
東京電機大学 工学部 情報通信工学科
ネットワークシステム研究室
指導教員 坂本 直志
15EC013 伊藤 聖弘
近年,AIの技術の注目がより一層高まっている.ゲームAIの分野では強化学習を用いた研究が数多く行われている.Google DeepMindによって開発されたコンピュータ囲碁プログラムであるAlphaGoではQ学習が使われており,人間のプロ囲碁棋士を対等条件で破った.Q学習は,ある状態における行動を評価し,得られる最も報酬が得られる方策を学習する.本研究では,二人零和有限確定完全情報ゲームである三目並べを対象とし,Q学習における最強プレイヤーとなる学習条件を調査する.
本論文の構成は以下の通りとなる.
2章においては本研究に用いる用語や,使用した手法についてまとめる.
3章においては本研究で用いるAIの概要と学習手法について述べる.
4章においては研究概要とその結果についてまとめる.
5章においては考察を述べる.
6章においては本研究のまとめを述べる.
7章においては参考文献を載せる.
8章においては本研究で使用したプログラム全文とその説明を行う.
ある環境内におけるエージェントが,現在の状態を観測し,取るべき行動を決定する学習を行う機械学習である.エージェントは行動を選択することで環境から報酬を得る.強化学習は一連の行動を通じて報酬が最も多く得られるように学習する.
ある状態sの下で行動aを選択する価値を学習する方法である.価値観数Qが与えられれば,ある状態sのとき価値Q(s,a)の最も高いaを最適な行動として選択すればよい.しかし,最初は状態sと行動aの組み合わせについて正しい価値Q(s,a)の値は分かっていない.Q学習では,得られる報酬により価値観数Qを学習する.価値Q(s,a)の更新式は,以下のようになる.
st,atは時刻tにおける状態と行動を表している. atによって状態はst+1に変わる.rt+1は状態変化によって得られる報酬である.maxの項は状態st+1の下で現時点で最も高い価値の値にγをかけたものであり,γは0<γ≦1のパラメータで,割引率と呼ばれる (0.9~0.99が多い) .割引率とは,将来もらえる報酬をどれくらい現在の価値として考慮に入れるかを表すパラメータである.ηも0<η≦1のパラメータで,学習率と呼ばれる (0.1程度が多い) .学習率とは,Q値の更新をどれだけ急激におこなうかを制御するパラメータである.
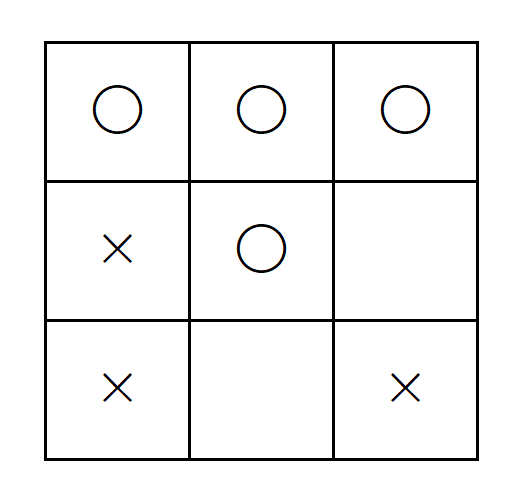
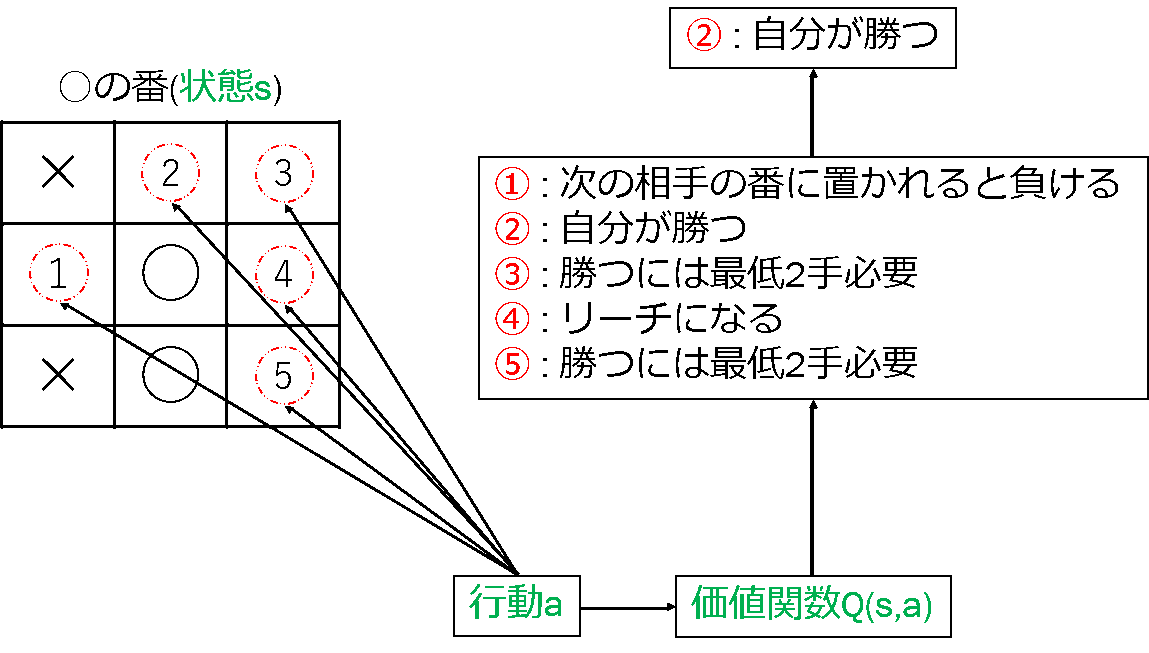
三目並べとは,3×3の盤面に〇と×を交互に書き,どちらかが縦・横・斜めのいずれかに3つ並べた方を勝ちとするゲームである.三目並べは,二人零和有限確定完全情報ゲームであるため,お互いに最善手を尽くすと引き分けとなる. 三目並べにおける価値は,あるマスを選択すると,将来的に得られる報酬がどれくらいになるか,を表している.報酬は,あるマスを選択したときに即得られる報酬であり,勝ちで「+1」,負けで「-1」とする.三目並べのQ学習では,得られる報酬を使いながら価値を更新する. 図2より,「〇」は①~⑤のどれかを選択できる.選択することが行動であり,行動によって得られる報酬から価値関数Qによって価値の高いものを選ぶ.②を選択すると,勝利が決まるため,価値の高い手となる.②を選択すればいいということを最初はわかっていないため,勝敗が決まった時に得られる報酬を使いながら学習する.
ランダムプレイヤーに対してQ学習で学習する.
初期盤面から,ランダムプレイヤーが「〇」,AIが「×」とし,勝負が決まるまで動かし,勝負がついたら勝負が決まったマスのQ値を更新する.riは0とする.Q値は盤面のパターン総数分(39行×9列)で作成する.勝負が決まったところで1回の学習とし,これを最大100万回行う.

基本的には更新された価値に従って行動が決定される.既に学習したパターンより,適切なパターンの行動を見逃してしまうことを回避するために,ある確率でランダムな行動をとらせている.その確率は,学習が進むにつれて徐々に小さくなるようにすることで,前半は幅広く学習し,後半はその結果を活用するようになっている.
Q学習を用いて三目並べの学習を行う.ランダム打ちプレイヤーを相手にしたとき,勝率が9割以上になる条件を調査する.
| 項目 | 環境 |
|---|---|
| OS | Windows 8.1 Pro 64bit |
| CPU | Intel Core i7-4790K 4.00GHz |
| RAM | 16384MB |
| GPU | NVIDIA GeForce GTX 980 |
| 項目 | 環境 |
|---|---|
| 言語 | Python 3.6.8 |
| 数値計算 | Numpy 1.16.4 |
最適な学習条件を探すために,学習回数,学習率,割引率の3つの変数を変化させ,勝率の変化を調査する.学習回数は勝敗や引き分けが決まった時を1回とし,100万回を上限とする.学習率は0.01,0.1,0.5,0.9の4パターン,割引率は0.1,0.5,0.9の3パターン,これらすべての組み合わせで学習させ,勝率が9割を超える学習回数を調査する.
全パターンの詳細を記載すると膨大な数になるため,詳細は一部のみ記載する.まず学習率0.1,割引率0.9で学習回数のみを変えた時の変化を示す.
| 学習回数 | 884,000 | 885,000 | 886,000 | 887,000 |
| Q学習AIの勝率 | 89.1 | 88.4 | 90.7 | 90.1 |
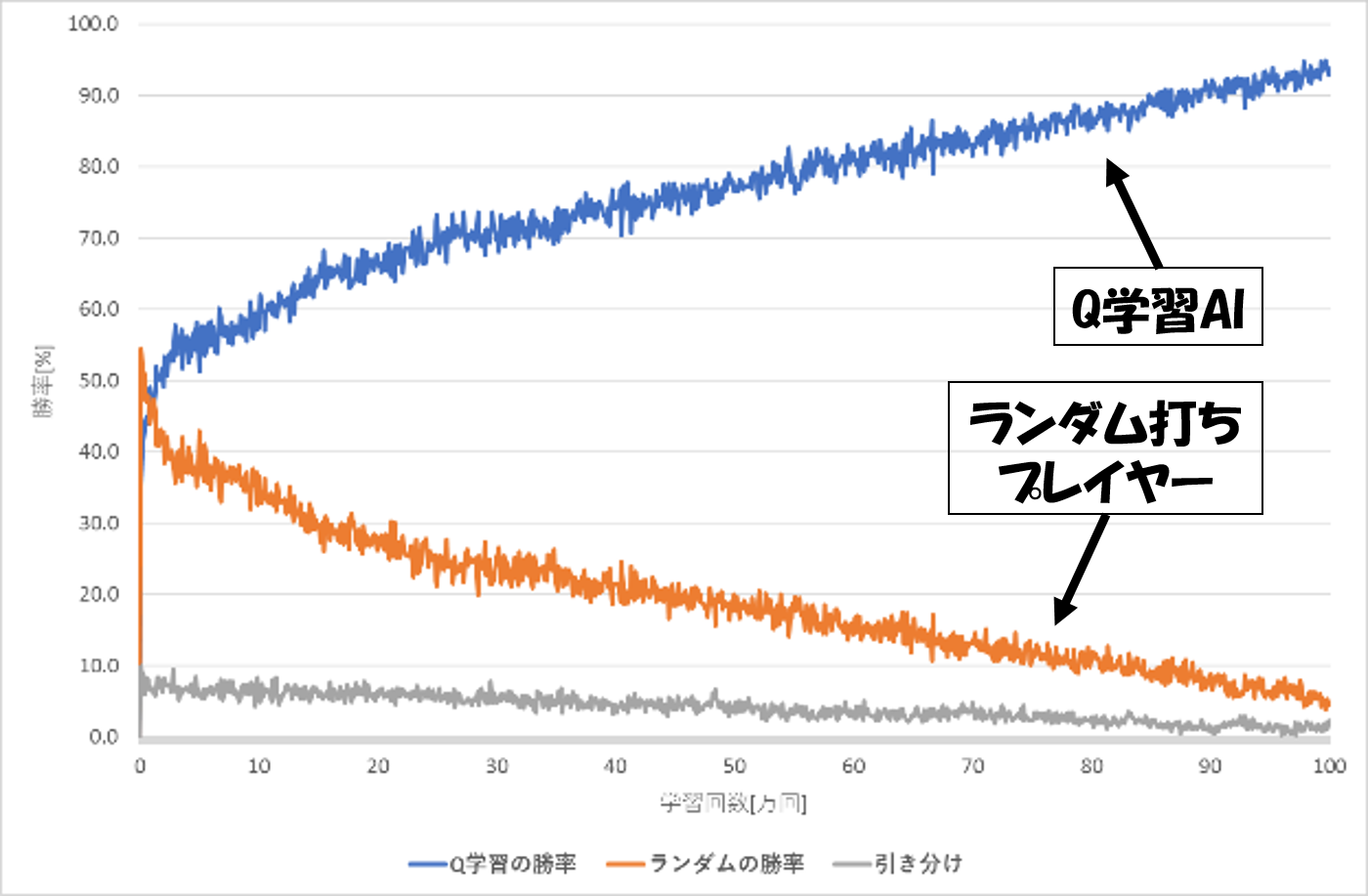
図3より,学習回数が増えるごとに勝率が高くなっていることが分かる.序盤ではランダム打ちプレイヤーの勝率がQ学習AIの勝率を上回っているが,3万回ほど学習した段階でQ学習AIの勝率がランダム打ちプレイヤーの勝率を上回った.
次に学習回数100万回,割引率0.9で学習率のみを変えた時の変化を示す.
| 学習率 | 0.01 | 0.1 | 0.5 | 0.9 |
| 最終的な勝率[%] | 89.4 | 92.9 | 92.3 | 89.3 |
| 学習回数 | 884,000 | 885,000 | 886,000 | 887,000 |
| Q学習AIの勝率 | 89.1 | 88.4 | 90.7 | 90.1 |
| 学習回数 | 982,000 | 983,000 | 984,000 | 985,000 |
| Q学習AIの勝率 | 89.2 | 88.4 | 90.4 | 94.9 |
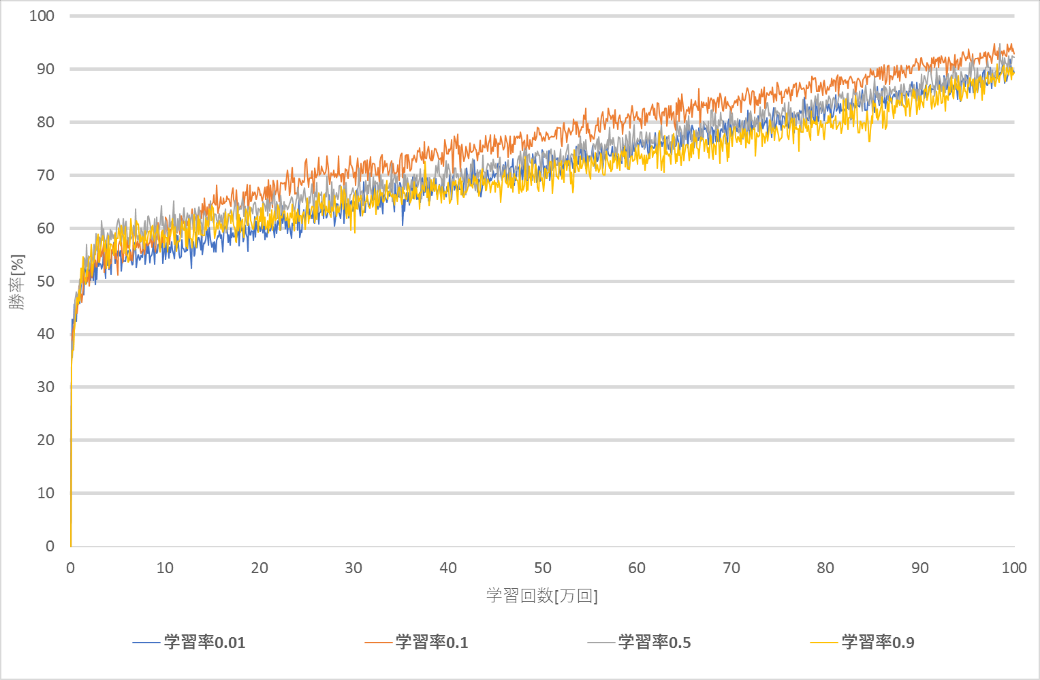
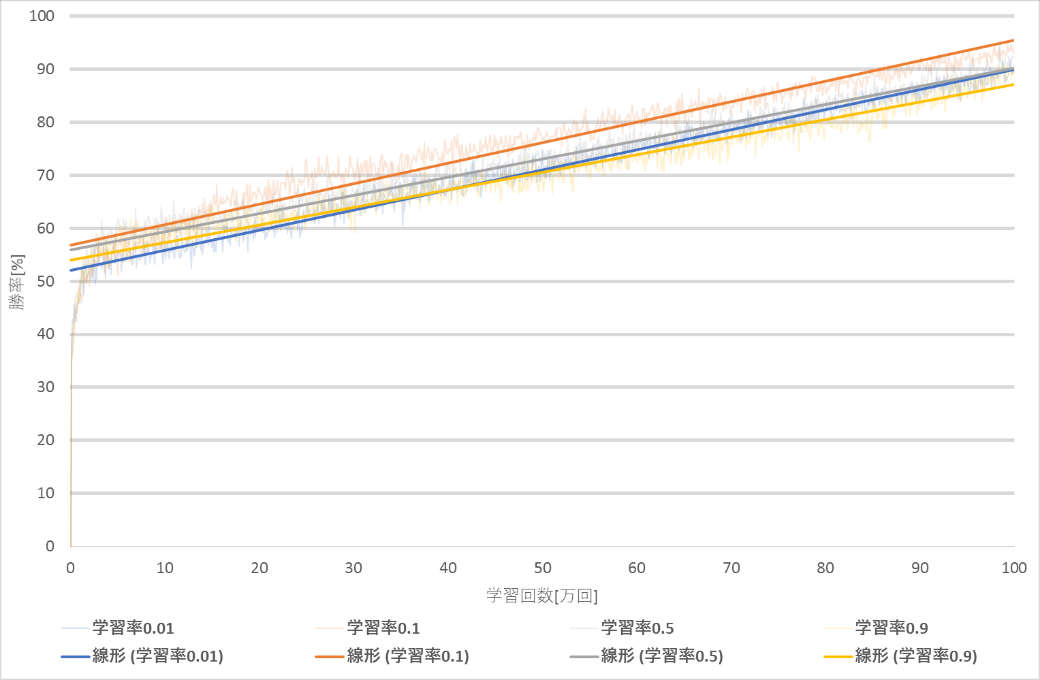
図4~図5より,勝率が9割に達するのが最も早い学習率は0.1となり,次点で学習率0.5となった.学習回数100万回では,学習率0.01,0.9は勝率9割に達することができなかった.
次に学習回数100万回,学習率0.1で割引率のみを変えた時の変化を示す.
| 割引率 | 0.1 | 0.5 | 0.9 |
| 最終的な勝率[%] | 88.5 | 91.8 | 92.9 |
| 学習回数 | 920,000 | 921,000 | 922,000 | 923,000 | 924,000 |
| Q学習AIの勝率 | 89.6 | 89.6 | 91.9 | 90.2 | 90.3 |
| 学習回数 | 884,000 | 885,000 | 886,000 | 887,000 | 888,000 |
| Q学習AIの勝率 | 89.1 | 88.4 | 90.7 | 90.1 | 90.6 |
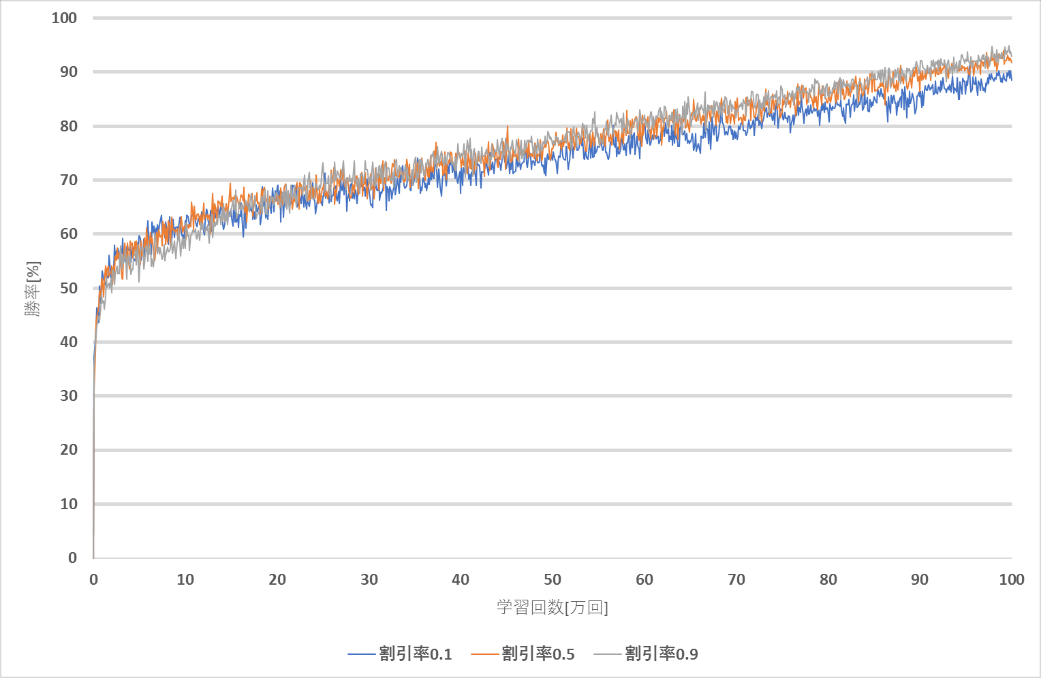
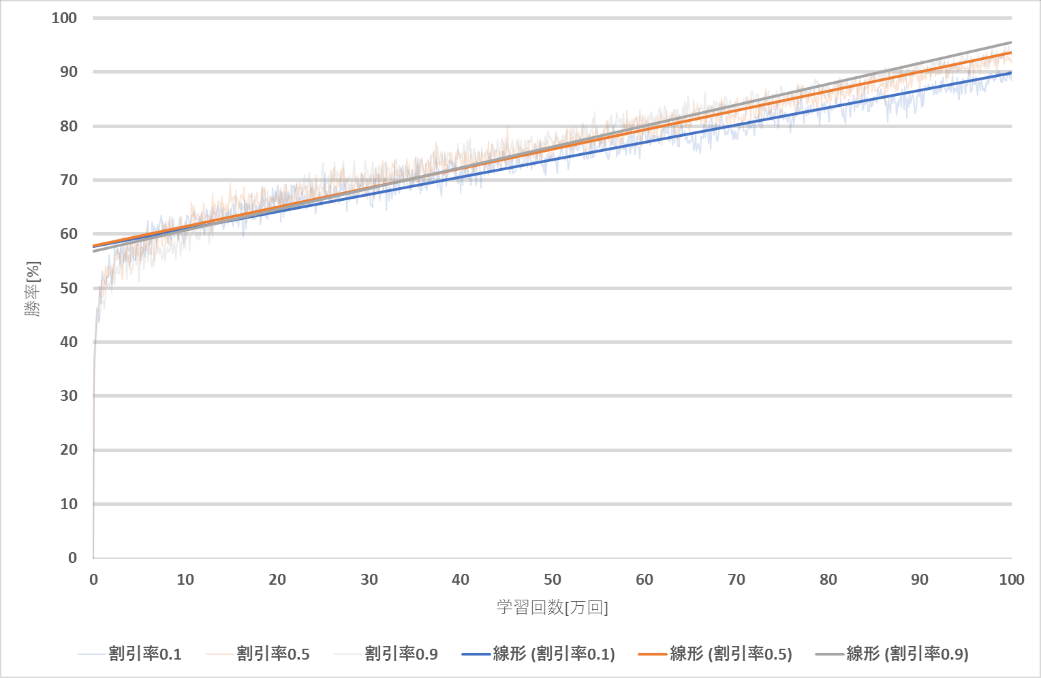
図6~図7より,勝率が9割に達するのが最も早い割引率は0.9となり,次点で割引率0.5となった.学習回数100万回では,割引率0.1は勝率9割に達することができなかった.
次に全パターンの勝率が9割に達した学習回数をまとめた表を示す.
| 割引率 | ||||
| 0.1 | 0.5 | 0.9 | ||
| 学習率 | 0.01 | - | - | - |
| 0.1 | - | 922,000 | 886,000 | |
| 0.5 | - | 961,000 | 984,000 | |
| 0.9 | 994,000 | - | - | |
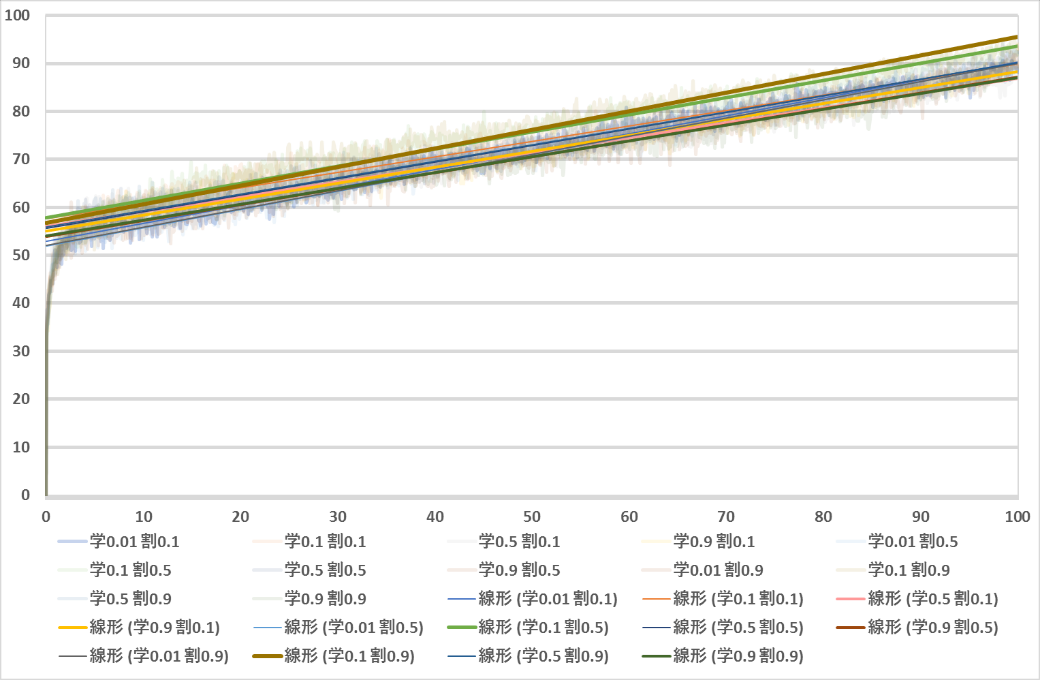
学習率と割引率として設定されることの多い学習率0.1と割引率0.9の組み合わせが88.6万回で勝率9割を超えた.次点では学習率0.1と割引率0.5の組み合わせが92.2万回で勝率9割を超えた.
本研究では,学習率は0.01,0.1,0.5,0.9に,割引率は0.1,0.5,0.9に限定したが,使用したプログラムでは,学習率や割引率がどうであれ,学習回数を増やすほど,勝率が上がっていくことが観測できた.割引率0.9で9割に達した学習率は0.1と0.5だが,その学習回数の差は約10万であり,同じく割引率0.5での差は,約4万回である.学習率0.1で9割に達した割引率は0.5と0.9だが,その学習回数の差は約4万回である.同じく学習率0.5での差は,約2万回である.このことから,学習率を変えることは割引率を変えることよりも重要度が高いことがわかる.
三目並べのパターン総数は3×3マスに「〇」「×」「未配置」の3つのどれかが入ると考えると,3^9=19683である.本研究での結果で,勝率が9割を超える学習回数が100万回に近い回数という,パターン総数と比べると大きな数になってしまうのは,ランダムに選ぶAIを相手にしているからではないかと考える.ランダムに選ぶということは学習済みのパターンも選ばれるため,全ての盤面を学習するのは確率的に試行回数が多くなってしまうと考える.
本研究では,Q学習を用いて三目並べプレイヤーを作成した.三目並べのような,簡単に見えるゲームであっても学習には時間がかかることが分かった.学習回数はやはり多ければ多いほど勝率が高くなり,学習率や割引率に関しては範囲内であればあまり大差はなかったが,学習率と割引率はよく設定される学習率0.1と割引率0.9が最速で勝率が9割を超える結果となった.今後としては,ランダムAIに加えて別のAIを使って学習させることで更に強いプレイヤーとなることが予想される.