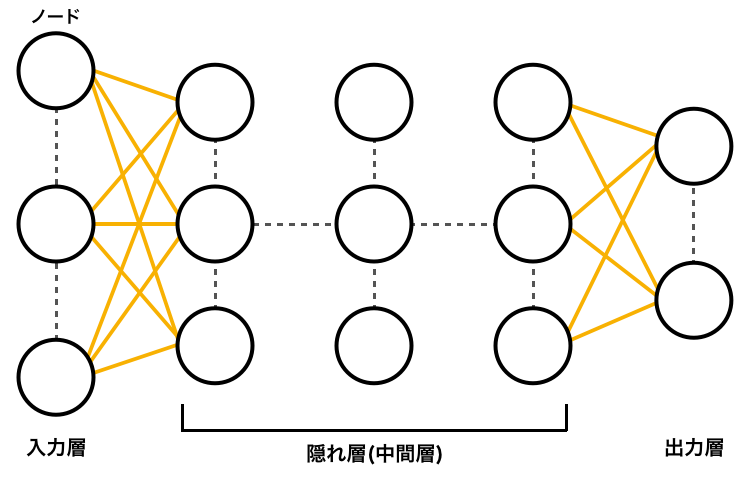
図1. ニューラルネットワークの例
東京電機大学工学部情報通信工学科
ネットワークシステム研究室
指導教員 坂本直志 教授
学籍番号 15EC043
氏名 木村大輝
ディープラーニング(深層学習)は、人間が行うタスクをコンピュータに学習させる機械学習の1つである。近年では画像認識技術の向上により、道路上の標識や人、車との車間距離を認識することができるなど自動化運転に実用化に大きな注目を集めている。また実生活においてはスマートフォンやスピーカーなどに音声認識技術が搭載されるなどIoT分野に貢献している。従来の技術では不可能であったレベルのパフォーマンスを発揮できるようになり、時には人間の認識精度を超えることもある。ところで、ディープラーニングが理論として登場したのは1980年代であるが、近年になって注目を集めるようになったのには2つの理由がある。
(1) 大量の学習データが必要
自動化運転には数百万の静止画像と数千時間の動画が必要である。近年のように大量なデータを入手することが容易ではなかったため、今ほど高いレベルの認識精度を実現できなかったが、インターネットの普及やSNSなどから誰もが気軽に画像や動画をできるようになりこの問題は解決された。
(2) コンピュータ処理能力
ディープラーニングには高度なコンピュータの処理能力が不可欠である。高性能なGPUは、ディープラーニングに効率的な並列構成になっており、クラスターやクラウドと組み合わせることで、これまでは数週間を要した学習時間を、数時間以下にまで短縮することができる。
しかし、現在においても学習に費やされる時間的コストは存在する。学習時間を短縮する方法としてハイパーパラメータの最適化はニューラルネットワークの学習において重要なテーマである。本研究ではハイパーパラメータの1つである「バッチサイズ」に触れ、学習速度の効率化について述べる。
本論文の構成は以下の通りである。
2章では本論文で用いる用語や技術についての説明、その定義について述べる。
3章では関連研究について述べる。
4章では本研究の実験概要と結果について述べる。
5章では4章で行った実験の考察について述べる。
6章では本論文を執筆するにあたり参考にした参考文献について述べる。
付録では本実験に使用したプログラムのソースコードの説明を記載する。
ニューラルネットワークは、入力層、隠れ層、出力層と3層を持ち、各層のノードは他の層の複数のノードと結ばれる構造となっている。隠れ層は複数の層を持つことができ、特に深い隠れ層を持つものを深層学習(ディープラーニング)と呼ばれる。各ノードには重みやバイアスなどのパラメータが存在する。学習から得た出力との誤差を比較しパラメータを修正していくことでより正解に近い学習を進める。
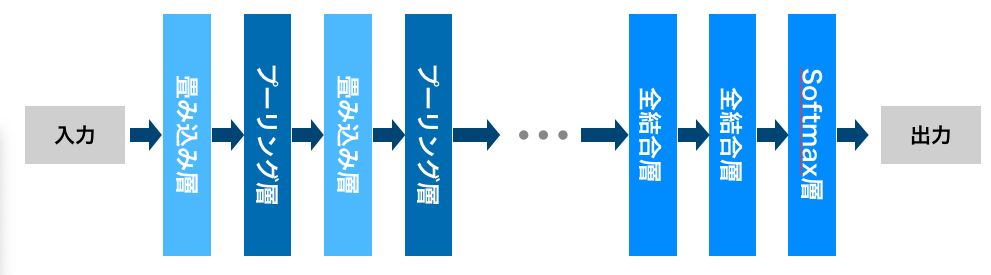
畳み込みニューラルネットワーク(Convolutional Neural Network)は一般的な順伝播型のニューラルネットワークとは違い、全結合層だけでなく畳み込み層(Convolution Layer)とプーリング層(Pooling Layer)から構成されるニューラルネットワークである。この2つの層が交互に学習を行い、最終的な計算を全結合層に集計するモデル構成となっている。CNNは、画像などから特徴の抽出するための検出器であるフィルタのパラメータを自動で学習させることができるため画像処理学習ではしばしば使用される手法である。
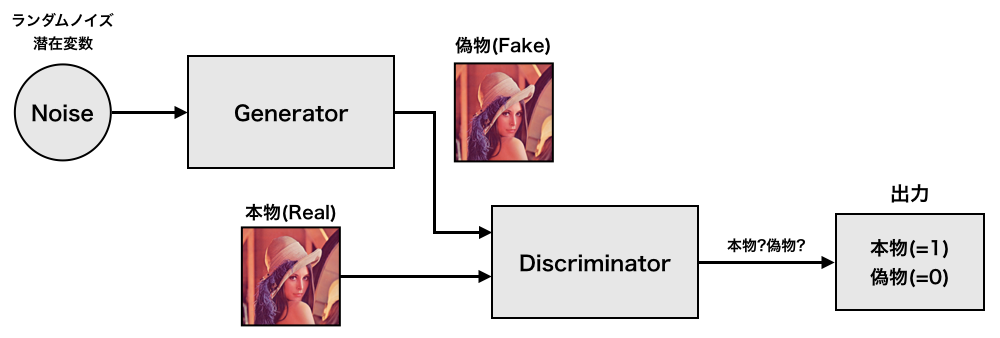
GAN(Generative Adversarial Network)は教師なし学習で使用される人工知能アルゴリズムの1つである。これは、生成器(Generator)と識別器(Discriminator)という2種類のネットワークを含む(図3)。
(1) 生成器(Generator)
潜在的変数と呼ばれる乱数(Noise)を入力し、訓練データと同じようなデータを出力することによって、判別機を騙すことを目的とする。
(2) 識別器(Discriminator)
入力されたデータが訓練データ(本物)から得られたものか、それとも生成器から得られたデータ(偽物)であるかを判別することを目的とする。
本研究の目的である画像生成を例とするならば、生成器が画像を出力し、識別器がその出力を正否を判別する。生成器は識別器を騙そう学習し、識別器はより正確に判別しようと学習する。このような2つのネットワークが相反する目的のもとに学習することから、敵対生成ネットワークとも呼ばれる。
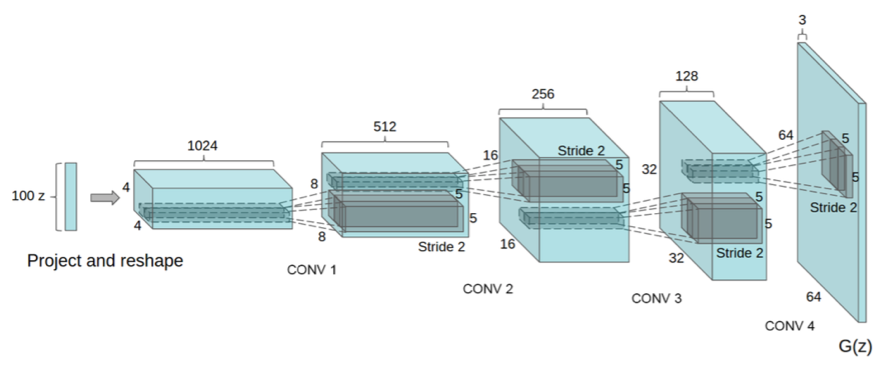
DCGAN(Deep Convolutional GAN)はCNNとGANを応用したモデルである。CNNは画像処理学習に大きな貢献しているモデルである。そのためGANでは難しかった画像生成をCNNと組み合わせることで高解像度画像生成に成功している。
また、DCGANはGANのモデル構造を安定させるために以下のような構造を採用している。
本研究はDCGANを採用し実験を行う。
(補足)
(1) Batch Normalization
Batch Normalizationは各ノードの重みを適切にパラメータ付けすることで、ネットワークを最適化するための方法の1つである。各ノードの出力をミニバッチごとに正規化した初期値に置き直すことで、内部の変数の分布が大きく変わるのを防ぎ、学習を早く進行させることができる。また、過学習を抑制する。
(2) ReLU関数
ReLU関数は活性化関数の1つである。入力が0を超えていれば、その入力をそのまま出力し、0以下ならば0を出力する。
数式で表すと式(1)のようになる。
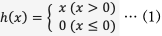
(3) Tanh関数
Tanh関数は活性化関数の1つである。出力範囲が-1から1の連続関数であり、出力の中心が0であることが大きな特徴である。
数式で表すと式(2)のようになる。
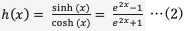
(4) LeakyReLU関数
LeakyReLU関数は活性化関数の1つである。ReLU関数に改良が加えられ、ノードにどの入力を受けても同じ値を返す問題を解決する。入力が負のときに傾きをもたせることで学習が停止してしまうことを防ぐという特徴がある。
数式で表すと式(3)のようになる。
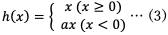
ソフトマックス関数はニューラルネットワークにおいて問題分類をする際に使用される活性化関数である。出力値の各要素の総和が1となるため、出力層の各ノードの値を確率として出力することができるという性質がある。ソフトマックス関数は以下の式(4)で表される。
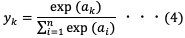
これは出力層が全部で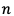 個あるとし、
個あるとし、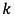 番目の出力
番目の出力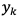 を求める計算式を表す。ソフトマックス関数の分子は入力
を求める計算式を表す。ソフトマックス関数の分子は入力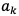 の指数関数、分母はすべての入力の指数関数の和から構成される。
の指数関数、分母はすべての入力の指数関数の和から構成される。
ハイパーパラメータとは、機械学習アルゴリズムの挙動を制御するパラメータである。特に深層学習では勾配法によって最適化しないパラメータに相当する。ハイパーパラメータが適切でなければ、訓練データ以外では性能を発揮できない場合がある。特に、深層学習はハイパーパラメータの数が多い傾向がある上に、その調整が性能を大きく左右すると言われている。
ハイパーパラメータの最適な値を求める方法は明確には存在しない。最適化を行う上で重要な点は、最適値を徐々に絞り込んでいくことである。範囲を徐々に絞り込んでいくというのは、初期値を大まかに範囲を設定し、その中から無作為にハイパーパラメータを選出し、そのサンプリングした値で精度の評価を行う。この過程を複数回繰り返し行い精度の結果を観察し、その結果ハイパーパラメータの最適値をの範囲を狭めていくことが最適化の手段である。
バッチサイズはハイパーパラメータの1つである。2.6章でも述べたように、学習性能に影響する要因である。
通常、ディープラーニングの学習では、データセットを幾つかのサブセットに分けて学習する。幾つかのサブセットに分けて学習する理由は、学習する際に異常値の影響を小さくするためである。
そして、この幾つかに分けた、それぞれのサブセットに含まれるデータの数をバッチサイズと呼ぶ。
例えば、1,000件のデータセットを200件ずつのサブセットに分ける場合、バッチサイズは200となる。
バッチ学習は以下の式(5)で計算される。
ディープラーニングは学習時に、いかに正解に近い値になるようにパラメータの調整を行う。そのためには、学習過程で得られた答えがどのくらい正解と離れているか、その誤差を把握しなければならない。その誤差を指標で表すのが損失関数である。損失関数の1つとしてミニバッチ学習がある。
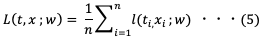
ミニバッチ学習では、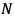 個の学習データがあるとき、無作為なバッチサイズ数
個の学習データがあるとき、無作為なバッチサイズ数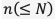 個のデータを用いて損失関数
個のデータを用いて損失関数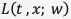 を求め、重み
を求め、重み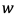 を更新する。学習データを
を更新する。学習データを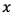 、学習データを
、学習データを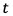 、
重みをとする。ニューラルネットワークを
、
重みをとする。ニューラルネットワークを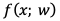 とすると、出力に対する 、による推定値
とすると、出力に対する 、による推定値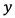 の誤差の大きさを表す損失関数は、と表記できる。
この損失関数がより小さくなるように重みを更新する処理を繰り返し学習を行う。
の誤差の大きさを表す損失関数は、と表記できる。
この損失関数がより小さくなるように重みを更新する処理を繰り返し学習を行う。
関連研究として、深層学習によるGANを用いた画像処理に関連して、早稲田大学飯塚氏らによる「ディープネットワークによるシーンの大域的かつ局所的な整合性を考慮した画像補完(GLCIC: Globally and Locally Consistent Image Completion)[3]」の研究について紹介する。
飯塚氏らの研究では、畳込みニューラルネットワークを用いて、画像の大域的かつ局所的な整合性を考慮した画像補完技術を提案している。提案研究では3つのネットワークを採用しているのが特徴である。一般的な画像処理を行う補完ネットワークでは全層が畳み込みそうで構成され、任意のサイズの画像における欠損部分を補完できる。この補完ネットワークに、シーンの整合性を考慮した画像補完を学習させるために、本物の画像と保管された画像を識別するための大域識別ネットワークと局所識別ネットワークを構築している。一般的なGANでは1つであった識別器を2種類に分けて画像を判別していることが大きな特徴であると言える。大域識別ネットワークは画像全体が自然な画像になっているかを評価し、局所識別ネットワークは補完領域周辺のより詳細な整合性によって評価する。この2つの識別ネットワークをGANをさせ、補完ネットワークを学習させることで、画像全体で整合性の取れた自然な補完画像を出力することができる。提案手法により、従来ではできなかった、人間などの複雑が画像や、入力画像に写っていない物体の生成も可能となった。

DCGANを使用し、画像の学習を行う。使用する画像はインターネット上に存在するアニメイラスト画像をOpenCVを利用した顔検出を行い、96×96にトリミングしたものである。使用する画像は14,491枚である。本研究では、バッチサイズを変更し、学習にどのように関係しているのかを考察し、また最適なバッチサイズの求め方について述べる。バッチサイズを128, 32, 16と3回に分けて学習を行い、「1エポックの学習速度」と「生成器と判別器の損失の推移」を調査する。各バッチサイズでの学習効率を比較し、最適なバッチサイズの絞り込みを目的とする。
はじめに学習データを用意する。本研究で使用するのはアニメイラスト画像である。収集にはインターネット上に存在するアニメイラスト画像をOpenCVを利用した顔検出を行い,96×96にトリミングしたものである。使用した14,491枚の画像は作者が統一されているわけではなく、年代も様々であるため、色彩などは統一されていない。また、インターネット上の膨大な数のアニメイラスト画像からトリミングを行ったため、顔以外にも文字、あるいは目的とする以外の顔などのノイズが含まれる。図7に使用した学習データのサンプルを示す。

実験で使用したモデル構成を表1.2に示す。
左から操作、カーネル、ストライド、チャンネル数、活性化関数の詳細を示している。
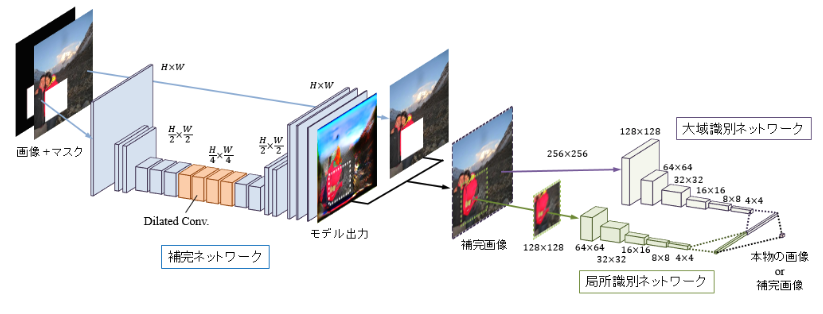
(1) カーネル
畳み込み層で行う処理は画像処理を例とすると「フィルター演算」に相当する。「フィルター」と言う用語は「カーネル」という言葉でも表現される。入力データに対し、カーネルを適用する。この例では、入力データは縦・横の形状を持つデータであり、カーネルも同様に、縦・横方向の次元を持つ。図8では入力サイズは4×4、カーネルサイズは3×3、出力サイズは2×2となる。
(2) ストライド


カーネルを適用する位置の間隔をストライド(stride)という。図9ではストライドが1であるが、ストライドを2にすると図10のようにカーネルを適用する窓の間隔が2要素ごとになる。
(3) チャンネル数
画像をデータとして扱う場合、通常は「高さ×幅×チャンネル」の行列形式で表現される。画像には1チャンネルと3チャンネルが存在し、3チャンネルとはRGBの情報を持つことを表す。また、1チャンネルとはグレースケールの画像を表す。
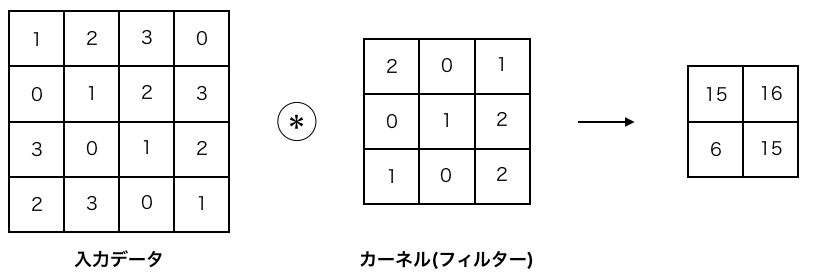
画像を生成するためのモデルであるのでDeconvolution(deconv.)層によって、逆畳み込みを行っている。カーネルは4×4、ストライドは2×2に固定する。
チャンネル数は一般的なDCGANの実装に従い、512 チャンネルから4層にかけて設定する。なお、2.4章のDCGANの安定化のため、生成器の活性化関数はReLU関数を使用する。
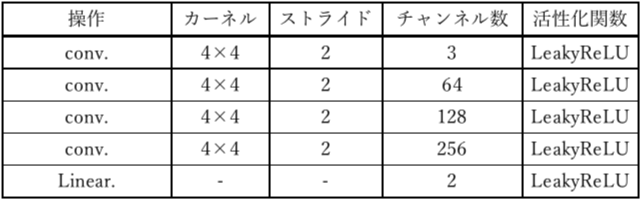
画像の判別を行うためのモデルであるので、画像の特徴量の抽出をする必要があるので、Convolution(conv.)層によって、畳込み演算を行うモデルである。カーネル、ストライドは生成器と同様である。2.4章のDCGAN安定化のために識別機ではLeakyReLUを活性化関数として使用する。
以上の構成を用いて、DCGANをPython3で実装した。実装したプログラム「DCGAN.py」の説明は付録で述べる。
実験結果から得られた、各バッチサイズの生成器と判別器の損失、1epochの学習時間をグラフ化し、図11,12,13に示す。
更に、学習結果から得られた出力画像を図14に示す。
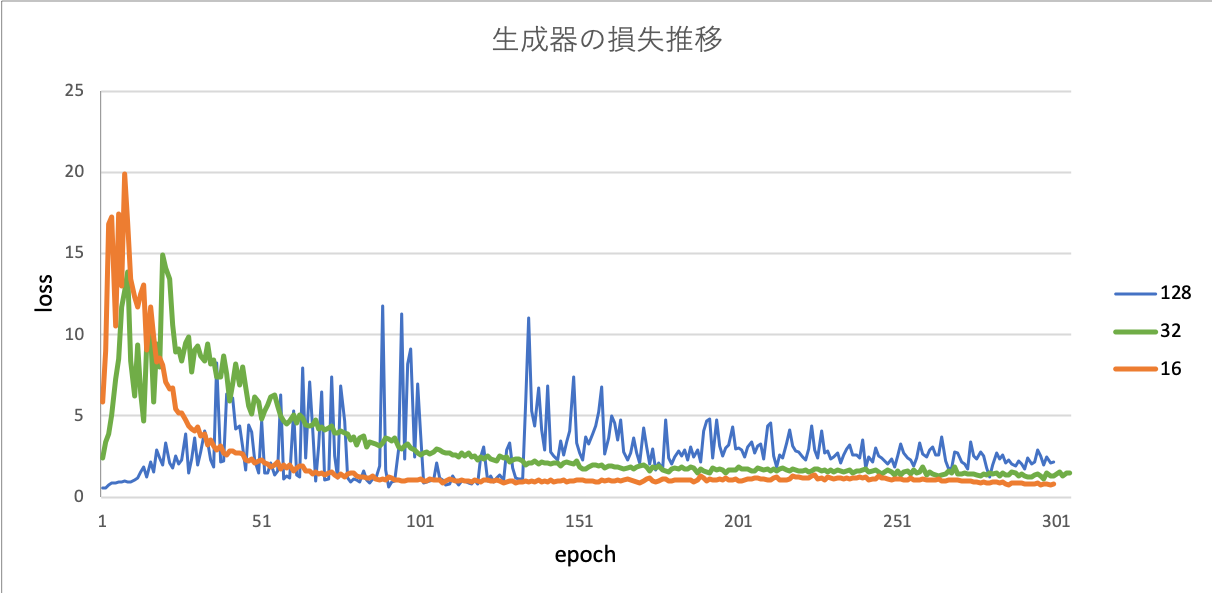
生成器は本物に近いものを生成したいので損失を1にすることが目標である。
バッチサイズ16,32に注目すると、早い段階で1に収束していることがわかる。さらに、epoch約25までは、大きな上下のブレも確認することができる。次に、バッチサイズ128に注目すると、徐々に上下のブレが大きくなっていき、epoch約160でようやく収束し始めることが確認できるが、最後まで損失は安定しないことがわかる。バッチサイズ16,32と128で大きな違いが見られた。
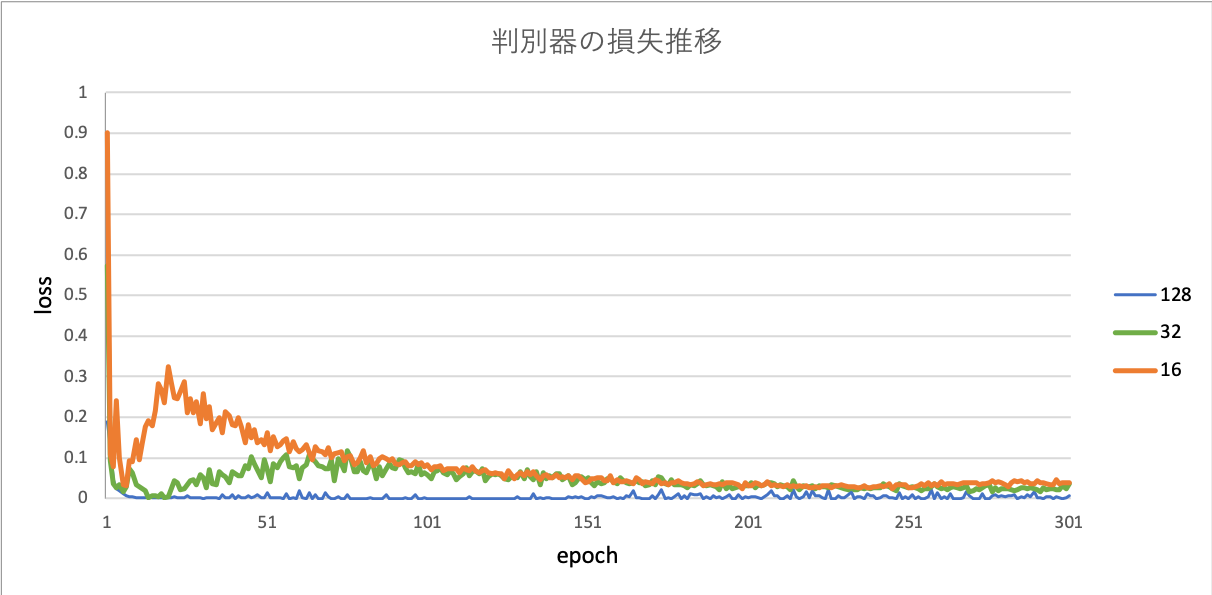
識別器は生成器から入力された画像が偽物であると判別したいので、損失を0にすることが目標である。
バッチサイズ16,32に注目すると、最初の方で損失が上がり、その後徐々に0に収束する様子が確認できる。しかし、バッチサイズ128では0に収束しているようだが、初めから限りなく0に近く、結果が正しいとは言えない。
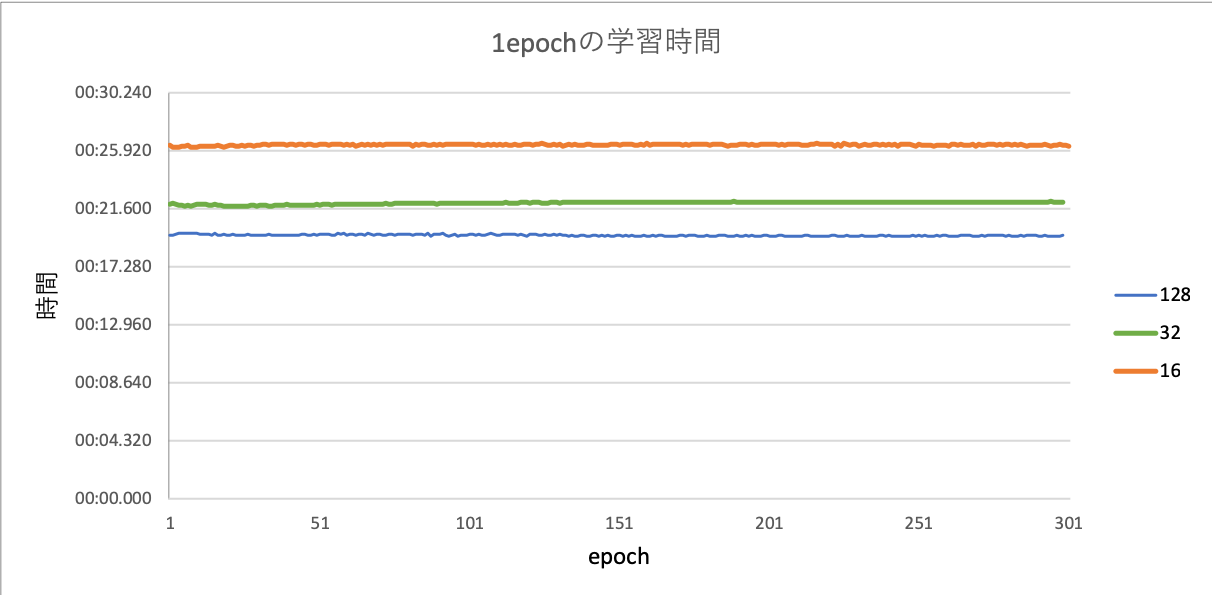
それぞれのバッチサイズにおいて、1epochでの学習時間が安定している事がわかる。さらに、バッチサイズを小さくするほど、学習時間が伸びることもわかる。

各バッチサイズを比較すると、明らかに128では画像が生成されていないことがわかる。16,32ではアニメイラスト画像であると人間が判断できるようには見えないが、目など髪型のようなものがわずかに生成されていることがわかる。
図11の生成器の損失推移について着目すると、バッチサイズは小さいほど損失の収束が速いことがわかる。これは、ミニバッチの単位で重みが更新されることから、平均をミニバッチ毎に取り、そのミニバッチ毎にパラメータを更新するため、ミニバッチの単位が小さければ小さいほど、訓練データ1つ1つに敏感に反応する、すなわち影響度が大きいと考えられる。反対に、ミニバッチの単位が大きいほど、その損失は平均化されるので、全体の特徴を捉えると言える。
また、これは学習速度にも関連していると考えられる。バッチサイズの単位が小さいほどパラメーターの更新頻度が大きくなり、学習時間が伸びていると思われる。
図12の識別器の損失推移について着目すると、バッチサイズ128では0に収束しているように見えるが、初めから限りなく0に近く、結果が正しいとは言えない。これが、図14の出力画像の結果からも分かる通り、正しく学習が進んでいないということがわかる。その原因として考えられるのは、訓練データの質が考えられる。4.1冒頭でも述べたようにデータの質は様々であり、かつデータ量が少ないのも少なからず影響しているのではないかと思う。バッチサイズ128においては300epoch目でほとんど何も生成されていないことから、少なくともバッチサイズ128以上は最適でないと言える。
バッチサイズを小さくするほど、時間的コストは削減できるが、学習収束速度は落ちることから一概に効率的になったとは言えない。この2つの面から最も効率的なパラメータを決定する必要がある。また、ハイパーパラメータの最適な数値は範囲を絞ることができる。検証データを使用し、絞った範囲でランダムにサンプリングを行う。出力精度を評価をし、最適なパラメータを探索することが最も効率的な最適化手法であると考える。
さらなる効率化を検討すると同時に、結果として得られる出力画像をも評価に値するものとできるように改善していきたい。
本研究で使用したプログラムDCGAN.pyの説明をする。
nz = 100
batchsize = 32
n_epoch = 500
n_train = 15000
weight_decay = 0.00001
本研究で使用するハイパーパラメータである。
batchsizeは16,32,128と変更させる。
fs = os.listdir(image_dir)
print(len(fs))
dataset = []
for fn in fs:
f = open('%s/%s' % (image_dir, fn), 'rb')
img_bin = f.read()
dataset.append(img_bin)
f.close()
本研究のデータセットはローカルディレクトリに保存されているため、image_dir変数に指定されているディレクトリからdataset変数へ格納する。
class ELU(function.Function):
def __init__(self, alpha=1.0):
self.alpha = np.float32(alpha)
def elu(x, alpha=1.0):
return ELU(alpha=alpha)(x)
ELUクラスはα値初期化の関数を記述している。
他にもCPUを使用した正伝播計算、CPUを使用した誤差逆伝播計算、GPUを使用した正伝播計算、GPUを使用した誤差逆伝播計算を行う関数がクラス内に存在するが、本研究では使用していないので割愛する。
Generatorクラスについて説明する。
def __init__(self):
super(Generator, self).__init__(
l0z=L.Linear(nz, 6 * 6 * 512, initialW=chainer.initializers.Normal(0.02 * math.sqrt(nz) / math.sqrt(10))),
dc1=L.Deconvolution2D(512, 256, 4, stride=2, pad=1,
initialW=chainer.initializers.Normal(0.02 * math.sqrt(4 * 4 * 512) / math.sqrt(10))),
dc2=L.Deconvolution2D(256, 128, 4, stride=2, pad=1,
initialW=chainer.initializers.Normal(0.02 * math.sqrt(4 * 4 * 256) / math.sqrt(10))),
dc3=L.Deconvolution2D(128, 64, 4, stride=2, pad=1,
initialW=chainer.initializers.Normal(0.02 * math.sqrt(4 * 4 * 128) / math.sqrt(10))),
dc4=L.Deconvolution2D(64, 3, 4, stride=2, pad=1,
initialW=chainer.initializers.Normal(0.02 * math.sqrt(4 * 4 * 64) / math.sqrt(10))),
bn0l=L.BatchNormalization(6 * 6 * 512),
bn0=L.BatchNormalization(512),
bn1=L.BatchNormalization(256),
bn2=L.BatchNormalization(128),
bn3=L.BatchNormalization(64),
)
詳しいモデル構造は表1に示す。
変数l0zでは入力ノイズnzに100次元の乱数ベクトルを入力。6*6*512次元の出力からバッチ正規化、同時にReLU関数計算が行われる。
Deconvolution層では512次元入力→256次元出力のように最終的に64次元での出力を行う。Deconvolution層も同様にバッチ正規化およびReLU計算を行っている
続いてDiscriminatorクラスについて説明する。
class Discriminator(chainer.Chain):
def __init__(self):
super(Discriminator, self).__init__(
c0=L.Convolution2D(3, 64, 4, stride=2, pad=1,
initialW=chainer.initializers.Normal(0.02 * math.sqrt(4 * 4 * 3) / math.sqrt(10))),
c1=L.Convolution2D(64, 128, 4, stride=2, pad=1,
initialW=chainer.initializers.Normal(0.02 * math.sqrt(4 * 4 * 64) / math.sqrt(10))),
c2=L.Convolution2D(128, 256, 4, stride=2, pad=1,
initialW=chainer.initializers.Normal(0.02 * math.sqrt(4 * 4 * 128) / math.sqrt(10))),
c3=L.Convolution2D(256, 512, 4, stride=2, pad=1,
initialW=chainer.initializers.Normal(0.02 * math.sqrt(4 * 4 * 256) / math.sqrt(10))),
l4l=L.Linear(6 * 6 * 512, 2,
initialW=chainer.initializers.Normal(0.02 * math.sqrt(6 * 6 * 512) / math.sqrt(10))),
bn0=L.BatchNormalization(64),
bn1=L.BatchNormalization(128),
bn2=L.BatchNormalization(256),
bn3=L.BatchNormalization(512),
)
def __call__(self, x):
h = elu(self.c0(x))
h = elu(self.bn1(self.c1(h)))
h = elu(self.bn2(self.c2(h)))
h = elu(self.bn3(self.c3(h)))
l = self.l4l(h)
return l
詳しいモデル構造は表2に示す。
Convolution関数は畳み込み層である。変数c0では3次元入力、64次元出力を行い、同時にバッチ正規化、ELU関数計算を行う。
最終的に変数l4lのLinear関数によって6*6*512次元入力から2次元出力を行っている。
続いてtrain_dcgan_labeled関数について説明する。
o_gen = optimizers.Adam(alpha=0.0002, beta1=0.5)
o_dis = optimizers.Adam(alpha=0.0002, beta1=0.5)
o_gen.setup(gen)
o_dis.setup(dis)
o_gen.add_hook(chainer.optimizer.WeightDecay(weight_decay))
o_dis.add_hook(chainer.optimizer.WeightDecay(weight_decay))
1,2行目ではAdamクラスを用いて、ハイパーパラメータのバイアス補正、すなわち最適化を行っている。
3,4行目のsetup関数では生成器、判別器のLinksクラスに最適化の準備をする。
5,6行目では、add_hook関数を用いて二重減衰などのパラメータの操作することで設定される。
x2 = np.zeros((batchsize, 3, 96, 96), dtype=np.float32)
for j in range(batchsize):
try:
rnd = np.random.randint(len(dataset))
rnd2 = np.random.randint(2)
img = np.asarray(Image.open(BytesIO(dataset[rnd])).convert('RGB')).astype(np.float32).transpose(2,0,1)
if rnd2 == 0:
x2[j, :, :, :] = (img[:, :, ::-1] - 128.0) / 128.0
else:
x2[j, :, :, :] = (img[:, :, :] - 128.0) / 128.0
except:
print('read image error occured', fs[rnd])
import traceback
traceback.print_exc()
break
はじめに初期値0の配列を生成し、x2に格納。
学習データの数の範囲内でランダムな数値をrndに代入、0か1の値をrnd2に代入する。
次にランダムに選択した学習データをRGBの3次元配列に変換し、さらぶtranspose関数で配列の形状変換を行う。次にimg配列を128で割り、正規化を行う。画像読み込みが失敗したときのために、例外処理を行う。
z = Variable(xp.random.uniform(-1, 1, (batchsize, nz), dtype=np.float32))
x = gen(z)
yl = dis(x)
L_gen = F.softmax_cross_entropy(yl, Variable(xp.zeros(batchsize, dtype=np.int32)))
L_dis = F.softmax_cross_entropy(yl, Variable(xp.ones(batchsize, dtype=np.int32)))
変数zには-1から1の間で一様分布の (100 x 100 )二次元のランダム値が代入される。
変数xに生成器からの出力を代入し、その出力xを判別器に代入する。このとき判別器の出力y1は「判別器が入力を生成器から出力されたものであると思う確率」を示している。すなわちDの出力が0であればデータセットからの出力、1であれば生成器からの出力と判断する。
次にソフトマックス関数を利用して、2つのモデルの損失を求める。y1とバッチサイズの数分並べた0とのソフトマックス関数計算を行い、L_genに代入。y1とバッチサイズの数分並べた1と同様に計算を行い、L_disに代入。
x2 = Variable(cuda.to_gpu(x2))
yl2 = dis(x2)
L_dis += F.softmax_cross_entropy(yl2, Variable(xp.zeros(batchsize, dtype=np.int32)))
cuda.to_gpu関数は変数x2の値をGPUデバイス上にコピーを行う。
次に、x2を判別器の入力としyl2を出力する。
生成器の損失にyl2とバッチサイズの数分並べて0とのソフトマックス関数計算から求めた損失を足し合わせる。
gen.cleargrads()
L_gen.backward()
o_gen.update()
dis.cleargrads()
L_dis.backward()
o_dis.update()
cleargrads関数では勾配の初期化を行い、backward関数で誤差逆伝播、さらにupdate関数でパラメータの更新を行う。