
03KC095 牧野 裕之
指導教員 坂本 直志
XML 1.0[1]が1998年にW3Cから勧告されてから、BtoC、BtoBを主に徐々に利用が高まってきた。XMLが広く普及し、様々なデータがXML形式で記述されるようになっている。また、普及に伴い、より大きなサイズのXML文書が生成・利用されるようになっている。また、それらのXML文書をHTMLに変換し閲覧することの需要も高まっている。
XMLは可読性、拡張性に優れているマークアップ言語である。タグによって表現されたノード間に包含関係があり、木構造とみなすことができる。これを利用してノードの位置関係を特定するXPointer[2]、元のXML文書から新たなXML文書やHTMLを生成するXSLT[3]、XPointerとXSLTの両者の共通機能を抜き出したXPath[4]など、多くの関連技術が実装されている。ただし、XMLはしばしば冗長であることが難点として挙げられる。包含関係を作り出すのに必ずタグを用いなければならず、文書中に頻出するタグが文書サイズを大きくしてしまうことが問題となることがしばしばある。
また、各ベンダーのブラウザの仕様により、表示の安定のために本来は表の作成に使用されるべきtable・tr・td要素が、レイアウトの設計に用いられるという傾向が存在する。そのため、table・tr・td要素を多く含む冗長なHTML[5]文書が多く存在している。
そこで本論文では、XML文書を保存する際に冗長な要素を復元性を保ったまま排除することで、XML・XHTML[5]文書の冗長性を低減する手法を提案する。さらに、提案手法を利用してXSLTを用いたXHTML文書の作成支援方式の一例を提示する。
本論文を読み進めるためには、XMLとXSLTについて知る必要がある。本稿で、XMLは圧縮の対象となるドキュメントの形式であり、XSLTはドキュメントの圧縮および復元に用いる。
XML(eXtensible Markup Language)とは、データの意味または構造を記述するためのマークアップ言語の一つである。テキストファイルにおいて < と > の2つの記号により、要素を次のように書く。
<html lang="ja">
<head>
<title>Sample</title>
</head>
<body>
<p>Example</p>
</body>
</html> |
図1 他の要素を含む要素例
図2 要素の包含関係
このうち、<要素名 ...>を開始タグ、</要素名>を終了タグと呼ぶ。タグは必ず閉じなければならず、また要素の内容に他の要素を含むことができる(図.1)ので、要素間に自然な包含関係が生じる (図.2)。そのため、要素をノード、包含関係をノード間の接続とみなすと、図3のような木構造のグラフができる。。
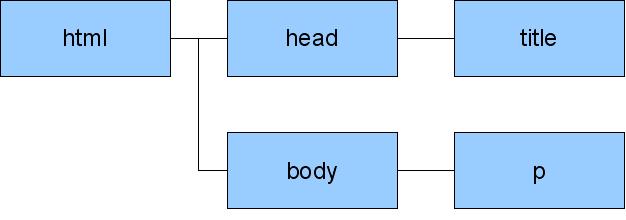
図3 木構造グラフ
上記のルールから、タグを論理的に記述することができるため、可読性の高い文章を作成することができる。通常のデータ構造は木構造により十分表現できるので、出版データ、Eビジネス向け電子データ、設定データ等の文書として、他のアプリケーションから幅広く利用されている。また、Webアプリケーションから用いることが容易である。これは、HTMLの処理とXMLの処理の共通部分が多いので、XML文書をプログラムやスクリプトで処理するためのAPI[6]が開発されているためである。また、各ベンダーのブラウザに対応しており、エンドユーザからも利用しやすい形式である。
XML文書は実体という記憶単位から成る。実体は構文解析されるデータ、または構文解析されないデータの二つに分けられる。構文解析されるデータは文字列から構成される。文字列はさらに文字データとマークアップの二つに分けられる。マークアップは,文書の記憶レイアウトおよび論理構造を記述する符号のことを指す。このマークアップを処理するために、XMLパーサと呼ばれるXML文書の構文解析プログラムを用いる。
しかし、XMLにも欠点がある。タグの利用のため、テキストのみの場合に比べて文書サイズが肥大化してしまうということが問題である。この問題の対応策として、様々な圧縮技術が提唱されている。それらの圧縮技術は圧縮率に着目し、優れた圧縮率を得ている。ただし、通常の圧縮では圧縮をかけたままでの処理ができないのが普通である。そのため、本研究では圧縮した文書も可読であるものを考えた。そのために、XSLTを応用し、XMLをXMLのまま圧縮することにより可読性の高い圧縮方式を提案する。
Webサイト等で記述されているHTMLはSGMLのアプリケーションである。つまりHTMLは、SGMLのルールに基づいて、要素や文法が定められている。SGMLの歴史は古く、そのため、純粋な機械処理を目標としておらず、冗長な表現などを省略できるので、人間も記述しやすいルールになっている。しかし、省略可能というルールは機械処理において多大な計算量を必要とする。そのため、省略可能というのを認めないようにルールを絞ったのがXMLになっている。
このXMLに基づいて要素や文法をHTMLとなるべく互換性があるように定められたのがXHTMLである。XHTMLは多くのブラウザが対応している。HTMLに対してXHTMLはXMLパーサにそのままかけることができるので、数多くのXMLアプリケーションがそのまま利用できるメリットがある。
XSLT(XML StyleSheet Language Transformation)は、XMLによって記述された文書を他のXML文書に変換するための言語である。文書の構造を別の形式に変形するための変換ルールを記述するもので、記述されたXSLT文書は「スタイルシート」と呼ばれる。本来はXSLの一部として変換処理を行なうために開発されたが、単独で使用することも可能である。おもに、XML文書からHTML文書やテキスト文書への変換などに使用される。
XSLTの規則に則って記述された文書をXSLTスタイルシートと呼ぶ。なお、XSLTスタイルシートはXMLの規則にしたがっているため、XML文書である。なお、XSLTによる変換を実行するためのソフトを「XSLTプロセッサ」と呼ぶ。ブラウザで最も大きなシェアを持つInternet Explorer(以下IE)もXSLTを解釈できるため「XSLTプロセッサ」である(厳密に言えば、IE6.0 SP1にmsxml3.0 SP3というXMLプロセッサがインストールされている。最新のmsxmlのバージョンは6.0)。
XSLTの主な特徴として以下が挙げられる。
次に変換原理を説明する。基本的な変換処理はパターン・マッチングにより行われる。入力が特定の条件を満たしたときに処理が行われるという形式を取るテンプレートで構成される。テンプレートの順序は重要でない。複数のテンプレートが同じ入力に一致する場合は、競合解決アルゴリズムが適用される。競合解決アルゴリズムとは、あらかじめ決められた優先順位に従って、適用対象が重複したテンプレートのうちで、どのテンプレートを使用するかを決定するものである。ただし、XSLTは、入力が1行ずつ順番に処理されないという点で、逐次形式のプログラム言語と異なっている。入力XML文書はツリー構造として扱われ、各テンプレート規則はツリー内のノードに適用される。次に処理するノードはテンプレート規則自体が決定できるため、入力は必ずしも元の文書における順序ではスキャンされない。
XSLTでは、XML文書の木構造から、別の木構造に一度変換する。変換後の木構造は、結果ツリーと呼ばれる。結果ツリーにスタイル情報や要素・属性を新たに付加することで、ユーザが望む出力が得られる。図4に変換例を示す。XSLTによるXML文書中のノードの指定には、XPathを用いる。
XPathは、XML文書の特定の部分を指し示す構文を規定する。XPathを利用すれば、XML文書中にアンカーなどが埋め込まれていなくとも、ソースツリー中の任意の位置を指し示すことができる。Xpathは、XPointerとXSLTの両者の共通機能部分を取り出して標準仕様としてまとめたものである。 後述のXSLTスタイルシート中で、XPathで定められるパス形式の構文に従って記述されたexpressionと呼ばれる式を条件分岐に用いている。
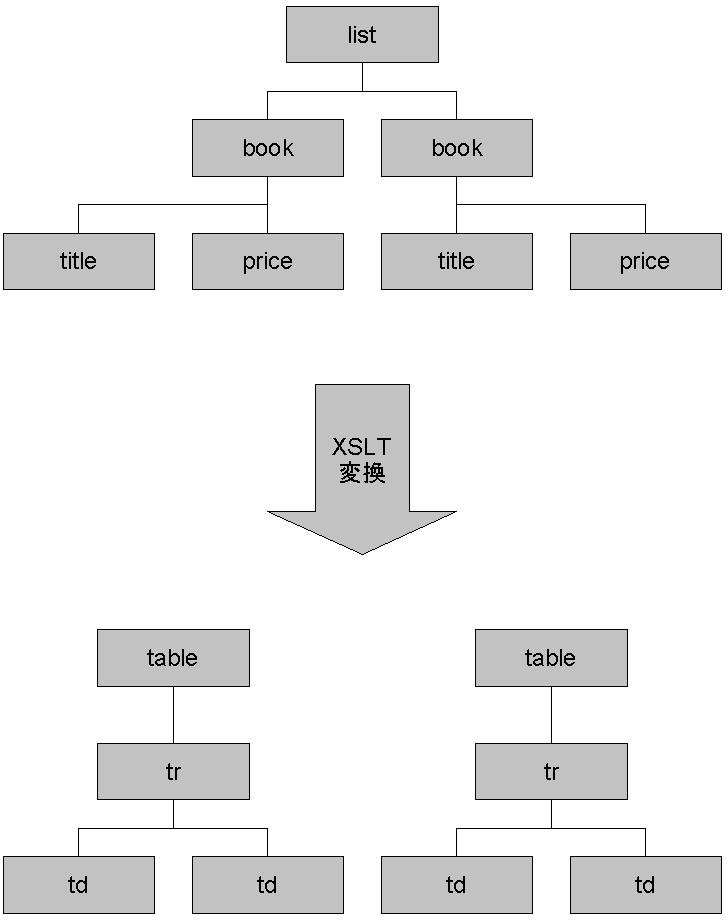
図4 XSLTによる木構造の変化
本論文では、XML文書を圧縮されたXML文書に変換する方式を提案しているので、これらの圧縮方式とは異なるが、参考として挙げる。
XMill[7]は、XML文書を外形が似ている文字列を複数に分割し、分割した文字列集合を異なる圧縮方式で圧縮した後に統合する圧縮技術である。XMillはまず初めにSAXパーサによりXML文書をパースし、同じような構造を持つ文字列集合を作る。その後に、それぞれの集合に適した圧縮をかけた上でgzipをかけることで、本来のXML文書に対してgzipをかけるよりもより高い圧縮率を得られるという利点がある。ただし、XMillには20,000バイト以上のデータに限り効果的に圧縮できるという制限と、加算処理をサポートしていないという制限がある。
XMLZIP[8]は、W3Cの定義したDOMに基づいたXML文書の圧縮・復元技術である。Javaで記述され、出力としてpkzip/Winzipファイルを生成する。XMLZIPはまずDOMパーサでXML文書をパースして基底ツリーを生成する。その後、基底ツリーを深さdのルートコンポーネントと深さdのサブツリー用のコンポーネントに分割する。各サブツリーはJavaのZIP-DEFLATEアーカイブライブラリを使って圧縮される。このスキームの利点は、メインメモリ中にツリー全体を保持することなく、文書の一部に対する制限つきのランダムアクセスを許可していることである。
XMLPPM[9]は、XML文書を圧縮するXML文書を圧縮プログラムである。 Prediction by Partial Matching(PPM)とMultiplexed Hierarchical Modeling(MHM)の組み合わせて処理を行う。PPMとは、既出のデータから次の文字を予測して、確率を変化させることにより圧縮するものである。MHMは、XMLの文法構造に基づいたいくつかのテキスト圧縮モデルを多重化することと、多重化されたモデルに階層情報を付加することを組み合わせた圧縮技術である。
Millau[10]はバイナリXML圧縮方式として設計された。XML文書のサイズを減らすため、圧縮はWAPによるバイナリXMLフォーマットに基づいている。MillauはXMLスキーマ中の構造とデータタイプの情報を利用することで圧縮性能を発揮する。Millauフォーマットは空白を文字列ではなく、トークンとしてタグと要素の表現することによって保存している。フォーマットの処理向けのパーサは、パフォーマンス向上のために文字列の代わりにトークンを採用した拡張バイナリSAX・DOM APIを含んだ、Millauストリームを処理するのに適応したDOMとSAXを用いて実装されている。このアプローチには算術処理の拡張が容易であるという利点がある。
XSLTスタイルシートの適用により任意の冗長な要素の数を減らすことで、対象のXHTML(XML)文書のファイルサイズを低減させる、すなわち圧縮する。ただし、復元に必要な情報は保持する。
可逆変換が可能なまま要素タグを減らす。本誌では空のtd要素を減らすことを考える。XSLTスタイルシートで空のtd要素以外の全てのノードを結果ツリーにコピーする。復元に必要な情報として、tr要素と空でないtd要素のそれぞれに属性n,pを追加する。属性nはtr要素が持つtd要素の個数、属性pはtr要素内におけるtd要素の位置情報を持つ。
対象のXHTML文書は、table、tr、td要素で構成されている。td要素がツリーの深度に関係なく除かれることを確かめるために、table要素の1つが入れ子構造になっている。
圧縮プログラムと圧縮対象文書を渡されれたXSLTプロセッサは、圧縮対象となるXHTML文書の検索を先頭から行い、XSLTスタイルシートに記述されたマッチング条件式と照らし合わせる。マッチングする要素が検索された場合、XSLTスタイルシートのテンプレートによる処理が行われる。
その後、ソースツリーに含まれる各要素と属性を順次コピーしていく。ただし、次の4つの点を満たす要素、はコピーの対象から外れる。なお、この条件を満たす要素は、空のtd要素である。
以上の条件にマッチしないノードは、そのまま処理を続ける。tr要素にマッチした場合、属性nを追加する。nの値は、tr要素に内包されるtd要素の個数とする。 また、td要素にマッチした場合、td要素に属性pを追加する。pの値はマッチしたtd要素の親であるtr要素の中で何番目のtd要素であるかを示す値である。 処理が完了した後、テンプレートnode()が再帰的に呼び出される。この再帰的処理を行うことで、ソースツリー中のすべてのノードに対して処理を行うことができる。 マッチングは全ノードに対する処理が完了した後終了する。
圧縮プログラムのソースコードを巻末の付録1に示す。以降では、ソースコードを一部ずつ取り上げ、適時解説していく。
<xsl:template match="node()"> |
本プログラムのテンプレートは、実質これのみである。パターンとしてnode()を指定している。node()は全ノードにマッチすることを表している。これは、XSLTを適用するXHTML文書はすべてノードで構成されているためである。
<xsl:if test="not((name()='td') and (count(descendant::*)='0') and not(text()) and (count(@*)='0'))"> |
ここで、上記のexpressionによる条件式を含めることにより、空のtd要素が結果ツリーにコピーされないように処理を行うことができる。
<xsl:when test="name()='tr'">
<xsl:attribute name="n">
<xsl:value-of select="count(child::*[name()='td'])"/>
</xsl:attribute>
</xsl:when>
<xsl:when test="name()='td'">
<xsl:attribute name="p">
<xsl:value-of select="count(preceding-sibling::*[name() = name(current())]) + 1"/>
</xsl:attribute>
</xsl:when> |
tr要素を示すノードにマッチするxsl:when文が記述されている。マッチした場合には、tr要素に属性nを付与する。nの値は、空のtd要素を含めたすべてのtd要素の個数となる。 また、td要素を示すノードにマッチするxsl:when文が続けて記述されている。マッチした場合には、td要素に属性pを付与する。pの値は、カレントノードであるtd要素の兄弟の中における位置となる。
<xsl:apply-templates/> |
そして終了タグが記述され、このテンプレートの処理が終了する。再帰的にnode()をパターンとするテンプレートが適用されるため、ソースツリー中の全てのノードとマッチする。
ここで、圧縮の一例を紹介する。図5のようなXHTML文書を圧縮する。
<?xml version="1.0"?>
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja">
<head>
<title> Element Compressing</title>
</head>
<body>
<h1> Element Compressing</h1>
<table border="">
<tr>
<td>2</td>
<td></td>
<td>x</td>
</tr>
<tr>
<td><a>1</a></td>
<td>2<table border=””>
<tr><td>2</td><td/><td>5</td></tr>
</table></td>
</tr>
</table>
</body>
</html> |
図5 圧縮対象XHTML文書
図5をXHTML文書としてレンダリングしたものを図6に示す。

図6 圧縮対象のXHTML文書のレンダリング
圧縮結果を図7(P.14)に示す。
<?xml version="1.0" encoding="UTF-8"?><html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja">
<head>
<title>Element Compressing</title>
</head>
<body>
<h1>Element Compressing</h1>
<table border="">
<tr n="3">
<td p="1">2</td>
<td p="3">x</td>
</tr>
<tr n="5">
<td p="1"><a>1</a></td>
<td p="2">2<table border=””>
<tr n="3"><td p="1">2</td><td p="3">5</td></tr>
</table></td>
</tr>
</table>
</body>
</html> |
図7 圧縮後のXML文書
図5と見比べると、圧縮が正常に機能していることが確認できる。 また、圧縮後の文書をXHTMLとしてレンダリングし図8に示す。

図8 圧縮後のXHTML文書のレンダリング
復元プログラムでは、先の圧縮プログラムで付加した属性n,pを使ってtd要素の位置とtd要素の生成個数を決定し生成することで、元のXHTML文書に復元する。 復元機能のコードを付録2に示す。以降、コードの解説を行っていく。
<xsl:template match="node()">
<xsl:copy>
<xsl:copy-of select="@*"/>
<xsl:apply-templates select="node()"/>
</xsl:copy>
</xsl:template> |
これは、node()をマッチ条件に指定しているテンプレートである。node()はあらゆるノードとマッチする。そのため、xsl:apply-templatesで再帰的にカレントノードの子をnode()でマッチングさせることで、ソースツリー中のすべてのノードに適用させることができる。これは復元対象ファイルのノードを全て結果ツリーにコピーするために必要である。
<xsl:template match="*[name()='tr']">
<xsl:copy>
<xsl:copy-of select="@*[not(name()='n')]"/>
<xsl:call-template name="decode">
<xsl:with-param name="count" select="1"/>
<xsl:with-param name="var" select="@n"/>
</xsl:call-template>
</xsl:copy>
</xsl:template> |
メソッドname()でtrを返すノード、すなわちtr要素全てにマッチするテンプレートである。マッチしたtr要素の属性nが除かれる。名前を指定してテンプレートdecodeを呼び出す。そのため、カレントノードはtr要素のままである。
<xsl:call-template name="decode">
<xsl:with-param name="count" select="1"/>
<xsl:with-param name="var" select="@n"/>
</xsl:call-template>
|
この部分で、テンプレートdecodeを呼び出している。呼び指す際に、変数countの値を1、varの値をtr要素の属性nの値で初期化している。
<xsl:template match="*[name()='td']">
<xsl:copy>
<xsl:copy-of select="@*[not(name()='p')]"/>
<xsl:apply-templates/>
</xsl:copy>
</xsl:template> |
td要素を示すノードとマッチするテンプレートである。td要素の属性pを除いて結果ツリーにコピーされる。圧縮も復元も、基本は再帰的処理ですべてのノードを結果ツリーへコピーしていく。その間にtr要素とtd要素を特定のexpressionを含む条件式でマッチさせ、異なる処理を行うという方針を採っている。復元機能を適用した出力を図9に示す。
<?xml version="1.0" encoding="UTF-8"?><html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja" lang="ja">
<head>
<title>Table Compressing</title>
</head>
<body>
<h1>Table Compressing</h1>
<table border="">
<tr><td>2</td><td/><td>x</td></tr>
<tr><td><a>1</a></td><td>2<table>
<tr><td>2</td><td/><td>5</td></tr>
</table></td><td/><td>4<table>
<tr><td/><td/><td>2</td></tr>
</table></td><td>5</td></tr>
</table>
</body>
</html>
|
図9 復元したXHTML文書
復元機能ソースコードのxsl:outputの属性indentをnoにすることでインデントを除いたが、元のXML文書と等価なXHTML文書が得られていることが確認できる。
Saxon-B 8.8
今回、実験の対象としてtable・tr・td要素による次のような構成を考案する。 1個のtable要素中にN個のtr要素が存在する 各tr要素中にN個のtd要素が存在する 全てのtd要素のうちPが任意の要素を持ち、残り半分が空要素である 空白、改行が無い。したがって、空白圧縮は行われない。
図10に例を示す。
<table border=””> <tr><td>*</td><td></td><td></td><td></td></tr> <tr><td></td><td>*</td><td>*</td><td>*</td></tr> <tr><td></td><td></td><td></td><td>*</td></tr> <tr><td>*</td><td>*</td><td></td><td>*</td></tr> </table> |
図10 NxN行列(N = 4, P=8)
見易さのためにインデントを加えてあるが、実際には改行も空白も無いことに注意していただきたい。 また、図10をXHTMLとしてレンダリングし図11に示す。
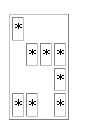
図11 NxN行列のレンダリング(N = 4)
圧縮後の文書は図12(P.16)のようになる。
<table border=""> <tr n="4"><td p="1">*</td></tr> <tr n="4"><td p="2">*</td><td p="3">*</td><td p="4">*</td></tr> <tr n="4"><td p="4">*</td></tr> <tr n="4"><td p="1">*</td><td p="2">*</td><td p="4">*</td></tr> </table> |
図12 NxN行列の圧縮(N = 4)
XHTMLとしてレンダリングし図13に示す。
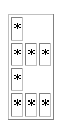
図13 圧縮後のXML文書のレンダリング(N = 4)
このような構成であり、かつNの次数が10、50、100、250の4つのXHTML文書に対して圧縮を行う。各NxN行列に圧縮のためのXSLTスタイルシートを適用し、出力されたXHTML文書のサイズと圧縮前のXML文書のサイズを測定する。
図14に、各Nごとの圧縮結果を示す。
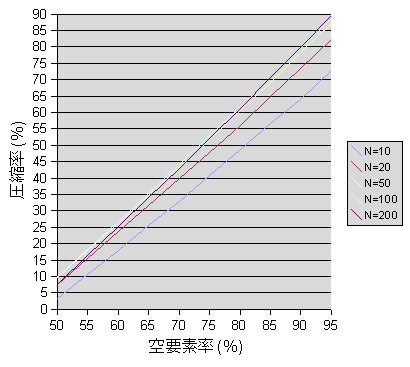
図14 XHTML文書の圧縮率
測定結果から、要素数をPとすると、圧縮率は次の式で近似できる。
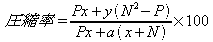
(ただし、x:要素1つのサイズ 、y:空要素1つのサイズ、a:属性1つのサイズとする)
これより、がより大きい場合に、大きな値が得られることがわかる。すなわち、空要素のバイト数が大きく、付与する属性のバイト数が少ないほど、高い圧縮率が得られるだろう。
圧縮は満足のいく圧縮率が得られなかったと思う。原因として、今回は空のtd要素で行ったため、削除されたそれぞれのtd要素のバイト数が少なかったことが挙げられる。この圧縮を応用し、属性が多く付与した要素に対して行えば、高い圧縮率が見込めると考える。
しかし、それで高い圧縮率が得られたとしても、zip等のテキスト圧縮技術でさらに圧縮をかける場合には、圧縮前のファイルよりもファイルサイズが大きくなってしまう。より高く実用的な圧縮方法を提案するためには、現在用いられている圧縮・解凍ソフトウェアの挙動を知り、その圧縮機能が最大限に活用されるような形式に変換することを考えねばならない。
ただし、復元用に付与した属性と復元機能を生かして、XHTMLの要素の生成に利用できることに気付くことができた。これを利用したアプリケーションを、第6節で紹介したい。
本節では、提案手法の復元機能を用いて、XHTMLの要素の生成を行う。その一例として、時刻表の生成を行う。
提案手法では、圧縮したXML文書を復元するために、tr要素が持つtd要素の個数と、td要素のtr要素内における位置をそれぞれ属性として追加した。この属性を利用し、td要素の生成を行う。
tr要素の属性nと、td要素の属性pを用いる。属性nでtd要素の数を指定し、属性pに任意の属性nを超えない数字を指定する。この記述を行った上でXSLTプロセッサ(ブラウザ)で処理することで、より簡潔にtable構造を作り出すことができる。
生成例として、変換対象の文書を図15に示す。
<html lang="ja">
<head><title>td要素の生成テスト</title></head>
<body>
<h1>td要素の生成テスト</h1>
<table border="">
<tr n="5"><td p="2">A</td><td p="4">A</td></tr>
<tr n="5"><td p="1">B</td><td p="3">B</td><td p="5">B</td></tr>
<tr n="5"><td p="2">C</td><td p="4" >C</td></tr>
</table>
</body>
</html>
|
図15 変換対象のXML文書
変換後の文書を図16に示す。
<!DOCTYPE html
PUBLIC "-//W3C//DTD HTML 4.0 //EN" "http://www.w3.org/TR/REC-html40/strict.dtd">
<html lang="ja">
<head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"><title>td要素の生成</title></head>
<body>
<h1>td要素の生成</h1>
<table border="">
<tr><td></td><td>A</td><td></td><td>A</td><td></td></tr>
<tr><td>B</td><td></td><td>B</td><td></td><td>B</td></tr>
<tr><td></td><td>C</td><td></td><td>C</td><td></td></tr>
</table>
</body>
</html>
|
図16 変換後のXHTML文書
このように、属性n,pを任意のtd要素に変換することができる。また、この機能を用いることで圧縮された文書から図17のような時刻表を生成することができる。

図17 生成した時刻表
参照元XML文書のサイズの小さくしたまま、XHTML文書を生成できることが確認できた。より簡単な方法でXML文書をXSLTプロセッサに通し、XHTMLとして出力できる仕組みを利用できれば、XHTMLの生成を大きく支援できるだろう。
本研究ではXSLTを用いたXHTMLの空要素の可読圧縮および復元と、XHTMLの要素生成を提案した。実験より、圧縮が行えることと、復元機能を生成機能としてとらえて応用できることが確認できた。
今後は、圧縮機能および復元機能を拡張・応用し、特定のXML文書の圧縮・復元に特化することを検討すべきだろう。また、圧縮率を高めるために他の圧縮技術との組み合わせの検討などが今後の課題として挙げられる。
研究内容の決定する際や、研究を進めるに当たって数多くのアドバイスをいただいた坂本先生に感謝します。 また、研究の大変さを共有し、時に適切なアドバイスをしてもらった学部4年生の研究員の皆さんに感謝します。
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:template match='/'>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="node()">
<xsl:if test="not((name()='td') and (count(descendant::*)='0') and not(text()) and (count(@*)='0'))">
<xsl:copy>
<xsl:choose>
<xsl:when test="name()='tr'">
<xsl:attribute name="n">
<xsl:value-of select="count(child::*[name()='td'])"/>
</xsl:attribute>
</xsl:when>
<xsl:when test="name()='td'">
<xsl:attribute name="p">
<xsl:value-of select="count(preceding-sibling::*[name() = name(current())]) + 1"/>
</xsl:attribute>
</xsl:when>
</xsl:choose>
<xsl:copy-of select="@*"/>
<xsl:apply-templates/>
</xsl:copy>
</xsl:if>
</xsl:template>
</xsl:stylesheet> |
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns="http://www.w3.org/1999/xhtml" version="1.0">
<xsl:output method="xml" indent="no/>
<xsl:template match='/'>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="node()">
<xsl:copy>
<xsl:copy-of select="@*"/>
<xsl:apply-templates select="node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="*[name()='tr']">
<xsl:copy>
<xsl:copy-of select="@*[not(name()='n')]"/>
<xsl:call-template name="decode">
<xsl:with-param name="count" select="1"/>
<xsl:with-param name="var" select="@n"/>
</xsl:call-template>
</xsl:copy>
</xsl:template>
<xsl:template name="decode">
<xsl:param name="count" select="1"/>
<xsl:param name="var"/>
<xsl:if test="$var > 0">
<xsl:choose>
<xsl:when test="*[@p = $count]">
<xsl:apply-templates select="*[@p = $count]"/>
</xsl:when>
<xsl:otherwise><xsl:element name="td"/></xsl:otherwise>
</xsl:choose>
<xsl:call-template name="decode">
<xsl:with-param name="count" select="$count + 1"/>
<xsl:with-param name="var" select="$var - 1"/>
</xsl:call-template>
</xsl:if>
</xsl:template>
<xsl:template match="*[name()='td']">
<xsl:copy>
<xsl:copy-of select="@*[not(name()='p')]"/>
<xsl:apply-templates/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
|