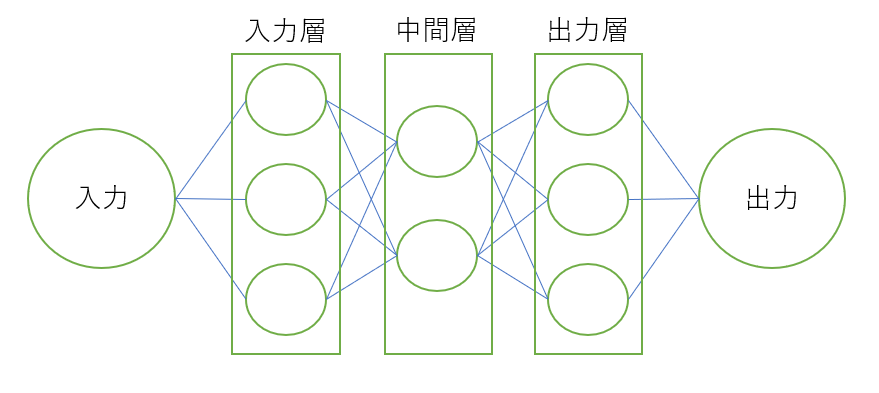
図1 ニューラルネットワークの概略図
近年,画像認識の分野で深層学習が注目され,様々な研究が行われている.ニューラルネットワークは様々なパラメータを持っており,特に人が調整しなければならないものをハイパーパラメータという.ニューラルネットワークの学習はハイパーパラメータの値によって成功するか否かが大きく左右される.ここで,学習とは学習用データをコンピュータが読みながら自動で適切なパラメータを決める作業を指す.
本研究ではハイパーパラメータの重要度を調べるために単純な学習として三角形と円の図形画像を対象とし,ハイパーパラメータの値の変化によりニューラルネットワークの図形画像判別にどの程度影響を及ぼすか調査する.
本論文の構成は以下のとおりである.
2章では本論文で用いる用語や技術についての説明,その定義について述べる.
3章では行った実験の手法と結果について述べる.
4章では考察を述べる.
5章では本研究のまとめを述べる.
6章では参考文献についてまとめる.
付録では本実験に使用したプログラムのソースコードを記載する.
図1 ニューラルネットワークの概略図
ニューラルネットワークとは,人間の脳神経系のニューロンを数理モデル化したものを組み合わせて作成されたネットワークである.入力層,中間層,出力層の3層で構成されており,入力データをこれらの3層に伝播させ,学習を行う.図1において左の層から入力層,中間層,出力層である.ニューラルネットワークの回答である出力と正しい回答とを比較し,それらの誤差が小さくなるように学習が行われ,正答率が高くなっていくというのがニューラルネットワークの基本的な仕組みである.
ニューラルネットワークのそれぞれの層は幾つものノードの組み合わせで構成されている.ノードとは人間の脳内にある神経細胞を模したニューラルネットワークの構造である.人工ニューロンと呼ばれることもある.ノードへの入力信号は前の層での出力信号にそれぞれ固有の重みと呼ばれるパラメータを乗算したもの(重み付き入力信号)とバイアスと呼ばれるパラメータの総和となり,重み付き入力信号の総和が一定の値を超えた場合にのみノードは値の出力を行う.ここで,重みは入力信号の重要度をコントロールするパラメータとして機能し,バイアスは出力信号が値を出力する度合いを調整するパラメータとして機能する.
入力信号の総和が一定の値を超えた場合にのみ値の出力を行うなどといった入力信号の総和を出力信号に変換する関数を活性化関数と呼ぶ.近年,ニューラルネットワークにおける活性化関数として中間層ではReLU関数を,出力層ではソフトマックス関数を用いるのが主流となっている.ReLU関数は以下の式で表される.
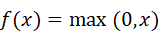
この関数は0より小さい出力値をすべて0にする関数であり,単純であるため計算量が少ないという特徴を持つ.
ソフトマックス関数は以下の式で表される.
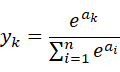
ここでは出力層が全部でn個あるとして,k番目の出力y_kを求める計算式を表している.このときy_kは0から1の値を取り,全ての次元で和を取ると1になるため,y_kを確率ととみなすことができる.
ニューラルネットワークは自身が学習データに対してどれだけ適合していないかを示す指標を用いて最適な重みパラメータの探索を行う.この指標を損失関数と呼び,小さければ小さいほど学習用のデータに対して一致していることを表す.本研究では三角形と円の2種類の図形画像を対象としているため,損失関数として2種類分類用であるbinary_crossentropyを用いている.
binary_crossentropyは損失関数として用いられる関数である交差エントロピー誤差の一つである.交差エントロピー誤差は次の式で表される.
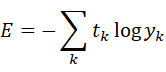
y_kはニューラルネットワークの出力,t_kは正解ラベルとする.また,t_kは正解となるもののみが1でその他は0とする.式の計算結果は正解ラベルに対応する出力が大きければ大きいほど0に近づく.
本研究で使用するニューラルネットワークではデータセットをいくつかのサブセットに分けて学習を行うミニバッチ学習という手法を用いている.幾つかのサブセットに分けて学習を行う理由は,学習する際に異常値の値を小さくするためである.この幾つかに分けたそれぞれのサブセットに含まれるデータの数をバッチサイズと呼び,選ばれたデータをミニバッチと呼ぶ.ニューラルネットワークはこのミニバッチに対する損失関数の値を減らすように重みとバイアスを調整することで学習用のデータに適応する.ここで,損失関数をどのような計算方法で減らしていくかということを表すハイパーパラメータがオプティマイザである.このオプティマイザを用いて,x個のデータに対してy個のミニバッチで学習した場合,x/y 回更新を行うことで全ての教師データを使い切ったこととなる.ここで,x/y 回を1エポックと表す.つまり,1エポックとは学習において訓練データをすべて使い切った回数に対応しており,エポック数とは一組のデータを何回繰り返して学習したかを示す値である.
関数における全ての変数の偏微分をベクトルとしてまとめたものを勾配といい,勾配が示す方向は各場所において関数の値を最も減らす方向であるということを利用して,勾配方向へ進むことを繰り返し,徐々に関数の値を減らすことを勾配法(勾配降下法)と呼ぶ.勾配法は次の式で表される.
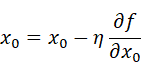
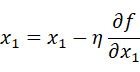
ηは更新の量を表し,学習率と呼ぶ.つまり,1回の学習でどれだけ学習するのかということを決めるのが学習率である.この式は一回の更新式を示しており,このステップを繰り返し行うことになる.ここでは変数が2つの場合を表しているが,変数が増えてもそれぞれの変数の偏微分の値によって更新されることとなる.学習率は大きすぎると大きな値へと発散してしまい,小さすぎるとほとんど更新が行われずに終了してしまうため適切な値を設定することが重要となる.ニューラルネットワークにおいては重みパラメータに対する損失関数の勾配を求め,重みパラメータを勾配方向に微小量更新することを繰り返すことで,学習を行う.このように勾配を利用して損失関数を減らそうとする方法を確率的勾配降下法(SGD)と呼ぶ.確率的勾配降下法(SGD)において重みwは以下の式で更新を行う.このとき,Eは誤差関数,ηは学習率を表すハイパーパラメータである.
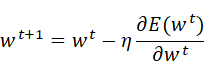
SGDは勾配方向へある一定の距離だけ進むという単純なオプティマイザであり,一度決めたηを用いて誤差の最小化を行なっていくことになるため,最適なパラメータを決めることが難しい場合がある.
SGDに対してAdamは重みwを以下の式で更新する.このとき,Eは誤差関数,ηは学習率を表すハイパーパラメータであり,m_0=0,v_0=0とする.
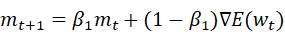
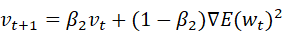
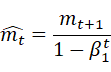
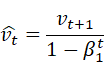
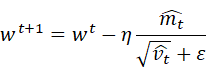
この手法はパラメータの要素ごとに適応的に更新ステップを調整するAdaGradを含む幾つかのオプティマイザを融合したかのような重みの更新方法をとる.移動平均の減衰率を調整するハイパーパラメータであるβ_1,β_2を用いることでハイパーパラメータの偏りの補正が行われる.
アフィン変換とは平行移動と線形変換を組み合わせた変換のことである.線形変換として回転があり,本研究では平行移動と回転の組み合わせで利用した.
[X]に対して
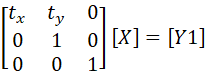
とすることで[X]に平行移動を加えた[Y1]が得られ,
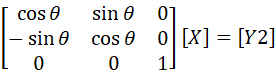
とすることで[X]に回転を加えた[Y2]が得られる.
本研究では図形認識をニューラルネットワークに行わせる際の,構成などのハイパーパラメータの性質を調べる.その第一歩として,円と三角形の認識を考える.そのため,アフィン変換を加えた図形をニューラルネットワークに学習させ,評価を行う.
まず,判別用のアフィン変換を加えた図形画像を作製する.解像度に対する図形の比率が7種類の図形画像を円と三角形それぞれで用意した.用意した画像の例を図2,図3に示す.

図2 解像度に対する図形の比率が7種類の図形画像例1

図3 解像度に対する図形の比率が7種類の図形画像例2
用意した14種類の図形画像にアフィン変換を加え,回転と移動を付加する.回転と移動を付加するために用いたプログラムをfig.pyとする.fig.pyは画像にランダムな角度の回転と水平,垂直シフトを加えて保存するプログラムである.回転は-180度から180度までの角度でランダムに,移動は画素数に対して上下左右ランダムに0から4.5割のシフトを加える.回転と移動を付加した画像例を図4から図7に示す.但し,図4,図5のように図形の全点がエリア内にある画像を円と三角形それぞれ6300枚,図6,図7のように図形の一部はエリア内にないが重心がエリア内にある画像を円と三角形それぞれ700枚用意した.

図4 回転と移動を付加した画像例1

図5 回転と移動を付加した画像例2

図6 回転と移動を付加した画像例3

図7 回転と移動を付加した画像例4
ニューラルネットワークはPythonで書かれたライブラリである"Keras"を用いて作成する.学習の基本的な流れとしては,初めに用意した回転と移動を付加した図形画像をグレースケールで28×28の解像度に変換と0,1で表される正解ラベル付けを施し,データセットを作成する.グレースケールで28×28の解像度に変換した画像例を図8から図11に示す.

図8 グレースケールで28×28の解像度に変換した画像例1

図9 グレースケールで28×28の解像度に変換した画像例2

図10 グレースケールで28×28の解像度に変換した画像例3

図11 グレースケールで28×28の解像度に変換した画像例4
データセットは訓練用,テスト用,検証用に3分割する.次に,訓練用,テスト用データセットを用いて作成したニューラルネットワークで学習を行う.学習は学習率を変えながら10回ずつ行い,図形判別の正答率が90%以上に達するのに必要とする平均のエポック数を記録する.このとき,図形判別の正答率が初めて90%以上に達したときのパラメータを保存し、検証用データセットで正答率の検証を行い、過学習が起きていないか確認する.これをオプティマイザごとに実施する.
また,オプティマイザごとに最も必要エポック数が少なかった学習率を用いて,訓練用,テスト用データセットの合計数を減らし,図形判別の正答率が90%以上に達するのに必要とする平均のエポック数を記録する.このときにも図形判別の正答率が初めて90%以上に達したときのパラメータを保存し、検証用データセットで正答率の検証を行い、過学習が起きていないか確認する.最後に,オプティマイザごとに最も必要エポック数が少なかった学習率を用いて,図形の全点がエリア内にある画像と図形の一部はエリア内にないが重心がエリア内にある画像の枚数の割合を変えながら学習を行い,図形判別の正答率の上昇が止まったときのパラメータを保存する.保存したパラメータを用いて図形の一部はエリア内にないが重心がエリア内にある画像の図形判別の正答率を検証する.
作成したニューラルネットワークの仕様を以下に示す.
表1 作成したニューラルネットワークの仕様
| 中間層数 | 3 | |
| ノード数 | 入力層 | 784 |
| 中間層1層目 | 640 | |
| 中間層2層目 | 640 | |
| 中間層3層目 | 640 | |
| 出力層 | 2 | |
| ドロップアウト | 0.2 | |
| 活性化関数 | 出力層以外 | ReLU関数 |
| 出力層 | ソフトマックス関数 | |
| 損失関数 | binary_crossentropy | |
| バッチサイズ | 64 | |
中間層が3層で中間層の各層は640個のノードで構成されており,訓練用データのみに適応しすぎてしまい,訓練用データに含まれない他のデータにはうまく対応できない状態である過学習を抑制するニューラルネットワークの手法の一つであるドロップアウトは各層で0.2に設定した.活性化関数は出力層のみでソフトマックス関数を用いており,それ以外ではReLU関数を用いている.作製するニューラルネットワークに解かせるのは円と三角形の2種類を分類する問題であるため損失関数として,交差エントロピー誤差で,特に2種類分類用である損失関数のbinary_crossentropyを用いている.また,バッチサイズは64とした.
実験1では用意した画像のうち図8,図9のように図形の全点がエリア内にある画像のみをニューラルネットワークに与え,学習させる.
まず,学習に用いたプログラムをtrain.pyとする.train.pyは初めに用意した回転と移動を付加した図形画像をグレースケールで28×28の解像度に変換と0,1で表される正解ラベル付けを施し,データセットを作成する.データセットは訓練用,テスト用,検証用いずれも4200枚で分割する.次に,訓練用,テスト用データセットを用いて作成したニューラルネットワークで学習を行う.学習は10回ずつ行い,図形判別の正答率が90%以上に達するのに必要とする平均のエポック数を記録する.このとき,図形判別の正答率が初めて90%以上に達したときのパラメータを保存し、検証用データセットで正答率の検証を行い、過学習が起きていないか確認する.これをオプティマイザ,学習率を変えて実施する.
訓練用,テスト用データセットでの学習で図形判別の正答率が90%以上に達するのに必要とする平均のエポック数とその時の検証データに対する正答率を表2,表3に示す.
表2 SGDの学習率に対する正答率が90%以上に達するのに必要とする平均のエポック数とその時の検証データに対する正答率
| 学習率 | 平均エポック数 | 検証時の平均正答率 |
|---|---|---|
| 0.0001 | 1039.2 | 88.4594 |
| 0.0005 | 172 | 88.0424 |
| 0.001 | 101.3 | 88.5667 |
| 0.005 | 18 | 88.1655 |
| 0.01 | 12.6 | 88.8167 |
| 0.05 | 6.1 | 88.7164 |
| 0.1 | 9.2 | 98.05 |
表3 Adamの学習率に対する正答率が90%以上に達するのに必要とする平均のエポック数とその時の検証データに対する正答率
| 学習率 | 平均エポック数 | 検証時の平均正答率 |
|---|---|---|
| 0.0000001 | 1970.9 | 88.4858 |
| 0.000001 | 183.2 | 88.4855 |
| 0.00001 | 11.1 | 88.4381 |
| 0.00005 | 3.3 | 88.469 |
| 0.0001 | 2.9 | 87.7594 |
| 0.0005 | 4.3 | 82.857 |
学習率に対する正答率が90%以上に達するのに必要とする平均のエポック数を図12にグラフ化する.
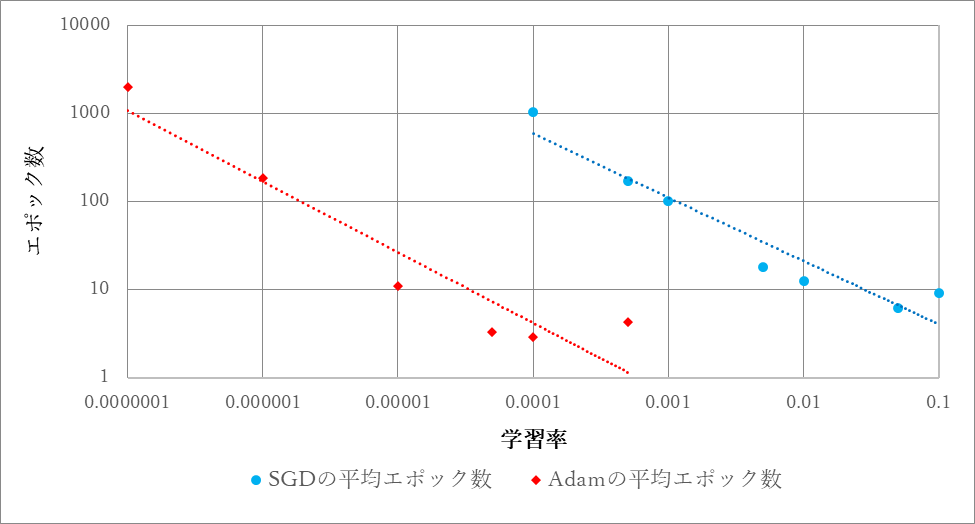
図12 学習率に対する正答率が90%以上に達するのに必要とする平均のエポック数
SGDでもAdamでも検証データに対する正答率が80%を下回ったものはなく,過学習が起こっていないことが確認できる.SGDでは学習率0.05のとき,Adamでは学習率0.0001のとき正答率が90%以上に達するのに必要とする平均のエポック数が最小となった.また,平均エポック数の最低値はAdamの方が小さくなった.
SGDでは学習率が0.5の時点で,Adamでは学習率0.005の時点で10回の試行の全てで正答率が40%から60%程度で変化せず,学習が行われていないと判断できる状況が発生した.10001エポック以上で正答率90%に達したとしてもSGDの学習率が0.05のとき及びAdamの学習率が0.0001のときに対して1000倍以上のエポック数が必要ということとなり,有用なデータであるとはいえないと判断したため本実験ではエポック数が10000に達した時点で学習を停止した.
次に,学習に用いたプログラムをtrain2.pyとする.train2.pyは初めに用意した回転と移動を付加した図形画像をグレースケールで28×28の解像度に変換と0,1で表される正解ラベル付けを施し,データセットを作成する.データセットは使用しない分,訓練用,テスト用,検証用に分割する.次に,訓練用,テスト用データセットを用いて作成したニューラルネットワークで学習を行う.学習は学習率をSGDが0.05,Adamが0.0001として,訓練用,テスト用データセットの合計数を減らしながら10回ずつ行う.このとき,図形判別の正答率が初めて90%以上に達したときのパラメータを保存し、検証用データセットで正答率の検証を行い、過学習が起きていないか確認する.データセットの合計数に対する正答率90%に達するのに必要なエポック数とその時の検証データセットに対する正答率を表4,表5に示す.
表4 SGDのデータセットの合計数に対する正答率90%に達するのに必要なエポック数とその時の検証データセットに対する正答率
| データセットの合計数 | 平均エポック数 | 検証時の平均正答率 |
|---|---|---|
| 8400 | 6.1 | 88.7164 |
| 4200 | 11 | 90.51429 |
| 2100 | 26.1 | 90.18333 |
| 1050 | 53.7 | 89.48288 |
| 840 | 66.1 | 89.55238 |
表5 Adamのデータセットの合計数に対する正答率90%に達するのに必要なエポック数とその時の検証データセットに対する正答率
| データセットの合計数 | 平均エポック数 | 検証時の平均正答率 |
|---|---|---|
| 8400 | 2.9 | 87.7594 |
| 4200 | 4.7 | 90.55 |
| 2100 | 11 | 90.22857 |
| 1050 | 26.6 | 89.60238 |
| 840 | 24.8 | 89.14286 |
データセットの合計数に対する正答率90%に達するのに必要なエポック数を図13にグラフ化する.
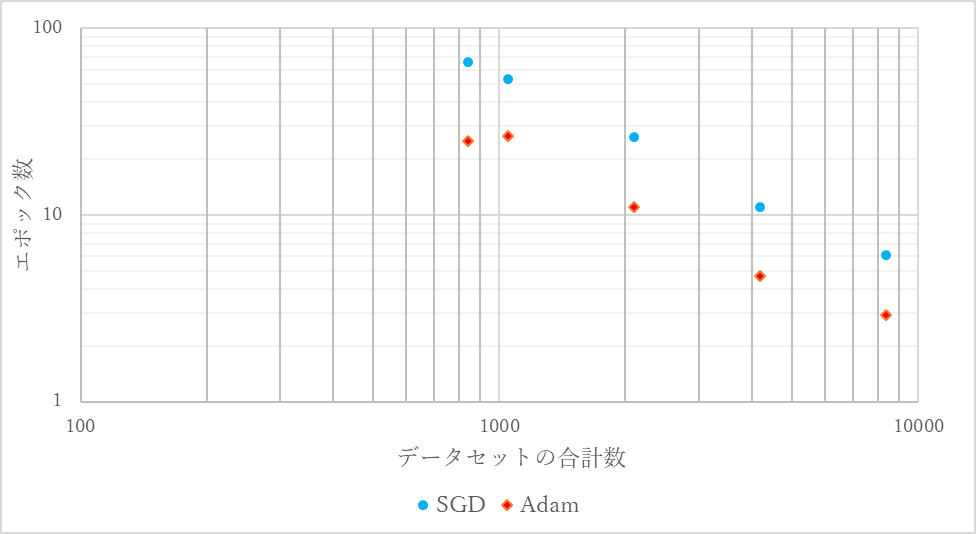
図13 データセットの合計数に対する正答率90%に達するのに必要なエポック数
SGDでもAdamでも検証データに対する正答率が80%を下回ったものはなく,過学習が起こっていないことが確認できる.Adamのデータセットの合計数が840枚の場合を除き,データセットの合計数が少なければ少ないほど必要なエポック数は増加した.また,データセットの合計数が同じであるときAdamの方が必要な平均エポック数は小さくなった.
データセットの合計数を420枚としたとき,SGDでもAdamでも10000エポック以下で正答率90%に達することは無かった.10001エポック以上で正答率90%に達したとしてもデータセットの合計数が8400枚のときに対してSGDでもAdamでも1000倍以上のエポック数が必要ということとなり,有用なデータであるとはいえないと判断したため本実験ではエポック数が10000に達した時点で学習を停止した.
実験2では用意した画像のうち図8,図9のように図形の全点がエリア内にある画像に加えて,図10,図11のように図形の一部はエリア内にないが重心がエリア内にある画像もニューラルネットワークに与え,学習させる.
まず,train.pyを用いて学習を行う.データセットは訓練用5000枚,テスト用5000枚,検証用4000枚で分割する.
訓練用,テスト用データセットでの学習で図形判別の正答率が90%以上に達するのに必要とする平均のエポック数とその時の検証データに対する正答率を表6,表7に示す.
表6 SGDの学習率に対する正答率が90%以上に達するのに必要とする平均のエポック数とその時の検証データに対する正答率(重心がエリア内)
| 学習率 | 平均エポック数 | 検証時の平均正答率 |
|---|---|---|
| 0.0001 | 1605.7 | 88.2925 |
| 0.0005 | 325.9 | 88.795 |
| 0.001 | 157.5 | 88.6825 |
| 0.005 | 36.1 | 89.0025 |
| 0.01 | 23 | 89.4275 |
| 0.05 | 14.9 | 89.065 |
| 0.1 | 20.2 | 89.2075 |
表7 Adamの学習率に対する正答率が90%以上に達するのに必要とする平均のエポック数とその時の検証データに対する正答率(重心がエリア内)
| 学習率 | 平均エポック数 | 検証時の平均正答率 |
|---|---|---|
| 0.0000001 | 3284.3 | 88.9275 |
| 0.000001 | 313.1 | 88.665 |
| 0.00001 | 24.2 | 88.485 |
| 0.00005 | 7.5 | 87.3525 |
| 0.0001 | 7.1 | 86.745 |
| 0.0005 | 8.8 | 84.535 |
学習率に対する正答率が90%以上に達するのに必要とする平均のエポック数を図12にグラフ化する.
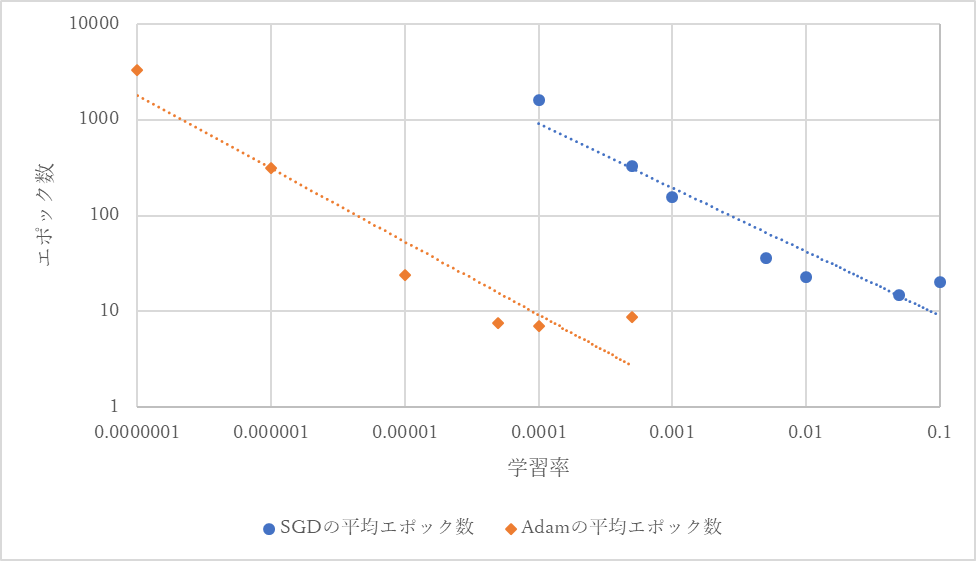
図14 学習率に対する正答率が90%以上に達するのに必要とする平均のエポック数(重心がエリア内)
SGDでもAdamでも検証データに対する正答率が80%を下回ったものはなく,過学習が起こっていないことが確認できる.実験1の結果と同様にSGDでは学習率0.05のとき,Adamでは学習率0.0001のとき正答率が90%以上に達するのに必要とする平均のエポック数が最小となる.また,必要な最低の平均エポック数はAdamの方が小さくなった.
実験1と同様に,SGDでは学習率が0.5の時点で,Adamでは学習率0.005の時点で10回の試行の全てで正答率が40%から60%程度で変化せず,学習が行われていないと判断できる状況となった.10001エポック以上で正答率90%に達したとしてもSGDの学習率が0.05のとき及びAdamの学習率が0.0001のときに対して500倍以上のエポック数が必要ということとなり,有用なデータであるとはいえないと判断したため本実験ではエポック数が10000に達した時点で学習を停止した.
次に,train2.pyを用いて学習を行う.学習は学習率をSGDが0.05,Adamが0.0001として,訓練用,テスト用データセットの合計数を減らしながら10回ずつ行う.このとき,図形判別の正答率が初めて90%以上に達したときのパラメータを保存し、検証用データセットで正答率の検証を行い,過学習が起きていないか確認する.
データセットの合計数に対する正答率90%に達するのに必要なエポック数とその時の検証データセットに対する正答率を表8,表9に示す.
表8 SGDのデータセットの合計数に対する正答率90%に達するのに必要なエポック数とその時の検証データセットに対する正答率(重心がエリア内)
| データセットの合計数 | 平均エポック数 | 検証時の平均正答率 |
|---|---|---|
| 10000 | 14.9 | 86.745 |
| 5000 | 40.7 | 90.2975 |
| 2500 | 43.9 | 90.5975 |
| 1250 | 87.9 | 89.5625 |
| 1000 | 116.5 | 88.9675 |
表9 Adamのデータセットの合計数に対する正答率90%に達するのに必要なエポック数とその時の検証データセットに対する正答率(重心がエリア内)
| データセットの合計数 | 平均エポック数 | 検証時の平均正答率 |
|---|---|---|
| 10000 | 7.1 | 86.745 |
| 5000 | 13.3 | 90.2975 |
| 2500 | 23.5 | 90.5975 |
| 1250 | 41.8 | 88.7525 |
| 1000 | 88.4 | 89.34 |
データセットの合計数に対する正答率90%に達するのに必要なエポック数を図15にグラフ化する.
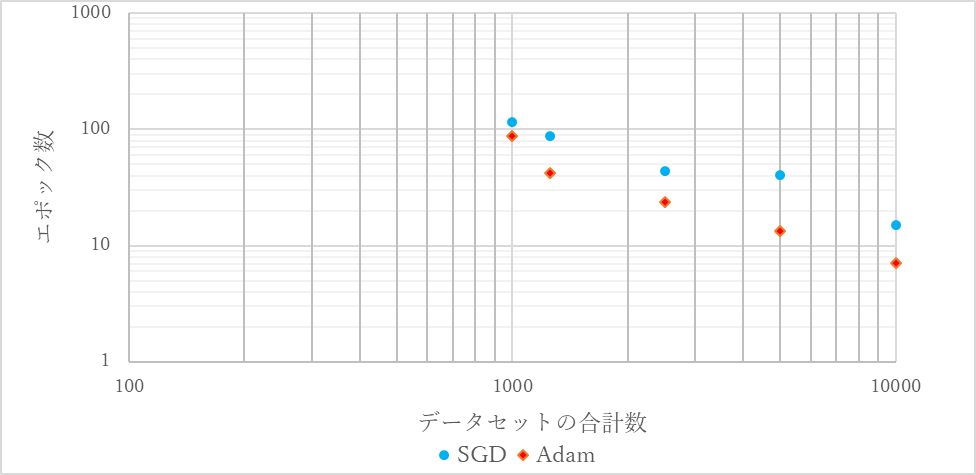
図15 データセットの合計数に対する正答率90%に達するのに必要なエポック数(重心がエリア内)
SGDでもAdamでも検証データに対する正答率が80%を下回ったものはなく,過学習が起こっていないことが確認できる.実験1の結果と同様にデータセットの合計数が少なければ少ないほど必要なエポック数は増加した.また,同じデータセットの合計数であってもAdamの方が必要な平均エポック数は小さくなった.
データセットの合計数を500枚としたとき,SGDでもAdamでも10000エポック以下で正答率90%に達することは無かった.10001エポック以上で正答率90%に達したとしてもデータセットの合計数が10000枚のときに対してSGDでもAdamでも500倍以上のエポック数が必要ということとなり,有用なデータであるとはいえないと判断したため本実験ではエポック数が10000に達した時点で学習を停止した.
学習用データセットの全点がエリア内に有る画像と図形の一部はエリア内にないが重心がエリア内にある画像の割合を変化させながらどの程度のエポック数で正答率が収束するか確認する.なお,学習用のデータセットは合計1300枚とする.
図16から図37にそれぞれのオプティマイザと学習用のデータセットの内容における10回の学習の誤答率の結果のグラフを示す.
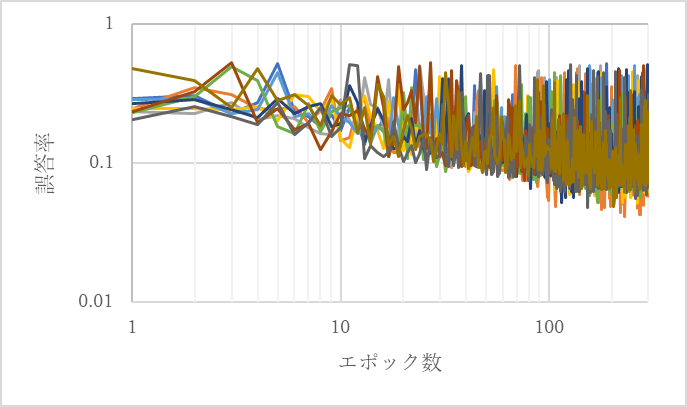
図16 SGDの10回の学習結果1(全体の0割が一部がエリア外の画像)
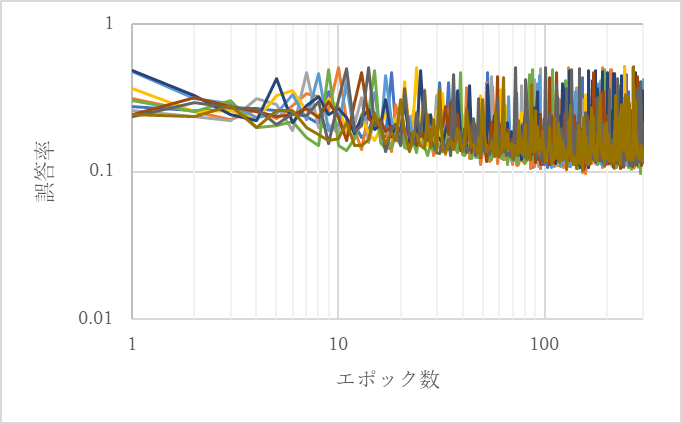
図17 SGDの10回の学習結果2(全体の1割が一部がエリア外の画像)
図18 SGDの10回の学習結果3(全体の2割が一部がエリア外の画像)
図19 SGDの10回の学習結果4(全体の3割が一部がエリア外の画像)
図20 SGDの10回の学習結果5(全体の4割が一部がエリア外の画像)
図21 SGDの10回の学習結果6(全体の5割が一部がエリア外の画像)
図22 SGDの10回の学習結果7(全体の6割が一部がエリア外の画像)
図23 SGDの10回の学習結果8(全体の7割が一部がエリア外の画像)
図24 SGDの10回の学習結果9(全体の8割が一部がエリア外の画像)
図25 SGDの10回の学習結果10(全体の9割が一部がエリア外の画像)
図26 SGDの10回の学習結果11(全体の10割が一部がエリア外の画像)
図27 Adamの10回の学習結果1(全体の0割が一部がエリア外の画像)
図28 Adamの10回の学習結果2(全体の1割が一部がエリア外の画像)
図29 Adamの10回の学習結果3(全体の2割が一部がエリア外の画像)
図30 Adamの10回の学習結果4(全体の3割が一部がエリア外の画像)
図31 Adamの10回の学習結果5(全体の4割が一部がエリア外の画像)
図32 Adamの10回の学習結果6(全体の5割が一部がエリア外の画像)

図33 Adamの10回の学習結果7(全体の6割が一部がエリア外の画像)
図34 Adamの10回の学習結果8(全体の7割が一部がエリア外の画像)
図35 Adamの10回の学習結果9(全体の8割が一部がエリア外の画像)
図36 Adamの10回の学習結果10(全体の9割が一部がエリア外の画像)
図37 Adamの10回の学習結果11(全体の10割が一部がエリア外の画像)
図16から図37より,正答率が90%を超えるとき以外のいずれの場合も100エポックから200エポック程度もしくは200エポックから300エポック程度で誤答率の下限が収束しているように見える.つまり,100エポック連続で正答率が更新されなければ学習は十分であると考えられる.そこで,正答率の最高値が100エポック連続で更新されていなければ学習は十分であるとし,その時のパラメータを用いて検証データセットで検証を行う.
実験4では学習用データセットの図形の全点がエリア内に有る画像と図形の一部はエリア内にないが重心がエリア内にある画像の割合を変化しながら検証用データセットで検証を行う.実験4での学習用のデータセットの合計数は1300枚とし,検証用データセットは図形の全点がエリア内に有る画像100枚のみで構成されているもの,図形の一部はエリア内にないが重心がエリア内にある画像100枚のみで構成されているものの2種類とする.
実験4に用いたプログラムをtrain3.pyとする.train3.pyは正答率が更新されるたびその時のパラメータを保存し,正答率が90%に達すればその時のパラメータを,100エポック連続で正答率が更新されなかったとき更新されなかった100エポック前のパラメータを用いて検証を行う.100エポック連続で正答率が更新されなかったときのパラメータでの検証データセットに対する正答率を表10,表11に示す.
表10 SGDの図形の一部がエリア外の画像の割合に対する検証データセットに対する正答率
| 図形の一部がエリア外の画像の割合 | 検証データセットに対する正答率 | |
|---|---|---|
| 全点がエリア内 100枚 | 一部がエリア外 100枚 | |
| 0 | 89.2 | 71.8 |
| 10 | 88.1 | 72.2 |
| 20 | 78.7 | 71.8 |
| 30 | 72.1 | 71.9 |
| 40 | 75.1 | 70.3 |
| 50 | 77.4 | 70.9 |
| 60 | 73.7 | 71.6 |
| 70 | 81.6 | 77.7 |
| 80 | 80.3 | 78.9 |
| 90 | 81.2 | 80.6 |
| 100 | 70.2 | 83.4 |
表11 Adamの全データセットに対する図形の一部がエリア外の画像の割合に対する検証データセットに対する正答率
| 図形の一部がエリア外の画像の割合 | 検証データセットに対する正答率 | |
|---|---|---|
| 全点がエリア内 100枚 | 一部がエリア外 100枚 | |
| 0 | 93.7 | 71.6 |
| 10 | 78.8 | 69.8 |
| 20 | 78.7 | 71.6 |
| 30 | 76.4 | 70.9 |
| 40 | 76.3 | 68.5 |
| 50 | 77.5 | 70 |
| 60 | 77.3 | 72.8 |
| 70 | 77.5 | 72.9 |
| 80 | 79.6 | 75.2 |
| 90 | 79.9 | 82.1 |
| 100 | 69.3 | 84 |
図形の一部がエリア外の画像の割合に対する検証データセットに対する正答率を図38にグラフ化する.
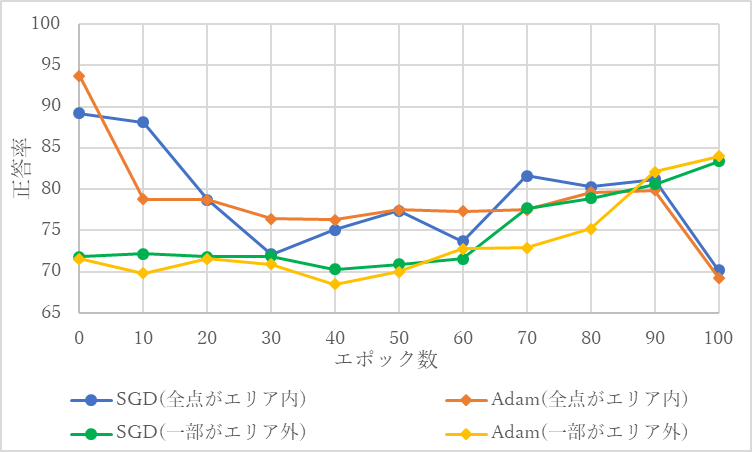
図38 データセット中の一部がエリア外の画像の割合に対する検証データセットに対する正答率
学習用のデータセット全てが図形の全点がエリア内の画像であったとき,全点がエリア内の検証用データセットに対する正答率はSGDでもAdamでも90%程度であったが,学習用のデータセット全てが画像の一部がエリア外の画像であったとき,図形の一部がエリア外の検証用データセットに対する正答率はSGDでもAdamでも85%程度となった.学習用のデータセットのうち2割から6割が図形の一部がエリア外であったとき,いずれの場合も正答率80%を超えるものはなかった.
学習用のデータセットの1割から5割が図形の一部がエリア外の画像であったとしても,図形の一部がエリア外の画像の判別の正答率はそれほど上昇せず,逆に図形の全点がエリア内の画像の判別の正答率が10%以上下がることすらあるため,図形の一部がエリア外の画像をデータセットに少量加えるのは正答率を上げるのに逆効果であると考えられる.逆に, 1割から2割程度が図形の全点がエリア内の画像でそれ以外が図形の一部がエリア外の画像となるように学習用のデータセットを構成することで,全く図形の全点がエリア内の画像が入っていないのに対し,全点がエリア内の画像の判別の正答率が10%程度上昇するため,図形の全点がエリア内の画像をデータセットに少量加えるのは正答率を上げるのに効果的であると考えられる.
いずれの実験においてもSGDよりもAdamの方が必要なエポック数は小さくなった.実験1の結果である図12,実験2の結果である図14の両方とも両軸が対数であるため一定の正答率に達するために必要とするエポック数は画像内の図形の全点がエリア内にあるか否かに関わらずSGDでもAdamでも反比例的に変化したといえる.また,学習率に大きすぎる値を設定すると学習が行われなくなることが確認できた.
図16に実験1と実験2の学習率に対する正答率が90%以上に達するのに必要とする平均のエポック数を比較したグラフを示す.
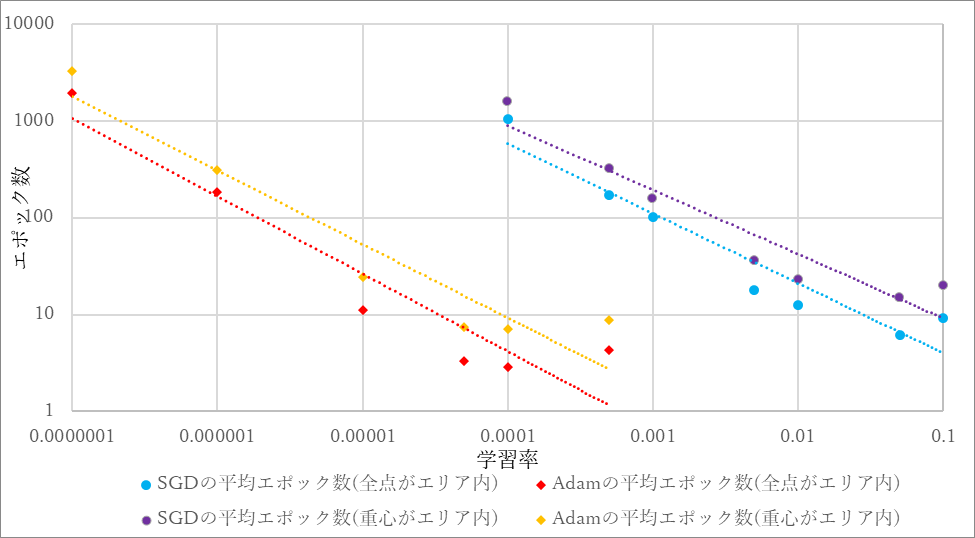
図39 学習率に対する正答率が90%以上に達するのに必要とする平均のエポック数の比較
図39から図形の一部がエリア内にない画像を加えると,データセットの数が一定の場合でも一定の正答率に達するために必要とするエポック数は増加していることが確認できる.
実験3の図38から学習用のデータセットの全てが図形の全点がエリア内の画像,もしくは図形の一部がエリア外の画像であっても,70%程度はもう一方を判別することができているということが確認できる.図形の全点がエリア内である画像は学習用のデータセットに全く入れないのと1割入れるのでは10%程度の正答率の差が生じたのに対し,図形の一部がエリア外の画像は学習用のデータセットに全く入れなくても1割から2割程度入れたとしても判別の正答率はそれほど変化しなかった.
本研究ではハイパーパラメータの重要度を調べるために単純な学習として三角形と円の図形画像を対象とし,ハイパーパラメータの値の変化によりニューラルネットワークの図形画像判別にどの程度影響を及ぼすか調査した.円と三角形の図形画像分類をニューラルネットワークを用いて行う際,学習率は一定の正答率に達するために必要とするエポック数に対して反比例的な影響を及ぼし,AdamはSGDよりも短い時間で一定の正答率に達することが確認できた.但し,SGDでは学習率が0.05より大きくなったとき, Adamでは学習率が0.0001より大きくなったとき一定の正答率に達するために必要とするエポック数は増加したため,一定の正答率に達するために必要なエポック数には下限があり,それを下回ることはないと考えられる.また,図形の一部がエリア内にない画像を加えると一定の正答率に達するために必要とするエポック数は増加した.
これらのことから,学習率は大きすぎる値を設定すると学習が行われなくなるため,学習率はニューラルネットワークの図形画像の判別の正答率に反比例的な変化を及ぼすことを考慮しつつ,学習率を設定する際には小さめの学習率で数回試行することで適切な学習率を推測するのがよいと考えられる.また,円と三角形の図形画像分類にはSGDよりもAdamの方が適しているといえるだろう.さらに,訓練時のデータセットが多ければ多いほど一定の正答率に達するための必要エポック数が少なくなるため,データセットは多い方がよく,円と三角形の図形画像分類を行う際には最低限1000枚程度の学習用のデータセットを用意した方がよいと考えられる.
実験3の結果から学習用のデータセットの全てが図形の全点がエリア内の画像,もしくは図形の一部がエリア外の画像であってもある程度はもう一方を判別することができているということが確認できた. また,図形の全点がエリア内の画像1: 図形の一部がエリア外の画像9といった学習用データセットを用いるといずれの検証においても正答率は80%程度になったため,図形の全点がエリア内の画像も図形の一部がエリア外の画像も分類したいのであれば,それぞれが1:9の割合の学習用データセットを用いるのが効果的であると考えられる.
本研究では,ハイパーパラメータの影響力を調査することで,限られた条件内のみで有効である可能性はあるものの,適切なハイパーパラメータの決定方法を見つけることができた.今後実験を行う際にはより複雑な画像を実験の対象にすることやより多くのオプティマイザを用いて実験を行うことでより汎用的なハイパーパラメータの決定方法を見つけることができると考えられる.