
本稿では、多視点画像から 3 次元形状を推定する機械学習を提案し、 評価観点から評価結果を生成したり、評価結果から評価観点を見つけ出したりするといった実験を行い、 その結果を考察する。
3章で行われる実験では、図2-1のような主観デコーダを構築した。
3次元空間内の被写体を透視投影して得られる画像をアングル情報から推定するニューラルネットワークモデルを学習する実験を行う。
Google Colab GPU
RAM: およそ12GB
本研究では、3次元空間を表現するためのソフトウェアとして MikuMikuDance(以下MMD)を用いた。しえら式アリス・オルタナティブ(アリス・マーガトロイド)のMMDモデルを用い、組(アングル, 画像)を4096枚用意した。
MMDに表示される(見かけ上の)座標軸と実際にシステムが基準としている座標軸は その\(z\)軸が入れ違いになっている。 例えば図3-3-1-1-1は、座標\((5, 0, 0)\)に赤白色の錠剤を、\((0, 5, 0)\)に黄色の錠剤を、 \((0, 0, 5)\)に青白色の錠剤を配置したものである。 この結果から、赤い線分は\(x\)軸、 緑の線分は\(y\)軸を表すが、青い線分は\(z\)軸ではなく\(-z\)軸を表現していることが分かる。 また、見かけ上の座標軸は右手座標系であるが、実際の座標軸は左手座標系である。
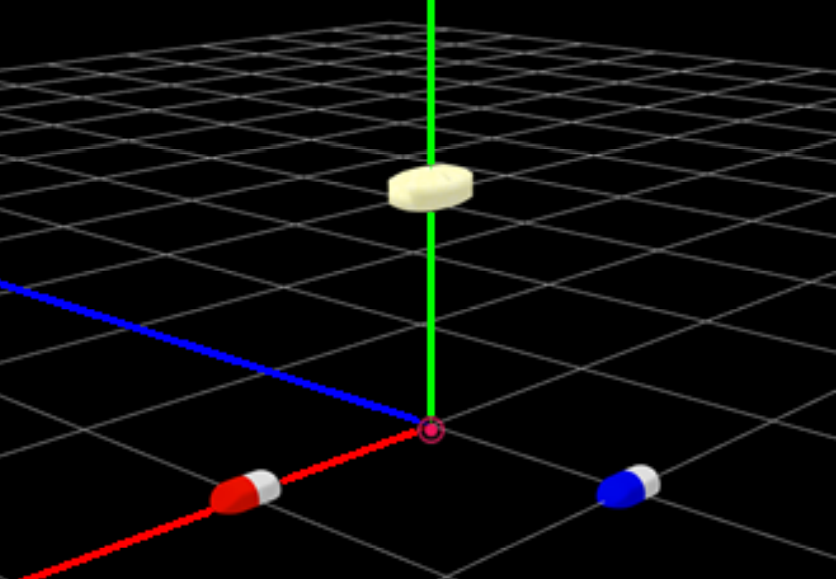
図3-3-1-1-1. 見かけ上の座標軸と実際の座標軸
MMDにおいて、基本的なカメラ操作は、表3-3-1-2-1に示す次の7つのパラメータに指定することにより行われる。
表3-3-1-2-1. MMDにおけるカメラの基本的なパラメータ
| パラメータ名 | 説明 | 設定値 |
|---|---|---|
| カメラ中心\(x\) | 透視投影後に投影面の中心点に写される、 3次元空間上の線分を「視線」と呼ぶことにする。 MMDユーザはこの視線が必ず通る点(カメラ中心点) を1箇所指定することができる。その座標。 | 0 |
| カメラ中心\(y\) | 18 | |
| カメラ中心\(z\) | 0 | |
| \(x\)角度(°) | 地球の中心が原点、中心から北極点への方向を\(y\)軸正、 経緯度0°地点への方向が\(x\)軸正となるように 地球を平行、回転移動させたとき、 \(y\)角度\(=-(180-\theta)^{\circ}\)、\(x\)角度\(=\phi^\circ\) の向きを眺めるカメラは東経\(\theta^\circ\)、緯度\(\phi^\circ\) の地点の上空、地上、地下のいずれかに位置することとなる。 | 入力データ |
| \(y\)角度(°) | ||
| \(z\)角度(°) | 透視投影後に投影面を反時計回りにいくら回転させるか | 0 |
| 距離 | 距離 | 5 |
アングルとは MMD モデルを眺める角度の情報である。
アングルは \(x\) 角度と \(y\) 角度をこの順で成分に持つ 2 次元ベクトルであり、各成分
は float32 型変数であって、0 以上 1 以下の値\(k\)により、\((360k − 180)^\circ\)
を表現する。
画像とは、そのアングルから得られた MMD モデルを bmp ファイル形式で描画
したデータ、またはこれに対応する uint8 型 3 次元 ndarray のことである。
実験に当たっての諸計画は次の通りである。
アングルを分類問題、データを 64 枚(8 方向×8 方向) とし、10500 エポックだけ学習した。 その結果の一部を図 3-4-1 に示す。

図3-4-1.実験Aにおける学習結果(\(y\)角度は0°)
図 3-4-1 における 1 画素ずつ点在する黒、赤、緑、青、シアン、マゼンタ、イエロー色のノ
イズは、出力結果の各成分を 256 倍して uint8 型に変換した際に発生したオーバフローに
起因するものであると考えられる。
正解データのうち、訓練データとして与えたデータはほぼ完全に再現されて出力されるも
のの検証データやテストデータに対しては全く見当外れの出力を行っていることが分かる。
このことは、過学習が発生していることを示唆している。
また損失や正解率のエポック回数に対する特性は図 3-4-2 および図 3-4-3 のようになった。 ここからおよそ 100 エポック目程度で過学習が発生したと考えることができる。
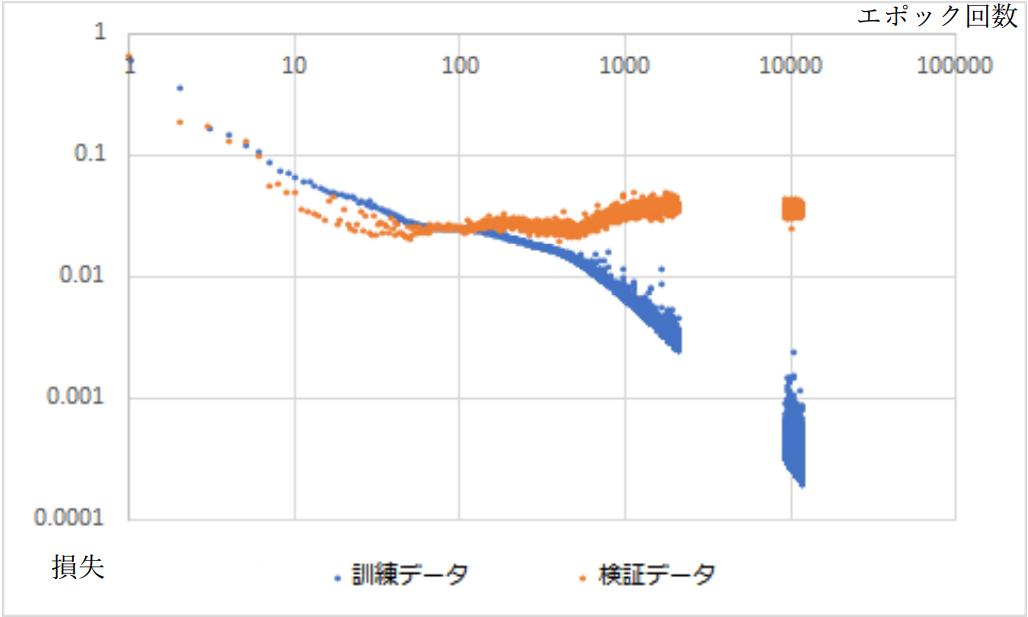
図3-4-2.損失(平行2乗誤差)のエポック回数特性
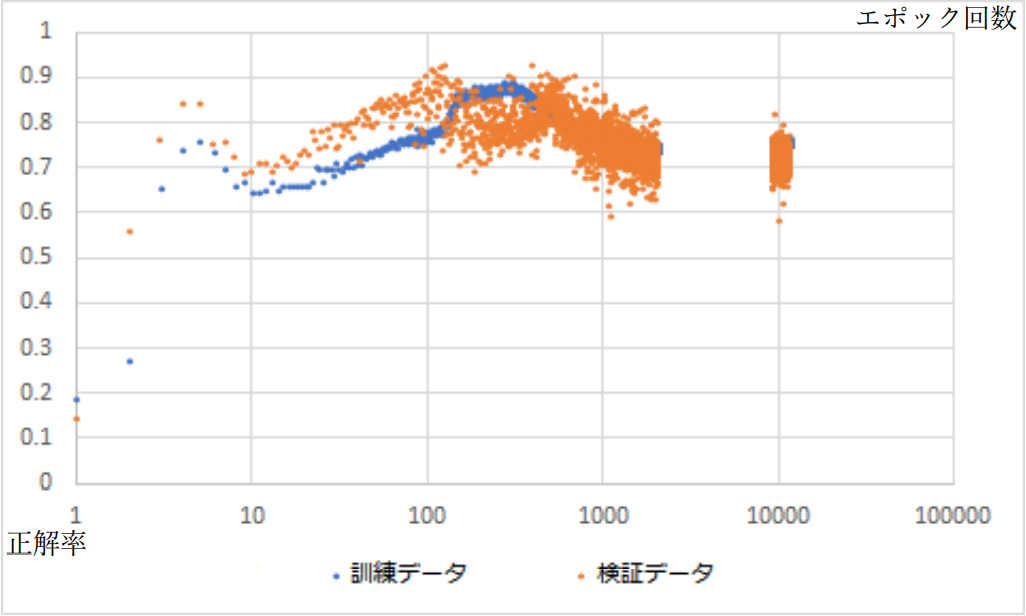
図3-4-3.正解率のエポック回数特性
アングルを回帰問題、データを 64 枚(8 方向×8 方向) とし、538 エポックおよび 3538 エ ポックだけ学習した。その結果の一部を図 3-5-1 に示す。

図3-5-1.実験B-1における学習結果(\(y\)角度は0°)
3538 エポック目について、左から 2 つ目と 4 つ目、1 つ目と 5 つ目の出力データが酷似し ている。このことから、未知の入力に対して、既に学習したデータを当てはめて出力するこ とを学習したことが示唆される。 また損失や正解率のエポック回数に対する特性は図 3-5-2 および図 3-5-3 のようになった。 およそ 1000 エポック目付近で過学習が発生したようだ。
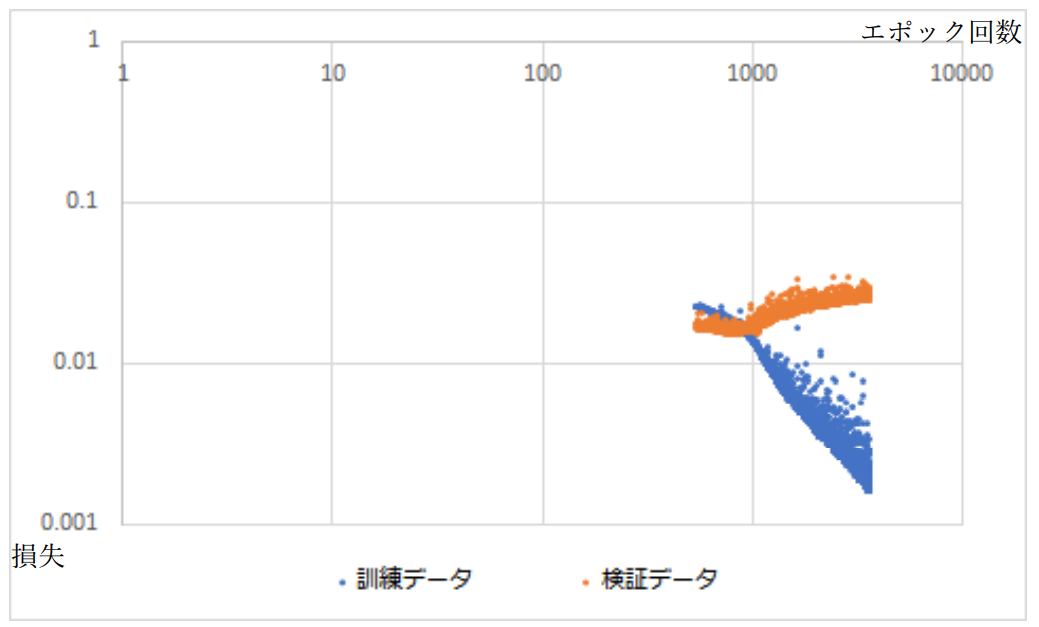
図3-5-2.損失のエポック回数特性
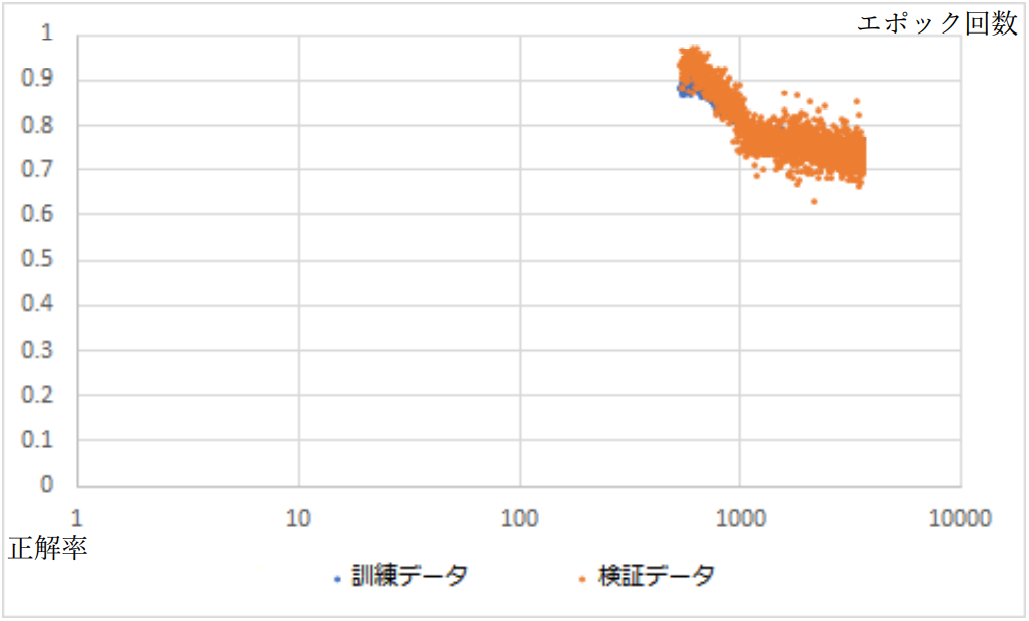
図3-5-3.正解率のエポック回数特性
但し、538 エポック以前については実験中の不具合によりデータが喪失している。
アングルを回帰問題とした場合、4096 枚(64 方向×64 方向)とし、84 エポックだけ学習し た。その結果の一部を図 3-6-1 に示す。
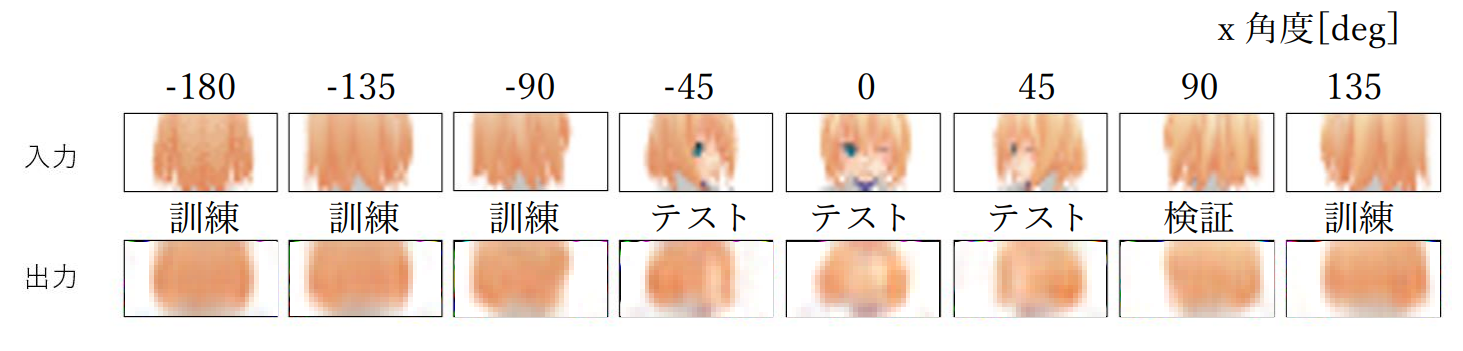
図3-6-1.実験B-2における学習結果(\(y\)角度は0°)
全体的にぼやけていて、表情などは確認できないが、訓練データとして与えた入力に対して もその他の入力に対してもその出力に明確な差異はなく、 直観的にも、髪の毛と肌を区別できていることがわかった。
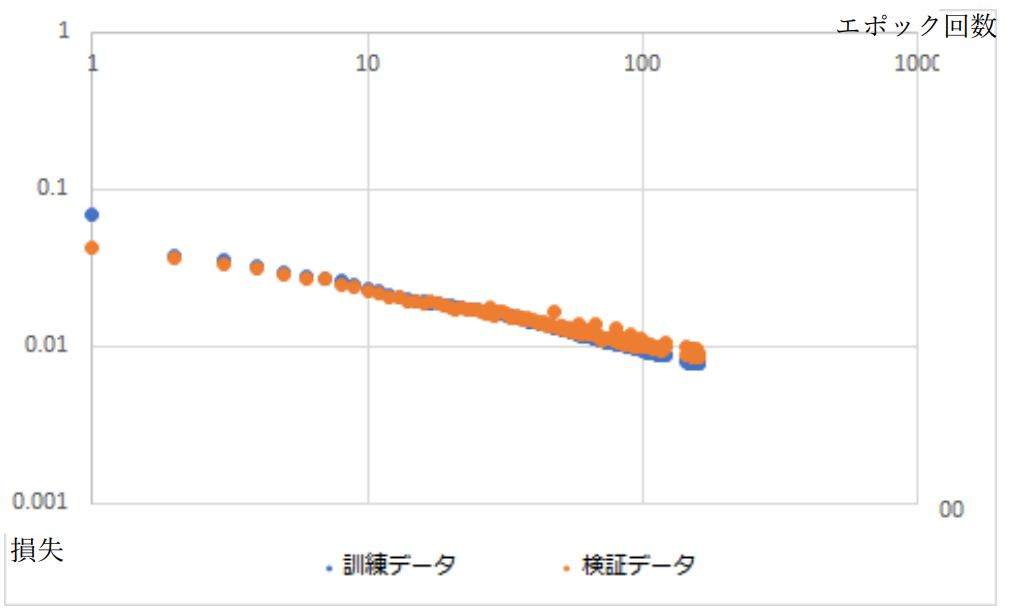
図3-6-2.損失のエポック回数特性
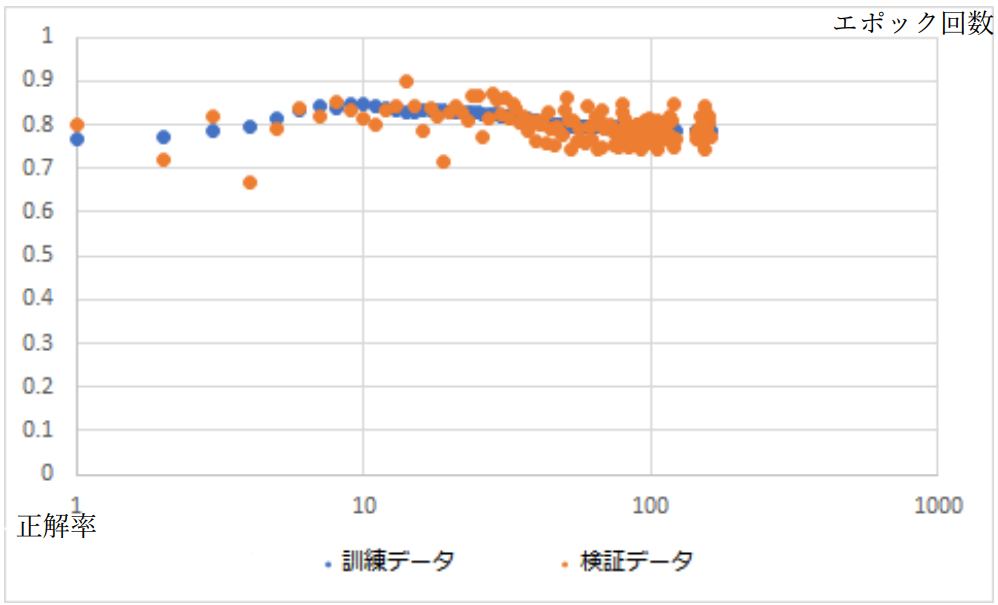
図3-6-3.正解率のエポック回数特性
過学習は少なくとも 100 エポック目以内において発生していないと考えられる。
自作モジュール learn.py を作成し、実行することで、データの成形、モデルの設計、学 習、学習結果の取得を行った。フローチャートは図 4-1 の通り。
図4-1.実験に用いたプログラムのフローチャート
本実験を通じて、3 次元顔モデルに対してアングルから 2 次元画像を推定するモデルにつ いて、アングルを one-hot ベクトルで表現する入力形式と、緯度と経度の 2 次元ベクトルで 表現する入力形式では後者がより優れていること、また教師データを増やすことで近似性 能が向上することがわかった。ただし図 3-6-1 からもわかる通り現状では細部(例えば目や 鼻などの構造)の再現には至っていないため、このことが今後の課題となる。
{kind=link}
{kind=link}