図2.サンプルXML文書のDOMツリー構造
現在、Windowsを搭載したコンピューターに市販のソフトウェアを導入する際には、 インストーラーと呼ばれる専用の実行ファイルを用いてインストールを行うものが多い。 しかし、個人製作のソフトウェアでは、LZHやZIPといった書庫ファイル形式で配布し、 ユーザーが任意の場所に展開を行うことでインストールを行うという方式を採用しているものが数多く存在する。 また、新しいバージョンのソフトウェアが配布された際には、 その更新処理を各ソフトウェアが持つ独自の更新機能を使って行うものが多く、一元的に管理ができないという欠点がある。
これに対してLinuxでは、ソフトウェアを構成するファイル群を「パッケージ」として捉え、 コンピューター上にインストールされているパッケージと、パッケージの配布元に配置されている「メタデータ」と呼ばれる、 ソフトウェアについての情報を記述したデータを比較し、ソフトウェアの追加、更新、削除といった管理を行う「パッケージ管理システム」というものが存在する。 本研究では、このシステムをWindows上でも実現できないかと考え、 インストール・更新作業を容易にするソフトウェアを制作するにはどのような処理が必要かを検討し、テスト実装と評価を行った。
この章では、更新管理システムにおいてよく使われる用語を説明する。
Linuxでは、コンパイル済みのソフトのプログラム本体やドキュメントファイル、 インストール時に実行するスクリプトを一つのアーカイブファイルにまとめ、それを「パッケージ」という単位で扱うことが多い。 そのパッケージを管理するシステムのことをパッケージ管理システムと呼ぶ。
パッケージのインストール時には、パッケージの情報がパッケージ管理システムの持つデータベースに登録される。 更新や削除時には、その情報をもとにそれぞれの処理を行う。
かつてのLinuxではソースファイルから手動でコンパイル作業を行ってソフトウェアをインストールしていたが、 パッケージ管理システムの登場により、この作業が不要になり、ユーザーの負担が軽減されるようになった。
ある対象のデータについての抽象的な情報のことを指す。例えば対象がファイルであれば、ファイルの名前や種類、 サイズなどがメタデータに用いる項目として挙げられる。情報を抽象化することによって、検索や管理を効率的に行うことができる。
対象となるソフトと他のソフトとの関係を示す。例えば、「対象となるソフトが動作するためには、別のソフトやライブラリが必要である」といった関係や、 「対象となるソフトは特定のソフトと共存できない」といった関係がある。
XMLは、W3Cによって策定されている、 文章やデータの意味、構造を記述するためのマークアップ言語である。マークアップ言語とは、文章の一部を「タグ」と呼ばれる特別な文字列で囲うことにより、 文章の構造や、文字の修飾情報を文章中に記述する言語のことである。構造化された文書やデータのインターネット上での共有を容易にすることを目的に作られたものであり、 テキストデータで構成されているため、異なるシステム間での情報交換が容易に行える。 ソフト間の通信や情報交換に用いるデータ形式や、様々な種類のデータを保存するためのファイルフォーマットの定義にも使われている。 タグと文章が組み合わせて記述されているので、人間が直接読み書きすることも容易にできる。
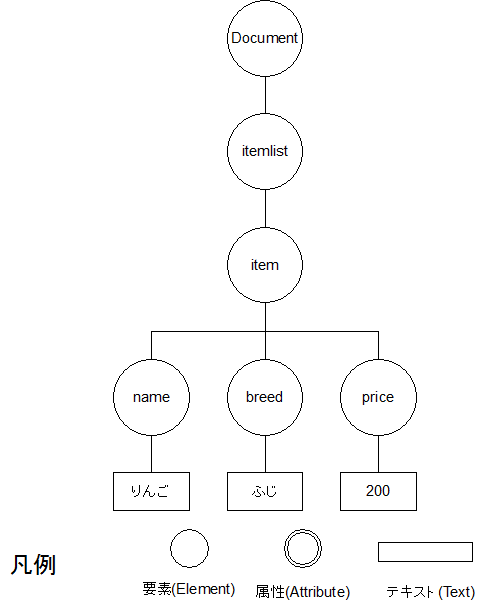
図1にXML文章の例を示す。XML文章では、ファイルの先頭にそのファイルの文章がXML形式で書かれていることを示す、「XML宣言」を表記する(図1の1行目)。 文章構造を構成する個々のパーツを「要素」と呼ぶ。この要素はタグを使って記述する。タグは要素名を"<>"で囲んだものであり、開始タグと終了タグがある。 終了タグには要素名の前に"/"をつける。そして、開始タグと終了タグで囲まれた部分が一つの要素となる。 このタグを入れ子にすることによってツリー状になった文章構造を再現することができる。 また、各要素は属性と属性値を持つことができ、属性と属性値は、開始タグの要素名の後に「属性名 = '属性値'」という形式で定義する。
XMLはメタ言語(言語を定義する言語)の役割を持っており、要素名や属性、文章構造をユーザーが自由に定義することができる。 これにより、ユーザーが定義した書式のXML文書を、ユーザーが作成したプログラムに読み込ませることができる。 一方、XMLでは要素が持つ意味やその関連性などについては定義できない。これについては、スキーマ言語を利用することでXML文書の構造を定義することができる。 スキーマ言語を利用すると、プログラム上のXMLパーサーに対して、XML文書がスキーマ言語で定義した構造に沿って正しく書かれているか調べさせることができる。 これを妥当性検証と呼ぶ。XML言語におるスキーマ言語には、DTDが広く利用されている。 XML形式に沿って書かれた文書を「整形式のXML文書」と呼ぶ。 これに加え、スキーマ言語によってXML文書の構文のチェックを行ったものを「妥当なXML文書」と呼ぶ。
DOMは、JavaやJavascriptなどのプログラミング言語から、HTMLやXMLを解釈するパーサーにアクセスするためのAPIの一つである。 現在W3CによりLevel 1〜3が策定されている。このLevelは規格のバージョンを表すものではなく、サポートする機能の程度を表すものであり、数字の大きい方が高機能である。
DOMはHTMLやXMLのドキュメントをDOMツリーと呼ばれるツリー構造として扱う。DOMツリーはメモリ上に展開され、一度読み込まれればドキュメント内の要素の順序に関係なく、高速にアクセスできる。 また、展開したツリー構造を変更することもできる。ただし、パーサーがドキュメント全体を読み込んだ後でなければ、文章内のデータにアクセスできないという点や、 ドキュメント全体を読み込むことにより、メモリを多く消費するという欠点もある。
例えば、図1のXML文章をDOMツリーで表すと図2のようになる。
<?xml version="1.0" encoding="utf-8"?>
<itemlist>
<item>
<name>りんご</name>
<breed>ふじ</breed>
<price>200</price>
</item>
</itemlist>図1.サンプルXML
図2.サンプルXML文書のDOMツリー構造
ここでは、現在実用化されている更新管理システムやインストーラーの例を取り上げる。
Windows Updateは、Microsoftの専用サーバーと通信を行い、必要なWindowsのアップデートファイルを自動でダウンロードし、インストールを行う。
初期の頃はOS本体とは独立した機能になっていた。これは、Internet Explorerというブラウザにより、専用のWebサイトに接続した後、ActiveXコントロールを通じて、既にインストールされた更新の情報をサーバーと通信することで更新チェックを行っていた。 しかし、Windows Vista以降のバージョンではOS本体に機能が統合された。以前の方法と同様にInternet Explorerから専用のWebサイトに接続しようとすると、コントロールパネルのWindows Updateが開かれ、それを使用するように促される。
Microsoft Updateは、Windows Updateの拡張機能で、Windows本体に加えて、Microsoft OfficeなどのMicrosoft製品の更新をサポートする機能である。この機能はオプション扱いとなっていて、機能の有効/無効をユーザーが切り替えできるようになっている。
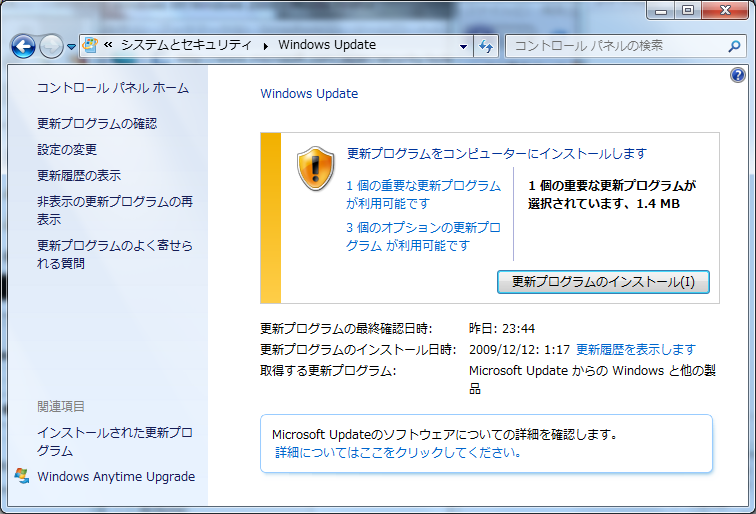
図3.Windows 7のWindows Update画面
Windows2000以降のWindowsには、Windows Installerと呼ばれる、アプリケーションをインストールするためのテクノロジーがOSに組み込まれている。
従来のインストーラーでは、配布者はインストーラーの動作をインストーラーのプログラムのコードに記述していた。ファイル形式は実行可能ファイル形式(EXEファイル形式)であり、 ユーザーがそれを実行すると、インストーラー自体がシステムに変更を加えていくという方法であった。
しかし、一方でWindows Installerでは、配布者はインストーラーの動作をMSI形式のデータベースに記述する。このデータベースは、MSIパッケージと呼ばれる、拡張子が.msiのファイルに格納されている。 インストーラーの実行時には、Windows Installerサービスが、MSI形式のデータベースに格納されている情報を読み取り、それをもとにシステムに変更を加える。このときユーザーからは従来のインストーラーのように、MSIファイルを実行しているように見える。
MSIファイルはCOM構造化ストレージと呼ばれる、単一のファイルの中に複数のオブジェクトを格納できる構造を持つ。 COM構造化ストレージファイルには、概要情報と呼ばれる情報が保管されており、その中にGUIDと呼ばれる一意の識別子がある。Windows Installerはこれをもとにパッケージを識別し、管理を行う。 GUIDとは、16進数で表される128ビットの識別子である。一意であることが保証されているため、別の製品が同一のGUIDをもつことはありえない。GUIDは主に、Microsoftが利用している仕様で、一般的には同様の識別子を持つ、UUIDとして扱われている。以下にWindows Installerの主な特徴を示す。
インストール中に何らかの原因でインストーラーが不正終了した場合、終了時点までに展開されたファイルや登録されたレジストリが残り、それがシステムに不具合を引き起こすことも考えられる。 Windows Installerでは、インストールプロセスを「トランザクション」として処理する手法が用いられ、途中で問題が起こった場合は処理以前の状態まで復元を行う。この復元動作をロールバックという。
トランザクションはデータベースの概念で用いられているもので、必要な一連の処理を、分割できない一つの処理単位として扱う。もし、一連の処理が全て成功した場合は、トランザクションの完了とみなし処理を確定する。 もし一連の処理のいずれかの部分で失敗した場合は、トランザクション開始前の状態に復元する。
オンデマンドインストールとも呼ばれる。インストール作業時にはインストールファイルのコピーやレジストリ情報の登録を行わず、拡張子の関連付けやCOM情報のインターフェイスのみ登録を行う。 そして、機能が初めて呼び出されたときにファイルのコピーとレジストリの登録を行う。これによって、使わない機能に対してディスク容量を節約することができる。
WiXは、2004年4月にマイクロソフト初のオープンソースプロジェクトとして登場した、Windows Installerの作成環境である。 XML形式で作成したソースコードをMSIパッケージ形式にコンパイルすることができる。
WiXはいくつかのコマンドラインベースのツールから構成される。主要なツールを以下に示す。
| Candle | コンパイラ。ソースファイルを中間コードに変換する。 |
| Light | リンカ。中間コードからMSIパッケージファイルを生成する。 |
| Lit | 他のインストーラーパッケージのビルドに使用できるライブラリを生成する。 |
| Dark | 逆コンパイラ。MSIファイルをWiXソースファイルに変換する。 |
| Heat | ファイルやVisual Studioプロジェクトの情報を基に、ソースファイルの断片を生成する。 |
WiXのソースコード例を下に示す。これはインストール情報をWindowsに登録する動作をするサンプルである。これをコンパイルして出力されたMSIファイルを開くとインストーラーが起動し、インストール情報が登録される。
<?xml version='1.0'?>
<Wix xmlns='http://schemas.microsoft.com/wix/2006/wi'>
<Product Id='fa5611bd-abe1-4199-ba89-1dbb1eaf2fd1' Name='Test Package'
Language='1033' Version='1.0.0.0' Manufacturer='Author'
UpgradeCode='52d8a9e8-73eb-4eb4-a862-dbe614e3fc5d' >
<Package Description='My first Windows Installer package'
Comments='Test Windows Installer database'
Manufacturer='Author' InstallerVersion='200' Compressed='yes' />
<Directory Id='TARGETDIR' Name='SourceDir'>
<Component Id='MyComponent' Guid='ee5743d1-4368-b5aa-411c-fe9ffeb492b6' />
</Directory>
<Feature Id='MyFeature' Title='My 1st Feature' Level='1'>
<ComponentRef Id='MyComponent' />
</Feature>
</Product>
</Wix>図4.WiXのソースコード例
以下に各要素の説明を示す。
| 属性名 | 属性値の意味 |
| Id | 製品識別子となるGUIDを設定する。Windowsはこの値を基にインストール状況を把握する。 |
| Language | インストーラーが表示する言語のコード番号。 |
| Manufacturer | 開発元の名前を指定する。 |
| Name | インストーラーの製品表示名を指定する。 |
| Version | 製品バージョン。 |
| UpgradeCode | 一連の製品群を識別するためのグループコード。 Windows Installerを用いて更新を行う場合はこの値が必要。 |
Product要素の内容として、Package要素、Directory要素、Feature要素を含むことができる。
MSIファイルの概要を指定するための要素。エクスプローラーからこの情報を参照することができる。
| 属性名 | 属性値の意味 |
| Description | ファイルの説明。 |
| Comments | ファイルのコメント。 |
| Manufacturer | 開発元の名前を指定する。 |
| InstallerVersion | 必要となるWindows Installerランタイムのバージョン。 |
| Compressed | 圧縮するかどうかの設定。 |
| 属性名 | 属性値の意味 |
| Id | ディレクトリーの識別子。 |
| Name | インストール先のディレクトリ名。 |
Directory要素の内容として、Component要素を含むことが出来る。
| 属性名 | 属性値の意味 |
| Id | コンポーネントの識別子。 |
| Guid | コンポーネントの外部識別子。 |
| 属性名 | 属性値の意味 |
| Id | Featureの識別子。 |
| Level | デフォルトのインストールレベルを指定する。 |
| Title | カスタムインストールのツリーで表示する名称。 |
Feature要素の内容として、ComponentRef要素を含むことができる。
| 属性名 | 属性値の意味 |
| Id | そのFeatureでインストールするComponent要素のIdを指定する。 |
RPM はRed Hat社が開発した、ソフトウェアのパッケージ管理システムである。同社のRed Hat Linux用に開発されたものだが、現在は多くのLinuxディストリビューションでも使われるようになった。 また、Linuxのディストリビューションが備えるべき最低限の機能のセットを定めた標準仕様である、Linux Standard Baseにも採用されている。パッケージは、cpio形式で圧縮されたアーカイブファイルで、.rpmという拡張子を持つ。
メタデータはRPMパッケージのヘッダに記述されている。RPMパッケージの基となるソースRPMパッケージにはソフト本体の他、そのパッケージの内容についての情報や、インストール時に実行するスクリプトを記述したSPECファイルが格納されている。
SPECファイルの内容は、以下の4つに分類される。
SPECファイルは各情報に対応した「タグ」を用いて記述する。タグの書式は、図5のようにタグ名とコロンで始まり、それ以降にタグの内容を1行で記述する。 例えば、Summaryはパッケージの要約を表すのに用いるタグであり、"Apache HTTP Server"がその内容である。
以下にパッケージの基本情報と依存関係の情報で使用されているタグを挙げる。
Summary: Apache HTTP Server
Name: httpd
Version: 2.2.3
Release: 1
URL: http://httpd.apache.org/
Vendor: Apache Software Foundation図5.SPECファイルのタグの例
| タグ | 内容 |
| Summary | パッケージの要約 |
| Name | パッケージの名前 |
| Version | パッケージのバージョン |
| Release | リリース番号。同バージョンで何度目のリリースであるかを意味する |
| License | アプリケーションのライセンス |
| Group | アプリケーションの種類 |
| Packager | パッケージの作成者 |
| Distribution | 対象となるディストリビューション |
| Url | アプリケーションの情報を提供しているURL |
| タグ | 内容 |
| Requires | RPMパッケージに入っているソフトの動作に必要なパッケージ名 |
| BuildRequires | RPMパッケージの作成時に必要なパッケージ名 |
| Conflicts | 共存できないパッケージ名 |
| Provides | 作成するパッケージが他のパッケージの代替になる場合の、そのパッケージ名 |
| Obsoletes | パッケージをインストールする際にアンインストールしたいパッケージ名 |
| BuildConflicts | パッケージ作成時にインストールしておけないパッケージ名 |
また、パッケージの詳しい内容を記述したい場合は、%descriptionと書き、次の行に説明文を書く。
rpmコマンドはインストールされたパッケージファイルの情報を、Berkeley DB形式のデータベースでローカルに保管している。 インストール時にソフトの情報をこのデータベースへ登録し、次回以降は登録された情報をもとに管理を行う。 また、rpmコマンドには依存関係のチェック機能があるが、RPM自身でその関係の解決を行うことはできず、例えばあるソフトのインストール時に、そのソフトの動作に必要とされているパッケージが不足している場合は、エラーを表示して終了する。
YUMはRPM用のパッケージ管理ツールである。Terra Softが開発したYellow Dog Linux用 のYUPをDuke Universityが改良したものである。 現在はRPMを使用するディストリビューションで広く使われるようになった。更新の仕組みは、リポジトリからファイル情報が記述されたXML形式のメタデータをダウンロードし、インストール時にyum自身の持つデータベースに登録していく仕組みである。
インストールや更新時には、依存関係を分析し、追加で必要なパッケージがあればダウンロードを行い、インストール順序を考慮してインストールを行う。このとき内部でRPMを呼び出している。
また、メタデータのキャッシュも持っており、最後に取得した時刻から一定時間以内であれば、キャッシュより読み出す仕組みになっている。
メタデータは記載されている内容によって、4種類のファイルに分けられており、gzip形式で圧縮されているファイルもある。
リポジトリに関するメタデータファイルである。各メタデータファイルの場所や更新日時、チェックサムが記述されている。
リポジトリ内にあるパッケージの名前、対応アーキテクチャ、バージョン、チェックサムなどの基本情報が記述されている。
パッケージの更新履歴などの付加的な情報が記述されている。
各パッケージ内のファイルリストが記述されている。
また、primary.xml.gzに記述されているチェックサムを各パッケージのIDとして用いており、other.xml.gzとfilelist.xml.gz内では、package要素内に、それぞれのパッケージのIDを示すpkgidという属性を持っている。
dpkgは、Debian GNU/Linuxで用いられているパッケージ管理システムである。rpmコマンドと同様に、自分自身で依存関係の解決を行うことができない。 これはRPM形式ではなく専用のdeb形式のパッケージを扱う。パッケージの仕様は、「Debianポリシーマニュアル」で定められている。
パッケージ構造は、一つのar形式のアーカイブファイルに、2つのtarアーカイブファイルを格納したもので、tarアーカイブはインストールするファイルが収録されたものと、パッケージのメタデータファイルが収録されたものに分かれている。 そのメタデータファイルが収録されたアーカイブ内の、controlファイルにパッケージの基本情報が収録されている。
◆コントロールファイルの書式
設定する属性を「フィールド」と呼ぶ。これはRPMのSPECファイルのタグと同様に、一つのフィールドは、フィールドの名前とその値のペアよって構成され、名前と値の間をコロンで区切る。コロンの後に一文字スペースを入れるのが慣習となっている。 フィールドが複数行に及ぶ場合は、継続行はスペースまたはタブで始まらなければならない。
例えば、「Package: libc6」ならば、フィールド名はPackage、フィールド値はlibc6となる。
以下にフィールド名の例とその内容を示す。
| フィールド名 | 内容 |
| Package | パッケージの名前 |
| Version | パッケージのバージョン番号 |
| Architecture | 対応アーキテクチャ |
| Maintainer | パッケージの作成者 |
| Description | パッケージの内容の説明。フィールド名の書かれている行に概要を記し、次の行から詳細な説明を記す。 |
| Section | パッケージの分類 |
| Priority | パッケージの重要度。システムが適切に動作するために、このパッケージがどの程度必要なのかを示す。 |
APTは、Debianパッケージの管理を行うツールである。yumと同様に、依存関係を分析し、必要な追加パッケージのダウンロードを行い、適切なインストール順序にしてdpkgに処理を渡す仕組みである。
つまり、ここで取り上げたパッケージ管理システムは、上位、下位の関係があり、RPMに対するyumの関係と、dpkgに対するaptの関係は同じであると言える。
これらの更新管理システムやインストーラー以外に、ソフト自身が更新機能を備えているものがある。例えばWebブラウザの"Mozilla Firefox"では、新しいバージョンがないか定期的にチェックし、ある場合には図6のようなダイアログを表示する。 また、Firefoxは、現在使用しているバージョンと新しいバージョンの差分データのみを取得し、更新された部分のみ適用を行う「差分アップデート機能」を持っており、差分データが利用できる場合はそのファイルのダウンロードと適用を試みる。もし失敗した場合は、全ての内容を含むファイルをダウンロードして適用する。
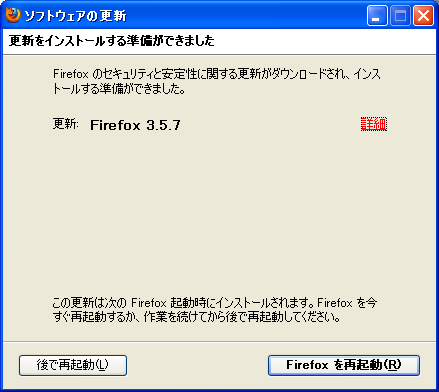
図6.Firefoxの更新画面
前章までの仕組みをもとに、Windows用のユーザーが自由に利用できるソフトウェアパッケージの更新管理ソフトを試作した。
本論文では、標準で用意されているAPIが豊富にあり、実装の追加や変更が容易に行えるという観点から、Java言語にて作成することにした。例えば、作成するソフトウェア(以後、更新管理ソフトと呼ぶ)にはインターネット上からXMLファイルを取得する処理が含まれているが、 TCP/IPやHTTPの接続に必要なコードを書く必要がなく、関数の引数に取得するファイルのURIを与えるだけで処理が実現できる専用のAPIが用意されている。開発環境は、Java SE Development Kit 6、Eclipse 3.5、Eclipse用Visual Editorプラグインを用いた。また、GUI部には、SWTを用いることにした。 SWTには、描画処理の多くをOSネイティブのコードを用いることにより実現するので、高速で、メモリの使用量が少なく、また、見た目や操作感をOSネイティブのものに近づけやすいというメリットがある。
さて、更新管理ソフトにおけるバージョンの確認方法は、管理対象のソフトに関する情報を記したメタデータファイルの参照と比較を行うことで、更新があるかどうかを調べるものとした。 このメタデータはXML形式のファイルとする。構造が自由に設計でき、そのままでも可読性があり、手作業で内容の確認や変更が容易に行えるためである。
メタデータファイルはアーカイブ内に含めず、別途用意することにした。これにより、ソフトの配布元は新たにソフトを収録するアーカイブやパッケージを用意したり、あるいは既にあるアーカイブに変更を加える必要はなく、メタデータファイルを新たに追加するだけでこの方法を適用できる。 さらに、ソフト本体の収録されたアーカイブファイルを手動で配布元のサイトからダウンロードし、展開する方法と共存できる。これに加えてユーザーには、手動でダウンロード・展開する方法と、本研究で用いる方法とを好みで選択する自由を与えることができる。
このような仕様により、メタデータの配布者は管理対象のソフト本体の開発者・配布者と同一である必要は無くなり、単にそのソフトに興味があったり、更に普及させたいという思いを持つ第三者であっても、メタデータの配布者になることができる。 そのような配布者は、必要な情報を用意し、それをメタデータとしてインターネット上に公開することで、この仕組みが成り立つという利点がある。
想定する更新処理の全体の流れを示す。
更新チェック時は手順(3)から繰り返し行う。
更新管理ソフトが扱うXMLドキュメントに必要な処理の流れと構成を考える。
更新管理ソフトでは、XMLのデータ形式を扱うためにDOMを使用する。 ここでこの更新管理ソフトがDOMとして扱うと想定されるXMLドキュメントは、インストールされているソフトの情報を格納したローカルにあるドキュメント、配布するソフトの情報を格納しているサーバー側のドキュメント、さらに更新ソフトの内部で処理を行うための作業用のドキュメントの3つが必要であろう。 なお、ローカル側のドキュメントにはインストールされているソフトの情報だけを持つものとする。また、更新ソフトの内部処理用のドキュメントは、ローカル側とサーバー側のソフトの情報を統合した情報とユーザーインターフェース側で設定した情報を記録する役割を持つ。 さらに、ユーザーインターフェース側で設定した情報を持つDOMオブジェクトは、処理が完了した時点で設定情報をファイルとして書き出すことが出来るようにした。
更新を行うためには、ソフトの情報を取得し、それを蓄積する必要がある。3章の実用化されている管理システムで使われている管理情報をもとに、更新のために必要な項目を選定した。項目は以下のとおりである。
UUIDと、バージョン番号は、ローカル側、サーバー側両方に最低限必要となる属性である。
UUIDは、管理対象となるソフトを特定するための識別子で、ソフトの判別に用いる。2つのソフト間のIDが異なる場合はそれぞれ別のソフトとして扱われる。このため、複数のメタデータ配布者が存在する場合には、何らかの手段を用いて、各配布者間でIDの相違が起こらないように注意する必要がある。 また、2つの異なるソフトが同一のIDを持つことはできないものとする。ソフト名自体を判別に用いる方法も考えられるが、同一のソフト名が存在した場合は、混同が起きてしまうので、管理に支障が起きる。
バージョン番号は、現在インストールされているソフトが最新のものであるか比較を行う際に用いる。書式は、ピリオド(".")でバージョン番号を区切る。 比較は先頭からピリオド毎に区切り、辞書順に行うものとする。ローカル側のバージョン番号よりもサーバー側のバージョン番号が大きい場合、最新バージョンがあると判定する。
ソフト名、コメント、作者名は、そのソフトの詳細をユーザーインターフェイスに表示させるためのものであり、更新処理に直接影響を与えることはないものとする。
作業用ドキュメントでは、ソフトのメタデータに加え、ローカルにソフトがインストールされているか区別する情報やユーザーが設定した情報を保持しなければならないので、
これらの2つを作業中のみ用いる要素として、作業用ドキュメントへのメタデータ取り込み時に追加を行うことにした。
一つのメタデータファイルの中に複数のソフトの情報を記すことができるものとする。一つのソフトについての情報をひとまとめにする要素が必要となるので、ここではitemという親要素を作成することにした。UUIDは、複数あるitem要素に区別をつける目的と、DOMのノードをたどっていくときに、1つのitem要素ごとに下の階層を探索すると手間がかかるので、item要素の属性とした。
itemの子要素として、各ソフト毎に必要な情報を要素として配置する。
| 必要な情報 | XMLドキュメントで用いる要素 |
| ソフト名 | softname |
| バージョン | version |
| URI | uri |
| コメント | desc |
| 作者名 | author |
| インストール状況 | status |
| 設定した操作 | operation |
図7にDOMツリーの構造を示す。
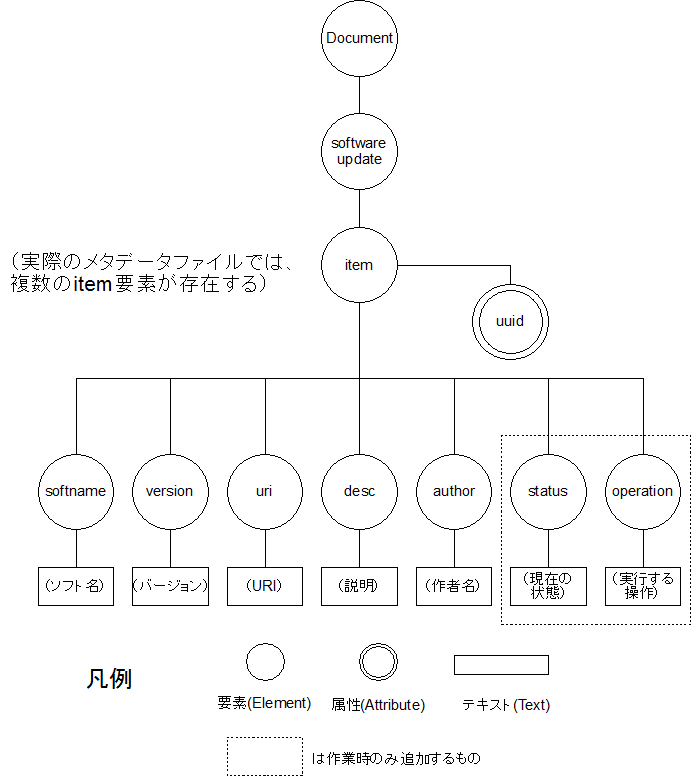
図7.DOMツリー構造
次に、更新管理ソフトが行う処理の流れをドキュメントに注目して説明する。
XMLドキュメントに着目した処理の流れを図8に示す。
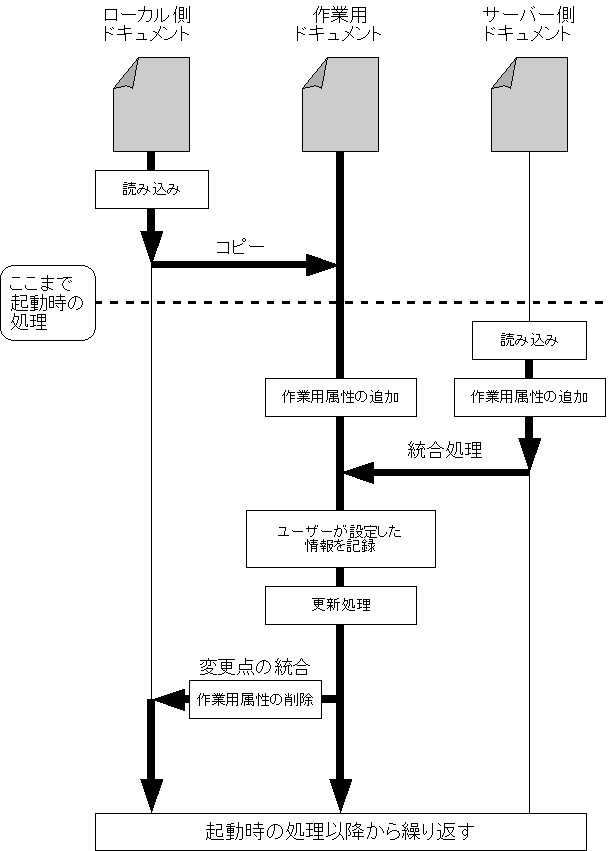
図8.XMLドキュメントの時系列の処理の流れ
前章までの仕様から、図8の「統合処理」までを行うプログラムを作成した。本章では作成したプログラムの説明を行う。
要求仕様(4.1.章)でGUI部にSWTを使用すると述べたが、SWTはOSネイティブの見た目に近づけられる分、動作対象のOSのAPIに依存する部分があり、SWTで構成されたオブジェクトにはJavaの特徴の一つである自動ガベージコレクション(不要になったメモリ領域を自動的に開放する作業のこと)が適用されない。 そのため、SWTを用いる部分で不要なメモリ領域が出た場合は、disposeメソッドを用いて明示的にメモリ領域の解放を指示しなければならない。
作成したプログラムでは、ソフト名リストや各情報を表示するメインウィンドウと、サーバー側のドキュメントのURIを入力するウィンドウの2つのウィンドウを作成した。SWTには、AWTやSwingと同様にレイアウトマネージャがいくつかあるが、各ウィジェットを格子状にレイアウトするGridLayoutを用いた。
プログラムの起動を行うクラスである。処理を行うTransaction1クラスと、ウィンドウを表示するFrontEndクラスのインスタンスを作成し、メインウィンドウを作成する。また、ローカル側のメタデータの読み込みを指示する。ローカル側のメタデータが存在しない場合や、読み込み時にエラーが発生した場合には、エラーを表示して終了する。
メインウィンドウが開いている状態では待機し、閉じられた場合にはdisposeメソッドを用いてメモリを解放する。
メインウィンドウを作成するクラスである。createMainWindowメソッドでシェルを作成し、メニューバーやボタン、ラベルといったウィンドウ内に必要なパーツを作成する。各パーツ毎の初期化処理は、別に用意したメソッドやクラスを呼び出すことで行う。
◆イベントリスナの作成
ボタンやリストボックスを操作したときに特定の動作を行わせるためには、addSelectionListenerでイベントリスナを作成する必要がある。メインウィンドウで必要な動作は、
の2つである。
そこで、リストボックスと「実行」ボタンにイベントリスナを作成し、動作については他のメソッドやクラスへ渡す。
このクラスは、サーバー側のメタデータのURLを入力するウィンドウを作成するクラスである。
最初に、コンストラクタでウィンドウの作成を行う。FrontEndクラスのメインウィンドウと同様に、各パーツ毎の設定は他のメソッドやクラスで行う。
ウィンドウやボタンなどの、各パーツのレイアウトの設定を行うクラスである。ウィンドウを作成するクラスからこのクラス内のメソッドを直接呼び出すことで設定を行う。
ウィンドウ内の各ラベルの操作を行うクラスである。ウィンドウ作成時にこのクラスのインスタンスが作成され、コンストラクタによって、各ラベルを初期化するメソッドが呼び出される。
メインウィンドウ内にある、ソフト名の一覧を表示するリストボックスの操作を行うクラスである。
リストボックス内の要素がクリックされた場合は、showDetaliTransaction1クラスに処理を渡す。
FrontEndクラスと内部処理を行うクラス間で行われる処理の橋渡しを行うためのクラスである。
このクラスではコンストラクタによって3つのXMLParserのインスタンスが生成され、各ドキュメントの読み込みを指示する。
ローカル側のメタデータの読み込みを行う。また、読み込んだメタデータの内容を作業用ドキュメントへコピーする。showSoftListを呼び出して、作業用ドキュメントにあるソフト名の一覧をGUIのリストボックスに表示する。
サーバー側のメタデータの読み込みを行い、作業用要素を追加する。
与えられたソフト名一覧のインデックスから、そのソフトのダウンロード用uriを取得し、Downloaderクラスを用いてダウンロードを行う。
FrontEndクラスで作成したリストボックスに対するイベントリスナの設定を行う。 リストボックスがクリックされた場合は、リストの何番目の要素が選択されたかを取得し、ソフトの詳細情報をラベルに表示させるため、MyLabelsクラスに処理を渡す。
このクラスは、XML形式のメタデータを読み込んで解釈し、DOMオブジェクトとしてデータの処理を行うクラスである。
処理用にListクラスとHashMapクラスの2つを用いる。
list_softnameは、ソフト名リストを格納する変数である。GUIのソフト名一覧の部分にソフト名を表示する際に、このリストを呼び出す。
このソフトではItem要素の中に、各ソフトについての情報を格納する仕様にしているので、Item要素単位でデータの操作を行うことが頻繁に起こる。 そこで、一つ一つのItem要素をリストの要素として格納し、特定のソフトについての情報にアクセスする際には、このリストを利用して各ソフトの情報にアクセス方法をとることにした。
HashMapクラスはキーと値のペアで要素を格納することができる。UUIDをString型のキーとして、item要素のリストのインデックスをInteger型の値として格納する。 UUIDをキーに検索を行うと、item要素のリストのインデックスが取得できるので、それをlist_softnameのgetメソッドの引数として与えれば、目的のソフトの情報がまとめて取得できる。
HashMapは重複するキーを許可しないという特徴がある。キーに設定しているUUIDも異なるソフト間で同じIDを持つことができないとしているので、適していると言える。 ただ、重複しているキーを登録しようとした場合、新規にキーと値のペアが作られることはないが、古い値の内容は新しい値の内容で上書きされてしまうので、それを避けるために登録する際は予め該当するUUIDが登録されていないか調べるようにした。
今回の実装では用意していないが、ソフト名で検索したい場合に、予めソフト名と要素を関連付けしておくことで、効率良く参照したいソフトについてのデータを取得することができる。
LinkedListにXMLドキュメント内のitem要素を先頭から順番に格納していく。同様にしてソフト名のLinkedListにitem要素内のソフト名を読み込み、格納していく。
一つのXMLParserのインスタンスにつき、一つのmetadocというDocumentインターフェースを持つ。
読み込みを行う際には、ローカル側のドキュメントと、サーバー側のドキュメントを読み込むときにはURIを指定して取得を行う必要があり、作業用ドキュメントを作成する時には、ローカルドキュメントのドキュメントのコピー作業を行う必要がある。 そこで読み込みを行うメソッドは、URIを引数に持つものと、Documentインターフェースを引数に持つものの2つを作成した。
DocumentBuilderFactoryクラスの新しいインスタンスを作成する。これは、XMLドキュメントからDOMオブジェクトツリーを生成するパーサーを取得できるファクトリーAPIを定義するものである。
読み込んだファイルの妥当性検証を行うため、setValidatingを有効にし、整形式XML文書の検証と妥当なXML検証の両方の検証を行う設定をする。また、検証の結果誤りが見つかった場合のエラーハンドリングをMyHandlerクラスで行うようにする。 MyHandlerクラスはエラーメッセージとエラーが起こった行数を標準出力に表示するものである。
XMLドキュメントからDOM Documentインスタンスを取得するAPIを定義する。これを定義することにより、様々な入力ストリームからXMLドキュメントの構文を解析できるようになる。
DOMの内容にアクセスするには、ツリー構造の一番上の階層から順番にたどっていく。この一番上の階層をルートと呼ぶ。最初にルートの要素を取得する。ルート要素の下の階層(これを子ノードと呼ぶ)に複数のitem要素が格納されている。 複数の子ノードは、ノードリストとして親のノードから取り出すことができる。
要素のタグ名を指定して取得することができるので、ここでは"item"という要素を指定して取り出す。
各item要素をitem要素を集めたリストとして、elementListへ格納する。また、item要素のuuid属性の取得を行う。次にソフトごとの情報が格納されている子ノードへアクセスし、ソフト名リストの表示に必要なsoftname要素から値をソフト名として取得し、それをsoftlistへ格納する。 UUIDをhashMapByUUIDのキーに、値はelementListのインデックスとして格納する。これを各item要素ごとに繰り返す。
最初にTransformerFactoryクラスとTransformerクラスのインスタンスをそれぞれ作成する。Propertiesクラスで保存する際の条件を設定できる。ここでは文字のエンコード方式にUTF-8を選択し、インデントを付ける設定をした。 これをTransformerクラスのsetOutputPropertiesメソッドの引数にとることで設定を適用できる。
次にDOMSourceクラスのsetNodeメソッドを用いて、メモリ上に展開されているドキュメントを取り込む。
ファイル名を引数にファイル出力ストリームを作成する。また、StreamResultクラスのインスタンスを作成し、出力先に先ほど作成したファイル出力ストリームを指定する。
最後にTransformerクラスのTransformメソッドを用いると、XMLデータがStreamResultを経由してファイルに出力される。
4.1.で述べた通り、作業用とローカル側のドキュメントには作業用要素の追加や削除が必要となる。ここでその手順を示す。
DOMの読み込みと同様に、ルート要素からitem要素ノードのリストである、ノードリストを取得する。ノードリストの個々の要素はノードであり、ドキュメント要素の各item要素ノードに対して追加を行うので、処理を各item要素ごとに繰り返す。 要素を追加するためには、最初にDocumentクラスのcreateElementメソッドを用いて、新規に要素を作成する。引数には要素名を指定する。
要素間に挿入するテキストを追加するには、前の手順で作成したElementクラスのsetTextContextメソッドを用いる。引数にテキストを指定する。
最後に作成した要素をitem要素ノードの子ノードとして追加する。
削除の場合も同様に、ルート要素からitem要素ノードのリストである、ノードリストを取得する。Item要素ノード中の指定した要素を削除するには、親要素から子要素ノードの削除を指示する。 ここでは、item要素からstatus, operationというタグ名のついた要素ノードのうち最初のノードを探し、item要素ノードにそのノードを引数にremoveChildメソッドを実行し、要素を削除する。
比較対象となる2つのメタデータから取得したバージョン番号を引数にとり、ピリオドで区切られたバージョン番号の要素を、要素数の少ない方の回数だけ辞書順でバージョン番号を比較する。 回数を繰り返しても大小が区別できない場合は、ピリオドで区切られたバージョン番号の要素数を比較することでバージョン番号を比較する。
ファイルのダウンロード操作を行うクラスである。
ダウンロードを行うURLと取得したファイルの保存先を引数にとる。
入力ストリームと出力ストリームを一つずつ作成し、URLクラスのインスタンスをダウンロードを行うURLを引数に作成する。
入力ストリーム側にURLクラスのopenStereamメソッド、出力ストリームにFileOutputStreamのインスタンスを、出力先のファイルのパスを引数に作成する。また、バッファ用のbyte列の変数Bufferを作成する。
以降バッファが空になるまで、つまりファイルのダウンロードが完了するまで出力ストリームに書き出しを行う動作を繰り返す。
完了した場合は各ストリームを閉じ、trueを返す。失敗した場合は例外を表示してfalseを返す。
読み込むXML文書の妥当性検証を行うため、XMLスキーマを作成する。作成したXMLスキーマは7章に示した。
以下に、更新管理ソフトに読み込ませるXMLファイルに必要な条件を挙げる。
ここから、読み込むXML文書の構造を定める。読み込むXML文書のルート要素はsoftwareupdateである。element要素で、name属性に要素名であるsoftwareupdateを指定する。
softwareupdate要素はitem要素という子要素を持つ。XML Schemaではデータ型と呼ばれる概念があり、子要素の形態によりデータ型が異なる。
ここでは複雑型となるので、複雑型であることを示すcomplexType要素を指定する。
次のsequence要素は子要素の順序を設定するものである。sequenceは上から記述した順番で子要素を記述しなければならないという決まりを指定する。
次にitemの子要素を指定するが、複雑なためref属性を用いた。ref属性は参照を表すもので、属性値に指定した要素名と同じものをname属性に持つelement要素を参照する。 この場合、element属性で、属性値にitemを指定したものの設定を参照することになる。また、ここでmaxOccurs属性を用いて出現回数を設定する。item要素は何度用いても良いという仕様なので、制限なしを示す"unbounded"を値に指定する。
softwareupdate要素の子要素はitem要素以外ないので、閉じタグを用いて一旦指定を終わらせる。
次に先ほど参照したitem要素について設定する。item要素の子要素も存在するので、複雑型を指定する。次のall要素は、all要素内のelement要素が順不同で現れるという指定である。
item要素の子要素は値を持っているので、その値の型を指定することにする。値の指定にはtype属性を用いる。stringは文字列型、anyURIはURI型、integerは整数型を表す。
status、operation要素は、必須ではない要素である。これをXML Schemaで表現するには、minOccurs属性を指定し、値に"0"を指定する。
最後に、item要素のuuid属性の指定を行う。この属性は必須であるので、use属性を指定し、値に"required"を指定する。ここでユーザー定義型のデータ型uuidを定義することにしたので、type属性に"uuid"を指定する。
以上でitem要素内の指定は終了したので閉じタグを用いて閉じる。
新しいデータ型を宣言するには、simpleType要素を使用する。name属性に作成したいデータ型である"uuid"を指定する。
データ型の定義は、既存のデータ型に制限を加えることで行われる。restriction要素を指定し、base属性に基本となるデータ型を指定する。次に文字列の形式をpattern要素を用いて指定する。value属性の値には、正規表現を用いて文字列の形式を表現する。
UUIDの文字列の形式は、
となり、それぞれの桁は16進数で表現される。これを正規表現で表すと、
となるので、これを値に指定する。以上で定義は完了であるので、閉じタグを用いて要素を閉じる。
作成したプログラムを実際に動作させ、正しく処理が出来ていることを確認する。
ここではtest_3.xmlをサーバー側のメタデータファイル、meta_local.xmlをローカル側のメタデータファイルに見立てて、ローカル側のメタデータファイルを読み込んだ後、サーバー側のメタデータファイルを統合する処理を行う。 それぞれのファイルの内容は付録(7章)に示した。
バージョン番号の比較処理を確認するために、サーバー側のファイルには、ローカル側のファイルに記載されている内容とバージョン番号だけ異なるものや、ローカル側のファイルに記載されていないソフトの情報を記載した。相違点をまとめると、
正しく処理されていれば、ローカル側がそのソフトの情報を持っていないか、ローカル側よりもサーバー側のほうが新しい(つまり、サーバー側の方がバージョン番号が大きい)場合に作業用ドキュメントの持っている該当するソフトの内容が、 サーバー側のデータで追加または書き換えられる。
つまり、統合処理後の作業用ドキュメントの内容は、ソフト2の情報がサーバー側の情報で書き換えられており、ソフト4の情報が追加されていれば正しいことになる。
また、統合処理後には作業用要素(status、operation)が全てのitem要素の子要素として追加されているはずである。
以下に具体的な手順を示す。
手順(1)、(2)の通りにファイルを所定の位置に配置し、Eclipse上で作成したソフトを実行した。実行画面を図9に示す。リストボックスにローカル側のファイルに記載されているソフト名の一覧が表示された。 また、ソフト名を選択するとそのソフトの情報が表示されることが確認できた。
次に手順(4)〜(6)を実行した。このときのスクリーンショットを図10に示す。リストボックスに「ソフト4」の項目が追加された。 また、「ソフト2」を選択するとサーバー側のファイルの情報が表示された。「ソフト1」「ソフト3」には変化がなかった。
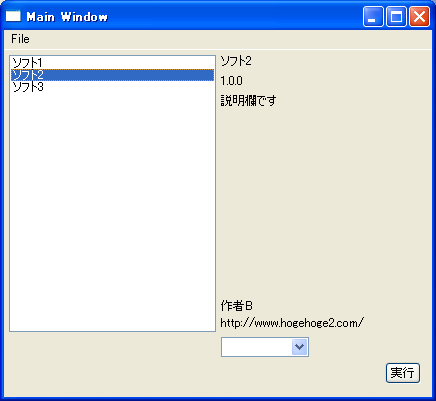
図9.更新用ソフト起動時のスクリーンショット
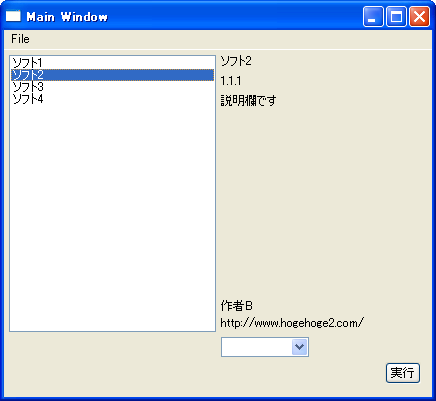
図10.手順(6)時のスクリーンショット
最後に手順(7)を行った。結果を以下に示す。インデントにずれがあるものの、XML構造は正しく、作業用要素であるstatusとoperationが追加されていることが確認できた。 また、ソフト2とソフト4はサーバー側の内容、ソフト1とソフト3はローカル側の内容が保存されていた。
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<softwareupdate>
<item uuid="8c349fdd-af4b-4eda-8184-93b1aad653b9">
<softname>ソフト1</softname>
<version>1.0.0</version>
<uri>http://www.hogehoge1.com/</uri>
<desc>説明欄です</desc>
<author>作者A</author>
<status>1</status>
<operation>0</operation>
</item>
<item uuid="247972df-838b-4044-850c-a11c31ea3eac">
<softname>ソフト2</softname>
<version>1.1.1</version>
<uri>http://www.hogehoge2.com/</uri>
<desc>説明欄です</desc>
<author>作者B</author>
<status>2</status>
<operation>0</operation>
</item>
<item uuid="bff3d373-cfe1-4a03-9dee-c778c04d3178">
<softname>ソフト3</softname>
<version>1.0.0</version>
<uri>http://www.hogehoge3.com/</uri>
<desc>説明欄です</desc>
<author>作者C</author>
<status>1</status>
<operation>0</operation>
</item>
<item uuid="9e6ed6e3-fd84-42cd-b847-da90adf1d13f">
<softname>ソフト4</softname>
<version>2.0.0</version>
<uri>http://www.hogehoge4.com/</uri>
<desc>説明欄です</desc>
<author>作者</author>
<status>2</status>
<operation>0</operation>
</item>
</softwareupdate>
以上より、正常に統合処理が出来ていることが確認できた。
本論文では、更新管理ソフトの動作の仕組みや、更新ソフトが持つメタデータの構造を分析し、それを参考にWindows用更新管理ソフトを作成するにあたって必要な要素を考察した。
また、Java言語と、DOM、XML SchemaなどのXML関連技術を用いて更新ソフトを試作し、更新動作時に必要となる、メタデータの比較と書き換えの処理を実現させることができた。 ユーザーはSWTを用いたGUI画面によって、更新処理の操作を行うことができるようになった。
本論文で作成したソフトでは以下のような課題が生じた。
本論文ではAPIが豊富で、実装が容易に行えるという理由から、Java言語を用いて、テスト用のアプリケーションの開発を行ったが、Javaは実行するにあたりランタイム環境を必要とする。 実運用ではこのアプリケーションの導入の前にこのランタイムの導入を行わなければならないため、手間がかかる。
Java言語はWindows以外の環境でも動作できるが、本論文はWindows環境のみの動作を前提としているので、実運用ではネイティブのWin32アプリケーションが作成できる言語で開発を行うことも考えられる。
4章で、第三者であっても、メタデータの配布者になることができると述べたが、第三者が配布元になりすまして、運用を妨害したり、 コンピューターにウィルスなどの悪意のあるプログラムをダウンロード・インストールするように指示することができてしまう。メタデータが信頼できるもなのかを確認できる手段が必要である。
解決策としては、電子署名を用いて、配布元が本物であるかどうかを認証することがひとつの例として考えられる。
一般ユーザー権限ではフォルダのアクセスが制限されるため、更新管理ソフトが正常に動作しない可能性がある。特にWindows Vista以降のバージョンではユーザーアカウントコントロール(UAC)機能により、 管理者権限を持っているユーザーであっても、通常は一般ユーザーの権限で行い、管理者に昇格する場合はユーザーの承諾が必要になった。このため、アクセス制限を避けるためには、管理者権限で更新管理ソフトを起動するよう設定する必要がある。
Firefoxや一部のLinux系ディストリビューションでは、差分更新機能が実装されている。これは前バージョンからの更新されたファイルだけが含まれたパッケージをダウンロードして、適用する方式である。 更新で必要なファイルが減るので、パッケージのファイルサイズも小さくて済み、更新の適用にかかる時間も短縮出来る。サーバー側にも転送量が少なくなり、ネットワークの混雑が避けられるというメリットがある。 したがって、効率良く更新作業を行うには、差分アップデートの機能の実装が必要であると考えられる。