図1. HybridP2Pモデル
1章. はじめに
P2Pとは、ネットワークサービスにおいて、特にServerを必要とせず、Peer同士が直接通信しあうことでサービスを提供する仕組みである一方、ドメインネームシステム、WWW、電子メールなどは特定のServerを前提とするシステムなので、サービス提供は特定の操作が必要であり、そのため各Serverには管理者と呼ばれる特別なユーザを必要としている。
ネットワーク対応デバイスはどんな種類のものであれ、P2Pテクノロジを利用することによってほかのネットワーク対応デバイスに相互にサービスを提供することができる。P2Pネットワークのデバイスがアクセスを提供できるリソースは、その支配下にあるものであれば、とくに種類を問われない。こうしたリソースには、ドキュメントはもちもんのこと、記憶域、計算処理能力、さらにはオペレータも含まれる。P2Pテクノロジは「分散化による堅牢さ」といるインターネット本来の考え方を率直に延長したものである。インターネットは、何百台ものServerの間で責任を分担することによって、ドメインネームシステム、WWW 、電子メールなどのサービスを提供している。同じようにP2Pはインターネット上の至る所に散在しているリソースを活用することよって、まったく新しい堅牢なアプリケーション群を駆動させることができる。
P2Pのアプリケーションとして最初に成功したのはNapsterである。Napsterは、1999年1月に発表された、インターネットを通じて個人間で音楽データの交換を行なうアプリケーションソフトである。
このソフトはNapster社が管理する中央Serverに接続し、ユーザのパソコンに保存されているMP3形式の音声ファイルのリストを送信する。これを、世界中のユーザが共有することにより、互いに他のユーザの所持する音楽ファイルを検索し、ダウンロードすることができる。中央Serverはファイル検索データベースの提供とユーザの接続管理のみを行っており、音楽データ自体のやり取りはユーザ間の直接接続によって行われている。
登場当初はアメリカの大学で大流行し、回線への負担の大きさから利用を禁止する大学が続出し、話題となった。
また、Napsterで流通している音楽データの多くが市販のCDなどからの違法コピーであることから、Napster社が全米レコード工業会(RIAA)に事実上の運営差し止め(著作権つき楽曲データの発見と排除)を求めて提訴されるなど、社会現象化した。
Napsterは、多数の個人を直接つないで情報を共有する「P2P」と呼ばれるインターネットの新しい利用形態を提示した初めての大規模なサービスであり、これに刺激を受けて、アメリカでは政府や有力企業、団体を巻き込んだ大規模な論争が巻き起こっている。
一方、本来の意味でP2P(Pure)として広まったのはGnutellaである。Gnutellaはインターネットを通じて個人間でファイルの交換を行なうアプリケーションソフトである。
最初のバージョンは、AOL社に買収された旧NullSoft社のWinAMP開発チーム有志が、同社に黙って開発したもので、2000年3月にAOL社のWebサイトで公開されたが、同社によって24時間と経たないうちに公開停止となった。
現在「Gnutella」として出回っているアプリケーションは、この24時間足らずの間に(オリジナルの)Gnutellaをダウンロードしたユーザの手によって再構成されたものである。
Gnutellaユーザはインターネットを通じて相互に接続され、互いに自分の持っているファイルのうち、他のユーザと共有してもよいファイルのリストを公開する。Gnutellaで検索を行なうと自分以外のユーザの持っているファイルの中から条件に合うものを探し出し、そのユーザのコンピュータから直接ダウンロードすることができる。
ユーザ同士が直接ファイルの送受信を行なう点は「Napster」と共通しているが、GnutellaはNapsterと違って中央Serverを必要とせず、すべてのデータが各ユーザ間を直接流れる。このため、Napsterと比べて監視や規制を行なうことが極めて難しいのが特徴である。
また、NapsterがMP3形式の音声ファイルしか扱えないのに対し、Gnutellaはデータの種類に制限がなく、あらゆるデータを共有することができる。
Napster同様、Gnutellaネットワーク上にも多くの違法データが流通しており、著作権管理団体などから問題視されている。また、ユーザの意図しない無差別広告やコンピュータウイルスが流されるなど、様々な問題が指摘されている。
しかし、耐障害性やデータ更新の早さなどの点で、特定の管理システムを要求しないデータ共有システムとしてのGnutellaは高い評価を得ており、一部の開発コミュニティではGnutellaの技術を応用したWWW検索システムの開発を進めている。
2章. P2Pの説明
2.1 P2Pとは
通常のクライアント/Serverモデルにおいては、一方のコンピュータがクライアントとなり、他方のServerとなるコンピュータに命令を出し、Serverとなるコンピュータはクライアントの命令を実行し、結果をクライアントに返す。この場合、Serverにかかる負担がクライアントにかかるそれよりも重くなることがある。クライアント/Serverモデルの最もわかりやすい例はWWWの閲覧である。クライアントはWebページのURLを解釈して目的のServerを通信すると、WWWServerはそのページを探してその内容をクライアントに対して返す。これがクライアント/Serverモデルである。
一方P2Pはネットワーク上に複雑にPeerと呼ばれる端末同士が相互に通信しあい、相互にサービスを提供しあう。このため、情報を共有しあうようなサービスの場合は一つのコンピュータにアクセスが集中するようなことは起きない、つまり負荷分散が行えるということである。そのためP2Pに高性能なネットワークを与える必要はない。インターネット上のPeerが相互に倫理的に接続することにより、一種の論理的なネットワークが構成されている。このようなネットワークをヴァーチャルネットやP2Pネットと呼ぶ。
P2PではコンピュータはクライアントとServerの両方の役割を状況に応じて使い分ける事が出来るのである。ここがクライアント/Serverモデルと異なって2台のコンピュータの関係が対等であるという事がわかるであろう。P2Pモデルの特長は、処理が分散して行われるために負荷が少なく回線が細くても良い点や、匿名性が高いので機密性が高いという点が挙げられる。
2.2 P2Pの種類
2.2.1 HybridP2P
このP2PモデルはServerを常には必要としません。ただ、いくつかの管理的なことをさせるためのServer機能が、このP2Pモデルには存在する。ただし、モデルのServerの役割とは、新規参入したPeerに、すでに接続されているPeerの名前を提供する機能に限られている。Server機能は、Peerに接続する相手のリストを提供し、接続開始時からジョブ実行時まで接続処理を行うことだけに限定されている。このP2Pモデルは、ネットワークにすでに接続されているより多くのPeerをみつけるチャンスを増やすためのリストを提供できるという点で、PureP2Pを凌いでいる。リソースをダウンロードする際には、Peerは接続された他のPeerにそれぞれ接続してリクエストを送る必要があるため、その分CPUの処理時間を消費することになる。このモデルにいては、Server自体に全ての要求内容が保存されるので、リソースを検索するために、Peer自身が他の接続されているPeerを探し回る必要がありません。
2.2.2 PureP2P
PureP2Pはコンピュータに完全に依存する。古典的なクライアント/Serverキテクチャのいずれのネットワークモデルにおいても、コンピュータはServerにもクライアントにもなりうるので、このことは矛盾しているように聞こえるかもしれません。しかし、PureP2Pでは中央に配置されたServerには頼らずに作動する。いったんマシンのメモリー上にP2Pアプリケーションが読み込まれると、それぞれのPeerは、ネットワーク上に接続されたPeerをダイナミックに探しはじめる。通信はすべて、Serverによるサポートなしに、接続されたPeer間でおこなわれる。ここで要る通信とは、ファイルのアップロードおよびダウンロードによるデータの転送、オンライン状態の通知、リクエストの送信、レスポンスの受信、などをいう。
PureP2Pモデルの持つこの機能は、クライアント/ServerモデルにおけるクライアントとServer間のすべの通信プロセスが、Serverセットがおかれている場所のルールに基づくという、従来の通信方法を打ち砕きました。PureP2Pモデルにおいては、自分たちのルールやネットワーク環境はユーザ自身できめることができる。このP2Pモデルでは、インターネットを利用する場合に頭痛のタネであった、ServerやISPの一部であることから完全に解放されることになる。
PureP2Pにおいての唯一の問題は、ネットワーク上のPeerを見つけなければならない事です。ネットワークにログイしてきたPeerの参入を登録する中央集権的なものが存在しないため、ユーザ自身で他のPeerの位置を探し出す必要がある。
P2PにはhybridP2PとPeerP2Pがある。hybridP2Pは、Server/クライアント方式とP2Pを組み合わせたもので仕組みは簡単ですが、Serverを必要とする。一方pureP2Pは、Serverを必要としないが仕組みが複雑になる。ここではHybrid, Pureのそれぞれの有効なシステムを紹介する。
・HybridP2P
Napster
検索機能を実行するための中央ServerからなるNapsterは、ハイブリッドなP2Pネットワークであり、1つのランデブーPeerと複数の単純Peerから構成され、ネットワークトランスポートとしてTCPが使用されているモデルとして捉えることができる。Napsterの単純Peerはランデブービアを利用して、ファイル名とIPアドレスとポート情報とからなるMP3ファイルアドバライズメントを見つけることができる。単純Peerはこの情報を使って、ファイルホストPeerに直接接続し、ファイルをダウンロードする。
Napsterは、ファイアウォールを迂回する完全なソリューションを提供するわけではなく、1つファイアウォールを通過できるだけである。それぞれのPeerは単純Peerとして振る舞い、HTTPを通じて要求が出されたときにファイアウォールの背後にいるPeerにコンテンツを送ることができる。Napsterはメッセージルーティング機能を提供しない。つまり、Napsterはメッセージルーティング機能を提供しない。つまり、Napsterの単純Peerは、ほかのPeerが2つのファイアウォールを通過するのを助けるためのルーターPeerとして振る舞うことができない。
NapsterはMP3の拡張子だけが対象であり、ユーザが何か楽曲を探そうと思った時には、ナップスターユーティリティを開くことになる。ナップスターはユーザのインターネット接続経由で、中央のServerにログインする。この中央のServerはオンライン状態にある全ての正規ユーザ分のインデックスを保持する。同時にユーザのマシンに格納されているMP3音楽ファイルのディレクトリ情報も保持される。これらのディレクトリ情報は、ユーザがナップスターServerにログイン/ログアウトするたびに更新される。
あなたが欲しい局を検索するリクエストを送信すると、中央ナップスターServerはオンラインユーザのインデックスからその曲を検索し、その曲を所有しているオンラインユーザの一覧を表示する。
あなたは、その一覧から誰かを選んでクリックすれば、そのユーザとダイレクトに接続することができる。中央Serverはあなたとユーザを接続した後は介在しません。ファイルは所有者からあなたに向かってダウンロードされ、ファイル自体は決してナップスターServerには保持されません。
・PureP2P
Gnutella
Gnutellaはネットワークでは、それぞれのPeerがメッセージトランスポートにTCPを使いファイル転送にHTTPを使って、単純Peer、ランデブーPeer、およびルーターPeerとして振る舞う。ネットワーク上での検索は、PeerからそのPeerが知っているすべての近隣Peerに伝達され、それらのPeerからさらにはかのPeerにリレー伝達される。Gnutellaネットワーク上でのコンテンツのアドバタイズ免とは、IPアドレス、ポート番号、ホストPeer上でファイルを識別するインデックス番号、およびファイル詳細が含まれる。GnutellaのPeerは完全なルータPeer機能を提供していない。つまり、Napsterと同様、GnutellaのPeerも1つのファイアウォールしか通過できない。
GnutellaはまさにPureP2Pモデルの働きをする。Gnutellaはダウンロードされ、ユーザのコンピュータにインストールされる。インストールされると、まず、インターネット上に構築されたグヌテラネットワークにおいて、接続されている他のコンピュータに対して、自分の存在を示すためにメッセージが送信される。メッセージは、「ネットワークに接続する」→「1台のコンピュータに通知する」→「そのコンピュータは他の10台のコンピュータに通知する」→「それら10台のコンピュータがそれぞれ9台以上のコンピュータがそれぞれ9台以上の別のコンピュータへ通知」という手順で次々に転送されている。
Gnutellaはファイル共有サービスと、小型のサーチエンジンと持つクライアントベースのソフトフェアです。いったんGnutellaをユーザのローカルなマシンにインストールすれば、ユーザは他のマシンから要求に応答することができる。ユーザは直接それらのマシンからコンテンツをダウンロードすることもできる。Gnutellaの検索機能は、他のサーチエンジンとほぼ同じですGnutellaはネットワーク上のプロセスとして動作し、何かリクエストを出したユーザを表示する。Gnutellaでは、中央に配置したServerによる検索ではなく、ユーザのコンピュータ間での直接検索がおこなわれるため、より便利で使いやすいものとなる。データ検索者の立場から見て、ネットワーク上では多くのデータ提供者が存在するが、どのクライアントが要求をちゃんと実行しくれるかの確信はありません。逆にデータ提供者の立場から見ても、検索結果のすべてをあなたが受け取っている保証もありません。
しかしながら、その優れたファイル共有システムのおかげで、Gnutellaは確かに他のP2Pモデルとは一線を画している。ナップスターでは、そのユーザたちに中央Serverに集められた音楽ファイルを共有することをサポートするが、Gnutellaではそれに留まらず、MP3から実行ファイルまであらゆる種類のファイルを、Serverなしで共有する事ができる。
2.4 P2Pに関する簡単な歴史
P2Pは最近急に出現したものではなく、ずっと以前から存在していました。しかし、その存在が常にきちんと認識されていたわけではありません。たとえば、固定または解決可能なIPアドレスを持つServerは、ほかのServerと通信してサービスにアクセスする能力をずっと持っていたので、こういったServerのネットワークは一種のP2Pでたった、といえる。電子メールやドメインネームシステムなどのP2P以前のアプリケーションは、こうしたServerの能力に基づいてネットワークを提供してきた。そうしたアプリケーションの中でひときわ目立つのがUsenetである。
Usenetは1979年にノースカロライナの2人の大学院生、Tom Truscott とJim Ellisによって、2つのコンピュータ間で情報の交換する手段として作られました。インターネット接続が普及する前の時代のことである。彼らが最初にやったことは、1つのコンピュータが別のコンピュータにダイヤルし、新しいファイルがかるかチェックし、それらのファイルをダウンロードする、といった処理を行えることだった。これは長距離電話料金を節約するために夜間に行われた。この2人の大学院生のシステムが発展して、今日のような堂々たるミュースグループシステムになったのです。しかし、たとえ大きくても、Usenetは最初のP2Pアプリケーションと呼べるような性格をいくつか備えている。Usenetには中央管理オーソリティが存在しない。コンテンツの配布は各ノードで管理され、Usenetネットワークのコンテンツはノード全体に複製される。
Usenetの最もおもしろいところは、Usenetを構成するものがソフトウェアでもなければServerのネットワークでもなく、Usenetの構成自体というものが存在しないことである。もちろんUsenetは動作するのにソフトウェアとServerを必要とするが、こうしたものがUsenetを特徴づけているわけではない。Usenetは、ネットワーク上でニュースメッセージを投稿/配布するためにマシンどうしが通信する方法にほかならない。Usenetでは、ネットワークミューストランスポートプロトコルといる明確に定義されたプロトコルによって、可能な限り多くのマシンが自由にサービス提供に参加できるようになっている。この責任分担がUsenetを特徴づけるものであり、この特性があるからこそ、Usenetは未熟ながらP2Pテクノロジの最初のアプリケーションだといえるのである。
1980年代は、「オレたちひょうきん族」などでコンピューグラフィックがTVの出演に使われた時代で、大型コンピュータにはテクトロニック端末のようなグラフィック専用端末が接続していることもめずらしくなかった。
また、SUN Microsystmsがグラフィカル機能を持つワークステーションを発売し、XwindowSystemも開発されていました。
また、シリコングラフィックスというグラフィック専用ワークステーションを専門につくる会社もありました。
PCをLANで接続することは80年代も普通に行われていました。Dos系はNetware,
AppleはLocal TalkやEthertalkがありました。
少し前までは、主にLAN,BBS,FTPという、既知のユーザ同士の閉じられた世界でファイルを共有する目的で同様なシステムが使われていました。もし未知のユーザとファイルを転送したければ、IRCまたは他のBBSを使う必要がありました。また80年代には、大型コンピュータは非グラフィカルユーザインタフェースでるという制約もありました。それゆえオンラインコンピュータを増加されるためには、PCをお互いに接続することよりもまず、新しい種類のServerコンピュータへ接続する方が重要であったといえる。
1994年まで、個人のコンピュータは固定的に割り当てられたIPアドレスを使ってしました。MosaicやNetscapeなどの新しいブラウザソフトウェアが、PCかWebにアクセスする手段として導入されました。これらのPCは、かつて大型コンピュータと違い、常時Webに接続されている訳ではありませんでした。Webユーザの爆発的な増加がIPアドレスの不足を引き起こし、ISPは新しいIPアドレスを時間で区切ってユーザに割り当てははじめたからです。それで、一時的なIPアドレスであったがゆえに、ユーザとってみれば、どんなデータも、またどんなWebアプリケーションも、それを公開する妨げとなりました。
Webのサービスに対する需要が増えた結果、ユーザはお互いが直接リソースをコントロールし交換し、共有することが必要だと感じるようになりました。一方では、1990年代後半なると、PCのスピードを処理能力は更に増大してきました。これらの事から、ソフトフェア開発者は、個々のPCでソフトフェアを導入し、ユーザ間で直接、双方向に情報をやりとりができるのではないかというこれに気がつきました。これによってP2Pが復興することになりました。
興味深いことに、IPルーティングの基本は現在でもP2Pであるといえる。インターネットルータは、ネット上のある地点から最適な経路を見つける際に、他と協調して動作する。この仕組みはまた、コンピュータの階層構造についてもあてはまる。ISPを使ってインターネットに接続するエンドユーザにとっては、階層構造が隠蔽されており、ISPと接続するだけでインターネットに接続できる。いわばISPも同じくP2P構造をもっているといえる。同様に、特定相手向けメールServerのネットワークが、電子メールの起源でした。1999年から2000年ごろ、Napsterがインターネット上で音楽共有する方法で革命をおこした際、人々はP2Pの本当の可能性を理解しはじめました。Napsterは、P2Pによる手段におけるはじめての営利的な大成功だったといえる。
3章. 製作したソフトについて
本研究ではP2Pの学習評価のために簡単なP2Pシステムを構築しました。これらの製作したソフトについて説明する。
3.1 HybridP2Pソフトについての説明
3.1.1 機能
HybridP2Pではファイル共有を行うためにPeerは次の機能を有しする。
・終了:プログラムを終了する。
・検索:Serverにアクセスし、自分が所有するファイル名を送信する。
その後にServerが保持しているファイル名及びそのファイルの有るアドレスを受信する。
・ファイルリスト出力:検索で得たファイルリストを出力する。
・ファイル要求:検索で得たファイルリストから欲しいファイルを選択し、そのファイルを得る。
3.1.2 操作方法
まず、最初にServerプログラムを起動する。このとき、ServerのIPアドレスを調べておく。
次に、PeerプログラムをServerのIPアドレスを入力し起動する。起動後は、検索、ファイル
要求を繰り返し行く。これによって目的のファイルを得ることができる。
3.1.3 起動画面例
・Serverプログラム
・Pureプログラム
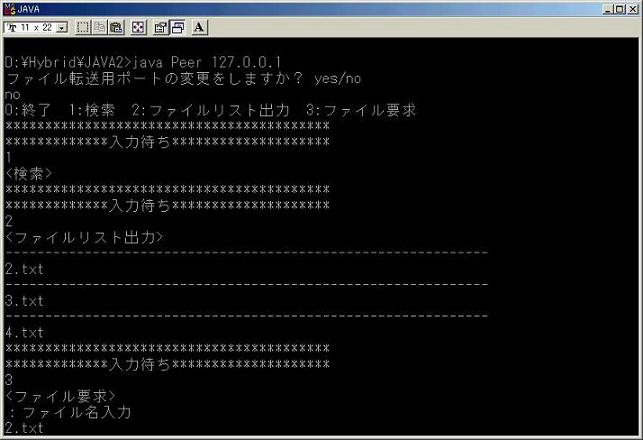
3.1.4 プログラムの説明
・Peerプログラム(プログラム全体は付録2にある)
3.1.5 プロトコルの説明
Step1:自分の持っているファイル情報をServerに転送する。
Step2:Serverが保持しているファイル情報をPeerに転送する。
Step1:目的のファイルを持つPeerに接続し、ファイル転送要求を出す。
Step2:要求のあったPeerに目的とされたファイルを転送する。
3.2 PureP2Pソフト
3.2.1 機能
PureP2Pではファイル共有を行うためにPeerは次の機能を有する。
・終了:プログラムを終了する。
・検索:自分が接続しているPeerを繋いでスッパニングツリーを形成し、
ファイル名及び、そのファイルの有るアドレスを得る。
・ファイルリスト出力:検索で得たファイルリストを出力する。
・ファイル要求:検索で得たファイルリストから欲しいファイルを選択し、
そのファイルを得る。
3.2.2 操作方法
Peerプログラムを起動させる。その後は検索、ファイル要求を繰り返す。
それによって目的のファイルを得る。
3.2.3 起動画面例
・Peerプログラム
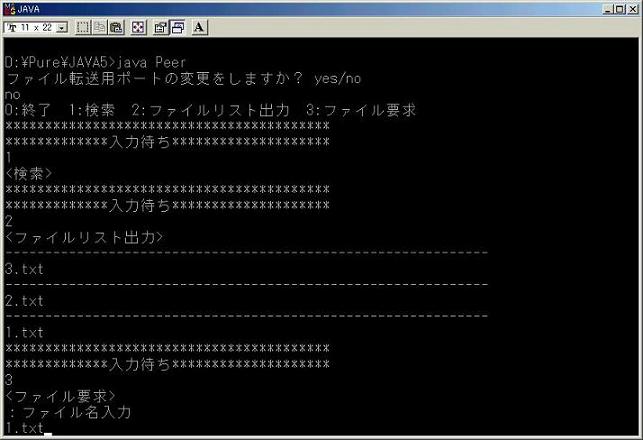
3.2.3 プログラムの説明
・Peerプログラム(プログラム全体は付録3にある)
30行目:max_u は相手に同時にファイルを送信できる最大数。初期値は2に設定して
いる。これを超えるとファイルを転送することは出来ません。
31行目:max_d は相手から同時にファイルを受信できる最大数。初期値は2に設定して
いる。これを超えるとファイル要求をすることができません。
132行目〜190行目:相手からファイル要求が有ったとき、そのファイルを相手に送信する。
max_uを超える場合はファイルの転送は行いません。
192行目〜328行目:キー入力に対する処理を行う。1を入力すると検索、2を入力すると
ファイルリスト出力、3を入力するとファイル要求、0を入力
するとPeerプログラムを終了する。
416行目〜461行目:ここでの処理は、欲しいファイルを受信を行う。
463行目〜895行目:ここでは、キー入力で1の検索を受けて、スパニングツリーを構成し、
検索を行う。
3.2.4 プロトコルの説明
Step1:自分の知っている接続先に子になるように命令をする。
Step2:子になるように命令を受けると誰の子でもないのであれば、子になると接続先に
返事を返す。もし、誰かの子であれば、子にはなれないと返事と接続先に返事を返す。
Step1:頂点の親に自分の持っているファイルリストを転送する。
Step2:子に自分の持っているファイルリストを転送する。
4章 製作したソフトの比較
本研究で製作したHybridP2PとPureP2Pソフトを比較する。比較方法は、決められた数のPeerを起動させ、自分が所有するファイル以外を全て得るまでの時間を計り比較する。結果は次の表にまとめる。最初にPeerが所有するファイルサイズは15MBです。

これらの表の結果より、まとめのグラフを書く
結果について
まずは、開始時間誤差は完了時間よりも遥かに小さいので無視するものとする。結果では完了時間はHybridP2Pの方がPureP2Pよりも完了時間が早いことが分かる。この差については、考えてみると2つのプログラムでファイル転送の仕組みは2つとも同じなので、差が出たのは検索のおいての過程であると考えられる。今回の実験では、一定の時間毎で検索をするようにプログラムをしている。結果、HybridP2PではServerに常にアクセスできるのに対して、PureP2Pは他のPeerが検索をしているときに待ちが生じる可能性がある。このことにより結果に差が生まれたものである。また、この結果は今回製作したソフトでの差であるので、これからの改良などでこの結果は変化していくと思われる。
5章. まとめ
今回は、二種類のP2Pプログラムを作成し、比較してきました。HybridP2P、PureP2Pにはそれぞれファイルの検索方法などが違っている。HybridP2Pではファイル検索を行う際は、必ずServerが必要となっている。このために、Serverへの負荷がとても高くなってしまう。しかし、Serverに接続するだけで全てのファイルの場所を知ることができる。PureP2Pは、Serverを必要としません。このため、一点に多くの負荷が集中することがなく、負荷を分散することができる。しかし、ファイル検索の効率はHybridP2Pに劣る。それぞは、短所、長所を持ち合わせている。
製作したソフトを比較してきましたが、ファイル検索の方法は他にも多く存在する。HybridP2PとPureP2Pの比較ではHybridP2Pの方が優れていると結果をだしましたが、ソフトの製作方法によっては、それは大きく変わってくる。二つソフトを比較することは、一つのソフトのみで検討するよりも多くの事柄を知ることができました。
最後に、P2Pは、とても有意義なシステムであるが、近年ではP2Pに関連した問題がニュースなど取り上げられること多くなった。これは、P2Pソフトを使う側のモラルの低下が原因である。P2Pを使うについては、著作権を侵さないように注意していかなければならない。このように、P2Pの問題が取り上げられることは、P2Pの技術自体に問題があるように想われるのは残念なことである。P2Pの技術を向上させていくことは当然必要なことであるが、ユーザのモラルの向上も欠かすことが出来ない。
参考文献
題:P2Pアプリケーションデベロップメント
著者:ドリームテックソフトウェアチーム
翻訳:ジンジャーウェーブインコーポレーテッド
監修:竹田 寛郁
出版社:秀和システム. 2003年
題:JXTAのすべて―P2P Javaプログラミング
著者:Brendon J. Wilson
翻訳:倉骨 彰
翻訳:佐野 元之
出版社:日系BP社. 2003年
題:TCP/IP ソケットプログラミング Java編
著者:Kenneth L. Calvert
著者:Michael J. Donahoo
翻訳:小高 知宏
出版社:オーム社. 2003年
題:通信ネットワーク早わかり講座
著者:中村 正司
著者:磯部 直也
著者:小原 英治
著者:津田 志郎
編者:日系コミュニケーション編集
出版社:日系BP社. 2003年
サイト名:P2P for Java / JXTA
管理者:丸山不二夫
アドレス:http://www.wakhok.ac.jp/~maruyama/jxta/html/
サイト名:JXTAプログラミング
アドレス:http://yudoufu.velvet.jp/jxta.html
サイト名:JavaでHello World
アドレス:http://www.hellohiro.com/
サイト名:P2P File Sharing
アドレス:http://www.ksc.kwansei.ac.jp/researchfair02/03/website/intro-j.htm