-
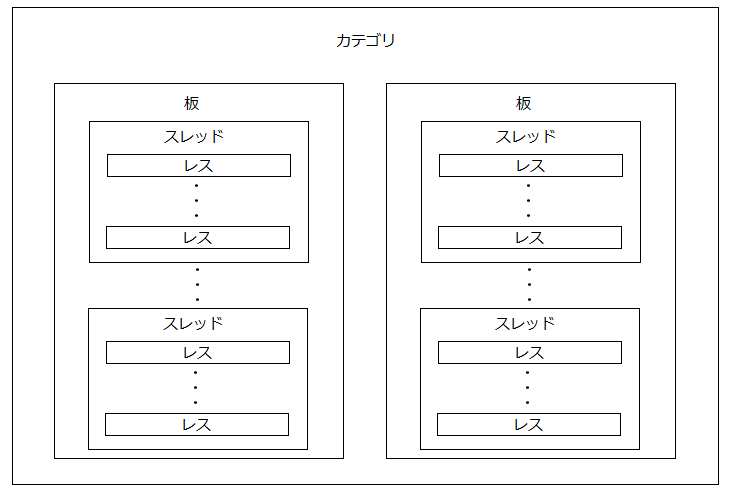
- 図1 2ちゃんねるおよびおーぷん2ちゃんねるの掲示板構成図
近年、Apple社のsiriやGoogle社のGoogle Nowに代表されるように、デバイスを音声で操作することが多く見られるようになり、対話システムの重要性が増してきている。それに加え、対話システムへのジョーク機能追加、SoftBank社の「Papper」、MicrosoftJapan社の「りんな」等のように人を楽しませることを主な目的としたシステムの開発も行われている。
そこで、本研究では「多人数の中の1人としての会話」という視点で対話システムを製作するために、大規模な電子掲示板サイトであるおーぷん2ちゃんねる[1]の投稿文を利用し、おーぷん2ちゃんねるの掲示板に投稿しても不自然ではないような投稿文を生成する手法を考える。
おーぷん2ちゃんねるとは、矢野さとるによって2012年に設立された、既存の2ちゃんねるに対して転載自由化した2ちゃんねる風電子掲示板である。掲示板の構造は2ちゃんねると同じである。
なお、2ちゃんねるとは、西村博之により1999年に設立された日本最大の電子掲示板サイトである。略称は「2ちゃん」、「2ch」、「にちゃん」等と表される。掲示板に投稿する人は「ねらー」、「にちゃんねらー」、「2ちゃんねらー」などと呼ばれている。
掲示板の構成は大きく分けて、カテゴリ、板、スレッド、レスの4つで成り立っている。カテゴリ内に板があり、板にスレッドを作成することでスレッド内に書き込み(レス)ができるようになる。カテゴリと板は既存のものである。構成図は以下である。
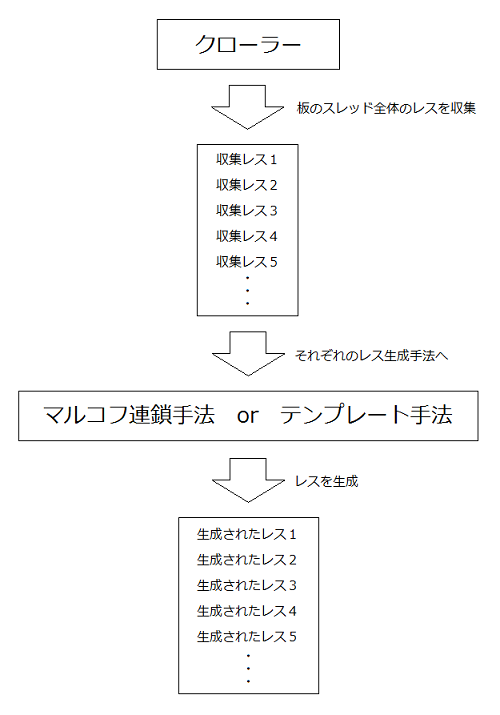
クローラーとはWeb上にあるファイルを収集するためのプログラムである。今回使用したプログラムは、おーぷん2ちゃんねるの板のスレッド一覧ページを取得し、そこからスレッドのページを取得し、そのページ情報をテキストファイルで収集するプログラムと、収集したタグ等を含むテキストファイルからレス以外を取り除く解析プログラムの2つである。改行処理はレス生成後に行うため、改行タグ<br>のみ任意の改行記号に置き換えて残してある。

形態素解析とは、文章を意味のある単語に区切り、辞書を利用して品詞や内容を判別することである。形態素とは、文章の要素のうち、意味を持つ最小の単位である。
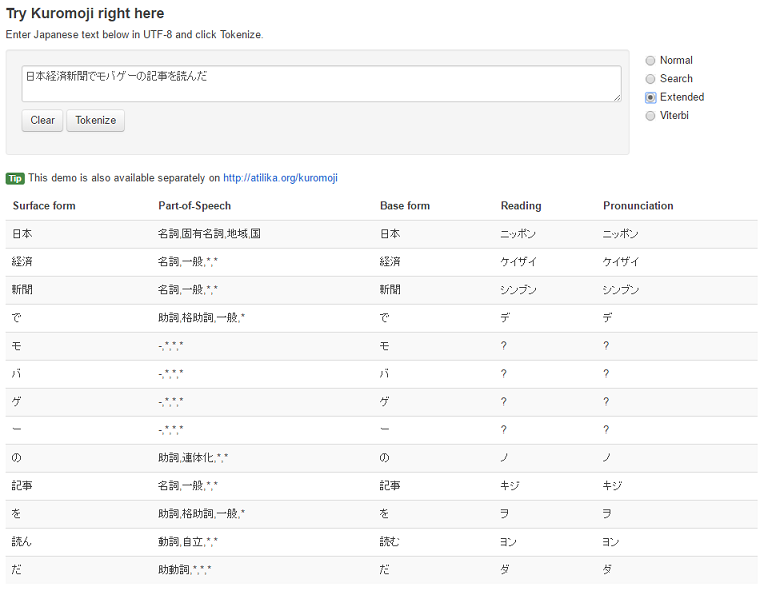
atilika社製の形態素解析エンジンkuromoji[2]の公式サイトにて形態素解析を試すことができる。図3が形態素解析例である。
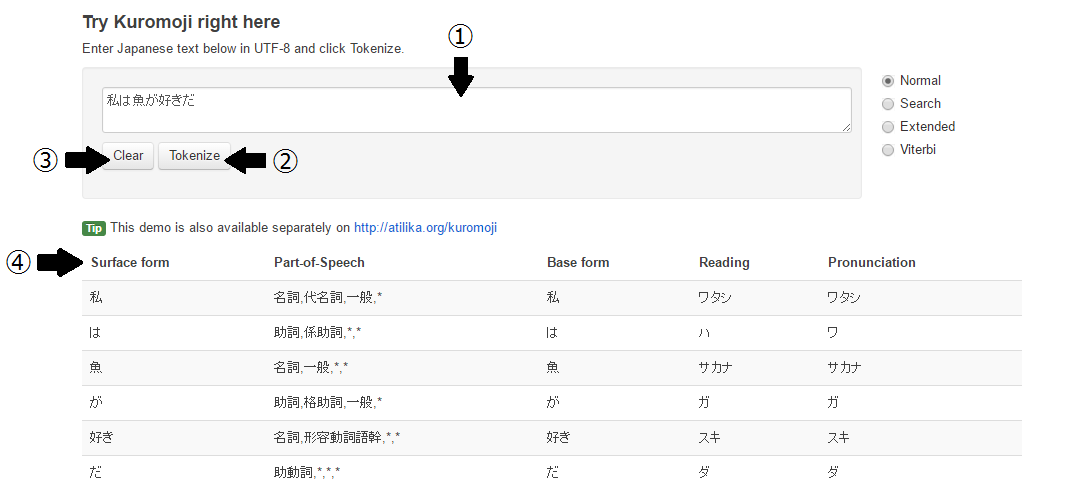
上部の①のテキストフィールドに解析したい文を入れ、②のTokenizeをクリックする。なお、③のClearは文を消去する。上部右に表示されているNormal・Search・Extended・Viterbiは二次節2.3.1で説明する。
④の解析結果の説明を次に示す。
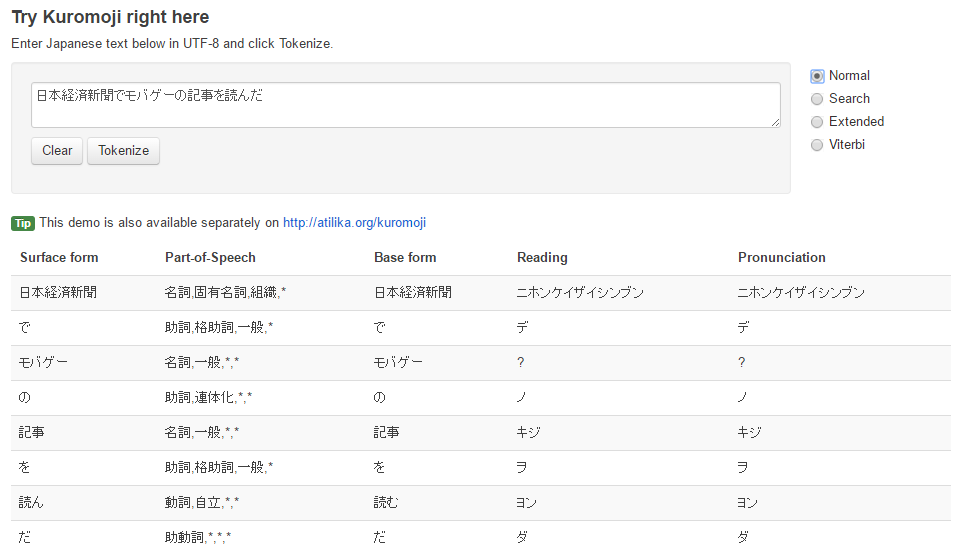
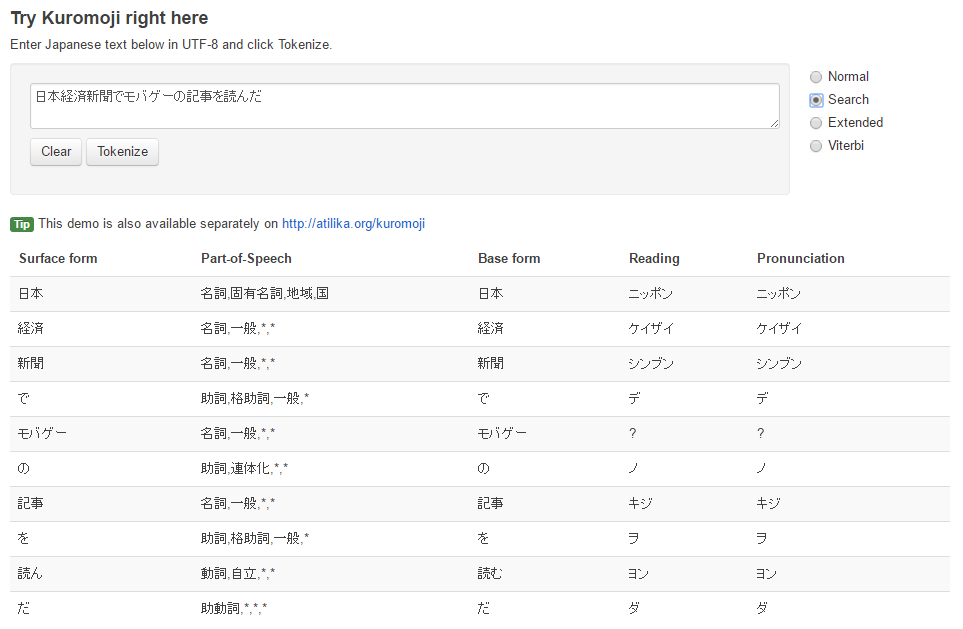
形態素解析にはkuromojiを使用する。kuromojiとはatilika社の製作によるjava言語で書かれた形態素解析エンジンである。kujromojiの形態素解析には3つのモードがあり、Normal・Search・Extendedがある。Normalモードを基本とし、Searchモードは被解析文を検索しやすい形に解析し、ExtendedモードはSearchモードに未知語をuni-gram(1文字列ずつ)に解析することを加えたものである。図4,5,6がそれぞれの比較である。
図5のSearchモードは、図4のNormalモードと比較して、「日本経済新聞」という複合語を「日本」「経済」「新聞」のように、更に形態素分解している。このように、Searchモードは、検索で利用しやすいように複合語の形態素を分解することができる。
図6のExtendedモードは、図5のSearchモードの結果と比較して、「モバゲー」という形態素を「モ」「バ」「ゲ」「ー」のように、更に形態素分解している。このように、Extendedモードは、Searchモードの形態素解析方法に加えて、kuromojiにおいて未知語である形態素をuni-gramに解析できる。
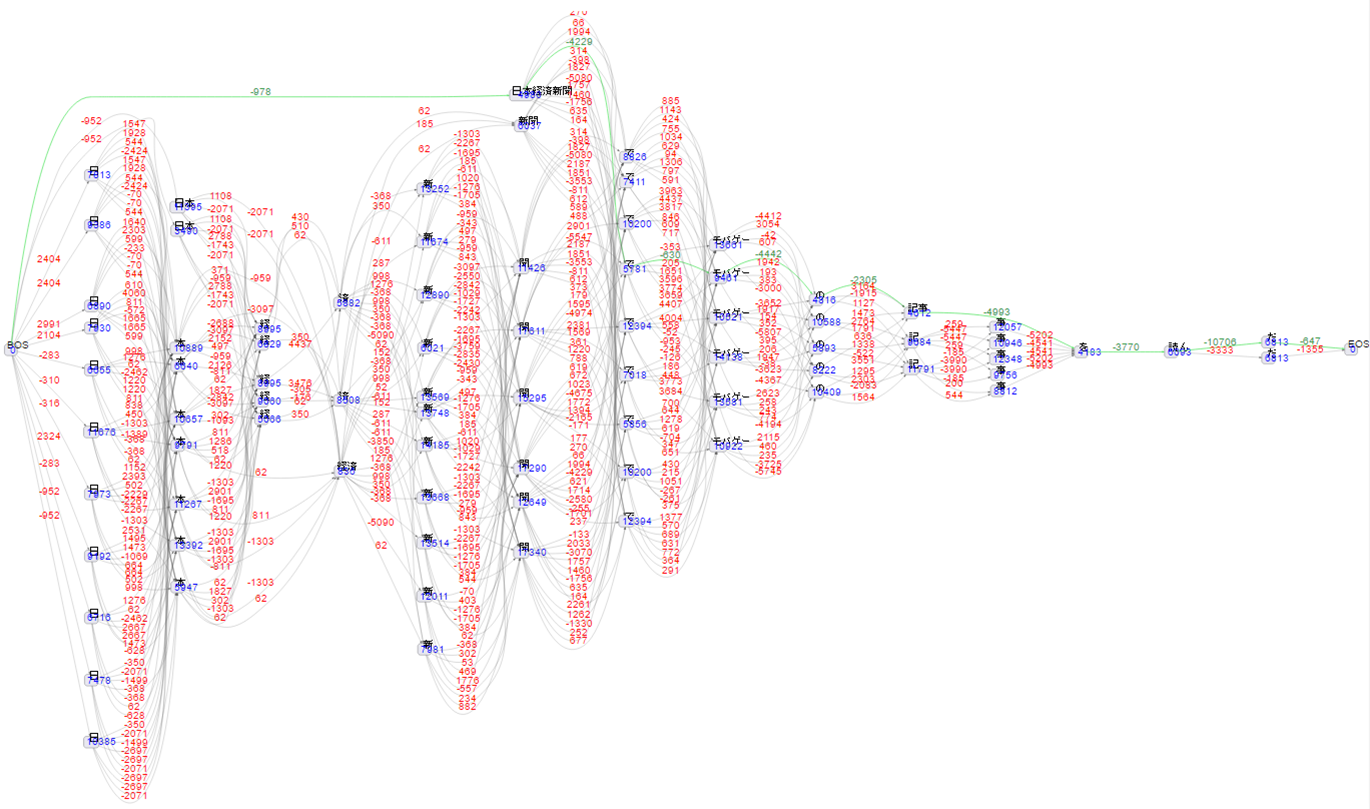
文を形態素解析する際に、kuromoji内部では解析結果となる形態素候補を辞書で探索し、文を形態素解析している。その辞書探索経路の結果を公式サイトでは見ることができる。結果の表示方法は、テキストフィールドに文を入力後、Viterbiを選択しTokenizeをクリックする。結果例を図7に示す。
最も合計スコアの低い経路が採用される。図7の上部を線でつないでいる黄緑色のラインの経路が採用された形態素候補である。
kuromojiライブラリの導入方法は、公式サイトでkuromoji-0.7.7.zip(2017年1月現在)をダウンロードし、フォルダの中に含まれているkuromoji-0.7.7.jarを、kuromojiライブラリを使用するプロジェクトのクラスパスに入れる。
kuromojiライブラリの使い方を説明する。
Tokenizer tokenizer = Tokenizer.builder().build();
List<Token> tokens = tokenizer.tokenize("文章");
上記の2行で、文章が形態素解析され、分解された形態素がtokensに格納される。for文等を使い、tokensの要素(形態素)1つ1つを処理する。
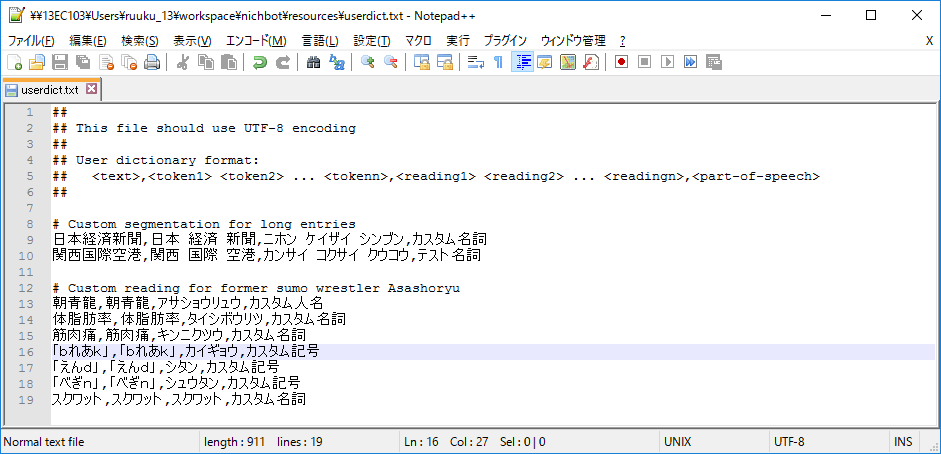
Tokenizer tokenizer=Tokenizer.builder().userDictionary(“userdict.txt”);
上記のようにbuilderメソッドを呼び出し後、userDictionaryメソッドを呼び出すと、指定したパスに記述されているユーザー辞書を登録できる。ユーザー辞書の例を表したものを図8に示す。次のように書く。
単語,単語を形態素分解した状態,読み方,品詞
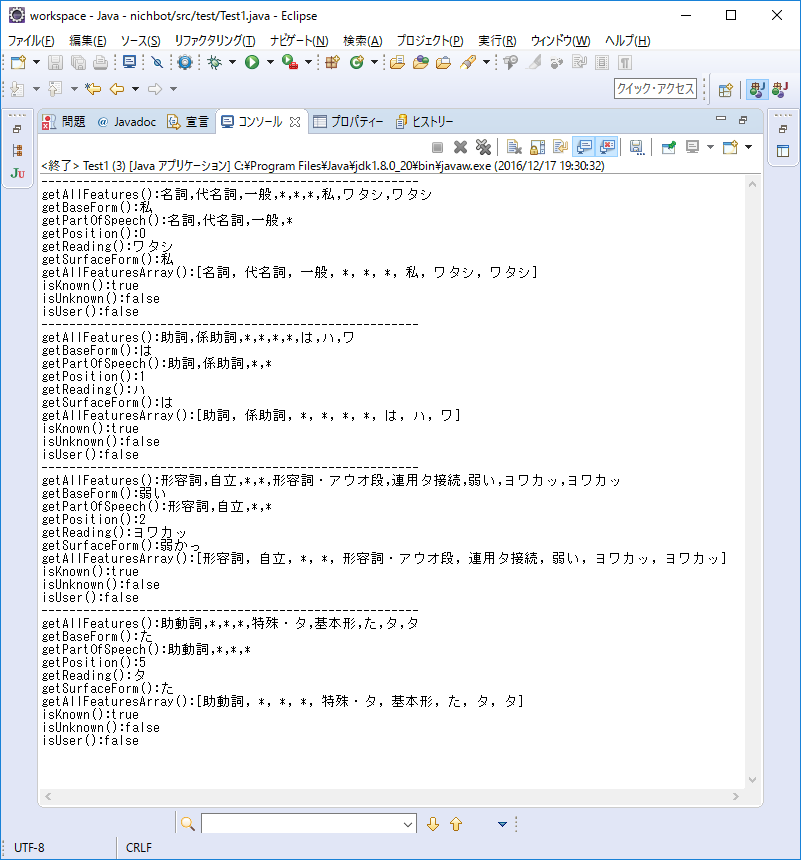
Tokenクラスに実装されているkuromojiライブラリのメソッドは以下である。
例として、「私は弱かった」を形態素解析したものを図9に示す。
レスを自動生成する提案手法として、マルコフ連鎖とテンプレートを使用する。
マルコフ連鎖とは、次の状態が起こる確率が現在の状態のみから決まる確率手法である。
| 原罪の状態 | 次の状態 | 確率 | |
|---|---|---|---|
| 朝食を食べる | → | トイレに行く | 高い |
| 朝食を食べる | → | 朝飯を食べる | 確率が低い |
このように現在の状態から次の状態の確率が決まることを言う。文での例を表すと、
| 次に来る語 | 適合度 | ||
|---|---|---|---|
| 私は山田 | → | おはよう。 | × |
| 私は山田 | → | です。 | ○ |
「私は山田」のあとに「おはよう」がくる確率は0%に決まる。
「私は山田」のあとにこられる言葉は「です」、「だ」、「だよ」等があるため、「です」がくる確率はそれらの数によって決まる。
次の状態が現在を含めた過去N個の状態履歴に依存して決まるとき、これをN階マルコフ連鎖という。上記の例2は、私・は・山田の3つの状態履歴から決まっているため、3階マルコフ連鎖である。
このような、今の状態から次の状態を決めていく仕組みを利用する。
マルコフ辞書とは、マルコフ連鎖で文を生成するときに必要となる、形態素接続の対応表である。A→Bという接続において、Aをプレフィックス(接頭辞)、Bをサフィックス(接尾辞)と呼ぶ。以下に例を示す。
リソースは以下とする。
形態素解析を行うと、以下のように分解される。
これらを辞書に入れていく。入れ方は3つの形態素を入れては1つの形態素分スライドして再度入れることを繰り返す。プレフィックスが同じになる場合、同じプレフィックスのサフィックスに形態素を追加する。図10にマルコフ辞書を示す。
文章生成は先頭([START])の形態素から始まり、プレフィックスの2単語に続くサフィックスをランダムに選択し、プレフィックス2と選択したサフィックスが新たなプレフィックスとなる。これが[END]まで繰り返され、選択されたものを結合し、文章が生成される。このようにすると、例えば「君は山田である」という新たな文が生成されうる。
| プレフィックス1 | プレフィックス2 | サフィックス |
|---|---|---|
| [START] | 君 | が、は |
| 君 | が | 山田 |
| が | 山田 | で |
| 山田 | で | ある、ない |
| で | ある | [END] |
| 君 | は | 山田 |
| は | 山田 | で |
| で | ない | と |
| ない | と | 思 |
| と | 思 | う |
| 思 | う | [END] |
テンプレートとは、何かを作るときの元となる定型的なデータやファイルである。本文章で指すテンプレートとは、文の一部分を脱落させた文の定型データである。その脱落部分にカテゴリ分けをしたキーワードを当てはめることで、新しい文を作る。
私は( )と( )が好きだ。(テンプレート)
( )には、「果物」というカテゴリのキーワードが入れるとする。 「果物」カテゴリのキーワードをリンゴ、ミカン、ブドウ、モモとすると次の新たな文を生成できる。
プログラム上における提案手法の実際のアルゴリズムを説明する。
マルコフ連鎖手法のプログラムはGitHubに掲載されているKurochan氏が作成したMarkovSentenceGenerator[3]を改変し、使用した。なお、変更点は以下である。
| 変更前 | 変更後 |
|---|---|
| 開始記号を設定しない | 開始記号を設定 |
| 文頭は先頭が名詞のdataを選択 | 文頭は先頭が開始記号のdataを選択 |
ここで示す例のリソースは3.1.1の例と同じものを使用する。
アルゴリズムは次である。
TokensListが図12のようになったとすると、新しい文は次のようになる
「君は山田である」
| 要素\配列 | data[0] | data[1] | data[2] |
|---|---|---|---|
| data | [START] | 君 | が、は |
| data | 君 | が | 山田 |
| data | が | 山田 | で |
| data | 山田 | で | ある、ない |
| data | で | ある | [END] |
| data | 君 | は | 山田 |
| data | は | 山田 | で |
| data | で | ない | と |
| data | ない | と | 思 |
| data | と | 思 | う |
| data | 思 | う | [END] |
| 要素\配列 | [0] | [1] | [2] |
|---|---|---|---|
| head | [START] | 君 | は |
| next | 君 | は | 山田 |
| next | は | 山田 | で |
| next | 山田 | で | ある |
| next | で | ある | [END] |
仕様は以下である。
アルゴリズムは次である。
上記を簡易的に表した例を示す。
なお、キーワード群からランダムで選ぶため、同じレスが出来上がる可能性もある。
2.2で説明したクローラーで、改行記号がついたレスをテキストファイルに収集する。1行1レスという形で収集する。これをレス生成のリソースとし、各手法でレスを生成後、アンカー(>>100等のように書かれる特定のレスに向けてレスを投稿するための合図)を取り除き、改行記号を改行コマンド\rに置き換える。マルコフ連鎖の場合は開始記号も取り除く。
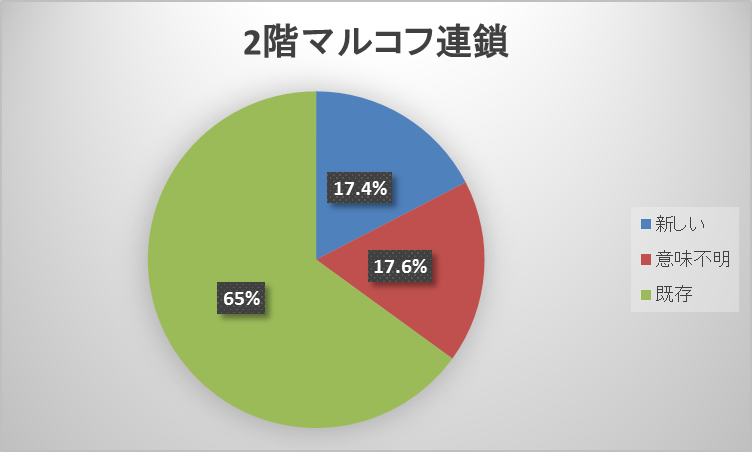
「食文化」カテゴリの「食べ物」板と「政治経済」カテゴリの「政治」板を対象に実験を行う。この板毎に4.3で述べた流れでレス生成実験を行っていく。各手法で100レスを生成し、それを「既存のレス」・「意味不明なレス」・「新しいレス(まともなレス)」に分類分けする。マルコフ連鎖手法に関しては、2階と3階でレスを生成する。
実験手順は次である。
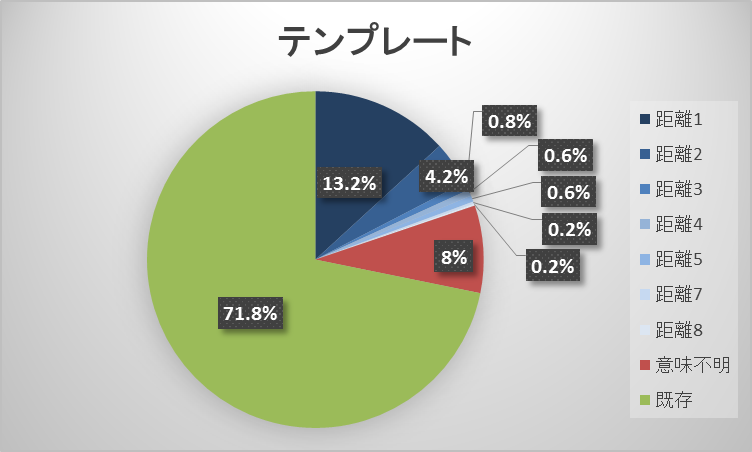
「食べ物」板での実験結果を示す。収集レス数は2750文、テンプレート数は1561文。図19の「距離」は、テンプレートとなった文とそのテンプレートを利用して生成された文を比較して、置き換えられたキーワードの数を示している。
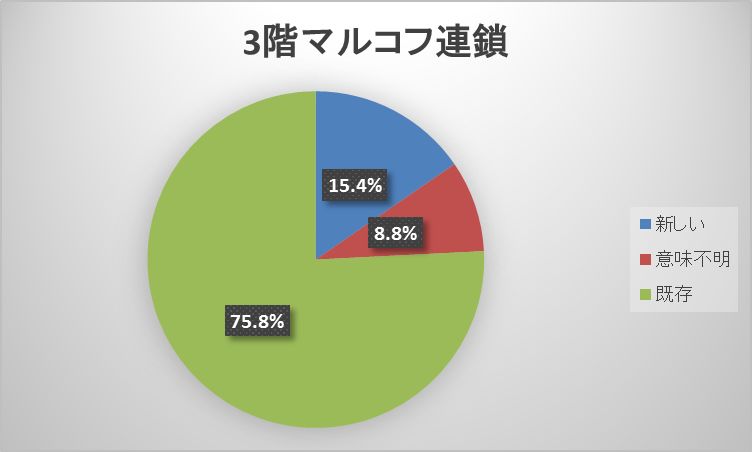
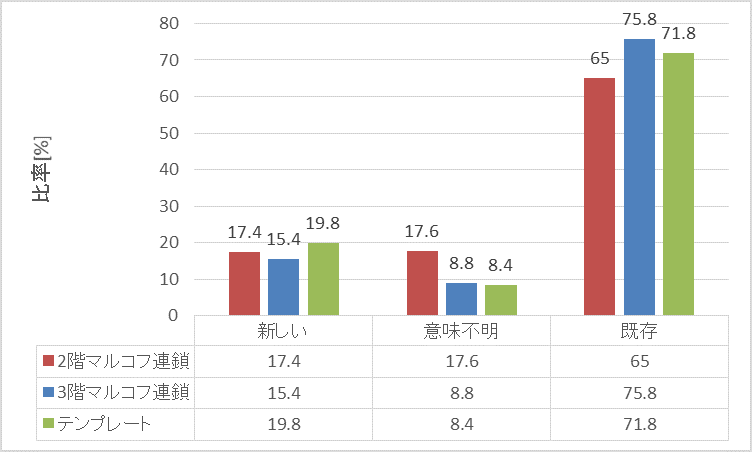
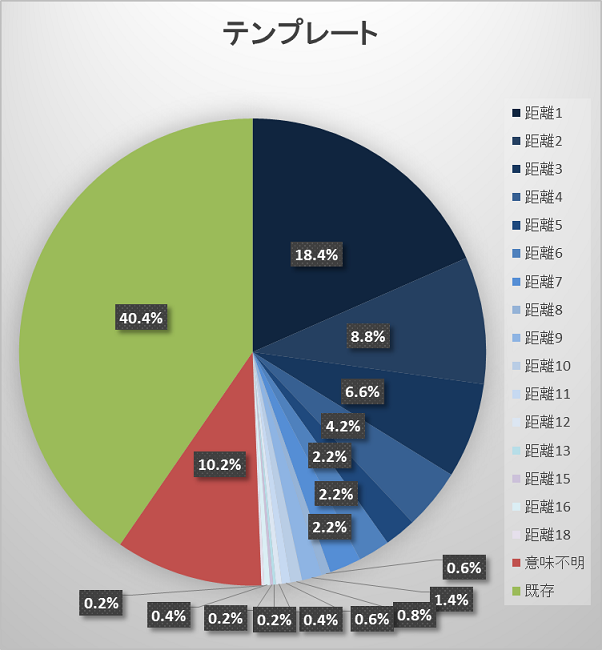
「政治」板での実験結果を示す。収集レス数は26106文、テンプレート数は18628文。5.2と同じように、図26の「距離」は、テンプレートとなった文とそのテンプレートを利用して生成された文を比較して、置き換えられたキーワードの数を示している。
「食べ物」板では、各分類の度数はどの手法でもあまり差が出なかったが、2階マルコフ連鎖17.4%・3階マルコフ連鎖15.4%・テンプレート19.8%とテンプレート手法が僅差で1番多く新しいレス(まともなレス)を生成した。差が出なかった要因は2つ考えられる。
1つは、「食べ物」板は一言のような短いレスで構成されるスレッド(食べておいしかった食べ物・嫌いな食べ物・【空腹注意】おまいらの今日の夜ご飯あげてけ等)が複数存在するため、短いレスが生成される傾向にあり、その影響でレスを生成するときに形態素を繋ぎ合わせる分岐が起こらず、変化したレスが生成されにくかったことが考えられる。もう1つは、素材となる収集レスが2750文と少なく、分岐のバリエーションが少なくなったことが考えられる。
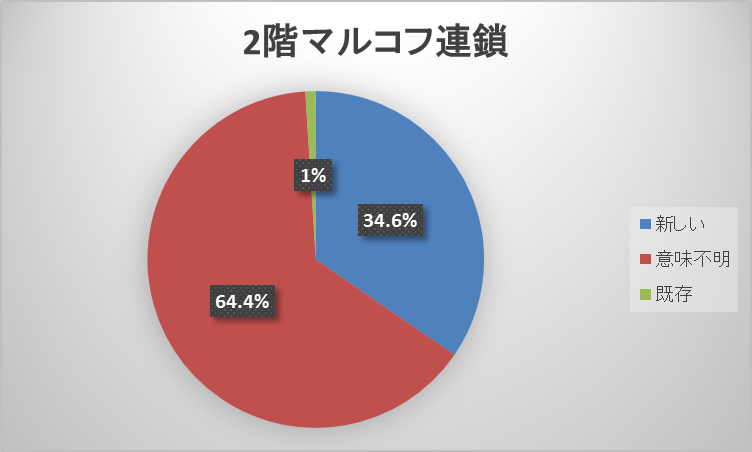
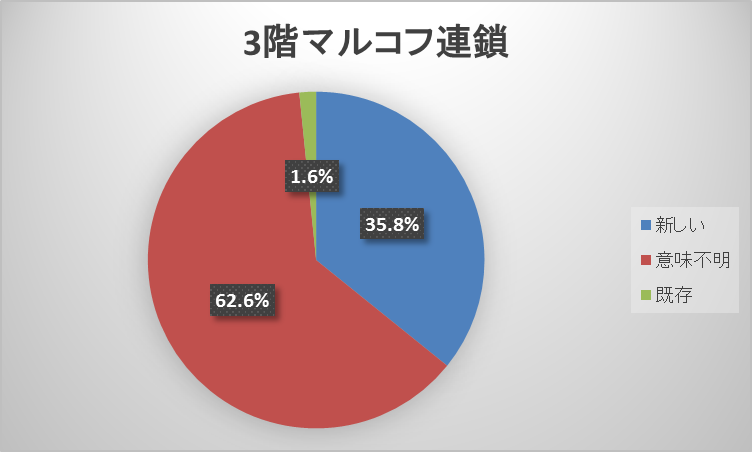
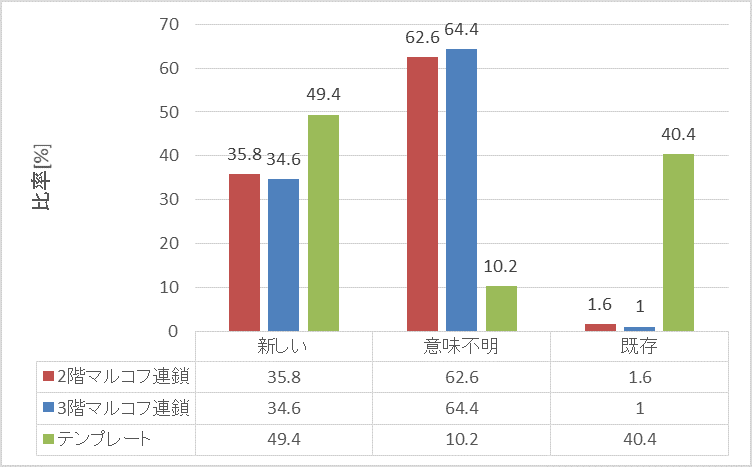
「政治」板では、テンプレート手法とマルコフ連鎖手法とで各分類の度数に差が出た。テンプレート手法の新しいレス(まともなレス)を生成する比率が、2階マルコフ連鎖35.8%・3階マルコフ連鎖34.6%・テンプレート49.4%とマルコフ連鎖手法より約15%高くなり、マルコフ連鎖手法は既存のレスが、2階マルコフ連鎖1.6%・3階マルコフ連鎖1.0%とほぼ生成されなかった。
テンプレート手法がより多く新しいレスを生成した要因はテンプレートを使用することで文法や文脈が崩れなかったからと考えられる。逆に、マルコフ連鎖手法は収集レスが20106文と多く、議論が行われている板であるため、1レス毎が長文の傾向にあったことから、形態素を繋ぎ合わせる分岐も多くなり、自由度があがって、文脈が崩れる・改行で文脈がおかしくなる等が起こったと考えられる。この自由度はマルコフ連鎖で既存のレスがほぼ生成されなかった要因にもなっていると考えられる。
上記と実験結果より、収集レスが多く、その収集レスが長い文であればテンプレート手法が有効であることが分かった。
本研究では、おーぷんにちゃんねるのレスを2つの板毎(「食べ物」板・「政治」板)で収集し、それをデータベースに2つの手法(マルコフ連鎖・テンプレート)でレスの自動生成を行い、2つの手法の生成レスを比較した。その結果、「食べ物」板では差が出ず、「政治」板では差が出た。この結果から、収集レスが多く、その収集レスが長い文であればテンプレート手法が有効になることが分かった。
今回の実験では、生成レスの評価基準が曖昧になってしまい、生成レスを実際に評価することに多くの時間がかかり、2つの板しか実験できず、被験者も自分のみとなってしまった。改善策として、実験で生成するレス数を減らす・評価基準を細かく設定する等があるため、今後、実験を行う際は実験方法を改善していきたい。