1.はじめに
プログラミング言語とはシステム化する対象物を抽象化し、コンピュータで処理可能なコードを記述するために用いる人工言語である。プログラミング言語はコンピュータの機械語と一対一の対応をもったアセンブラから始まり、コンパイラを用いて機械語に翻訳することを前提としたコンパイラ言語、インタプリタと呼ばれるプログラムがソースコードを解釈し実行するスクリプト言語と、記述できる抽象度を高める方向へと進化してきた。
プログラミング言語はその存在理由から、より抽象度の高い記述が行えること、すばやい開発を行える事が求められる。抽象度の高い記述とは、プログラムがどういう処理を行うか(HOW)ではなく何の処理を行うか(WHAT)を記述しやすい構文、機能を持っていることを、すばやい開発とは記述性の高さ、コードの密度の高さ、バグの発生しにくい構文、機能を持っていることをさす。
この抽象度の高い記述、すばやい開発を行う妨げになるのが記憶領域の管理である。記憶領域の動的確保を行う場合など、コンピュータの抽象化されていない部分を直接プログラマが操作する必要が生じる。記憶領域の操作は領域の不正アクセス、開放忘れによるメモリリークなどのバグと常に隣り合わせである。言語処理系の構文木など、複雑な参照が行われているデータ構造ではとくに記憶領域の開放が問題となる。
これらの問題を解決するための機構がガベージコレクションである。ガベージコレクションは記憶領域の動的確保、開放を抽象化し、プログラマが明示的に管理を行う必要を減らす。本研究では、ガベージコレクションをLISPというプログラミング言語処理系に実装することにより、実装方法などの検討を行った。
2.ガベージコレクション
ガベージコレクション(GCと略す)はプログラミング言語処理系(以下言語処理系)の一部もしくはライブラリとして提供される、動的に確保した記憶領域のうち利用されていない記憶領域を自動的に回収し、再利用または開放を行う機構である。
GCを導入することによりプログラマは手動での記憶領域の管理から開放される。
2.1.ガベージコレクションの必要性
GCは近年の言語処理系では必須の機能として提供されているが、この要因としては、
- 言語処理系の提供する機能の高度化
- 明示的な管理を行うと実現しにくいプログラミングスタイルの主流化
- コンピュータの高速、大容量化により、実行効率より開発効率が求められるようになった
などが考えられる。
2.1.1.例 : 例外
例外とはプログラム実行中におこる不都合を処理するための分岐である。不都合は対処されもとの処理に戻ればよいが、ファイルやメモリなどの資源確保の失敗など取り返しのつかない不都合に対しては処理の継続をあきらめなければならない。その場合、それまでの処理で確保した資源の開放が問題となる。
ここではGCの存在が例外を利用したプログラミングにどのような影響を与えるかを述べる。プログラムの例としてC++とJavaをあげ、例外を利用したプログラムとしてコンストラクタで例外を発生させるクラスを作成する。
2.1.1.1.C++
Figure 1.とFigure 2.はファイルを管理するクラスを利用したプログラムである。
C++の標準ライブラリは初期設定では例外を発生させることは無いため、通常は例外を発生させないFigure 1.のようなプログラミングスタイルが主流であるが、ここではFigure 2.のように意図的に例外の発生を許可している。Figure 2.は全ての例外を捕捉してコンストラクタ外に例外が漏れないよう記述している。
C++ではコンストラクタで例外が発生して処理が中断してしまった場合にデストラクタが呼び出されないという有名なバグが存在する。また、デストラクタで例外が発生した場合、例外クラスの中で例外が発生する場合も再現が難しいバグになる。例外クラスの中で例外が発生する代表的な例としては、bad_alloc例外が発生した状況で、例外オブジェクトを作成するためにnewを使い、再度bad_allocを発生させる場合などがある。これらのバグは発見することが難しい。
このため、コンストラクタ、デストラクタの処理が例外により中断することは許されない。つまり、C++では例外安全(例外が発生しても処理が中断されないこと)なコンストラクタ、クラスを作成することが安全なプログラムを作成する必要条件である。これらのことから、C++は例外という機構を取り入れたがために例外を利用するための資源管理をプログラマに強いるようになってしまった。
これらは資源管理をプログラマが行う必要から生じる。GCが存在すればこのように資源の解放について注意を向けるコストが軽減される。
#include <iostream>
#include <fstream>
#include <string>
class file_io {
private:
std::ifstream *ifs_;
std::ofstream *ofs_;
bool is_fail_;
public:
file_io() : is_fail_(false), ifs_(NULL), ofs_(NULL) {}
file_io(std::string input_file, std::string output_file)
: is_fail_(false) , ifs_(NULL), ofs_(NULL)
{
ifs_ = new std::ifstream();
ofs_ = new std::ofstream();
if (ifs_ == NULL || ofs_ == NULL) {
is_fail_ = true;
return ;
}
ifs_->open(input_file.c_str());
ofs_->open(output_file.c_str());
if (ifs_->fail() || ofs_->fail()) {
is_fail_ = true;
}
}
~file_io() { delete ifs_; delete ofs_; }
bool fail() { return is_fail_; }
/* and more definitions ... */
};
int main(int argc, char **argv) {
if (argc < 3) { return -1; }
file_io fio = file_io(argv[1], argv[2]);
std::cout << fio.fail() << std::endl;
}
#include <iostream>
#include <fstream>
#include <string>
#include <new> // new 演算子の例外発生を許可する
class file_io {
private:
std::ifstream *ifs_;
std::ofstream *ofs_;
bool is_fail_;
public:
file_io() : is_fail_(false), ifs_(NULL), ofs_(NULL) {}
file_io(std::string input_file, std::string output_file)
: is_fail_(false) , ifs_(NULL), ofs_(NULL)
{
try {
ifs_ = new std::ifstream();
ofs_ = new std::ofstream();
} catch (std::bad_alloc) {
is_fail_ = true;
return ;
}
// 例外を許可する
ifs_->exceptions(std::ios_base::failbit);
ofs_->exceptions(std::ios_base::failbit);
try {
ifs_->open(input_file.c_str());
ofs_->open(output_file.c_str());
} catch (std::ios_base::failure) {
is_fail_ = true;
}
}
~file_io() { delete ifs_; delete ofs_; }
bool fail() { return is_fail_; }
/* and more definitions ... */
};
int main(int argc, char **argv) {
if (argc < 3) { return -1; }
file_io fio = file_io(argv[1], argv[2]);
std::cout << fio.fail() << std::endl;
}
2.1.1.2.Java
Figure 3.はJavaでの例である。このプログラムではFileIOクラスのオブジェクトを得るときにコンストラクタが呼ばれる。コンストラクタはファイル名を引数に取り、FileInputStreamを作成する。ファイルが存在しない場合にはjava.io.FileNotFoundExceptionが発生する。Javaではコンストラクタ内での例外の呼び出しがされてもデストラクタ不在にようメモリリークはGCが存在するため発生しない。
import java.io.*;
class FileIO {
FileInputStream fis;
FileOutputStream fos;
FileIO(String input, String output)
throws Exception
{
fis = new FileInputStream(input);
fos = new FileOutputStream(output)
}
}
class ExceptionWithGC {
static public void main(String[] args) {
try {
FileIO fio = new FileIO(args[0], args[1]);
} catch (Exception e) {
System.out.println("Exception occurred");
System.out.println(e);
}
}
}
2.1.2.例 : プログラミングスタイル
文字列の拡張の例を挙げる。Javaでの文字列の拡張とCでの拡張の例を示す。
2.1.2.1.C
Figure 4.は標準入力から一行文字列を読み込むプログラムである。
このプログラムは一文字読み込んだ後バッファを拡張して、一文字追加していく。改行もしくはEOFに達したら、バッファからstrdupで文字列を複製し、その複製した文字列を返している。
Cのプログラムでは文字列への文字の追加と記憶領域の管理が分離できずに、本来の意味が薄れてしまっている。
#include <stdio.h>
#include <stdlib.h>
/* read line */
char *freadline(FILE* in)
{
char *buffer, *tmp;
int c;
buffer = malloc(1);
if (buffer == NULL) goto END;
buffer[0] = “\0”;
while ((c = fgetchar(in)) != EOF) {
tmp = realloc(buffer, strlen(buffer) + 2);
if (tmp == NULL) break;
buffer = tmp;
tmp = tmp + strlen(buffer);
*tmp++ = c;
*tmp = “\0”;
if (c == “\n”) break;
}
END:
return buffer;
}
int main(void)
{
char * line = readline(stdin);
printf(“%s”, line);
free(line);
}
2.1.2.2.Java
Figure 5.はFigure 4.をJavaで書き直したプログラムである。
一文字読み込むごとに可変の文字列に文字を追加していき、一行分読み込んだら可変長文字列から文字列へ変換を行って、文字列を返している。このプログラムのソースからはメモリ管理を行っている部分は隠蔽され、非常にわかりやすいソースコードとなっている。
class ReadLine {
static public String readline(InputStream is) {
StringBuilder sb = new StringBuilder();
int ch = 0;
while((ch = is.read()) != -1 || ch == '\n') {
sb.appned((char)ch);
}
return sb.toString();
}
static public void main(String [] args) {
Stirng line = ReadLine.readline(System.in);
System.out.println(line);
}
}
この例ではプログラムの記述性、可読性を重点に置いている。実際のプログラム開発ではプログラムの保守、拡張段階でこの二つの要素が大いに影響してくる。保守を行うには保守するプログラムの理解が必要となる。Figure 5.のように記憶領域の管理が隠蔽されていると、本来のプログラムの意味が理解しやすくなる。
この二つの例のとおり、GCを利用することによりプログラミングの手間が大幅に省かれ、GCのない言語処理系では行いにくい、目的の処理だけに注目したプログラミングも利用できるようになる。
また、メモリ管理をGCに一任することにより、文字列操作などで生じやすいプログラマのミスによる不正領域へのアクセス、利用中の領域の開放や領域の二重開放、メモリリークを軽減できることもできる。 これにより、メモリ管理用コードが必要なくなることによるソースコードの簡潔さの向上、メモリ関連のデバッグのコストの軽減など開発効率の向上が得られる。
2.2.ガベージコレクションの速度
一般的にmalloc/freeを利用した手動でのメモリ管理と比べGCの方が処理速度が遅いと考えられがちだがこれは間違いである。メモリ開放のコストが変化するのではなく、手動でメモリ管理を行いコストを分散するか、GCを利用して集中して行うかの差である。したがって、速度のよしあしは分散、集中によるメリットを比較するだけに依存する。
これとは別に、特定の条件下ではGCとmalloc/freeとでは速度の差が顕著に現れる例がある。
GCの速度がでる場合としてはmalloc/freeの実装に失敗していている場合がある。通常GCでは巨大な記憶領域を確保してその領域のうち必要な領域をGCが切り売りして管理を行う。そのためmalloc/freeの実装に左右されず一定の性能を得られる可能性が高い。
malloc/freeが早い例としては、大量の記憶領域を利用し、さらにその記憶領域のほとんどが利用される場合である。この場合、GCが発生する度に大量の記憶領域を走査しなければならない。この場合、malloc/freeで必要ない領域だけを開放する方法が速度が得られる。
このように、条件をそろえれば差は生じるが、双方とも実装の未熟さが原因にくるため、洗練された実装では差は生じないと考えることができる。
2.3.GCのアルゴリズム
GCの基本的なアルゴリズムは大きく分けて二つに分けられる。
- 参照カウント(Reference counting)
- Tracing collectors
2.3.1.参照カウント
参照カウント(Reference counting)はオブジェクト(動的に確保したメモリ領域の単位)が参照されている数を元に領域の開放を行うGCである。全てのオブジェクトに対して参照カウントと呼ばれる整数値を付加する。参照カウントはプログラム全体にこのオブジェクトを指し示すポインタがいくつ存在するかを記録するもので、変数の代入などによって変化する。そして、この参照カウントが0になった場合、つまり、どこからも参照されなくなった場合にそのオブジェクトを開放するというものである。
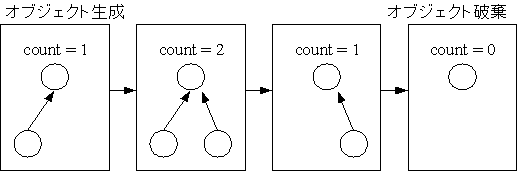
参照カウントの利点としては以下のことがあげられる。
- 処理が高速
- 手動の管理と同様に参照されなくなった時点で即座にオブジェクトの開放が行われる
- 記憶領域管理以外にも利用ができる(File、mutexなど)
逆に欠点としては、
- 整数値を付加するため領域のオーバーヘッドが生じる
- 参照カウントのオーバーフローを考慮する必要がある
- 循環参照が起こった場合に回収が行われない(Figure 7.)
などががある。
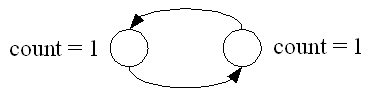
2.3.2.Tracing collectors
Tracing collectorsは次のような段階を含むGCで、一般的にGCと呼ばれているのはこちらのアルゴリズムである。
- 初期化(例、マークをはずす)
- トレース(例、マークもしくはコピー)
- 回収
- 確保した領域の再利用
Tracing collectorsは名前のとおりオブジェクトに含まれるポインタをトレースして利用しているオブジェクト、していないオブジェクトを判別する。このとき、トレースのはじめとなるオブジェクトをルート(Root)と呼び、到達できたオブジェクトはプログラムが利用中のオブジェクト、到達できなかったオブジェクトはごみとみなし回収を行う。したがって、アルゴリズムの回収段階では確保した全てのオブジェクトに何らかの方法でアクセスできる必要がある。
トレースのアルゴリズムにはマークアンドスイープ(Mark and Sweep)、コピー(Copying)という二つの方法が存在する。
2.3.2.1.マークアンドスイープ
マークアンドスイープはトレース段階と回収段階が明確に分かれたアルゴリズムである。
アルゴリズム1のトレース段階ではルートから到達できるオブジェクトに印をつけていく。
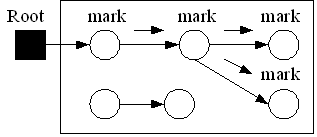
アルゴリズム1の回収段階では、全てのオブジェクトを調べマークのついていないオブジェクトを回収する。
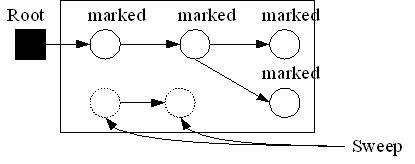
マークアンドスウィープGCの利点としては以下のことがあげられる。
- 実装が容易である
- オブジェクトがあまり回収されない場合にコピーGCと比べて性能がよい
- 循環参照が起こったオブジェクトでも回収が行える
欠点としては、
- 必要ない部分から回収を行うため領域の断片化が生じる
- 管理する記憶領域の量に応じて性能が劣化する
などがある。
本論文ではこのマークアンドスイープの派生である保守的マークアンドスイープを利用している。保守的マークアンドスイープについては処理系の実装の項で再度取り上げる。
2.3.2.2.コピー
コピーは領域を半分にしてGCを行うアルゴリズムである。
アルゴリズム1のトレース段階ではルートから到達できるオブジェクトを新しい領域にコピーしていく。トレースが終わり、利用中の全てのオブジェクトを新しい領域にコピーできたら、古い領域全てを破棄する(アルゴリズム1の回収段階)。
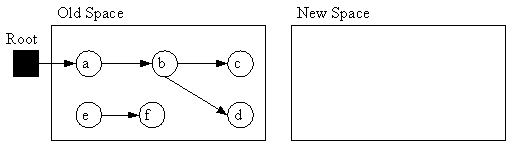
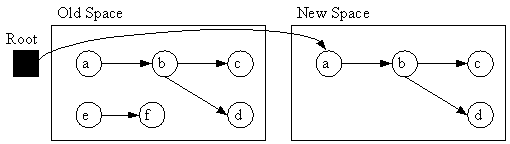
オブジェクトを移動させるため、ポインタの付け替えを行うか、プログラム内ではポインタとは別のIDを用いる必要がある。
コピーGCの利点としては以下のことがあげられる。
- 回収段階がほとんどないためマークアンドスイープGCと比べ高速
- 隙間を詰めてコピーを行うため領域の断片化が発生しない
- 循環参照が起こったオブジェクトでも回収が行える
欠点としては、
- コピーを行ったオブジェクトのポインタの付け替えが必要(Figure 11.)
- ポインタ以外のIDを用いての管理が必要
- ごみとなる領域が極端に少ない場合性能が劣化する
などがある。
2.4.正確 vs 保守的
利用しているオブジェクトをたどる方法とは別に、利用しているオブジェクトの判定法について正確なGC(precise GC)と保守的GC(conservative GC)という区別がある。
正確なGCは、利用中のオブジェクトを正確に求め、利用していないオブジェクトを全て回収するGCである。通常GCといえば正確なGCを示す。
保守的GCは利用中らしき曖昧なオブジェクトは保持して回収を行わないGCである。具体的にはオブジェクトのルートに管理するオブジェクトの領域(ヒープなど)をさすポインタがに含まれた場合には、そのポインタがさすオブジェクトの回収は行わないなどの方針を採る。結果として本来ゴミであるオブジェクトを保持してしまうが、このオブジェクトは無効なポインタをさすことはないので若干のメモリリークが生じるが、単純な割りに安全である。通常ルートはレジスタ、スタック、大域領域、ヒープ領域などがあるが、これら全てが曖昧として保守的GCを行う場合を特に全保守(fully conservative)、一部を曖昧として行う場合を半保守(partially conservative)という。
保守的と正確という考え方は記憶領域をマークする方針であるため、具体的なアルゴリズムは規定しない。
保守的GCはマークアンドスイープGCと組み合わせて利用されることが多い。また、本来GCをサポートしないCなどの言語での実装が容易であるため、Rubyなどの言語処理系ではこの保守的マークアンドスイープGCが利用されている。
3.Lisp
本研究ではさまざまなGCの効率を調べるためにプログラミング言語を作り、GCを実装する。そしてベンチマークテストによって比較を行う。そこで、GCの性能が反映されやすく実装がやさしい構造をもつLISP言語を選んだ。
LISP(LISt Processingの略)は1958年にジョン・マッカーシーによって発明されたプログラミング言語である。ラムダ演算の計算モデルを紙の上で表現するための記法をFORTRANの上に移植することにより初のLISPインタプリタが誕生した。
現在LISPはCommon LispとSchemeという二つの方言が主流であるが、ここではLISP全てに当てはまる話題を取り上げる。
3.1.特徴とプログラムの例
3.1.1.Atom
LISPで扱うデータの中で、値そのものを示すデータをAtomと呼ぶ。Atomには名前をあらわすシンボル(Symbol)、真偽値、数値を表す数字そのもの、文字列、関数をあらわすプロシージャ(Procedure)などが含まれる。
AtomはLISPプログラムに直接リテラルとして記述できるもの(数値、文字列等)や、LISPの式を実行した結果として得られるもの(シンボル、プロシージャ)、その他LISP処理系の拡張で用意されたデータ構造などが含まれる。
| リテラルもしくは式 | 実行した結果 | Atomの種類 |
|---|---|---|
| 10 | 10 | 数値 |
| "the string" | "the string" | 文字列 |
| 'symbol | symbol | シンボル |
| (quote symbol) | symbol | シンボル |
| (lambda (x) x) | procedure(何らかの内部表現) | プロシージャ |
3.1.2.Cons Cell
LISPにはもうひとつCons Cell(もしくはPair)と呼ぶデータが存在する。Cons Cellは二つのデータをまとめるデータである。Cons Cellの先頭をCar(カー)、最後をCdr(クダー)と呼ぶ。Car、CdrはAtom、 Cons Cellどちらのデータも示すことができる。
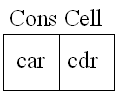
AとBのCons(もしくはPair)と言った場合、CarがAを、CdrがBを示すCons Cellのことを言う。Cons Cellを作成することをconsすると言う。
3.1.3.S式
LISPはプログラムの記述法にS式(Symbol-Expression)と呼ばれる記述方式を採用している。S式は次のように定義される。
S式 ::= Atom S式 ::= S式とS式のCons
S式はAtomを含むがconsされているものはAtomではない。S式を記述する場合、リテラル表記できるAtomはそのまま記述し、Cons Cellはドット対(A . B)のように表記する。AがCar、BがCdrにあたる。
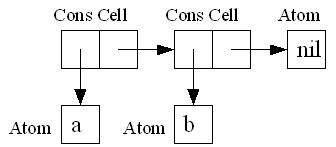
LISPではCons Cellをドット対で表現したS式よりも次のように連続する". ("と対応する")"を省略したリスト表記を主に利用する。リスト表記されたS式のうち、(<S式> ... <S式 n>)という形になっているものをリストと呼び、リストの最後がドット対になっているものをドットリストと呼ぶ。
| S式 | リスト表記 | 種類 |
|---|---|---|
| (a . b) | (a . b) | ドットリスト |
| (a . (b . c)) | (a b .c) | ドットリスト |
| (a . (b . ())) | (a b) | リスト |
| ((a . b) . (c . (d . e))) | ((a . b) c d . e) | ドットリスト |
| ((a . b) . (c . (d . ()))) | ((a . b) c d) | リスト |
| ((a . (b . ())) . (c . (d . ()))) | ((a b) c d) | リスト |
特別な例としては、何もないリストをnil(Common Lispでの表現。ニル)や()(Schemeでの表現。空リスト)などで表す。nilや()はAtomでもある。
3.1.4.プログラム
LISPではS式(リストやAtom)を式として評価(Eval)していく。評価とは式から値を求めることを言う。LISPでは式の種類に応じて次のように評価を行う。
| 式の種類 | 評価の方法 |
|---|---|
| リスト | (<関数> <引数> ... <引数>)のような関数呼び出しとみなして評価する。 |
| シンボル | シンボルに対応付けられた値を取り出す。 |
| シンボル以外のAtom | Atom自身を返す。 |
関数には引数を全ては評価しない特殊形式(special form, macro)と引数を全て評価するプロシージャの二種類が存在する。関数に引数を渡して値を求めることを引数を関数に適応(apply)する、もしくは単に適応すると言う。
3.1.4.1.特殊形式
代表的な特殊形式にはquote、set!、cond、lambdaなどが存在する。構文(syntax)とも呼ばれる。
3.1.4.1.1.quote
quote引数を評価せずにそのまま返す特殊形式である。引数を一つとる。リストをデータ構造として扱いたい場合、シンボル自体を取り出したい場合などに利用する。'(クオート)を利用した省略記法をサポートするLISP処理系も多い。
(quote 10) ; =>10
(quote a) ; => a
(quote (this is the list)) :=> (this is the list)
'symbol ; => symbol
'(another list) ; => (another list)3.1.4.1.2.set!
set!はシンボルに値を対応付ける特殊形式である。二引数をとる。第一引数はシンボルをとり、第二引数の評価した値を第一引数のシンボルに対応付ける。なおLISPでは値をシンボルに対応付けることを束縛するという。
(set! a 10)
a ; => 10
(set! b '(the list))
b ;=> (the list)3.1.4.1.3.cond
condは分岐を表す特殊形式である。複数の引数をとり、引数の構造は次のようになっている必要がある。
(cond <condition clause1> <condition clause> ...)
<condition clause n> := (<condition> <expression> ...)condでは<condition clause>を順番に評価していく。<condition clause>のうち、<condition>を評価して真を示す値であれば続く<expression>を順番に評価し、<condition>が偽を示す値であれば続く<expression>を評価せずに次の<condition clause>を評価する。
最後の<condition clause>の<test>はelseなどの特別なシンボルが使われる場合も許されており、その場合は無条件で続く<expression>が評価される。
(set! a 10)
(cond ((<= 1 a) 1)
((= 0 a) 0)
(else -1)) ; => 1
(set! b -1)
(cond ((<= 1 b) 1)
((= 0 b) 0)
(else -1)) ; => -13.1.4.1.4.lambda
lambdaはプロシージャを作る特殊形式である。第一引数にはプロシージャの引数のリストを、第二引数以降にはプロシージャの中身を記述する。プロシージャを呼び出した場合は、中身のうち一番最後に評価した式の値を返す。lambda式とも言う。
(lambda (x) x) ; => procedure
(set! identity (lambda (x) x))
(identity 10) ; => 10
((lambda (x y) (+ x y)) 10 20) ; => 30
((lambda (x y) x (+ x y) y) 10 20) ; => 203.1.4.1.5.プロシージャ
プロシージャは特殊形式とは異なり引数の評価を行ってから関数の値を求める関数のことである。プロシージャには大きく分けてCons Cellを作成するcons、四則演算の+や*、比較関数<といった言語処理系に組み込まれている組み込みプロシージャと、プログラマがlambda式で作成した自作プロシージャの二つの種類が存在する。
プロシージャでは全ての引数を評価してから関数の評価を行うため、特殊形式と異なり構文ではない。LISPには特殊形式とプロシージャの二種類の関数しか存在しないともいえる。
(set! a 10)
(cons 'a 'b) ; => (a . b)
(cons a (cons 'b nil)) ; => (10 b)
(* a 4) ; => 40
(< a 2) ; => 偽を表す値(nil、#fなど)
(+ a (* 3 4)) ; => 22
(set! add-1 ((lambda (x) (lambda (y) (+ x y))) 1))
(add-1 10) ; => 113.1.5.環境
LISPではC言語などで言うスコープを環境と呼び、また一番外側の環境をトップレベル(Top-Level)と呼ぶ。LISPではlambdaで作成するプロシージャのみが新しい環境を作成する。
プロシージャは作成されたときの環境を持ち、プロシージャが持つ仮引数と、実引数を束縛する時、つまり評価する時に作成されたときの環境を拡張する形で新しい環境を作成する。
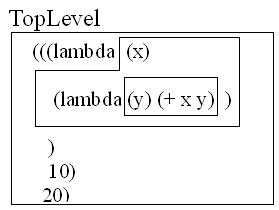
現在のLISPではスタティックスコープが採用されているが、スタティックスコープは定義された時の環境をプロシージャが保存することにより実現している。Figure 23のxやyなど、トップレベル以外に定義されているlambdaの仮引数となっている変数をレキシカル変数と呼ぶ。
レキシカル変数xは(lambda (y) (+ x y))が作成するプロシージャが破棄されるまでプロシージャの中で半永久的に利用できるが、このようにレキシカル変数を利用しているプロシージャを特にクロージャと呼ぶ。
3.2.LISPとGC
GCはLISPと同時に誕生した機構である。LISPではプログラムを読み込み、リストを作成し、そのリストを評価してプログラムを実行する。評価した後のリストや、評価で利用した一時領域はごみとなるが、LISPではプログラマが明示的にメモリを確保、開放する方法は用意されていないためこれらのごみはいずれは計算機の資源を食いつくしてしまう。しかし、このリストを構成するCons CellやAtomはごみとなっても再利用が可能であるので再利用を行う。
LISP以外のインタプリタの言語処理系も同様にプログラムを読み込み、実行する際に言語特有のデータ構造(文字列、ファイルポインタ、構文木など)を作成する。ここで構文木とは与えられたプログラムを解釈するためにインタプリタが一時領域に作るデータ構造である。名前を変数、配列、関数、型と区別したり、かっこが無くても演算子の優先順位を理解して数式の解釈したりする。
構文木はLISPはすでに示したようにかっこの木構造のみで構文が規定されるため、多言語と違い構文解釈はかっこ表示を内部リスト構造に変換するだけである、つまり構文木はリストに、構文木を構成するデータ構造がCons Cell、要素がAtomに相当する。LISPと同様にインタプリタの言語処理系を利用する場合には構文木を管理する必要がある。この管理にしばしばGCが利用される。
リスト、構文木はプログラマが直接管理を行うことも可能な場合がある。しかし、その場合は言語処理系の内部に手を加えることになり言語処理系をして抽象度を向上させる目的と反してしまう。
このように、抽象度の高いインタプリタの言語処理系を利用して抽象度の高いプログラムを作成する場合にはGCは必須の機能となっている。
4.GC付属LISP処理系
本論文ではGC付属のLISP処理系の作成する。LISP処理系の仕様はSchemeのサブセットとする。処理系の構造には古典的なS式のインタプリタ(解釈系)、GCのアルゴリズムには保守的Mark and Sweepを採用する。
4.1.LISP処理系の構造
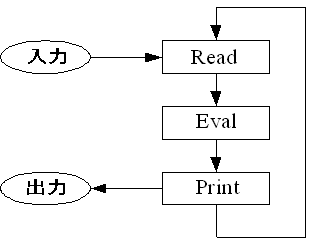
古典的なS式のインタプリタとしてのLISP処理系を作成する場合に肝となる機能はread-eval-print-loop(replと略す)とGCである。このreplはその名のとおり、入力を読み取り、評価(evalute)し、出力することを繰り返す機構である。
readを行うreaderは文字列としてのS式を読み取り、LISP処理系の内部表現としてのS式(リスト)を組み立てる。evalはreaderが作り出したリストを解釈しプログラムを実行する。printは実行結果を目に見える形で出力する。
4.2.作成言語
本研究ではGCを実装することもあり、あらかじめGCが搭載されたプログラミング言語ではなくC言語によって作成を行った。C++言語を採用しなかった理由は、保守的GCとインスタンスのファイナライザの協調を行うことにより、本質でない部分に注意をそそがれてしまうのを防ぐためである。
4.3.作成
本研究で作成したLISP処理系(以下処理系)の解説を行う。
4.3.1.データ構造
作成した処理系全体で利用するデータ構造はscheme.hで定義している。古典的なLISP処理系ではCellと呼ばれる複数のデータ構造をunionでまとめたメンバとそのunionを識別するメンバを持つデータ構造を利用するのが主流である。
Cellがもつunionでまとめたメンバのデータ構造にはS式の項で述べたcons(Cellのポインタを二つ持つデータ構造)とatomを含む。今回作成する処理系のatomはsymbol、integer、 primitive、closure、macroである。
CellにLISP処理系で利用するデータ構造を詰め込む理由には、Cellというひとつのデータ構造で処理系で利用するS式を全て表現できることの他に、データのサイズを一定にし、GCでのメモリ領域の断片化を防ぐ意味も含まれてる。
作成した処理系ではCellはSCMという名前にtypedefしている
typedef struct _Cell* SCM; /* scheme cell object interface */
struct _Cell {
struct _Header {
enum SchemeCellType type;
short gc_flag;
} header; /* cell header */
union {
struct _Cons {
SCM car;
SCM cdr;
} cons;
struct _Integer {
int value;
} integer;
struct _Symbol {
char *name;
int length;
SCM value;
} symbol;
struct _Primitive {
enum PrimitiveType type;
char *name;
SCM (*proc)();
} primitive;
struct _Closure {
SCM args;
SCM body;
SCM env;
} closure;
struct _Macro {
SCM closure;
} macro;
/* more ... */
} object; /* cell object */
};なおCellのための記憶領域の確保にはGCが深くかかわってる来る。現段階では特別な管理せずにmallocのみで済ませる。Cellの確保についてはGCの項(4.4.1)で詳しく述べる。
4.3.2.シンボルテーブル
シンボルというデータ構造はscheme.hで、シンボル、シンボルテーブルとその操作を行う関数はsymbol.cにて定義している。
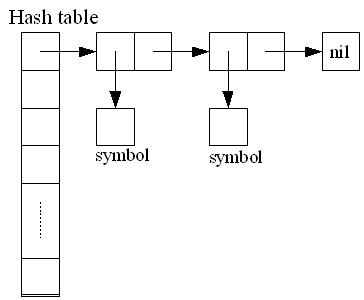
シンボルとはLISPのatomで名前をつかさどるデータ構造である。同じ名前を持つシンボルは常に同じオブジェクトを利用すること、つまり同じシンボルは同じアドレスを持つことがLISP処理系では求められる。これを実現するためにシンボルテーブルを利用する。本処理系ではシンボルテーブルはチェインハッシュで実現している。シンボルは名前(文字列)から求める。はじめに名前のハッシュ値を求め、チェインハッシュの位置を決定する。次にS式と同様にCons Cellを利用している線形リストをたどり、文字列と同様の名前を持つシンボルを求める。名前に対応するシンボルが存在しない場合は新たにシンボルを作成してシンボルテーブルに追加を行う。
名前からシンボルを求めることをinternと呼ぶ。
4.3.3.reader
readerはread.cに定義している。S式を読み取りCellを利用してリストを作成する。
読み込めるS式の字句解析についてはR5RS[1]を参考に作成した。再帰降下型のパーサとなっている。 このreaderが生成するリストは通常primitive、closure、macroなどのを含まないCellだけでできたものを返す。primitive、closure、macroなどは4.3.5で説明するevalにて、symbolに束縛された値を取り出したり、関数を実行することにより作成するのが常である。
4.3.4.print
printはprint.cに定義している。
printはS式を表示するための機構である。printの本体は巨大なif-else文である。引数として与えられたS式の要素にあわせて印字を行う。要素がAtomの場合はprintがそのAtomに対応する印字を行う。 要素がCons Cellリストの表示の場合はpirntはprint_listに役割を譲渡する(Figure 27. (1))。
print_listはCons Cellをたどりそれぞれの要素を引数にprintをよびだし、リストの表示を行う(Figure 28. (1))。
SCM print(SCM sexp, FILE *file)
{
if (SCM_CONSTANT_P(sexp)) {
switch(AS_UINT(sexp)) {
case AS_UINT(SCM_NULL): fprintf(file, "()"); break;
case AS_UINT(SCM_FALSE): fprintf(file, "#f"); break;
case AS_UINT(SCM_TRUE): fprintf(file, "#t"); break;
case AS_UINT(SCM_EOF): fprintf(file, "#eof"); break;
case AS_UINT(SCM_UNDEFINED):
fprintf(file, "#undefined"); break;
default:
scheme_error("bad constant"); break;
}
return SCM_UNDEFINED;
}
if (SYMBOL_P(sexp)) {
fprintf(file, "%s", SYMBOL_NAME(sexp));
} else if (INTEGER_P(sexp)) {
fprintf(file, "%d", INTEGER_VALUE(sexp));
} else if (STRING_P(sexp)) {
fprintf(file, "\"%s\"", STRING_VALUE(sexp));
} else if (CONS_P(sexp)) {
print_list(sexp, file); /* (1) */
} else if (PRIMITIVE_P(sexp)) {
fprintf(file, "#<primitive %s>", PRIMITIVE_NAME(sexp));
} else if (CLOSURE_P(sexp)) {
fprintf(file, "#<closure>");
print(CLOSURE_ARGS(sexp), file);
print(CLOSURE_BODY(sexp), file);
} else if (MACRO_P(sexp)) {
fprintf(file, "#<macro>");
print(MACRO_CLOSURE(sexp), file);
} else {
printf("print unsupported: %p", sexp);
}
return SCM_UNDEFINED;
}static SCM print_list(SCM sexp, FILE *file)
{
SCM lst = sexp;
putc('(', file);
for(;;) {
print(CAR(lst), file);
lst = CDR(lst);
if (NULL_P(lst)) break;
else if (CONS_P(lst)) putc(' ', file);
else { fprintf(file, " . "); print(lst, file); break;} /* (1) */
}
putc(')', file);
return SCM_NULL;
}4.3.5.環境
環境についての実装はenv.cに定義している。evalでプログラムを評価する際に変数の値を取り出す先が環境である。そのため環境はスコープと等価であるともいえる。
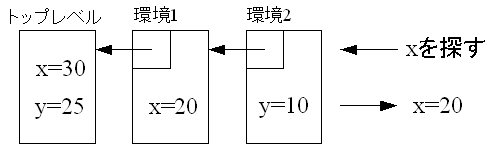
一番外側の環境はトップレベルと呼ばれLISP処理系の中でグローバルなものである。トップレベルではシンボルと値が一対一の関係となるため、シンボルそのものと値を関連付けることによりトップレベル環境を実現する。トップレベル以外の環境については、Figure 30.のようにシンボルと値のリストのペアをリストとして持つことにより実現する。新しい環境はlambda式でプロシージャを作成するときに作成される。
environment = ((var1 var2 var3 ...)
(val1 val2 val3 ...))
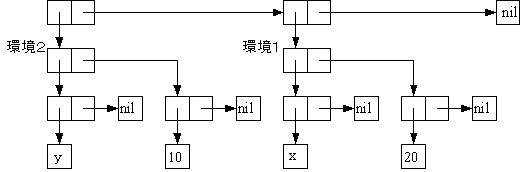
environments = (environmentN environmentN-1 ... )環境の例をFigure 31.に、そのときの環境のリスト表記をFigure 32.に、AtomとCons Cellを用いたデータ構造をFigure 33.に示す。(lambda (x) ...)が作り出す環境を環境1、(lambda (y) ... )が作り出す環境を環境2とする。この例では環境1にてxが20に対応付けられ、環境2にてyが10に対応付けされる。この環境下で(+ x y)の評価を行うと式は(+ 20 10)となり、30が得られる。
( ((y) . (10)) // 環境2
((x) . (20)) // 環境1
)
4.3.6.Static scope
スタティックスコープ(Static scope)とは4.3.5で示した環境を使って変数の値を取り出す方法である。3.1.5でも示したとおり、スタティックスコープでは複数の環境で同様の変数が使われていた場合は、式に一番近い環境の値を利用する。また、スタティックスコープはlambda式の様に定義したときの環境を保存するので、プロシージャの中身では、定義したときの環境の変数が利用できる。SchemeがLISP処理系としてはじめてスタティックスコープを採用して以来、現在ではスタティックスコープが主流である。
これとは異なり、初期のLISPはダイナミックスコープを採用していた。lambda式でプロシージャはただのコードの断片として扱い、定義した時の環境を保存せず、適応した時の環境の変数を利用していた。
本処理系ではスタティックスコープを実現するために、lambda式が作り出すプロシージャが環境を保存する。プロシージャが環境を保存することにより、処理系全体の動作をスタティックスコープにすることができる。
4.3.7.評価
evalとapplyはeval.cに定義している。処理系の心臓部分である。readerが作成したリストを解釈、評価(evaluation)、関数の適応(apply)を行う。3.1.4のFigure 17.を再度示す。
| 式の種類 | 評価の方法 |
|---|---|
| リスト | (<関数> <引数> ... <引数>)のような関数呼び出しとみなして評価する。 |
| シンボル | シンボルに対応付けられた値を取り出す。 |
| シンボル以外のAtom | Atom自身を返す。 |
evalでは数値のような即値やシンボルに束縛された値を取り出したりする(Figure 35. (1),(2))。
また、リストの先頭のatomを評価したときの値が関数として実行するが、この関数を引数に適応させるにはapplyを利用する(Figure 35. (3))。applyはその中でapply_primitive(Figure 36.)とapply_closure(Figure 37.)を呼び出す。これらの関数の中でさらにevalが呼び出される。evalとapplyは相互再帰呼び出しを行いながらプログラムを実行する。
SCM eval(SCM sexp, SCM env)
{
SCM kar = SCM_NULL;
SCM result = NULL;
struct EvalState state = { env, EVAL_STATUS_RETURN_VALUE};
eval_loop:
set_current_sexp(sexp);
if (SYMBOL_P(sexp)) return symbol_value(sexp, state.env); /* (2) */
if (! CONS_P(sexp)) return sexp; /* (1) */
if (CONS_P(sexp)) {
SCM subr;
state.status = EVAL_STATUS_RETURN_VALUE;
kar = CAR(sexp);
if (SYMBOL_P(kar)) { subr = symbol_value(kar, state.env); }
else if (CONS_P(kar)) { subr = eval(kar, state.env); }
result = apply(subr, CDR(sexp), &state, SCM_TRUE); /* (3) */
sexp = result;
if (state.status == EVAL_STATUS_NEED_EVAL) {
goto eval_loop;
}
}
return sexp;
}static SCM apply(SCM subr, SCM arg, struct EvalState *state, SCM need_argument_eval)
{
if (PRIMITIVE_P(subr)) {
return apply_primitive(subr, arg, state, need_argument_eval);
} else if (CLOSURE_P(subr)) {
return apply_closure(subr, arg, state, need_argument_eval);
}/* ... */ else {
scheme_error("subroutine type error");
return NULL;
}
}static SCM apply_closure(SCM closure, SCM arg, struct EvalState *state, SCM need_argument_eval)
{
SCM closure_env = NULL;
SCM result = SCM_NULL;
SCM evaled_arg = SCM_NULL;
SCM body = CLOSURE_BODY(closure);
if (length(CLOSURE_ARGS(closure)) > length(arg)) {
scheme_error("argument error");
}
if (FALSE_P(need_argument_eval) ) { evaled_arg = arg; }
else { evaled_arg = eval_list(arg, state->env); }
closure_env = extend_environment(CLOSURE_ARGS(closure), evaled_arg, CLOSURE_ENV(closure));
while (! NULL_P(body)) {
// need_argument_evalで末尾再帰 /* (1) */
if (LIST_1_P(body) && FALSE_P(need_argument_eval)) {
state->status = EVAL_STATUS_NEED_EVAL;
state->env=closure_env;
result = CAR(body);
break;
}
result = eval(CAR(body), closure_env);
body = CDR(body);
}
return result;
}static SCM apply_primitive(SCM subr, SCM arg, struct EvalState *state, SCM need_argument_eval)
{
if (SPECIAL_FORM_P(subr)) {
return PRIMITIVE_PROC(subr)(arg, state);
} else if (LIST_EXPR_P(subr)) {
SCM evaled_arg;
if (FALSE_P(need_argument_eval) ) { evaled_arg = arg;
} else { evaled_arg = eval_list(arg, state->env); }
return PRIMITIVE_PROC(subr)(evaled_arg);
} else {
SCM result, evaled_arg;
if (FALSE_P(need_argument_eval) ) { evaled_arg = arg;
} else { evaled_arg = eval_list(arg, state->env); }
switch(PRIMITIVE_TYPE(subr)) {
case PRIMITIVE_TYPE_EXPR_0:
if (length(arg) != 0) goto ARG_ERROR;
result = PRIMITIVE_PROC(subr)();
break;
/* ... */
case PRIMITIVE_TYPE_EXPR_4:
if (length(arg) != 4) goto ARG_ERROR;
result = PRIMITIVE_PROC(subr)(CAR(evaled_arg),
CADR(evaled_arg), CADDR(evaled_arg), CAR(CDDDR(evaled_arg)));
case PRIMITIVE_TYPE_EXPR_5:
if (length(arg) != 5) goto ARG_ERROR;
default:
return SCM_NULL;
}
return result;
ARG_ERROR:
scheme_error("eval unsupported :");
}
return SCM_NULL;
}4.3.8.末尾再帰の最適化
Lisp方言Schemeでは、末尾再起の最適化が言語使用として含まれており、最適化のためのアルゴリズムはこのeval、applyに記述する。
コンパイルしてVMやCPUで実行する処理系などでは、再起をループに変換する一般的なアルゴリズムが採用できる。しかし、今回作成する処理系のようにS式を直接解釈し、再起にネイティブスタックを利用する処理系ではこの方法は利用できない。
よって、今回の最適化には、SIODなど古い処理系で採用されている方法を利用する。アルゴリズムは、最後に評価するリストをいったんevalに返し、そのリストを再度evalすることによって実現する(Figure 38. (1))。Figure 39.はこのアルゴリズムのスケッチである。
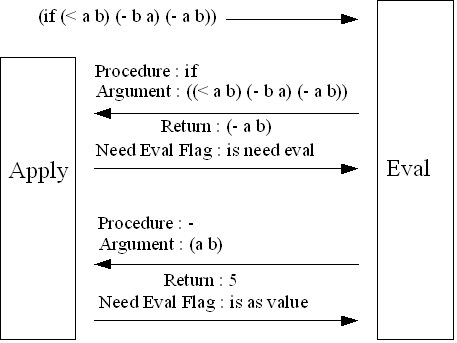
リストの再評価は評価が必要かどうかのフラグで管理する。フラグが値を示す場合(Figure39,40.ではis as value、プログラムではEVAL_STATUS_RETURN_VALUE)の場合はapply関数の戻り値は値とみなしそのまま、eval関数の戻り値とし、再評価を示す場合(Figure 39,40.の場合はis need eval、プログラムではEVAL_STATUS_NEED_EVAL)の場合は再評価を行う。
この再評価の環境は最後のリストを評価する時の環境と一致している必要があるため、何らかの方法で利用する環境を新しい環境に更新する必要がある。今回作成した処理系ではeval関数の引数には環境を持たせeval関数からいったん戻す前に環境を更新している(Figure 40.)。
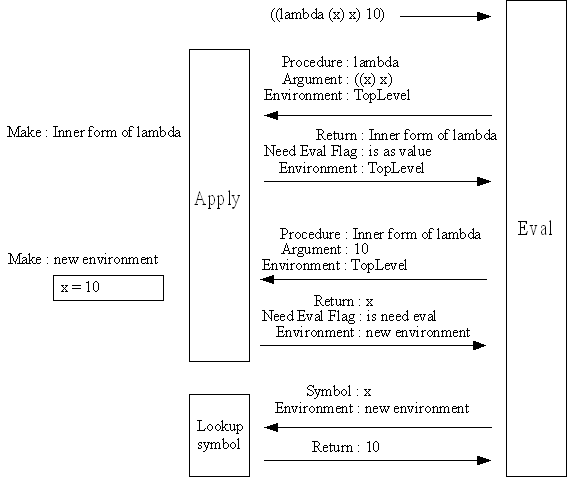
LISP処理系全体が末尾再帰の最適化に対応するには、特殊形式全てとプロシージャで末尾再帰の最適化を行うように変更すればよい。これは、LISPのプログラムは最終的には特殊形式とプロシージャの二つの関数の実行に簡約されるからである。
4.4.GCの制作
4.3.1で説明したようにCellの確保に関しては本節で説明する。具体的にはalloc.cにおいてCellの確保とGCを行う手続きを記述する。なおGCには保守的マークアンドスウィープGCを使用する。
4.4.1.Cell allocator
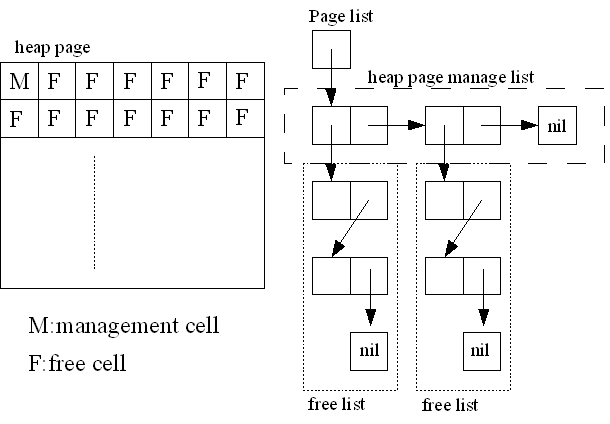
GCでは動的に確保したデータを全て管理する必要がある。そのため、GCを利用する場合にはGCに対応した専用のメモリアロケータを作成しそのアロケータを利用する必要がる。そのためCellを確保する専用のアロケータを定義する。
このCellアロケータは一度に大量のヒープを確保してCellの単位で切り売りする仕組みを実装してある。ヒープの最初の要素を各ヒープページとfree Cellの管理に利用している。
Cellアロケータではfree Cellの残り総数が0になるとまずGCでCellを回収する。その後free Cellが一定以上回収できなかった場合、mallocでヒープを追加確保して、free Cellを追加する。
4.4.2.マークアンドスイープ
GCの実装には保守的マークアンドスウィープを利用する。保守的なGCの実装法については次の章で説明を行い、ここではその基礎であるマークアンドスウィープの実装について説明を行う。
マークアンドスウィープGCとは次の二段階のアルゴリズムを利用するGCである。
- 全ての使われているCellにマークをする。
- マークの付いていないCellを回収する。
以下のその動作を詳しく説明していく。
マークアンドスウィープでマークを行う始点となるオブジェクトをRootとよぶ。LISP処理系でのRootとなるオブジェクトは値が束縛されているシンボル、グローバル変数に代入されたCell、そして保守的GCの対象となるマシンスタックとレジスタにあるCellである。GCではまずこれらRootを走査し、走査できる全てのオブジェクトにマークをつけていく。走査の次はマークのついていないオブジェクトの回収を行う。そして、回収できたオブジェクトの総数に応じてヒープの拡張を行う。
static void scheme_gc(void)
{
int collect_cells;
gc_mark_stack();
gc_mark_symbol_table();
/* ... */
collect_cells = gc_sweep();
/* ... */
if (collect_cells < 600) {
add_heap();
}
current_search_page = page_list;
}オブジェクトのマークを行うgc_mark_objectではRootとなるオブジェクトを基準に再帰的にリストをたどりオブジェクトにマークしていく。ここでいうオブジェクトはCellのことである。定数やすでにマークがついているオブジェクトはそれ以上走査しないようにはじいている(Figure 43. (1))。また、Cellの中の型にあわせて次のオブジェクトへの走査の方法を変えている(Figure 43. (2))。さらに次に走査するオブジェクトがひとつになった場合はgoto分で末尾再起の最適化を行い、スタックの消費を抑えている(Figure 43. (3))。
オブジェクトの回収を行うgc_sweepでは各ヒープページを全て走査し、マークのついていないCellをFreelistに追加する(Figure 44. (1))。マークのついているCellはマークを外して、次回の回収に備えている(Figure 44. (2))。
static void gc_mark_object(SCM obj)
{
loop:
if (obj == NULL) return;
/* (1) */
if (SCM_CONSTANT_P(obj)) return ; /* scm constant is not marking */
if (FREE_CELL_P(obj)) return ; /* free cell is not marking */
if (GC_MARK_P(obj)) return ; /* already marked. */
GC_MARK(obj);
/* (2) */
if (CONS_P(obj)) {
gc_mark_object(CAR(obj));
obj = CDR(obj);
goto loop; /* (3) */
} else if (INTEGER_P(obj)) {
return ;
} else if (SYMBOL_P(obj)) {
gc_mark_object(SYMBOL_VCELL(obj));
} else if (STRING_P(obj)) {
return ;
} else if (PRIMITIVE_P(obj)) {
return ;
} else if (CLOSURE_P(obj)) {
gc_mark_object(CLOSURE_ARGS(obj));
gc_mark_object(CLOSURE_BODY(obj));
obj = CLOSURE_ENV(obj);
goto loop; /* (3) */
} else if (MACRO_P(obj)) {
obj = MACRO_CLOSURE(obj);
goto loop; /* (3) */
}
}static int gc_sweep(void) {
SCM page = page_list;
int collect = 0;
gc_sweep_symbol_table_free_cell_remove();
while(page != NULL) {
SCM cell = page;
SCM last_cell = page + ALLOCATE_HEAP_PAGE_OBJECT_SIZE - 1;
while (AS_UINT(cell) <= AS_UINT(last_cell)) {
if (FREE_CELL_P(cell)) { /* through */
} else if (GC_MARK_P(cell)) {
if (! GC_FOREVER_MARK_P(cell)) { GC_UNMARK(cell); } /* (2) */
} else { /* unmarked */ /* (1) */
cell_finalize(cell);
int cell_index = 0;
if (PAGES_FREE_CELL_LIST(page) != NULL) {
cell_index = AS_UINT(FREE_CELL_INDEX(PAGES_FREE_CELL_LIST(page)));
}
cell_index++;
FREE_CELL_CONSTRUCT(cell, AS_SCM(cell_index), PAGES_FREE_CELL_LIST(page));
PAGES_FREE_CELL_LIST(page) = cell;
free_cell_total_size++;
collect++;
}
cell++;
}
page = NEXT_PAGE(page);
}
return collect;
}4.4.3.保守的GCの方法
保守的なGCとはスタックアドレスの中身などが、ヒープに確保したGCの管理下にあるオブジェクトをさしている場合に、そのオブジェクトが利用中であると考えGCを行う方法である。正確なGCとは異なり、利用中のオブジェクトらしきものは回収を行わないため保守的と呼ばれる。
C言語などでスタックの底のアドレスを得るに、LISPを行うプログラムの先頭でローカル変数を宣言する。このローカル変数のアドレスをスタックの底のアドレスとする。
#define SCHEME_STACK_INITIALIZE \
SCM __dummy_scheme_stack_start_object; \
stack_initialize(&__dummy_scheme_stack_start_object)int main(int argc, char **argv) {
{
SCHEME_STACK_INITIALIZE;
scheme_initialize();
read_eval_print_loop();
scheme_finalize();
exit(EXIT_SUCCESS);
}
}次にスタックの先端のアドレスの確保するために、スタックのGCを行うコードの直前、変数宣言の最後にスタックの先端のアドレスの確保するためのローカル変数を宣言する。このローカル変数のアドレスをスタックの先端のアドレスとする。
スタックアドレスはこれで取得できたので次にレジスタの内容の保存を行う(Figure 47. (1))。レジスタの内容を保存するにはC言語の標準ライブラリのsetjmpを利用する。jmp_bufをスタックの先端のアドレスの確保するためのローカル変数の前に宣言する。確保したjmp_bufに対してsetjmp関数を実行し、レジスタの中身をjmp_bufに保存する(Figure 47. (2))。
最後にこれらの情報からマシンスタックの範囲を求め、その領域の値がGCが管理しているヒープのアドレスだった場合gc_mark_objectを実行する。
static void gc_mark_stack(void) {
jmp_buf save_register_for_gc_mark;
void *start;
void *end;
int i;
void *end_of_stack;
/* (2) register value dump */
setjmp(save_register_for_gc_mark);
/* (1) スタックの先端を記録 */
SCHEME_SET_STACK_END(&end_of_stack);
if (AS_UINT(stack_start) < AS_UINT(stack_end)) {
start = stack_start; end = stack_end;
} else {
start = stack_end; end = stack_start;
}
/* 保守的GCを行う */
for (i = 0; i < sizeof(void *); i++) { gc_mark_memory(start, end, i); }
return ;
}static void gc_mark_memory(void *start, void *end, int offset) {
SCM *obj;
for (obj = (SCM *) (char *) start + offset; (void *) obj < end; obj++) {
gc_mark_maybe_object(*obj);
}
}5.評価
たらいまわし関数の実行例で他のインタプリタと比較を行う。また、言語処理系の作成とGCの作成の結合関係、保守の容易さについて評価を行う。
5.1.性能比較
性能比較をたらいまわし関数の実行時間により行う。比較対象には同じインタプリタのScheme処理系のSigScheme[3]を利用する。
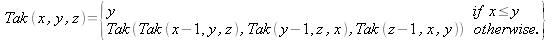
比較に利用したソースコードを示す。
(define tak
(lambda (x y z)
(cond ((< y x)
(tak (tak (- x 1) y z)
(tak (- y 1) z x)
(tak (- z 1) x y)))
(#t y))))
(tak 10 5 0)
(exit 0)(set! tak
(lambda (x y z)
(cond ((< y x)
(tak (tak (- x 1) y z)
(tak (- y 1) z x)
(tak (- z 1) x y)))
(#t y))))
(tak 10 5 0)
(exit 0)実行結果を以下に示す。
% time cat tarai.scm | sscm > /dev/null
cat tarai.scm 0.01s user 0.00s system 71% cpu 0.017 total
sscm > /dev/null 0.69s user 0.07s system 98% cpu 0.774 total% time cat tarai.lisp | ./thesischeme > /dev/null
cat tarai.lisp 0.00s user 0.00s system 19% cpu 0.020 total
./thesischeme > /dev/null 5.82s user 0.04s system 97% cpu 5.990 total% time cat tarai.lisp | ./thesischeme > /dev/null
cat tarai.lisp 0.00s user 0.01s system 20% cpu 0.040 total
./thesischeme > /dev/null 4.52s user 0.06s system 95% cpu 4.810 total% time cat tarai.lisp | ./thesischeme > /dev/null
cat tarai.lisp 0.00s user 0.00s system 35% cpu 0.011 total
./thesischeme > /dev/null 2.14s user 0.02s system 99% cpu 2.173 totalこの結果より、一度に確保するヒープサイズを大きくするほど速度が出ることがわかる。しかし、ヒープサイズを大きくしても作成した処理系はSigSchemeと比べ2倍以上処理が遅いことがわかる。
5.2.言語処理系とGCの結合関係
通常の言語処理系はメモリアロケータが全資源を握っていると仮定する。このメモリアロケータを含む記憶領域管理機構に対して不要なメモリを自動的に回収するか、言語から回収するかを考える。すると言語から回収するには言語に記憶領域管理情報を扱う機能が必要となる。これは言語が扱うコンピュータの機構の抽象度が低くなるため、抽象度の高いプログラミング言語にはふかしたくない機能である。したがって、GCの依存度は言語の抽象度と関連すると考えられる。
一方、記憶領域管理機構は言語に要求され記憶領域を渡せばどのような手法をとってもよいブラックボックスになってる。そのためアルゴリズムの改良などが独自に行える。ただし、言語が要求する記憶領域に一定の規則(同一サイズなど)がある場合、アルゴリズムの効率化が図れる。
したがって記憶領域管理機構は言語の扱うデータに依存する。又、記憶領域管理にかかる時間はプログラマーから見ると予期しがたいものがあるため、この時間が一定ではなくばらつく場合はプログラム実行時のリアルタイム性が失われる。そのため言語実行に関する制約がある場合、記憶領域の手法に制約が課せられることがある。
5.3.プログラムの保守
言語処理系とGCとの依存関係を考慮すると、処理系に新しいデータ構造を追加した場合、新しいルートを追加した場合のみGCに手を加える必要があることがわかる。ルートを言語処理系側でリンクトリストなどで管理すればさらに変更点が減り、新しいデータ構造のときのみGCを修正すればよいことがわかる。またGCの変更点はgc_mark_objectただひとつであるので、GC付属の言語処理系の保守のコストは言語処理系のみの場合の保守のコストと限りなく近いことが推測できる。
6.まとめ
GC付属のLISP処理系を作成した。これにより、保守的GCを採用する限り言語処理系とGCは完璧に分離して実装を行えることを確認できた。しかし、マークアンドスウィープGC以外のGCのアルゴリズムや保守的でないGCの場合に同様に分離して実装を行えるかの実証ができなかった。
GCのアルゴリズムによりプログラミングスタイルにどのように制限が生じるかをあらかじめ確認できれば、新たにGCを実装する開発者にとって見積もりがしやすくなる。
今回の研究で作成した処理系は一種類のGCしか実装できなかったため、もうひとつの代償的なGCであるコピーGCの実装を行うことや、GCの実行時間を分散してリアルタイム性を向上させるリアルタイムGCなどの実装を行うことが今後の研究課題である。
7.参考文献
- [1] Revised5 Report on the Algorithmic Language Scheme http://schemers.org/Documents/Standards/R5RS/HTML/
- [2] SIOD: Scheme in One Defun http://www.cs.indiana.edu/scheme-repository/imp/siod.html
- [3] sigscheme http://code.google.com/p/sigscheme/
- [4] プログラミング言語SCHEME R.ケント ディヴィグ 著 村上 雅章 翻訳 ピアソンエデュケーション
- [5] ANSI Common Lisp ポール グレアム 著, 久野 雅樹 , 須賀 哲夫 翻訳 ピアソンエデュケーション
- [6] 計算機プログラムの構造と解釈 ジェラルド・ジェイ サスマン , ジュリー サスマン , ハロルド エイブルソン 著, 和田 英一 翻訳 ピアソンエデュケーション
- [7] Rubyソースコード完全解説 HTML版 http://i.loveruby.net/ja/rhg/book/
- [8] GC FAQ draft http://www.iecc.com/gclist/GC-faq.html
- [9] Slides for talk on memory allocation myths. http://www.hpl.hp.com/personal/Hans_Boehm/gc/myths.ps
- [10] McCarthy's Original Lisp http://lib.store.yahoo.net/lib/paulgraham/jmc.lisp