3.現代CPUの進化
この章では、CPUの進化について述べる。コンピュータの実行速度に大きな影響を与えるのはベクトルの掛け算であり、また画像処理の演算でもよく使用される。そのためこの章では、掛け算命令の比較を行うことででCPUの進化について述べる。
コプロセッサ(co-processor)とは、マイクロプロセッサの性能を強化するために、特定分野に特化した補助プロセッサである。浮動小数点演算を行うFPUなどがある。Intel社のx86系アーキテクチャでは、Intel i386(旧80386)に80387を接続することで浮動小数点演算の高速化が行えたが、i486以降のプロセッサには本体に内蔵されるようになった。
FPUのアセンブル命令は通常の命令の頭にfがつき「f+命令」という形で表せる。またFPU内蔵のCPUでは、FPU命令を使用するとFPUレジスタが使用される。FPUレジスタは汎用レジスタと異なり値を8個まで格納でき、st(0),st(1)と表記される。GFortran等のコンパイラで倍精度浮動小数点数型を計算するときによく使われる。FPUの掛け算命令は[fmul]である。FPUのレジスタを利用することで、単精度浮動小数点や倍精度浮動小数点数型の掛け算が行える命令である。次のコードが実際にfmullを使用した例である。
fldl (%edx)
fmull _cmnleg_+2097144(,%eax,8)
faddp %st, %st(1)
incl %eax
addl $8, %edx
cmpl $513, %eax
jne L10
fstl _cmnleg_+2101240(,%ecx,8)
fmul %st(0), %st
faddp %st, %st(1)
addl $512, %esi
cmpl $512, %ecx
je L11
incl %ecx
jmp L12
SIMD(Single Instruction Multiple Data)とは、マイクロプロセッサにおいて、1つの命令で複数のデータを扱う処理手法である。もともとはスーパーコンピュータのベクトル命令やDSPの成和演算専用レジスタを用いた積和演算命令などで実装されていた。しかし最近では市販の汎用CPUにも実装され、Intel社のCPUには1992年に発売したPentiumⅢでSSE(Streaming SIMD Extensions)というストリーミングSIMD拡張命令が実装された。
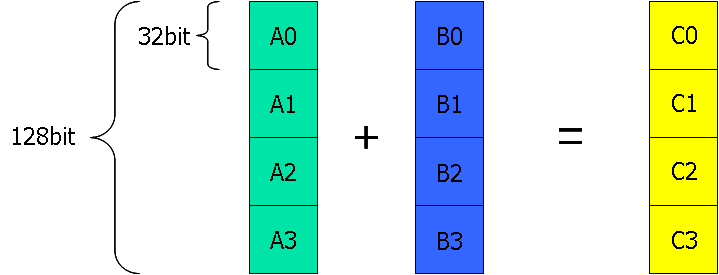 図2 SIMDの例
図2 SIMDの例
図2はSIMDの例である。AとBの2つの配列を足し合わせるとき、通常の演算であれば4回演算しなければならないが、SIMD演算であれば一回の演算で処理が出来る。
Intel系のプロセッサでは、MMXやSSE等の拡張命令セットとしてSIMDが搭載されている。MMXでは浮動小数点用のレジスタを利用して複数のデータを処理するが、SSEではSIMD専用レジスタであるXMMレジスタを利用している。
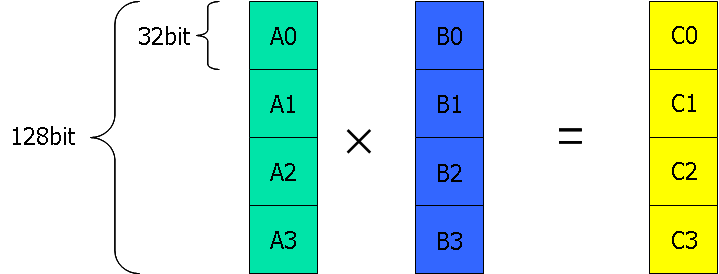 図3 SIMDの掛け算の例
図3 SIMDの掛け算の例
SIMDのアセンブル命令は通常の命令の終わりにpsがつき「g+命令」という形で表せる。
SIMDの掛け算命令はfloat型の場合[mulps]である。SIMDレジスタであるXMMレジスタの要素を掛け合わせる命令である。mulpsの場合、xmmレジスタのfloat型4要素を掛け合わせる命令となる。次のコードが、実際にmulpsを使用した例である。
movaps (%edx), %xmm0
mulps (%esi,%eax), %xmm0
movaps %xmm0, (%ebx,%eax)
addl $16, %eax
addl $16, %edx
cmpl $2048, %eax
jne L11
xorw %ax, %ax
.p2align 2,,3
3.3.CPUとコンパイラ
CPUが年々進化していくと共に、コンパイラも進化している。Free Software Foundationが開発した、GNU Compiler Collectionのパッケージに含まれているC言語のコンパイラもCPUの進化に伴い対応している。表1はCPUの拡張命令とそれに対応するGCCのヴァージョンの表である。
GCC3.1までは、単精度浮動小数点の処理はFPUによって処理されていた。しかしGCC3.1からは、PentiumⅢから搭載された単精度浮動小数点データをまとめて処理することができるSSEが利用可能となった。またPentium4から搭載された倍精度浮動小数点演算や整数演算を複数まとめて計算が可能となったSSE2も、GCC3.1で使用が可能となった。Pentium4第三世代から搭載された、浮動小数点演算の処理能力を向上させたSSE3はGCC3.3、Core 2Penrynから搭載された画像操作のパフォーマンスが改善されたSSE4はGCC4.3で対応された。また、GCC4.2からマルチスレッディングに対応し、OpenMPオプションをつけることで並列処理が可能となった。
表1 CPUとコンパイラの対応表
| CPU | 拡張命令 | GCCの対応ヴァージョン |
| Pentium第三世代以降 | MMX | 3.1以降 |
| PentiumIII以降 | SSE | 3.1以降 |
| Pentium 4以降 | SSE2 | 3.1以降 |
| Pentium 4第三世代以降 | SSE3 | 3.3以降 |
| Core 2 Penryn以降 | SSE4 | 4.3以降 |
3.4.ベンチマークテストプログラム
ベンチマークテストとは、コンピュータシステムのハードウェアの性能を測定するための指標のことである。本論文では、高速化の対象としてベクトルの乗算を大量に行うことで性能を図るベンチマークを利用する。このベンチマークプログラムをC言語に移植し高速化、比較を行うことで速度を評価する。
本論文では、田嶋のベンチマークプログラム[1]を利用する。利用したプログラムは、倍精度実数の1024×1024次元正方行列をベクタに掛ける操作を2000回繰り返し行列の固有値を求める処理を3回行うことで、実行時間を計測しマシンの性能を計測するものである。今回は512次元正方行列に変更して使用する。
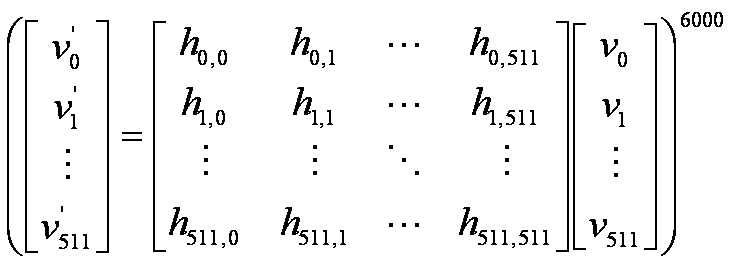 図4 本研究で使用するベンチマークプログラムの計算量
図4 本研究で使用するベンチマークプログラムの計算量
この章では、作成したプログラムとその概要について述べる。なお、開発環境は以下の通りである。
表2 実験環境
| CPU | Intel(R) Core(TM)2 Duo CPU P8400 2.26GHz |
| メモリ(RAM) | 3.00GB |
| OS | Windows Vista Home Premium 32bit |
| コア数 | 2 |
| コンパイラ | GCC4.5.2 |
本論文では、高速計算の比較対象として、FORTRANで記述されたプログラムを使用した。FORTRANの特徴の一部は以下の通りである。
- 7桁~72桁までにプログラムを書く
- 関数のはじめにAからH,OからZまでの変数を倍精度浮動小数点型、IからNまでを整数型として暗黙的に宣言する。
- 配列の添字は1から始まる。
- 比較演算子は「.LT.」「.LE.」「.GT.」「.GE.」「.EQ.」「.NE.」と記述する。
- 繰り返し文はDOを用いる。
- 名前付き定数を指定する際にPARAMETER文を使用する。
- プログラム単位間でデータのやり取りをする場合にはCOMMON文を利用する。
以下の二つのプログラムはFORTRANで記述されたプログラムと、それと同等の動きをするC言語のプログラムである。倍精度型の変数Aに1を足す行為を10回行い、「HELLO WORLD!」を出力する素朴なプログラムである。C言語に移植する際に、変数Aはdouble型として明示的に宣言し、繰り返し文にはfor文を用いた。また出力はprintfを使用した。このように、FORTRANとC言語は記述の仕方が異なっている。
PROGRAM HELLO
IMPLICIT REAL*8 (A-H,O-Z)
A=0
DO 900 I=1,10
A=A+1
900 CONTINUE
C
WRITE(6,910)
910 FORMAT('HELLO WORLD!')
C
END
#include<stdio.h>
int main(){
doube A = 0;
int I;
for(I=1;I<=10;I++){
A=A+1;
}
printf("HELLO WORLD!");
//
return 0;
}
まず、3.4で説明したベンチマークプログラムをFORTRAN言語からC言語に移植した。(付録7-1)移植は、次の内容に沿って行った。
- FORTRANでは関数のはじめにAからH,OからZまでの変数を倍精度浮動小数点型、IからNまでを整数型として暗黙的に宣言してしまうので、明示的に宣言し直す。
FORTRANの例
IMPLICIT REAL*8 (A-H,O-Z)
C言語の例
double E,F,S,T;
int I,J,K,L,M;
FORTRANでは比較演算子は「.LT.」「.LE.」「.GT.」「.GE.」「.EQ.」「.NE.」と記述されているので、「<」「<=」「>」「>=」「==」「!=」と記述する。
FORTRANの例
IF(NSOL .GT. MSOL) STOP 1
C言語の例
if(NSOL > MSOL) return 1;
FORTRANでは繰り返し文はDOを用いているので、for文に記述し直す。
FORTRANの例
DO 10 I=1,N
H(I,I)=I-A/I
DO 10 J=1,I-1
H(I,J)=B/(I-J)**2
10 H(J,I)=H(I,J)
C言語の例
for (I=1;I<=N;I++){ //10
CMN->H[I-1][I-1] = (double)I - A/(double)I;
for(J=1;J<=I-1;J++){
CMN->H[I-1][J-1] = B/(double)((I-J)*(I-J));
CMN->H[J-1][I-1] = CMN->H[I-1][J-1];
}
}//10end
FORTRANでは名前付き定数を指定する際にPARAMETER文を使用するが、C言語ではdifneで定数を定義する
FORTRANの例
PARAMETER(N=512,MSOL=3)
C言語の例
#define N 512
#define MSOL 3
FORTRANでは512×512次元行列とベクタをCOMMON文で宣言されているが、値引渡しをしていないので、構造体として扱う。
FORTRANの例
PARAMETER(N=512,MSOL=3)
COMMON /CMNLEG/ H(N,N),V1(N),V2(N),EG(MSOL)
C言語の例
typedef struct{
double H[N][N];
double V1[N];
double V2[N];
double EG[MSOL];
}CMNLEG;
行列の大きさが大きいので、ヒープ領域を使用するためにmalloc関数を使用しメモリを確保する。
CMNLEG *CMN;
CMN = malloc(sizeof(CMNLEG));
if(CMN == NULL){ //動的に配列を確保出来なかったら終了する
printf("failure");
return -1;
}
以上の点を含めて移植した素朴なC言語と、FORTRANのプログラムを実行時間で比較した結果が以下の通りである。
表3 素朴なC言語とFORTRANの実行結果
| プログラム | 実行時間 |
| FORTRAN | 00:07.425 |
| C言語 | 00:17.160 |
表3から、FORTRANで記述されたプログラムの方が、実行時間がおよそ2.4倍早いことがわかる。
また、最適化オプションで-O2を指定した場合の実行時間の比較が以下の通りである、
表4 最適化を行った場合の実行結果
| プログラム | 実行時間 |
| FORTRAN | 00:02.308 |
| C言語 | 00:12.000 |
表4から、およそ6倍FORTRANの方が早いことがわかる。今後は、最適化を施したFORTRANの実行結果と比較を行う。
また、SIMD化をするにあたって、double型からfloat型への変更を行う。float型に直したC言語の実行結果が以下の通りである。
表5 float型へ変更後の実行結果
| プログラム | 実行時間 |
| C言語 | 00:10.124 |
表5から、double型より1.1倍速くなっていることがわかるが、それでもまだFORTRANのほうが4.38倍速いことがわかる。
次に、4-2の素朴なC言語のプログラムにSIMD化を行った。SIMD化は、連続したメモリアクセスが見込まれるところに行うとより効果的である。そのため、まず効率化出来る部分の抽出を行った。
for(K=1;K<=ITER;K++){//60
S = 0.0;
for(I=1;I<=N;I++){//40
T = 0.0;
for(J=1;J<=N;J++){//30
T = T + CMN->H[J-1][I-1]*CMN->V1[J-1];
}
CMN->V2[I-1] = T;
S = (S + (T*T));
}
E = sqrt(S);
F = 1 / E;
for(I=1;I<=N;I++)//50
CMN->V1[I-1] = F * CMN->V2[I-1];
}//60end
上記の部分の、一番深い階層のループを今回の対象とした。今回は下記の部分の抽出を行い、SIMD化を行った。今回のベンチマークプログラムでは以下の部分が最も多く行列計算が行われているところである。
for(J=1;J<=N;J++){//30
T = T + CMN->H[J-1][I-1]*CMN->V1[J-1];
}
ここの部分は、総和の計算(加算)と乗算が同時に行われているので、SIMD化するために式を二つに分ける。
for(J=1;J<=N;J++){//30
temp = CMN->H[J-1][I-1]*CMN->V1[J-1];
T = T + temp;
}
また、SIMD演算が使用できるよう、にCMN->H[J-1][I-1]とCMN->V1[J-1]をSIMD演算用の型である__m128型変数hに格納する。このとき、float型4要素を1要素にまとめるので、配列の長さは1/4になる。この二つの式を、SIMD化する。また、メモリアクセスが連続するようにするため、CMN->Hの配列の対称性を利用し行列の転置を行い計算を行う。具体的には以下のようにする
 図5 SIMDレジスタ格納前
図5 SIMDレジスタ格納前
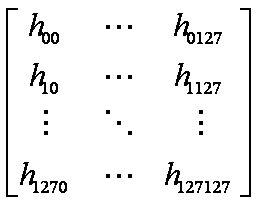 図6 SIMDレジスタ格納後
図6 SIMDレジスタ格納後
乗算手法
SIMD演算で乗算を行う関数である_mm_mul_ps()関数を使用する。乗算の部分のSIMD化は図7のようにして行う。
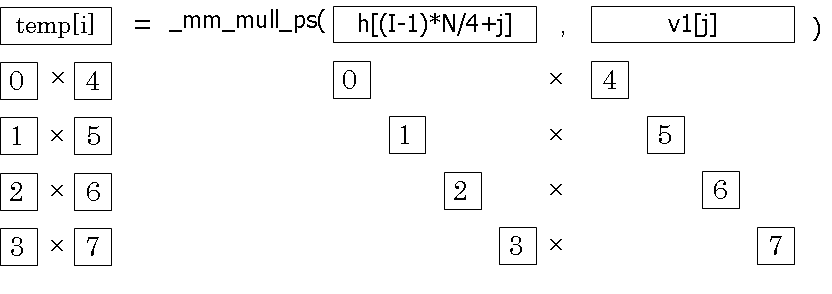 図7 乗算手法
図7 乗算手法
上記のように、SourceとDestinationをかけ合わせ、一時的な_m128型の配列tempに結果を格納した。実際に乗算部分をSIMD化したコードが以下の通りである。
for(j=0;j<N/4;j++){
temp[j] = _mm_mul_ps(h[(I-1)*N/4+j],v1[j]);
}
加算手法
次に、上記で乗算した結果の総和を求める。総和は、図8のようにして求める。
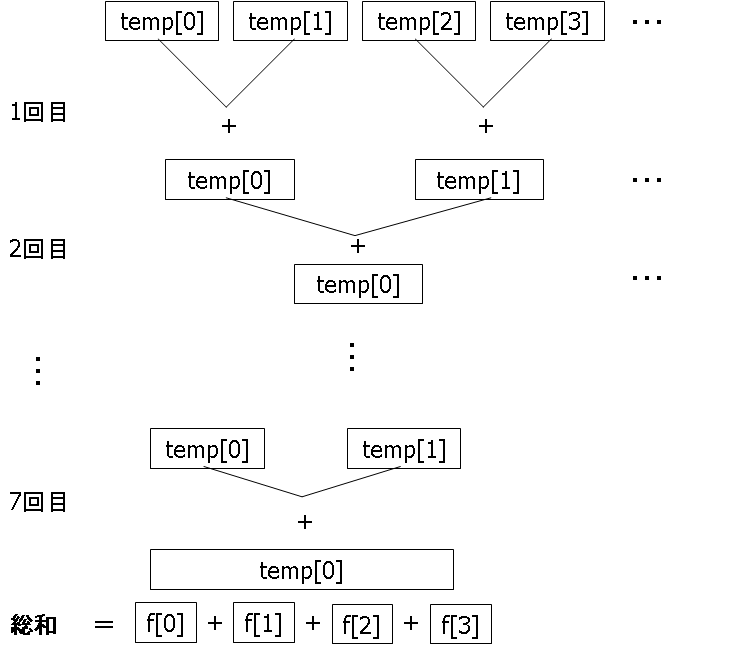 図8 総和の計算手法
図8 総和の計算手法
乗算で求めた結果が格納されている変数tempの配列を順次加算し、部分和を求める。そして配列の大きさは127なので、7回繰り返すことで最終的にtemp[0]に部分和が格納される。最後に全ての部分和が格納されたtemp[0]の4要素を足し合わせることで、総和を求め。また、加算するためにSIMD演算の加算関数である_mm_add_ps()関数を使用する。
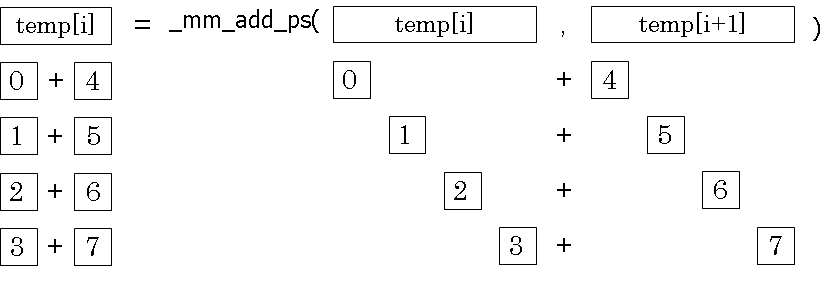 図9 加算手法
図9 加算手法
実際に加算部分をSIMD化したコードが以下の通りである。
for(i=0;i<N/4/2;i++)
tempT[i] = _mm_add_ps(temp[i*2],temp[i*2+1]);
for(j=0;j<6;j++){
for(i=0;i<N/4/(2*(j+1));i++)
tempT[i] = _mm_add_ps(temp[i*2],temp[i*2+1]);
}
Ttemp = (float*)tempT;
Ttemp[0] = Ttemp[0]+Ttemp[1]+Ttemp[2]+Ttemp[3];
結果
SIMDを施したC言語とFORTRANの実行結果が以下の通りである。
表6 SIMDを施したC言語の実行結果
| プログラム | 実行時間 |
| C言語 | 00:01.622 |
表6から、これまでの実験結果と合わせた各プログラムの結果のグラフが図10である。
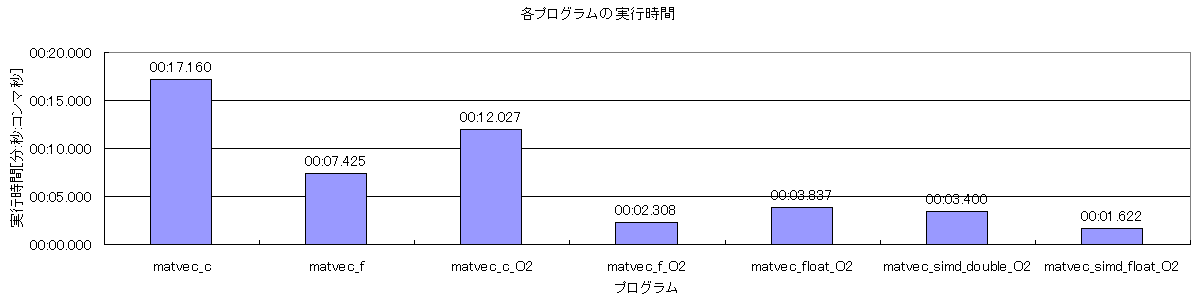 図10 各プログラムの実行結果のグラフ
図10 各プログラムの実行結果のグラフ
図10から、作成したSIMD化プログラムは、FORTRANのプログラムよりおよそ1.4倍早いことがわかる。
7-1.FORTRANのベンチマークプログラム[matvec.f]
C MATVEC.F OF N.TAJIMA'S FORTRAN BENCH-MARK TESTS (VER.2)
C MULTIPLIES REAL MATRIX TO VECTOR REPEATEDLY "NSOL*ITER" TIMES
C IN ORDER TO OBTAIN LARGEST "NSOL" EIGENVALUES.
C HISTORY: 98/6/24-26
PROGRAM MATVEC
IMPLICIT REAL*8 (A-H,O-Z)
A=1
B=1
NSOL=3
ITER=2000
CALL MATVC1(A,B,NSOL,ITER)
END
C
SUBROUTINE MATVC1(A,B,NSOL,ITER)
IMPLICIT REAL*8 (A-H,O-Z)
PARAMETER(N=512,MSOL=3)
COMMON /CMNLEG/ H(N,N),V1(N),V2(N),EG(MSOL)
IF(NSOL .GT. MSOL) STOP 1
WRITE(6,900) N,N,NSOL,ITER
900 FORMAT(' MULTIPLY ',I4,'*',I4,' REAL MATRIX TO VECTOR',I5,'*',I7
& ,' TIMES.')
DO 10 I=1,N
H(I,I)=I-A/I
DO 10 J=1,I-1
H(I,J)=B/(I-J)**2
10 H(J,I)=H(I,J)
DO 80 L=1,NSOL
F=SQRT(6.0D0/(N*(N+1)*(2*N+1)))
DO 20 I=1,N
20 V1(I)=F*I
E=0
DO 60 K=1,ITER
S=0
DO 40 I=1,N
T=0
DO 30 J=1,N
30 T=T+H(J,I)*V1(J)
V2(I)=T
S=S+T**2
40 CONTINUE
E=SQRT(S)
F=1/E
DO 50 I=1,N
50 V1(I)=F*V2(I)
60 CONTINUE
EG(L)=E
DO 70 I=1,N
DO 70 J=1,N
70 H(I,J)=H(I,J)-V1(I)*E*V1(J)
80 CONTINUE
WRITE(6,930) (EG(L),L=1,NSOL)
930 FORMAT(' LARGEST EIGENVALUES=',3F13.5:/' ',6F13.5)
END
7-2.FORTRANのベンチマークプログラムを移植した素朴なプログラム[matvec.c]
#include<stdio.h>
#include<stdlib.h>
#include<math.h>
#define N 512
#define MSOL 3
int MATVC1();
typedef struct{
double H[N][N];
double V1[N];
double V2[N];
double EG[MSOL];
}CMNLEG;
int main(){
double A,B;
int NSOL,ITER;
A = 1.0;
B = 1.0;
NSOL = 3;
ITER = 2000;
MATVC1(A,B,NSOL,ITER);
return 0;
}
int MATVC1(double A,double B,int NSOL,int ITER){
double E,F,S,T;
int I,J,K,L,M;
double E0 =0.0;
CMNLEG *CMN;
double *h,*v1,*v2,*eg;
CMN = malloc(sizeof(CMNLEG));
if(CMN == NULL){
printf("failure");
return -1;
}
if(NSOL > MSOL)
return 1;
printf(" MULTIPLY %d*%d REAL MATRIX TO BECTOR %d * %d TIMES.\n",N,N,(int)NSOL,(int)ITER);
for (I=1;I<=N;I++){ //10
CMN->H[I-1][I-1] = (double)I - A/(double)I;
for(J=1;J<=I-1;J++){
CMN->H[I-1][J-1] = B/(double)((I-J)*(I-J));
CMN->H[J-1][I-1] = CMN->H[I-1][J-1];
}
}//10end
for(L=1;L<=NSOL;L++){//80
F = sqrt(6.0/(double)(N*(N+1)*(2*N+1)));
for(I=1;I<=N;I++){//20
CMN->V1[I-1] = F * (double)I;}
E = 0.0;
for(K=1;K<=ITER;K++){//60
S = 0.0;
for(I=1;I<=N;I++){//40
T = 0.0;
for(J=1;J<=N;J++){//30
T = T + CMN->H[J-1][I-1]*CMN->V1[J-1];
}
CMN->V2[I-1] = T;
S = (S + (T*T));
}
E = sqrt(S);
F = 1 / E;
for(I=1;I<=N;I++)//50
CMN->V1[I-1] = F * CMN->V2[I-1];
}//60end
CMN->EG[L-1] = E;
for(I=1;I<=N;I++){//70
for(J=1;J<=N;J++){
CMN->H[I-1][J-1] = CMN->H[I-1][J-1] - CMN->V1[I-1]*E*CMN->V1[J-1];
}
}//70end
}//80end
printf(" LARGEST EIGENVALUES= %lf %lf %lf \n",CMN->EG[0],CMN->EG[1],CMN->EG[2]);
free(CMN);
return 0;
}
7-3.SIMD演算を用いたプログラム[matvec_simd.c]
#include<stdio.h>
#include<stdlib.h>
#include<math.h>
#include <nmmintrin.h>
#include <smmintrin.h>
#include <emmintrin.h>
#include <xmmintrin.h>
#include <mmintrin.h>
#define N 512
#define MSOL 3
int MATVC1(float A,float B,int NSOL,int ITER);
typedef struct{
float H[N][N];
float V1[N];
float V2[N];
float EG[MSOL];
}CMNLEG;
int main(){
float A,B;
int NSOL,ITER;
A = 1.0;
B = 1.0;
NSOL = 3;
ITER = 2000;
MATVC1(A,B,NSOL,ITER);
return 0;
}
int MATVC1(float A,float B,int NSOL,int ITER){
float E,F,S,T;
int I,J,K,L,i,j;
float E0 =0.0;
CMNLEG *CMN;
CMN = (CMNLEG *)malloc(sizeof(CMNLEG));
__m128 *h,*v1,*v2,*eg,*temp,*tempT;
float zero[N];
float *Ttemp;
/*動的に配列を確保出来なかったら終了する*/
if(CMN == NULL){printf("failure");return -1;}
if(NSOL > MSOL)return 1;
printf(" MULTIPLY %d*%d REAL MATRIX TO BECTOR %d * %d TIMES.\n",N,N,(int)NSOL,(int)ITER);
for(i=0;i<N;i++){
zero[i] = 0.0;
}
h=(__m128*)zero;
v1=(__m128*)zero;
v2=(__m128*)zero;
eg=(__m128*)zero;
temp=(__m128*)zero;
tempT=(__m128*)zero;
/*10 配列の初期化*/
for (I=1;I<=N;I++){
CMN->H[I-1][I-1] = (float)I - A/(float)I;
for(J=1;J<=I-1;J++){
CMN->H[I-1][J-1] = B/(float)((I-J)*(I-J));
CMN->H[J-1][I-1] = CMN->H[I-1][J-1];
}
}
/*10 END*/
h=(__m128*)CMN->H;
for(L=1;L<=NSOL;L++){//80
F = sqrt(6.0/(float)(N*(N+1)*(2*N+1)));
for(I=1;I<=N;I++){//20
CMN->V1[I-1] = F * (float)I;}
E = 0.0;
v1 = (__m128*)CMN->V1;
for(K=1;K<=ITER;K++){//60
S = 0.0;
for(I=1;I<=N;I++){//40
//30
//mull
for(j=0;j<N/4;j++){
temp[j] = _mm_mul_ps(h[(I-1)*N/4+j],v1[j]);
}
//mullend
//sum all
for(i=0;i<N/4/2;i++)
tempT[i] = _mm_add_ps(temp[i*2],temp[i*2+1]);
for(j=0;j<6;j++){
for(i=0;i<N/4/(2*(j+1));i++)
tempT[i] = _mm_add_ps(temp[i*2],temp[i*2+1]);
}
Ttemp = (float*)tempT;
Ttemp[0] = Ttemp[0]+Ttemp[1]+Ttemp[2]+Ttemp[3];
//sum all end
//30 end
CMN->V2[I-1] = Ttemp[0];
S = (S + (Ttemp[0]*Ttemp[0]));
}
E = sqrt(S);
F = 1 / E;
for(I=1;I<=N;I++)//50
CMN->V1[I-1] = F * CMN->V2[I-1];
}//60end
CMN->EG[L-1] = E;
for(I=1;I<=N;I++){//70
for(J=1;J<=N;J++){
CMN->H[I-1][J-1] = CMN->H[I-1][J-1] - CMN->V1[I-1]*E*CMN->V1[J-1];
}
}//70end
}//80end
printf(" LARGEST EIGENVALUES= %lf %lf %lf \n",CMN->EG[0],CMN->EG[1],CMN->EG[2]);
free(CMN);
return 0;
}
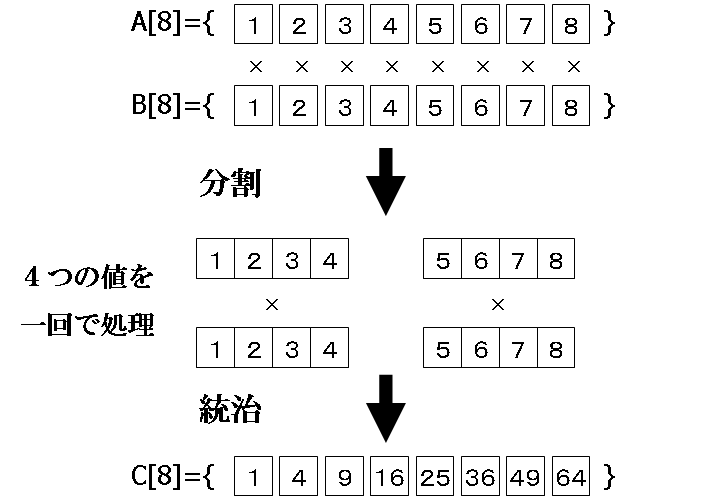 図1 分割統治法の例
図1 分割統治法の例