�t�@�C�������ɂ�����z�z�����ɂ���
00kc539 ��݁@���C
�w�������@��{���u������
�͂��߂�
�@�ߔN�AP2P�����ڂ����߂Ă��܂��BP2P�Ƃ́APeer-to-Peer����������ł��BP2P�̓N���C�A���g
���m�̐ڑ������ŁA���݂��̃m�[�h���T�[�o������Ɏ������U�I�ɓ������Ƃɂ���āA
�T�[�r�X����邱�Ƃ��\�ȃR���s���[�^��l�b�g���[�N�̈�̌`�Ԃł��B���̃l�b�g���[
�N����������Z�p�₻�ꂪ�������ꂽ��Ԃ�P2P�ƌĂт܂��B
�]���̃C���^�[�l�b�g���\�����Ă����N���C�A���g�T�[�o�^�l�b�g���[�N�́A�l�b�g���[�N��
�s��������T�[�o�ɒ~�ς���A�T�[�o���m�̑��ݐڑ��ɂ���ăG���h���[�U�ɒ~�ς���A
�T�[�o���m�̑��ݐڑ��ɂ���ăG���h���[�U�ɏ�s���n��V�X�e���ł��B
P2P�Ƃ́A�W���Ǘ����s���R���s���[�^�ł���T�[�o�𗘗p�����A�e�l�b�g���[�N�[��������
�Ȃ����āA���������L����l�b�g���[�N�E�V�X�e�����w���܂��BP2P�l�b�g���[�N�E�V�X�e����
�́A���ׂẴR���s���[�^�����݂��Γ��ɏ����v������T�[�o�ł�����A������v������
�N���C�A���g�ł����邽�߁A�T�[�o���g�iServant=Server+Client�j�ƌĂт܂��B�]���A
P2P�l�b�g���[�N�E�V�X�e���́A���K�͂�LAN�iLocal Area Network�j�̒��ŃR���s���[�^���m��
���ڐڑ����邱�Ƃɗ��p����Ă��܂����B����������Peer-to-Peer�l�b�g���[�N�E�V�X�e���́A
LAN�̒��Ɍ��炸�A�C���^�[�l�b�g����ăO���[�o���ɑ��݂���R���s���[�^���m�ڌ��т�
���܂��B���݂�P2P�l�b�g���[�N�́A�e�m�[�h���A�v���P�[�V�������x���ő��݂ɐڑ����s����
�`������܂��B����̓I�[�o�[���C�l�b�g���[�N�Ƃ��Ă�ATCP/IP�w�̏�A�v���P�[�V����
�w��Ɍ`�������_���l�b�g���[�N�ł��B������P2P�l�b�g���[�N��ɃT�[�o�����݂��Ȃ����Ƃ�
�Ȃ�̂ŁA�P���Q�_���Ȃ��ό̏ᐫ�ɗD��Ă���A�Ǘ��R�X�g��������Ȃ��Ƃ����������������܂��B���̈���ŃT�[�o��N���C�A���g�Ƃ������m�Ȗ������S���Ȃ��̂ŁA���ׂẴR���s���[�^���ǂ���̖��������˂܂��B���̂��߁A�T�[�o�Ƃ��ē����邾���̐��\���v������܂��B�������������N�̃p�\�R���̍����\���ƒቿ�i��������ɉ����邱�Ƃ�e�Ղɂ��܂����B�܂��AADSL�Ȃǂ̍�������Ə펞�ڑ��̕��y��P2P�̕��y���㉟�����邩�����ƂȂ�܂����BP2P�̃V�X�e������������L���Ȃ��̂Ƃ��āANapster[1]��Gnutella[2]�Ȃǂ��������܂��BP2P�̃V�X�e���́A�T�[�r�X�ɎQ������[���̓s�A�ƌĂ�A�W�܂��Ăł����_���l�b�g���[�N�ɂ����āA�s�A��ŃT�[�r�X�v���������ƁA�s�A�̓T�[�r�X��ł���ʂ̃s�A��T���o���A���̃s�A����T�[�r�X���܂��B�܂��A���g�̒ł���T�[�r�X�����J���邱�ƂŁA���̃T�[�r�X��~����ʂ̃s�A�ɒ��邱�Ƃ��ł��܂��B�������A���鑤�̃��[�U�ɑ��ėv�����鑤�̃��[�U�̕��������ꍇ�A�S���ɒ���ɂ́A�����̎��Ԃ�v���܂��B������A��ʂ�P2P�T�[�r�X�͎��s����A�v���P�[�V�����\�t�g�E�F�A��œ��삷�邽�߁A���[�U�ɂ�闣�E�����R�ɍs���܂��B���̂��߃T�[�r�X�̒�҂��Ă������[�U���A�����̔Ԃ�����Ă���O�ɒ������E���Ă��܂����ƂŁA�T�[�r�X���邱�Ƃ��o���Ȃ����Ƃ�����܂��B���̎��́A�T�[�r�X����Ă��炦��ʂ̃s�A��T���o�����Ԃ̈�Ԍ��ɕ��Ԃ��ƂɂȂ�܂��B�܂��A�ґ��������ɕ����ɒ���ƁA���x�́A���Ă���l���őш���邱�ƂɂȂ�̂ŁA���M���x���x���Ȃ�A���ʁA��l������̃T�[�r�X����������Ԃ��x���Ȃ�܂��B����́A�T�[�r�X�̗e�ʂ�������Α����قǁA���̌��ۂ͋N����܂��B�����Ŗ{�����ł́A�T�[�r�X�܂ł̒x���������Ȃ�̂ŁA�T�[�r�X��m�������Ⴍ�Ȃ�܂��B����͒��ɑ����̃��[�U�[���W�߂邱�Ƃɂ��N����҂����Ԃ����炷���Ƃɂ��A�������鎖���ł���ƍl���܂����B
�P.�w�i�y�ъ֘A����
�@P2P�̎������@�ɂ́A�s�A�̌������ɂ��傫���킯��2����܂��B
2.1�@�s���A�^P2P
�@��́A�u�s���A�^P2P�v�ƌĂ����̂ł��B�����ɂ����邷�ׂĂ̒ʐM���o�P�c�����[���ōs
�����̂ŁAP2P�̊T�O�����̂܂܌`�ɂȂ������̂ł��B�l�b�g���[�N�Ɍq����R���s���[�^�͂���
�Ă��Γ��ŁA���݂̒ʐM�ɉ����ăT�[�o�ƃN���C�A���g�̖����S���܂��B���[�U�̈ӎv
�Ńf�[�^�̂���������̂ŁA������Ǘ�����R���s���[�^�����݂��Ȃ��̂������ł��B����
�̓���Ƃ��ẮA���[�U�̎��z�X�g���X�g����L�ڂ���Ă���s�A�փR���e���c��v�����A
����̃s�A�����̃R���e���c�������Ă���ΐڑ����s���܂��B�����Ă��Ȃ��ꍇ�́A
����s�A�������̃z�b�g���X�g���Q�Ƃ��āA�L�ڂ���Ă���s�A�֗v���������A�R���e���c��
����ŏ��̗v�����������s�A�֏��݂𑗐M���܂��B����Ɋ�Â��ėv�����̃s�A�ƃR���e���c
�����s�A�Ƃ̊ԂŁA�ڑ����s���܂��BGnutella[2]��Winny[3]�����̕����ɂȂ�܂��B
2.1.1�@Gnutella
�@Gnutella[2]��Justin Frankel��Tom Pepper�ɂ���ĊJ�����ꂽ�t�@�C�����L�A�v���P�[�V������
���B�����ɂ���ăt�@�C�������������ꍇ�ɂ́A�����҂ƃt�@�C���̕ێ��҂����ڐڑ���
HTTP[4]�ɂ���ē]������܂��BGnutella�̓T�[�o��u���Ȃ��s���A�^P2P�V�X�e���ł��B
�T�[�o���������߃��[�U���m���ڑ����邱�ƂŁAGnutellaNet�Ƃ������z�I�ȃl�b�g���[�N��
�`�����܂��B���̃l�b�g���[�N���Ńt�@�C�����L����܂��BGnutella�ł̌����͌��
�Љ��Napster�̃T�[�o�ɑ���������̂��Ȃ��A���z�I�ȃl�b�g���[�N�ł���GnutellaNet��
�����v���������܂��BGnutellaNet�ɐڑ����ꂽ�T�[�o���g�Q�Ɍ����v�����s�����ƂŖړI��
�t�@�C�������������܂��BGnutellaNet�ɐڑ����邽�߂ɎQ�����Ă��郆�[�U�̒[��
�m�T�[�o���g�n�Ɛڑ����܂������[�U�̕p�ɂȗ��E�����邽��Gnutella�ł́A�f�t�H���g��
���4��̃T�[�o���g�Ƃ̐ڑ���z�肵�Ă��܂��B�����ɂ�����Gnutella�̓t�H���[�h�@�\��
���ڂ��Ă���̂ŁA���T�[�o���g���v�����錟���˗���ڑ����Ă���4��̃T�[�o���g�Ɉ˗�����
���ƂŁA���̃T�[�o���g�͎����̃C���f�b�N�X���������܂��B�����ɁA�������ڑ����Ă��鎟��
4��̃T�[�o���g�ɂ��ꂼ��̌����˗����t�H���[�h���܂��B�e�T�[�o���g�����̃t�H���[�h��
�s�����ƂŁAGnutella�́A���ڐڑ����Ă���T�[�o���g�����łȂ��A���̐�ɂ��鑽����
�T�[�o���g�ɂ����������˗��������邱�Ƃ��ł��܂��B�������ʂɂ���ĖړI�̃t�@�C����
����
�T�[�o���g�Ƀ_�E�����[�h�v�����s���܂��B���̂Ƃ����T�[�o�̓_�E�����[�h�������t�@�C����
�����Ă���T�[�o���g�����ł��Ă���̂ŁA�t�@�C�������T�[�o���g�ɑ��Ē��ڐڑ�����
�t�@�C�����_�E�����[�h���܂��B
2.1.2�@Winny
�@Winny[3]�͒��p�]���ƃL���b�V���ɂ����J�҂�擾�҂̑o���������̂܂܃t�@�C���̔z�z��
�s
�����Ƃ��ł���t�@�C���̋��L�A�v���P�[�V�����ł��B�t�@�C���̕ێ��҂��I�[�o���C�l�b�g
���[�N��̋ߗׂ̃m�[�h�ɕێ������L�����܂��B�ێ�����������m�[�h�͂��ꂼ��
�����̏��������ɓK�����邩�ׁA�K��������̃t�@�C�����擾���܂��B�ێ�����
�e�m�[�h���]������ۂɕێ���IP�A�h���X������������̂ŁA�t�@�C���ێ��҂̓�������
����܂��B�]���̍ۂ́A�����������s�����m�[�h���t�ɂ��ǂ�ێ��҂Ɛڑ����܂��B
Winny�ł́A�ш敝�ƗD��x�̓�̃p�����[�^���瓮�I�ɍ\������܂��B�����ȉ��������
�m�[�h����葽���̕ێ����⌟���v���������ł���悤�ɑш敝�ɂ���ĊK�i�I�ɂԂ炳����
�悤�Ƀm�[�h�Ԃ̃����N��܂��B����Ɏ����X���̃t�@�C����
���m�[�h���I�[�o���C�l�b�g���[�N��ŋ߂��ɔz�u���邽�ߔC�ӂɎw�肵���N���X�^��
�L�[���[�h�������N�ڑ����Ɍ������A���̗ގ��x���m�[�h�̗D��x�Ƃ��܂��B����ɂ���
�m�[�h����t�@�C���]�������������ꍇ�ɗD��x�������܂��B���߂�ꂽ�ڑ���������z���Đڑ����ꂽ�ꍇ�ɂ́A�D��x�̒Ⴂ�m�[�h���珇�Ƀ����N��ؒf���܂��B�ʐM�҂��璆�p�҂Ɏ���o�H��ɋ����ш敝��x���̑傫�����������ƒ��ړ]������ꍇ�ɔ�ׂċɂ߂ăp�t�H�[�}���X�������܂��B
2.2�@�n�C�u���b�g�^P2P
�@������́A�u�n�C�u���b�g�^P2P�v�ƌĂ����̂ł��B���S��P2P�ƁA
�N���C�A���g��T�[�o�[�^�̒��Ԃɂ�������̂ł��B�T�[�o�[��R���s���[�^��p����̂ŁA
�N���C�A���g��T�[�o�[�^�ƈႢ���Ȃ��悤�Ɏv���܂��B�n�C�u���b�g�^P2P��
�T�[�o�[��R���s���[�^�̓��[�U�̃R���s���[�^�ւ̉ߓx�Ȋ��͂��܂���B
�T�[�o�|��R���s���[�^�̓s�A�̂��R���e���c�Ə��݂��Ǘ����A���[�U����̖₢���킹��
�����邾���ł��B���ۂ̂����́A�T�[�o�[������ɁA���[�U�̃s�A���m�ōs���܂��B
���ۂ̓���Ƃ��ẮA���[�U�́A�v������R���e���c�̏��݂��T�[�o�[��R���s���[�^��
�₢���킹�܂��B�T�[�o�|��R���s���[�^�͈ꌳ�I�ɕێ����Ă�����v�����ꂽ���̂�
�����R���e���c�����s�A�̏��݂�v�����̃s�A�ɕԂ��܂��B���̌������ʂ����ƂɁA
�v�����̃s�A�ƃR���e���c�����s�A�Ƃ̊ԂŁA�ڑ����s���܂�Napster[1]��WinMX[5]���A
���̕����ɂȂ�܂��B�l�b�g���[�N�̈ꕔ���T�[�o�[��R���s���[�^���Ǘ�����̂ŁA
�ʐM���~���ɍs���₷���Ƃ��������������܂��B�������A���̔��ʁA
�T�[�o��N���C�A���g�V�X�e���Ɠ����悤�ɁA�������������Ȃ�ƃT�[�o�̕��ׂ��܂��܂��B
�����āA�T�[�o�[�̎��̂����ڃl�b�g���[�N�̒�~�Ɍ��т��Ă��܂��܂��B
2.2.1�@Napster
�@Napster[1]�́A���̋��L�\�t�g�ł��B���[�U�[�͕K���ǂ����̃T�[�o�ɐڑ���������t�@�C���̂����͂��̃T�[�o���o�R���܂��BNapster��MP3��p�̃t�@�C�����L�V�X�e���ł��BNapster�́A�����ɃT�[�o������Hybird�^Peer-to-Peer�V�X�e���ł��B�T�[�o�̓��[�U�̃A�J�E���g���ƃ��[�U�����L���Ă���mp3�t�@�C���̃C���f�b�N�X����ێ����Ă��邾���ŁA���ۂ�mp3�t�@�C���͊e�T�[�o���g�ɂ���܂��BNapster�́ANapster.com�̃h���C���Ƀ��O�C�����ׂ��T�[�o�����蓖�Ă郊�_�C���N�g�T�[�o�ƁA���ۂɃ��O�C�����Č����������s�����O�C���T�[�o������܂��B���_�C���N�g�T�[�o�́A�T�[�o�ɕ��ו��U�Ɗg�����̔z�����邽�߂ɐݒu���ꂽ�T�[�o�ŁA���[�h�o�����V���O�̖�ڂ�S���Ă��܂��B���[�U�́A���_�C���N�g�T�[�o�̐U�蕪����ɐV���ȃ��O�C���T�[�o��lj�����ݒ肾���ł��ނ��߁A�T�[�o�̑��݂��ȒP�ɍs���܂��B���O�C���T�[�o�́A���[�U�̃A�J�E���g���ɂ��������ă��O�C���������s���A��[�ꃓ�g���瑗���ꂭ�������ɋ��L���Ă���mp3�t�@�C���̃C���f�b�N�X���쐬���܂��B�T�[�o���g����̌����v���ɑ��ẮA�C���f�b�N�X�����������Č��ʂ�Ԃ��܂��B�܂��A�_�E�����[�h�̏����𒇉����A�܂��A�`���b�g�T�[�o�̖�ڂ��ɂȂ��Ă��܂��B
2.2.2�@WinMx
�@WinMX[5]�̓��[�U�[�ƃ��[�U�[���q�����߂ɁA�T�[�o����鋤�L�V�X�e���ł��B�@�\�I�Ȗ����������ꍇ�A�ق�Gnutella�Ɠ���̋@�\��L���Ă��܂��BGnutella�Ƃ̍ő�̈Ⴂ�͓��{��t�@�C���̌����@�\�̔\�͂ɐs���܂��BGnutella�ł��A���{��t�@�C���̗��p�͉\�ł������A2�o�C�g�������A���t�@�x�b�g2�����ƌ��m���Ă���炵���A������v���Ă��郂�m�����ׂă��X�g�A�b�v����Ƃ�����������A���{��Ō������������ꍇ�A�W�̂Ȃ��p��t�@�C����������ꍇ�����������܂����BWinMX�͌��XNapster�̃N���[���\�t�g�Ƃ��ĊJ������܂����BNapster�Ƃ̈Ⴂ��WinMX�ł́A�T�[�o�@�\�����[�U�[�ɔC����Ă���_�ł��BNapster�͂��ׂẴ��[�U�[���ݒu����Ă���T�[�o�ɐڑ����邪�AWinMX�ł͂������̏����������Ă��郆�[�U�[�͎����I�ɃT�[�o�ɂȂ�܂��B���̃T�[�o�̂��Ƃ���{�ł͐e�T�[�o�ƌĂ�Ă��܂��B��ʂ̃��[�U�[�͎q�ƌĂ�A�q�͐e�T�[�o�ɐڑ����A�e�T�[�o�͑�{�̃T�[�o�ɐڑ����܂��B��{�̃T�[�o��WPNP�ƌĂ�܂��BWinMX�s�A�l�b�g���[�L���O�v���g�R���̗��ŁAWinMX�p�̃T�[�o�̖��̂Ƃ��Ďg���܂��B�q�͎����̋��L���Ă���t�@�C�����X�g�⌟���̗v���Ȃǂ�e�ɑ��M���܂��B�e�͎q����̌����v����WPNP�ɔ��M���A�������瑼�̐e�ɑ����A���̐e�Ɍq�����Ă���q�ɓ͂��܂��BWPNP�͂��Ȃ�̍�Ƃ�e�T�[�o�ɂ܂����邱�Ƃ��ł��A���[���y�����邱�Ƃ��ł��܂��B�������A�e�̉�����x�A�i���ɂ���Đe���_�E�����[�h��A�b�v���[�h���J�n����ƁA����Ɍq�����Ă���q�̌����v�����ʂ�Ȃ��Ȃ邱�Ƃ�����܂��B�܂��A�q�̎��t�@�C���ɑ��錟����ڑ��̗v�����ʂ�ɂ����Ȃ邱�Ƃ�����܂��B�e���܂���ʂ̃��[�U�[�ł��邽�ߕp�ɂɗ��E����B����ɂ��q��ID���ς���Ă��܂��܂��B�ǂ���̕��@�ɂ������Ă��A�������̉��P��Ă���Ă��܂��B�T�[�r�X�̈��肵�����������邽�߂ɁAP2P�̃V�X�e����A��葽���̊�]����R���e���c�̏��݂������邱�ƂŁA���萫���܂��Ƃ����̂���{�I�ȍl�����ł���܂��B�����ŁA��������̓I�Ȍ�������������܂��B
2.2.3�@Amonphic�@Net
�@�����قǁA�q�ׂ��悤��Hybrid P2P�̕����̖��_�̃T�[�r�X�����s�A�̏��݂�
���Ǘ����邽�߂ɒu�����T�[�o�ւ̃A�N�Z�X�W���̉�����Ƃ��āA�K�v�ɉ����ď��݂��Ǘ�����T�[�o�I�ɐ������Ȃ����K�X�Ĕz�u���邱�ƂŁA����ɏW���ƁA�g���t�B�b�N����Ƃ��ɉ������P2P�V�X�e���uAmorphicNet�v[6]����Ă���Ă��܂��B�e�s�A�́A���g��ʉ߂���p�P�b�g���珊�ݏ������o���ăL���b�V�����A������̖₢���킹�ɍ��v������̂�����ΕԐM���邱�ƂŁA�g���t�B�b�N�y���ɂ���^���܂��B�����āA�g���t�B�b�N�����l���z�����m�[�h�́A����̃L���b�V�����e���ʒu���Ƃ��Ď��T�[�o�Ɏ�����i�グ���܂��B�T�[�o�ւ̃A�N�Z�X���������ĕ��ׂ����܂����ꍇ�A���g�𗘗p���Ă���m�[�h�̈�ɃT�[�o�i�グ�v�������āA����̃C���f�b�N�X����n���܂��B�����̃T�[�o�Q�͐e�q�W�ɏ]���ĊK�w���\�����܂��B�A�N�Z�X���������ĕ����̃T�[�o���K�v�Ȃ��Ȃ�����A���m�[�h�Ɋi�������܂��B
2.3�@P2P�ɂ�����l�X�ȋZ�p
�@�ʒu���Ǝ��ۂ̒����T�[�r�X�����ĕʂ̃s�A�ɍ쐬����A���v���P�[�V�����ƌĂ����@������܂�[7]�B���v���P�[�V�����Ƃ́A���ꂽ�T�[�r�X�̕����i���v���J�j��ʂ̃s�A�ɔz�u���邱�Ƃł���A���Ƃ��t�@�C���擾�T�[�r�X�ł���Ηv�����ꂽ�t�@�C���̕�������܂��͕����̕ʃs�A�ɃR�s�[���邱�Ƃ�\���܂��B���v���P�[�V�����̎�@�ɂ͊������܂����A�T�[�r�X�s�A����ю�M�s�A�Ԃ̌o�H��ɑ��݂���s�A�ɕ�����z�u����Path Replication���̗p���Ă��܂��B���v���P�[�V�����ɂ��A��̃T�[�r�X�͕����̃s�A�ɂ���Ē\�ł��B���������Ă��̂����ꕔ�̃s�A���_���l�b�g���[�N���痣�E�����ꍇ�ł��T�[�r�X�͕����̃s�A�������ɂ������ĉ����ł��邱�Ƃ���A�T�[�r�X�܂ł̒x���̌y�������҂ł��܂��B����ɁA�����̌��ʓ���ꂽ�����̃s�A����A�ʐM���x�������Ƃ��傫���s�A��I�����邱�Ƃ������\�ł��B���v���P�[�V�����̓s�A��P2P�_���l�b�g���[�N����̗��E�ւ̑ϐ�����A�������Ԃ̒Z�k�Ȃǂ̗��_������܂��B���̃��v���P�[�V�����̔z�u���@�ɒ��ڂ��A�����l�b�g���[�N�̓������l�������z�u��@[8]����Ă���Ă��܂��B���ɁAP2P�_���l�b�g���[�N�����ׂ��@���ipower-law�j[9]�̐����𗘗p���A�s�A�̗��E�Ȃǂɂ��_���l�b�g���[�N�̈��萫�艿�����コ���郌�v���P�[�V�����z�u��@����Ă���Ă��܂��B
�@���ۂ̃T�[�r�X����邤���ŁA�x���͈��萫�̒ቺ���܂˂��������ȗv���̈�ł��B����T�[�r�X�����s�A�����Ȃ��ꍇ�A�T�[�r�X����]����s�A��������Α����قǒx���͑傫���Ȃ�Ǝv���܂��B�Ȃɂ��AP2P�̐�����A�T�[�r�X��m�����������邱�ƂɂȂ�B�����ŁA�ł��邾���A�����̃s�A�ɓ����ɔz�M���邱�Ƃ��A�x����h�����ƂɌq����܂��B
����Ȃǂ̃R���e���c�z�M�̕���ɂ������āA���M�������グ�A���M���x�����コ������@�Ƃ��āA�I�[�o���C�l�b�g���[�N��p���āA�[���}���`�L���X�g����������P2P�X�g���[�~���O�z�M�V�X�e��������܂��B�����̓X�g���[�~���O����M���Ă���m�[�h������ɕʂ̎�M�m�[�h�ɒ��p���M���s�����Ƃœ��I�ɔz�M�c��-���`�����A�z�M��̑ш���������邱�ƂȂ���ʂ̃m�[�h�ɓ���̃X�g���[�~���O��z�M�ł��܂��B����Peer-to-Peer�X�g���[�~���O�ɂ́A�I�[�o���C�l�b�g���[�N�ւ̎Q���m�[�h�̈ꗗ��ێ����钇��T�[�o�𗘗p������̂ƁA����T�[�o�Ȃ��ŁA�z�M�c���[���\�z������̂ɕ������܂��B�O�҂Ɋ܂܂����̂Ƃ��ăV�F�A�L���X�g[10]�A��҂Ɋ܂܂����̂Ƃ���PeerCast[11]������܂��B
�@1�Α��A���Α��^�ʐM�`�Ԃ���������w�Ƃ��āA�l�b�g���[�N�w�m���[�^�n�ƃA�v���P�[�V�����w�m�z�X�g�n�̓������܂��B��҂�ALM[12](Application-Layer Multicast)�ƌĂт܂��BALM�́A�z�X�g�������\���v�f�Ƃ���I�[�o���C�l�b�g���[�N�̏�Ƀ}���`�L���X�g�c���[���`�����A���̃c���[�ɔ����ăz�X�g�Ԃ��o�P�c�����[���Ƀf�[�^���]�������B����́AIP�}���`�L���X�g�C���t����K�v�Ƃ��Ȃ����n�_�X�g���[���z�M�Z�p�ŁA����̃f�[�^���ɕ����̃z�X�g�ɔz�M���邱�Ƃ��ł��܂��B
�R�@Gnutella�̏ڍ�
�@���݂�Gnutella�̃t�@�C���l���̗���́A�����v���ɉ������z�X�g�ɐڑ��v���������A���̌��ʑ��肪�ڑ����\�ł���t�@�C���̃_�E�����[�h���J�n����܂��B���̏͂ł͎����̃��f���Ƃ����AGnutella�̎d�l�ɂ��ďq�ׂ܂��B
3.1�@.Gnutella�̓���T�v
�@Guntella�́A��{�I��Pure�^Peer-to-Peer�ł��BGnutella�́AServer��u���܂���BServer���Ȃ����߁A�T�[�o���g���m���ڑ����鎖��GnutellaNet�Ƃ������z�I�ȃl�b�g���[�N���`�����A�l�b�g���[�N���Ńt�@�C�����L����܂��B
GnutellaNet �ɐڑ����邽�߂ɂ́A�ŏ��ɐڑ�����T�[�o���g�̃A�h���X��m��K�v������܂��B���̃A�h���X�́AGnutellaNet�̃A�h���X�Ƃ��ăC���^�[�l�b�g��Ō��J����Ă��܂��B���̃A�h���X���e�L�X�g�`����Gnutella.net�t�@�C���ɋL�q���邱�ƂŁAGnutellaNet�ڑ����邱�Ƃ��ł��܂��BGnutellaNet�̃A�h���X�ɂ���T�[�o���g�͂����ғ����Ă���ۏ��Ȃ����߁A������GnutellaNet�A�h���X�ɑ��Đڑ������݁A�������������T�[�o���g��GnutellaNet�̓�����Ƃ��ĉ��z�l�b�g���[�N�ɐڑ����܂��B���̂���GnutellaNet�ւ̐ڑ����ɁA�������̃g���C��A���h��G���[���������邽�߁A�l�b�g���[�N�ɎQ�����邽�߂ɂ͂�����x�̎��Ԃ�������܂��B���T�[�o���g�ɑ��Ă��ق��̃T�[�o���g����̐ڑ��v��������̂ł���ɉ������邱�ƂŎ�����ʂ���GnutellaNet�ڑ�����T�[�o���g������܂��BGnutellaNet�ւ̓�����Ƃ��ė��p���Ă����T�[�o���g���l�b�g���[�N���痣�E���邱�Ƃ�����܂��B���̎��͕ʂ̉ғ����Ă���T�[�o���g��T���Đڑ�����K�v������܂��B���̂��߉ϓI�ȃl�b�g���[�N�ł���GnutellaNet�ڑ����邽�߂ɁA�����̃T�[�o���g�Ɛڑ����ێ����Ă����܂��BGnutella�͏��4��̃T�[�o���g�Ɛڑ���z�肵�Ă��܂��B�܂��A�]�����x�̒ᑬ�ȃT�[�o���g�͂��GnutellaNet�̖��[�֍~�i����܂��B����͓]�����x�̍����ȃT�[�o���g����葽���̃g���t�B�b�N�����������ق����ǂ�����ł��B
�@Gnutella�ł́A�t�@�C������������ۂɃC���f�b�N�X�����T�[�o�ɑ�������@�\�����T�[�o���g���Ȃ��̂ŁA���z�I�ȃl�b�g���[�N�ł���GnutellaNet�Ɍ����v���������܂��BGnutellaNet�ɐڑ����ꂽ�T�[�o���g�Q�Ɍ����v�����������ƂŃt�@�C���������������܂��BGnutella�ł͊e�T�[�o���g�Ƀt�H���[�h�@�\�𓋍ڂ��Ă��܂��B���T�[�o���g���v�����錟���˗���ڑ����Ă���4��̃T�[�o���g�Ɉ˗����邱�ƂŁA���̃T�[�o���g�͎����̃C���f�b�N�X���������܂��B�����Ɏ������ڑ����Ă��鎟��4��ɃT�[�o���g�ɂ��ꂼ��̌����˗����t�@���[�h���܂��B�e�T�[�o���g�����̃t�H���[�h���s�����ƂŁAGnutella�͒��ڐڑ����Ă���T�[�o���g�����łȂ��A���̐�ɂ���T�[�o���g�Ɍ����˗��������邱�Ƃ��ł��܂��B�����˗��ɂ������Ĉ�v����t�@�C�������T�[�o���g�͌������ʂ�ԐM���܂��B���̂Ƃ������˗����^��Ă��������o�H���ɉ����ĕԐM����܂��B
Gnutella�ł̃t�@�C���̃_�E�����[�h��GnutellaNet��œ]������邱�Ƃ͂���܂���B�t�@�C���͒��ڃ_�E�����[�h����܂��B�����˗��ɂ������ĕԐM����Ă������e�����ƂɃT�[�o���g�͖ړI�̃T�[�o�Ƀ_�E�����[�h�v�����o���܂��B�t�@�C���̃_�E�����[�h�v���g�R����HTTP1.1�ł��B
GnutellaNet�ڑ���t�@�C���̌����A���̕ԐM��Gnutella�Ǝ���Gnutella�v���g�R���ɂ���ĒʐM���s���܂��B
3.2�@Gnutella�̃��b�Z�[�W
�@GnutellaNet�ڑ���t�@�C���̌����A���̕ԐM��Gnutella�Ǝ���Gnutella�v���g�R���ɂ���ĒʐM���s���܂��B�ʐM���b�Z�[�W�̓w�b�_�ƃy�C���[�h�ɂ킯���Ă��܂��B
3.3�@Gnutella�̃v���g�R��
�@�����ł�Gnutella�̃v���g�R�����ɗp���Đ������܂��B
��
�@A:�_�E�����[�h��
�@B:�A�b�v���[�h��
�P�A A��B�̎��t�@�C�����_�E�����[�h���悤�Ƃ��邪B�ɐڑ��ł��Ȃ��ꍇ GnutellaNet��Push�𑗂�܂��BPush�ɂ́AA�̃A
�h���X�A�|�[�g�AB�̃_�E�����[�h�������t�@�C����
�C���f�b�N�X�������Ă���܂��B
�Q�A B���^�ǂ�Push������Ď�����GUID�ƈ�v����AB��A�̃A�h���X�̃|�[�g�ɒ���
�ڑ�����GIV�𑗂�܂��B
�R�A A�̗~�����t�@�C����GIV�̃t�@�C���ƈ�v����A���̐ڑ������̂܂g����
GET���N�G�X�g�𑗂�܂��B��͒ʏ�̃_�E�����[�h�Ɠ����ł��B���ɋ�̓I�ȗ����������܂��B
�P�@�܂������������ď��݂������o���Ƃ���܂ł́A���݂̃V�X�e���Ɠ����ł��B
���Ɋ�]�t�@�C�������T�[�o���g��Query�����QueryHit��Ԃ��܂��B
���̂Ƃ��ɒ��̃T�[�o���g�̓A�b�v���鑤�̃T�[�o���g��IP�A�h���X���L���b�V��
���Ă����܂��B����ɂ��A���̃T�[�o���g�ɑ���Query���ʂ̃T�[�o���g���痈���ꍇ
QueryHit��IP�A�h���X�͌��݃A�b�v�����Ă���T�[�o���g��IP�A�h���X�ŕԂ��܂��B
�_�E�����[�h�v���͌��݃A�b�v�������Ă���T�[�o���g�ɑ��čs���܂��B�����Ƃ��āA
���݃_�E�����[�h�����Ă���t�@�C���ɑ��鑼�̃T�[�o���g����̃_�E�����[�h�v����
���Ă͒��J�n����悤�ɂ��܂��B�܂��A���̎��ɂ��łɑ��̃T�[�o���g�ɑ���
���s���Ă���ꍇ�́A���̃T�[�o���g��IP�A�h���X���̂���Query��Ԃ��Ƃ��܂��B
�Ȃ��AGnutella �̂��킵���v���g�R���̓��e�͕t�^���Q�Ƃ��Ă��������B
4�́@�{����
4.1�@Gnutella�̖��_�Ɩ{�����̖ڕW
�@�����ł́AP2P�ɂ�����A���̓`�B���Ԃɂ��čl���܂��B
�Ⴆ�A1��1�̒ʐM��T�b������t�@�C����1024�l�̃p�|�e�B�ɂ�����
1�l�����������Ă���Ƃ��܂��B����ƒP���ɑS�����]���v�����ɏo�����ꍇ�A
�l�b�g���[�N�������Ɏg�����ƂŁA�S�����t�@�C�����l������̂�1023T�b������܂��B
����A���̏������l���܂��B
1. �]����1�x�ɂ�1�l�ɂ����s��Ȃ�
2. �t�@�C�����l�������l�́A���l�Ƀt�@�C���]�����ł���
3. �]���v���͊����ɃR���g���[������A�]���\�ɂȂ����l�͕K��������͑��̐l�ւ�
�]�����s���܂��B
���̂悤�ȏ����ł́A�ŏ���T�b�Ńt�@�C�������l��2�l�ɂȂ�܂��B
����T�b�ł͂���2�l���ʂ�2�l�ɓ]�����邽�߁A�t�@�C�������l��4�l�ɂȂ�܂��B
�ŏI�I�ɂ�10T�b��1024�l�Ƀt�@�C�����n��܂��B���̏����ł́A���̂悤�Ƀt�@�C���̕��z�҂�
���U�����邱�Ƃ��ł���Βx�������炷���Ƃ��ł��܂��B
�ړI�̃t�@�C�������m�[�h���������Ƃ��Ă��K���A
�����Ƀ_�E�����[�h���J�n�����킯�ł͂���܂���B
����́A�������m�[�h�����̃m�[�h�ɑ��āA
�t�@�C���̒̓r���ł���ꍇ�ł��B���̏ꍇ�A�ő�ڑ����̐����ɂ��A
���̃_�E�����[�h���I���܂Őڑ���f���邱�Ƃ�����܂��B
�����ŁA���̑҂����Ԃ������Ɍ��炷�����l���܂��B
��L�̂悤�ȋɒ[�ȉ���̂��Ƃł͒P���Ȍv�Z�ŁA
��s���n��܂ł̎��Ԃׂ邱�Ƃ��ł��܂������A
������P2P�̃��f���Ƃ͂�������Ă��܂��B
�����ŁA�{�����ł�P2P��P�����������f���ŃV�~�����[�V�������s���A
�ǂ̂悤�ȃp�����[�^��ݒ肷��Ə��`�B�������Ȃ邩�ׂ܂����B
���߂ł̓V�~�����[�V�����ɂ�����A�����ȏ����ɂ��Đ������܂��B
4.2 �V�~�����[�V�����̏���
�t�@�C������������l�b�g���[�N�̍\���́AGnutella�l�b�g���[�N�Ɠ����^�C�v��Peer-to-Peer�^���̗p���܂��B
�l�b�g���[�N�ɎQ������e�m�[�h�͕����̑��̃m�[�h�ƌq�����Ă��܂��B�ŏ��̎��_�ŁA
�t�@�C�������m�[�h�̓l�b�g���[�N��ɂЂƂƂ��܂��B�҂����Ԃ͌������q�b�g���Ă���
�_�E�����[�h���J�n�����܂ł̎��Ԃƌ������q�b�g����܂ł̎��Ԃ̍��v�Ƃ��܂��B�����͖���s���A
�]���v���ɑ���ԓ��̓����_���ɍs���܂��B�Q���m�[�h���A�]�����ԁA�ш�i�����ɑ��邱�Ƃ̂ł���m�[�h���j�A
�����͈͎͂����̎�ނɂ���ĕω������āA�V�~�����[�V�������s���܂��BGnutellaNet�����̂悤�ɗ��z�����Ă܂��B
��S�T�[�o���g�̔\�͓͂�����
��e�ʐM�����N�̓`���ʁA�X���[�v�b�g�͈��œ�����
��t�@�C���̃_�E�����[�h�͌������ʂ��Ԃ��Ă�����0�b�ŊJ�n�����B�����܂łɂ����鎞�Ԃ����Ƃ��܂��B
���̂悤�ȏ����ɂ����āA���̌��������ɂ��]���������r���܂����B
���x�ɑS�̂ɑ��Č������������A0�b�Ō��ʂ��Ԃ��Ă���
��C�ӂ̋����ȓ��ɂ̂����������A0�b�Ō��ʂ��Ԃ��Ă���
�Ȃ���r�̂��߈ȉ��̂悤�ȈقȂ�ɂ��Ă��ꂼ��V�~�����[�V�������s���܂����B
������]�����ƌ����͈͂�ς�����
������]�����ƃm�[�h����ς�����
����_���Ɠ����]������ς�����
4.3 �V�~�����[�V�����v���O�����̊T�v
�@�V�~�����[�V�����v���O������Java2SDK���g���č��܂����B�o�[�W������1.2.2�ł��B
�v���O�����͑傫��������4����\������Ă��܂��Bnewsim�AServantList�AServant�A��
�R�̃N���X�ƃV�~�����[�V�����̏����Ɋւ��ϐ����܂Ƃ߂�Constant����ł��Ă��܂��B
�v���O�����͕t�^�ɓY�t���܂����B
�newsim�N���X
�@���C���N���X�ł��BServantList�̃C���X�^���X�����A�V�~�����[�V�����̏����ɍ��킹��
�m�[�h��������A�m�[�h�Ԃ̒ʐM��1�X�e�b�v���V�~�����[�V�������܂��B
�S�̂ɏ�s���킽�������A���������X�e�b�v�����o�͂��ďI�����܂��B
�ServantList�N���X
ServantList�N���X�ł́A�v�����A�]�����A������3�̃O���[�v����Ȃ�܂��B
Servannt�̃��X�g��ێ����Ǘ����܂��B
Servant�����X�g�ɒlj�����add CarriedNod(),addEmptyNod()���\�b�h�A
�l�b�g���[�N���쐬����makeRandamConnection()���\�b�h
lstep�ʐM���V�~�����[�V��������play()���\�b�h�Ȃǂ�����܂��B
�Servant�N���X
�@�X�̃m�[�h�������܂��B�אڃm�[�h�Ɠ]�����̃m�[�h�̃��X�g��ێ����܂��B
�������X�g�����@lookup()���\�b�h
�@�]��������@ack()���\�b�h
�@lstep�]�����s��deliver()���\�b�h�Ȃǂ�����܂��B
�Constant
�@�V�~�����[�V�����̏�����ς��鎞�ɏ���������ϐ���5����܂��B
�@CarrideNod�F���������Ă��钸�_��
�@EmptyNode�F���������Ă��Ȃ����_��
�@Connections�F�e���_�̗v���ڑ��m�[�h���i���ϐڑ����́~2�j
�@Distance�@�@�F�����̐[��
�@MaxTrans�@�F�����]����
���ɌX�̃T�[�o���g�̓���ɂ��Đ������܂��B
�T�[�o���g�̏�Ԃ̓t�@�C���������Ă����ԂƎ����Ă��Ȃ���Ԃ�2�ł��B
����͗v�����m�[�h�A�]�����m�[�h�A�����m�[�h��3�̓��삪����܂��B
�����y�ѓ]���v���̏�����ServantList�N���X��processRequire�ŏ�������܂��B
������̓���͗v�����m�[�h�̃��X�g�ɑ��Ĉȉ����������܂��B
�Distane�ɂ���Č��߂�ꂽ�͈͂��w�肵�āAlookup()���\�b�h�Ō������X�g�܂��B
��������X�g���烉���_����1�m�[�h��I�т܂��B
����̃m�[�h�ɑ��āAack()���\�b�h�𑗂�܂��B
�����ack()���\�b�h����ꂽ��v�����m�[�h��]�����m�[�h���X�g�ֈڂ��܂��B
�]���y�ъ����̏�����ServantList�N���X��processTransferring�ŏ�������܂��B
������m�[�h���ێ�����Ă��郊�X�g�ɂ���Servant�ɑ���deliver()�𑗂�܂��B
��]�����̃��X�g�ɂ���Servant�ɑ��ē]�����I����Ă����ׁA�I����Ă�����A
�����m�[�h�̃��X�g�Ɉڂ��܂��B
�ȏ���Q������m�[�h�����ׂăt�@�C��������ԂɂȂ�܂�
newsim�N���X�͏������J��Ԃ��܂��B�������I���Ɗ|���������Ԃ�\�����ďI�����܂��B
�S�|�S�@����
�@����1
�@�܂������͈͂�3�ɂ����ꍇ�ƑS�̂Ɍ������|�����ꍇ�ɂ��Ď����������Ȃ��܂����B
����ɂ�茟���͈͂����肷�邱�Ƃ��t�@�C���̔z�z������ǂ����邩�ׂ܂����B
�ݒ�@�Q���m�[�h���T����1500�܂ŕω������܂��B
�@ �����͈�3�ȓ��̒��_���͂R�Ƃ��܂��B
�@ �t�@�C�������m�[�h��1�B
�@�@�@�ڑ����_���@1
�@�@�@�����]�����@1
 �}1�A�S�̌�����3�m�[�h�ȓ��̌����ɂ����錋��
�@
�}1�A�S�̌�����3�m�[�h�ȓ��̌����ɂ����錋��
�@
���ʂɑ傫�ȍ��������邱�Ƃ͂���܂���ł����B���̏����ł͌����͈͂̉e�������A
�Q���m�[�h���̒l���t�@�C���̔z�z�����ɗ^����e�����傫���ƍl�����܂��B
����2
�@���ɂ���ȊO�̐ݒ肪�ǂ��e���������炵�Ă��邩�ׂ܂��B
�܂������]�����ƒ��_���̉e���ɂ��Ē��ׂ܂���
�ݒ� �����]�����P����101
�@ �ڑ����_��1����10
�@ �Q���m�[�h����1000
�@ �t�@�C�������m�[�h���P
�@ �����͈́�1
�@�@�@
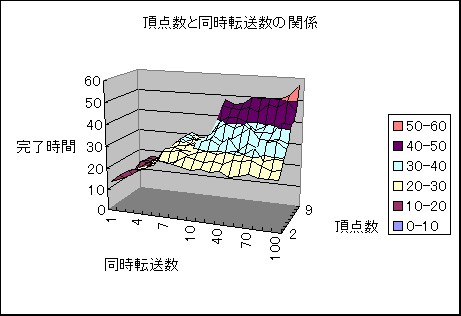 �}2�@���_���Ɠ����]�����̊W
�}2�@���_���Ɠ����]�����̊W
�ڑ����_������1�̎��̓t�@�C�����z�z�����l�b�g���[�N�Ԃƌq����Ȃ������Ԃ�
�Ȃ��Ă��܂��S�̂Ƀt�@�C�����s���n��Ȃ���Ԃ��������Ă��܂����Ƃ�����܂����B
�ڑ����_���������ꍇ�A�����]��������������ɂƂ��Ȃ��������Ԃ͑������܂��B
�������ꍇ�A�ڑ����_�����������Ă����܂荷�͐����܂���ł����B
�������A�����]�����̒l���傫���ꍇ�͊������Ԃ̍��͑傫���Ȃ�܂��B�ȏ�̂��Ƃ���
�@(1)�����]�����𑝂₷�Ɣz�z�����������Ȃ�
�@(2)�ڑ����_���������Ȃ�ƌ����̈����Ȃ肩�����Ђǂ��Ȃ�A���Ȃ����ɂ͈����Ȃ�ɂ����Ȃ�
���Ƃ��킩��܂����B
����3
�@�����͈͂Ɠ����]�����̊W�ɂ��Ē��ׂ܂����B
����ɂ��A�����͈͂ɓ����]�������A�ǂ̂悤�ɉe����^���邩�ׂ܂����B
�ݒ� �����]����1����100
�@ �����͈͂P����5
�@ ���_��=2
�@ �Q���m�[�h��=2000
�@ �t�@�C�������m�[�h��=�P
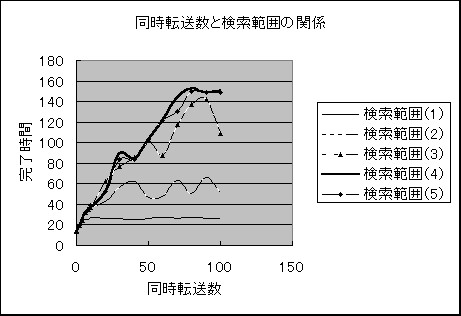
�}3�A�����]�����ƌ����͈͂̊W
�����͈͂��P�̎��͂قƂ�Ǖω����܂���ł������A�����͈͂�2�ȏ�ɂȂ��
�����]�����̉e������悤�ɂȂ�܂����B
���̂��Ƃ���A�����͈͂����߂�Ɠ����]�����̉e�������܂�
�Ȃ��Ȃ�Ƃ������ʂ������܂����B
�@����4
�@�Q���m�[�h���Ɠ����]�����ɂ��ω��ׂ܂����B
�����͈͂�1�̏ꍇ�ƂQ�̏ꍇ�ɂ��Ē��ׂ܂����B
�ݒ� �����]����1����T
�@ �Q���m�[�h���P����1000
�@ �t�@�C�������m�[�h��=1
�@ ���_��=2
�@ �����͈�1�܂���2
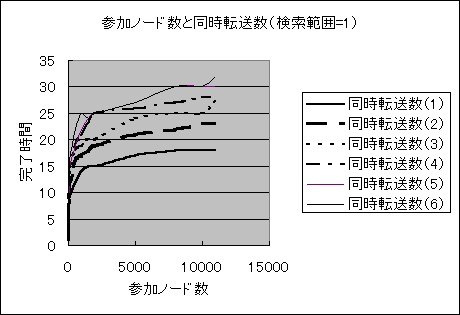
�}4�Q���m�[�h���Ɠ����]�����i�����͈�=1�j�̊W
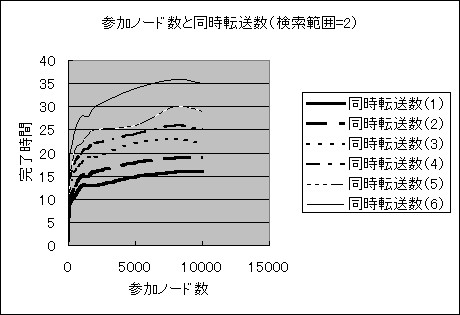
�}5�@�Q���m�[�h���Ɠ����]�����i�����͈�=2�j�̏ꍇ
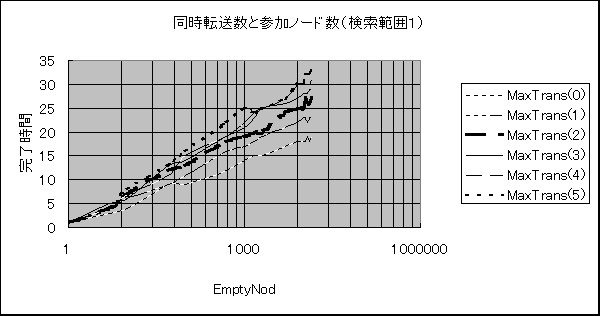
�}�U�@�Q���m�[�h���Ɠ����]�����i�����͈�=1�j�̋ߎ��l�Ȑ�
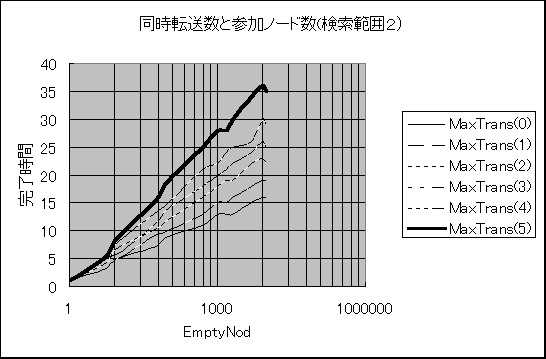
�}�V�@�Q���m�[�h���Ɠ����]�����i�����͈�=2�j�̋ߎ��l�Ȑ�
�����͈͂�1�̏ꍇ��2�̏ꍇ���Q���m�[�h���̑����A
�����]�����̑����ɂƂ��Ȃ��������Ԃ͑������܂����B
�����]�������ǂ̒l�ł����Ă��Q���m�[�h�������ȏ�ɂȂ��
�������Ԃ͑傫���ω����Ȃ��Ȃ�܂����B
�����]�����ɂ���ĎQ���m�[�h���̑����ɂƂ��Ȃ��������Ԃ͑������Ă��܂��B
���̂��Ƃ���A�Q���m�[�h�������Ƃ��āA�������Ԃ�T�A�萔a�Ƃ��āA�}6��}7����
T=alog10n���A
�萔a�Ɠ����]�����̊W���O���t�ɕ\���܂����B
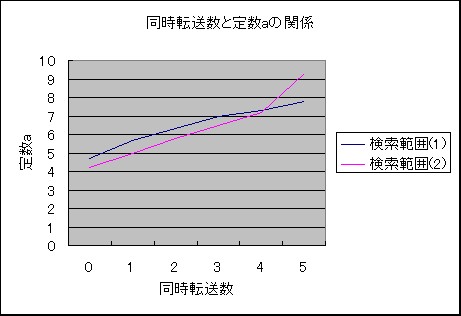
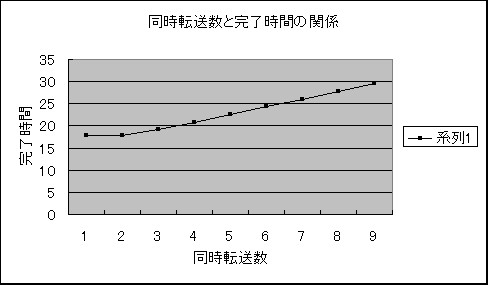
�}�W�@�����]�����ƒ萔a�̊W
�ȏ�̌��ʂ���A�����͈͂P�C�Q�̊�������T��
T=(14+2.0�~MaxTrans) )log10n
T=(4.2+0.8�~MaxTrans)log10n
�ŋ��߂邱�Ƃ��ł��܂����B
����5
�@�Ō�Ɋ������Ԃɉe���̑傫�������]�����ƒ��_����100�ɂ��āA�����̈����ꍇ�ł̊������Ԃׂ܂����B�����͈͂�1��2�̏ꍇ�ɂ��čs���܂����B
�ݒ� �Q���m�[�h�����P����1500
�@ �����͈͂�1�̏ꍇ�ƂQ�̏ꍇ
�@ �t�@�C�������m�[�h��=1
�@ �����]����=100
�@ ���_��=100
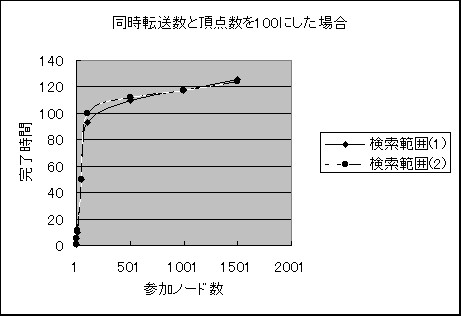
�}�W�@�����]�����ƒ��_����100�ɂ����ꍇ
�����������̂ŎQ���m�[�h���������ł����Ă����Ȃ�̎��Ԃ��|����܂����B
���̐ݒ�̏ꍇ�ł��Q���m�[�h�������Ȃ����_�ł͋}���Ɋ������Ԃ͑����Ă������A
���̌�͊ɂ₩�ȋȐ��ɂȂ�܂����B�܂��A�����͈͂͂��܂�W����܂���ł����B
�T�@����
5.1�@���ʂɂ���
�@�o2�o�ɂ����鉼�z�l�b�g���[�N��A�T�[�r�X�̃p�����[�^�Ƃ���
�����]�����A�ڑ����_���A�����͈͂�ω������āA�l�b�g���[�N�S�̂ւ̏��A
�`�����x���V�~�����[�V�����ʼn�͂��܂����B���̌��ʗ\�z�Ƃ͑傫���قȂ錋�ʂ��ł܂����B
�����]�����A�ڑ����_���A�����͈͂Ƃ��A
���₷�قǃT�[�r�X�����シ��悤�Ɏv���܂����ǂ�����₹�Α��₷�قǑ��x��
�ቺ���Ă����܂����B���ɓ����]�����͑��₷�ƌ����ɑ��x�͒ቺ���܂����B
�������A�ڑ����_�������Ȃ��ꍇ�͓����]�����̉e���͏��Ȃ��Ȃ�܂��B
�����ɂ��čl����ƁA�����]�����𑝂₷�ƂP��̓]���ɂ����鎞�Ԃ������邱�Ƃ�
�l�����܂��B�����ŁA���ɗ��z�I�ȏ����ŗ��_�����܂��B
�S�Ă̓]�����������]�����ɓ������ꍇ���l���܂��B�����]������d,�]�����̐[����k
�Ƃ��܂����B

�@ �����Q�`5�̎���N��T�̊W
�A N���Œ肵�Ă����A����T�̊W
�ȉ��̏ꍇ�ɂ��Ă����܂����B
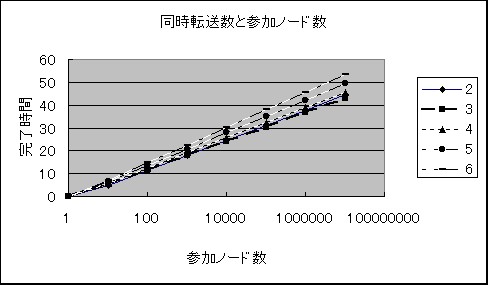
�}10 N��T �̊W
�}11�@����T�̊W
N���\���傫�����T�͂ق�log���ɔ�Ⴕ�đ��������A
����́A�����������T��������̂��������ʂƈ�v���܂��B
5.2 ��ăV�X�e���̎����\���ɂ���
�@�����͈͂����肷�邱�Ƃ��������]���������Ȃ����邱�ƂŃt�@�C���̔z�z������ǂ������V�X�e����
�������邱�Ƃ��ł���ƍl�����܂��B�܂��A�����]�����𑝂₵���ꍇ�ɂ͌����͈͂̒l�ɂ���Ċ������Ԃ���������̂�
�����]�������������ɂ͌����͈͂����߂邱�Ƃ����ʂ�����V�X�e���������ł���ƍl�����܂��B
�U,�܂Ƃ�
�@������_�E�����[�h�͈̔͂����肷�邱�Ƃ́A�S�̂ł̊����܂ł̎��Ԃ��l����ƁA
�������悭���邱�Ƃɂ͌q����Ȃ��Ƃ������_�ɂȂ�܂����B������ǂ����邽�߂ɂ́A
�����]���������Ȃ����邱�Ƃ��ł��z�z������ǂ����邱�ƂɌq����ƍl�����܂��B
����͓����]�����������قǃt�@�C�������m�[�h���z�z����m�[�h���������邱�ƂɂȂ�̂ŁA
��ɏW���Ɠ�����ԂɂȂ�ƍl�����܂��B���̂��ߓ����]���������Ȃ����邱�Ƃ͗v����f�邱�ƂɂȂ��肻�ꂪ�A
���U���Ɍq�������ƍl�����܂��B�܂��A���_���⌟���͈͓͂����]�������傫���l�ȂقNJ������Ԃ͑������܂��B
���_���ɂ����Ă͏��Ȃ��Ƃ�1�ȏ�ɂ��Ȃ��Ɨ�����ۂőS�̂Ƀt�@�C�����s���n��Ȃ����Ƃ�����܂��B
�ȏ�̂��Ƃ���A�����]���������Ȃ����A��葁�����ԂŃt�@�C�������m�[�h���m���ɑ��₵�Ă������Ƃ�
�z�z������ǂ����邱�ƂɌq����Ƃ������_�ɂȂ�܂����B
�Q�l����
[1]http://napster.com/
[2]http://gnutella.wego.com/
[3] http://winny.info/
[4] http://www.studyinghttp.net/
[5]http://www.xinmx.com/
[6]�C���f�N�X�T�[�o�I�����z�u����P2P�V�X�e��AmorphicNet
�@ ���c�Ǘ��@�g�c�I�F�@�M��C��
[7]Q.Lv,P.Cao,E.Cohen,K.Li,and S.Shenker,�hSearch and replication in unstructured peer-to-peer networks�h,in Proceedings of 16th ACM International Clnference on Supercomputing(ICS�f02),June 2002.
[8]]P2P�l�b�g���[�N�ɂ�����T�[�r�X���萫����̂��߂̃��v���P�[�V�����z�u��@
�@�@�@�@�㓡�ÍG�@�����M��@���c���K
[9]�@A-L.Barabasi and R.Albert, �gEmergence of scaling in random networks,�hScience,vol.286,pp.509-512,1999.
[10]�@�@http://www.scast.tv/scast/
[11]�@�@http://peercast.gooside.com/
[12] RelayCast:�s�A�c�|�s�A�^�X�g���[���z�M�̂��߂̃~�h���E�F�A
�@�@�@�@�O���@�a�@�@�����@���G�@�@�X��@���V�@�@�R�@�F�I
�t�^
�w�b�_�[
| byte | �T�v | ���� |
| 0�`15 | ���b�Z�[�W���ʎq | �����Windows��GUID���B���͂��ꂪ�ǂ̂悤��
globally-unique�ł���ׂ��Ȃ̂��{���ɗ������Ă���킯�ł͂Ȃ�.
����͓���̃��b�Z�[�W�����Ɍ������̂��ǂ������f����̂Ɏg���Ă���B |
| 16 | �y�C���[�h���ʎq(function identifier) | �l�@�@�\
0x00 Ping
0x01 Pong (Ping�ւ̉���)
0x40 Push request
0x80 Query
0x81 Query hits (Query�ւ̉���)
|
| 17 | TTL | Time to live. TTL�l�̓t�H���[�h�����x��1�Â��Z�����B
����1��菬����TTL������������b�Z�[�W�́A
�t�H���[�h�����ׂ��ł͂Ȃ��B |
| 18 | Hope | ���̃��b�Z�[�W���t�H���[�h���ꂽ�� |
| 19�`22 | <�y�C���[�h��/TD> | �����y�C���[�h�̒����B |
�o�h�m�f�̓y�C���[�h�͂���܂���B
�y�C���[�h�Fpong
| byte | �T�v | ���� |
| 0-1 | �|�[�g�ԍ� | IPv4�ł̃|�[�g�ԍ� |
| 2-5 | IP�A�h���X | IPv4�ł�IP�A�h���X�Bx86�̃o�C�g�I�[�_�[�Ń��g���G���f�B�A���ł� |
| 6-9 | �t�@�C���� | ���̃z�X�g�����L���Ă���t�@�C���̐��B |
| 10-13 | �L���o�C�g�� | ���̃z�X�g�����L���Ă���L���o�C�g�� |
�y�C���[�h�Fquery
| byte | �T�v | ���� |
| 0-1 | �Œᑬ�x | ���̗v���ɉ�������ׂ��T�[�o�̍Œᑬ�x(�L���r�b�g/�b) |
| 2 | ����� | �����L�[���[�h�A���邢�͑��̔��f��BNULL�ŏI�� |
�y�C���[�h���Fquery hit
| byte | �T�v | ���� |
| 0 | �q�b�g���� (N) | ���̐ݒ�ł̃q�b�g�����B��q����"�������ʂ̏W��"���Q�ƁB |
| 1-2 | �|�[�g�ԍ� | IPv4�ł̃|�[�g�ԍ� |
| 3-6 | IP�A�h���X | IPv4 �ł�IP�A�h���X�Bx86 �̃o�C�g�I�[�_�[�̓��g���G���f�B�A���ł� |
| 7-10 | ���x | �������̃z�X�g�̑��x�i�L���r�b�g/�b�j |
| 11+ | �������ʂ̏W�� | �����̑�����N���� (��q��"�q�b�g����" ���Q��).
bytes�@�@�@�T�v�@�@�@�@�@�@����
0-3 �@�@�C���f�b�N�X�@�@�@�t�@�C���̃C���f�b�N�X�ԍ�
4-7�@�@�@�@�T�C�Y�@�@�@�@�@�@�o�C�g�P�ʂ̃t�@�C���T�C�Y
8�@�@�@�@�@�t�@�C�����@�@�@�@�t�@�C���̖��O�B�I�[�͓�d��NULL�B
|
| Last 16bytes | �N���C�A���g���ʎq | �������̃z�X�g��GUID�BPUSH�Ŏg���� |
�y�C���[�h���Fpush request
| byte | �T�v | ���� |
| 0-15 | �N���C�A���g���ʎq | �v�b�V�����ׂ��z�X�g��GUID |
| 16-19 | �C���f�b�N�X | �t�@�C���̃C���f�b�N�X�ԍ�(�N�G���[�q�b�g�ŗ^����ꂽ����) |
| 20-23 | IP�A�h���X | IPv4�ł̃v�b�V����A�h���X |
| 24-25 | �|�[�g | IPv4�ł̃v�b�V����̃|�[�g�ԍ� |
�v���O�������X�g
�@
import java.util.*;
interface Constant {
final static int CarriedNode=1;//the number of nodes that have the information
final static int EmptyNode=1000;//the number of nodes that want the information
final static int Connections=2;//the number of connections
final static int Distance=7;//the depth of searching
final static int MaxTrans=8;//the number of accepting transferring
}
class newsim implements Constant {
public static void main(String args[]){
ServantList sl=new ServantList();
sl.addCarriedNode(CarriedNode);
sl.addEmptyNode(EmptyNode);
sl.makeRandomConnection(Connections);
//sl.showMap();
int timer=0;
while(!sl.finished()){
sl.play();
System.out.println(timer);
sl.show();
timer++;
}
System.out.println(timer);
}
}
class ServantList implements Constant {
ArrayList requiring;
ArrayList receiving;
ArrayList carried;
static Random random=new Random();
ServantList(){
requiring=new ArrayList();
receiving=new ArrayList();
carried=new ArrayList();
}
void makeRandomConnection(int width){
ArrayList l=new ArrayList(requiring);
l.addAll(carried);
for(Iterator i=l.iterator();i.hasNext();){
Servant s=(Servant) i.next();
for(int j=0; jMaxTrans){
return false;
}
transferring.add(s);
return true;
}
void deliver(){
double amount=1.0/(double)transferring.size();
for(Iterator i=transferring.iterator(); i.hasNext();){
Servant s=(Servant) i.next();
if((s.receiving+=amount)>=1.0){
i.remove();
}
}
}
boolean finished(){
return receiving>=1.0;
}
int getID(){
return no;
}
ArrayList lookup(int distance){
ArrayList l=new ArrayList();
if(distance>0){
for(Iterator i=neighbor.iterator(); i.hasNext();){
Servant n = (Servant) i.next();
if(n.finished()){
l.add(n);
}
l.addAll(n.lookup(distance-1));
}
}
return l;
}
void join(Servant s){
neighbor.add(s);
}
void showNeighbor(){
for(Iterator i=neighbor.iterator(); i.hasNext();){
Servant n = (Servant) i.next();
System.out.print(n.getID()+" ");
}
System.out.println();
}
}