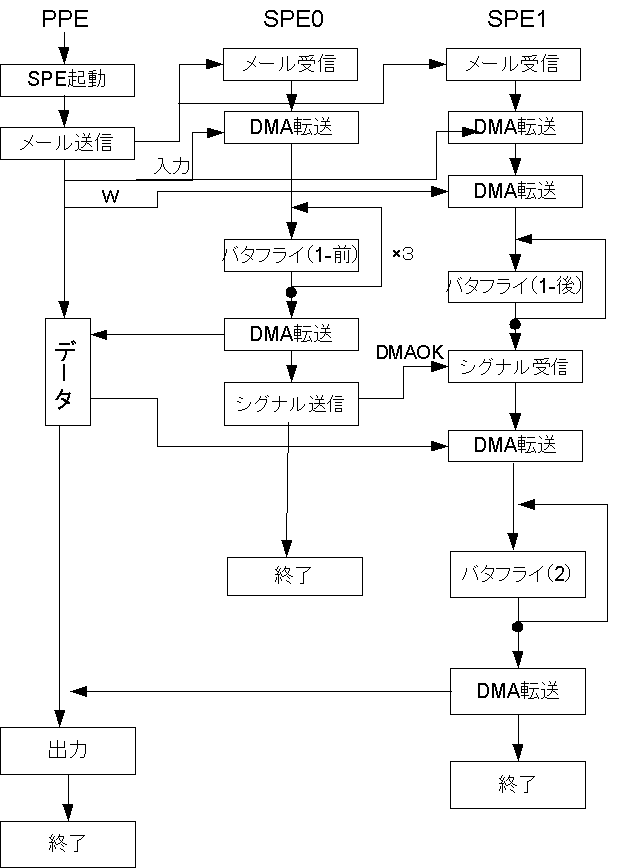
まず、SPE1は後半のバタフライ演算に必要な配列Wをメインメモリより転送する命令を出す。 この時、SPE1はWの転送終了を待たずにバタフライ演算を開始する。 SPE0でもバタフライ演算を実行する。 バタフライ演算を行う際にはSIMD演算を行えるようfloatの配列をvector float型にキャストを行う。 SPE0は前半のバタフライ演算が終了した時点の出力をDMA転送を用いて、PPEに転送する。 SPE1は前半のバタフライ演算が終了すると、SPE0からのシグナルを受信するまで待機する。 SPE0が出力の転送が終了した時、シグナル通知レジスタを使用しSPE1にシグナルを発し、転送した旨を知らせる。 SPE0はここで処理を終了する。
SPE0よりシグナルを受け取ったSPE1はDMA転送を用いて、処理結果を転送する。 SPE1上でそれぞれの処理結果を足しあわせて、残りのバタフライ演算の処理を行う。 出力は入力と同じく(実数)+(虚数)の組み合わせになるよう入れ替えを行う。
出力outをDMA転送を用いてPPEに返す。SPE1も処理を終了する。
出力をPPE側で表示させ、全ての処理を終了する。
本方式を用いて作成したSPEのプログラムはentry2-fft.cとspu-include.hとfft_1d.hからなる。 そして、entry2-fftをロードするPPEのプログラムはppu.cとppu-include.hからなる。
entry2-fft.cではSPE上で実際にFFTを行う関数を作成した。前半と後半で関数を分けて、main関数上で前半の処理結果の統合を行っている。 前半のFFTを行う関数ent_fft()ではビットを入れ替えながらバタフライ演算を行う。
entry2-fft.c:
/*インクルード*/
#include "spu-include.h"
#include "fft_1d.h"
/*変数宣言*/
static float src_spe[N*2] __attribute__((aligned(128)));
float dst_spe_re[N] __attribute__((aligned(128)));
float dst_spe_im[N] __attribute__((aligned(128)));
static fft_params_t fft_params __attribute__((aligned(128)));
float dst_spe[N*2] __attribute__((aligned(128)));
static float src_spe_re[N] __attribute__((aligned(128)));
static float src_spe_im[N] __attribute__((aligned(128)));
static float w[N/4] __attribute__((aligned(128)));
vector float *re;
vector float *im;
float tmp_re[N] __attribute__((aligned(128)));
float tmp_im[N] __attribute__((aligned(128)));
/*シグナル送信用配列*/
static volatile unsigned int signal[4] __attribute__ ((aligned (128)));
/*各SPEのシグナルレジスタへの実効アドレスを格納する配列
で、シグナル通知レジスタを使用するときに使用。*/
unsigned int ps_area_ptr[NUM_SPE];
/*シグナルの送信関数
int id: 送信先のSPE番号
int value: 送信する値
*/
void send_sig(int id, int value){
signal[3] = value;
mfc_sndsig(((char *) &signal[0]) + 12, ps_area_ptr[id], 31, 0, 0); /*送信先のSPEの実効アドレスを渡す*/
mfc_write_tag_mask(1<<31);
mfc_read_tag_status_all();
}
/*シグナルの受信関数*/
unsigned int recv_sig()
{
return spu_read_signal1(); /*受信するまで待機*/
}
/*前半の3回のバタフライ演算を行う関数。
vector float *re: 前半の処理が終わった時の実数のポインタ
vector float *im: 前半の処理が終わった時の虚数のポインタ
vector float *in: 入力。DMA転送でメインメモリから受け取る
int flag: SPE番号
*/
static __inline void ent_fft(vector float *re, vector float *im, vector float *in, int flag){
int i, j, k;
int stage, offset;
int i_rev;
int n, n_2, n_4, n_8, n_16, n_3_16;
int w_stride, w_2stride, w_3stride, w_4stride;
int stride, stride_2, stride_4, stride_3_4;
vector float *W0, *W1, *W2, *W3;
vector float *re0, *re1, *re2, *re3;
vector float *im0, *im1, *im2, *im3;
vector float *in0, *in1, *in2, *in3, *in4, *in5, *in6, *in7;
vector float *out0, *out1, *out2, *out3;
vector float tmp0, tmp1;
vector float w0_re, w0_im, w1_re, w1_im;
vector float w0, w1, w2, w3;
vector float src_lo0, src_lo1, src_lo2, src_lo3;
vector float src_hi0, src_hi1, src_hi2, src_hi3;
vector float dst_lo0, dst_lo1, dst_lo2, dst_lo3;
vector float dst_hi0, dst_hi1, dst_hi2, dst_hi3;
vector float out_re_lo0, out_re_lo1, out_re_lo2, out_re_lo3;
vector float out_im_lo0, out_im_lo1, out_im_lo2, out_im_lo3;
vector float out_re_hi0, out_re_hi1, out_re_hi2, out_re_hi3;
vector float out_im_hi0, out_im_hi1, out_im_hi2, out_im_hi3;
vector float re_lo0, re_lo1, re_lo2, re_lo3;
vector float im_lo0, im_lo1, im_lo2, im_lo3;
vector float re_hi0, re_hi1, re_hi2, re_hi3;
vector float im_hi0, im_hi1, im_hi2, im_hi3;
vector float pq_lo0, pq_lo1, pq_lo2, pq_lo3;
vector float pq_hi0, pq_hi1, pq_hi2, pq_hi3;
/*減算が必要な部分で掛ける*/
vector float ppmm = (vector float) { 1.0f, 1.0f, -1.0f, -1.0f};
vector float pmmp = (vector float) { 1.0f, -1.0f, -1.0f, 1.0f};
vector unsigned char reverse;
/*SIMDを使って変数を入れ替える時の並べ順*/
vector unsigned char shuf_lo = (vector unsigned char) {
0, 1, 2, 3, 4, 5, 6, 7,
16,17,18,19, 20,21,22,23};
vector unsigned char shuf_hi = (vector unsigned char) {
8, 9,10,11, 12,13,14,15,
24,25,26,27, 28,29,30,31};
vector unsigned char shuf_0202 = (vector unsigned char) {
0, 1, 2, 3, 8, 9,10,11,
0, 1, 2, 3, 8, 9,10,11};
vector unsigned char shuf_1313 = (vector unsigned char) {
4, 5, 6, 7, 12,13,14,15,
4, 5, 6, 7, 12,13,14,15};
vector unsigned char shuf_0303 = (vector unsigned char) {
0, 1, 2, 3, 12,13,14,15,
0, 1, 2, 3, 12,13,14,15};
vector unsigned char shuf_1212 = (vector unsigned char) {
4, 5, 6, 7, 8, 9,10,11,
4, 5, 6, 7, 8, 9,10,11};
vector unsigned char shuf_0415 = (vector unsigned char) {
0, 1, 2, 3, 16,17,18,19,
4, 5, 6, 7, 20,21,22,23};
vector unsigned char shuf_2637 = (vector unsigned char) {
8, 9,10,11, 24,25,26,27,
12,13,14,15,28,29,30,31};
vector unsigned char shuf_0246 = (vector unsigned char) {
0, 1, 2, 3, 8, 9,10,11,
16,17,18,19,24,25,26,27};
vector unsigned char shuf_1357 = (vector unsigned char) {
4, 5, 6, 7, 12,13,14,15,
20,21,22,23,28,29,30,31};
/*入力の個数から分割した時に移動する数*/
n = 1 << log2_size;
n_2 = n >> 1;
n_4 = n >> 2;
n_8 = n >> 3;
n_16 = n >> 4;
n_3_16 = n_8 + n_16;
/* ビット反転を行うパターンの生成*/
reverse = spu_or(spu_slqwbyte(spu_splats((unsigned char)0x80), log2_size),
spu_rlmaskqwbyte(((vec_uchar16){15,14,13,12, 11,10,9,8,
7, 6, 5, 4, 3, 2,1,0}),
log2_size-16));
i = 0;
i_rev = 0;
/*入力の実数の先頭アドレス*/
in0 = in;
in1 = in + n_8;
in2 = in + n_16;
in3 = in + n_3_16;
in4 = in + n_4;
in5 = in1 + n_4;
in6 = in2 + n_4;
in7 = in3 + n_4;
re0 = re;
re1 = re + n_8;
im0 = im;
im1 = im + n_8;
w0_re = (vector float) { 1.0f, INV_SQRT_2, 0.0f, -INV_SQRT_2};
w0_im = (vector float) { 0.0f, -INV_SQRT_2, -1.0f, -INV_SQRT_2};
/*SPE番号が1なら入力の後半のアドレスに移動する*/
if(flag ==1){
for(j = 0; j< 2; j++){
re0 += 2;
re1 += 2;
im0 += 2;
im1 += 2;
i += 8;
i_rev = BIT_SWAP(i, reverse) / 2;
}
j = 0;
}
/*logN回繰り返す*/
do {
/*計算用の変数に入力を割り当てる*/
src_lo0 = in0[i_rev];
src_lo1 = in1[i_rev];
src_lo2 = in2[i_rev];
src_lo3 = in3[i_rev];
src_hi0 = in4[i_rev];
src_hi1 = in5[i_rev];
src_hi2 = in6[i_rev];
src_hi3 = in7[i_rev];
/* 入れ替え*/
dst_lo0 = spu_shuffle(src_lo0, src_hi0, shuf_lo);
dst_hi0 = spu_shuffle(src_lo0, src_hi0, shuf_hi);
dst_lo1 = spu_shuffle(src_lo1, src_hi1, shuf_lo);
dst_hi1 = spu_shuffle(src_lo1, src_hi1, shuf_hi);
dst_lo2 = spu_shuffle(src_lo2, src_hi2, shuf_lo);
dst_hi2 = spu_shuffle(src_lo2, src_hi2, shuf_hi);
dst_lo3 = spu_shuffle(src_lo3, src_hi3, shuf_lo);
dst_hi3 = spu_shuffle(src_lo3, src_hi3, shuf_hi);
/*1回目のバタフライ演算*/
pq_lo0 = spu_madd(ppmm, dst_lo0, spu_rlqwbyte(dst_lo0, 8));
pq_hi0 = spu_madd(ppmm, dst_hi0, spu_rlqwbyte(dst_hi0, 8));
pq_lo1 = spu_madd(ppmm, dst_lo1, spu_rlqwbyte(dst_lo1, 8));
pq_hi1 = spu_madd(ppmm, dst_hi1, spu_rlqwbyte(dst_hi1, 8));
pq_lo2 = spu_madd(ppmm, dst_lo2, spu_rlqwbyte(dst_lo2, 8));
pq_hi2 = spu_madd(ppmm, dst_hi2, spu_rlqwbyte(dst_hi2, 8));
pq_lo3 = spu_madd(ppmm, dst_lo3, spu_rlqwbyte(dst_lo3, 8));
pq_hi3 = spu_madd(ppmm, dst_hi3, spu_rlqwbyte(dst_hi3, 8));
/* 2回目のバタフライ演算*/
re_lo0 = spu_madd(ppmm,
spu_shuffle(pq_lo1, pq_lo1, shuf_0303),
spu_shuffle(pq_lo0, pq_lo0, shuf_0202));
im_lo0 = spu_madd(pmmp,
spu_shuffle(pq_lo1, pq_lo1, shuf_1212),
spu_shuffle(pq_lo0, pq_lo0, shuf_1313));
re_lo1 = spu_madd(ppmm,
spu_shuffle(pq_lo3, pq_lo3, shuf_0303),
spu_shuffle(pq_lo2, pq_lo2, shuf_0202));
im_lo1 = spu_madd(pmmp,
spu_shuffle(pq_lo3, pq_lo3, shuf_1212),
spu_shuffle(pq_lo2, pq_lo2, shuf_1313));
re_hi0 = spu_madd(ppmm,
spu_shuffle(pq_hi1, pq_hi1, shuf_0303),
spu_shuffle(pq_hi0, pq_hi0, shuf_0202));
im_hi0 = spu_madd(pmmp,
spu_shuffle(pq_hi1, pq_hi1, shuf_1212),
spu_shuffle(pq_hi0, pq_hi0, shuf_1313));
re_hi1 = spu_madd(ppmm,
spu_shuffle(pq_hi3, pq_hi3, shuf_0303),
spu_shuffle(pq_hi2, pq_hi2, shuf_0202));
im_hi1 = spu_madd(pmmp,
spu_shuffle(pq_hi3, pq_hi3, shuf_1212),
spu_shuffle(pq_hi2, pq_hi2, shuf_1313));
/* 3回目のバタフライ演算*/
FFT_1D_BUTTERFLY(re0[0], im0[0], re0[1], im0[1], re_lo0, im_lo0, re_lo1, im_lo1, w0_re, w0_im);
FFT_1D_BUTTERFLY(re1[0], im1[0], re1[1], im1[1], re_hi0, im_hi0, re_hi1, im_hi1, w0_re, w0_im);
/*次の処理結果を入れられるようにアドレスの移動*/
re0 += 2;
re1 += 2;
im0 += 2;
im1 += 2;
i += 8;
i_rev = BIT_SWAP(i, reverse) / 2;
j++;
}while(j < 2);
}
/*後半のバタフライ演算を行う関数
vector float *re: 前半の処理結果の実数部
vector float *im: 前半の処理結果の虚数部
vector float *out: 出力。形式はinと同じ
vector float *W: W行列
*/
static __inline void sec_fft(vector float * re, vector float * im, vector float * out, vector float * W){
int i, j, k;
int stage, offset;
int i_rev;
int n, n_2, n_4, n_8, n_16, n_3_16;
int w_stride, w_2stride, w_3stride, w_4stride;
int stride, stride_2, stride_4, stride_3_4;
vector float *W0, *W1, *W2, *W3;
vector float *re0, *re1, *re2, *re3;
vector float *im0, *im1, *im2, *im3;
vector float *in0, *in1, *in2, *in3, *in4, *in5, *in6, *in7;
vector float *out0, *out1, *out2, *out3;
vector float tmp0, tmp1;
vector float w0_re, w0_im, w1_re, w1_im;
vector float w0, w1, w2, w3;
vector float src_lo0, src_lo1, src_lo2, src_lo3;
vector float src_hi0, src_hi1, src_hi2, src_hi3;
vector float dst_lo0, dst_lo1, dst_lo2, dst_lo3;
vector float dst_hi0, dst_hi1, dst_hi2, dst_hi3;
vector float out_re_lo0, out_re_lo1, out_re_lo2, out_re_lo3;
vector float out_im_lo0, out_im_lo1, out_im_lo2, out_im_lo3;
vector float out_re_hi0, out_re_hi1, out_re_hi2, out_re_hi3;
vector float out_im_hi0, out_im_hi1, out_im_hi2, out_im_hi3;
vector float re_lo0, re_lo1, re_lo2, re_lo3;
vector float im_lo0, im_lo1, im_lo2, im_lo3;
vector float re_hi0, re_hi1, re_hi2, re_hi3;
vector float im_hi0, im_hi1, im_hi2, im_hi3;
vector float pq_lo0, pq_lo1, pq_lo2, pq_lo3;
vector float pq_hi0, pq_hi1, pq_hi2, pq_hi3;
vector float ppmm = (vector float) { 1.0f, 1.0f, -1.0f, -1.0f};
vector float pmmp = (vector float) { 1.0f, -1.0f, -1.0f, 1.0f};
vector unsigned char reverse;
vector unsigned char shuf_lo = (vector unsigned char) {
0, 1, 2, 3, 4, 5, 6, 7,
16,17,18,19, 20,21,22,23};
vector unsigned char shuf_hi = (vector unsigned char) {
8, 9,10,11, 12,13,14,15,
24,25,26,27, 28,29,30,31};
vector unsigned char shuf_0202 = (vector unsigned char) {
0, 1, 2, 3, 8, 9,10,11,
0, 1, 2, 3, 8, 9,10,11};
vector unsigned char shuf_1313 = (vector unsigned char) {
4, 5, 6, 7, 12,13,14,15,
4, 5, 6, 7, 12,13,14,15};
vector unsigned char shuf_0303 = (vector unsigned char) {
0, 1, 2, 3, 12,13,14,15,
0, 1, 2, 3, 12,13,14,15};
vector unsigned char shuf_1212 = (vector unsigned char) {
4, 5, 6, 7, 8, 9,10,11,
4, 5, 6, 7, 8, 9,10,11};
vector unsigned char shuf_0415 = (vector unsigned char) {
0, 1, 2, 3, 16,17,18,19,
4, 5, 6, 7, 20,21,22,23};
vector unsigned char shuf_2637 = (vector unsigned char) {
8, 9,10,11, 24,25,26,27,
12,13,14,15,28,29,30,31};
vector unsigned char shuf_0246 = (vector unsigned char) {
0, 1, 2, 3, 8, 9,10,11,
16,17,18,19,24,25,26,27};
vector unsigned char shuf_1357 = (vector unsigned char) {
4, 5, 6, 7, 12,13,14,15,
20,21,22,23,28,29,30,31};
n = 1 << log2_size;
n_2 = n >> 1;
n_4 = n >> 2;
n_8 = n >> 3;
n_16 = n >> 4;
n_3_16 = n_8 + n_16;
/* 4回目のバタフライ演算。6回より多いバタフライ演算を行うときはこの部分を繰り返す*/
for (stage=4, stride=4; stage<log2_size-1; stage++, stride += stride) {
w_stride = n_2 >> stage;
w_2stride = n >> stage;
w_3stride = w_stride + w_2stride;
w_4stride = w_2stride + w_2stride;
W0 = W;
W1 = W + w_stride;
W2 = W + w_2stride;
W3 = W + w_3stride;
stride_2 = stride >> 1;
stride_4 = stride >> 2;
stride_3_4 = stride_2 + stride_4;
re0 = re; im0 = im;
re1 = re + stride_2; im1 = im + stride_2;
re2 = re + stride_4; im2 = im + stride_4;
re3 = re + stride_3_4; im3 = im + stride_3_4;
for (i=0, offset=0; i<stride_4; i++, offset += w_4stride) {
w0 = W0[offset];
w1 = W1[offset];
w2 = W2[offset];
w3 = W3[offset];
tmp0 = spu_shuffle(w0, w2, shuf_0415);
tmp1 = spu_shuffle(w1, w3, shuf_0415);
w0_re = spu_shuffle(tmp0, tmp1, shuf_0415);
w0_im = spu_shuffle(tmp0, tmp1, shuf_2637);
j = i;
k = i + stride;
do {
re_lo0 = re0[j]; im_lo0 = im0[j];
re_lo1 = re1[j]; im_lo1 = im1[j];
re_hi0 = re2[j]; im_hi0 = im2[j];
re_hi1 = re3[j]; im_hi1 = im3[j];
re_lo2 = re0[k]; im_lo2 = im0[k];
re_lo3 = re1[k]; im_lo3 = im1[k];
re_hi2 = re2[k]; im_hi2 = im2[k];
re_hi3 = re3[k]; im_hi3 = im3[k];
FFT_1D_BUTTERFLY (re0[j], im0[j], re1[j], im1[j], re_lo0, im_lo0, re_lo1, im_lo1, w0_re, w0_im);
FFT_1D_BUTTERFLY_HI(re2[j], im2[j], re3[j], im3[j], re_hi0, im_hi0, re_hi1, im_hi1, w0_re, w0_im);
FFT_1D_BUTTERFLY (re0[k], im0[k], re1[k], im1[k], re_lo2, im_lo2, re_lo3, im_lo3, w0_re, w0_im);
FFT_1D_BUTTERFLY_HI(re2[k], im2[k], re3[k], im3[k], re_hi2, im_hi2, re_hi3, im_hi3, w0_re, w0_im);
j += 2 * stride;
k += 2 * stride;
} while (j < n_4);
}
}
/* 5回目のバタフライ演算*/
w_stride = n_2 >> stage;
w_2stride = n >> stage;
w_3stride = w_stride + w_2stride;
w_4stride = w_2stride + w_2stride;
stride_2 = stride >> 1;
stride_4 = stride >> 2;
stride_3_4 = stride_2 + stride_4;
re0 = re; im0 = im;
re1 = re + stride_2; im1 = im + stride_2;
re2 = re + stride_4; im2 = im + stride_4;
re3 = re + stride_3_4; im3 = im + stride_3_4;
for (i=0, offset=0; i<stride_4; i++, offset += w_4stride) {
w0 = W[offset];
w1 = W[offset + w_stride];
w2 = W[offset + w_2stride];
w3 = W[offset + w_3stride];
tmp0 = spu_shuffle(w0, w2, shuf_0415);
tmp1 = spu_shuffle(w1, w3, shuf_0415);
w0_re = spu_shuffle(tmp0, tmp1, shuf_0415);
w0_im = spu_shuffle(tmp0, tmp1, shuf_2637);
j = i;
k = i + stride;
re_lo0 = re0[j]; im_lo0 = im0[j];
re_lo1 = re1[j]; im_lo1 = im1[j];
re_hi0 = re2[j]; im_hi0 = im2[j];
re_hi1 = re3[j]; im_hi1 = im3[j];
re_lo2 = re0[k]; im_lo2 = im0[k];
re_lo3 = re1[k]; im_lo3 = im1[k];
re_hi2 = re2[k]; im_hi2 = im2[k];
re_hi3 = re3[k]; im_hi3 = im3[k];
FFT_1D_BUTTERFLY (re0[j], im0[j], re1[j], im1[j], re_lo0, im_lo0, re_lo1, im_lo1, w0_re, w0_im);
FFT_1D_BUTTERFLY_HI(re2[j], im2[j], re3[j], im3[j], re_hi0, im_hi0, re_hi1, im_hi1, w0_re, w0_im);
FFT_1D_BUTTERFLY (re0[k], im0[k], re1[k], im1[k], re_lo2, im_lo2, re_lo3, im_lo3, w0_re, w0_im);
FFT_1D_BUTTERFLY_HI(re2[k], im2[k], re3[k], im3[k], re_hi2, im_hi2, re_hi3, im_hi3, w0_re, w0_im);
}
/*6回目のバタフライ演算。実数と虚数を組み合わせ、outに入れる*/
re0 = re;
re1 = re + n_8;
re2 = re + n_16;
re3 = re + n_3_16;
im0 = im;
im1 = im + n_8;
im2 = im + n_16;
im3 = im + n_3_16;
out0 = out;
out1 = out + n_4;
out2 = out + n_8;
out3 = out1 + n_8;
i = n_16;
do {
/* Fetch the twiddle factors
*/
w0 = W[0];
w1 = W[1];
w2 = W[2];
w3 = W[3];
W += 4;
w0_re = spu_shuffle(w0, w1, shuf_0246);
w0_im = spu_shuffle(w0, w1, shuf_1357);
w1_re = spu_shuffle(w2, w3, shuf_0246);
w1_im = spu_shuffle(w2, w3, shuf_1357);
/*バタフライ演算の入力を設定する*/
re_lo0 = re0[0]; im_lo0 = im0[0];
re_lo1 = re1[0]; im_lo1 = im1[0];
re_lo2 = re0[1]; im_lo2 = im0[1];
re_lo3 = re1[1]; im_lo3 = im1[1];
re_hi0 = re2[0]; im_hi0 = im2[0];
re_hi1 = re3[0]; im_hi1 = im3[0];
re_hi2 = re2[1]; im_hi2 = im2[1];
re_hi3 = re3[1]; im_hi3 = im3[1];
re0 += 2; im0 += 2;
re1 += 2; im1 += 2;
re2 += 2; im2 += 2;
re3 += 2; im3 += 2;
/* バタフライ演算*/
FFT_1D_BUTTERFLY (out_re_lo0, out_im_lo0, out_re_lo1, out_im_lo1, re_lo0, im_lo0, re_lo1, im_lo1, w0_re, w0_im);
FFT_1D_BUTTERFLY (out_re_lo2, out_im_lo2, out_re_lo3, out_im_lo3, re_lo2, im_lo2, re_lo3, im_lo3, w1_re, w1_im);
FFT_1D_BUTTERFLY_HI(out_re_hi0, out_im_hi0, out_re_hi1, out_im_hi1, re_hi0, im_hi0, re_hi1, im_hi1, w0_re, w0_im);
FFT_1D_BUTTERFLY_HI(out_re_hi2, out_im_hi2, out_re_hi3, out_im_hi3, re_hi2, im_hi2, re_hi3, im_hi3, w1_re, w1_im);
/*実数部と虚数部を組み合わせる*/
out0[0] = spu_shuffle(out_re_lo0, out_im_lo0, shuf_0415);
out0[1] = spu_shuffle(out_re_lo0, out_im_lo0, shuf_2637);
out0[2] = spu_shuffle(out_re_lo2, out_im_lo2, shuf_0415);
out0[3] = spu_shuffle(out_re_lo2, out_im_lo2, shuf_2637);
out1[0] = spu_shuffle(out_re_lo1, out_im_lo1, shuf_0415);
out1[1] = spu_shuffle(out_re_lo1, out_im_lo1, shuf_2637);
out1[2] = spu_shuffle(out_re_lo3, out_im_lo3, shuf_0415);
out1[3] = spu_shuffle(out_re_lo3, out_im_lo3, shuf_2637);
out2[0] = spu_shuffle(out_re_hi0, out_im_hi0, shuf_0415);
out2[1] = spu_shuffle(out_re_hi0, out_im_hi0, shuf_2637);
out2[2] = spu_shuffle(out_re_hi2, out_im_hi2, shuf_0415);
out2[3] = spu_shuffle(out_re_hi2, out_im_hi2, shuf_2637);
out3[0] = spu_shuffle(out_re_hi1, out_im_hi1, shuf_0415);
out3[1] = spu_shuffle(out_re_hi1, out_im_hi1, shuf_2637);
out3[2] = spu_shuffle(out_re_hi3, out_im_hi3, shuf_0415);
out3[3] = spu_shuffle(out_re_hi3, out_im_hi3, shuf_2637);
out0 += 4;
out1 += 4;
out2 += 4;
out3 += 4;
i -= 2;
} while (i);
}
/*メイン関数
unsigned long long spe: SPEコンテキストの実効アドレス
unsigned long long argp: DMA転送をする構造体のメインメモリのアドレス
unsigned long long envp: SPE番号
*/
int main(unsigned long long spe, unsigned long long argp, unsigned long long envp){
int tag = 1;
int i;
unsigned long long ea_src;
unsigned long long ea_src_re;
unsigned long long ea_src_im;
unsigned long long ea_dst_re;
unsigned long long ea_dst_im;
unsigned long long ea_dst;
unsigned long long ea_w;
unsigned int num;
/*入出力のポインタの入った構造体をDMA転送*/
spu_mfcdma64(&fft_params, mfc_ea2h(argp),mfc_ea2l(argp), sizeof(fft_params_t), tag, MFC_GET_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
ea_src = fft_params.ea_src;
ea_dst_re = fft_params.ea_dst_re;
ea_dst_im = fft_params.ea_dst_im;
num = fft_params.num;
/*入出力のDMA転送*/
spu_mfcdma64(src_spe, mfc_ea2h(ea_src), mfc_ea2l(ea_src), num *2*4 , tag, MFC_GET_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
/*各SPEのシグナルレジスタへのポインタをメールボックスで受信*/
for(i = 0; i < NUM_SPE; i++){
ps_area_ptr[i] = spu_read_in_mbox();
}
/*SPE番号が1*/
if(envp == 1){
ea_src_re = fft_params.ea_dst_re;
ea_src_im = fft_params.ea_dst_im;
ea_w = fft_params.ea_w;
ea_dst = fft_params.ea_out;
vector float* re_s = (vector float *)src_spe_re;
vector float* im_s = (vector float *)src_spe_im;
vector float* re_d = (vector float *)dst_spe_re;
vector float* im_d = (vector float *)dst_spe_im;
vector float* re = (vector float *)tmp_re;
vector float* im = (vector float *)tmp_im;
/*Wの転送命令 */
spu_mfcdma64(w, mfc_ea2h(ea_w), mfc_ea2l(ea_w), num * 4 , tag, MFC_GET_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
/*前半のバタフライ演算*/
ent_fft((vector float *) dst_spe_re, (vector float *) dst_spe_im, (vector float *) src_spe, (int) envp);
/*Wの転送が終わってなければ待機*/
spu_mfcstat(MFC_TAG_UPDATE_ALL);
/*シグナル受信*/
recv_sig();
/*SPE0の処理結果を受信*/
spu_mfcdma64(src_spe_re, mfc_ea2h(ea_src_re), mfc_ea2l(ea_src_re), num*4 , tag, MFC_GET_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
spu_mfcdma64(src_spe_im, mfc_ea2h(ea_src_im), mfc_ea2l(ea_src_im), num*4 , tag, MFC_GET_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
/*処理結果をあわせる*/
for(i = 0; i < N/4; i++){
re[i] = spu_or(re_s[i],re_d[i]);
im[i] = spu_or(im_s[i],im_d[i]);
}
/*後半のバタフライ演算*/
sec_fft(re, im, (vector float *) dst_spe, (vector float *) w);
/*出力*/
spu_mfcdma64(dst_spe, mfc_ea2h(ea_dst), mfc_ea2l(ea_dst), num *2 *4 , tag, MFC_PUT_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
/*SPE番号が0*/
}else{
/*前半のバタフライ演算*/
ent_fft((vector float *) dst_spe_re, (vector float *) dst_spe_im, (vector float *) src_spe, (int) envp);
/*処理結果をメインメモリにDMA転送*/
spu_mfcdma64(dst_spe_re, mfc_ea2h(ea_dst_re), mfc_ea2l(ea_dst_re), num*4 , tag, MFC_PUT_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
spu_mfcdma64(dst_spe_im, mfc_ea2h(ea_dst_im), mfc_ea2l(ea_dst_im), num*4 , tag, MFC_PUT_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
/*DMA転送が完了したらSPE1にシグナルを送信*/
send_sig(1, 0);
}
return 0;
}
ppu.cは最初に実行される。使用するSPEの数だけスレッドを生成し、スレッド上でSPEのプログラムを実行させる。 SPEのプログラムが実行されると処理が終了するまでPPEは待機してしまうので、SPE1のスレッドではSPEのプログラムを実行させる前にメールボックスを管理する子スレッドをたてる。 SPEの処理が全て終了したら処理結果を出力する。
ppu.c:
#include "ppu-include.h"
fft_params_t fft_params[NUM_SPE+1] __attribute__((aligned(128)));
float re[2][128] __attribute__((aligned(128)));
float im[2][128] __attribute__((aligned(128)));
spe_context_ptr_t spe[NUM_SPE];
/*子スレッド上で実行するスレッド関数
使用するSPEの実効アドレスを求め、SPEのメールボックスに送信する
*/
void *run_mbox(void *thread_arg){
int i, j;
spe_sig_notify_1_area_t *psig_area[NUM_SPE];
unsigned int sig_area[NUM_SPE];
thread_arg_t *arg = (thread_arg_t *) thread_arg;
/*各SPEのシグナルレジスタの実効アドレスを記録*/
for(i = 0; i < NUM_SPE; i++){
psig_area[i] = (spe_sig_notify_1_area_t*)spe_ps_area_get(spe[i], SPE_SIG_NOTIFY_1_AREA);
sig_area[i] = (unsigned int) (&(psig_area[i]->SPU_Sig_Notify_1));
}
/*全SPEに、メールボックスを通じて各SPEのシグナルレジスタのアドレスを通知*/
for(i = 0; i < NUM_SPE; i++){
for(j = 0; j < NUM_SPE; j++){
spe_in_mbox_write(spe[i], &sig_area[j], 1, SPE_MBOX_ALL_BLOCKING);
}
}
}
/*SPEを実行するスレッド関数
SPEコンテキストを走らせる前にメールボックスを管理するスレッドを生成
*/
void *run_fft_spe(void *thread_arg){
int ret;
thread_arg_t *arg = (thread_arg_t *) thread_arg;
unsigned int entry;
spe_stop_info_t stop_info;
pthread_t thread2;
/*SPE番号が1*/
if(arg->num == 1){
ret = pthread_create(&thread2, NULL, *run_mbox, arg);
entry = SPE_DEFAULT_ENTRY;
ret = spe_context_run(arg->spe, &entry, 0, arg->fft_params, arg->num, &stop_info);
if(ret < 0){
perror("spe_context_run");
return NULL;
}
pthread_join(thread2, NULL);
/*SPE番号が0*/
}else{
entry = SPE_DEFAULT_ENTRY;
ret = spe_context_run(arg->spe, &entry, 0, arg->fft_params, arg->num, &stop_info);
if(ret < 0){
perror("spe_context_run");
return NULL;
}
pthread_exit(NULL);
}
return NULL;
}
/*スレッドの数だけSPEコンテキスト生成する。
入力と出力の領域は確保されているのでDMA転送で渡せるように構造体にアドレスを渡す。
*/
void run_fft(float* out, float* in, float* W, int log){
spe_program_handle_t *prog, *prog2;
pthread_t pthread[NUM_SPE];
thread_arg_t arg[NUM_SPE];
int i, j, ret;
unsigned int entry;
spe_stop_info_t stop_info;
/*speプログラムのロード*/
prog = spe_image_open("entry2-fft.elf");
if(!prog){
perror("spe_image_open");
exit(1);
}
/*使用するSPEの数だけ繰り返し*/
for(i = 0; i < NUM_SPE; i++){
/*SPEコンテキストの生成*/
spe[i] = spe_context_create(SPE_MAP_PS, NULL);
if(!spe[i]){
perror("spe_context_create");
exit(1);
}
ret = spe_program_load(spe[i], prog);
if(ret){
perror("spe_program_load");
exit(1);
}
}
/*使用するSPEの数だけ繰り返し*/
for(i = 0, j = 0; i < NUM_SPE; i++, j += (N / NUM_SPE)){
/*入出力、Wのポインタを渡す*/
fft_params[i].ea_src = (unsigned long) in;
fft_params[i].ea_dst_re = (unsigned long) &re[1][0];
fft_params[i].ea_dst_im = (unsigned long) &im[1][0];
fft_params[i].num = (unsigned int) N;
fft_params[i].ea_w = (unsigned long) W;
fft_params[i].ea_out = (unsigned long) out;
arg[i].spe = spe[i];
arg[i].fft_params = &fft_params[i];
arg[i].num = i;
if(i == 1)
arg[i].spe1 = spe[0];
ret = pthread_create(&pthread[i], NULL, run_fft_spe, &arg[i]);
if(ret){
perror("pthread_create");
exit(1);
}
}
for(i = 0; i < NUM_SPE; i++){
/*同期*/
pthread_join(pthread[i], NULL);
ret = spe_context_destroy(spe[i]);
if(ret){
perror("spe_context_destroy");
exit(1);
}
}
for(i = 0; i < N * 2; i++){
re[0][i] += re[1][i];
im[0][i] += im[1][i];
}
ret = spe_image_close(prog);
if(ret){
perror("spe_image_close");
exit(1);
}
}
/*入力値を作成する。
Wの行列の値も作成。
出力を行う。
*/
int main(){
float in[2*N], out[2*N], W[N/2]
__attribute__ ((aligned (16)));
int i;
int j = 0;
/*入力値作成*/
for(i = 0; i < N/2; i += 2, j++){
in[i] = 1.0f;
in[i+1] = 0.0;
}
for(i = N/2; i < 2*N; i += 2){
in[i] = 0.0;
in[i+1] = 0.0;
}
/*W行列生成*/
for(i=0; i < N/2; i +=2){
W[i] = cos(((double)i * M_PI) / N);
W[i+1] = -sin(((double)i * M_PI) / N);
}
run_fft((float *)out, (float *)in, (float *)W, log2_size);
/*出力*/
for(i = 0; i < 2*N; i+=2){
printf("%f + %fi\n", out[i], out[i+1]);
}
return 0;
}
本研究ではIBM社のCellSDKに付属しているLibfftライブラリの中に含まれているインライン関数fft_1d_r2hを比較対象とする。
比較用のプログラムとして、一つのSPE上でfft_1d_r2h関数を呼び出し、SPE上で出力を行うSPEのプログラムとSPEのプログラムをロードするだけのPPEのプログラムを作成する(null.elf)。
既存のライブラリの関数を使用したプログラムと本方式を使用したプログラム(ppu.elf)の実行時間を測定し、比較を行う。
以下に使用環境を以下に述べる。
実験には別にPCを用意しTera Termを使用し、ネットワーク経由でSSHを用いてPS3にアクセスする。 SSHを介してコンパイル、実行を行う。 実行時間の測定には、Linuxに標準で実装されているtimeコマンドを用いて、その実時間を測定する。 誤差をなるべく少なくするため既存のライブラリを用いたプログラムと本方式を用いたプログラムを10回ずつ実行し、それらの実行時間の平均値を求めて比較をする。
10回の実行時間の平均時間を測定した結果改良を施した。 以下に実行結果のスクリーンショットを添付する。 これは、ppu.elfを実行した時のものである。
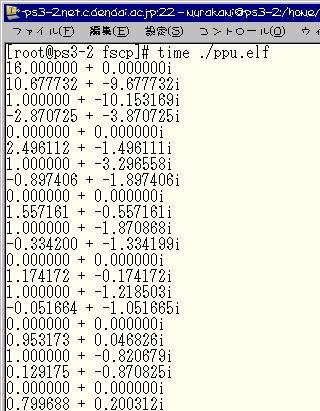
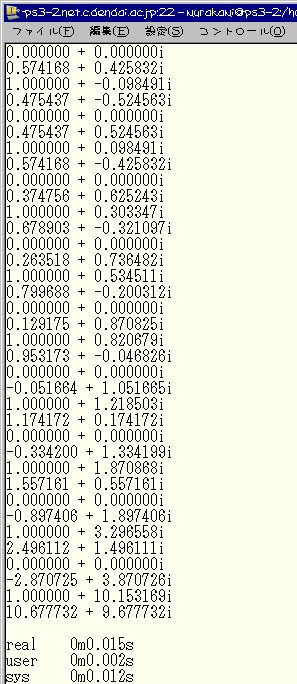
それぞれのプログラムの実行時間を以下の表にまとめる。
| n(回目) | 実行時間 | |||
| null.elf(s) | ppu.elf(s) | |||
| 1 | 0.014 | 0.012 | ||
| 2 | 0.016 | 0.013 | ||
| 3 | 0.018 | 0.013 | ||
| 4 | 0.014 | 0.013 | ||
| 5 | 0.016 | 0.013 | ||
| 6 | 0.014 | 0.013 | ||
| 7 | 0.017 | 0.017 | ||
| 8 | 0.019 | 0.020 | ||
| 9 | 0.014 | 0.015 | ||
| 10 | 0.026 | 0.016 | ||
| 平均 | 0.017 | 0.015 | ||
今回の実験では、ppu.elfの方がnull.elfと比べ、約12%の短縮を確認することに成功した。
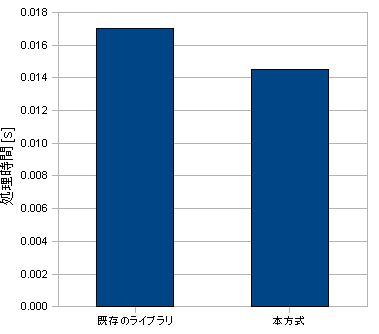
4.2で示した通り、平均時間を比較すると、改良前と改良後のプログラムでは改良後のプログラムの方が速度が上がることが確認できた。 1回ごとの比較では改良後のプログラムの方が時間がかかることもあったが、これは割り込みやスタックによるものと考えられ、誤差の範囲内である。
本研究のプログラムは、FFTの行程を前半と後半に分け、この前半部分を2つのSPEで処理を行った。 これは後半のバタフライ演算において、前半部分と後半部分の計算結果が必要であるためにそのように設計したが、後半部分を分割処理することができれば更なる速度の向上が期待できる。前半部分に関しても、SPEの数を2つで実験を行ったが、これを4つ6つと増やして行けば、こちらも速度の向上を見込めると思われる。但し、サンプリング数(入力)が少ない状態で分割数を増やした場合、DMA転送の転送量が増加し、転送に時間が取られる。分割する分多くのスレッドを立てる必要があるためPPEでの処理量が増加する、といった観点から単純に速度が向上するとは考えにくい。
この点について、DMA転送の転送時間とSPEの起動時間、及びFFTの処理時間についての追加実験を行った。
SPEの起動時間の実験についてはPPE上から複数のSPEを立ち上げ何も処理を行わずに終了するまでの時間をtimeコマンドを用いて計測する。10回実行してその平均値をとる。実験結果を以下の表にまとめる。
以下にSPEの起動時間の実験結果を示す。
| n(回目) | 起動時間(s)(SPE×1) | 起動時間(s)(SPE×2) |
| 1 | 0.008 | 0.008 |
| 2 | 0.008 | 0.008 |
| 3 | 0.008 | 0.008 |
| 4 | 0.008 | 0.008 |
| 5 | 0.008 | 0.008 |
| 6 | 0.008 | 0.008 |
| 7 | 0.008 | 0.008 |
| 8 | 0.008 | 0.008 |
| 9 | 0.008 | 0.008 |
| 10 | 0.008 | 0.008 |
| 平均 | 0.008 | 0.008 |
SPEの起動実験ではSPEを1つでも複数起動した場合でもかかる時間は変化は認められなかった。
転送時間の実験についてはそれぞれ、4.2で使用したppu.elfに入力データinを転送する時間をSPU Decrementerを用いて時間を計測する。SPU Decrementer は 32 bit 幅の値を保持し、名前の通り、その値をある一定の周期で 1 ずつ減らしていく。SPU Decrementer を用いると、SPE プログラム中の処理を局所的に時間計測できるために、PPE 上での処理時間計測手法よりも詳細に SPE プログラムの処理時間を調べることができる。
転送実験と同時にFFTの処理時間の計測も行う。測定にはSPU Decrementerを用いる。前半のバタフライ演算と後半のバタフライ演算を足した値を処理時間とする。前半と後半の間のDMA転送などの時間は含まない。以下にそれぞれの時間をまとめる。
| n(回目) | 転送時間 | FFTの処理時間(SPE×2) |
| 1 | 0.00165 | 0.000165 |
| 2 | 0.00180 | 0.000164 |
| 3 | 0.00165 | 0.000165 |
| 4 | 0.00185 | 0.000164 |
| 5 | 0.00185 | 0.000164 |
| 6 | 0.00181 | 0.000164 |
| 7 | 0.00179 | 0.000164 |
| 8 | 0.00179 | 0.000164 |
| 9 | 0.00180 | 0.000165 |
| 10 | 0.00179 | 0.000164 |
| 平均 | 0.00178 | 0.000164 |
FFTの処理時間は、DMA転送の処理時間の10分の1程度の時間という結果になった。しかしながら、転送時間もFFTの処理時間も値が小さいので、通信遅延などの誤差が考えられ、正確な値であるとは言い切れない。 したがって、別の方法での検討を考える必要があると思われる。
本研究では、libfft内の関数fft_1d_r2()と同じようなFFTを計算する関数として、2個のSPEを使用するプログラムを作成し、その性能評価を行った。
作成したプログラムは既存のライブラリの関数に比べて処理時間が12%短縮することに成功した。これより、複数のSPEでFFTを実行することはプログラム全体の速度向上につながるということが確認できた。
SPEの数を増やした場合に効率が上がるかということと、今回はデータを2分割したが他に最適化の手段がないか検討することが今後の課題である。
それぞれ実験で使用したプログラムのソースコードを添付する。以下にファイル名と利用目的を示す。
ppu-include.h:
#ifndef __PPU_INCLUDE__
#define __PPU_INCLUDE__
#include<stdio.h>
#include<stdlib.h>
#include<libspe2.h>
#include<pthread.h>
#include<math.h>
#include<malloc.h>
#define NUM_SPE 2
#define PI 3.14159265358979323846
#define N 64
#define log2_size 6
typedef struct{
unsigned long long ea_src; /*speに渡すポインタ*/
unsigned long long ea_dst_re; /*speから帰るポインタ*/;
unsigned long long ea_dst_im; /*ent用*/
unsigned long long ea_out;
unsigned long long ea_w;
unsigned int num;
int pad[1]; /*16の倍数に揃える*/
} fft_params_t;
typedef struct{
spe_context_ptr_t spe;
fft_params_t *fft_params;
int num;
spe_context_ptr_t spe1;
} thread_arg_t;
void *run_fft_spe(void *thread_arg_t);
void run_fft(float*, float*, float*, int);
#endif
spu-include.h:
#ifndef __SPU_INCLUDE__
#define __SPU_INCLUDE__
#include<stdio.h>
#include<spu_intrinsics.h>
#include<spu_mfcio.h>
#include<math.h>
#include<simdmath.h>
#define MAX_BUFSIZE ((16 << 10) / 4)
#define PI 3.14159265358979323846
#define N 64
#define log2_size 6
#define NUM_SPE 2
#define SPU_DECREMENTER_INITIAL_VALUE 0x7FFFFFFFU
typedef struct{
unsigned long long ea_src; /*speに渡すポインタ*/
unsigned long long ea_dst_re; /*speから帰るポインタ*/;
unsigned long long ea_dst_im; /*ent用*/
unsigned long long ea_out;
unsigned long long ea_w;
unsigned int num;
int pad[1]; /*16の倍数に揃える*/
} fft_params_t;
#endif
null.c:
#include<stdio.h>
#include<libspe2.h>
int main(int argc, char **argv)
{
int ret;
spe_context_ptr_t spe;
spe_program_handle_t *prog;
unsigned int entry;
spe_stop_info_t stop_info;
prog = spe_image_open("null-spu.elf");
if (!prog) {
perror("spe_image_open");
exit(1);
}
spe = spe_context_create(0, NULL);
if (!spe) {
perror("spe_context_create");
exit(1);
}
ret = spe_program_load(spe, prog);
if (ret) {
perror("spe_program_load");
exit(1);
}
entry = SPE_DEFAULT_ENTRY;
ret = spe_context_run(spe, &entry, 0, NULL, NULL, &stop_info);
if (ret < 0) {
perror("spe_context_run");
exit(1);
}
ret = spe_context_destroy(spe);
if (ret) {
perror("spe_context_destroy");
exit(1);
}
ret = spe_image_close(prog);
if (ret) {
perror("spe_image_close");
exit(1);
}
return 0;
}
null-spu.c:
#include "spu-include.h"
static float src_spe[N*2] __attribute__((aligned(128)));
static fft_params_t fft_params __attribute__((aligned(128)));
int main(unsigned long long spe, unsigned long long argp, unsigned long long envp){
return 0;
}
entry2-fft_t(但しmain関数のみ):
int main(unsigned long long spe, unsigned long long argp, unsigned long long envp){
int tag = 1;
int i;
unsigned long long ea_src;
unsigned long long ea_src_re;
unsigned long long ea_src_im;
unsigned long long ea_dst_re;
unsigned long long ea_dst_im;
unsigned long long ea_dst;
unsigned long long ea_w;
unsigned int num;
uint32_t t,s;
spu_write_decrementer(0xffffffff/*SPU_DECREMENTER_INITIAL_VALUE*/);
/*unsigned int profile = spu_readch(SPU_ReDec);
*/
t = spu_read_decrementer();
spu_mfcdma64(&fft_params, mfc_ea2h(argp),mfc_ea2l(argp), sizeof(fft_params_t), tag, MFC_GET_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
ea_src = fft_params.ea_src;
ea_dst_re = fft_params.ea_dst_re;
ea_dst_im = fft_params.ea_dst_im;
num = fft_params.num;
spu_mfcdma64(src_spe, mfc_ea2h(ea_src), mfc_ea2l(ea_src), num *2*4 , tag, MFC_GET_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
t -= spu_read_decrementer();
/*各SPEのシグナルレジスタへのポインタをメールボックスで受信*/
for(i = 0; i < NUM_SPE; i++){
ps_area_ptr[i] = spu_read_in_mbox();
}
if(envp == 1){
ea_src_re = fft_params.ea_dst_re;
ea_src_im = fft_params.ea_dst_im;
ea_w = fft_params.ea_w;
ea_dst = fft_params.ea_out;
vector float* re_s = (vector float *)src_spe_re;
vector float* im_s = (vector float *)src_spe_im;
vector float* re_d = (vector float *)dst_spe_re;
vector float* im_d = (vector float *)dst_spe_im;
vector float* re = (vector float *)tmp_re;
vector float* im = (vector float *)tmp_im;
/*wの転送命令 */
spu_mfcdma64(w, mfc_ea2h(ea_w), mfc_ea2l(ea_w), num * 4 , tag, MFC_GET_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
t = spu_read_decrementer();
ent_fft((vector float *) dst_spe_re, (vector float *) dst_spe_im, (vector float *) src_spe, (int) envp);
t -= spu_read_decrementer();
spu_mfcstat(MFC_TAG_UPDATE_ALL);
recv_sig();
spu_mfcdma64(src_spe_re, mfc_ea2h(ea_src_re), mfc_ea2l(ea_src_re), num*4 , tag, MFC_GET_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
spu_mfcdma64(src_spe_im, mfc_ea2h(ea_src_im), mfc_ea2l(ea_src_im), num*4 , tag, MFC_GET_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
for(i = 0; i < N/4; i++){
re[i] = spu_or(re_s[i],re_d[i]);
im[i] = spu_or(im_s[i],im_d[i]);
}
s = spu_read_decrementer();
sec_fft(re, im, (vector float *) dst_spe, (vector float *) w);
s -= spu_read_decrementer();
/*出力*/
spu_mfcdma64(dst_spe, mfc_ea2h(ea_dst), mfc_ea2l(ea_dst), num *2 *4 , tag, MFC_PUT_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
printf("SPE time_fft : %f\n", (t+s) / 2000000000.0f * 1000.0f);
}else{
ent_fft((vector float *) dst_spe_re, (vector float *) dst_spe_im, (vector float *) src_spe, (int) envp);
spu_mfcdma64(dst_spe_re, mfc_ea2h(ea_dst_re), mfc_ea2l(ea_dst_re), num*4 , tag, MFC_PUT_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
spu_mfcdma64(dst_spe_im, mfc_ea2h(ea_dst_im), mfc_ea2l(ea_dst_im), num*4 , tag, MFC_PUT_CMD);
spu_writech(MFC_WrTagMask, 1 << tag);
spu_mfcstat(MFC_TAG_UPDATE_ALL);
send_sig(1, 0);
printf("SPE time : %f\n", t / 2000000000.0f * 1000.0f);
}
return 0;
}