
情報化社会の発展より、ユーザは増え続ける膨大な情報の中から自分が求めている情報を探し当てることが容易ではなくなっている。そのため、情報過多を克服する情報推薦技術は必要不可欠なものになりつつである。そして、豊富なオンラインサービスのおかげで、情報推薦技術のサブクラスであるレコメンデーションシステムはますます重要な役割を果たしている。レコメンデーションシステムは、様々な選択肢からユーザが関心のある製品やサービスを案内するための情報フィルタリングツールである。これは様々な情報アクセスシステムにおいて、ビジネスの促進と意思決定プロセスの加速をもたらす重要かつ不可欠な役割を果たしている。現在、 Netflix、Amazon、Spotifyなどの主要企業がユーザにアイテムを提案するために使用している。
一方、過去十年にわたり、深層ニューラルネットワークはコンピュータビジョンや音声認識などの多くのアプリケーション分野で注目を集めてきた。多くの複雑なタスクを解決する能力と最先端の結果を提供する能力のおかげで、学術界と産業界など幅広いアプリケーションに適用されている[1]。推薦技術についても従来のモデルでの困難を克服し、高いレコメンド品質を達成するようになってきており、深層学習モデルを応用したレコメンデーションシステムの進歩は注目を集めている。しかし、協調フィルタリングというレコメンデーションシステムの実現手法を適用する試みは疎な入力を扱うためあまりされなかった。深層学習は非線形で自明ではないデータの関係を効果的に捉え、上位層でより複雑な抽象を表現することを可能にするため、現在の協調フィルタリングよりいい性能をもたらすことが期待できると考えられる。
本論文の目的は、オートエンコーダという深層ニューラルネットワークモデルを使って協調フィルタリングを実現することである。さらに前処理がどのように結果に影響を与えることを考察する。
本文では、まず2章で、レコメンデーションシステムとニューラルネットワークの理論的基礎と本論文で提案した実現手法について述べる。次に3章ではこれまでに行われて来た深層ニューラルネットワークを応用した推薦システムモデルについて述べる。さらに4章では提案手法を適用した評価実験の実験環境、データセットと実験結果などを示す。最後にベースラインと比較を行なった上、提案手法の有効性を考察する。
まず「レコメンデーションシステムとは?」について説明する。レコメンデーションシステム(Recommender system)という名前は1997年のACM Communications誌の特集[2]で定着したものである。当時記述した定義は以下である。
すなわち、レコメンデーションシステムは利用者にとって有用と思われる対象,情報,または商品などを選び出し,それを利用者の目的に合わせた形で提示するシステムといえる。広義には情報検索や情報フィルタリング技術の一つとみなせる。そして、初期のレコメンデーションも確かにこれらの技術を基盤としていた。しかし、情報検索技術に対して、レコメンデーションシステムは不要なものを除外するのではなく、必要なものを取り出すのが主目的である。
レコメンデーションシステムは達成するタスクに基づいて分類すると適合アイテム発見と評価値予測の二種類に分類することできる。適合アイテム発見とは利用者が自分の嗜好に適合するものを,何か見つけ出すことである.例えば、ケーキを買うために推レコメンデーションシステムを利用する場合、評価が高いいものをいくつ絞り込んでユーザに提示する。評価値予測とは利用者がアイテムにつける評価値を予測することである。さらに実現手法に基づいた分類は大きく分けてコンテンツベース(Content-Base)、協調フィルタリング(Collaborative Filtering)とハイブリッド手法(Hybrid)の3つである。それについては2.3章で詳しく述べる。なお今回の実験はタスク分類には評価値予測、実現手法分類では協調フィルタリングに属している。
レコメンデーションシステムは予測精度で評価する。予測精度とは予測して推薦したアイテムに実際にどれくらい利用者が関心をもつかを数値化したものである。この評価にはオンラインとオフラインがある。オンライン評価とは,被験者に実際にシステムを利用させ,推薦が適合したかどうかを調査するものである。一方、オフラインは事前に被験者から集めた嗜好データと,予測した結果の一致を調べる方法である。前者の方がより実際の運用に近いが、得られるデータ数が少なく安定した検証が困難であったり,多数の項目での比較が困難になるなどの問題点があるため、本研究ではオフライン方式でシステムを評価する。オフラインの評価では,一般の機械学習と同様に,交差確認によって汎化誤差を推定し,その汎化誤差で予測精度を評価する。今回の実験は二乗平均平方根誤差(RMSE)を汎化誤差として予測精度を評価する。
レコメンデーションシステムはシステムである以上、入力と出力が存在する。レコメンデーションシステムの入力は嗜好データである。嗜好データとは,いろいろなアイテムについての関心や好みの度合いを数値化したデータである[2]。嗜好データの最も顕著な特徴は非常に疎 (sparse) であること。すなわち,非常に多くのアイテムが存在するが,利用者が評価しているのはごく一部で,その他のアイテムへの評価値は欠損している。具体的には,評価値があるのは全体の3%~ 0.001%のオーダである。また,欠損は均一ではなく、被評価数の順に,被評価数ごとのアイテム数を整列すると、被評価アイテム数は指数的に減少する現象がみられる[4]。嗜好データは一般にはユーザ-アイテムという疎な行列で表される。
本実験で使用した Movie Lens[5]データセットも同じである。163949のアイテムに対して評価数が僅かの100004で、スパース率は1.4%である。ず1が今回の実験で利用したユーザ-アイテム行列の一部である。
| A | B | C | D | E | F | G | H | ... | |
|---|---|---|---|---|---|---|---|---|---|
| ア | - | 5 | - | - | - | - | - | - | ... |
| イ | 4 | - | - | - | - | - | - | - | ... |
| ウ | 3 | - | - | - | - | 4 | - | - | ... |
| エ | - | 3 | 3 | - | 3 | - | - | - | ... |
| オ | - | - | - | - | - | 5 | - | - | ... |
| カ | - | - | - | - | - | 4 | - | - | ... |
| キ | - | - | - | - | - | - | - | - | ... |
| ク | - | - | - | - | - | - | - | - | ... |
| ケ | 4 | - | - | - | - | - | - | - | ... |
| コ | 5 | - | - | - | - | - | - | - | ... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
2.1節で紹介したように既存のレコメンデーションシステムの実現手法には、大きく分けてコンテンツベース、協調フィルタリング、ハイブリッド手法の3つがある。
コンテンツベース手法は、ユーザープロファイルや製品説明を利用して推薦を行う。 例えば、映画を推薦する場合、映画のジャンル、年齢と俳優などを使ってユーザをクラス分類する。分類したクラスに基づいて推薦を行う。一方、協調フィルタリングは、ユーザまたは製品のコンテンツ情報を使用せず、ユーザの過去の行動または好み(例えば評価)を使用する。最後に、ハイブリッド手法とは、コンテンツベースと協調フィルタリングを組み合わせることによって、両方のベストを得ることを目指している。
このように,協調フィルタリングは与えられたデータの中から,規則性を見つけ出し,その規則性に基づいて予測するため、機械学習や統計的予測などの手法が使われている。協調フィルタリングの目標は表1のような疎なユーザ-アイテム行列を表2のような密なユーザ-アイテムマトリックスに変換することである。従来の実現手法はマトリックス分解と近傍モデルの二通りであるが、本実験では深層ニューラルネットワークモデルを使ってそれを実現する。
| A | B | C | D | E | |
|---|---|---|---|---|---|
| ア | - | 3 | 5 | - | - |
| イ | - | 5 | - | 5 | 4 |
| ウ | 5 | - | 4 | - | - |
| エ | 2 | - | 1 | 4 | - |
| A | B | C | D | E | |
| ア | 4 | 3 | 5 | 1 | 5 |
| イ | 2 | 5 | 2 | 5 | 4 |
| ウ | 5 | 4 | 4 | 3 | 2 |
| エ | 2 | 3 | 1 | 4 | 4 |
ニューラルネットワークは機械学習モデルの一種で、(人工)ニューロンによって構成されたネットワークである。ニューロンとは図1のような計算ユニットであること。
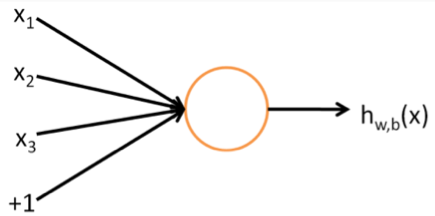
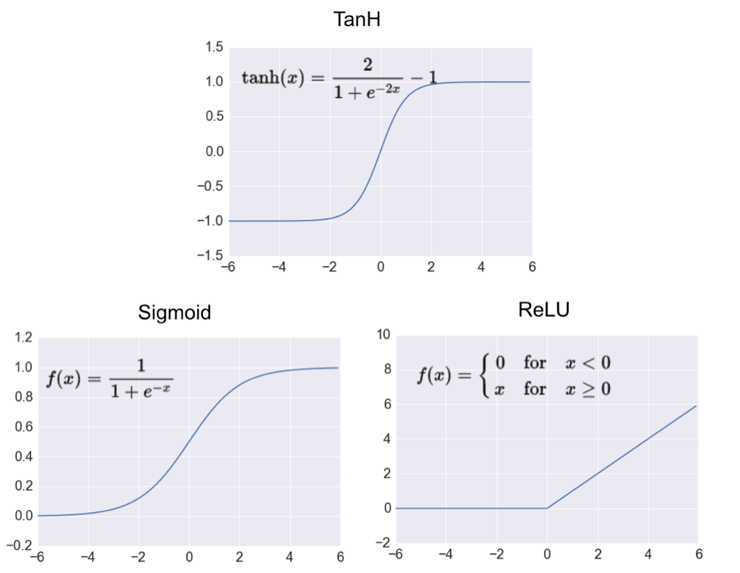
式(1)のfは活性化関数( activation function)と呼ぶ非線形関数である。ニューラルネットワークで使う活性化関数は主に図2で示した三種類がある[1]。本実験ではReLUを使っている。
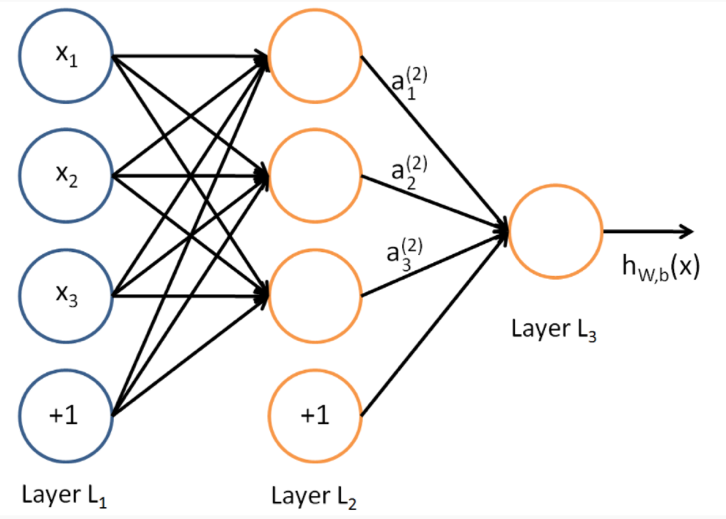
そのようなニューロンの出力を別のニューロンの入力となるようにつなぎ合わせたものがニューラルネットワークである。ニューラルネットワークの目的は、目標とした関数を近似することである。図3はニューラルネットワークの一例である。一番左側のニューロン層(Layer
もっと一般的には式(6)で表す。
これを順方向伝播と呼ぶ。
そして、このネットワークを訓練するために訓練データが必要である。m個の訓練例の固定訓練集合{(),(),…,()}があると仮定する。単一のトレーニング例(x、y)に対して、その単一の例に関するコスト関数は式7のように定義する。
m個の例の訓練セットが与えられると、全体コスト関数は式8のように定義する。
これを損失関数(loss function)と呼ぶ。我々の目標がこの損失関数を最小化とすることである。この目標を達成するために逆方向伝播法を以下に示すだる。
順方向伝播を実行し出力レイヤーまで計算する。
出力レイヤー内の各出力ユニットiについて式9を計算する。
各レイヤーの各ノードに対して式10を計算する。
式11と12を従って偏微分を計算し、重みとバイアスを更新する。なお、
オートエンコーダは教師無し深層ニューラルネットワークモデルの一つである。一般的には情報を圧縮するエンコータと復元するデコーダで構成する。図4にオートエンコーダのモデルを示す。目的はネットワークの出力から初期入力を再構成することで関数
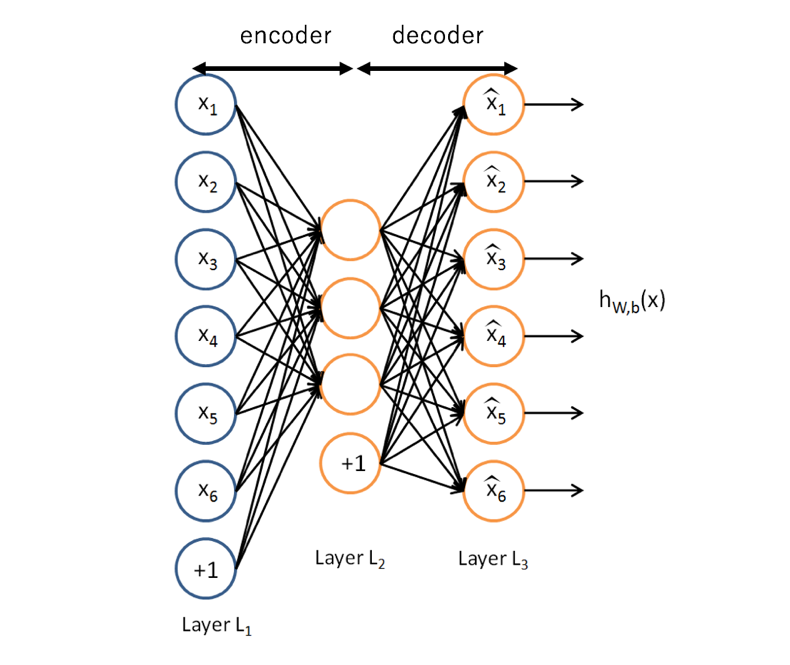
しかし、本実験の場合はユーザ-アイテムマトリックスの欠落しているデータを予測することを目的としているため別の制限が必要である。それは順方向伝播と逆方向伝播において欠損値をゼロ値に変えることである。これは、ネットワークからニューロンを除去することと厳密に同じである。ここでの入力/出力サイズはユーザ-アイテム行列に依存する。図5にこの訓練方法を示している。ユーザ-アイテム行列の欠損値をゼロで補完する。補完したユーザ-アイテム行列の行ことにモデルに入力し、順方向伝播で出力する。ここでゼロ値を入力したニューロンは順方向伝播に介入しない。次に出力したニューロンに対して入力が欠損していなかったニューロンと対応したニューロンだけ逆方向伝播を行え、モデルを訓練する。

本実験は二乗平均平方根誤差を損失関数としてモデルを訓練するが、2.6節紹介した循環訓練だけ二乗平均平方根誤差以外、式(13)のマスクされた平均二乗誤差損失関数を導入する[5]。
上で述べた訓練では、欠損値をゼロに充填するゼロ値充填法しか適応していない。しかし、この手法はデータの特性を表現できないと考えられう。よって本実験はゼロ値充填法に代わり中央値、ユーザ平均、中心化と循環訓練の四つの前処理を上記のオートエンコーダモデルにそれぞれ適応し、その影響を比較する。
中央値手法は、評価の定義域の中央値をユーザ-アイテム行列に代入する方法である。本実験で使うデータセットは0~5の5段評価であるため、行列の欠損値に3を代入した後、学習を行う。表1に充填した結果が表4である。
| A | B | C | D | E | F | G | H | ... | |
|---|---|---|---|---|---|---|---|---|---|
| ア | 3 | 5 | 3 | 3 | 3 | 3 | 3 | 3 | ... |
| イ | 4 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | ... |
| ウ | 3 | 3 | 3 | 3 | 3 | 4 | 3 | 3 | ... |
| エ | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | ... |
| オ | 3 | 3 | 3 | 3 | 3 | 5 | 3 | 3 | ... |
| カ | 3 | 3 | 3 | 3 | 3 | 4 | 3 | 3 | ... |
| キ | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | ... |
| ク | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | ... |
| ケ | 4 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | ... |
| コ | 5 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | ... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
ユーザ平均手法は中央値手法と類似する方法である。中央値の代わりにユーザごとの評価の平均をユーザ-アイテム行列の欠損値に代入する。すなわち、ユーザ-アイテム 行列の行ことに平均を求める。
| A | B | C | D | E | F | G | H | ... | |
|---|---|---|---|---|---|---|---|---|---|
| ア | 3.4 | 5.0 | 3.4 | 3.4 | 3.4 | 3.4 | 3.4 | 3.4 | ... |
| イ | 4.0 | 3.7 | 3.7 | 3.7 | 3.7 | 3.7 | 3.7 | 3.7 | ... |
| ウ | 3.0 | 3.8 | 3.8 | 3.8 | 3.8 | 4.0 | 3.8 | 3.8 | ... |
| エ | 3.3 | 3.0 | 3.0 | 3.3 | 3.0 | 3.3 | 3.3 | 3.3 | ... |
| オ | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 | 3.0 | 3.0 | ... |
| カ | 3.7 | 3.7 | 3.7 | 3.7 | 3.7 | 4.0 | 3.7 | 3.7 | ... |
| キ | 3.5 | 3.5 | 3.5 | 3.5 | 3.5 | 3.5 | 3.5 | 3.5 | ... |
| ク | 3.4 | 3.4 | 3.4 | 3.4 | 3.4 | 3.4 | 3.4 | 3.4 | ... |
| ケ | 4.0 | 3.7 | 3.7 | 3.7 | 3.7 | 3.7 | 3.7 | 3.7 | ... |
| コ | 5.0 | 3.9 | 3.9 | 3.9 | 3.9 | 3.9 | 3.9 | 3.9 | ... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
中心化とはユーザ-アイテム行列から、アイテム平均を差し引いた値(式15)
を入力する手法である。そうすることでデータごとの特徴を取り除く。具体的な入力値は、例えばあるユーザiのアイテムjに対する評価点が=4で、アイテムjについた評価点の平均が=1.2の場合、入力値は=4 – 1.2 = 2.8となる.予測値については、ネットワークから出力された与えにアイテム平均を加えた。(式16)[6]
を予測値とする。表1にユ中心化を適応した結果が表6である。
| A | B | C | D | E | F | G | H | ... | |
|---|---|---|---|---|---|---|---|---|---|
| ア | -3.9 | 1.6 | -3.1 | -2.3 | -3.2 | -3.9 | -3.3 | -3.8 | ... |
| イ | 0.1 | -3.4 | -3.3 | -2.3 | -3.2 | -3.9 | -3.3 | -3.8 | ... |
| ウ | -0.9 | -3.4 | -3.3 | -2.3 | -3.2 | 0.1 | -3.3 | -3.8 | ... |
| エ | -3.9 | -0.4 | -0.1 | -2.3 | -0.2 | -3.9 | -3.3 | -3.8 | ... |
| オ | -3.9 | -3.4 | -3.1 | -2.3 | -3.2 | 1.1 | -3.3 | -3.8 | ... |
| カ | -3.9 | -3.3 | -3.1 | -2.3 | -3.2 | 0.1 | -3.3 | -3.8 | ... |
| キ | -3.9 | -3.4 | -3.1 | -2.3 | -3.2 | -3.9 | -3.3 | -3.8 | ... |
| ク | -3.9 | -3.4 | -3.1 | -2.3 | -3.2 | -3.9 | -3.3 | -3.8 | ... |
| ケ | 0.1 | -3.4 | -3.1 | -2.3 | -3.2 | -3.9 | -3.3 | -3.8 | ... |
| コ | 1.1 | -3.4 | -3.1 | -2.3 | -3.2 | -3.9 | -3.3 | -3.8 | ... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
循環訓練は厳密に定義すると前処理ではなく、訓練手法の一つに属すべきである。しかし、今回はそれをあるニューラルネットワークモデルを使った前処理として捉え、その効果を検証する。
レコメンデーションシステムにおいて、入力は非常に疎である。その理由は、ユーザが評価する項目はあくまですべての項目のごくわずかな部分しかないからである。一方、今回提案したモデルであるオートエンコーダの出力
以上に従って、全ての訓練データに対して以下のアルゴリズムが導かれる。
疎なユーザベクトルを入力とし、順方向伝播を行え、密な予測ベクトルを
偏微分を計算し、逆方向伝播で重みを更新する。
密な予測ベクトルを新たな訓練例として入力、順方向伝播を行う。
偏微分を計算し、逆方向伝播で重みを更新する。
近年、深層ニューラルネットワークは画像認識や自然言語処理などの領域で画期的な結果を生み出した。そのため、それらに関する新論文は一日に何十本も発表している。しかし、推薦技術に関してはそこまで顕著でなかった。ニューラルネットワークモデルを応用したレコメンデーションシステムに関する論文はSalakhutdinovらが2007に提案した制限付きボルツマンマシン(Boltzmann machine)を用いた。これは協調型フィルタリングモデルの二項関係をモデル化する最初の論文である[7]。そして2016年、Google社は線形モデルと深層ニューラルネットワークを組み合わせて共同学習し、両者の欠点を補うレーコメンデーションシステムモデルを公表し、それはオンライン実験で良い結果が得られた[8]。さらに、YouTubeが2017年に発表した論文[9]でわかるように、YouTubeもすでに正式的に深層ニューラルネットワーク技術を応用したレコメンデーションシステムを導入している。
一方、深層ニューラルネットワークを応用して協調フィルタリングを実現する手法は、オートエンコーダ以外にもボルツマンマシンと深層ニューラルネットワーク(DNN)による行列分解(Matrix Factorization)[10]などがある。しかし、ボルツマンマシン-協調フィルタリングは離散的な評価にのみ適用可能という問題点がある。そして、ボルツマンマシン-協調フィルタリングは各評価値に対して個別にパラメータセットを推定することになる。つまりr個可能な評価がある場合、ボルツマンマシンはnkr個パラメーターが必要となる。(nはユーザ数、k隠れニューロン)それに対して、 オートエンコーダはrに関係なくパラメーターが一定であるため、必要とするパラメーターが少ない。そして、行列因子分解アプローチは線形潜在表現しかを学習できないと比べて、オートエンコーダは活性化関数を介して非線形潜在表現を学習することができる。
また、オートエンコーダ-協調フィルタリングの前処理に関する研究として川上のDeep Collaborative Filtering がある[6]。川上は嗜好データを事前に中心化をしたあと、訓練済みのオートエンコーダに入力することで、従来の協調フィルタリングより精度が上昇したことを報告している。しかし、これも中心化の前処理とその効果だけを検証したため、他の前処理は一切触れていない。
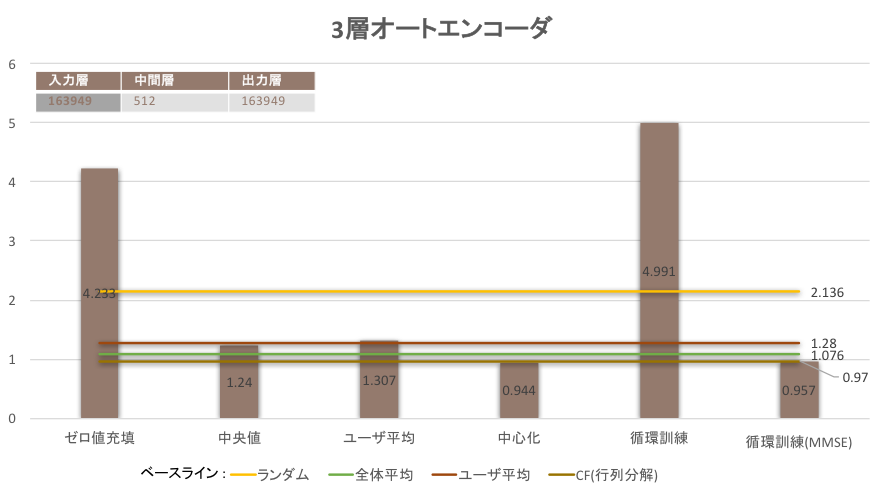
本実験ではオートエンコーダによる協調フィルタリングの実現と前処理による影響の観測を行う。実験は3層オートエンコーダと3層オートエンコーダを使って、それぞれゼロ値充填、中央値、ユーザ平均、中心化と循環訓練の5つの前処理に対して実験を行う。表4にオートエンコーダの各層の次元数を表す。
| 層数 | 入力層 | 中間層 | 出力層 |
|---|---|---|---|
| 3 | 163949 | 512 | 163949 |
| 5 | 163949 | 512-256-512 | 163949 |
| OS | Windows 10 Pro |
|---|---|
| プロセッサ | ntel Core i7-4820K 3.70GHx |
| メモリ | 32.0GB |
| GPU | NVIDA Geforce GTX TITAN |
| 言語 | Python バージョン3.6.0 |
|---|---|
| 深層学習 | Tensorflow |
| 数値計算 | Nmpy |
| 機械学習 | Scikit-learn |
| データ処理 | Pandas |
本研究を用いるMovie Lens 1Mでいうデータセットは映画の推薦サービスMovie Lensでユーザが映画を5段階評価した記録を収集したものである。Movie Lensは情報推薦アルゴリズムを検証のために用いられる標準的なデータセットである。データの概要は表7にまとめた。本実験ではデータに対して90%を訓練デー、10%をテストデータに分割した。
| 項目 | Movie Lens |
|---|---|
| 最終更新日 | 2016/10 |
| 種類 | 5段評価 |
| ユーザ数 | 617 |
| 映画数 | 163949 |
| 評価数 | 100004 |
| スパース度 | 1.4% |
本実験のベースラインとして四つの手法を使っている。
ランダム : 実験と同じ次元のユーザ-アイテム行列を生成し、その評点に1から5のランダムな値を振る。生成した行列とMovie Lensからなるユーザ-アイテム行列の誤差を計算する。
全体平均 : 実験と同じ次元のユーザ-アイテム行列を生成し、その評点にMovie Lensデータセットからなるユーザ-アイテムの全評価の平均を振る。生成した行列とMovie Lensからなるユーザ-アイテム行列の誤差を計算する。
ユーザ平均 : 実験と同じ次元のユーザ-アイテム行列を生成し、その評点にMovie Lensデータセットからなるユーザ-アイテムのユーザごとの平均を振る。生成した行列とMovie Lensからなるユーザ-アイテム行列の誤差を計算する。
行列分解協調フィルタリング : 回帰モデルをユーザ-アイテム行列Rの分解として捉え、解決する従来手法である。与えられたユーザ-アイテム行列の未評価アイテムの部分は欠損しているが、欠損していない完全なユーザ-アイテム行列を考え、この行列を次のように分解する。
𝐔はK×n、はK×mである(nはユーザ数、mはアイテム数)。 𝐔の第𝑥列ベクトルは利用者𝑥の特徴を、𝐔の第𝑦列ベクトルはアイテム𝑦の特徴を表している。すると、利用者𝑥へのアイテム 𝑦への評価値は
| 実験手法 | RMSE |
|---|---|
| ランダム | 2.136 |
| 全体平均 | 1.076 |
| ユーザ平均 | 1.280 |
| CF(行列分解) | 0.97 |
Movie Lensデータから分割した訓練データから訓練済みの3層/5層オートエンコーダモデルにテストデータを入力する。モデルが出力したユーザ-アイテム行列とMovie Lensからなるユーザ-アイテム行列のRMSE誤差を計算し、記録する。
| 実験手法 | RMSE |
|---|---|
| ゼロ値充填 | 4.233s |
| 中央値 | 1.240 |
| ユーザ平均 | 1.307 |
| 中心化 | 0.944 |
| 重複訓練 | 4.991 |
| 重複訓練, Loss=MMSE | 0.957 |
| 実験手法 | RMSE |
|---|---|
| ゼロ値充填 | 4.373 |
| 中央値 | 1.210 |
| ユーザ平均 | 1.317 |
| 中心化 | 0.941 |
| 重複訓練 | 4.901 |
| 重複訓練, Loss=MMSE | 0.953 |
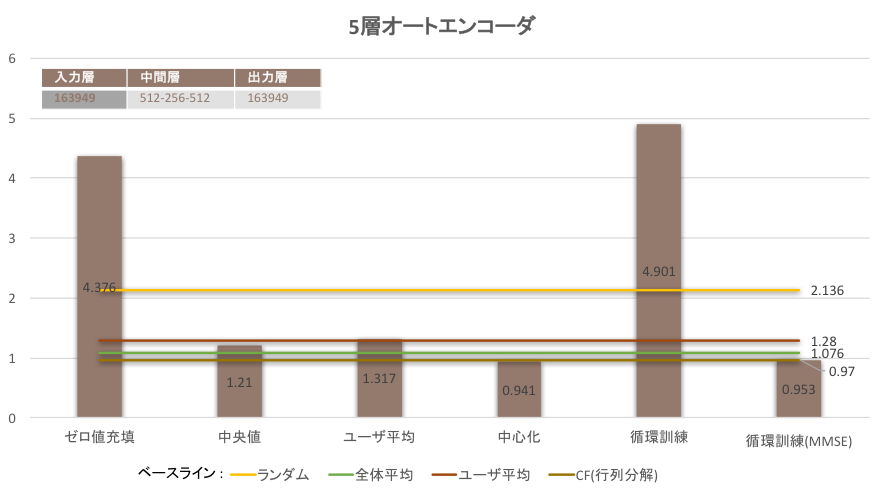
実験の結果、ゼロ値充填のユーザ-アイテム行列をそのままモデルに入力するとランダムより大き誤差が生じた。それは出力したユーザ-アイテム行列を観測すると、入力データの学習によってマイナスの予測値が出るわかった。そして、中央値とユーザ平均の前処理操作は学習の精度をある程度向上させたが、あくまでベースライン2と3に近い結果しか得れなかった。一方、中心化は評価していない商品を好き嫌いがない中間評価と仮定して扱うため、従来の手法を超える一番いい結果を得られた。最後に、循環訓練は一般のRMSE損失関数モデルはランダムより悪い精度をだした。これは出力を観測するとやはりマイナスの予測値が発生したのが原因であると考えられる。一方、MMSEを損失関数としたモデルには従来の協調フィルタリングを超える精度を得た。それはMMSEより欠損したデータについての学習は行われていなっかたため、ばらつきが少ない既存データだけを学習しているのが原因と考えられる。
また、深層化の効果については、5層モデルは3層よりいい結果が得られた。
本論文はオートエンコーダ協調フィルタリングを構築した上で、ゼロ値充填、中央値、ユーザ平均、中心化と循環訓練の5つの前処理をそれそれ加え、性能の評価を行なった。
映画への評点のようなばらつきが大きなデータに対して、データのばらつきやデータごとの特徴を緩和する前処理はモデルの精度向上を繋がることを確認できた。特にマスク損失関数モデルのオートエンコーダは循環学習を応用することで従来の協調フィルタリングの性能を超えた結果が得られた。さらに循環学習は、その他の前処理と異なり、データの種類に依存した手作業は必要なく、データによらず一意である。
今後の発展として、本実験は一番基本であるオートエンコーダモデルしか実装されていないため、同様な前処理の有効性についてはデノイジングオートエンコーダ(Denoisiing Auto-Encoder)、スタックオートエンコーダ(Stacked Auto-encoder)などのモデルにもたらした影響は検証していない。そのため今後は多様なモデルに基についた実験が必要であると思う。
また、今回の実験にはユーザのアイテムに対する評価しか考慮していない。これは言わば明示的な嗜好データだけで実験をしている。しかし、ユーザのウェブサイトの閲覧やアプリケーションの使用につれ大量な暗黙的な嗜好データも生成している[11]。暗黙的な嗜好データは大変価値があるが、大量かつ曖昧であるため、前処理はもっと重要になるではないかと考えられる。今後は暗黙的な嗜好データも考慮し、実験する必要がある。
J. Bobadilla, F. Ortega, A. Hernando, and A. Guti ́errez. Recommender systems survey. Knowledge Based Systems, 46:109–132, 2013.
神嶌敏弘,"推薦システムのアルゴリズム",人工知能学会誌 23(1), Jan.2008.
A. S. Weigend. Analyzing customer behavior at Amazon.com. In The 9th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining, Kyenote, p. 5, 2003.
GroupLens research lab, University of Minnesota ⟨http://grouplens.org/datasets/movielens/⟩
川上和也, 松尾豊, “Deep Collaborative Filtering: Deep Learning技術の推薦システムへの応用”人工知能学会全国大会論文集 28, 1-4, 2014
Ruslan Salakhutdinov,Andriy Mnih, and Geoffrey Hinton. 2007. Restricted Boltz-mann machines for collaborative filtering. In Proceedings of the 24th international conference on Machine learning. ACM, 791–798.
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, Hemal Shah. 2016. Wide & Deep Learning for Recommender Systems.DLRS
Paul Covington,Jay Adams and Emre Sargin. 2016. Deep neural networks for youtube recommendations.In Proceedings of the10th ACM Conference on Recommender Systems. ACM, 191–198.
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, Tat-Seng Chua. 2017. Neural Collaborative Filtering. WWW2017
A. V. D. Oord, S. Dieleman, and B. Schrauwen. Deep content-based music recommendation. In NIPS, pages 2643–2651, 2013.
本プログラムはpre_processクラス、data_process処理クラス、base_lineクラス、auto_encoderクラスとmain関数の五つで構成する。
実験で述べた中央値、ユーザ平均と中心化の三つの前処理を行うクアラスである。
Movie Lensデータを整理するためのクラスである
ベースラインを生成するクラスである。
オートエンコーダを生成するクラスである。
main関数はコマンドライン引数として次の値を取得する。
main関数ははじめにcsvフォーマットのMovie Lensデータを読み込み、data_converterでゼロ値充填したユーザ-アイテム行列を生成する。 次にtrain_test_splitを実行し、ユーザ-アイテム行列トレニング行列とテスト行列に分割する。
中央値、ユーザ平均、中心化したトレニング行列を生成する。
中央値、ユーザ平均、中心化したトレニング行列でそれぞれオートエンコーダモデルを訓練する。訓練済みのモデルにテスト行列を入力し、RMSE誤差を出力する。