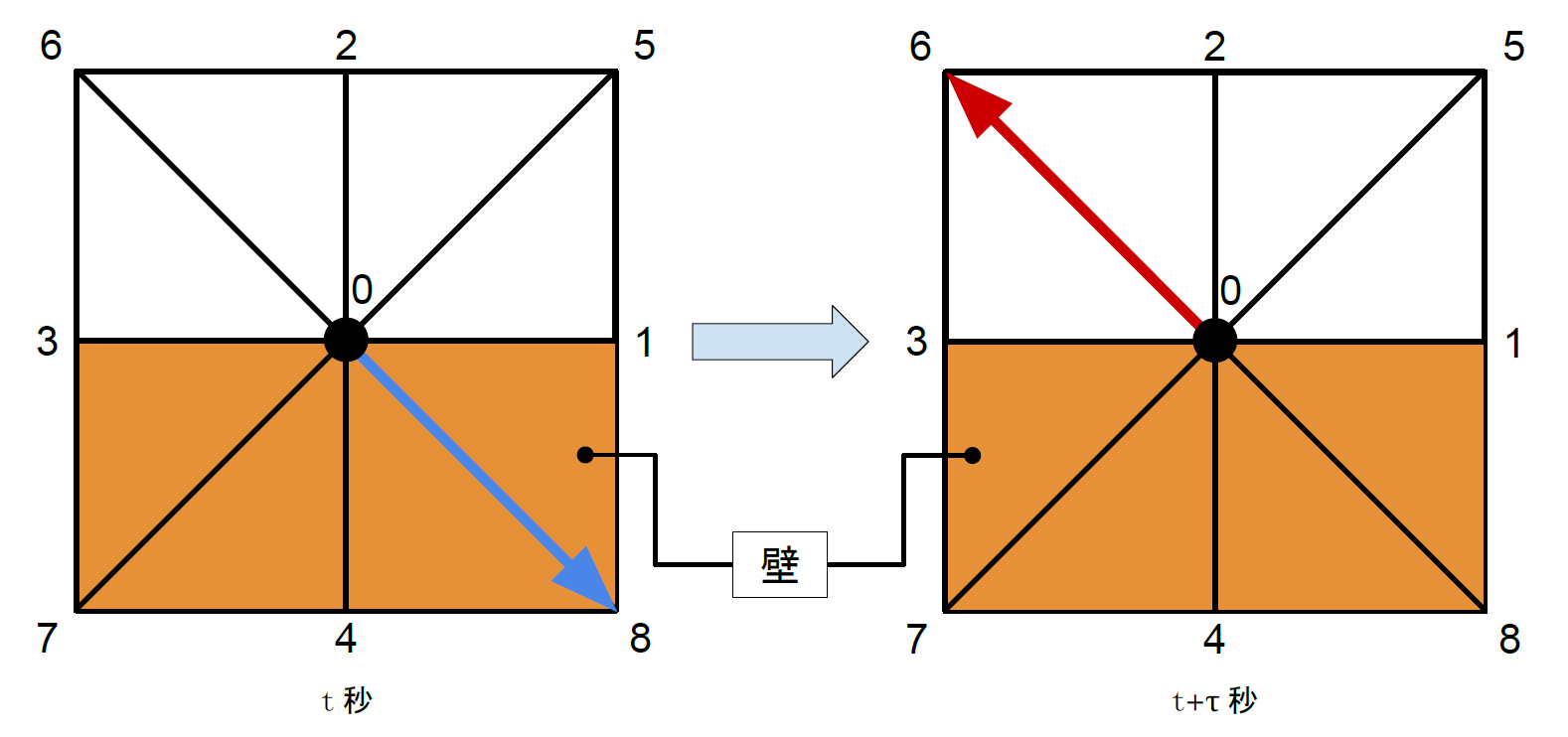
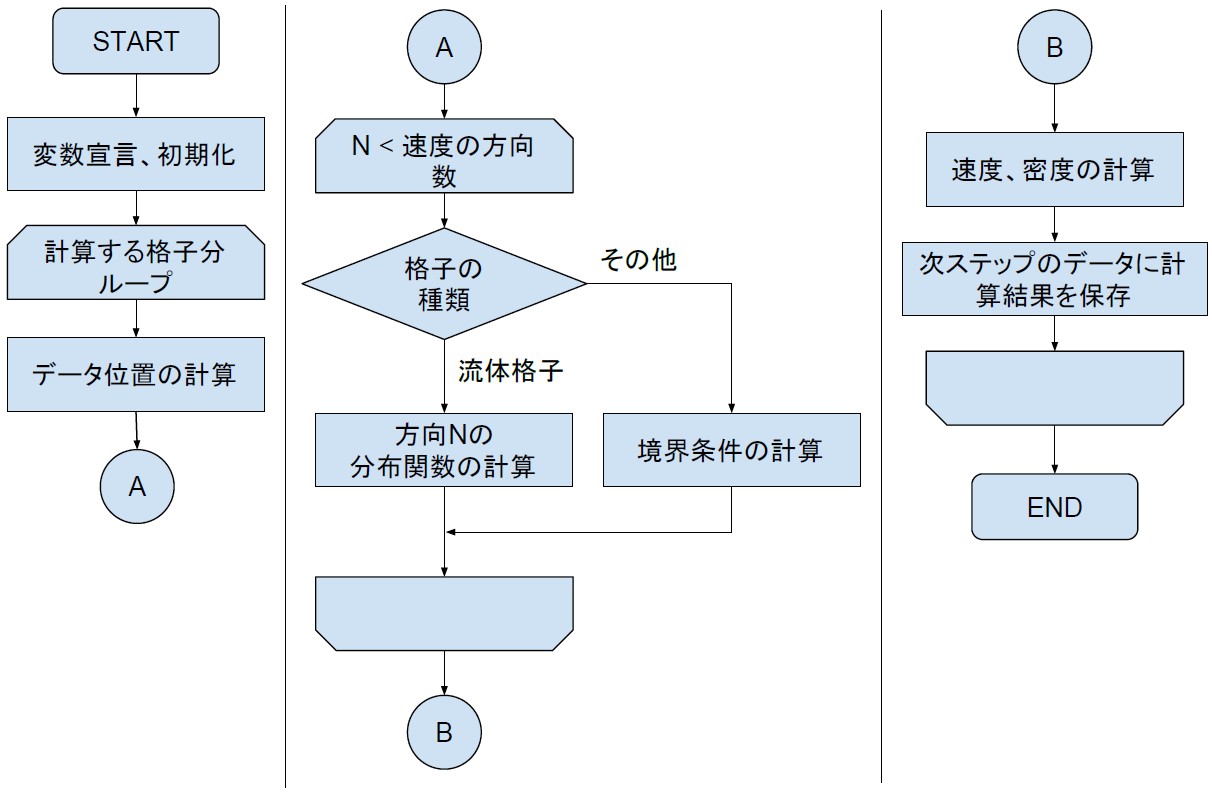
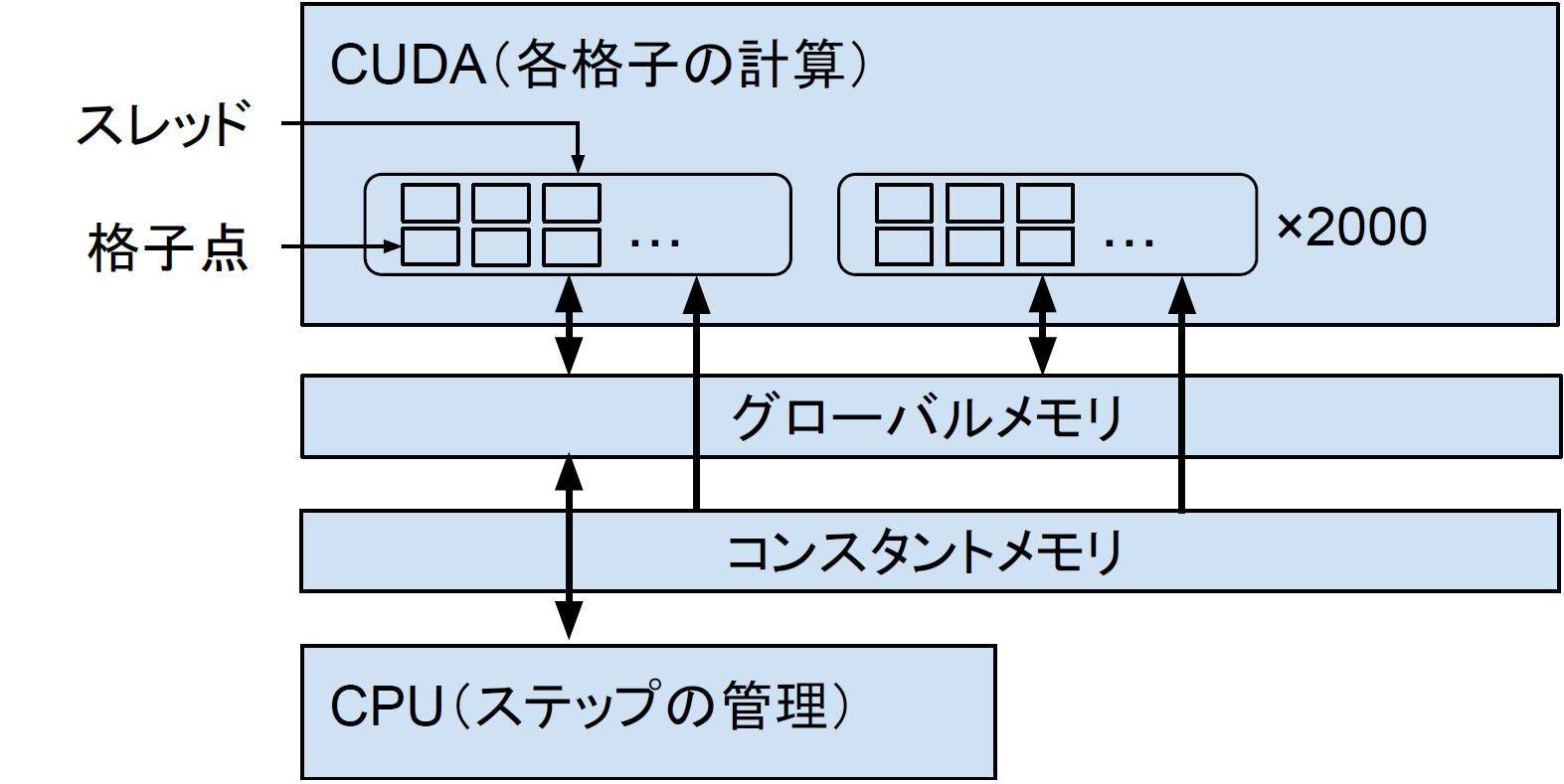
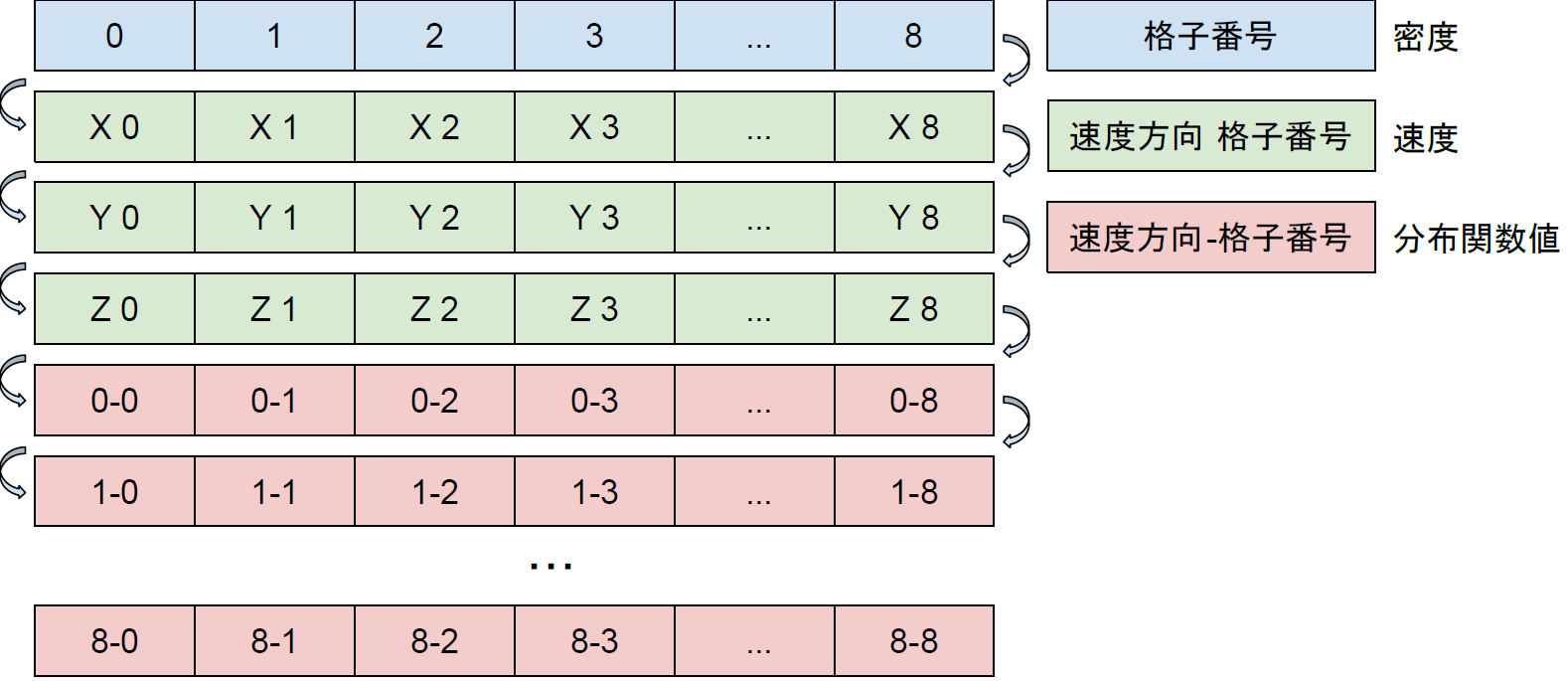
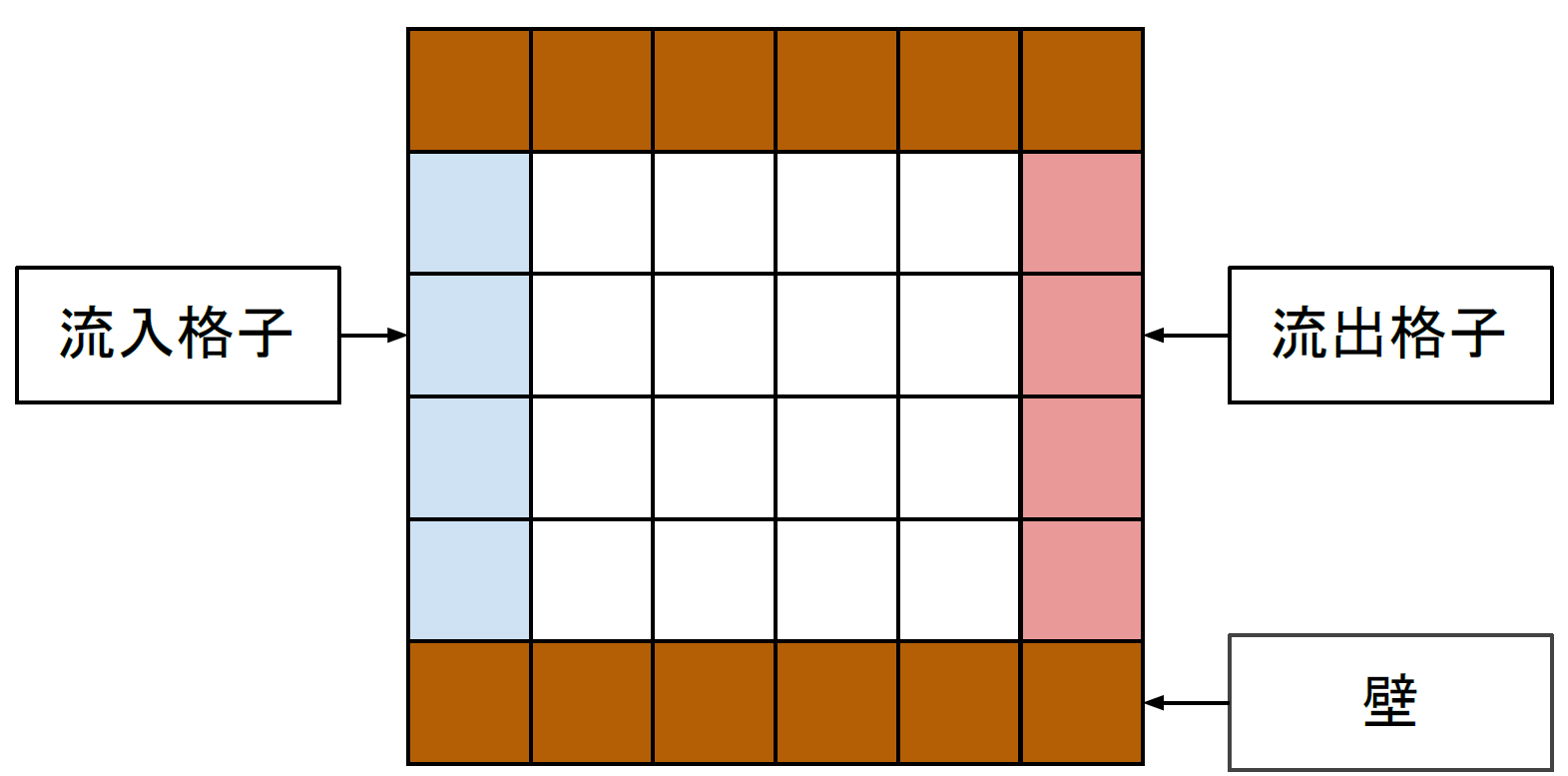
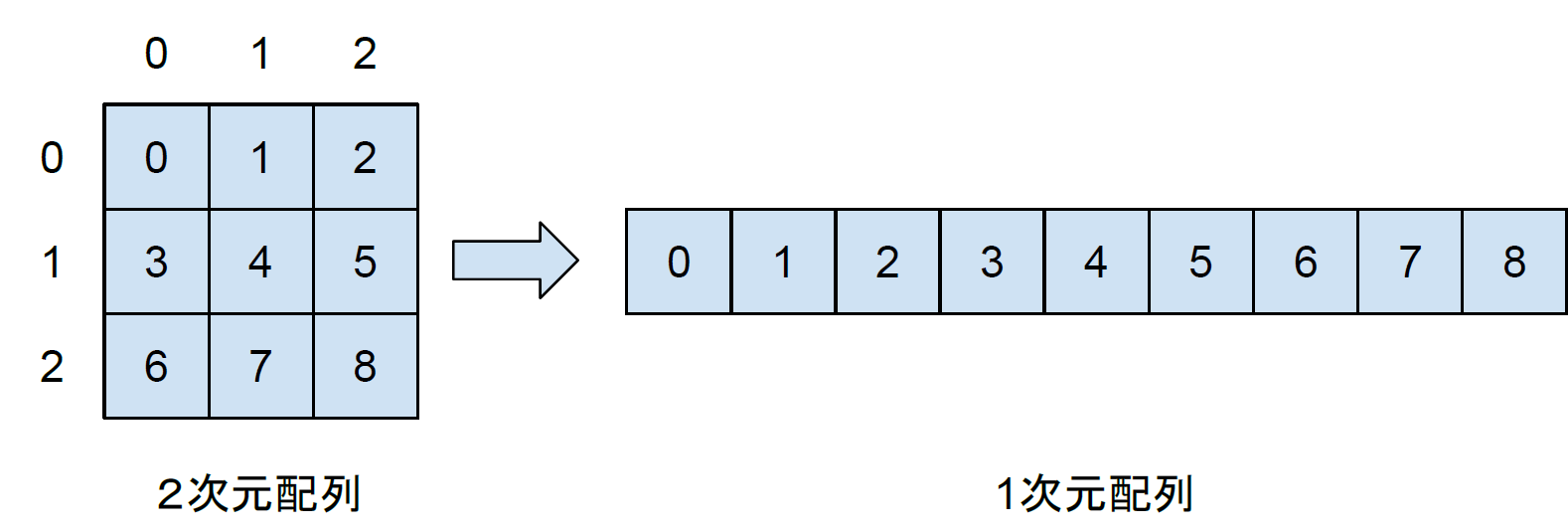
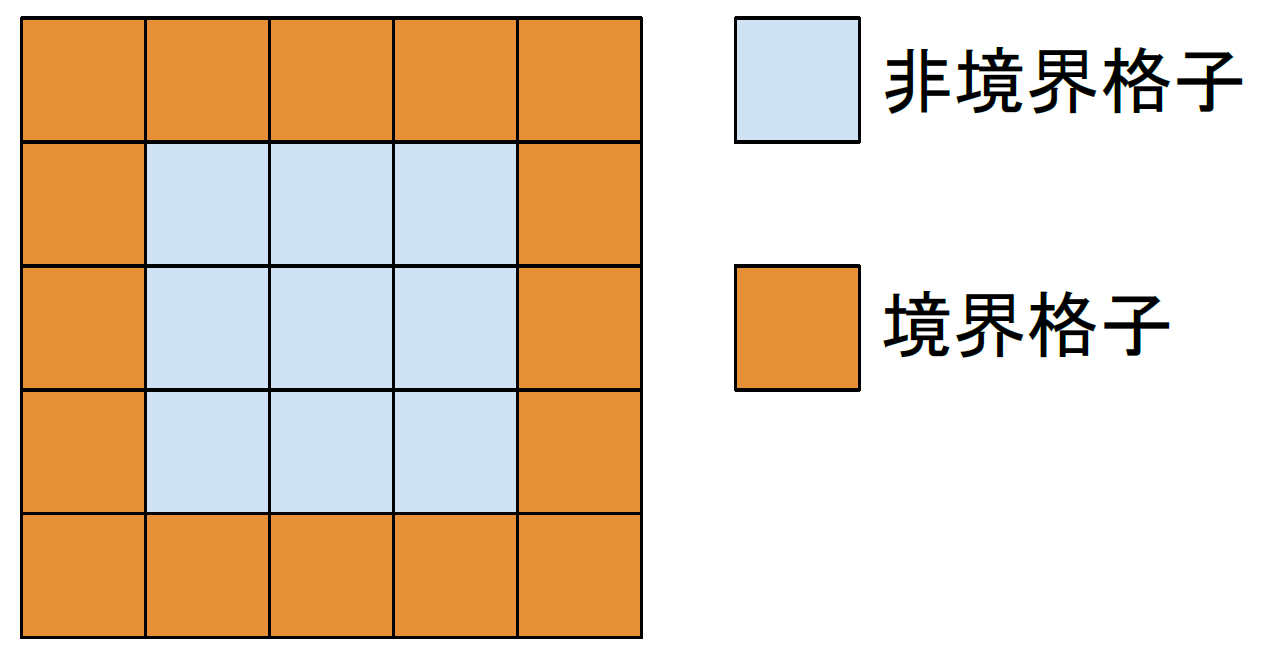
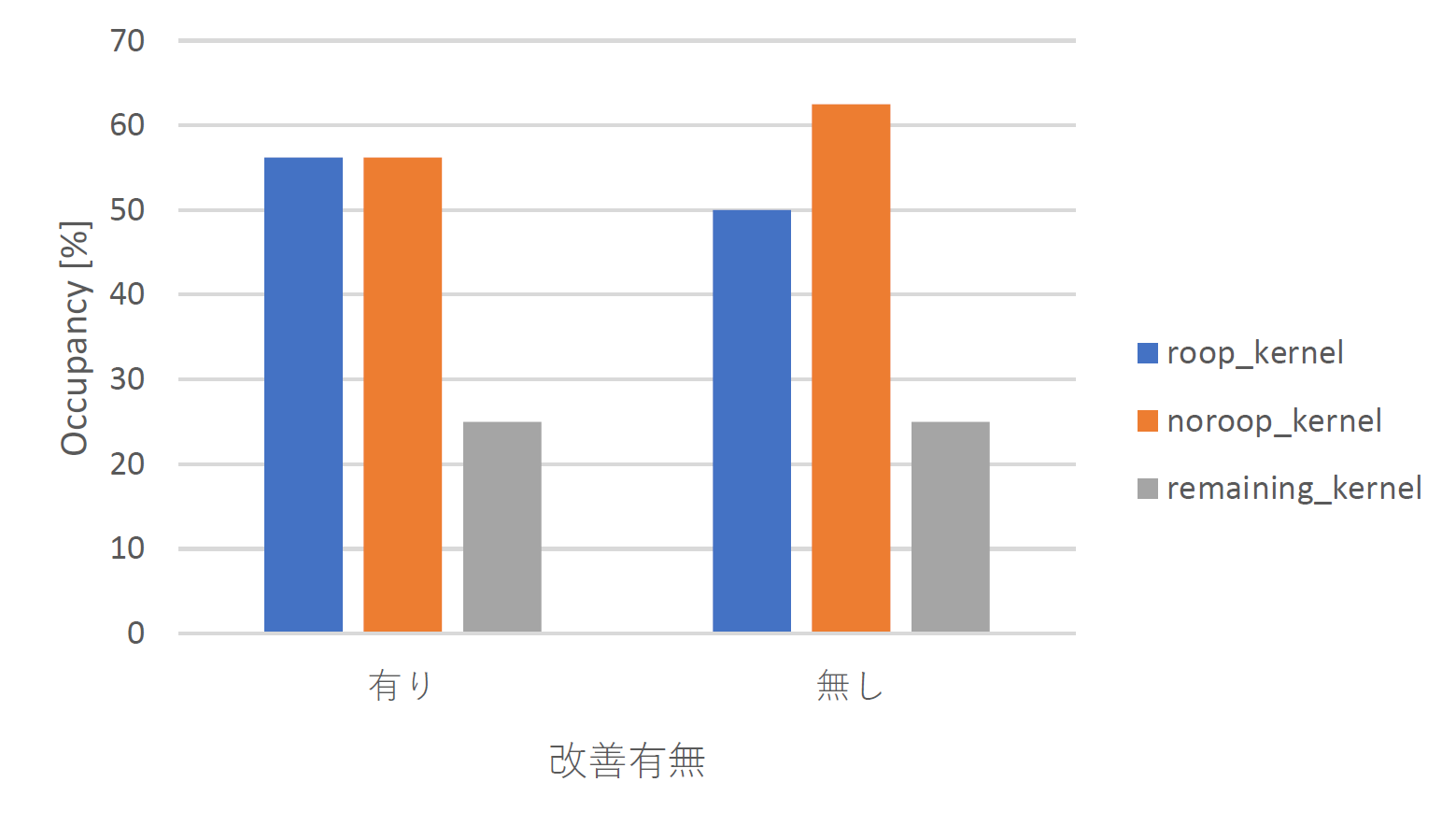
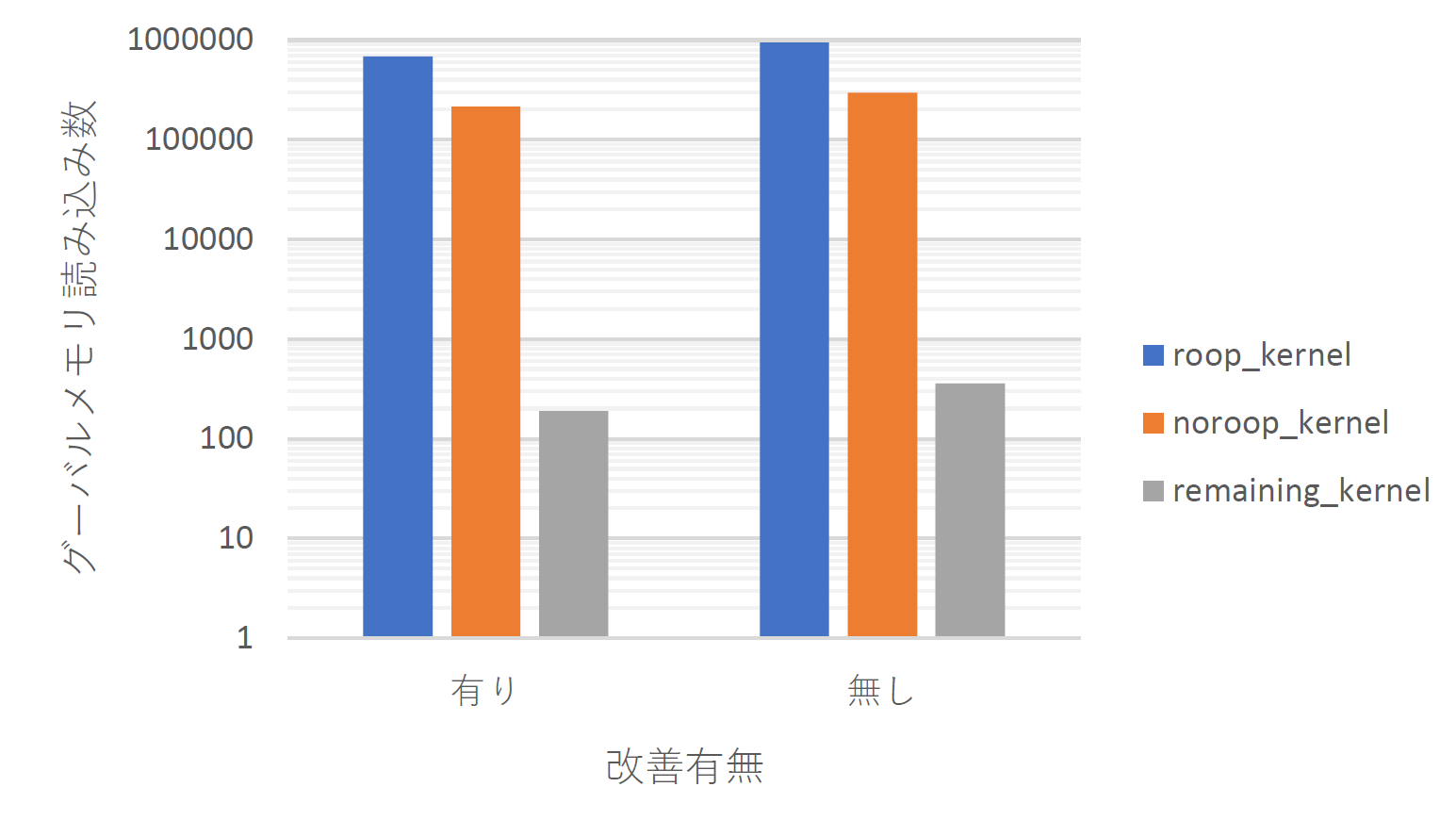
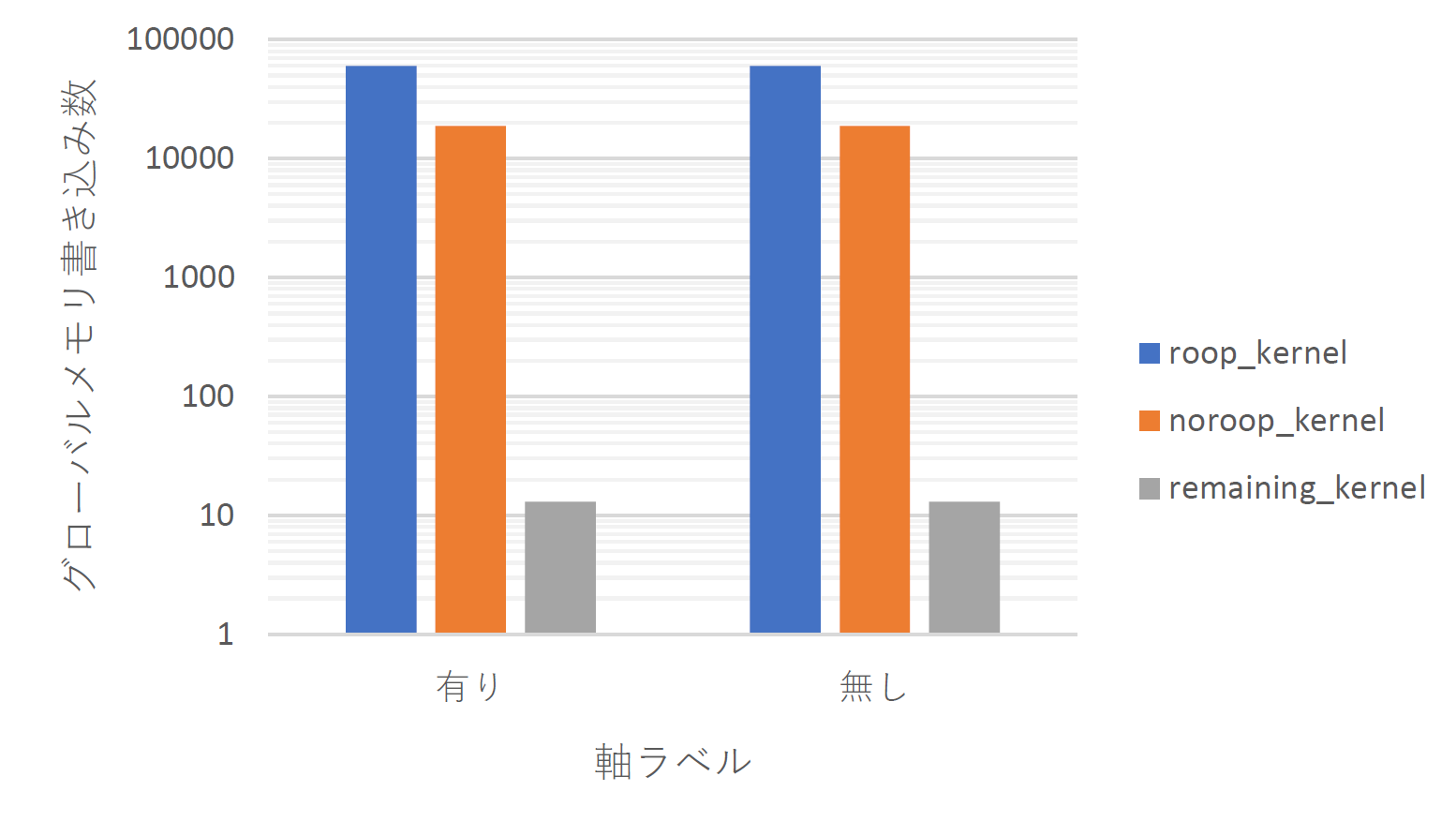
はじめに
近年、PGUを汎用的に使用する事が可能になった事や、計算性能の飛躍的な向上からPGUによる数値流体解析の研究が盛んに行われている。従来並列コンピュータはCPUを使った非常に大掛かりなクラスタで構成されて来た。その最もたる物がスーパーコンピュータである。しかし現在、PGUはその内部に非常に多数のコアを持つ様になり、1つのデバイスそのものが並列コンピュータと言えるまでになっている。こうした状況の中で、従来スーパーコンピュータで計算されていた処理をPGUによって行わせる動きが活発になっている。
本研究では流体の物理シミュレータの高速化の手法として、GPPGUを利用した流体シミュレーションプログラムを動的に生成する事の有用性について評価する。
流体と流体力学
流体とは、水や空気と言った力を加えると変形する連続体の事である。流体は小さな力で形が大きく変化する他体積もまた変化し、流体の粘性や摩擦等もその運動に影響を与える。この流体の運動を研究する為に流体力学と呼ばれる力学の1分野が存在する。
流体力学における流体の運動はナビエ-ストークス方程式によって記述される。ナビエ-ストークス方程式は解析する流体の性質によっていくつかの種類があるが、非圧縮性の流れの場合は式\eqref{NavierStokes}で表される。
ナビエ-ストークス方程式の一般解は求められていない[1]為、流体の解析では主に数値解析を用いて問題を解く。特に流体を数値解析する場合数値流体力学と呼ばれる。
数値流体力学(CFD)
数値流体力学(CFD : Computational Fluid Dynamics)とは流体に関する方程式をコンピュータで計算する事により数値的に流れを求める手法の事である。CFDでは流体の方程式をコンピュータで計算する為、空間や時間と言った連続的な値を離散化して解を求める。離散化された空間ではその一つ一つの離散点に同じ方程式が適用される。
CFDは主に陰的な解法によって計算される。陰的な解法とは計算する方程式の従属変数が他の方程式によって定義されるような場合に反復計算などを行って解を求める解法である。
GPUとGPGPU
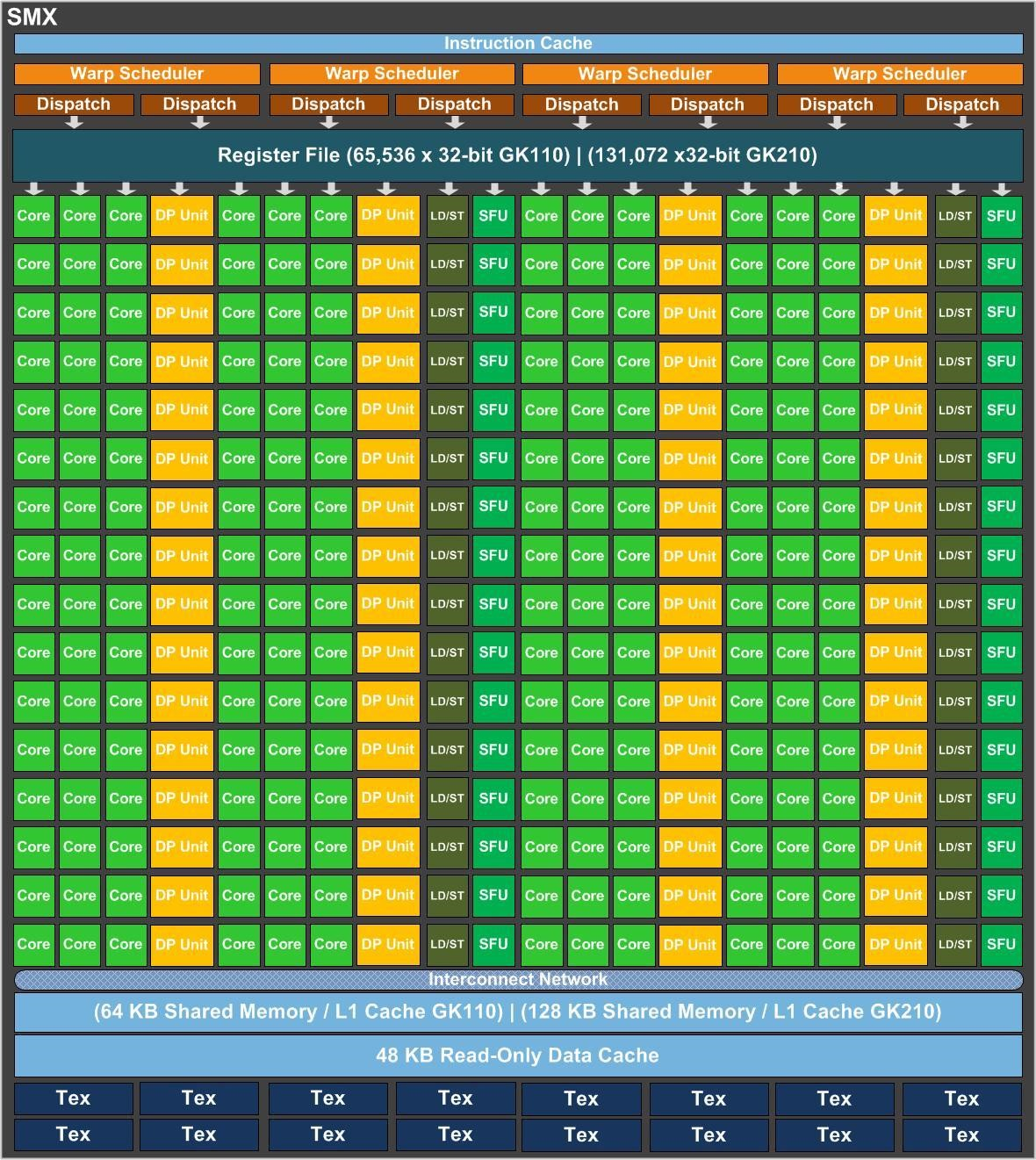
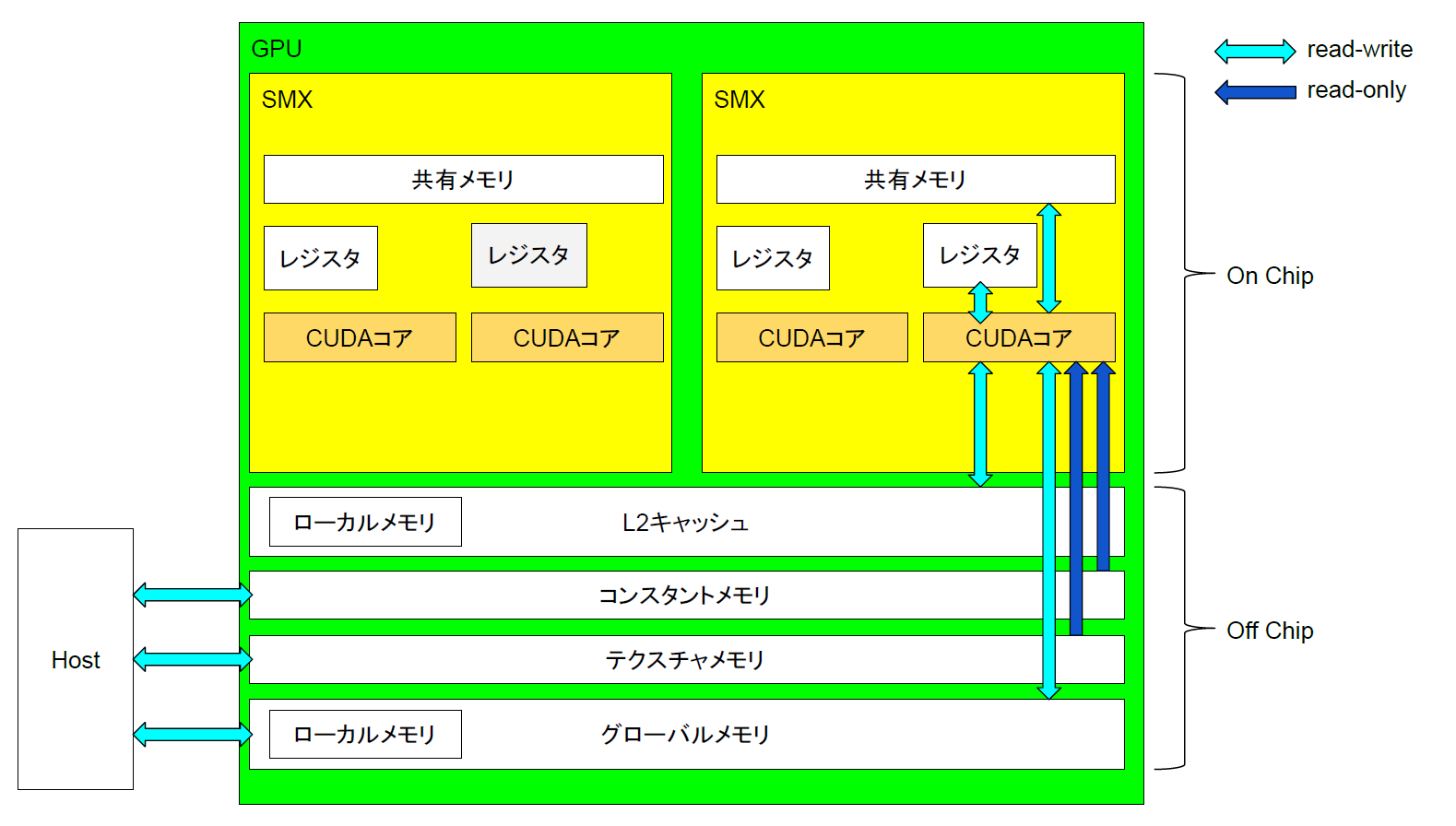
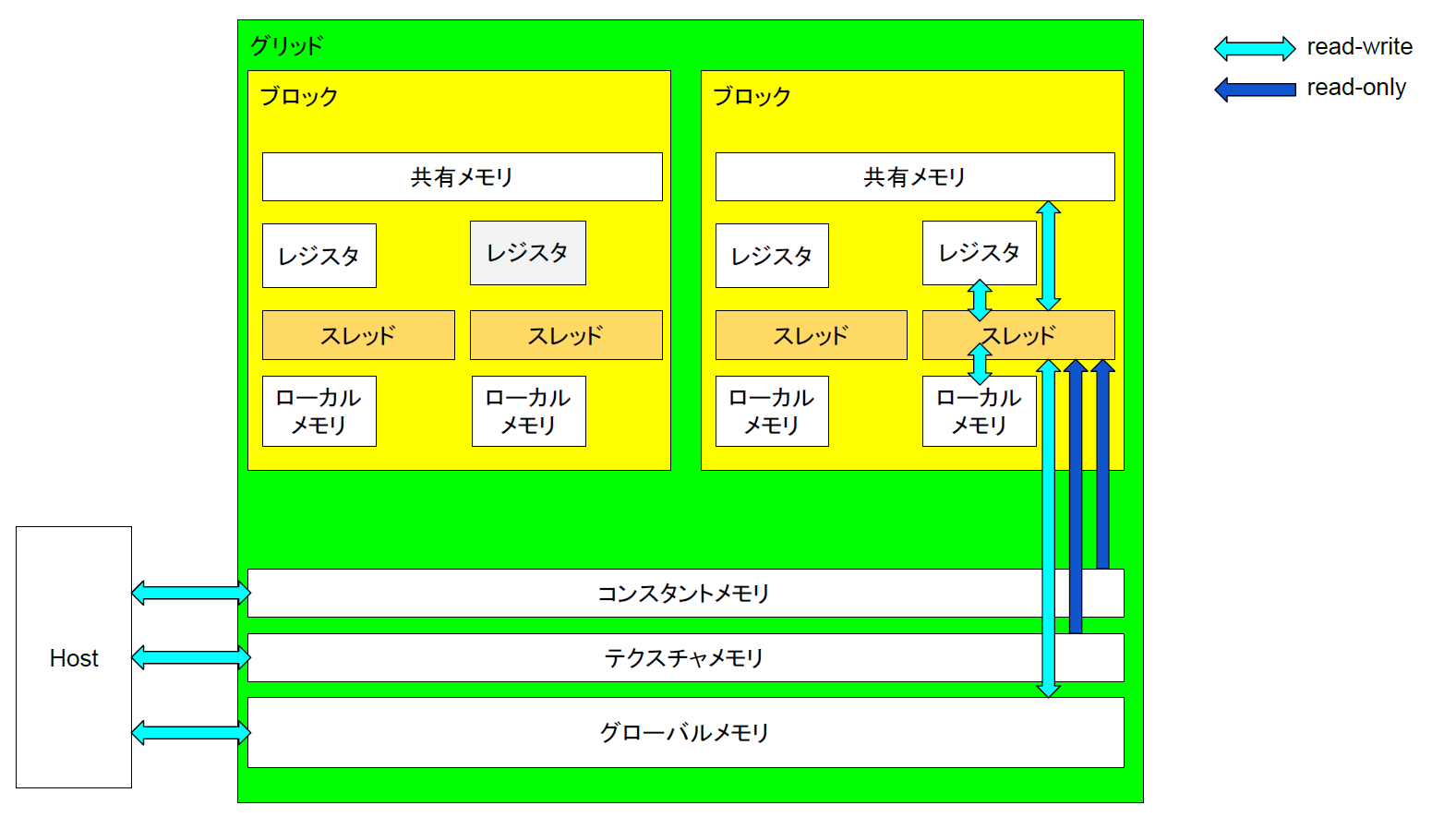
GPUとはGraphics Processing Unitのことであり、コンピュータの画面表示を司る装置である。昔はCPUのアクセスできるメモリの一部を用いて画面のイメージを表示していたが、現在のコンピュータでは図形などの描画用のAPIが用意され、PGUが図形などの表示を担当する。そのため、図形表示などの特定の処理を高速に実行できるように画像処理に最適なハードウェアが構築されている。具体的にはPGUは1つの命令で同時に多数のデータを処理するSIMD(Single Instruction Mdltiple Data)と呼ばれる方法で計算を行う。もともとPGUは2Dの描画機能をCPUから切り離しCPUの負荷を低減させる為の物であったが、次第に3Dグラフィックスの描画高速化としてベクトルや行列の演算を行えるよう拡張されていった。ベクトルや行列等の計算が行えるようになると、その計算能力をグラフィックス目的だけでなく汎用的に使用するニーズが生まれてきた。こうしてGPPGUが生まれた。
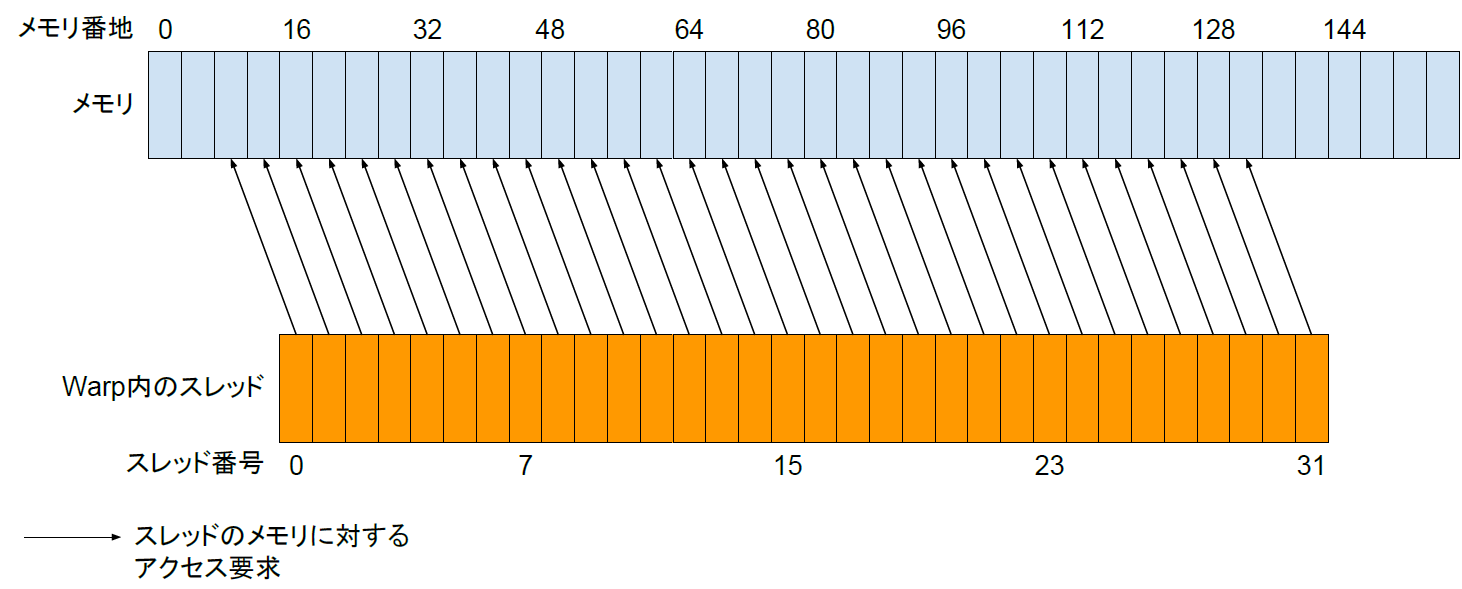
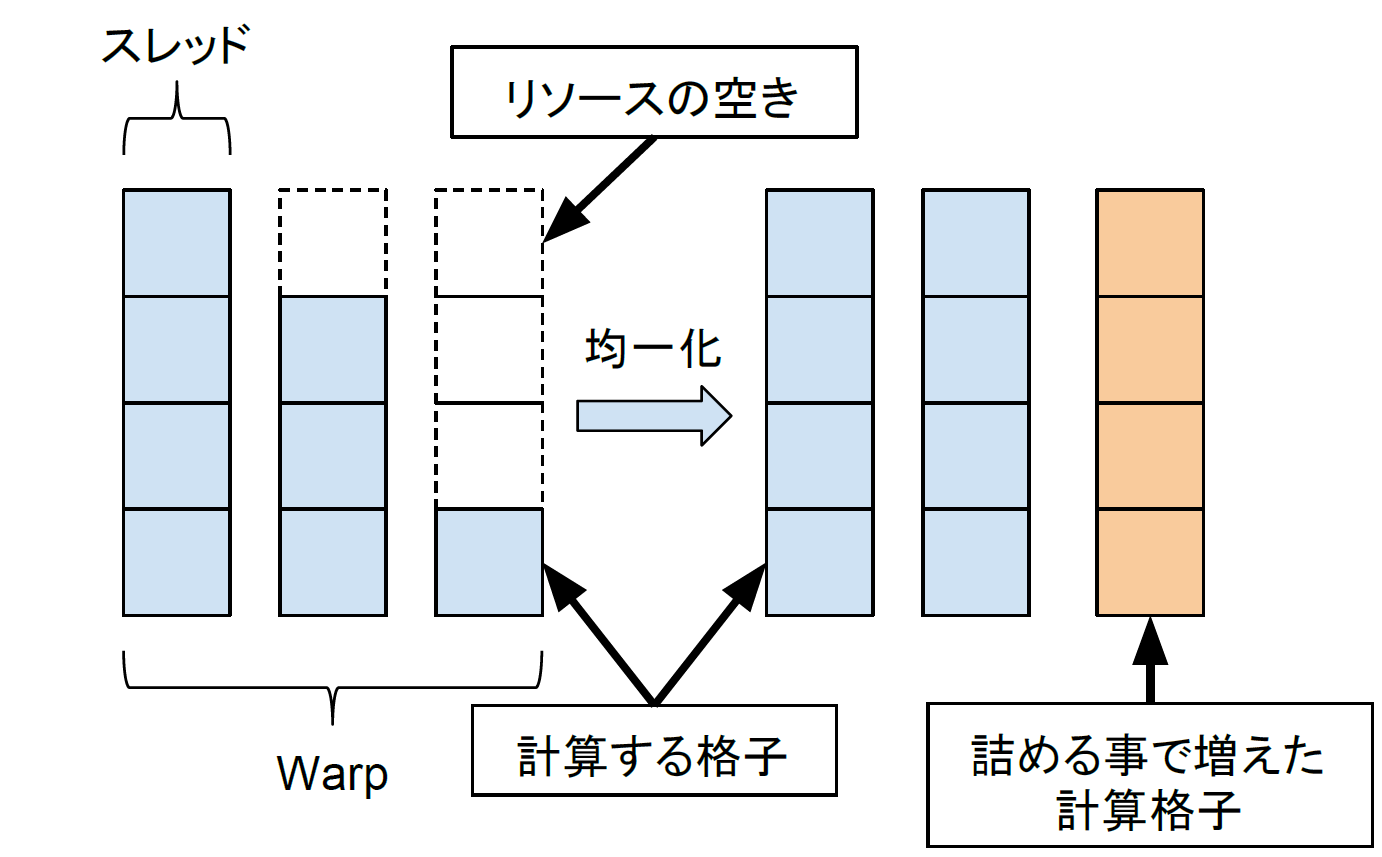
GPGPU(General-Purpose computing on Graphics Processing Units)とは、PGUを汎用計算に応用する技術の事である。PGUの得意とするベクトルの並列処理をあらゆるデータに対し行えるようにする物で、単純な命令を多量のデータに並列に適応させる事で高速化を図る。なお、GPPGUはあらゆる処理を高速化できるわけではない。例えば一般にGPPGUでは条件分岐は計算速度を損なわせる。これはPGUの演算器に条件分岐を最適化する投機実行や分岐予測と言った機能が無い[2]為である。また、PGUはメモリアクセスの際一定量をまとめて読み込む仕組みの為、アクセスするメモリ位置が連続していない場合は何度もメモリ転送が発生し速度が低下する。したがって、特定の目的をGPPGUで高速化できるかどうかは重要な研究課題である。
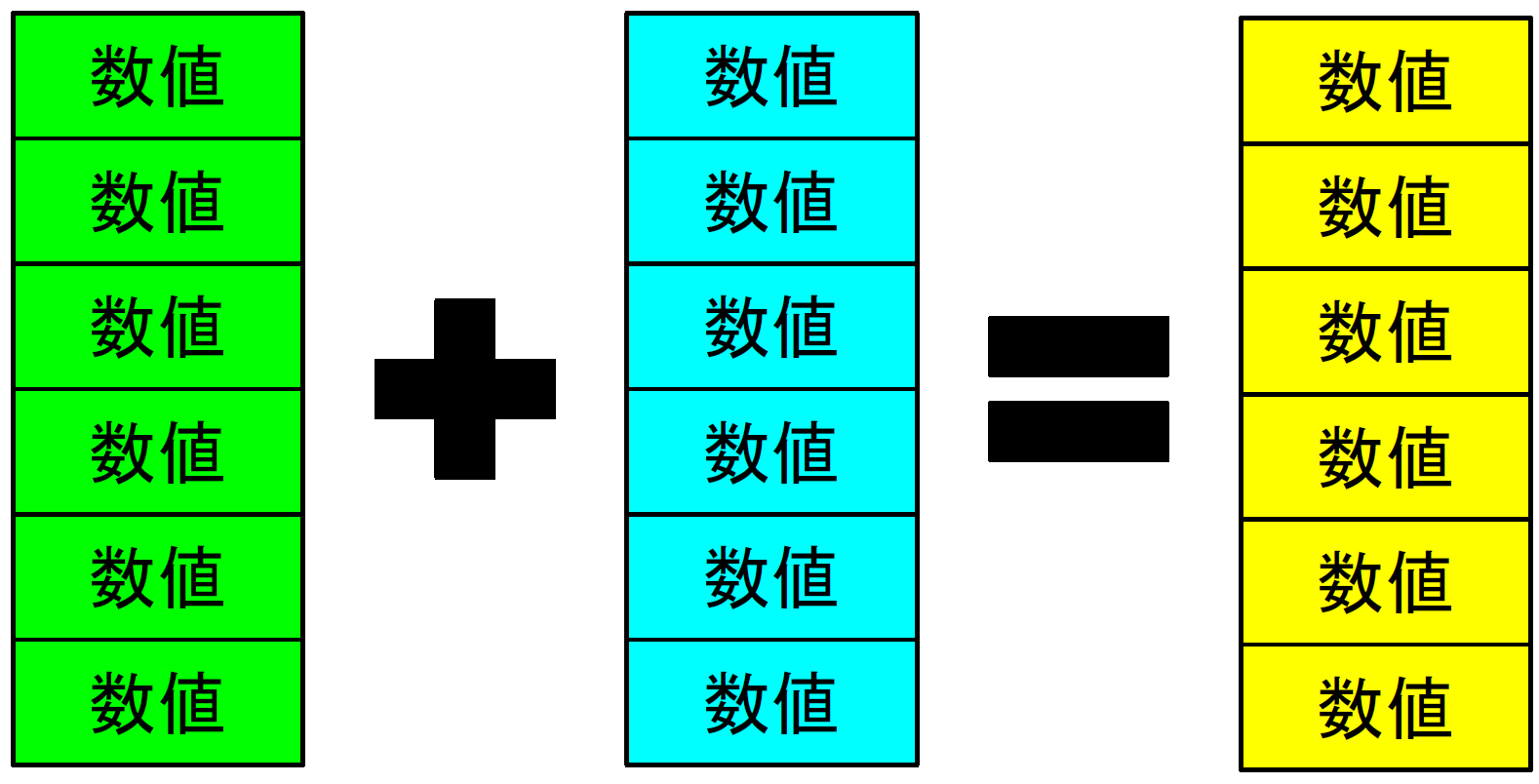
CFDとGPPGU
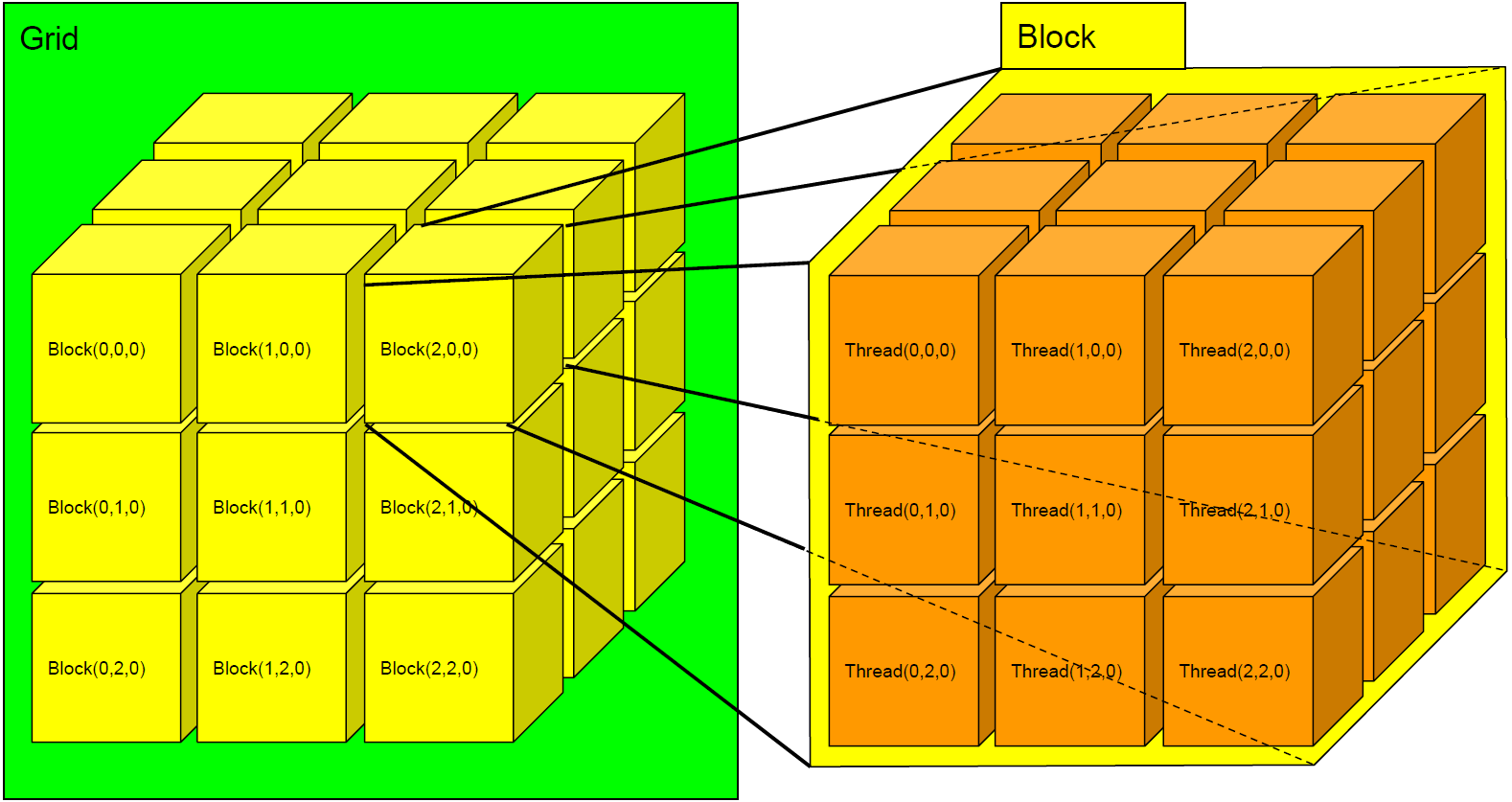
CFDとGPPGUは非常に親和性が高い。これは空間の離散化と言う点にある。CFDでは解析する空間領域を離散化し、各離散点ごとに流体の方程式を計算するが、CPUの場合は2017年現在での並列度は多くて数十なので、個々のコアで全離散点を逐次的に計算するため時間がかかる。一方GPPGUの場合離散点の計算を並列に行うのにSIMD計算が使え、またコア数も数千から数万となるためこの計算時間を大幅に減らすことが出来る。
本研究の概要
本研究では流体の物理シミュレータの高速化手法として、GPPGUを利用した流体シミュレーションプログラムを与えられた格子数やスレッド数などで最適化を施し動的に生成するプログラムを作成した。高速化の手法としてプログラムの動的生成が有用であるか評価する。
2章では本研究で使用したGPPGU環境であるCUDAの基礎的な用語や技術を解説する。
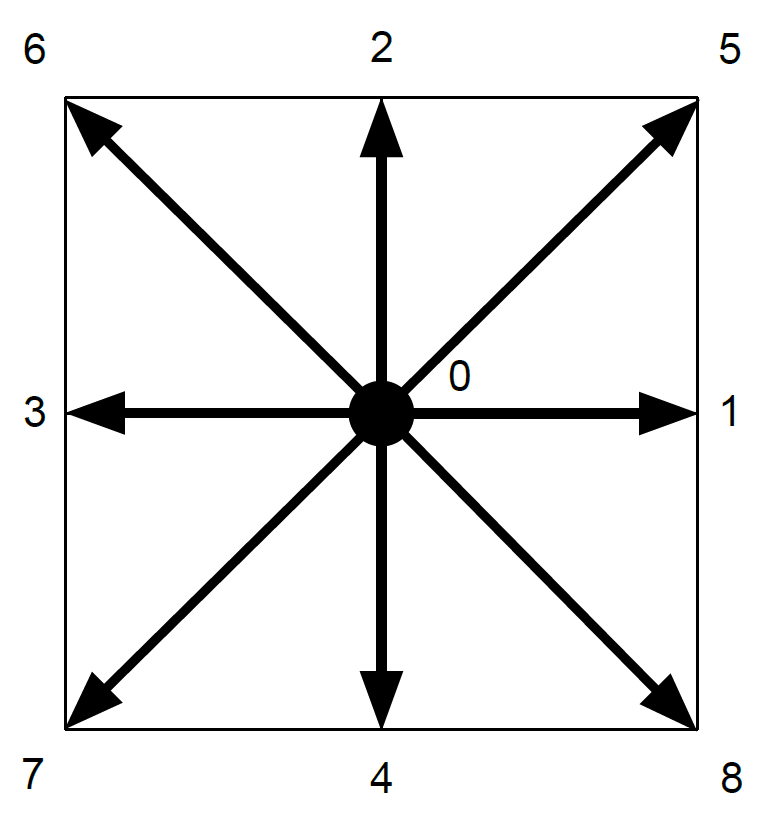
3章では本研究の流体シミュレーション方法として使用した格子ボルツマン法について述べる。
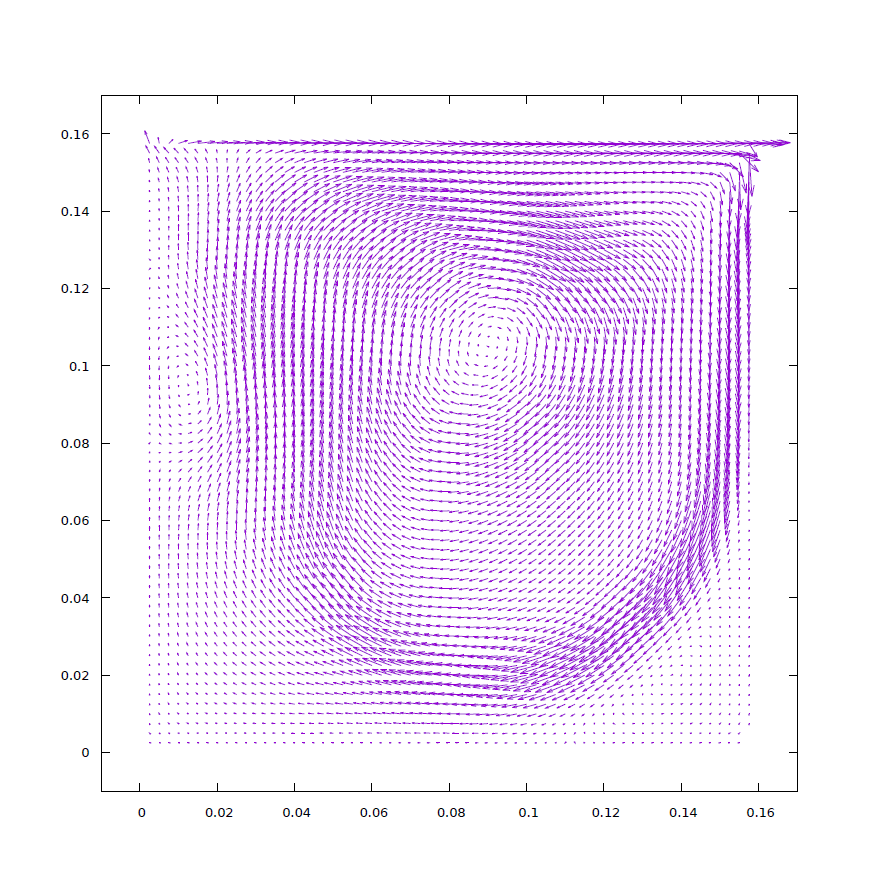
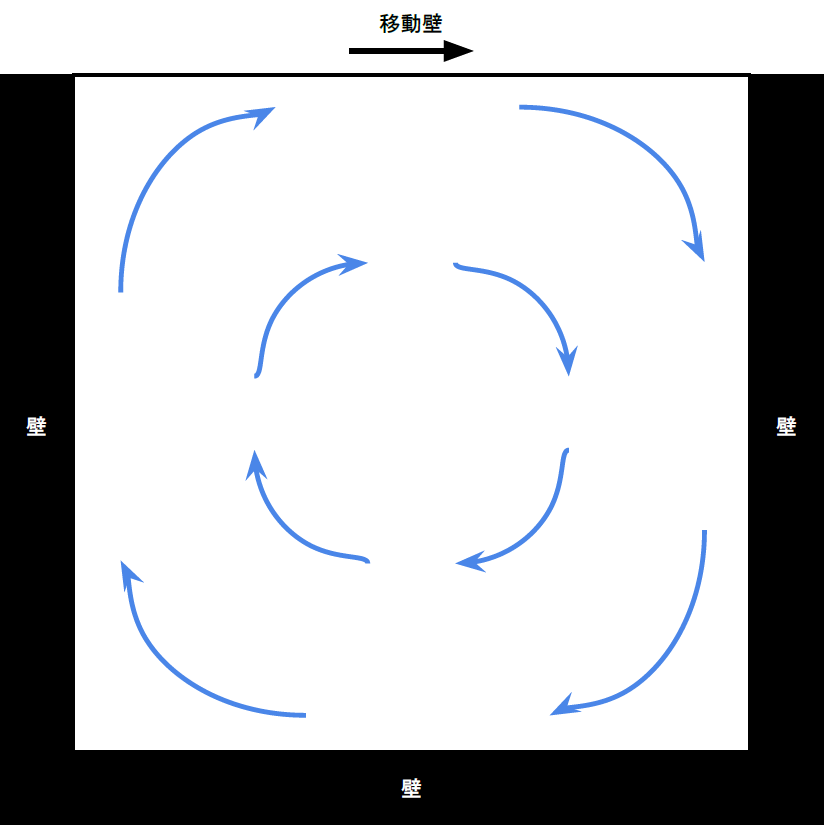
4章では本研究で作成した流体シミュレータのシミュレーション内容について述べる。
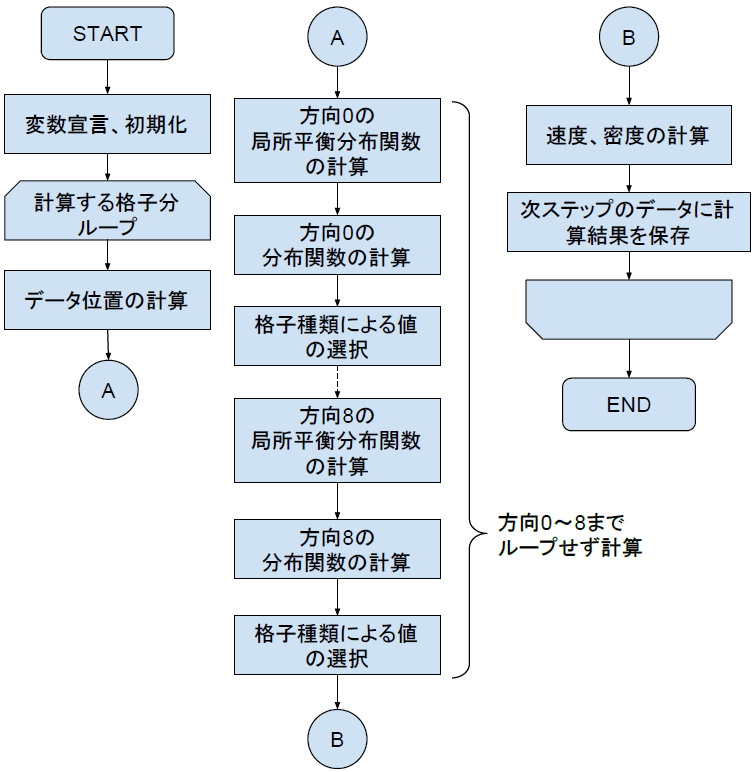
5章では本研究の内容についてCPUコードによるLBMの実装からCUDAでの実装、そして本研究で行った高速化手法の解説する。
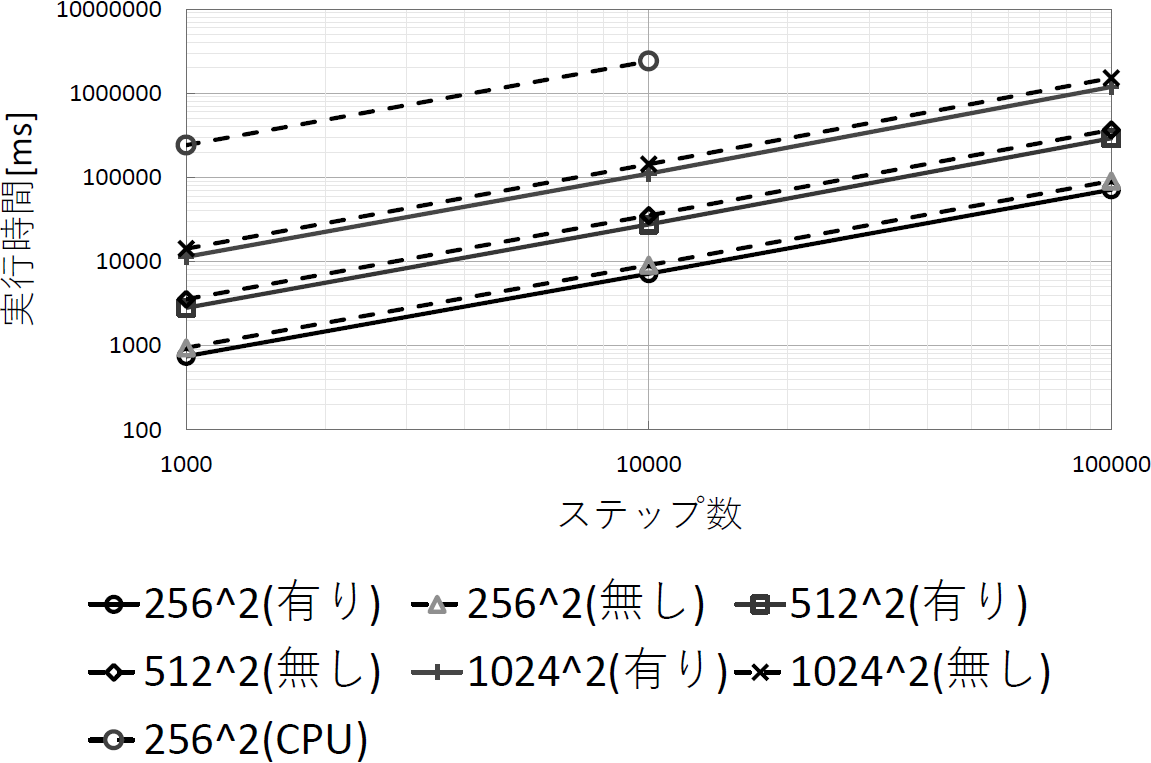
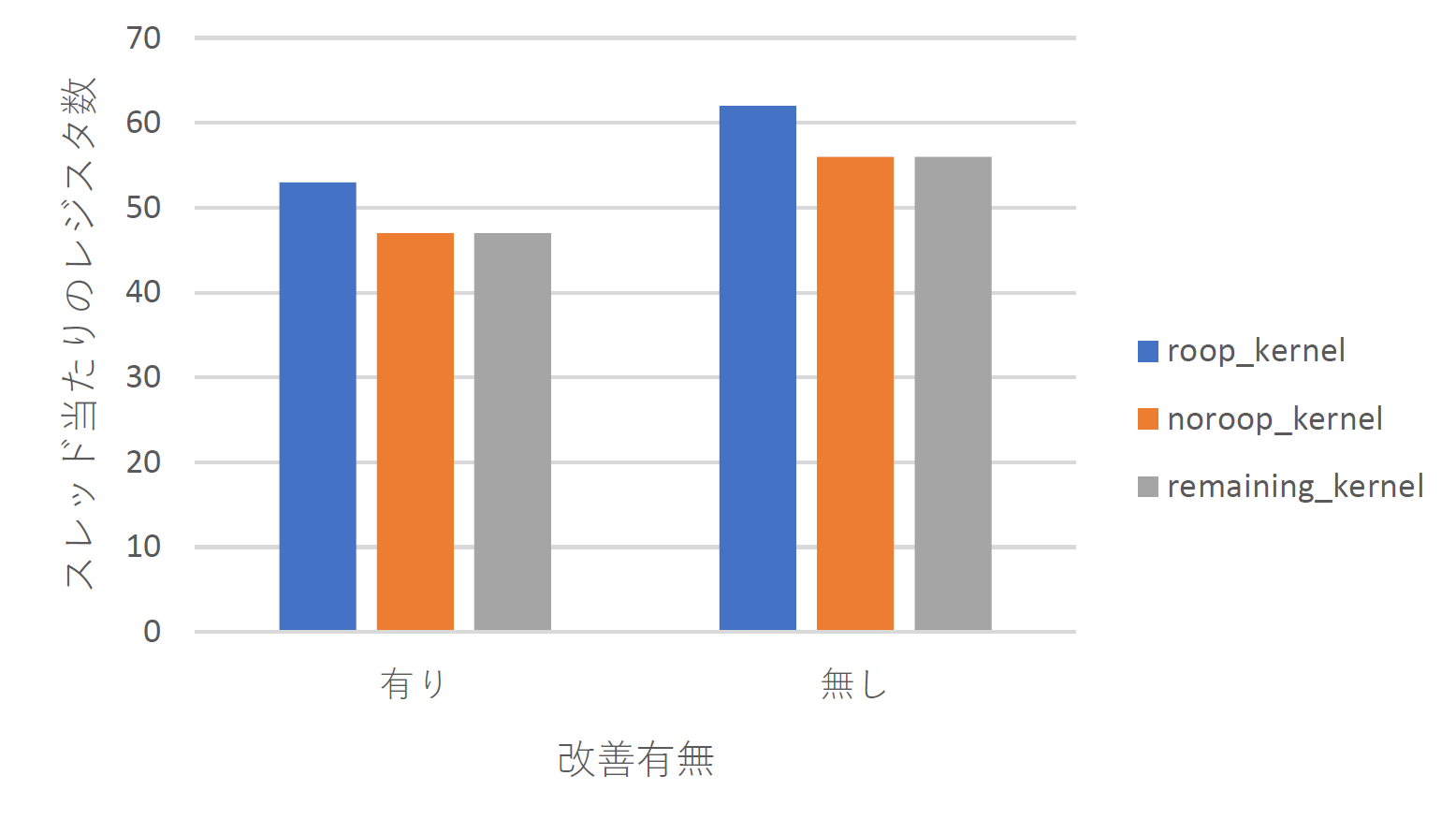
6章では本研究の結果を示し、評価を行う。
7章では本研究のまとめを述べる。
8章では計測値の生データを示し、本研究で作成したプログラムとその説明を書く。